
AI 应用的崛起,推动了数据处理方式的变革
2023 年被广泛认为是大语言模型的元年,这一年我们见证了人工智能技术前所未有的飞跃。而步入 2024 年,围绕大语言模型诞生出来的 AI 原生应用如雨后春笋般涌现。越来越多的 AI 应用已经不再局限于纯文本生成和回答,而是逐渐向多模态应用程序演进。
以典型的多模混合查询为例,消费者在 AI 应用中搜索“推荐距离 500 米以内,人均消费 24 元以下,评价 4.5 分以上,不用排队的奶茶店”时,数据库要同时处理 GIS 数据(距离)、关系型数据(价格、评分)、向量数据(不排队)等不同类型的数据。这就意味着,传统的数据处理方式已经很难满足新 AI 应用带来的复杂需求。
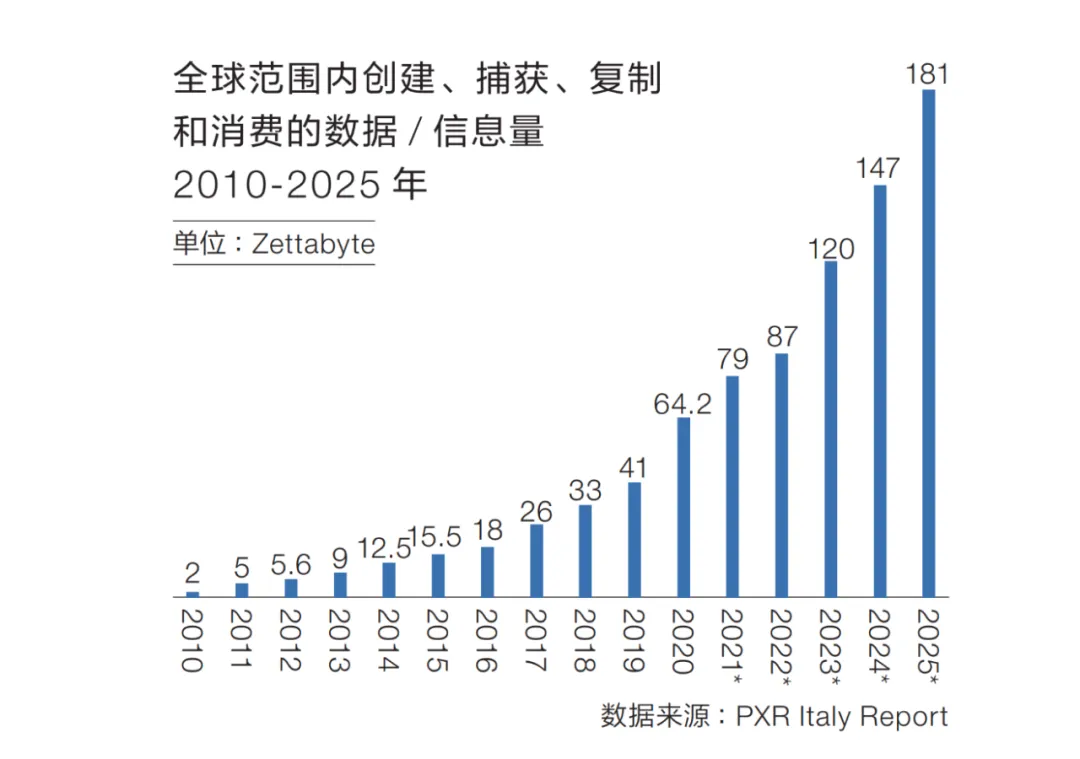
意大利 PXR 研究机构数据统计,全球范围内创建、捕获、复制和消费的数据 / 信息量从 2010 年的 2ZB 增长到 2020 年的 64.2ZB。预计到 2025 年,全球数据总量将超过 181ZB。
这些数据中,既包含动态、实时的数据流,也涵盖静态、历史的数据存储;既有结构化的数据库记录,也有非结构化的语音、图像和视频。如此海量、复杂的数据给数据库提出了新要求:
实时性与低延迟:随着实时数据分析和决策的需求增加,数据库必须能够快速处理大量数据,以支持实时应用,如在线推荐和动态定价。这对传统数据库在性能和响应时间上提出了更高的要求。
海量数据与多样性:AI 应用生成的数据量大且类型多样(结构化、半结构化和非结构化),数据库需要具备处理和存储不同类型数据的能力,要求支持多模架构,以满足多模态的数据需求。
复杂融合查询:AI 应用对复杂数据分析提出更高的需求,数据库需要支持复杂 SQL 查询优化,提升查询性能,以满足深度学习和机器学习模型的训练与预测需求。
多源数据融合:不同来源的数据需要进行融合处理,以获取更全面、更准确的信息。例如,将企业内部不同业务、不同工作负载的数据,甚至生态业务数据、行业数据进行融合,分析企业的市场竞争力和发展趋势。
在 AI 技术的推动下,单一、结构化、静态数据架构的时代已经一去不复返,数据库架构的变革正在呼之欲出。那么落实到技术上,到底什么样的数据库才能应对以上种种挑战,能承接住 AI 应用井喷后带来的海量数据处理需求?
AI 时代,我们需要什么样的数据库?
刚刚,OceanBase 提出了自己的解法。
在 10 月 23 日举办的 2024 OceanBase 年度发布会上,OceanBase 推出了 OceanBase 4.3.3 版本,增加了全新的向量检索与索引功能,实现了 SQL+AI 一体化。该版本深度融合 AI 与数据库处理能力,支持多模态数据融合查询,帮助企业简化 AI 技术栈,提升 AI 应用构建效率。
也就是说,OceanBase 希望用一个数据库满足客户 80% 的数据库场景需求,将所有的复杂性工作交给数据库,将简单留给客户。
作为首个面向实时分析的 GA 版本,OceanBase 4.3.3 在多个关键能力上取得了显著突破,其重要创新与对 AI 场景的支持主要体现在以下几个方面:
向量融合查询能力:OceanBase 4.3.3 在关系型数据库基础上新增了向量检索能力,支持向量数据类型、向量索引以及基于向量索引的搜索能力。用户可以通过 SQL 和 Python SDK 等方式灵活使用 OceanBase 的向量检索能力。结合 OceanBase 对海量数据的分布式存储能力,以及对多模数据类型和多种索引的支持,OceanBase 4.3.3 提供了更加丰富的融合查询能力,大幅简化 AI 应用的技术栈,加速 RAG、智能推荐和多模态搜索等业务场景的落地。
全新的列存副本形态:为了更好地支持 HTAP 混合负载场景,OceanBase 4.3.3 引入了列存副本的新形态,满足 TP 和 AP 负载资源物理强隔离的需求。在混合场景中,事务处理和分析处理通常会对系统资源产生不同的需求,而这种物理隔离的副本机制确保了系统在处理事务型负载的同时,不会受到分析型负载的干扰。尤其对于实时数据分析和决策,这种隔离机制能够确保系统的高性能和稳定性。
AP 类查询的性能优化:在新的版本中,OceanBase 针对 AP(分析处理)场景进行了大幅度的性能优化。通过对 AP 类 SQL 的执行计划生成和执行策略的优化,显著提升了复杂查询的效率。特别是在海量数据分析和复杂数据融合查询时,新版本提供了更短的响应时间和更高的吞吐能力,帮助企业在实时分析和预测任务中更快获得结果。
新增并且优化了对复杂数据类型的支持:OceanBase 4.3.3 进一步扩展了对复杂数据类型的支持,新增了 Array 类型,并优化了 Roaringbitmap 类型的计算性能。这为企业处理多样化数据结构提供了更大的灵活性,同时强化了基于物化视图的改写与刷新机制,使得复杂的分析任务能够更高效地执行。
外表功能扩展及性能提升:在数据导入和集成方面,OceanBase 4.3.3 大幅优化了外表(External Table)的功能,并提高了数据导入的性能。这使得外部数据源的整合更加流畅,特别是对于需要频繁导入大规模数据的场景,企业可以更快地完成数据同步,满足业务的实时需求。
快速恢复与 QUERY 级资源组支持。OceanBase 4.3.3 引入了一种无需恢复数据到本地即可通过恢复日志提供读写服务的快速恢复能力,这种机制在数据恢复场景中显著提升了系统的可用性。此外,该版本还支持了 QUERY 级别的资源组设定,使得系统能够更灵活地分配和管理资源,进一步提升了在高并发、复杂查询环境下的可靠性。

总的来说,OceanBase 4.3.3 通过对向量支持、实时 AP 及混合负载、复杂查询优化、外部数据集成及系统可靠性的全面提升,为 AI 时代的企业数据处理提供了更高效、灵活和稳定的技术支撑。
发布会上,OceanBase 与蚂蚁集团联合开发的向量库在业内标准的 ANN Benchmarks 基准测试中,针对 GIST-960 数据集表现出色。测试结果显示,该向量库在 ANN Benmarks 测试中性能远超其他算法,排名第一。特别是在 90% 以上的召回率区间,查询性能(QPS)相比此前最优算法 glass 提升 100%,相比基线算法 hnswlib 提升 300%。
CEO 杨冰表示,伴随着互联网 / 移动互联网时代向 AI 时代演进,数据库也正从分向合统一,一体化数据库将成为 AI 时代的数据底座。

那么,该如何理解所谓的一体化数据库?OceanBase 又为何会在这样的时间点上提出一体化数据库的概念?
据杨冰介绍,一体化数据库是一种能够处理多种工作负载、数据类型及场景的数据库系统,旨在通过一个数据库满足企业各种复杂的数据需求,简化技术栈,提升效率并应对日益复杂的数据需求。这种数据库通常具备事务处理(TP)和分析处理(AP)能力,支持多模数据处理(如 JSON、XML、GIS、文档等),并兼容多种主流数据库协议(如 MySQL 和 Oracle),让用户能够在一个数据库上满足多样化的数据处理需求。

OceanBase 的一体化数据库的概念并非一蹴而就,而是伴随着 OceanBase 的整个生命周期,逐步演化、成熟。这种一体化能力并非凭空设计,而是深深植根于客户场景和需求之中,是市场实践的结晶。在这一过程中,OceanBase 经历了两次大的技术迭代。
第一次是 OceanBase 1.0,真正实现了原生分布式架构的可读可写。第二次是 OceanBase 4.0,提出并实现了单机分布式一体化架构,用一个系统满足一个用户从小到大、全生命周期的数据存储与管理需求。
基于分布式和单机分布式的一体化架构,OceanBase 不断丰富数据库功能。包括打造一体化 SQL 引擎,全面兼容 MySQL 和 Oracle;增强对实时 AP 的支持,实现 TP+AP 一体化;打造 SQL+NoSQL 能力,增强对多数据类型的支持。
而随着 AI 技术不断深入应用,OceanBase 进一步实现 SQL+AI 的能力,支持向量检索,并能处理向量与其他数据类型的混合查询,如 GIS、关系型数据、向量数据、文档等。通过向量融合查询能力,帮助企业更轻松地将 AI 能力与数据库系统集成,简化 AI 应用技术栈,为复杂的 AI 应用提供强有力的支持。
想象一下,如果某家公司需要处理各种各样的数据任务,既要管理日常的财务记录,又要进行大数据分析来预测市场趋势,还要存储和查询各种格式的信息,如地图数据、文档报告等。以往,他们可能需要用到几种不同的数据库系统来完成这些任务,每个系统都有自己的一套规矩和工具,这不仅麻烦,而且效率不高。
而类似于一体化数据库这样的产品出现后,它就像一个超级智能助手,它能一口气搞定所有事情。这个助手不仅精通处理日常交易(TP),比如快速准确地记录每一笔收支;还擅长做数据分析(AP),比如帮公司算出哪个产品最畅销,未来市场可能会怎么变化。更重要的是,它在处理结构和非结构化数据上也游刃有余,无论是简单的文字记录、复杂的地图信息,还是各种文档报告,它都能轻松应对。
这样一来,无论是财务部门想要精确记录每一笔账目,还是市场部门想要分析大数据预测未来,或者是研发团队需要存储和查询各种格式的研发文档,都可以在同一个数据库系统上完成,大大简化了工作流程,提高了效率。这就是一体化数据库的魔力所在。
面向未来,一体化数据库大有可为
一体化数据库的出现,弥补了传统独立式数据库在处理结构化、半结构化和非结构化数据时存在的诸多局限,比如技术栈的复杂性、数据库系统运维的困难性、数据处理效率和准确性低等问题。
AI 时代,一体化数据库在多工作负载处理、多模数据处理以及向量(SQL+AI)融合等方面展现出了显著的优势。
事实上,不只是 OceanBase 在加快向一体化数据库演进的速度,放眼国际,不少全球头部数据库厂商也在积极推进向一体化数据库的演进。
Snowflake 是作为新生代的云原生数仓的主动者之一,目前已经实现了基于多个公有云架构的云上数仓服务。作为一家从数仓起家的公司,Snowflake 近年来却一直忙于拥抱数据湖,实现数据湖、数据仓库一体化,并且通过并购和与行业巨头合作的方式加速向 AI 靠拢。自 2022 年以来,Snowflake 开始布局“数据 +AI”模式,共先后并购六家相关公司并且已经与微软和英伟达等公司展开合作。
作为 NoSQL 数据库的佼佼者,MongoDB 也一直推进其一体化数据库的进程,而 MongoDB 走的路线是为开发者提供多模数据库平台。MongoDB 的 Atlas 平台不仅支持文档、键值、图和搜索等多种数据模型,还通过自动化的扩展能力和多云部署,极大地简化了企业复杂的数据架构管理。这种灵活性使得 MongoDB 在应对多样化数据需求时游刃有余。同时,MongoDB 在 SQL 与非关系型数据(如 JSON)的融合上持续优化,进一步拓宽了其应用场景。然而,MongoDB 也面临着提升混合负载处理能力的挑战,特别是在事务处理(TP)与分析处理(AP)之间的平衡上,这对其底层架构的创新提出了更高要求。
全球单机数据库领导者 Oracle 也越来越注重 AI、ML 和多模处理能力的融合。Oracle 的 Autonomous Database 不仅支持关系型、文档型、JSON、图形和向量数据等多种数据类型,还通过 HTAP(混合事务与分析处理)技术,实现了在同一平台上高效处理事务型和分析型数据的能力。这使得 Oracle 在应对复杂业务场景时表现出色。然而,随着多租户环境和复杂分析任务的增多,Oracle 也面临着资源隔离和性能优化的难题,如何保持高效的资源利用率和成本控制,成为其需要重点解决的问题。
此外,Amazon Redshift、Google BigQuery 等云数据仓库也在不断优化其一体化数据库的功能和性能,以满足用户对高效、灵活数据处理的需求。
由此可见,SQL+AI 正被越来越多数据库厂商视为重要技术演进方向,但在此过程中他们也面临着共同的挑战和难题。
具体而言,HTAP 性能优化、多模数据处理的深度融合以及 AI 与数据库的深度集成是当前一体化数据库发展面临的主要挑战。如何在混合负载下实现更加高效的资源隔离和优化 AP 与 TP 之间的调度,是提升 HTAP 性能的关键。
同时,随着数据类型的多样化和复杂化,如何进一步优化多模数据的处理性能,特别是在高并发场景下的查询性能,也是当前需要解决的问题之一。而且随着 AI 技术的快速发展,如何在一体化数据库中高效地支持 AI 模型的训练和推理,特别是在 AI 数据预处理和向量检索方面,需要进一步的架构调整与创新。
基于以上,我们有理由相信,一个由“SQL+AI”引领的一体化数据库新时代正在走来。在这个时代里,数据库将不再是简单的数据存储工具,而是成为推动业务创新与发展的重要引擎。




