
InfoQ 趋势报告为 InfoQ 读者提供了一个关于我们认为架构师和技术领导者应该关注的主题的高层级概述。此外,它们还可以帮助 InfoQ 的编辑团队专注于撰写新闻和招募文章作者来报道创新技术。
在这份年度报告中,InfoQ 的编辑们讨论了人工智能(AI)、机器学习(ML)和数据工程的现状,以及作为软件工程师、架构师或数据科学家应该关注的新兴趋势。文章将编辑们的讨论整理成了一条技术采用曲线,并提供了支持性评论,以帮助大家了解事物是如何演进的。
在今年的播客(podcast)中,来自 Chime 的软件工程师 Sherin Thomas 加入了 InfoQ 编辑团队。本文中下面的内容总结了其中的一些趋势,以及不同技术在技术采用曲线中的位置。
生成式 AI
生成式 AI,包括GPT-3、GPT-4 和Chat GPT等大语言模型,现已成为人工智能(AI)和机器学习(ML)行业的主要力量。这些技术已经引起了极大的关注,特别是考虑到它们在过去一年中取得的进展。我们已经看到这些技术被用户广泛采用,特别是在 ChatGPT 的推动下。谷歌和 Meta 等多家公司已经宣布了自己的生成式 AI 模型。
我们期望的下一步是更多地关注 LLMOps,以便在企业环境中操作这些大语言模型。对于 prompt 工程是否会成为未来的一个大主题,或者它是否会被广泛采用以至于每个人都能够为自己所使用的 prompt 做出贡献,我们存在分歧。
向量数据库和嵌入存储
随着 LLM 技术的兴起,人们越来越关注向量数据库和嵌入存储。一个吸引人的应用是使用句子嵌入来增强生成式 AI 应用程序的可观察性。
对向量搜索数据库的需求源于大语言模型的限制,这些模型具有有限的 token 历史记录。向量数据库可以将文档摘要存储为这些语言模型生成的特征向量,从而可能产生数百万或更多的特征向量。对于传统数据库,随着数据集的增长,查找相关文档会变得很有挑战性。向量搜索数据库实现了高效的相似性搜索,允许用户定位查询向量的最近邻居,从而增强了搜索过程。
一个显著的趋势是对这些技术的投资激增,这表明投资者认识到了它们的重要性。然而,开发人员的采用速度较慢,但预计在未来几年会加快。Pinecone、Milvus等向量搜索数据库和Chroma等开源解决方案正在获得关注。数据库的选择取决于特定的应用程序和所搜索数据的性质。
在包括对地观测在内的各个领域,向量数据库已显示出它的潜在实力。例如,美国国家航空航天局(NASA)利用自监督学习和向量搜索技术来分析地球的卫星图像,以帮助科学家追踪飓风等天气现象。
机器人和无人机技术
机器人的成本正在下降。过去,腿型平衡机器人很难实现,但现在已经有一些型号的机器人售价约为 1500 美元。这使得更多的用户可以在他们的应用程序中使用机器人技术。机器人操作系统(ROS)仍然是该领域的领先软件框架,但像 VIAM 这样的公司也在开发中间件解决方案,以使集成和配置机器人开发插件变得更加容易。
我们预计,无监督学习和基础模型的进步将转化为能力的提升。例如,通过将大语言模型集成到机器人的路径规划中,以实现使用自然语言来进行规划。
负责任且合乎道德的人工智能
随着人工智能开始影响全人类,人们对负责任且合乎道德的人工智能越来越感兴趣。人们同时呼吁对大语言模型进行更严格的安全保护,同时也对此类模型提醒用户的现有保障措施输出感到沮丧。
对于工程师来说,重要的是要牢记需要改善所有人的生活,而不仅仅是改善少数人的生活。我们预计人工智能监管将产生与几年前 GDPR 类似的影响。
我们已经看到一些人工智能因为糟糕的数据而失败。数据发现、操作、数据沿袭、标记和良好的模型开发实践将成为中心。数据对可解释性至关重要。
数据工程
现代数据工程的特点是动态地转向更加分散和灵活的方法来管理不断增长的数据量。数据网格(Data Mesh)是一个新颖的概念,它的出现是为了解决集中式数据管理团队成为数据运营瓶颈所带来的挑战。它主张建立一个跨域分区的联邦数据平台,将数据视为一种产品。这允许域所有者拥有对其数据产品的所有权和控制权,从而减少了对中心团队的依赖。尽管数据网格的采用前景广阔,但可能面临与专业知识相关的障碍,需要先进的工具和基础设施来实现自助服务功能。
数据可观察性在数据工程中已经变得至关重要,类似于应用程序架构中的系统可观察性。可观察性在所有层面上都是必不可少的,包括数据的观察性,尤其是在机器学习的背景下。对数据的信任是人工智能成功的关键,数据可观察性解决方案对于监测数据质量、模型漂移和探索性数据分析至关重要,以确保可靠的机器学习结果。数据管理的这种范式转变以及跨数据和机器学习(ML)管道的可观察性集成反映了现代数据工程的发展前景。
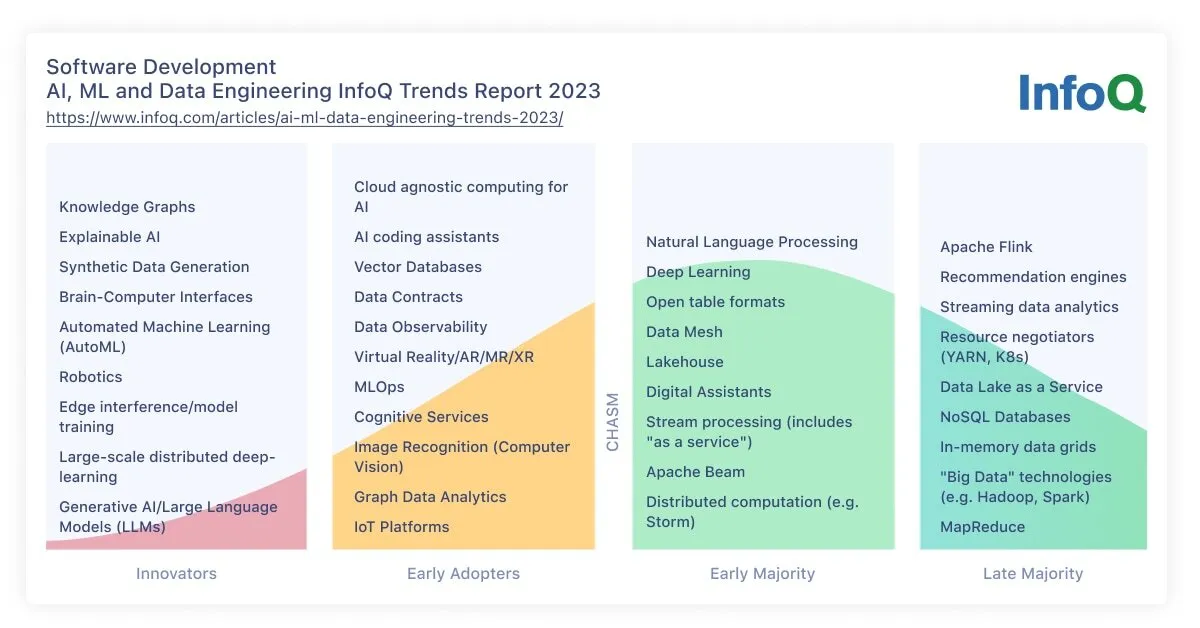
曲线的更新的相关解释
这份趋势报告还提供了一张更新的图表,显示了我们对某些技术的看法。这些类别基于 Geoffrey Moore 的《跨越鸿沟》(“Crossing the Chasm”)一书。在 InfoQ,我们主要关注那些尚未跨越鸿沟的类别。
从创新者到早期采用者的一个显著升级是“人工智能编码助手”。尽管它们在过去一年非常新,几乎没有使用过,但我们看到越来越多的公司将其作为一项服务提供给员工,以提高他们的效率。它并不是每个技术栈的默认部分,我们仍在探索如何最有效地使用它们,但我们相信其采用率将会继续增长。
我们认为现在正在跨越鸿沟的是自然语言处理。这对任何人来说都不会感到惊讶,因为在 ChatGPT 取得巨大成功之后,许多公司目前都在试图找出如何在他们的产品中采用生成式人工智能的功能。因此,我们决定让它跨越鸿沟,进入早期多数的类别。它在这里仍然有很大的增长潜力,时间会告诉我们更多关于这项技术的最佳实践和能力。
有一些值得注意的类别根本没有移动。这些技术包括合成数据生成、脑机接口和机器人技术。所有这些似乎都一直被困在创新者的范畴里。在这方面最有希望的是合成数据生成主题,最近随着 GenAI 的炒作,该主题受到越来越多的关注。我们确实看到越来越多的公司在谈论生成更多的训练数据,但还没有看到足够多的应用程序在它们的技术栈中实际使用这些数据来保证它进入到早期采用者的类别。多年来,机器人技术一直备受关注,但它的采用率仍然太低,我们无法保证它的发展。
我们还在图中引入了几个新的类别。一个值得注意的是向量搜索数据库,这是 GenAI 炒作的副产品。随着我们对如何将概念表示为向量有了更多的理解,我们也更需要有效地存储和检索所述向量。我们还将可解释的人工智能添加到创新者的类别中。我们相信,计算机解释它们为什么会做出某个决定,对于广泛采用以对抗幻觉和其他危险至关重要。然而,我们目前还没有看到足够的行业工作来保证它进入更高的类别。
结论
人工智能(AI)、机器学习(ML)和数据工程领域每年都在不断发展。在技术能力和可能的应用方面仍有很大的增长。对于我们 InfoQ 的编辑来说,能够如此接近这一进展是令人兴奋的,我们期待着明年能做出同样的报告。在播客中,我们对未来一年做了一些预测,从“将不会有 AGI”到“自动代理将成为一件事”。我们希望你喜欢听播客并阅读这篇文章,并希望能在本文的下面看到你的预测和评论。
原文链接:
https://www.infoq.com/articles/ai-ml-data-engineering-trends-2023/
相关阅读:




