
1. 背景
现在公司有两套日志分析平台,一套是最初基于开源 ELK 栈(OSS 版本)自行搭建的微服务系统的日志分析平台,该平台主要用于自研系统中微服务的日志集中管理,日志的搜索与问题分析查找。由于微服务的监控告警,有另外一套监控告警平台 Prometheus 进行处理,因此日志监控告警并未纳入系统建设考量中。另外一套是后续引入的基于国内某商用日志产品(以下简称 R 产品)搭建的运维日志分析平台,该日志平台主要用于非自主开发的各业务应用系统,以及各基础设施,操作系统等日志的收集,日志的集中存储。一是满足金融监管的需要,二是对第三方日志数据进行分析,监控与告警。
R 产品与其他广泛使用的商用日志平台如商用 ELK、Splunk 的收费模式不一样,它基于日志流量来计费。以前我们只接入了挑选的核心日志数据,随着公司需接入的日志种类越来越多,现有的流量计划已经远不能满足运维日志增长的需求了,超出的流量需要购买额外的流量包,花费也还不小。而自研系统中日志监控也在纳入建设计划中,并且 ELK 平台不仅仅是一个日志分析平台,它更是一个完善的大数据分析平台,为统一日志分析平台,同时也为今后的大数据分析打下基础,我们有了自建平台并替换现有的 R 产品的构想。
下面我们就将这次日志平台的选型、部署架构设计、配置管理、相关插件应用、性能分析、服务监控的改进与展示等实践经验进行分享。
1.1 适用对象
该日志平台重构全部基于开源软件,经过近半年的生产上线实践,平台运行稳定,可扩展性好,可用性高,可以很好满足公司对于金融业务不断发展的需要,也对中小型企业的日志平台,大数据分析平台选型和部署有较好的参考作用。
1.2 术语与缩写
ES:Elasticsearch
ELK:Elasticsearch,LogStash,Kibana 栈
ODFE:Open Distro for Elasticsearch
2. 日志平台选型
原有的 R 产品相对开源的 ELK 的额外功能,对于我们的系统应用来说主要体现在以下几个方面:
用户认证及权限管理。
告警功能,R 产品提供了邮件、短信等告警功能。
提供了统一的部署、管理、监控功能,界面配置更方便。
对于权限管理与告警功能,Elastic 增值版(增值模块部分开源,比如加密与 SQL,带开源增值模块的称为 Basic 版,但 License 不同,我们需要的告警和认证权限管理为收费版本,它按数据节点收费)和商用的 Splunk 也涵盖,但按我们的需求两者每年的授权费用也都不低。
再看看开源方案,亚马逊有一个利用开源的 Elasticsearch 和 Kibana 的代码开发的一个开源日志产品 Open Disto for ElasticSearch,许可方式与开源的 ELK 一致,它以插件的方式提供了 Elastic 的增值功能,如告警与安全权限管理,多租户管理等,涵盖了我们需要的所有增值功能,重要的是它 100%开源。该产品也比较成熟,亚马逊自身就基于 Open Distro 提供日志云服务,与 Elastic 展开竞争,Elastic 为此还修订了开源平台许可协议。
以下列表为几个 Elasticsearch 产品增值功能的横向对比。
Amazon 也正在将 Open Distro 迁往 opensearch.org,让该产品成为一个独立的竞品,产品将基于 Elasticsearch 7.10.2,并继续保持开源,Amazon 同时也表达了团队对该产品的长期持续的支持。
以上增值功能数据表明,Open Distro for Elasticsearch 可以涵盖现有公司运维 R 产品平台的所有功能,同时有著名企业 Amazon 长期的产品支持,而我们现有的两个日志平台底层都是基于 Elasticsearch,可以进行平滑迁移,迁移成本很低,因此它也成为我们这次平台迁移的不二选择。
3. 部署架构设计
对于数据类服务,内存和磁盘 I/O 非常重要,而对于数据集群来说,由于涉及节点之间的通信和数据传输,快速可靠的网络显然对分布式系统的性能也是很重要的。对于硬件配置,Elasticsearch 官方有一些指引。
3.1 硬件配置指引
3.1.1 内存
Elasticsearch 官方对于内存的使用,32G 是一条重要的分界线,一般建议一个节点内存不要超过 64G,标准的建议是把 50% 的可用内存作为 Elasticsearch 的堆内存,因为排序和聚合都很耗内存,剩余的留给 Lucene 做缓存。Lucene 段存放在单独的文件中,这些文件不会改动,非常适合在内存中做缓存以提升存取速度。
对于超过 64G 内存的大内存机器,可以考虑在同一台机器中划分出多个 Elasticsearch 节点,每个节点使用 64G 内存。
3.1.2 磁盘
建议 SSD 存储或速度较快的硬盘,Elasticsearch 中内部使用 Replica 来保证数据的高可用,因此没有必要考虑使用硬盘镜像如 RAID 1,RAID 0 可提供更高的磁盘容量,存取速率更高。
Elasticsearch 可以通过设置节点类型热,温,冷的方式来实现不同存储介质的混合存储,以取得存储速度和存储成本之间的平衡。
3.1.3 网络
现在的千兆和万兆网络对于 Elasticsearch 集群来说已经足够,应该避免集群跨越多个数据中心,更大的延时会加重分布式系统中的问题而且使得调试和排错更困难。
3.1.4 CPU
大多数 Elasticsearch 部署往往对 CPU 要求不高,当然更多的核心数更好,因为 elasticsearch 的 thread pool 和这个配置直接相关。
3.2 软硬件配置
以下是我们这次重构使用的软硬件方面的配置信息。
3.2.1 主机硬件配置
没有配置 SSD,硬盘转速 10K,存储介质没有差异,我们暂不考虑 Hot-swarm 节点。
3.2.2 软件配置
3.3 Elasticsearch 节点设计
由于物理机器配置比较高,内存大,CPU 核心数多,单台物理机部署单个 ES 节点并使用全部内存的方式并不能充分发挥 ES 的性能。按以上内存配置指引,我们可以在一台物理机上部署多个 ES 节点,在我们的节点类型设计中,每个 ES 节点不采用复合类型而采用专用节点类型,也就是各个节点只能有一种节点类型,不能既是主节点,又是数据节点。
3.3.1 ES 节点类型与设计
按 Open Distro 官方支持的类型,我们选定部署以下节点类型:
主节点,主节点负责整个集群的元数据管理,包括全局的配置信息、索引信息和节点信息,负责索引的创建或删除,分配分片等操作。为实现高可用集群将设置专用的 3 个主节点。
数据节点,用于数据的存储,CRUD,搜索,聚合等,数据节点保存包含已建立索引的文档的分片,集群中各物理主机设计了 4 个数据节点。
预处理节点,在索引数据之前通过 Pipeline 执行数据的预处理,类似 Logstash,对数据进行解析转换,集群中设计了 3 个专用预处理节点,各物理主机 1 个。
协调节点,协调节点将请求转发给持有数据的数据节点。每个数据节点在本地执行请求,并将其结果返回给协调节点。在收集阶段,协调节点协调节点将这些结果汇总(reduce)成一个单一的全局结果集(gather 阶段) 。集群中设计了 3 个协调节点,各物理主机 1 个。
下表是各节点类型对硬件资源的需求情况:
3.3.2 ES 节点设计
单台物理机部署多个 ES 节点,可以采用多种方式:
虚拟机
容器
单机启动多个 ES 进程
虚拟机相对容器来说比较重,对资源消耗大,而采用多 ES 进程方式却难以对资源进行隔离和控制,容器则结合了两者的优点,ES 容器节点可做到相互隔离,比虚拟机轻量,也更能充分发挥物理主机的性能,容器方式是一个不错的选择。
基于以上原因,整个 ES 集群及相关服务软件将采用容器方式进行配置与管理,为便于管理,容器集群的编排方案采用公司现有标准 Docker Swarm Mode,配置文件则采用 docker-compose.yml 格式。
为保证数据的高可用,我们设置 ES 副本数 Replica 为 1,按设计同一台物理机将部署多个数据节点,为避免主分片和副本分片分配到同一台物理机上,我们可以通过 Shard Allocation Awareness 的设计,将 ES 集群中的节点按不同的物理主机分配不同的 rack id,实现方式如下:
节点命名规范化,比如 elk1 机器上的节点名后缀为 x1。
通过 Lable 将所有节点名后缀为 x1 限定部署在 elk1 上。
所有节点名后缀为 x1 的设置为同一个 rack id,比如 rack_01。
Elasticsearch 应用配置文件中配置相应的 awareness。
整个 ES 相关节点的配置如下表所示(生产环境):
3.4 逻辑架构设计
日志按数据源分为两大类,一类是落地的日志文件,这些日志文件需要通过 ES 客户端比如 FileBeat,WinLogBeat 直接读取并发送到 ElasticSearch 由 ingest 节点进行解析然后通过数据节点进行存储;一类是日志格式的网络包,它们通过网络协议(TCP/UDP)发送,比如网络设备通过 TCP/UDP 或者微服务直接通过 TCP 发送的日志信息,这些通过网络传输日志一般先通过 LogStash 进行日志解析,然后再通过 Logstash 写入 ElasticSearch。
以下是 ES 集群的逻辑架构图:
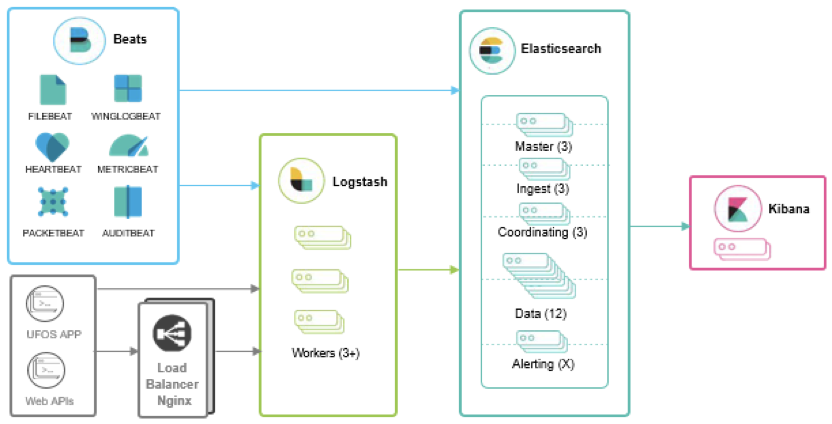
图中,对于直接通过网络比如网络设备传输的日志我们引入了 Nginx 对数据进行负载均衡。其实 Docker Swarm 集群内部本身就提供负载均衡机制,但由于该负载均衡不能保持网络设备发送端的源 IP(经 Swarm 变成了 Docker Ingress 的内部 IP),因此我们引入了外部的 Nginx 分别为 TCP 和 UDP 包做负载均衡并配置了相应的源 IP 保留设置,Logstash 容器运行也采用了 host 网络模式以保留源 IP。对于流量比较小的日志数据包,可以不需要通过 Nginx 做负载均衡,直接发送到 Logstash 进行处理即可。
架构中并没有设计消息队列,这是基于以下原因:
现有通过网络协议传输的日志整体流量不大,不到 M/s 级别,而 Logstash 本身内部就具有缓存机制,可有效应对波峰的数据缓冲,该缓存大小可以自行配置。
ES 文件类传输客户端如 Filebeat,在将数据发送到 Elasticsearch 时,Filebeat 使用背压敏感协议,以应对更多的数据量。如果 Elasticsearch 正在忙于处理数据时,则会告诉 Filebeat 减慢读取速度。一旦拥堵得到解决,Filebeat 就会恢复到原来的步伐并继续传输数据。
因此在我们架构设计中没有采用消息队列,避免进行过度设计。
3.5 ES 集群高可用部署架构设计
金融系统向来对高可用性有着较高的要求,在 ES 集群的高可用设计中,我们主要是通过以下几个层面进行。
3.5.1 硬件设施
硬件上主要是保证主机和网络设备的高可用:
物理主机三台,通过部署架构设计,允许在一台主机出现问题时,另外两台主机还可以支撑整个 ES 集群的运行。
主机上 4 个网卡两两绑定,绑定的两组网卡分别连接到一主一备的交换机,允许在一台交换机或两个网卡出现问题时,不影响 ES 集群节点之间的通信。
3.5.2 基础服务软件
3.5.2.1 系统软件
对于 ES 集群的访问都限定为通过设定的域名进行访问,为防止主机故障时导致的不可用,在系统层面,我们配置了虚 IP(VIP),该虚 IP 对应设定的域名。对于虚 IP 资源的创建和管理我们采用了 Linux 系统提供的资源管理软件 PaceMaker&CoroSync,该软件通过 heartbeat 方式检测主机故障,在主机故障时会自动进行 IP 地址的切换,从故障主机切换到其他运行正常的主机。
红帽的 OpenShift 套件底层就是使用 PaceMaker&CoroSync 进行的资源高可用性管理,它的稳定性毋庸置疑。
3.5.2.2 Docker 集群
ES 所有相关的服务都采用 Docker 方式部署在 Docker 集群,在 Docker 集群的节点编排上,我们采用的是公司现有实施标准 Docker Swarm。三台物理主机都配置为 Swarm Manager,三个 Manager 可保证单台 Docker 节点故障时依然保证 Docker 集群的高可用。
添加更多的物理主机时可以将 Docker 节点以 Worker 节点方式加入 Swarm 集群。
3.5.3 ES 核心访问软件
ES 集群本身本来就是按高可用模式设计,可以简单通过加入更多的 ES 节点进行横向扩展,ES 在存储数据时,会尽量把一个索引的分片(Shard)存储在不同的节点上,同样分片的副本也尽可能存在不同的节点上,这样可以提高容错率,在节点设计一节中我们描述了如何配置节点 rack_id 以支持在一个物理节点部署了多个 ES 节点的情况下仍就保持 ES 集群的高可用(ES 会根据 rack_id 避免将主分片和副本分片分配到同一台物理机上)。
3.5.4 ES 集群高可用部署架构
如果将 ES 集群所用到的所有系统软件和应用软件划分开来,ES 集群高可用软件部署架构如下图所示:
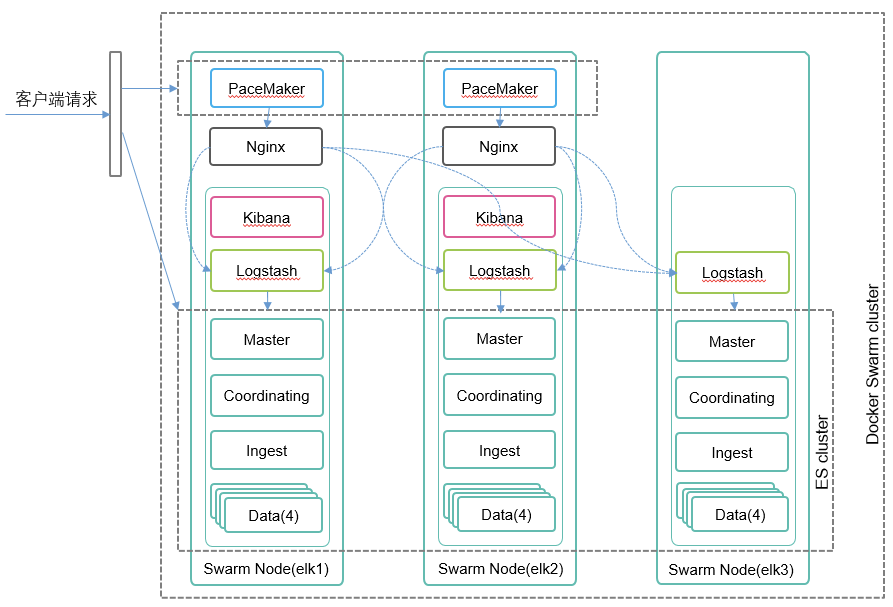
通过 Linux PaceMaker 服务,在 elk1 和 elk2 主机创建一个虚 IP 资源,并在 DNS 服务器创建一个域名指向该 VIP,客户端对 ES 集群的访问都通过该域名进行。
在 elk1 和 elk2 上分别部署了一个 Nginx 和 Kibana 容器实例,这样在其中一台主机发生故障 VIP 漂移到另外一台主机时,客户端可以以最快的速度切换连接到该正常主机上启动的 Nginx/Kibana 服务。
Logstash 和 Ingest 节点需要通过 Pipeline 对数据进行预处理,计算资源消耗较高,因此在每个主机分别部署一个实例。
所有对 ES 的请求(包括 Logstash 和 Filebeat 客户端)都是通过 Coordinating 节点进行,因此也在各个主机部署了一个实例,这个采用 Swarm 的 global 选项来配置,Swarn 的 ingress 内部机制保证访问的负载均衡,当然也可以直接在客户端通过指定 ES 节点进行直接访问。
3.6 Elasticsearch 服务治理
3.6.1 ES 集群监控
Elasticsearch 本身可以搜集系统,应用或服务的数据(包括使用 Filebeat 收集日志数据,Metricbeat 搜集系统级如 CPU,磁盘等统计数据,或经常使用的服务如 Nginx,MySQL,Prometheus 等的指标数据),通过分析这些日志,指标/度量数据,对相应的系统,服务和应用的性能,健康状态进行监控和告警。
但 Elasticsearch 自身出现问题不能由自己来监控,除非准备另外一套 ES 集群,ES 集群自身的问题可以通过其他的工具来监控。
公司现有的运营微服务平台有一套基于 Prometheus 的业务监控系统,Prometheus 有着丰富的监控插件,其中就提供了对 Elasticsearch 集群的度量数据进行导出的 Exporter;结合 Grafana,还可以对 ES 集群的度量数据进行图形展示。
3.6.2 ES 集群监控管理工具
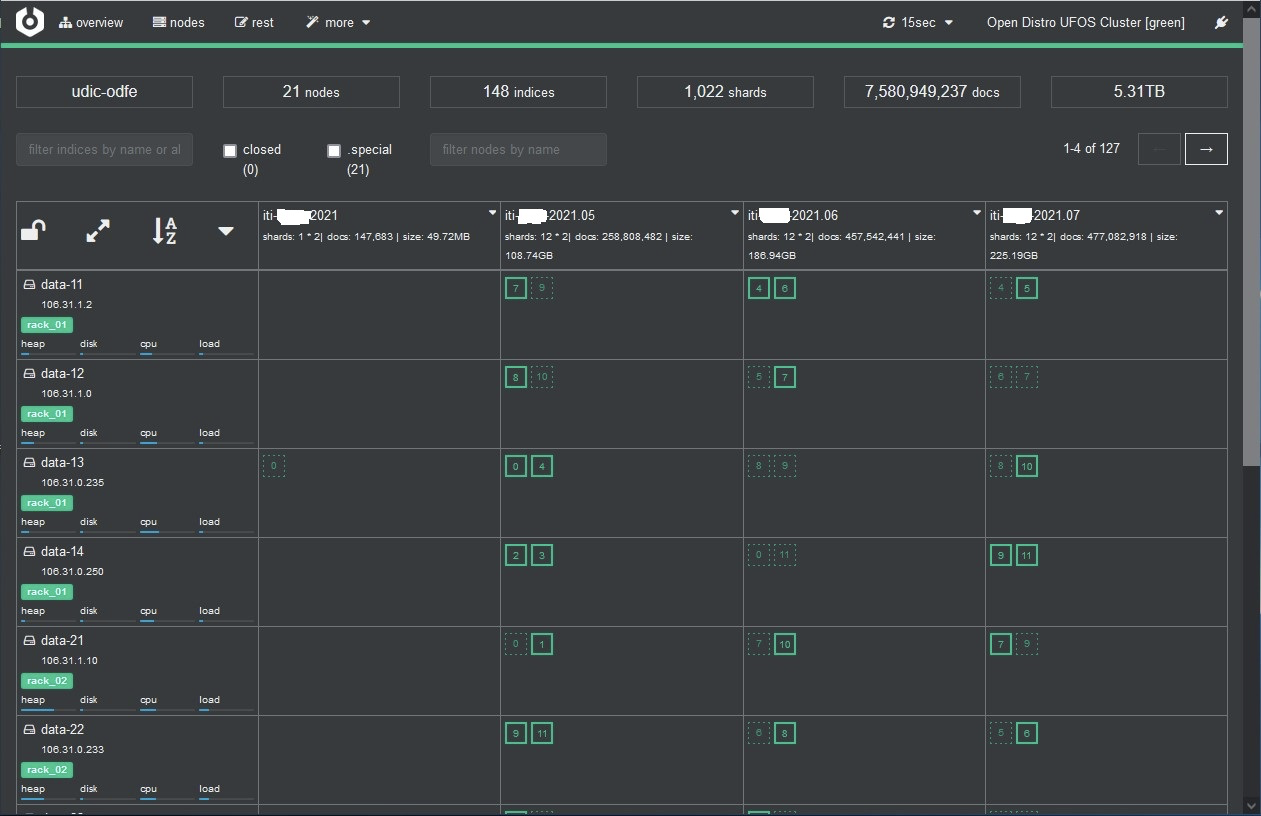
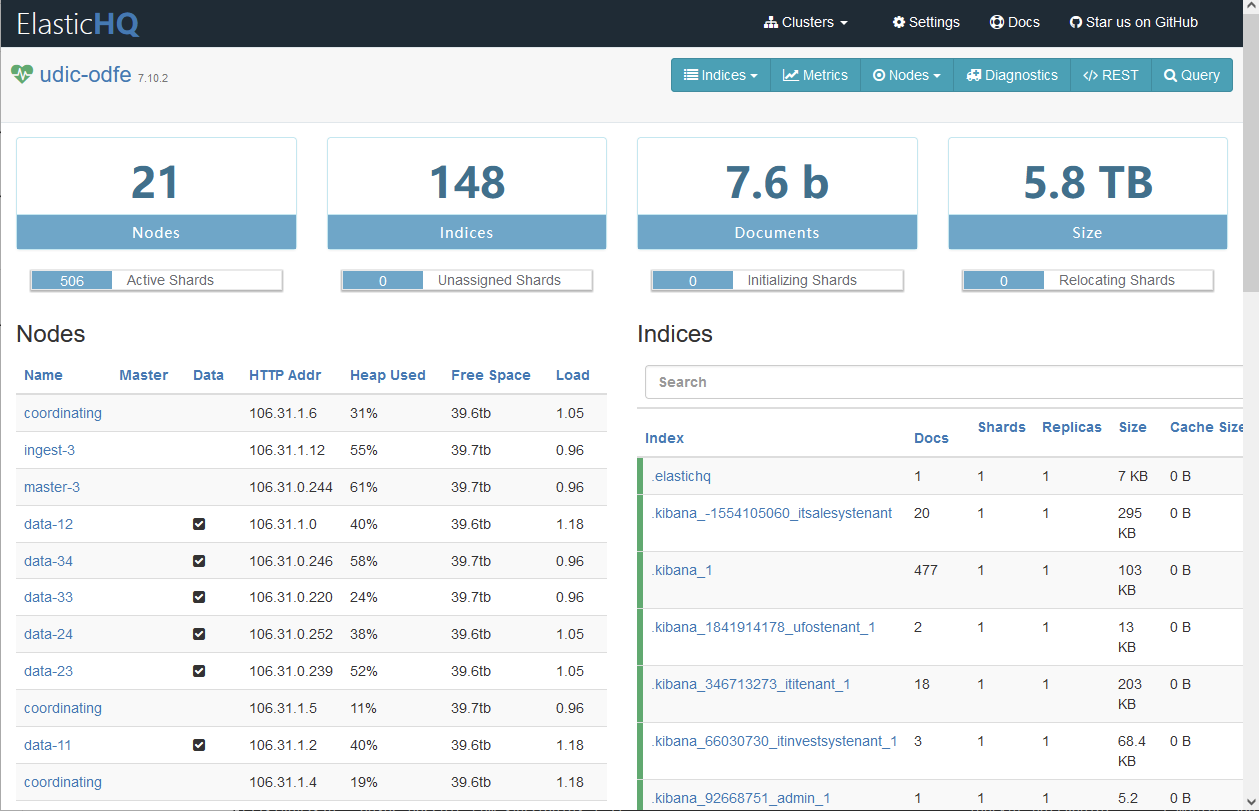
以下两个开源工具都是使用比较广的 ES 集群监控管理工具,比较直观,可以提供实时监控、全集群管理、搜索和查询服务,两者对监控数据展示略有差异,比如 Cerebro 使用图形化方式对于节点资源使用情况进行展示,同时也对索引的分片进行了展示。
Cerebro
ElasticHQ
因此,两者互有补充,可以结合使用。
4. OpenDistro 告警功能改进
OpenDistro 主要针对国外用户,告警中的有的功能并不能满足我们的需求,比如本地化时间,微信告警,邮件内容 HTML 格式支持等。这里我们就体会到使用开源软件带来的好处了,我们可以从 GitHub 获取源码,然后根据我们的需求对源码做相应地改进。
4.1 通用
PeriodStart 和 PeriodEnd 变量支持本地时区,缺省采用的是 UTC 时间格式,看上去不是很直观,我们对相应的模块 TriggerExecutionContext.kt 进行了修改,修改后显示时区以 UTC+800 北京时间为准
4.2 邮件
对于 OpenDistro 邮件告警,因为它现有的功能不能满足我们邮件服务器配置的需求,以及对邮件内容格式化的需要,因此我们对原有代码进行了改进,改进的功能包括:
邮件 SMTP 连接认证,原告警安全模块只有在邮件选择 TLS/HTTPS 加密协议的情况下,才从秘钥库(Key Store)中读取用户名和密码,而我们的邮件服务采用的是非加密协议,但是发送邮件的时候又需要使用用户名和密码进行认证,因此我们需要修改源文件 DestinationContextFactory.kt,注释掉对应的 emailAccount.method 判断语句。
邮件内容支持 HTML,原邮件发送模块 DestinationEmailClient.java 中采用的是 mailmsg.setText,这个我们修改为先检测邮件内容中是否有 HTML 标记,如果是调用 mailmsg.setContent 以 HTML 格式进行发送,否则采用文本格式发送。
4.3 微信
OpenDistro 告警方式中支持的即时通是 Slack 和 Chime,主要针对的是国外用户;对于国内主流的微信和钉钉,我们可以通过 OpenDistro 提供的 custom webhook 进行,该方式需要先建群,然后通过群机器人进行告警,但这种方式显得不够灵活。
企业微信可以通过 API 对特定的用户或组发送信息,这样在配置告警推送时更加方便。但该 API 需要两次调用,一次获取 Token,另一次再跟进获取的 Token 进行信息推送,而 webhook 只能进行一次调用。对此,有两种实现方式:
参考 Prometheus,Prometheus 原生支持微信,只需在配置文件中填写 api_corp_id 和 api_secret,Prometheus 内部根据配置信息,调用企业微信 API 完成信息推送。但是 OpenDistro 中的告警配置在 Kibana 界面中进行,如果采取这种方式,需要改动 Kibana,工作量比较大。
将 API 的两次调用放到另外一个服务中进行处理,比如我们的企业微信微服务,该微服务扮演一个企业微信代理或网关的角色,这样我们就可以 webhook 方式调用该微服务了。
我们采用了第二种方式并已成功对接。
以上改进的源码已上载到 Github,参考https://github.com/marshell0/alerting
5. 数据备份与恢复
对于日志数据,由于 ES 我们配置了副本,而且日志数据量大,因此对于日志数据我们并未进行数据的备份。但是对于集群中通过界面配置的配置信息,由于经常有更新,我们需要定时进行备份,比如安全,告警等配置数据,主要关系到以下几个索引:
.kibana*,该索引包括 Kibana 租户配置数据,包括各租户配置的搜索,index pattern、Dashboard。
.opendistro-alerting-config,该索引包含所有的告警配置相关信息,如 Monitor、Destinations。
.opendistro_security,包括安全配置信息,如角色,权限等。
对于这些重要数据的备份,可以通过以下几种方式进行数据备份:
对于索引,可以使用快照(snapshot)的方式对数据进行备份。
对于安全配置,可以使用 OpenDistro 内置的工具 securityadmin.sh 进行导出和导入,对于其他索引或全局信息配置如 ingress pipeline,可以通过相应的查询语句将数据以 json 格式存储。
上述操作的数据恢复可以通过相应的 API 调用进行。
6. 配置管理与安装
基于 Docker 的安装,OpenDistro 官方有基于 docker-compose 的集群例子,但该例中集群的配置是基于单台主机的简单配置,因为有的配置对于 Docker 集群来说只能配置在 Docker Engine 中,以下是基于 Docker Swarm 的配置与安装管理,ELK 核心配置仍旧采用 docker-compose.yml,只不过需要使用 docker stack deploy 运行。
以下配置的大部分配置文件和脚本已经上载到:https://github.com/marshell0/opendistro-deployment
6.1 操作系统配置
作为数据密集处理平台,ES 对操作系统配置有一些要求,在生产环境中,对于 Linux 系统 Open Distro 建议以下配置:
vm.max_map_count 至少设置为 262144,Open Distro Docker 镜像中缺省是该值,这个可以通过 sysctl -p 检测,sysctl.conf 其他配置项可以参考其他大数据中心的配置进行参数调整。
文件打开数 nofile 65536,禁止内存交换 memlock
Docker Swarm Mode 运行的 Docker 配置修改这些参数比较方便的地方是在 Docker Engine 的配置文件 daemon.json 中。
"default-ulimits": { "nofile": { "Name": "nofile", "Hard": 65536, "Soft": 65536 }, "memlock" : { "Name": "memlock", "Hard": -1, "Soft": -1 } }注意对于 Docker Swarm 这些配置在 docker-compose.yml 中将不会起任何作用。
6.2 Elasticsearch 配置
ES 节点的配置我们将按节点类型进行描述。
6.2.1 节点通用配置描述
所有的节点共有的配置选项如下:
ES 节点的 Docker image 为自建的镜像,在官方镜像的基础上添加了网络工具,经过修改的配置文件,如 elasticsearch.yml,config.yml,用于初始化配置的自定义脚本,扩展的 plugin,修改后的认证配置文件,改进后的告警模块编译后的 jar 包文件等。
ES 节点的集群名为 udic-odfe,表示所有的节点在一个集群中。
ES 节点都接入外部创建的 Swarm Overlay 网络 esnet。
为区分每个 ES 节点都定义了自己特有的端口。
另外,所有的节点共享 elasticsearch.yml,config.yml 配置文件(打包在镜像文件中),因此,个性化的参数配置都通过配置环境变量来覆盖。
6.2.2 Master 节点配置
配置如下所示,描述如下:
node.master 为 true,其他两个属性为 false 表明这是一个专职的 Master 节点。
discovery.seed_hosts,cluster.initial_master_nodes 配置 Master 节点列表。
bootstrap.memory_lock 配合 memlock 禁止内存交换。
ES_JAVA_OPTS 配置 ES 的虚拟内存为最大内存的一半。
config 项加载认证文件到指定目录,所有节点使用相同的指定目录,以便于配置文件中对认证的统一处理。
deploy 中设定了节点使用 CPU 和内存的保留值和最大值。
constrain 定义了该节点只能运行在 elk1 物理机 。
master-1: image: nexus.my-domain.com:9443/opendistro-for-elasticsearch:1.13.1 hostname: master-1 environment: - cluster.name=udic-odfe - node.name=master-1 - node.attr.rack_id=rack_01 - node.master=true - node.data=false - node.ingest=false - http.port=9202 - transport.port=9302 - discovery.seed_hosts=master-1:9302,master-2:9303,master-3:9304 - cluster.initial_master_nodes=master-1,master-2,master-3 - bootstrap.memory_lock=true # disables swapping - "ES_JAVA_OPTS=-Xms4g -Xmx4g -Des.enforce.bootstrap.checks=true" volumes: - /esdata/master-node/data:/usr/share/elasticsearch/data configs: - source: master-node.pem target: /usr/share/elasticsearch/config/node.pem - source: master-node-key.pem target: /usr/share/elasticsearch/config/node-key.pem networks: - esnet deploy: replicas: 1 resources: limits: cpus: '4' memory: 8G reservations: cpus: '1' memory: 2G placement: constraints: - node.labels.master-node==true - node.hostname==elk1.my-domain.comMaster 节点 2 和 3 配置类似。
6.2.3 Coodinating 节点配置
协调节点作为 ES 的入口,其配置如下:
node.master 等三个属性都设为 false 表明这是一个专职的协调节点。
因为是入口节点,所以它的配置端口为标准端口 9200/9300/9600。
涉及计算和内存使用比较大,因此 CPU 和内存的保留值和最大值都设置得相对比较大。
部署模式设为 global,也就是在各个配置了 node.labels.coordinating-node 标签的物理主机都会启动一个实例,自动实现负载均衡。
coordinating: image: nexus.my-domain.com:9443/opendistro-for-elasticsearch:1.13.1 hostname: coordinating environment: - cluster.name=udic-odfe - node.name=coordinating - node.master=false - node.data=false - node.ingest=false - http.port=9200 # custom port for HTTP - transport.port=9300 - discovery.seed_hosts=master-1:9302,master-2:9303,master-3:9304 - cluster.initial_master_nodes=master-1,master-2,master-3 - bootstrap.memory_lock=true - "ES_JAVA_OPTS=-Xms31g -Xmx31g -Des.enforce.bootstrap.checks=true -Des.transport.cname_in_publish_address=true" volumes: - /esdata/coordinating-node/data:/usr/share/elasticsearch/data configs: - source: coordinating-node.pem target: /usr/share/elasticsearch/config/node.pem - source: coordinating-node-key.pem target: /usr/share/elasticsearch/config/node-key.pem ports: - 9200:9200 - 9300:9300 - 9600:9600 # required for Performance Analyzer networks: - esnet deploy: mode: global resources: limits: cpus: '16' memory: 64G reservations: cpus: '4' memory: 4G placement: constraints: - node.labels.coordinating-node==true6.2.4 数据节点配置
数据节点配置项这里不完整贴出,重点配置项描述如下:
node.data 属性设为 true,其余为 false,表明这是一个专职的数据节点。
数据存储映射关系为:data-11 节点 -> /esdata/data-node-x1,data-12 节点 -> /esdata/data-node-x2,以此类推,保证同一台物理机上 ES 节点数据相互独立。
注意 node.attr.rack_id=rack_01,数据节点 data-1x(x=[1,2,3,4])的 rack_id 都相同,并且他们的 constrain 都限定了 node.hostname==elk1.my-domain.com,也就是绑定到 elk1 主机上,这样 Elasticsearch 知道这些节点处于同一个 rack,不会将主分片和副本分片分配到同一个物理主机,保证高可用。
data-11: hostname: data-11 environment: - cluster.name=udic-odfe - node.name=data-11 - node.attr.rack_id=rack_01 - node.master=false - node.data=true - node.ingest=false …… - "ES_JAVA_OPTS=-Xms31g -Xmx31g -Des.enforce.bootstrap.checks=true -Des.transport.cname_in_publish_address=true" volumes: - /esdata/data-node-x1/data:/usr/share/elasticsearch/data deploy: replicas: 1 resources: limits: cpus: '8' memory: 64G reservations: cpus: '2' memory: 4G placement: constraints: - node.labels.data-node==true - node.hostname==elk1.my-domain.com6.2.5 Ingest 节点配置
Ingest 节点配置与数据节点类似,只不过 node 属性有所不同,不复赘述。
6.2.6 Kibana 配置
Kibana 节点使用官方镜像,配置如下所示:
因为 Kibana 服务与 ES 节点同处一个 Docker Overlay 网络,因此 Kibana 可以使用内部服务名访问 ES 协调节点,coodinating 服务名对应一个虚 IP,可以实现负载均衡。
Kibana 连接 ES 节点需要配置用户名,密码和 CA 证书。
Kibana 配置了认证证书,连接到 Kibana 需通过 https。
kibana: image: nexus.my-domain.com:8445/amazon/opendistro-for-elasticsearch-kibana:1.13.1 hostname: kibana ports: - 5601:5601 environment: ELASTICSEARCH_URL: https://coordinating:9200 ELASTICSEARCH_HOSTS: https://coordinating:9200 ELASTICSEARCH_USERNAME: kibanaserver ELASTICSEARCH_PASSWORD: xxxxxx SERVER_SSL_ENABLED: "true" ELASTICSEARCH_SSL_CERTIFICATEAUTHORITIES: /usr/share/kibana/config/root-ca.pem SERVER_SSL_CERTIFICATE: /usr/share/kibana/config/node.pem SERVER_SSL_KEY: /usr/share/kibana/config/node-key.pem networks: - esnet deploy: mode: global6.2.7 Logstash 配置
因需要保留源 IP 地址,因此 Logstash Docker 运行在 host 网络,不采用 Docker service 方式部署,而采用本地 docker 直接运行方式,配置文件如下,需要在三台主机上分别运行,Logstash 会定期从 pipeline 目录扫描更新,因此配置了 pipeline 的本地映射,这样可以方便从本地映射目录更新 pipeline 脚本,不过需要注意在三台机器中同步。
Logstash 使用 Elastic 官方的 oss 版本,版本号需要与 Open Distro 内部的 ES 版本保持一致(7.12.0)。
docker run -d \ --restart=unless-stopped \ --name logstash \ --mount type=bind,source=/esdata/logstash/data,target=/usr/share/logstash/data \ --mount type=bind,source=/home/elasticsearch/ssl-key/root-ca.pem, target=/usr/share/logstash/config/root-ca.pem,readonly \ --mount type=bind,source=/home/elasticsearch/ssl-key/logstash.pem, target=/usr/share/logstash/config/logstash.pem,readonly \ --mount type=bind,source=/home/elasticsearch/ssl-key/logstash-key.pem, target=/usr/share/logstash/config/logstash-key.pem,readonly \ --mount type=bind,source=/home/elasticsearch/logstash/pipeline/, target=/usr/share/logstash/pipeline/ \ --mount type=bind,source=/home/elasticsearch/logstash/config/pipelines.yml, target=/usr/share/logstash/config/pipelines.yml \ --mount type=bind,source=/home/elasticsearch/logstash/config/logstash.yml, target=/usr/share/logstash/config/logstash.yml \ --network host \ -e 'LS_HEAP_SIZE=8G' \ nexus.my-domain.com:9443/logstash/logstash-oss:7.12.16.2.7.1 pipelines.yml
该文档配置所有要加载的 Pipeline 配置文件:
- pipeline.id: ufos-pipeline path.config: "/usr/share/logstash/pipeline/ufos.conf" queue.max_bytes: 4gb pipeline.workers: 6- pipeline.id: hsfw-pipeline path.config: "/usr/share/logstash/pipeline/hsfw.conf" queue.max_bytes: 4gb pipeline.workers: 66.2.7.2 ufos.conf
该文件存放在本地~/logstash/pipeline 目录,由 logstash docker 映射到 docker 的/usr/share/logstash/pipeline/目录,logstash 会定时扫描该目录,并加载更新,因此可以在不重启 logstash docker 的情况下修改 Pipeline 配置文件。
配置中 proxy_protocol 是配合 nginx 对 TCP 传输源地址保持的配置。
ES 连接配置了用户名,密码和 CA 证书。
ilm_enable 必须设为 false,它是 xpack 选型,我们这里使用的是 OpenDistro 安全配置。
input { tcp { port => 5100 type => ufoslog codec => json proxy_protocol => true }}……output { elasticsearch { hosts => ["https://elk.my-domain.com:9200"] index => "ufos-%{+YYYY.MM}" ssl => true ssl_certificate_verification => true cacert => '/usr/share/logstash/config/root-ca.pem' user => eslog password => xxxxxxx ilm_enabled => false }6.3 Elasticsearch Snapshot 配置
要对 ES 进行快照,需要进行以下配置:
在 ES 的配置文件 elasticsearch.yml 中登记快照仓库配置,例如:path.repo: ["/mnt/snapshots"]。这个配置项我们已经放进了自建的 Docker images 中。快照仓库其实就是一个存储路径,注意该存储路径必须是以共享性质的路径,比如 NFS,HDFS,Amazon S3 等,不能配置为本地路径,因此在 docker-compose.yml 中,我们配置了 NFS 共享目录用于 snapshot 绑定。
创建快照的仓库。
volumes: snapshots: driver: local driver_opts: type: nfs o: "addr=eagle.my-domain.com,nolock,soft,rw" device: ":/var/nfsshare/elasticsearch/snapshots"创建仓库后,就可以使用相关的 REST API 进行 ES 的快照和从快照中恢复。
PUT /_snapshot/config_repository{ "type": "fs", "settings": {"location": "/mnt/snapshot", "compress": true}}6.4 Elasticsearch 扩展配置
6.4.1 中文分词插件
Elasticsearch 模糊搜索快是因为底层的开源库 Lucene 使用了倒排索引,倒排索引需要对文档进行分词,英文语句分词非常简单,语句本身就有空格分词,但是中文语句因为汉字都是连在一起的,所以 Elasticsearch 内置的分词器对于中文语句分词只能分成一个个的汉字,显然这样我们不能查询出我们想要的结果,因此我们需要安装专门的中文分词器来对语句进行解析。
Elasticsearch 中最常用的分词器是 IK 分词器,其地址在 https://github.com/medcl/elasticsearch-analysis-ik,可以直接下载软件包,并解压到 Elasticsearch 的 plugins 目录中即可。我们在 Elasticsearch 镜像的脚本 Dockerfile 中已经将该软件包直接打入了 Elasticsearch 的 plugins 目录。
在索引模板中,就可以配置索引使用 ik 进行分词了,配置 analyzer,支持两种模式:
ik_smart:最粗粒度的拆分,一般这种模式就够用了。
ik_max_word:会将文本做最细粒度的拆分,穷尽各种组合。
6.4.2 性能分析插件(Performance Analyzer)
OpenDistro 官方提供一个插件生成性能分析数据并提供相应 REST API 进行查询,该插件缺省已经安装到官方提供的容器镜像中,我们只需要打开相应开关和设置相关配置,就可以获取这些性能数据了。
配置和启用性能分析功能的步骤如下:
性能分析器缺省使用/dev/shm 做数据缓存,在数据处理量大的集群中,可能会生成高达 1G 的度量数据,而容器缺省的/dev/shm 容量是 64M,容器修改该参数比较方便的地方是在 Docker Engine 的配置 daemon.json 中设置:
"default-shm-size": "1G"当然也可以选择进行动态绑定,但是相对配置起来比较麻烦。
修改 plugins/opendistro_performance_analyzer/pa_config/目录下的配置文件 performance-analyzer.properties
为配置方便,我们把该配置文件打包到基于官方的自定义容器镜像中。
# WebService bind host; default to all interfaceswebservice-bind-host = 0.0.0.0#Setup the correct path for certificatescertificate-file-path = /usr/share/elasticsearch/config/node.pemprivate-key-file-path = /usr/share/elasticsearch/config/node-key.pem开启 Performance Analyzer 插件。
curl -XPOST https://elk.my-domain.com:9200/_opendistro/_performanceanalyzer/rca/cluster/config -u admin: passwd --insecure -H 'Content-Type: application/json' -d '{"enabled": true}'开启 Root Cause Analyzer (RCA) 框架。
6.4.2.1 客户端工具
PerfTop 是展示性能分析数据的缺省工具,可以根据官方提供的地址进行下载,使用方式如下:
./perf-top-linux --dashboard NodeAnalysis --endpoint https://elk.my-domain.com:9600curl -XPOST https://elk.my-domain.com:9200/_opendistro/_performanceanalyzer/cluster/config -u admin:passwd --insecure -H 'Content-Type: application/json' -d '{"enabled": true}'Dashboard 可以参考官方的文档进行创建,简单的方式是使用官方提供的四种标准 Dashboard:
ClusterOverview
ClusterNetworkMemoryAnalysis
ClusterThreadAnalysis
NodeAnalysis
截屏如下:
数据图形展示并不是很好,通过配置 stats 度量数据拉取到 Prometheus,然后通过 Grafana 展示,不管是数据还是图形细节都相对更好。
6.5 自定义镜像及相关配置文件
为了简化启动配置文件 docker-compose.yml,我们将一些公共的配置文件打包到了基础镜像中(该文件还可以通过 yml 的 alias 进行重复配置的简化),各脚本和配置文件列表如下:
6.5.1 Dockerfile
在定制镜像 Dockerfile 中,包含的主要指令有:
镜像本地化配置
使用定制的配置文件,keystore 覆盖缺省的配置文件
拷贝公共的认证文件,如 admin 和 root-ca
使用定制的脚本在启动的时候对容器进行初始化
打包扩展的插件
使用修改后的告警的插件覆盖原有的插件
6.5.2 elasticsearch.yml
该配置文件为 Elasticsearch 节点的配置信息,配置信息可以通过环境变量进行覆盖,比如 docker-compose.yml 中的 cluster.name,node.master 等。
下面描述一下里边几段重要的配置信息:
Shard Allocation Awareness,上面讲的利用 rack_id 进行高可用
安全认证配置文件,因此各个节点的安全认证配置文件的路径需要保持一致
集群中节点的 DN 配置,必须对集群中所有节点的 DN(对应认证文件中的 DN)进行配置,不然节点之间访问会报安全错误;定义管理员 DN,也就是拥有 admin_dn 的具有管理员权限
opendistro_security.nodes_dn: - "CN=*.xxxxx.com,OU=ITDEPT,O=XXXXXXX,L=SHENZHEN,ST=GD,C=CN" - "CN=master-*,OU=ITDEPT,O=XXXXXX,L=SHENZHEN,ST=GD,C=CN"opendistro_security.authcz.admin_dn: - "CN=admin,OU=ITDEPT,O=XXXXXX,L=SHENZHEN,ST=GD,C=CN"ENV TZ=Asia/ShanghaiENV LANG=zh_CN.UTF-8 \ LC_ALL=zh_CN.UTF-8 \ LC_CTYPE=zh_CN.UTF-8 \ LC_MESSAGES=zh_CN.UTF-8COPY --chown=elasticsearch:elasticsearch ./config/config.yml ./config/internal_users.yml ./config/roles_mapping.yml /usr/share/elasticsearch/plugins/opendistro_security/securityconfig/COPY --chown=elasticsearch:elasticsearch ./config/elasticsearch.yml ./config/elasticsearch.keystore ./config/log4j2.properties ./ssl-key/root-ca.pem ./ssl-key/admin.pem ./ssl-key/admin-key.pem /usr/share/elasticsearch/config/COPY --chown=elasticsearch:elasticsearch ./config/default.policy /opt/jdk/lib/security/default.policyCOPY --chown=elasticsearch ./config/coordinating.sh ./config/docker-entrypoint.sh /usr/local/bin/COPY --chown=elasticsearch ./config/performance-analyzer.properties /usr/share/elasticsearch/plugins/opendistro-performance-analyzer/pa_config/配置审计 auditlog 索引格式,缺省是按日生成,这样创建的索引过多。
配置快照的存储路径,必须配置该选项才能进行索引的快照
opendistro_security.audit.config.index: "'security-auditlog-'YYYY"path.repo: ["/mnt/snapshots"] ldap: description: "Authenticate via LDAP or Active Directory" http_enabled: true transport_enabled: true order: 1 http_authenticator: type: basic challenge: true authentication_backend: type: ldap config: enable_ssl: false enable_start_tls: false enable_ssl_client_auth: false verify_hostnames: false hosts: - xxx.0.0.1:xxxx bind_dn: 'CN=xxx,CN=xxxx,DC=xxxx,DC=com' password: 'xxxxxxxxxxx' userbase: 'DC=xxxxx,DC=com' usersearch: '(sAMAccountName={0})' username_attribute: uid6.5.3 config.yml
该配置文件主要是配置认证与授权信息。认证中我们使用了两种认证方式,一种是基础的内部用户名口令方式(初始从 internal_user.yml 装载,该文件里配置的 hash 配置项可以通过 plugins/opendistro_security/tools/hash.sh 产生);另外认证方式是通过公司办公网 AD 域进行认证,因此配置了 ldap 选项。
其他详细配置信息请参考项目 Repository 中的配置文件以及脚本。
6.6 第三方软件配置
参考项目 Repository 脚本,略。
7. 告警配置与管理
对于国内用户只有两种选择,邮件或 Webhook,由于大多数通信软件都支持 Webhook,因此可以通过 Webhook 支持微信,钉钉等国内流行通信软件平台告警。
7.1 邮件告警
OpenDistro 邮件告警配置中,与邮件服务器通信的方式支持三种,TLS,SSL,明文,如果选择前面两种加密通信方式,则必须在节点上添加邮件用户名与密码到 keystore。
./bin/elasticsearch-keystore add opendistro.alerting.destination.email.<sender_name>.username./bin/elasticsearch-keystore add opendistro.alerting.destination.email.<sender_name>.password由于我们的邮件系统采用明文通信方式,却需要使用用户名与密码认证才能使用邮件发送,因此我们对相应的源码进行了改动以支持明文通信方式下的用户名与密码认证,改动后将编译的 jar 包替换源系统中的相应模块。
7.2 微信告警
微信告警官方提供两种方式:
企业微信群机器人告警模式,该模式直接支持 Webhook。
企业微信 API 调用模式,先使用企业微信 corpid 和生成的 corpsecret 通过 API 调用获取 Token,尔后使用该 Token 发送告警信息,Token 具有 expire 时间,超过该时间过后需要重新获取 Token,这种方式比较灵活,不需要先建群,只要通知到企业微信联系人即可。
第一种方式,在建立的企业微信群中打开机器人页面,生成机器人,将生成的 URL 拷贝用作 Kibana 中的 Webhook URL,如:
https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=1fe0992f-xxxx-xxxx告警中的消息须采用 json 格式,并符合微信官方的接口标准,参考如下:
{ "msgtype": "markdown", "markdown": { "content": "Monitor **{{ctx.monitor.name}}** just entered alert status. \n >Trigger: {{ctx.trigger.name}} >Severity: {{ctx.trigger.severity}} >Period start: {{ctx.periodStart}} >Period end: {{ctx.periodEnd}}", "mentioned_list": ["username1 ","username2"] }}第二种方式不直接支持 Webhook,如 4.3 所述,我们采用了内部微服务网关方式实现,这里不做阐述。
7.3 告警详细内容
采用 Kibana 界面就可以配置告警,它可以使用图形化的方式生产查询语句并根据查询的结果进行报警;但是如果在告警内容中携带触发告警的详细条目,则需要:
手写查询语句,在 Define extraction query 里,需要设置 size 为返回的详细条目数量,该 size 缺省值为 0,也就是不返回详细条目,只返回统计数目。
可以通过 ctx.results.0.hits.hits 获取返回的详细信息内容并生成告警信息,这些详细信息一般只用在邮件告警中。
{{#ctx.results.0.hits.hits}} <tr> <td style='text-align:center;'> {{_source.service_name}} </td> <td style='text-align:center;'> {{_source.host}} </td> <td style='text-align:center;'> {{_source.message}} </td> </tr> {{/ctx.results.0.hits.hits}}



