
演讲嘉宾 | 张磊 字节跳动 /Web Infra 前端负责人
整理|Penny
编辑|Kitty
近年来,XR 技术兴起以及人工智能技术的高速发展,为大前端领域注入了新的活力。这些技术不仅为用户带来了更加沉浸和智能的体验,也为前端、客户端的开发者们开辟了全新的视野和可能性。欢迎关注即将于 10 月 18 -19 日召开的 QCon 上海站,我们将在【新技术浪潮下的大前端机遇与挑战】专场为大家奉献 XR 、 AI 与大前端技术相结合,创造出的令人激动的新应用和解决方案落地实践。目前购票可享 9 折优惠,感兴趣的同学可访问 QCon 官网购票页面了解详情。
本文整理自字节跳动 Web Infra 前端负责人张磊在 QCon 2024 北京 的演讲分享“Rust 如何引领前端基建新潮流以及字节跳动的应用”。
大家好,我是张磊,目前担任字节跳动 Web Infa 团队的前端负责人。今天,我非常高兴能与大家分享 Rust 语言在前端领域的发展趋势以及字节跳动在这方面的实践经验。
本次分享将分为三个主要部分:
Rust 在前端领域的发展:介绍 Rust 在前端行业的发展情况,重点放在工程化应用上。
字节跳动的实践案例:分享字节跳动在 Rust 前端开发中的一些具体实践。
Rspack 项目中的架构设计:深入探讨我们在 Rspack 项目中采用的中等复杂度系统的架构设计方法。
我们团队负责维护和开发多个开源项目,包括 Rspack、Rsbuild 和 Modern.js 等,这些项目为公司内部超过 5000 名前端研发人员提供了工程化和微前端解决方案的基础设施。目前,我们团队还在积极探索 AI 领域的相关工作。我们团队也在积极招募架构师等相关岗位的人才。如果大家对此感兴趣,欢迎通过 GitHub 关注我们的项目:https://github.com/web-infra-dev。今天的分享内容可能涉及到一些我们团队的利益相关部分,但我会尽量保持中立和客观,与大家分享我对这个行业的理解和见解。
Rust 在前端行业的发展
让我们从 Rust 的发展开始谈起。在我们开源 Rspack 项目之初,我们撰写了一篇文章,阐述了我们为什么要启动这样一个项目。文章中有一段提到:在生产环境中,一些应用程序的构建时间经常需要 20 - 30 分钟。这段话发布后,在业界引起了不小的反响。有些人质疑,一个项目怎么可能需要构建 30 分钟?我们究竟在做什么项目?怎么可能会有 50000 个模块?使用 Rust 来处理这样的问题,是否有些小题大做?面对这些反馈,我们也曾陷入自我怀疑,我们的做法真的这么糟糕吗?怎么会有这样的问题?
Rspack 开源之后,许多开源社区的团队联系了我们。我们发现,面临这种问题的并不只有我们。例如,Kibana 项目,这是一个在 GitHub 上开源的项目。当项目作者联系我们时,他们告诉我们整个项目的构建时间接近 60 分钟。该项目包含 4,999,000 行 TypeScript 代码,有 5 万个 TypeScript 文件,整个项目已经迭代超过 11 年。另一个例子是 Discord 项目,这个项目也非常复杂。在接入 Rspack 之前,它在 CI 环境中的构建时间需要 11 分钟。接入 Rspack 之后,构建时间缩短到了 3 分钟。还有一个案例来自我们社群中的一位海外成员。他在描述项目中说:big legacy frontend monolith project.(大型遗留前端单体项目)。他说,在接入 Rspack 之前,该项目在 CI 环境中的构建需要将近 1 小时,而在接入 Rspack 之后,构建时间缩短到了 9 分钟。
我们总结了一下,在前端环境中,确实存在许多一次性应用。我们可能开发一段时间后就上线,然后就停止了,不再需要迭代和维护。但前端也会存在像 Super APP 这样的场景,比如我们在字节跳动内部使用的飞书文档,以及刚才提到的 Kibana 等项目。这些项目的生命周期非常长,需要长时间的迭代。随着迭代的进行,项目也会不断膨胀,可能会因为各种 A/B 测试等原因,代码量越来越多。
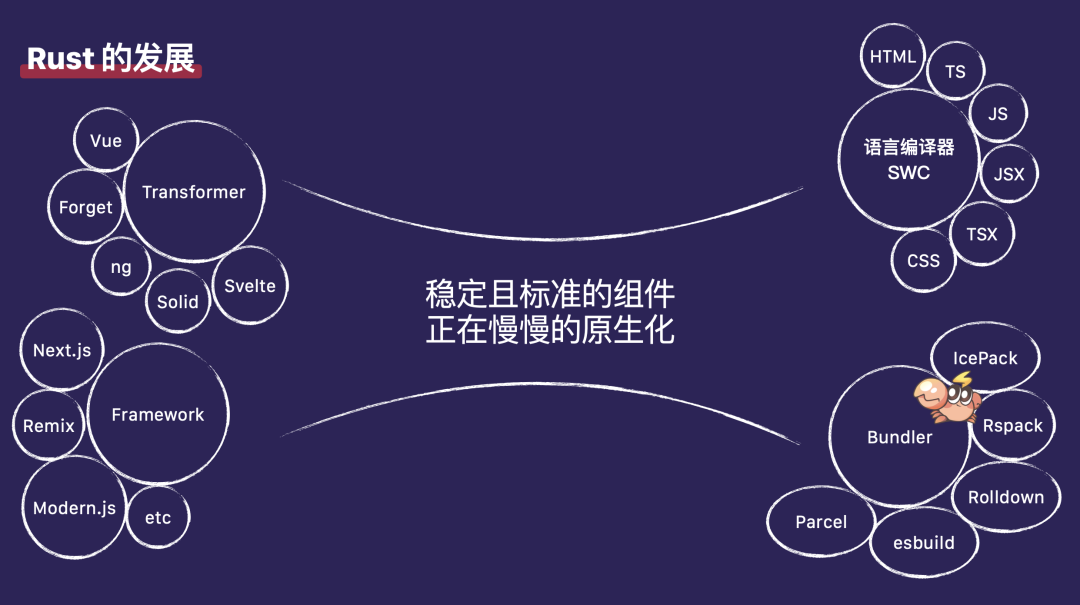
作为公司的中台部门,我们经常接到业务团队的请求,希望我们帮助他们优化构建体验,特别是解决构建时间过长的问题。同时,我们也在深入思考前端工程化的未来发展方向。我们观察到自 2012 年以来,前端的基础语法和工具生态都在迅速发展。到了 2020 年,整个前端基础设施变得越来越稳定。例如,我们依赖的 JavaScript 语法提案逐渐减少,这种稳定性也带来了前端工具的变化,稳定且标准化的组件开始逐渐原生化。
现在,我们可以看到,在基础语言编译器方面,如下图右侧上方所示,SWC 已经完全支持 HTML、TypeScript 和 JavaScript 等代码的编译。在图的最下方是 Bundler 部分,Rspack、Rolldown 和 esbuild 等项目已经完成了 Bundler 部分的原生化。有些部分的原生化仍在推进中,比如左上角的 Transformer 部分。这部分 Transformer 主要指的是 UI 框架的 Transformer ,例如 Vue、Solid 和 Svelte 等,它们依赖的编译器目前主要是用 JavaScript 编写的。当然,许多团队和社区成员正在探索原生化的道路,这是一个持续发展的过程。图中左下角我们常用的开发框架,如 Next.js,仍然处于 JavaScript 生态系统中。
分享一个我们团队的观点:JavaScript 和 Rust 在长期内将会共存。你可能会通过各种插件 API 或其他 API 将它们转化为性能更优的版本。在一些控制力强的场景,比如小程序或跨端框架场景中,会出现很多完全使用 Rust 的工具的团队。
站在今天这个时间点,回顾我们开始 Rspack 项目之前,我们首先需要思考一个问题:为什么选择 Rust?在决定选择 Rust 之前,我们需要先了解 JavaScript 这门语言存在哪些问题。
我们主要在 Node.js 环境中使用前端工具。Node.js 的第一个主要问题是多线程支持。尽管 Node.js 提供了工作线程 API,但直接在工作线程之间共享内存并不容易。虽然我们可以使用 SharedArrayBuffer 来实现共享内存,但这需要手动处理同步和并发等问题。第二个问题是语言性能。JavaScript 或者我们常用的 V8 虚拟机在性能优化方面存在一定的不可控性。性能优化往往难以预测和控制。第三点是垃圾回收(GC)。我们曾经遇到过一个有趣的案例:一位开发者反馈他的构建工具性能非常不稳定,HMR 的速度时快时慢。我们对其进行了性能分析,发现有时 HMR 的耗时会达到 2 秒,其中大约有 800 毫秒是花在了垃圾回收上。作为 JavaScript 开发者,我们无法控制 GC 的触发时机,这在整个构建过程中是一个相当棘手的问题。
在认识到 JavaScript 存在一些问题后,我们面临选择:Golang、C++、Rust,为什么我们最终选择了 Rust,或者说为什么社区倾向于选择 Rust?我认为主要有四个原因。

第一,工具链完善。Rust 的开发主要依赖于两个工具:Cargo 和 Rust Analyzer。Cargo 本身内置了 37 个命令,涵盖了开发过程中所需的大部分功能。学习 Cargo 一个工具,基本上就可以解决所有问题。而 Rust Analyzer 工具,特别是在使用 VS Code 插件开发时,为我们提供了代码提示和诊断功能。
第二,生态丰富。我昨天在 Cargo 搜索与 JavaScript 相关的包,发现有 1856 个。而且,对于我们做 Bundler 这类基础设施所依赖的包,如 Parser 等,社区已经建立了非常成熟的生态。例如,esbuild 虽然内置了 Parser,但它是与 esbuild 工程紧密绑定的,难以单独使用。而我们现在依赖的 Biome 和 Lightning CSS 等,整个生态已经相当完善。
第三,多线程支持。Rust 的官方文档中有专门章节讨论 “fearless concurrency” 无谓并发),意味着开发者不需要担心并发问题,Rust 已经内置了解决方案,如 send 和 sync 特性,编译器会自动进行检查。
第四,对 WebAssembly(Wasm)友好。虽然许多静态语言都对 Wasm 友好,但 Rust 可能更为突出。Wasm 友好的价值在于,我们开发的工具可以方便地被用户用于自定义需求或进行代码反馈。
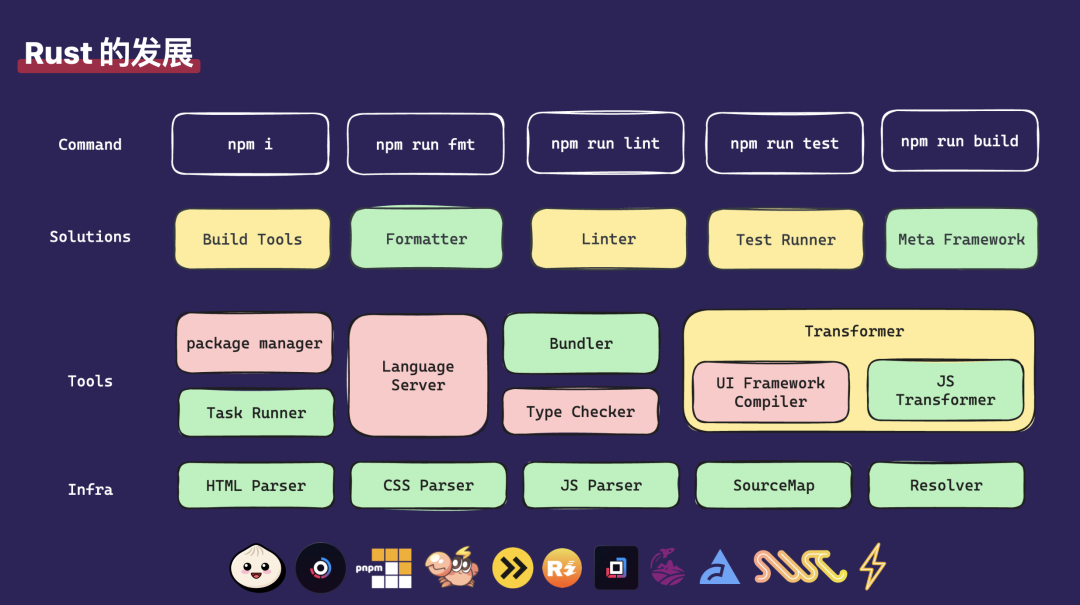
Rust 语言发展至今,已经达到了一个相当不错的阶段。在前端社区中,一些非常流行的由 Rust 等原生语言编写的工具包括 Bun、Turborepo、pnpm、Rspack、Rolldown、esbuild、Turbopack、Biome 和 Lightning CSS 等。从我们的观察来看,在前端的日常开发中,我们主要使用的是五个命令。
第一部分:我们从 npm install 命令开始讲起。 最初学习时,我们知道 install 命令用于安装依赖。但随着 Monorepo 类工具的发展,npm install 的过程已经不仅仅局限于安装依赖,它还包含了 task runner 等基础功能。在这个方向上,以 Bun 为例,它已经将 package manager 和 Task Runner 的功能完全内置。而 Turborepo 项目,它主要提供 Task Runner 的功能。目前,我们接触到的大多数项目都是以 Task Runner 功能为主。至于 package manager 的实现,对应的是像 pnpm 这样的项目。但值得注意的是,pnpm 的 Rust 版本目前迭代并不活跃。
第二部分:npm run fmt。 过去我们主要使用 Prettier 这样的工具进行代码格式化。去年,社区发起了一个挑战,宣称完成 Prettier 100% 的测试用例可以获得 2 万美金。许多社区内的开源团队积极参与了这个项目。最终,Biome 团队赢得了挑战。目前,我在做工程时,也主要使用像 Biome 这样的工具来进行代码格式化。
第三部分:npm run lint。Lint 功能主要分为两部分,一部分是代码检查,这部分已经非常成熟。社区内目前有两个主流的 lint 工具,一个是 OXCLint,另一个是 Biome 的 lint。但它们被标记为黄色,主要是因为它们依赖的 Type Checker 功能,目前社区内还没有任何一个项目能够完全实现。过去,SWC 的作者曾探索过 Rust 版本的 Type Checker,名为 STC,但该项目目前已经停滞。我认为,这个工程的整体工作量非常大,实现起来不太现实。
第四部分:npm run test。 测试方向也分为两部分内容。一部分是基本的测试驱动器,即扫描到 test 文件并运行它们。Rust 在这一方面的实践或工具相对较少,但我们可以通过依赖底层的 Parser 来完成这一部分。例如,swcjs 的插件,只需挂载在 JavaScript 上就可以使用。
最后一个部分:npm run build。 这是我们开发中主要接触的,也是我们这些开发者们主要忙碌的事情。在 Meta framework 上,它主要依赖两部分。首先是 Bundler 领域,这是目前 Rust 化内竞争非常激烈的一个领域,我们目前也在进行 Rspack 这样的项目。其次是对 JS 语法进行 Transformer。Transformer 分为两部分:一是 UI 部分的 Transformer,这部分目前还是探索项目,还没有完全 Rust 化的解决方案。二是语法本身的转换,如 ES6 转 ES5,或者高级语法转低级语法,这方面 SWC 已经相当完善,OXC 也在进行这方面的探索,但目前还没有完成。
字节跳动的实践
目前,Rust 在前端工程化领域的发展现状是令人鼓舞的。字节跳动在这方面的进展也大致相同。接下来,我想分享我们在采用 Rust 过程中的心路历程。字节跳动的实践可以分为三个阶段:esbuild 阶段、Rspack 阶段和全面采用 Rust(All in Rust)阶段。让我们从 esbuild 阶段开始说起。
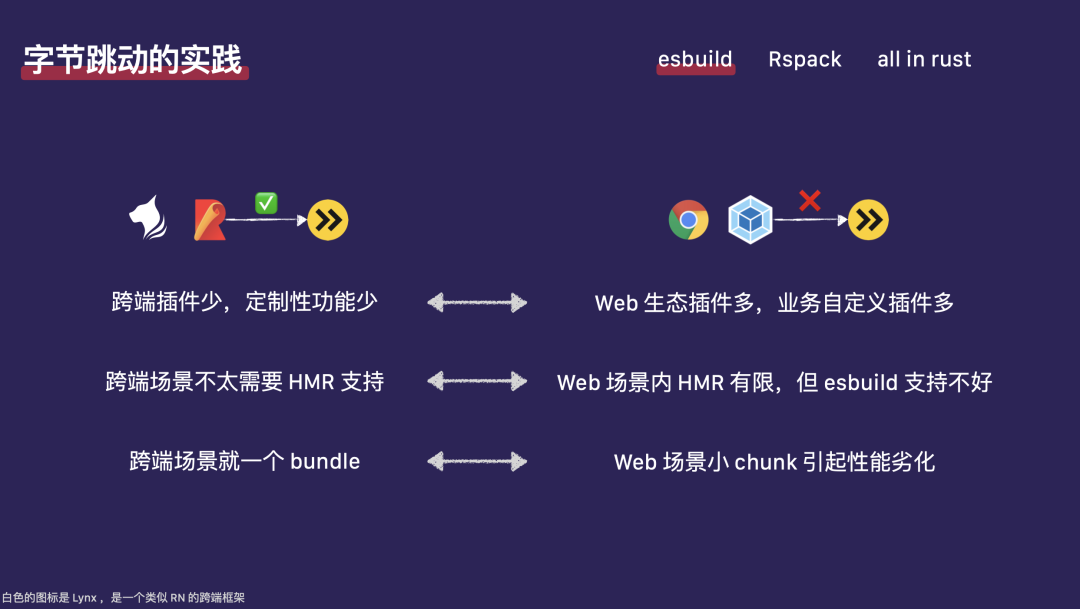
图左上角的白色 logo 是我们公司内部的跨端框架 Lynx,它适用于跨端场景。2020 年,抖音在春节期间的主要工程基础设施就是基于 Lynx。当时我和团队负责 Lynx 的工程化工作。我们最初使用的是基于 Rollup.js 加上一些插件来完成基础环境的打包。由于人力充足,加上春节项目的重要性,我们得到了良好的支持,并迅速推进了这个项目。项目推出后,业务反馈非常积极。尽管参与春节项目的人员众多,但整个研发团队的规模庞大,可能占据了一整层楼。随着代码量的增加,我们并没有观察到性能明显下降,而且 CI/CD 的发布时间也显著缩短。因此,我们首次尝试这种新方法,感觉非常新鲜且效果良好。春节结束后,我们希望将这种能力扩展到 Web 生态。我们想做的第一个项目是抖音的购物车,是我们公司在 Web 场景上首次尝试使用 esbuild 的项目。然而,这也是最后一次,因为它最终失败了。失败的原因我在这里总结如下。
首先,我们来对比跨端场景和 Web 生态的不同。 在跨端场景中,运行时环境相对受限,可用的插件较少,因此大部分业务功能需要由跨端框架的开发者来实现。这为我们提供了良好的控制性和较少的定制性需求,使得实现起来相对容易。在 Web 生态下,我们能够利用的社区插件功能非常丰富。业务上也有许多自定义插件,这导致 JavaScript 部分和原生部分需要频繁交互,进而使得性能提升不是很明显。
第二个问题是热模块替换(HMR)的支持。 在跨端场景中,例如 Flutter 和 Lynx,对 HMR 的支持并不特别友好。它们大多采用 LiveReload 的方式进行更新,而在 Web 场景中,HMR 是一个非常重要的特性。尽管 esbuild 最近在这方面有所改进,但与 Rspack 等项目相比,其支持程度仍有较大差距。
最后一个,也是最关键的问题,是关于打包。 在跨端场景中,通常只有一个 bundle,所有代码都加载到一个 bundle 中,类似于小程序的场景,我们不需要进行非常精细的分包或对产物进行极致优化。但在 Web 场景下,情况就大不相同了。在 Web 生态中,Webpack 在这方面的功能已经非常成熟。如果我们在创建上有所变化,导致运行时加载性能下降,对业务的影响将是致命的。特别是对于抖音购物车这样的 C 端场景,性能劣化将引起严重问题。因此,我们在 esbuild 方面的探索最终以失败告终。
我们对工具原生化这个方向非常认可,认为这是值得深入探索的领域。因此,在下一个阶段,我们进行了调研,发现社区内并没有能够解决我们需求的工具,于是我们决定自己开发一个名为 Rspack 的项目。项目启动初期,在公司内部遇到了很多质疑的声音,我们自己内心也有所疑虑。这里,我想分享以下三个观点。
工具使用者与开发者应使用同一编程语言。 这个观点有一定的道理,因为如果双方使用相同的语言,开发者可以更好地理解使用者的痛点,了解 JavaScript 生态的现状。然而,也有不同的情况,如果开发者使用与使用者不同的语言,可能有助于拓展工程视野。
分享案例。 在公司内部,我们有许多组件库和基础工程库,这些库的构建使用的是我们的基础工具。我们在 JavaScript 社区内对类似工具进行了调研。但当我们团队开始使用 Rust 开发时,发现情况有所不同。例如,Cargo 集成了文档和测试功能,这些集成显著提升了库的开发体验。通过使用 Rust,我们学习到了新知识,拓宽了视野,这也有助于 JavaScript 社区生态的发展。
跨语言学习的价值。 以 Bun 工具为例,Bun 的发展目标与 Cargo 类似,旨在集成包括运行时、包管理器、任务运行器在内的所有工具。这表明,即使工具使用者和开发者使用不同的语言,也可以通过跨语言学习获得宝贵的洞见。此外,React 团队在开发过程中不仅仅局限于 JavaScript 生态,他们也会研究 iOS 和 Android(如 Jetpack Compose)的实现方式。我们公司内部也在思考跨端框架的未来发展方向。
JavaScript 本身并不慢。实际上,工具的性能并不完全取决于所使用的语言。只要架构设计合理,就能发挥出良好的性能。这个观点有一定的正确性,但也存在错误之处。正确的地方在于,通过设计更好的架构确实可以实现更好的性能。错误之处在于,语言本身的限制可能会影响架构设计的能力。例如,JavaScript 在多线程方面的限制使得我们难以实现多线程操作。但是,有了 Rust 这样的工具后,我们可以更灵活地处理多线程问题,实现各种生产者 - 消费者模型等。
在 Rspack 的内部实现中,我们已经能够充分利用当前计算机的 CPU 性能。接下来,讨论 Webpack 的性能问题。Webpack 的慢并不是因为 Webpack 本身,而是慢在了插件上。我们在实际使用 Webpack 的经验中发现,如果不配置任何插件,它的性能实际上是可接受的。但随着插件的增加,性能就会下降。因此,在开发 Rspack 时,我们考虑了这个问题,并决定将更多插件功能内置化,将社区内已经标准化的功能整合进来。使用 Rspack 的用户可能会注意到,它内置了很多 loader。这些 loader 并不需要进行 AST 或字符串的序列化和反序列化操作,它们仅仅是作为一个标识符存在,从而提高了性能。
当前社区在推进打包(bundle)技术的方向上,有一个非常极致的目标,那就是实现一次性处理的打包。这意味着我们不需要对单个文件进行反复的编译和代码注入(Code In),而只需通过一次处理就能完整地完成整个打包过程。在明确了这些目标之后,我们的项目也逐渐取得了成功。现在,大家可能已经在社区中看到了我们的项目成果。同时,我也想借此机会感谢大家过去对我们的支持和帮助。
在字节跳动内部,我们很快就从业务上获得了实际收益,这也为我们迎来了下一个发展阶段,即全面采用 Rust(all in Rust)。我们计划推进的目标是,将所有基于 Rspack 的 Rust 基础工具覆盖到我前面提到的主流场景。我们正在推进的一个重点是,在控制力较强的场景中,如跨端开发和小程序开发,实现全面采用 Rust 工具。
接下来,我想分享一下我们在做这件事情时给公司带来的一些收益。首先,最明显的收益是性能方面的提升。许多业务在接入 Rspack 后,获得了大约 10 倍的性能提升。例如,CI/CD 构建时间明显缩短,本地开发时间也显著减少。这种性能上的提升进一步引发了后续的传导效应,即对工作流程(workflow)的优化。
aPass 团队负责的工程是一个在字节跳动内部经过长时间迭代、涉及多个团队的复杂单仓库项目。过去的工作流程是:首先进行一次发布,记录当前发布所包含的所有包和子包信息,这些信息会以 JSON 格式保存。一周后再次发布时,他们会拿出之前的 JSON 文件进行对比,以找出增量变化的包,检查是否有重复引入的包,例如 React 是否引入了重复的依赖等。但这种实践存在一个明显问题:经过一周的时间,如果团队有 50 人,每人提交了一个更改(commit),就会有 50 个 commit。在这种情况下,要定位到底是哪个 commit 引入了问题变得非常困难。为了解决这个问题,我们引入了新的工作流程。过去无法实现这种优化的主要原因是构建过程耗时太长。例如,aPass 项目的关键构建可能需要 30 分钟,合并请求要等待 30 分钟这是不可接受的。优化后的工作流程基于 Rspack。现在,一次检查只需要一两分钟,大大提高了效率。Rspack 会生成一个 Rspack.json 文件,它可以精确地告诉你是否有重复的包出现,哪个包体积变大了,从而可以进行有效的工作流程优化。

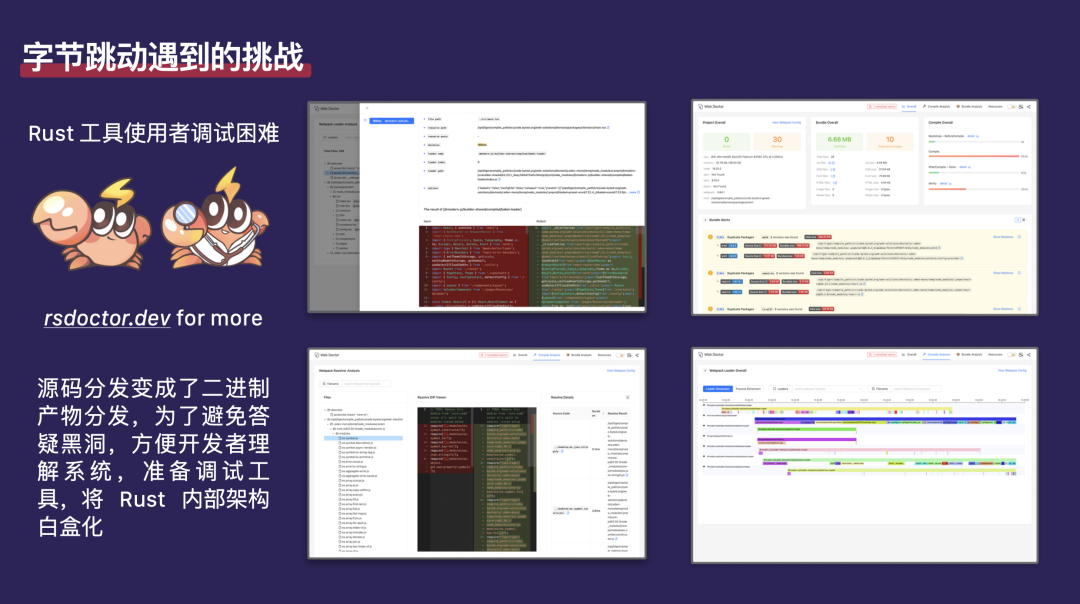
接下来,我想和大家分享我们在推进这项工作过程中遇到的挑战。主要有两个问题。首先是 Rust 工具的使用者面临的调试难题。我们过去分发的是 JavaScript 源码,现在转变为分发二进制产物。如果业务在构建过程中遇到错误,比如 segmentation fault 或其他问题,他们很难像以前处理 JavaScript 那样自行调试。使用 Rspack 后,这种调试能力似乎丧失了。我们作为中台需要支持业务的 OnCall 需求。为了防止二进制分发带来的 OnCall 问题,我们开发了一个调试工具。目前,这个工具已经开源:
rsdOXCtor.dev。在设计这个工具时,我们的理念与 Chrome 团队相似。Chrome 是用 C++ 实现的,但我们并不觉得它的开发体验差,也不认为它难以使用。核心原因在于 Chrome 的开发工具做得非常好,使我们能够方便地了解其中的所有流程。同样,我们开发的这个工具旨在将 Rspack 内部的所有流程白盒化。我们会展示每个 loader 是如何处理的,流程是如何串联的,文件是如何被发现和加载的,以及整个处理流程的细节。这样,用户就能更好地理解和使用 Rspack。
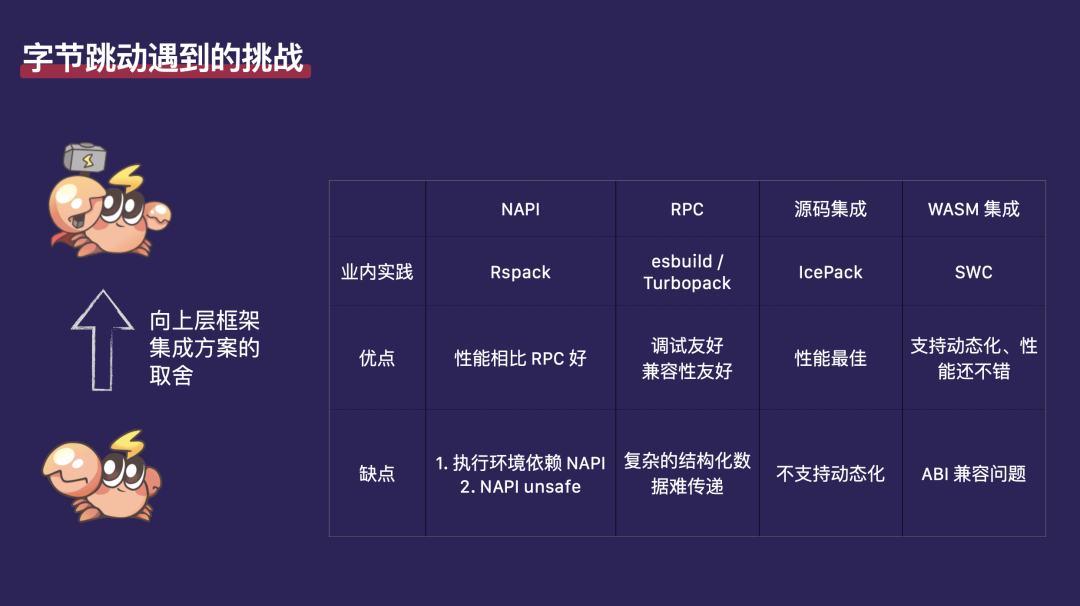
第二个问题涉及到集成方面的挑战。我们的工具和框架是分层构建的,正如大家之前在图上看到的,我们有多种上层解决方案。作为一个基础的 Rust 库,当我们考虑向上层集成时,我们面临多种选择。主要的集成方案有四种:NAPI(Node.js API)和 RPC(远程过程调用)主要用于与 JavaScript 的集成;源码集成和 Wasm(WebAssembly)集成则更适用于 Rust。
NAPI 这种方案目前在 Rspack 和 Rolldown 等项目中得到了应用,并且在社区内属于相对主流的集成方式。它的优点在于整体性能表现良好,尤其是与 RPC 方案相比,NAPI 在性能上具有优势。NAPI 方案也存在一些缺点。首先,执行环境高度依赖于 NAPI 的实现,这可能限制了其灵活性和可移植性。其次,NAPI 本身涉及大量 unsafe,这意味着它更易受到内存相关的错误影响,增加了开发和维护的复杂性。
第二个方案是 RPC 方案,目前 esbuild 和 Turbopack 正在使用这种方案。它的优点主要包括两个方面:
调试优化:RPC 方案对于基础的 Rust 开发者来说,在开发像 esbuild 和 Turbopack 这样的工程时,提供了便利的调试体验。例如,设置断点和进行调试相对容易。
兼容性友好:RPC 本质上是一种跨线程的通信机制,类似于通过 HTTP 进行的通信。因此,它对运行环境的依赖性较低,使得它在不同环境中具有较好的兼容性。
RPC 方案也存在缺点,尤其是在处理复杂对象时。如果需要将结构化的对象序列化传输,然后在另一端进行反序列化,这个过程可能会变得相当复杂和难以处理。
对于 Rust 版本的集成,实际上有两种主要方式:源码集成和 Wasm 集成。
源码集成 的一个例子是淘天集团正在开发的 IcePack 项目。源码集成的过程相对直接:将 Rust 代码合并到项目中,根据需要进行修改,然后发布一个新的包。这种方法的优点在于它提供了最佳的性能。但同时,它也存在一个问题,即集成的插件不是动态化的。这意味着,每当 IcePack 发布更新时,你需要自动滚动到一个新的 commit,以便获取更新后的代码和功能。
Wasm 集成 则是通过 Wasm 插件实现的,这是 SWC 目前主要推广的方案。Wasm 集成支持动态化,并且性能表现也相当不错。不过,它的缺点在于需要基础库的开发者确保 ABI 的前后版本兼容性。
Rust 中等复杂系统的设计
前面我分享了我们在实践中遇到的问题和一些收益。接下来这部分内容会更加深入和实用,我将和大家探讨在开发 Rspack 这个中等复杂度系统时遇到的架构设计问题。为了更好地理解这些内容,你需要具备一些基础的 Rust 知识,比如了解所有权、生命周期、引用借用以及内部可变性等概念。
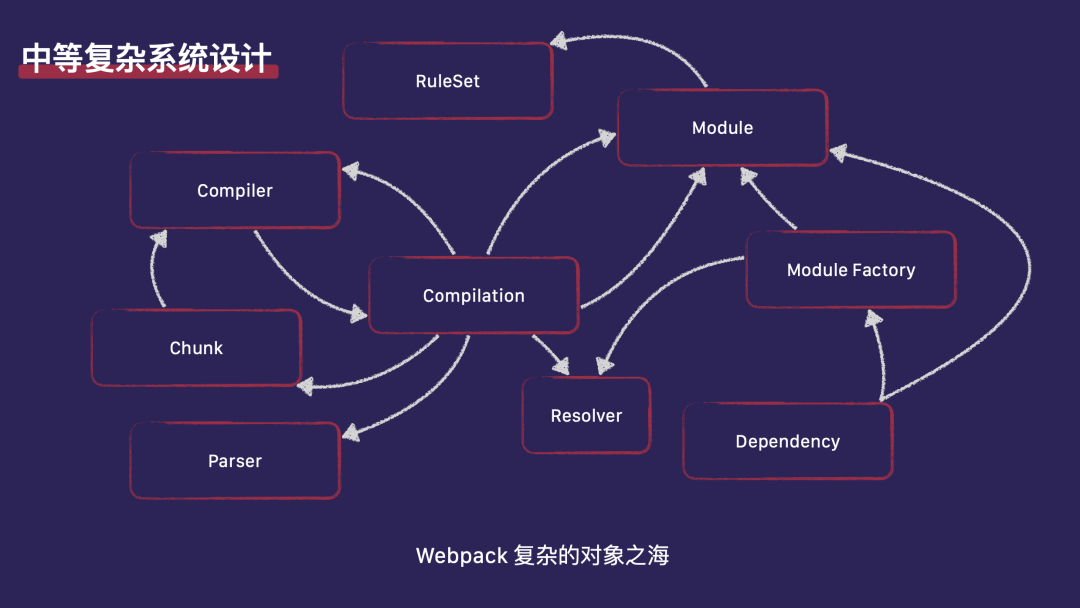
我们从熟悉的 Webpack 开始。Webpack 包含一个复杂的对象网络,对象之间存在复杂的引用关系。在 Webpack 中,这些模型得到了很好的抽象和建模,并且已经能够支持我们所有的业务需求。作为 JavaScript 开发者,垃圾回收(GC)的概念贯穿于我们工作的各个环节,无论是代码编写还是架构设计,都依赖于 GC 的存在。然而,在 Rust 中,情况有所不同。Rust 强调所有权概念、借用检查和编译时检查,这使得我们无法直接复制 Webpack 的完整模型。同时,我们又需要对标 Webpack,那我们应该怎么做?
我们先将问题简化,从内存被两个对象同时持有的情况开始讨论,这种情况称为多引用。在 Rust 中,我们可以通过生命周期(lifetime)来标记引用,以确保内存安全。生命周期使用一个撇号(’)加上小写字母表示,例如 A’c,它表明对象 a 引用了对象 c,且 c 的生命周期必须长于 a。同样,我们也可以让 a 和 b 都引用同一个对象 c。
这种方法在 Rust 中很常见,例如在 Lightning CSS 中就存在大量这样的代码。其优点是性能良好,几乎不会带来性能问题。然而,它也存在一些问题。首先是生命周期的复杂性,因为生命周期是 Rust 语言的一个强传导性特性。例如,在 Lightning CSS 中,一个结构体的实现可能已经包含了 6 个生命周期参数,这增加了开发和维护的成本。如果你需要修改一个生命周期参数,它可能会引起广泛的连锁反应。其次,引用在多线程环境下会带来限制。如果我们想构建一个复杂的多线程架构,引用的使用可能会限制我们在架构设计上的灵活性。

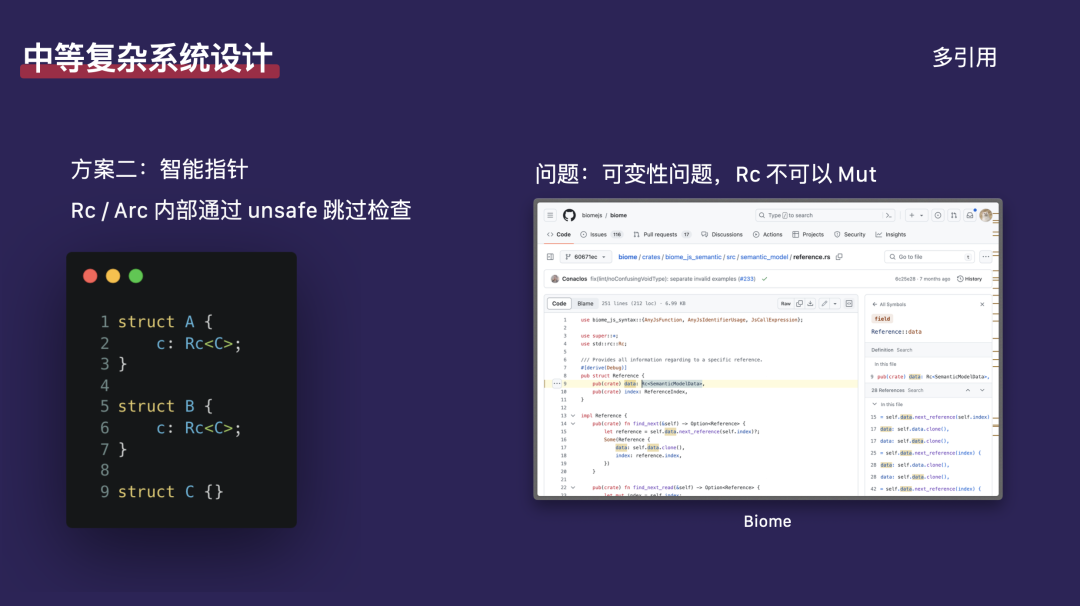
Rust 提供了另一种解决方案,即智能指针,我们可以通过 Rc(引用计数)和 Arc(原子引用计数)来标记一个对象,从而绕过对生命周期的检查。Rc 是 “Reference Count”的缩写,而 Arc 是 “Atomic Reference Count” 的缩写。两者的区别在于 Arc 是线程安全的,而 Rc 则不是。它们内部通过 unsafe 代码块来跳过编译器的某些安全检查。使用 Rc 可以让我们实现对象 a 和 b 同时引用对象 c。然而,这种方法引入了新的问题:Rc 本身是不可变的,因为在 Rust 中,可变性是一个需要明确检查的概念。尽管如此,Rc 和 Arc 在行业内被广泛使用。例如,在 Biome 项目中就有许多基于 Rc 的代码。但是,由于 Rc 的不可变性,它不允许对象被修改。在进行复杂的架构设计时,我们通常希望能够修改对象。如果我们不能修改对象,这在实际应用中往往是不可接受的。
Rust 提供了第三个解决方案,即结合智能指针和 RefCell。RefCell 引入了内部可变性的概念。尽管 Rc 本身不可变,但 RefCell 允许其内部可变,它通过 unsafe 代码实现这一功能。我们可以先将结构体 c 包装在 RefCell 中,然后再将其包装在 Rc 中。这样,对象 a 和 b 就可以同时引用 c,并且能够对 c 进行修改。通过这种方式,我们就能够模拟 Webpack 中复杂的对象网络建模。这种方法仍然面临一个问题:对象之间可能会形成循环引用。例如,对象 a 持有对象 b 的引用,而对象 b 也持有对象 a 的引用。这种循环引用在智能指针中是难以解决的,因为 Rc 本质上是基于引用计数的。当两个对象相互引用时,即使不再使用它们,它们的引用计数可能仍然为 1,导致它们无法被释放,从而引起内存泄漏问题。

在我们讨论的背景下,我想提到一个行业内的实验案例,即 Yew。Yew 是一个使用 Rust 开发的 UI 框架,在它的实现中大量使用了 Rc 和 RefCell。面对循环引用导致的内存泄漏问题,我们应该如何去解决呢?实际上还有第四种解决方案,那就是使用 unsafe 代码结合原始指针(*mut T)。这种方案在 Rust 语言的基础库中比较常见,例如 Rc 和 RefCell 的实现。然而,对于 Rust 的业务逻辑代码来说,我们很少直接使用这种功能,因为它涉及到直接的内存操作,风险较高。
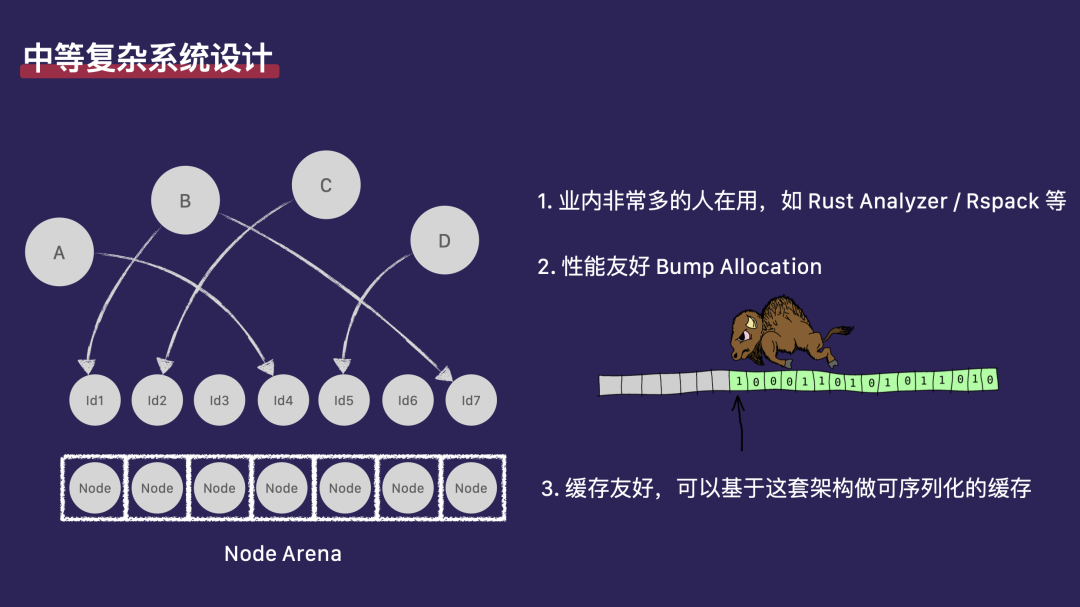
我们还有一个方案,称为 Arena。熟悉 Rust 的开发者可能对 Arena 已经比较了解。Arena 的本质是变长数组(动态数组)。每个对象都由这个 Arena 数组来持有。例如,如果我们要创建一个 Node 对象,我们会将它放在 Arena 数组的下一个空位中。所有想要持有 Node 的对象,实际上持有的是指向 Node 的索引,也就是数组中的位置。在这个系统中,如果对象 a 想要持有数组中的第四个 Node,它不会直接持有这个 Node,而是持有这个 Node 索引(usize 类型)。这种方式可以很好地支持 clone、copy 操作,以及跨线程发送。我们可以用它来构建复杂的架构,例如 Rust Analyzer 和 Rust 编译器自身就大量使用了 Arena 架构。
使用 Arena 的另一个特点是,它要求对象可以不同时间创建,但必须同时销毁。Arena 的销毁是通过一次性释放整个数组来完成的。如果我们想在中间释放数组中的某个元素,比如第四个 Node,但可能已经找不到所有引用它的地方,那么如果再次访问该元素,可能会发生不可预知的事情。这是使用 Arena 方案可能遇到的问题,但尽管如此,这个方案仍然有许多优点。
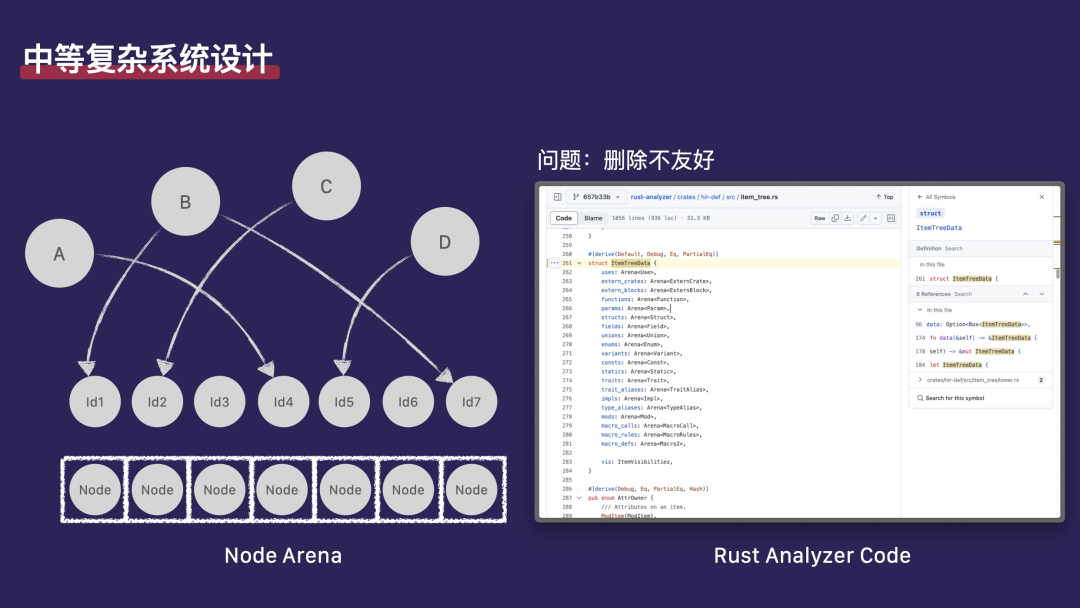
首先,Arena 这种技术方案在业界有非常广泛的应用。 不仅在游戏开发的实体组件系统(ECS)中,甚至在 Rust Analyzer、Rust 编译器(Rust c)以及 Rspack 等项目中,都在大量使用 Arena。
第二点是性能优势。 在 Rust 生态中,有一个库叫做 Bump AllOXCation,其核心原理是在系统启动时预先分配一大块内存。之后,所有对象的创建都在这块已经分配好的内存上进行,从而避免了频繁进行系统调用去请求系统的内存分配器。减少对系统内存分配器的调用,可以显著提升性能。在 OIC 等工程项目实践中就大量依赖了 Bump AllOXCation。
第三点是缓存友好性。 以 Webpack 为例,虽然它支持本地可落盘的缓存,但其缓存能力并非极致,无法将整个系统序列化。在 JavaScript 开发中,如果遇到循环引用的对象,使用 JSON 序列化会失败,因为系统无法处理这种需求。而 Arena 帮助解决了循环引用问题,我们只需将整个数组序列化到硬盘,之后再反序列化回来,就能实现可落盘的、可序列化的缓存架构。目前在 Rspack 工程以及社区内的许多项目中,都在大量依赖这种对象组织方式。我们也通过这种方法完成了 Rspack 内部的基础架构建模。
总结
最后,我想做一些总结。首先,从个人角度来看,技术成长和发展需要我们具备跨语言的技术储备。无论是进行基础架构设计还是业务开发,掌握多种语言都能极大地拓宽我们的技术视野。
第二点,科技企业在 Rust 方向的投入也在增加。一些动作迅速的公司已经开始实施相关项目。在字节跳动,Rust 的应用不仅限于前端工程化领域,还扩展到了后端框架和后端研发。例如,抖音的一些服务端业务已经开始使用 Rust 进行开发。此外,过去的 Lark 客户端 SDK 也是利用 Rust 来构建平台业务逻辑的。
第三点,工程化是 Rust 在前端领域展现优势的最佳场景之一。如果大家还在犹豫是否应该开始使用 Rust,现在可以放心地尝试,因为在这个领域取得成果相对容易。
第四点,我相信 Rust 在前端领域将会有更多的应用场景。例如,最近开源的名为 Zed 的编辑器,它可能成为 Visual Studio Code 的竞争者。Zed 的 UI 实现完全是用 Rust 完成的,它还引入了一个名为 GPUI 的库,允许开发者使用 Rust 构建跨平台的高性能 UI。
会议推荐
AI 应用开发、大模型基础设施与算力优化、出海合规与大模型安全、云原生工程、演进式架构、线上可靠性、新技术浪潮下的大前端…… 不得不说,QCon 还是太全面了。现在报名可以享受 9 折优惠,详情请联系票务经理 17310043226 咨询。





