
背景
自从谷歌的 BERT 预训练模型横空出世,预训练 - 下游任务微调的方式便成了自然语言处理任务的灵丹妙药。然而,复杂度高、显存消耗大等问题一直困扰着 BERT 等预训练模型的优化;由于 BERT 中 Transformer(多层自注意力)关于输入文本长度 L 有的 O () 的时间空间复杂度,长文本消耗显存陡然增加。想象一下,一位工程师兴致勃勃地将数据在设计好的下游任务上微调,满怀期待地盼望着结果的提升,却因为其中的一些长文本使得显存溢出或超过位置嵌入(position embedding)最大长度,该是一件多么沮丧的事情。
解决这个问题最直接的方法是滑动窗口(sliding window)对每个 512(通常 BERT 位置嵌入的最大长度)字符的窗口分别预测,最终合并不同窗口的结果的方式随着具体下游任务的不同略有差异,例如阅读理解问答可以输出各段中总评分最高的小段(span)作为答案。然而,如果问题需要长程注意力,也就是两个关键的句子分布在段落中相距较远位置的时候,这种方法的效果就会大打折扣,下图就是一个例子。

解决这个问题的另一种思路是优化 Transformer 结构,这一条思路的工作有很多,例如 Longformer、BlockBert、最近的 BigBird 等…… 但是这些工作通常只是将文本长度从 512 扩展几倍(基于现有的硬件条件),让 BERT 一次 “看到” 更多的文本;然而,人类并不需要如此强的瞬时阅读能力 —— 实际上人类同时在工作记忆里存储的元素通常只有 5-7 个 —— 也能阅读并理解长文本,那么人类是如何做到的呢?
认知中的工作记忆和调度
“工作记忆的核心是一个中央处理机制,它协调来自于多种来源的信息”, 并且 “它发挥一个有限容量的注意力系统的作用,这个系统能选择和操作控制过程和策略”, 这是工作记忆的提出者 Baddeley 在他 1992 年《Science》著作中的论断。事实上,人脑正是通过回忆和注意力,协调长期记忆和短期记忆(工作记忆)的使用策略来完成对长文本的理解。下图是分层注意力机制的图解,工作记忆从当前的感知记忆空间或者长期记忆中抽取关键信息进行深层理解,然而这些信息如果没有被不断重演(rehearsal)就会在大约 5-15s 后逐渐忘掉,剩余的有用的信息来进行继续的推理。
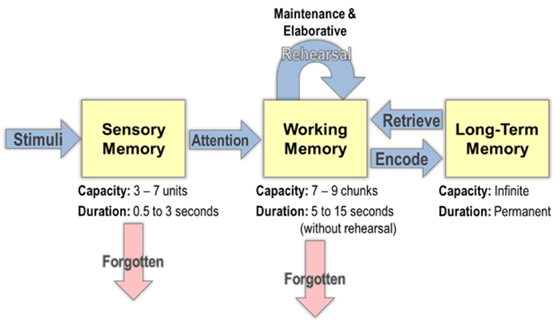
CogLTX 的工作流程
受到人的认知过程启发,我们用同样的方法来处理长文本。如果将 BERT 的 512 输入字符限制比作人的工作记忆,那么既然人思考问题时能够找到关键的少量信息,并在工作记忆中推理出结果,BERT 的 512 也应该远远足够,关键是对于特定的问题,我们要最终用的真正关键的那部分信息。
因此,CogLTX 遵循一种特别简单直观的范式,即 抽取关键的句子 => 通过 BERT 得到答案 这样的两步流程。常见的几种任务都可以用这种范式来解决。比如下图列举了语段抽取、序列级别任务、字词级别任务的处理方法。
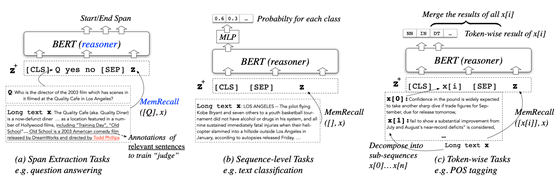
在这里,我们将完成任务要训练的 BERT 称为推理机(reasoner),解决问题的关键语段记为 z,CogLTX 通过一个被称为 “MemRecall” 的过程,如同人类调度工作记忆一样的方式来抽取关键的语段 z。
MemRecall 关键信息抽取
对于关键信息的认识本身也是智能的重要部分,这并非易事。最直观的想法是通过信息检索的办法(例如 BM25)来抽取关键句,但是仔细一想就会发现这其实是不可行的,因为下游任务的不确定性,无法建模成信息检索的形式。例如,文本分类任务如果用 BM25 去检索,则无法定义查询(query)是什么。因此抽取的模型也要与任务息息相关。
其次就是直接检索的方式过于粗糙,同时对于无法处理多跳推理的信息。而人在工作记忆中的思考是一个时序的过程,会不断忘记被错误检索的信息而将空间留给新信息。因此,我们模仿这样的过程设计了 MemRecall,其核心是一个对于每个字词进行相关度打分的评分机(judge)模型,也用 BERT 实现。MemRecall 的过程如下图所示。
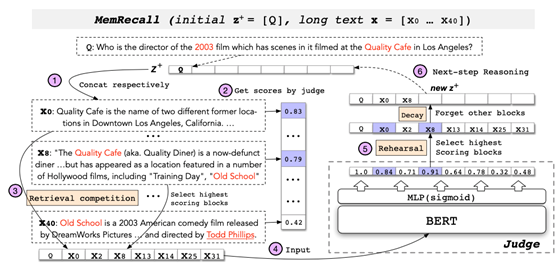
我们首先将长文本切块,用现有的关键信息去连接每一块,通过评分机获取块平均相似度得分,其中最高分的块被放入“工作记忆”——但是这是暂时的,正如人脑的工作记忆一样,我们如果只对重要的信息进行重演,其他信息就会很快忘掉——在 MemRecall 中我们将这些最高分的块一起通过评分机,信息充分交换后再进行评分,并且“忘掉”那些得分不高的块。新的关键信息将用来重复这一过程,完成多步推理。
训练
在模型训练时,我们考虑两种情况:第一种是阅读理解问答这样的任务,由于信息句可以从答案所在句推断出来,因此是监督学习。此时评分机和推理机的训练(finetuning)都比较简单,只需将真正的关键句和一些负样本信息句组合,然后像正常 BERT 那样训练即可;第二种是文本分类这种,数据集中往往不会提供关键句的标注,这就需要我们自己推断。关键句的一个特性是,如果缺少关键句将不能推断到正确答案,因此我们先用词向量等方法初始化关键句标签后,再训练中调整关键句标签,如果某个句子剔出后损失函数骤然增加那么就必然是关键句,如果可有可无则不是,根据这个方法在调整关键句标签后可重新进行下一轮训练,具体算法如下:

从隐变量的角度,如果认为关键句是隐变量,那么 CogLTX 的算法则可以看成是由于隐变量 z 取值空间离散且较大,选择的一种点估计的近似。
实验
文章在 NewsQA、HotpotQA 问答数据集,20NewsGroup 文本分类和 Alibaba 淘外文本多标签分类等几个任务上进行试验,结果均超过或类似于目前最好的模型效果,具体数据在论文中列举。
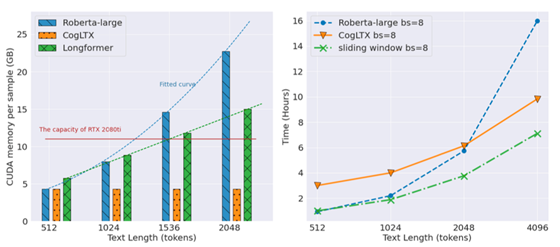
同时,CogLTX 牺牲了部分推理的时间,换取了与文本长度无关的训练空间开销。下图展示了 BERT-large 在 batch size 为 1 的时候的时空开销对比,可以看出 CogLTX(橙色)消耗的空间是固定的。
小结
对于 BERT 处理长文本时遇到的困境,通常的做法都会考虑轻量化 Transformer 的思路,然而如果能从人类处理信息的方式得到启发,另辟蹊径从下游任务微调的流程上考虑,更直接地解决这个问题。




