1982 年 1 月 11 日,22 位计算机科学家聚在一起讨论了有关“计算机邮件”(也就是电子邮件)的问题。与会者包括创建了Sun Microsystems 公司的家伙,开发了Zork 的家伙,发明NTP 的家伙,以及说服政府需要为Unix 付费的家伙。当时他们讨论的问题其实很简单:ARPANET 上已经有455 台主机,情况似乎开始有些失控。
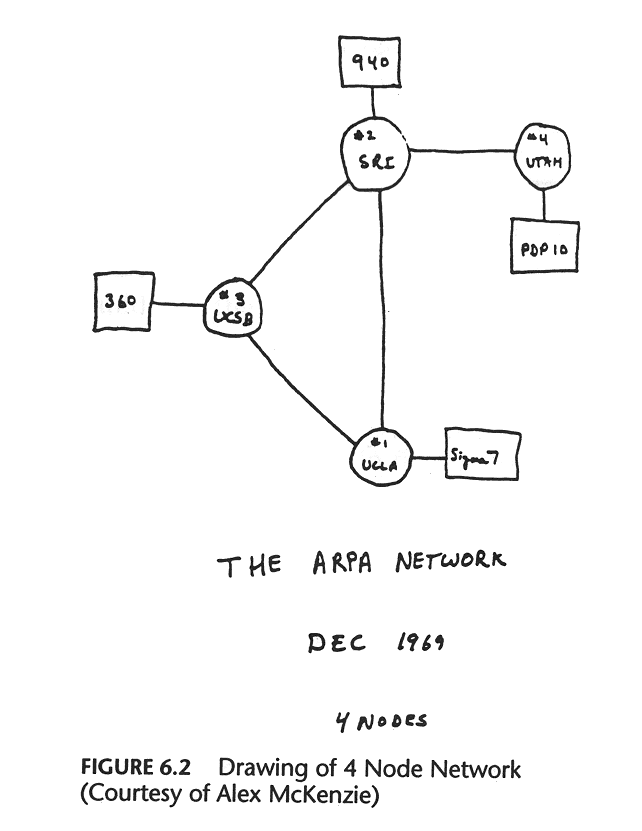
当时提到这个问题主要是因为ARPANET 即将把最初使用的 NCP 协议更换为TCP/IP 协议,我们现在熟知的互联网就是在后者基础上建立的。更换后即将出现很多相互连接的网络(莫非是传说中的“互联…网”), 需要一种“层次”更明确的域名系统,由ARPANET 解决自己的域名问题,其他网络的域名问题也由它们自己解决。
当时其他网络都使用了一些很不错的名字,例如“COMSAT”、“CHAOSNET”、“UCLNET”,以及“INTELPOSTNET”,这些网络由全美国的很多大学和公司自行维护,但他们希望能够跨网通信,并愿意为此从电话公司租用56k 带宽的线路并购买负责处理通信路由任务的 PDP-11s 设备。

http://www.saccade.com/writing/projects/PDP11/PDP-11.html
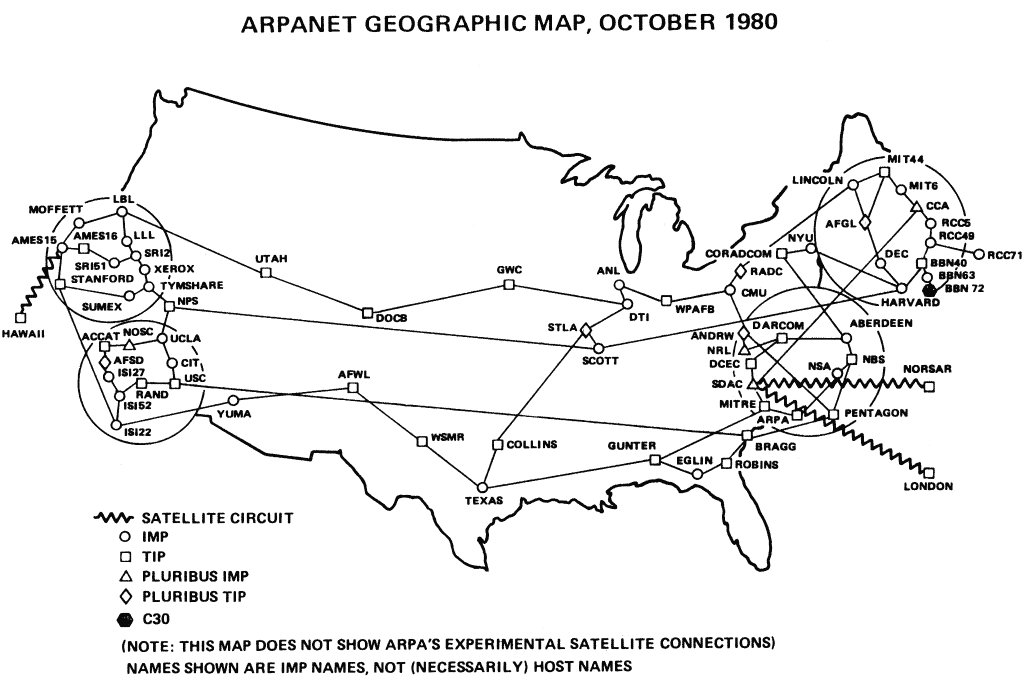
在 ARPANET 最初的设计中,由集中的网络信息中心(NIC)负责维护一份列出网络上每台主机的文件。这个文件就是 HOSTS.TXT ,与当今 Linux 或 OS X 系统中的 /etc/hosts 文件作用类似。针对网络进行的所有改动都需要由NIC 使用FTP(一种诞生于 1971 年的协议)发送给网络中的每台主机,这对他们的基础结构造成了极大的负担。
面对规模无限大的互联网,用一个文件列出互联网上的每台主机这种做法当然是不可行的。不过他们当时想解决的最大问题是电子邮件,这也是当时最大的挑战。经研究他们最终决定创建一种层次式的系统,用户可以通过这个系统查询外部系统的域名或设置自己需要的域名。换句话说:“通过对这一领域研究他们发现,目前使用类似‘user@host’这样的邮箱标识符应该扩展为‘user@host.domain’,其中‘domain’代表域名的层次结构。”就这样,域名系统诞生了。
https://personalpages.manchester.ac.uk/staff/m.dodge/cybergeography/atlas/
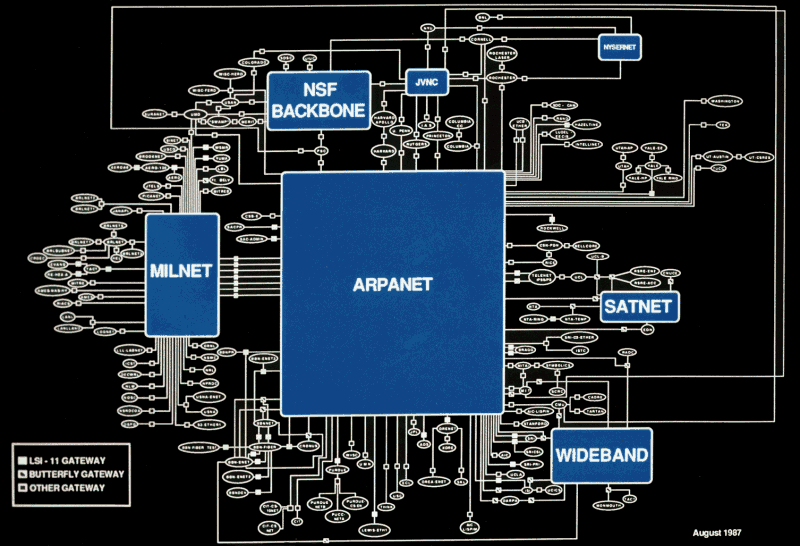
这里要打消大家一个很常见的错觉,当时的这个决定并没有预见到域名系统的未来发展。实际上他们选择这样的解决方案主要是因为,这种方案“是在现有系统基础上实现难度最小的。”例如,对于电子邮件地址有一个提议是使用“.@”的形式,如果当时电子邮件的用户名中不包含“.”字符,那么今天你可能要使用“zack.eager@io”这样的地址给我发邮件了。
https://personalpages.manchester.ac.uk/staff/m.dodge/cybergeography/atlas/
UUCP 和一路的感叹号
有种说法认为操作系统的主要功能是为相同的对象定义一系列不同名称,这样才能让操作系统自己忙于追踪所有这些不同名称之间的关系。网络协议在某种程度上似乎也有类似的特征。
– David D. Clark, 1982 年
另一个失败的提议想使用感叹号(!)分隔域名的不同组件。例如为了联系ARPANET 上的ISIA 主机就需要连接到!ARPA!ISIA,随后可以使用通配符查询主机,例如查询!ARPA!* 可以看到ARPANET 上的每台主机。
这种寻址方法与目前使用的标准方法相差并不太多,只是维护方面所做的一次尝试。这种使用感叹号的体系会使用1976 年发明的一种名为 UUCP 的数据传输工具传播有关主机的数据。如果使用 OS X 或 Linux 计算机阅读这篇文章,你也许依然可以在终端中使用 uucp。
诞生于 1969 年的 ARPANET 很快就变成一个强大的通信工具… 很多大学和政府机构都可以访问。而我们今天所熟知的互联网在这之后过了 21 年,才在 1991 年被研究机构以外的普通公众所了解。其实在这之前不同计算机用户之间早已可以通信了。

在互联网诞生前的时代里,计算机之间最常见的通信方式是使用直接点对点拨号连接。举例来说,如果你想给我发送一个文件,需要用你的调制解调器呼叫我的调制解调器,随后就能传输文件了。为了将这种方式形成某种形式的网络,人们发明了 UUCP。
在 UUCP 系统中,每台计算机上都用一个文件列出了自己所知道的主机,以及对方的电话号码和主机上的用户名与密码。随后即可借助多台知道该如何与周围主机建立联系的主机,从自己的计算机建立到目标计算机的“通路”:
sw-hosts!digital-lobby!zack

这个地址不仅提供了向我发送文件或直接连接我计算机的方法,而且可以用作我的电子邮件地址。在“邮件服务器”诞生之前,如果我的计算机关机了你将无法给我发送邮件。
虽然当时 ARPANET 只能被最顶尖的大学使用,但 UUCP 实际上为普通人建立了一个私下的互联网。随后 UUCP 也成为新闻组和 BBS 系统的基础。
DNS
最终,我们直到今天还在使用的 DNS 系统是在 1983 年提出的。今天在进行 DNS 查询时,例如使用 dig 工具查询,你可能会看到类似下面这样的回应:
;; ANSWER SECTION:
google.com. 299 IN A 172.217.4.206
这些信息是在告诉我们 google.com 可以通过 172.217.4.206 访问。你可能已经知道,A 是指这是一条将域名映射到相应 IPv4 地址的“地址(Address)”记录。299 是“存活时间”,可以告诉我们这条记录的有效时间还剩多少秒,过期后需要重新进行查询。但 IN 是什么意思?
IN 代表“Internet”。类似这样的字段可以追溯至有多种相互竞争的计算机网络需要交互的时代。其他类似的字段还有代表 CHAOSNET 的 CH,以及代表 Athena system 所提供的名称服务 Hesiod 的 HS。CHAOSNET 早已关闭,但目前 MIT 的很多学生还在使用改进版的 Athena。IANA 网站列出了完整的 DNS 类清单,不过毫无疑问只有一个值在今天依然被广泛使用。
顶级域名
已经完全不可能再需要创建其他顶级域名了。
— John Postel, 1994 年
当上文提到的那些牛人们决定应该让域名带有层次结构后,还需要决定这种层次结构的“根”是什么。这个根通常是使用一个“.”代表的。实际上让所有域名以“.”结尾从语义上来说是正确的,并且浏览器绝对支持这种做法: google.com. 。
世界上出现的第一个顶级域名(TLD)是.arpa,用户可以借助这个顶级域名在过渡期内对传统的 ARPANET 主机名进行寻址。举例来说,如果我的计算机之前曾注册为 hfnet,那么我的新地址就是 hfnet.arpa。但这只是暂时的,在过渡期内服务器管理员需要做一个重要的选择:共五个顶级域名,自己到底要用哪个?“.com”、“.gov”、“.org”、“.edu”,还是“.mil”?
之前说 DNS 有层次结构时,实际是指需要用到一系列根 DNS 服务器并让它们承担重要的任务,例如将.com 指向.com 名称服务器,由后者负责告诉用户如何到达 google.com。互联网的根 DNS 区域由 13 个 DNS 服务器集群组成,一共只有 13 个服务器集群,因为这是一个 UDP 数据包可以容纳的上限。在历史上 DNS 是通过 UDP 数据包运作的,这意味着请求的回应不能超过 512 字节。
; This file holds the information on root name servers needed to
; initialize cache of Internet domain name servers
; (e.g. reference this file in the "cache . "
; configuration file of BIND domain name servers).
;
; This file is made available by InterNIC
; under anonymous FTP as
; file /domain/named.cache
; on server FTP.INTERNIC.NET
; -OR- RS.INTERNIC.NET
;
; last update: March 23, 2016
; related version of root zone: 2016032301
;
; formerly NS.INTERNIC.NET
;
. 3600000 NS A.ROOT-SERVERS.NET.
A.ROOT-SERVERS.NET. 3600000 A 198.41.0.4
A.ROOT-SERVERS.NET. 3600000 AAAA 2001:503:ba3e::2:30
;
; FORMERLY NS1.ISI.EDU
;
. 3600000 NS B.ROOT-SERVERS.NET.
B.ROOT-SERVERS.NET. 3600000 A 192.228.79.201
B.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:84::b
;
; FORMERLY C.PSI.NET
;
. 3600000 NS C.ROOT-SERVERS.NET.
C.ROOT-SERVERS.NET. 3600000 A 192.33.4.12
C.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:2::c
;
; FORMERLY TERP.UMD.EDU
;
. 3600000 NS D.ROOT-SERVERS.NET.
D.ROOT-SERVERS.NET. 3600000 A 199.7.91.13
D.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:2d::d
;
; FORMERLY NS.NASA.GOV
;
. 3600000 NS E.ROOT-SERVERS.NET.
E.ROOT-SERVERS.NET. 3600000 A 192.203.230.10
;
; FORMERLY NS.ISC.ORG
;
. 3600000 NS F.ROOT-SERVERS.NET.
F.ROOT-SERVERS.NET. 3600000 A 192.5.5.241
F.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:2f::f
;
; FORMERLY NS.NIC.DDN.MIL
;
. 3600000 NS G.ROOT-SERVERS.NET.
G.ROOT-SERVERS.NET. 3600000 A 192.112.36.4
;
; FORMERLY AOS.ARL.ARMY.MIL
;
. 3600000 NS H.ROOT-SERVERS.NET.
H.ROOT-SERVERS.NET. 3600000 A 198.97.190.53
H.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:1::53
;
; FORMERLY NIC.NORDU.NET
;
. 3600000 NS I.ROOT-SERVERS.NET.
I.ROOT-SERVERS.NET. 3600000 A 192.36.148.17
I.ROOT-SERVERS.NET. 3600000 AAAA 2001:7fe::53
;
; OPERATED BY VERISIGN, INC.
;
. 3600000 NS J.ROOT-SERVERS.NET.
J.ROOT-SERVERS.NET. 3600000 A 192.58.128.30
J.ROOT-SERVERS.NET. 3600000 AAAA 2001:503:c27::2:30
;
; OPERATED BY RIPE NCC
;
. 3600000 NS K.ROOT-SERVERS.NET.
K.ROOT-SERVERS.NET. 3600000 A 193.0.14.129
K.ROOT-SERVERS.NET. 3600000 AAAA 2001:7fd::1
;
; OPERATED BY ICANN
;
. 3600000 NS L.ROOT-SERVERS.NET.
L.ROOT-SERVERS.NET. 3600000 A 199.7.83.42
L.ROOT-SERVERS.NET. 3600000 AAAA 2001:500:9f::42
;
; OPERATED BY WIDE
;
. 3600000 NS M.ROOT-SERVERS.NET.
M.ROOT-SERVERS.NET. 3600000 A 202.12.27.33
M.ROOT-SERVERS.NET. 3600000 AAAA 2001:dc3::35
; End of file
根 DNS 服务器放置在上锁机柜中的保险箱里,保险箱上还放置了一个表,这是为了确保监控视频不被篡改并循环播放。尤其是考虑到 DNSSEC 的实施实在是进展缓慢,对这些服务器中的任何一台进行攻击都会使得攻击者对全部或部分互联网用户的流量进行重定向。这些措施确保了最天马行空的高科技犯罪电影也未曾“染指”根 DNS 服务器。
可想而知,顶级 TLD 的名称服务器实际上并不需要经常更改。根 DNS 服务器收到的所有请求中有 98% 是错误导致的,大部分源自未能对结果进行恰当缓存的有故障或瑕疵的客户端。这种情况造成的后果越来越严重,以至于很多根 DNS 的运营人员计划逐渐部署多台特殊的服务器,这些服务器的作用仅仅是跟想要对本地IP 地址进行反向DNS 查询的人说一句话:“走开”。
TLD 名称服务器由全球不同公司和政府部门管理( Verisign 负责管理.com)。每次你购买.com域名时,其中约有 0.18 美元会付给 ICANN,另外 7.85 美元会付给 Verisign。
Punycode
现实中我们开发者为新项目想的那些愚蠢的名字很少会直接用于最终公开发布的产品。我们可能会将公司使用的数据库命名为 Delaware(因为所有公司都是在这里注册的),但几乎可以确定的是,在用于生产环境时肯定会使用类似 CompanyMetadataDatastore 这样的名字。但是机缘巧合的情况下,天上星星排成排,老板外出度假时,疏忽就这么不经意地产生了。
Punycode 系统可供我们将 Unicode 字符编码为域名。这套系统所解决的问题很简单:如果整个互联系统都是围绕 ASCII 字母表建立的,其中大部分外文字符都是腭化符号(例如Ñ),你该怎样写出“比薩.com”?
这个问题并不是简单地将域名切换为使用 Unicode 就能解决的。决定域名系统规范的原始文档明确要求域名要使用ASCII 编码,过去四十年来生产的所有网络硬件,包括在你查看本页过程中为你提供服务的 Cisco 和 Juniper 路由器都是基于这一规范生产的。
网络本身从不是只允许使用ASCII 的。其实最开始网络讲的是 ISO 8859-1 语言,其中不仅包含所有 ASCII 字符,而且额外增加了一些特殊字符,例如“¼”和带有特殊标记的字母,例如“ä”。然而其中并不包含任何非拉丁语系的字符。
HTML 中有关这个问题的限制最终于 2007 年取消,同年 Unicode成为网络上最受欢迎的字符集。但域名依然只能使用ASCII。
http://www.alanwood.net/unicode/
你可能会猜到 Punycode 最初的提议并非为了解决这个问题。其实你可能听说过 UTF-8,这是一种将 Unicode 编码为字节的主要方式(名称中的“8”代表一个字节中包含的 8 个比特)。 2000 年,互联网工程任务组的多个成员提出了 UTF-5,他们的想法在于将 Unicode 编码为五比特的块。随后将每五比特映射为可以在域名中使用的字符(A-V 和 0-9)。那么如果我建立了一个学习日语的网站,我的网站“日本語.com”会将域名显示为“M5E5M72COA9E.com”。
这种编码方式有很多局限。例如 A-V 和 0-9 会显示在编码后的输出结果中,这意味着如果你想要真正在自己的域名中包含上述任何一个字符,依然需要将这个字符像其他内容一样进行编码。这就使得十分长的域名会遇到一个严重的问题,域名的每个片段最多只能使用 63 个字符。缅甸文的域名最多将只能使用 15 个字符。不过这个提议依然给出了一个有趣的建议,通过 UTF-5 使得 Unicode 能借助摩斯电码或电报传输。
另外还有个问题需要考虑:如何让客户端知道这个域名是编码后的,这样客户端才能用相应的 Unicode 字符在地址栏显示域名,而不是显示为类似“M5E5M72COA9E.com”这样。对于这个问题曾经有多个建议,建议之一是在DNS 的回应中使用未使用的“位”。当时“回应报头只剩下最后一个未使用的‘位’”,然而负责DNS 的那帮人“对于放弃这个‘位’显得非常犹豫”。
另一个建议是让所有域名使用ra–打头的编码方法。在当时(2000 年4 月中旬)没有任何域名是恰好以这个特殊字符打头的。而我恰恰就知道在这个提议刚刚发布后,立刻有人蓄意注册了一个ra–域名。
2003 年终于有了最终定论,大家决定采用一种名为Punycode 的格式,在这种格式中通过一种形式的差值压缩(Delta compression)大幅缩短编码后的域名。差值压缩是个很棒的想法,因为巧就巧在域名中的所有字符都位于Unicode 的通用区域内。例如,波斯文中的两个字符要比一个波斯文字符和一个印度语字符更为接近。这到底是怎么回事?我们用一个无意义的词组来看看:
يذؽ
在未压缩的格式中,上述词组会保存为三个字符[1610, 1584, 1597](基于它们的Unicode 码点)。要压缩这串词组,首先需要按照数值对其排序(同时记录原始字符的位置)并获得:[1584, 1597, 1610]。随后存储最小值(1584),以及这个值与下一个字符的差值(13),并继续存储与下一个值的差值(23),这样需要传输和存储的内容就少很多了。
随后Punycode 会用(非常)高效的方式将这些整数编码为域名中可以使用的字符,并在开头处插入一个xn–,借此让客户知道这是个编码后的域名。你会发现所有Unicode 字符会一起显示在域名末尾。Punycode 不仅会编码相应的值,而且会对要插入到域名ASCII 部分的位置进行编码。例如“熱狗sales.com”这个网站会变成xn–sales-r65lm0e.com。在浏览器的地址栏输入基于Unicode 的域名都会这样编码。
上述转换过程应该是透明的,但这样会造成一个重要的安全问题。所有类型的Unicode 字符打印出来会与现有ASCII 字符完全相同。例如你可能看不出西里尔文小写字母a(“а”)与拉丁文小写字母a(“a”)之间的区别。如果我注册了西里尔文的аmazon.com(xn–mazon-3ve.com)并骗你访问,你很难知道自己访问了错误的网站。因此当你访问 x.ws 时,浏览器反而会在地址栏显示 xn–vi8hiv.ws。
协议
URL 中显示的第一部分内容是访问所用的协议。最常见的协议是 http,Tim Berners-Lee 发明的这种简单文档传输协议驱动着今天的整个互联网。但可用协议不光这一个。一些人认为我们应该只使用 Gopher。除了常规用途外,Gopher 明确针对类似于文件树结构的结构化数据传输进行了考虑。
举例来说,如果请求 /Cars 端点,可能返回下列内容:
1Chevy Camaro /Archives/cars/cc gopher.cars.com 70
iThe Camero is a classic fake (NULL) 0
iAmerican Muscle car fake (NULL) 0
1Ferrari 451 /Factbook/ferrari/451 gopher.ferrari.net 70
从中可以看出有两辆车,此外还有一些有关车的元数据以及访问哪里可以了解更详细信息。随后客户端需要将这些信息解析为更易用的形式,并将不同条目与目标页面链接在一起。

http://www.yale.edu/pclt/WINWORLD/GOPHER.HTM
诞生于 1971 年的 FTP 是第一个广受欢迎的协议,该协议可以列出并下载远程计算机上的文件。Gopher 是该协议的一种逻辑扩展,可以提供类似的列表功能并读取不同条目的元数据。这意味着可以将 Gopher 用于更广泛的用途,例如新闻源或简单的数据库。然而在自由度和简单程度上不如 HTTP 和 HTML 出色。
HTTP 是一种非常简单的协议,相比其他类似协议,例如 FTP 甚至最近逐渐开始流行的 HTTP/2 协议依然显得非常简单。首先,HTTP 是完全基于文本的,不包含任何定制的二进制内容(因此显得更为高效)。Tim Berners-Lee 准确地察觉到使用基于文本的格式可以让一代代程序员更容易地开发和调试基于 HTTP 的应用程序。
HTTP 几乎完全无需考虑你要传输的内容是什么。尽管在发明之初这个协议就是明确用于处理 HTML 语言的,但你可以为自己的内容指定任何类型(使用 MIME Content-Type,在当时这也是个新发明)。这个协议本身也相当简单:
下面这样的请求:
GET /index.html HTTP/1.1
Host: www.example.com
可以得到下列回应:
HTTP/1.1 200 OK
Date: Mon, 23 May 2005 22:38:34 GMT
Content-Type: text/html; charset=UTF-8
Content-Encoding: UTF-8
Content-Length: 138
Last-Modified: Wed, 08 Jan 2003 23:11:55 GMT
Server: Apache/1.3.3.7 (Unix) (Red-Hat/Linux)
ETag: "3f80f-1b6-3e1cb03b"
Accept-Ranges: bytes
Connection: close
<html>
<head>
<title>An Example Page</title>
</head>
<body>
Hello World, this is a very simple HTML document.
</body>
</html>
如果想要更形象地理解,可以将互联网所用网络系统的起点想做是 IP(Internet 协议)。IP 负责在不同计算机之间搬运小数据包(每个数据包大约 1500 字节)。在这之上是 TCP,负责搬运更大的数据块,例如整个文档和文件,并通过很多 IP 数据包以可靠的方式发送。在这之上我们实施了诸如 HTTP 或 FTP 等协议,这些协议决定了在通过 TCP(或 UDP 等)协议发送数据时所要使用的格式。就这么简单好理解。
换句话说,TCP/IP 只负责将一整批字节发送给其他计算机,由协议决定这些字节是什么,有什么含义。
如果愿意你也可以开发自己的协议,按照自己喜欢的方法将字节装配成你自己的 TCP 消息。但唯一需要注意的是任何你希望与之联系的人必须说和你一样的语言。因此这些协议有必要实现标准化。
当然还有很多不那么重要的协议可以使用。例如有 Quote of The Day 协议(17 端口),有 Random Characters 协议(19 端口)。这些协议今天看起来似乎有些好笑,但也证明了像 HTTP 这样常规用途文档传输格式的重要性。
端口
Gopher 和 HTTP 的时间先后也可以从它们各自的默认端口号看出来。Gopher 是 70,HTTP 是 80。HTTP 端口是在接到 Tim Berners-Lee 在 1990 年和 1992 年之间某个时间提出的请求后分配的(很可能是由 IANA 的 Jon Postel 负责分配)。
这种“注册端口号”的概念诞生时间甚至早于互联网。在最初用于驱动 ARPANET 的 NCP 协议中,远程地址是通过 40 比特数值识别的。其中前 32 比特用于确定远程主机,这一点类似于目前的 IP 地址。后面 8 比特则是 AEN (代表“Another Eight-bit Number”),远程计算机将其用于类似今天端口号的作用,借此可以区分发给不同进程的信息。换句话说,地址决定了信息要发给哪台计算机,AEN(或端口号)可以告诉远程计算机要将这条信息交给哪个应用程序。
为了限制可能产生的冲突,他们很快就要求用户注册这些“套接字(Socket)编号”。当 TCP/IP 将端口号扩展为 16 比特之后依然需要进行这这样的注册。
虽然每个协议都有默认端口,但为了方便本地开发和在同一台计算机上托管多个服务,依然有必要允许用户手工指定要使用的端口。给网站使用 www. 前缀的基本依据也是基于相同的逻辑。当时几乎没有人可以访问自己域名的根,只能托管“实验性”的网站。但如果你告诉别人自己某一计算机的主机名(例如 dx3.cern.ch),如果要更换计算机将会造成不小的麻烦。通过使用通用子域(例如 www.cern.ch),就可以在需要时更改该子域指向的计算机。
中间那个比特
你可能知道,URL 语法需要在协议和 URL 的其他内容之间放置一个双斜线(//):
http://eager.io
这个双斜线继承自 Apollo 计算机系统,该系统曾是全球首个联网的工作站。Apollo 团队遇到了一个与 Tim Berners-Lee 类似的问题:他们需要通过某种方法将路径和路径所在计算机区分开。他们的解决方案是创建了一个特殊的路径格式:
//computername/file/path/as/usual
TBL 也沿用了这样的做法。顺便说一下,现在他对于这个决定非常后悔,希望域名(例如 example.com)能够成为路径的第一部分内容:
http:com/example/foo/bar/baz
后续
本文介绍了帮你连接到互联网上某个远程服务器上的应用程序时所使用的 URL 及其组成元素。这一系列的第二篇,并且是最后一篇文章准备介绍 URL 中的这些元素是如何被远程应用程序处理,并将特定的内容、路径、片段、查询,以及身份验证的结果返回给你。
我很希望用一篇文章清楚地介绍所有这些内容,但太长篇幅的内容很容易吓退读者。不过第二篇内容依然值得一读,将介绍很多内容,例如 Tim Berners-Lee 为 URL 考虑过的备用方案,表单的历史和 GET 参数语法的制定过程,以及针对如何确保 URL 不会变化所进行的长达十五年的争议。
阅读英文原文: The History of the URL: Domain, Protocol, and Port
感谢陈兴璐对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




