
在当前,随着新一轮技术浪潮的兴起,以传统计算机技术为基础的信息时代正逐步过渡到由人工智能、云计算等关键技术驱动,各领域趋向融合的信息新时代。在这一背景下,数据库技术也正朝着崭新的方向不断发展。前不久刚结束的 ACM SIGMOD 2021 大会上,就涌现出很多值得关注的前沿技术热点。
为了让更多的数据库从业者能了解数据库领域的最新研究成果,熟悉行业前沿发展趋势,近日,腾讯云数据库联合深圳计算机学会数据科学与工程(DSE)专委会,举办了一场围绕 SIGMOD 2021 与数据库前沿研究热点的线上研讨会分享活动。
深圳大学计算机与软件学院、深圳计算科学研究院秦建斌老师,南方科技大学数据库团队负责人唐博老师,南方科技大学数据库团队晏潇老师,腾讯金融云数据库 TDSQL 资深研究员、腾讯云数据库专家工程师李海翔,以及主持人腾讯云数据库高级工程师赵展浩,多位学术专家与研究者在直播中各抒己见。以下是分享回顾。

精华抢先看
秦建斌:
在更大规模数据的驱动下,将持续催生数据 driven 的 AI+ 数据库结合等新应用。同时,数据规模的不断增大,也使得数据治理变得愈发重要,我更加倾向于关注整个数据从创建到分析利用的整个生命周期。
2007 年 SIGMOD 第一次在中国北京举办,当时论文接收率仅为 14.6%;时隔了 14 年,今年第二次在中国举办,研究型与工程型论文的接收率都有所提高。这体现的其实是数据管理技术本身的一些变化,随着云计算、大数据、智能计算等技术的演进,作为底层技术,数据库从传统的只关注 Management Of Data 开始向 Data Science 还有 Data Engineering 方面进行了拓展。
唐博:
我认同未来不仅要关注数据跑得快不快,还需要关注数据质量高不高——因为整个数据库系统是一个闭环,底层数据质量直接影响上层应用。
Cloud-Native Database System 来看,现在是处于百花齐放的状态,但还缺乏支配性的产品和应用,不管是企业,还是学术界,肯定会有越来越多的研究成果,越来越多的创新技术出现,使得 Cloud-Native Database System 逐渐成熟。
晏潇:
今年的 SIGMOD 可以看到很多关于 DB for Machine Learning 和 Machine Learning for DB 方面的成果,这意味着整个数据库的外延已经被拓宽到更加丰富的应用上。基于机器学习的 index 和查询优化值得长期关注,这其中我比较关注相似性检索和 LSH,现阶段我们也在研究利用机器学习来增强 index 和检索。
前沿成果越来越多是产学研合作的产物,深度的产学研合作融合是数据库基础研究创新的重要推动力。做有影响力的研究,要更多看向工业界,和工业界真实的需求和应用场景相结合。
李海翔:
从 2017 年起,TDSQL 开始前沿技术的研究,积极参与了 VLDB、SIGMOD、ICDE 等国际会议。在公司内部,有长期的研究积累,认为事务处理将是分布式数据库需要从基础理论层面突破的方向。在研究的过程中,瞄准业界难题,把高性能分布式事务下的“事务一致、分布式一致”双一致性等难题列入研究范围。TDSQL 在分布式事务型数据库中,首次提出顺序可串行化,有效区分了严格可串行化、顺序可串行化、可串行化的异同,丰富了分布式数据库中只有“严格可串行化”一个可串行化级别的体系,并进一步提出了多种强一致性的完整技术,在实现分布式数据库“双一致性”的同时,保持了良好的系统处理效率。
从首次举办到重返中国,14 年间数据库历经哪些技术变迁?
赵展浩:时隔 14 年以后,SIGMOD 今年再次来到中国。从首次在中国举办到重返中国,透过 SIGMOD 的 14 年发展,我们可以看到数据库历经哪些技术变迁?
秦建斌:从数据库系统来看,其实数据库整体的理论模型在这十年或者在过去二十年并没有发生一个巨大的变化,但是逐步也呈现出从以前的单机数据库到现在向云、向 NoSQL、分布式等平台进行分化演进的趋势。过去十年,数据技术领域经历了从大数据,到数据湖的发展,数据规模的不断增大催生了一系列新的应用。其次,在更大规模的数据环境驱动下,继续催生了数据 driven 的 AI+ 数据库结合的新应用。近年来的 DB for AI 和 AI for DB——AI 和数据库交叉相关的课题非常多。最后,在数据规模变大的情况下,数据治理也显得愈发重要,所以近年来数据治理的论文通常会占到 SIGMOD 收录论文的 1/5 到 1/4,全世界有很多公司,以及一些学术机构也在做这方面的研究。未来的趋势实际上是向着更加丰富的应用,以及融入 AI、拥抱 AI 等方向发展。此外一个值得关注的方向是,如何利用 GPU、NVM、RDMA 等新硬件提升数据库的效率。
唐博:2007 年,SIGMOD 第一次在中国举行,时隔 14 年,SIGMOD 又回到了中国。过去的 14 年 SIGMOD 和中国数据库界都发生了什么变化? 世界数据库领域又有哪些变化?这是我一直在思考的问题。将 2007 年 SIGMOD 的 Call for paper 与 2021 年 SIGMOD 的 Call for paper 相对比,有个明显的变化——在以前,通常大家都会关注 Data management,但 2021 年除了 Data management 部分,还关注到了 Data Science, Engineering and Applications 这两个部分。由此可以看出,整个数据库界越来越关心 Data Science 或者 Data Application 的部分。
如果再从 Topic 的角度看,从 2007 年到 2021 年,有些 Topic 是一直存在的,比如 Benchmarking and performance evaluation、Date mining and OLAP、Query processing。Transaction processing or TP、AP,这些一直存在的 Topic 是数据库特别关注的领域。

与此同时,2021 年出现了很多新的技术热点,比如 Cowdsourcing,Data Visualization,Data Systems and Management for Machine Learning,Machine Learning for Data Management and Data Systems,Distributed and Parallel Databases 以及 Scientific Databases 等,这些都是新出现的技术。
此外,也有部分已经过时的技术被替代,比如说 Peer-to-peer and networked data management, Personalized information systems,这些技术现在已经很少有人关注了。
晏潇:我提供一个观察和预测以后数据库发展的思路,就是从应用和工具这两方面去看数据库技术的演化。
从应用的角度看,首先,数据库在各个领域得到越来越多的应用,尤其是在数据整合或者机器学习方面,在今年的 SIGMOD 上我们也可以看到很多关于 DB for Machine Learning 和 Data Infrastructure 等方面的成果,这意味着整个数据库的外延已经被拓宽到更加丰富的应用上。其次,随着数据规模的不断增加,数据库中的效率和分布式问题也得到越来越多的重视。再者,越来越多的企业选择把数据库部署到云上,云数据库成为了大家关注的焦点。像资源弹性、数据库自动配置、对特定业务的优化,这些都是本届 SIGMOD 的热门话题。
从工具的角度看,最近出现的硬件,比如 SSD、NVM、FPGA、GPU、RDMA 等,这些在今年的 SIGMOD 上都备受关注。此外,还有一个特别重要的工具,就是 Machine Lerning。数据库中的查询处理、资源配置等关键步骤都有很多参数需要配置,Machine Lerning 可以作为数据库管理和配置的工具。因此,Machine Lerning 得到越来越多的认可和重视。
我认为目前数据领域的研究热点,大多是由应用和工具两股力量联合推动的,这两股力量也会持续催生出新的研究热点。
李海翔:我想介绍一下腾讯近年来在数据库技术发展以及在学术界所做的基础研究工作。
腾讯数据库的技术发展分为 4 个阶段。2000 年,我们使用了开源的数据库;随着社交增值业务的爆发增长,当时业界的开源产品包括国外的商业数据库产品,都无法满足我们的需求,2007 年,我们开始进入自研阶段,做一个像 NoSQL 这样的系统,解决高并发、金融级场景下系统面临的可用性问题,即打造了 7*24 小时高可用、高性能弹性扩展能力;2012 年,随着腾讯业务进一步发展,腾讯进入第三个阶段,即开源定制和自研,打造一个通用型的分布式数据库产品。TDSQL 从 2014 年的时候对外已经在微众银行核心系统上使用,并且逐步推广到更多的银行、保险、互联网、电商等行业企业,得到了更广泛的使用和场景验证。之后腾讯又进入了一个新的阶段,这个新的阶段就是深度开源定制 + 完全自研。直至 2017 年腾讯数据库开始重点投入基础技术研究,来从基础理论层面出发,布局前沿数据库技术创新突破。
回看腾讯数据库创立的过程,腾讯创立的早期,为了高效支持社交业务快速增长的需求,使用开源数据库去搭建数据库应用。当时最流行的是集中式的 Oracle。但是面对互联网的海量数据业务,Oracle 在性能、扩展性方面远远无法满足腾讯这种互联网公司的需求。实际上随着腾讯业务的技术发展,当时行业上包括开源、国外数据库产品等的技术边界日益显现,逐渐都无法满足我们的要求。互联网业务,要求数据库要具有很好的连续性,即高可用性,从而保障客户的体验。因此对数据库的自动故障恢复能力,7×24 小时的容灾能力有非常高的要求。其次,对于增值业务这种涉及了资金的业务不允许有一分一毫的差异,对于数据库的高一致、高可靠性有着非常高的标准和要求。在这种背景下腾讯开始围绕着金融级的高可用、高一致性以及弹性扩展等数据库基础能力,构造应用于云计算、互联网这种海量场景的金融级分布式数据库技术。
2014 年,腾讯数据库遇到了发展的重要契机,支持面向普惠的微众银行的构建。普惠,意味着成本要低。如何把内部使用的 TDSQL, 应用到银行去,这是非常巨大的挑战,也是 TDSQL 发展的机会。在微众银行场景的磨练下,TDSQL 真正地变成了一款满足金融级监管和业务要求的成熟标准化国产分布式数据库产品。不同于传统的集中式数据库,TDSQL 基于自研的互联网分布式技术架构,针对金融以及政企行业连接交易场景提供成本低,高可靠、高可用、高弹性的数据库服务,为金融行业“去 IOE”提供了切实可行的解决方案。
在微众银行得到应用后,TDSQL 被部署上腾讯云,开始面向全行业开放。我们开始意识到,在云计算时代分布式架构转型是一种必然趋势,TDSQL 在微众银行的成功实践,必然可以帮助更多的金融政企客户实现低成本、高可用的“去 IOE”改革。事实证明,TDSQL 突破性帮助用户实现了银行传统核心系统的数据库国产化。比如帮助平安银行客户实现行业首例大机下移,这是金融数据库国产化替换的里程碑事件。但是在这个阶段腾讯的 TDSQL 数据库一直在思考的是,替换就是我们的终极目标吗?我想肯定不是的,因为技术一直在发展。对我们厂商来讲,分布式数据库的产业化是企业没有走过的路,而技术与场景都在不断演变而前进的,这更加充满了不确定性。举个例子,腾讯 TDSQL 在全国第七次人口普查工作时就用到了 OLTP 以及 OLAP 这两个融合引擎的能力,这就我们此前一直在研发的 HTAP 混合架构。
技术和场景经过这样相互促进,催生出一种创新的力量,让 TDSQL 得到巨大的锻炼。我想未来这样的机会还有很多,比如 AI 和数据库的融合,在数据库中如何实现智能运维、自动化调优等等能力,这些都是新的挑战。因此我们必须要立足于工业应用的基础,来看基础理论创新,去做更多创新性的工作,从追赶到实现超越,推动产业不断升级。近几年腾讯也在数据库基础技术方面投入了很多,也有了一些比较好的产出,并在 CCF 推荐的 A 类顶会顶刊发表的一些论文。
从 SIGMOD 论文看数据库技术热潮
赵展浩:可以看到这十多年来数据库行业确实发生了很多变化,包括 AI+DB、新硬件、分布式数据库的发展等都是近年来关注度很高的领域。接下来,请各位老师点评一些专业领域内的论文技术,从专业的方向角度分析某一具体领域的技术发展。
秦建斌:先看一点背景,2007 年 SIGMOD 第一次在中国北京举办,当时论文接收率仅为 14.6%;时隔了 14 年,今年第二次在中国举办,今年工程型与研究型论文接收率都有所提高。其实这背后是 SIGMOD 代表的数据管理技术本身的一些变化,随着云计算、大数据、智能计算等技术演进,作为底层技术,数据库从传统的只关注 Management Of Data 开始向 Data Science 还有 Data Engineering 方面进行了拓展。
而从我个人研究领域出发,回国以后我的研究方向主要是数据治理。在今年的 SIGMOD 论文中大概有接近 1/4 的是围绕数据治理方面的。数据库系统在做数据管理之后,数据已经被存下来。这些存下来的数据,要应用到后面的数据分析过程。因此数据的有效性、可靠性就十分关键。大概二三十年前,就已经有人在研究这方面的内容,那时候偏理论化一点。
这几年我们可以感觉到数据库领域在数据治理方面更偏向于解决系统运行过程中遇到的实际问题。
第一个问题叫做自动化配置,这是数据治理系统一个很重要的问题。在数据治理系统架设之后,由于功能非常强大,有上百个参数和配置供我们去选择。遇到这种实际的问题时候,自动化配置是非常关键的。在一个新的数据环境下,如果没有一个很好的配置,可能跑起来根本就达不到预期的效果。
第二个是复杂约束条件。基于传统逻辑延伸过来的简单约束条件,无法表达现实生活中一些比较复杂的情况,所以像 FD、CFD、Deny constriant 这种复杂的约束条件就出现了。这次大会也有关于复杂的约束条件的论文出现。
第三个隐私计算。隐私计算实际上是这十年发展比较快的领域。自从 2007、2008 年有差分隐私的论文以来,数据库一直在关注差分隐私怎么用在数据库里面。因为在数据治理的过程中也需要关注隐私会不会被泄露。
第四个是数据剖析。近几年我们在做数据治理项目的时候发现,用户希望知道数据里面的问题,他们希望拿到数据后,你可以快速地告诉他们,这个数据里面正确率有多少,不一致性有多强。他们更希望看到做宏观上统计性的数据,以及看到你剖析的统计意义上的数据质量问题,指出质量统计值的变化和提升。所以数据剖析也是很重要的。其实这是一个蛋生鸡还是鸡生蛋的问题,你有一个很好的办法来判断数据哪里有质量问题你才能更好地剖析,但如果你没有很好的剖析方法,你也不知道数据的质量问题在哪。近几年有些研究工作在打破这样的死循环,提出了一些比较通用的数据质量剖析方法。
第五个是数据探索,利用可视化工具来对大规模的数据进行有效的探索,从而发现需要的数据或者数据中的问题。
第六个是 Outlier。Outlier,是我们真正做数据治理的时候会遇到一个比较常见的问题,今年好几篇论文也在做这方面的研究。
第七个问题是 Incomplete 数据。在做数据治理的时候,包括做实体匹配、实体消歧的时候,常常我们拿到的数据是不完整,有很多空的数据,这就会带来不同的语义。
最后一个是数据扩增。数据扩增是近年来数据库和 AI 领域结合的产物。数据库数据的扩增它一方面是为了来更好地利用标记好的数据,标记好的数据可以扩展到更多没有标记好的数据。另外一方面利用数据库聚类,还有 AI 的方法来把正确的或者说质量比较高的数据,来扩增出质量比较差的数据用于做 training。
唐博:我来讲一下我关注的系统方面的几个工作。
第一个工作就是 Shared Query Execution。其实 Shared Query Execution 是 Core DB 里面大家比较关注的问题。我记得最早看到 Shared Execution 的文章是在 2014 年,ETH 团队做的一个 Shared computing。他们这篇 Paper Focus 是在 Time Slackness。我们如果有一些其他新的场景或者新的业务,Shared Execution 应该是一个很 promising 的方向,能够给我们 Insights 或者能够给我们 guideline, 去 implement 一个 new 或者 nova 的 Techniques,去加速我们现有的 Query possessing。
另外一个我比较关心的问题就是 Cardinality Estimation。这个工作是 NTU Gao Cong 他们团队的。NTU 的这个工作其实是在提高 Cardinality Estimation 的准确度。这个背景很简单,就是我们要做查询优化器的提升或者 Cardinality Estimation 的提升。传统的办法是用 histogram 得到查询的 selectivity,Cardinality Estimation。现在因为 ML For DB 的火热,就有很多论文出现了,比如说 VLDB2020,就有两篇论文,通过 Learn from Data 去提高 Cardinality Estimation 的准确度。基于这一点他们从 Data 本身出发,去挖掘 Data 的信息,去 Learn from Data,然后去做 Query 的 Cardinality Estimation,这是一个方向。另外一个方向是从 Query 出发,在 Learn 已有 Workload 的基础上,再去做 prediction。其实很久之前的 multidimensional workload-aware histogram,就是通过类似的 Workload-aware 机制去建立 Histogram 的。
最后是 EDA(Exploratory Data Analysis)。Insight exploration 是一个很传统 OLAP 的工作。Auto Insight,是指自动挖掘隐藏在数据里面有价值的部分——相当于通过几个步骤的工作,把 Multi-dimensional 的中间结果 cache 起来,然后利用 Query cache 实现 Data Pattern Mining,在 Data Pattern Mining 之后实现 Meta Insight Mining,在 Meta Insight Mining 完成后把结果 Ranking 结果返回给用户。
我关注的其他 Paper 是关于 System 或者 core Database 的。第一篇我感兴趣的论文 Scan in MVCC Databases, 就是 Query Optimization 的一个典范。从我的角度来讲,在 Query Optimization 领域有很多工作可以探索,但我们现有的这些工作是不是真的能应用到实际的 Database System 上,能有多大的性能增益,查询处理时间是否会因为 ML 技术的引入而缩小?到现在为止我们还没看到一个真的 System 加入了 ML 的 Techniques 去做 Query Optimization,而能够实现比原来的 Query scan 这些方法要好。

这有两方面的问题:一方面 Database 是一个大的 System,想要 Integrated 进去并不容易。另一方面现有的 Research 其实是在为后续的研究开辟方向,正向 Engineering 的 System 扩展,这个难度是显而易见的,因此我觉得未来在这个方向上还有很多可以去做的事情。
此外像 Query Processing Engine for Irregular Table Partitioning,这也是很有意思的研究。当你有一堆 Table 的 Partitioning 的时候如何做 Storage 和 Query Processing;如何去 utilize Bandwidth,从而提升 OLAP Workload 的 performance;以及在 Multi-GPU Architectures 里面,如何 Scalable Join Processing,这些都是很有意思的问题。
其次是 Instance-Optimized Data Layouts for Cloud Analytics Workloads,一个基于云计算进行的研究。接下来的 Steering Query Optimizers,是 Query Optimizers 方面的研究。
再者 Benchmarking the Efficiency of a Cloud Service,这个方向我也感兴趣,用一个 Benchmark 来 evaluate 一个 System 到底好不好或者它在哪些情况下好,到现在为止行业尚未产生非常好的方法,能够实现 Benchmarking the Cloud Service。
最后是 Cloud-Native Storage,我们都知道,在 Cloud-Native 的 Database System 里有很多新的挑战,比如说进行资源调度,计算和存储分离之后整个存储层的资源调度是一个很大的问题,以及如何实现具备优秀 Storage 的 System,这些都是具有挑战性的事情。
晏潇:我主要是跟大家交流一下 Sketch 和 LSH 结合这个领域的最新进展。
LSH 和 Sketch 是一个历史悠久的研究领域,LSH 是一种 Sublinear time 的相似性检索算法,基本思路是建立 Hash table,能够保证相似的对象被 hash 到同一个 bucket 的概率更高。这个基础理论,早在 1998 年被 Indyk 提出,后面慢慢发展出了 E2LSH(对于 P-norm),SRP(对于 Cosine similarly)等不同相似度量的哈希函数。在 Query Processing 这方面,研究建好 index 之后,如何提高查询处理效率,代表性的工作有 Multi-Probe LSH、LSB-Tree 等。Bloom filter 是一个能够做 set membership test 的数据结构,它建立一个 binary array,通过对 entry 进行哈希,就能判断一个它是否属于一个集合。还有 Count-min Sketch 或者 Count Sketch,用于 frequency estimation,即估计一个集合里面的 entry 出现的次数,也在 2005 年被就被提出来了。
可以看出 LSH 和 Sketch 是一个研究历史非常悠久的领域。因为它们能够实现数据的高效处理,也是 SIGMOD 中备受重视的领域。在今年 SIGMOD 的 Keynote 中,李建中老师指出,随着数据量的爆发式增长,为未来对高效数据处理的需求将更为迫切。以下我将结合今年 SIGMOD 的文章,讲一讲在 LSH 和 Sketch 领域最近的新应用和研究发展。
第一个用 LSH 去做异常检测。每个记录都是高维向量,如果它是一个正常数据,它应该是离大家都比较近;如果是个 Outlier,它应该离大家都比较远。但如果要对整个数据集都计算距离,那么复杂度很高。这种场景下,我们可以用一个简单的方式来进行:建一个 LSH Counter,在 LSH Hash table 里,我们不存 Item,我们只存每个 bucket 里面有多少 item。一个查询到达之后,我们看它 hash 到哪些 bucket,然后将这些 bucket 中的 item 数求和,如果和的数值比较少,它就可能是个 Anomaly。这个方法能得到证一些理论上的保证,效果比较好。
第二个工作是用 Count Sketch 进行机器学习模型的压缩。一些线性模型,比如说 SVM 和 Logistic Regression, 当 feature 维度很高时,模型会很大。比如如果我们利用文本中的 skip gram 来构建 feature,Model 可能包含 million 或者几十个 Million 的 Features 级的参数,这样存储或者在网络上传输都很不方便。这里介绍一个斯坦福大学的研究:如果有一个特别高维的分类器,这个高维的分类器权重一定是稀疏的,在这个稀疏的权重写入一个 Count-min Sketch——因为 Count-min Sketch 用于进行 Heavy Hitter 检测,保证比较大的 entry 受到干扰比较小,所以它也证明了在一定条件下用 Count-min Sketch 来学习 classifier 和精确的 classifier,也是有一个 error bound。
最后一个工作是用 LSH 实现图压缩。因为 Sketch 和 LSH 能够对大数据进行高效的处理,所以一直是数据库领域研究的热点,我检索了一下,发现 SIGMOD 上 180 篇文章中大概有 14 篇是研究这个方向。
总的来说,Sketch 和 LSH 大概有两个研究方向,第一个研究方向是把 Sketch 和 LSH 和更多的应用相结合,比如说 Kernel Density Estimation,分布式机器学中的梯度压缩,机器学习中的 privacy 等,加速神经网络的训练和推理,互信息的估计。当然也有对新的度量,设计新的 LSH 函数,比如说 LSH for string edit distance,LSH for earth move distance。另外,最近两年用机器学习来增强 Index 这个方向也有很多研究工作。作为一种从数据中学习规律的方法,用机器学习来增强 Sketch、LSH 也是很自然的事情,比如说增强 Bloom filter,增强 Count-min Sketch,还有增强的 LSH。
近几年明显的数据库技术趋势之一,是把 Sketch 和 LSH 用到大规模机器学习任务或者数据库任务里面,或者利用机器学习对 Sketch 和 LSH 进行增强。

李海翔:我先分享下腾讯数据库在数据一致性方面的研究。本届 SIGMOD,我们发表了一篇 Sigmod Paper SRC track,就是在讨论数据一致性问题。
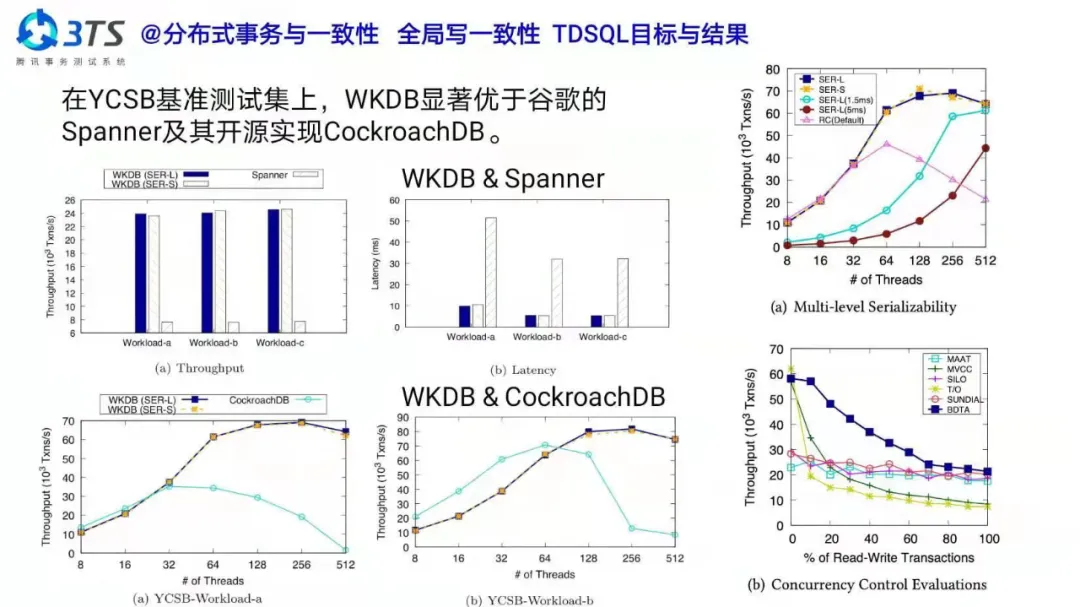
高性能分布式事务下的事务一致、分布式一致,一直是业界难题。我们研究出的 TDSQL 多级一致性技术,是在遵循了 ACID 特性的同时,使得事务处理技术符合 CAP 原理,并在理论层面相较“严格可串行化”技术做了扩展,并进一步提出了多种强一致性的完整技术。在实现分布式数据库“双一致性”(事务一致、分布式一致)的同时,极大地提高了处理效率。各类测试显示,该技术性能是同类产品 Spaneer 性能的 4+ 倍、CorchroachDB 的 2+ 倍,而高并发场景下是 Greenplum 性能的 3+ 倍。
下面我将重点分享另一个事情,即数据异常。
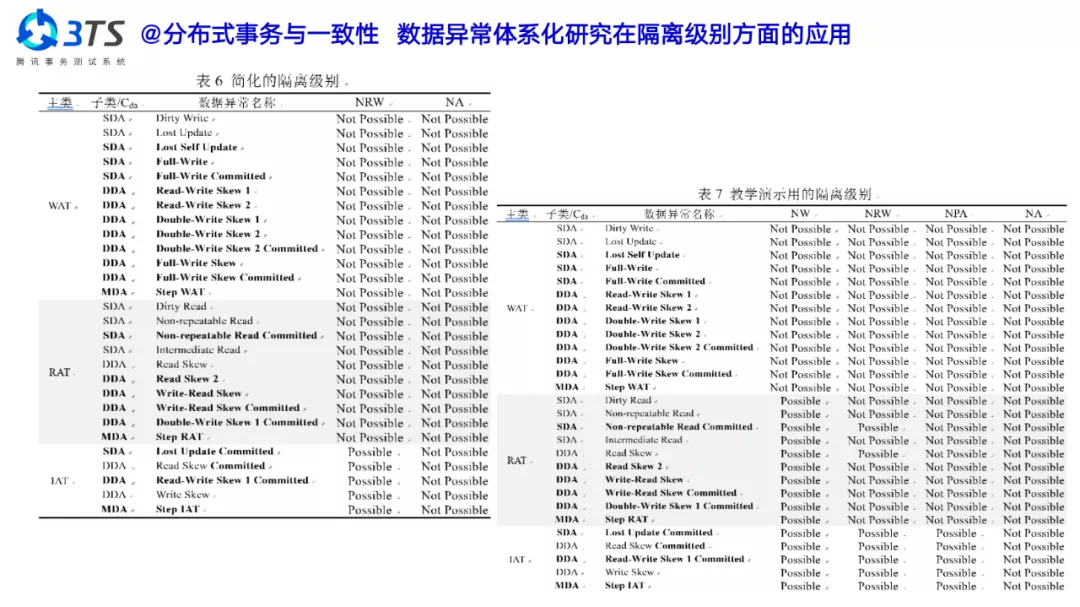
数据异常目前并没有一个通用的定义。我们从数据异常、变量和并发事务之间的关系入手,把三者统一在一个模型下,对数据异常加以形式化的定义,这时我们发现数据异常其实有无穷多个。我们对数据异常进行了特征研究,然后用环科学得表达了所有的数据异常。

此外,我们也去探索了数据异常和数据一致性之间的关系。两者的关系可以用形象的定义来描述:“一致性等于无数据异常”,只要没有数据异常那么就符合数据一致性;反之,“不一致就等于有数据异常”。我们用数据异常去尝试定义了数据的一致性。
同时,我们还研究了数据异常和隔离级别之间的关系。当我们在数据异常分类的基础上,尝试去重新定义隔离级别时,我们发现隔离级别的定义似乎是很灵活的,它可以定义出不同级别或者不同粒度的一致性。我们可以分成多个层次,去定义成不同粒度的隔离级别。
总的来说,腾讯在整个事务处理领域所做的基本工作,可以概括为:我们希望提供一个相关的研究框架(Tencent Transaction Processing Testbed System,简称 3TS),在这个系统里做一些以事务处理为核心的工作,或者和其他技术相结合来做一些具体的研究。比如事务处理怎么和可用性相结合,怎么和可靠性相结合,怎么和安全相结合。
数据库发展下半场,专家们都在关注哪些方向?
赵展浩:这个环节想请老师们谈谈,下个阶段有什么课题或技术方向值得我们持续关注?
秦建斌:目前我们正在关注包括数据治理方面等。以前很多做数据库系统的朋友,比较关注的是数据库系统跑得快或慢,但实际上我更想关注这个数据生成的过程——从数据的最早创立到后面处理,直至最后整个生命周期的管理的过程。
目前,数据库做数据治理已经有很多工具,但怎么能发挥发真正的价值,这是我们在关注的工作。
唐博:关于未来,我觉得不仅要关注数据跑得快不快,还需要关注数据到底好不好,这是整个数据库系统的闭环,即是从底层数据质量保证上层的应用。同时,未来有以下几个大方向值得关注:
第一,Cloud-Native Database System 领域,现在看来是处于百花齐放的状态,但尚缺乏一个 dominate 的因素,不管是企业,还是说学术界,肯定会有越来越多的研究成果,越来越多的创新技术出现,使得 Cloud-Native Database System 慢慢得到大家的认可。
第二,我们现在所有的东西都是基于现有的计算硬件,比如说英特尔的芯片,或者是 GPU,来对 Database System 进行优化。但是有越来越多业界人士认为,可以探索推动 DB 和 OS 的结合。因为我们知道很多业务场景,机器压根就是在做 DB 的事情,跟其他 OS 功能关系不大。是否可以针对 DB 的基本操作,设计专门的 OS 呢?这个方向会遇到很多挑战,也会是未来大家越来越会关注到的地方。
第三,查询引擎的优化。AI 的到来一定会带来查询引擎的改变,不管是 AI 辅助 DB,还是 AI driven DB,这部分会有更多的可能。另外,这也会让云和设备出现新的场景。
晏潇:数据库主要是应用驱动的领域,最近几年图数据库异军突起,出现了 TigerGraph,Titan,JanusGraph 等系统。因为有很多查询,需要做比较复杂的关联分析,而在图上做 pattern matching,相比于 SQL 的 join 在复杂关系分析能力有很多的优势。因此图数据的发展值得持续关注。
另外是先进硬件方面,先进硬件为 Query 的查询和优化都带来了很多不同的挑战。像 GPU 这种先进硬件带来的查询,机遇和挑战是并存。现阶段我们也在用 GPU 做向量空间、Top-K 查询的加速。
第三个方向是基于机器学习的 index 和查询,我比较关注相似性检索和 LSH,现阶段我们也在研究用机器学习来增强 index 和检索的工作。
此外值得一提的是,从今年的 SIGMOD 来看,有一个特别明显的趋势,很有影响力的 Paper,单独在学校做的已经越来越少,大多有影响力的 Paper 都是和业界合作的,比如说和谷歌、亚马逊这些顶级公司合作。我认为做 Reserch,想要有影响力,就要更多看向工业界,和工业界真实的需求和应用场景相结合。我觉得这在未来会是学术研究的新范式。
李海翔:未来,腾讯还会长期致力于在数据库的关键技术领域,比如事务处理、AI 智能化结合、查询优化、数据治理等方面,持续投入研究。我们将会下沉到基础理论层面开展更多深入研究,推动基础研究与工程应用相结合,同时加强与业界、学术界的合作,把先进的技术成果引进来,让研究成果更好地落地到实际应用中。




