现如今, NoSQL 数据库与关系型数据库往往并存于企业的数据架构中。但是在 NoSQL 的数据管理方面,还缺乏像管理关系型数据那样成熟的方法与工具。
当前流行的 NoSQL 数据库在设计时更多地考虑了应用程序的性能,而较少考虑到高层业务模型、数据的集成以及数据的标准化。对于 NoSQL 数据库来说,其数据建模与物理数据之间存在着一条明显的鸿沟。
在本文中,我将介绍一种利用统一数据建模技术管理 NoSQL 与关系型数据库的方案。统一数据建模支持多种特性,例如为 NoSQL 数据库的模式生成文档,以及对现有数据库中的数据进行反向工程。它同时也支持对现有数据库的可视化表现。
随着数据在 4 个方面的增长(数据量、多样性、速度以及值),数据的管理方式也发生了转变,从纵向扩展变为横向扩展,通过几十万台小型的服务器创建分布式计算应用,以取代单一的强大机器。为了支持分布式计算的需求,数据也必须转换为一种不同的模型。
当前的关系型数据库都支持第 3 范式。对于 ACID(原子性、一致性、隔离性与持久性)事务模型,如果一份数据在数据库中只拥有一个拷贝,那么更适合使用关系型数据库。这意味着任一时间内只有一份拷贝会更新。但对于来自多个不同应用的查询,数据必须进行聚合。因此,为了满足业务需求,数据必须进行分布式处理,而数据模式也必须进行反范式化。在设计模式时,必须允许进行分布式的查询,这就需要处于不同数据节点上的每个数据集必须包含足够的信息,能够独立地执行查询。
基于以上特征可知,创建 NoSQL 数据库时的基本要点在于通过逻辑模型描述业务需求,并通过反范式化的模式对应实际的数据模型。而不是在没有数据建模的情况下直接从程序向 NoSQL 数据库中写入数据。
此外,由于数据的多样性将进一步提高,因此在灵活性方面要能够匹配数据的原生格式,使其能够保存在文档、图形或键值数据库中。在敏捷的业务场景中,数据的结构也将产生改变。但预定义的强模式将受到这种业务场景的限制。在关系型数据库中,对现有数据列的更改或是新建数据列操作将造成数据表的重建,但对于NoSQL 数据库来说,添加新的属性或组合对象操作都非常灵活。
另一方面,在NoSQL 中写入数据前也无需强制使用预定义的模式。而在读取数据时,模式的应用表现为用户以原始形态加载数据,在读取后就可以按需求随意变换。对于数据的读取与理解来说,模式是必需的,但这对于使用Map Reduce 程序,而又并非开发人员的使用者来说是一个不小的挑战,因为模式在Map Reduce 程序中是隐含的,因此大多数DBA 与数据分析师无法访问与理解这些模式。正因为如此,数据建模就成为了更好地理解企业数据的关键因素。
此外,与传统的批量数据集相比,流数据的处理又提出了不同的要求(实时性,只增性等等)。为了支持多个并发式数据处理系统的需求,数据本身或许还要进行某种形式的转换。在数据分析过程中,数据模型能够帮助用户理解数据,并调整数据结构。根据数据模型的设计,数据集成系统能够从原始的流数据中萃取出维度数据,并导入数据仓库中。
因此,为了让基于RDBMS 与NoSQL 数据库的数据架构满足业务上的需求,数据模型扮演了关键的角色。
RDBMS 中的 ACID(原子性、一致性、隔离性和持久性)特性是数据库方面最重要的一种需求,这种重要性在今后也将继续。而在未来,RDBMS 与 NoSQL 的混合使用将成为企业架构中的一种典型场景。Unified Modelset(统一模型)将用于描述 RDBMS 与 NoSQL 数据库的数据模式。
以下是 RDBMS 与 NoSQL 数据库之间区别的简单总结。
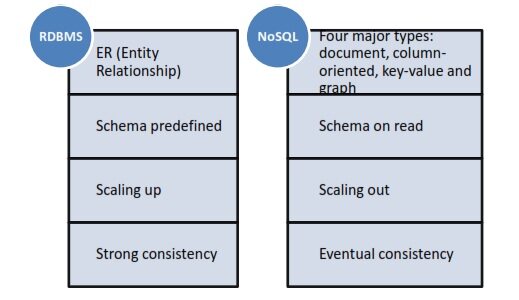
图 1,RDBMS 与 NoSQL 数据库的区别
要在不同的业务场景中管理关系型与 NoSQL 数据库的区别,并充分利用他们的功能,这是一个极大的挑战。因此,我们需要一种统一的方式以管理这些数据库。
CA ERwin Unified Data Modeler 支持对 RDBMS 与两种主流的 NoSQL 数据类型(文档数据库及列族数据库)进行数据建模。它还支持数据发现以及 RDBMS 与 NoSQL 数据库之间的数据迁移。
通过 Unified Modelset 管理 RDBMS 与 NoSQL 数据的方法
Unified Modelset 为业务需求及实际数据模式的文档化提供了一个良好的方案,并且能够管理 RDBMS 与 NoSQL 数据库中的数据。
通过概念 / 逻辑模型描述业务需求的表示法
- 概念 / 逻辑模型的表示法包括:
- 实体(Entity)
- 属性(Properties)
- 关系(Relationship)
- 标签(Tags)
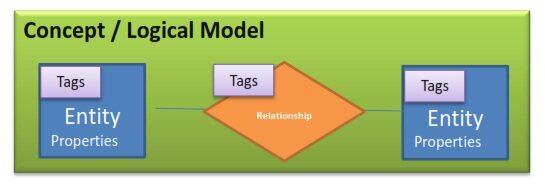
图 2,概念 / 逻辑模型的定义
逻辑、RDBMS 与 NoSQL 数据模型基本概念的对照
概念 / 逻辑 RDBMS NoSQL 实体 表 集合或列族 实体的实例 行 文档或行 属性 列 键或列 某个实体实例的属性 单元格的值 字段值 领域 数据类型 数据类型(某些 NoSQL 数据库没有定义数据类型,所有的值都是纯文本。) 关系 约束 引用、嵌入或附加表 / 跨多个行的列族。 键 索引 索引、附加表或引用 唯一标识符 主键 行键### 统一建模过程
业务概念与需求可以由逻辑模型进行描述,而后者又可以转换为目标物理模型。转换过程取决于在逻辑模型中描述的查询模式和数据生成模式。转换规则已预定义为模式转换策略,具体会影响到哪种策略决定于描述查询模式和数据生成模式的标签。这些标签与规则都可以由用户进行修改和自定义。在该过程的最后,原始数据将按照所设计的物理模型进行格式化,并以正向工程的方式迁移至数据库中。
使用 Unified Modelset 的业务场景:
- 对 RDBMS 与 NoSQL 的数据模式进行文档化,并支持对现有数据库的反向工程。
- 根据所设计的 Unified Modelset,在不同的数据库之间进行数据迁移(正向工程)。并且支持基于 Unified Modelset 对现有的数据库进行重构。
- 从头开始创建 Unified Modelset,生成新的物理模型并绑定到数据库,并将模型封装为 UDBC 数据源。管理 UDBC 的读写数据操作。
- 为生产环境中的数据库创建数据仓库,与场景 2 相类似。从现有的数据库中进行反向工程,设计数据仓库的物理模型,迁移数据以完成数据仓库的构建。
以下是为某个电影资料库所设计的数据库示例,业务需求如下所示:
- 一部电影可以由多位演员出演,一部电影可以属于多个不同的分类。
- 一位演员可以出演多部电影。
- 一个分类可以包括多部电影。
在概念 / 逻辑模型中,可以辨别出以下实体及关系:
- 实体 —— 角色(Actor)、分类(Category)和电影(Film)
- 关系 —— (角色 - 电影,多对多);(电影 - 分类,多对多)
图 3 是一个由 ER 图所描述的电影资料系统的逻辑模型图,而图 4 则是由 ER 图所描述的物理 RDBMS 模型图。
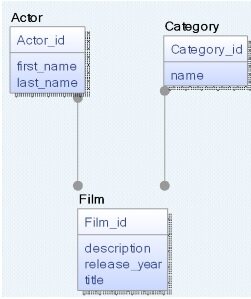
图 3,以传统 ER 图表现的逻辑模型
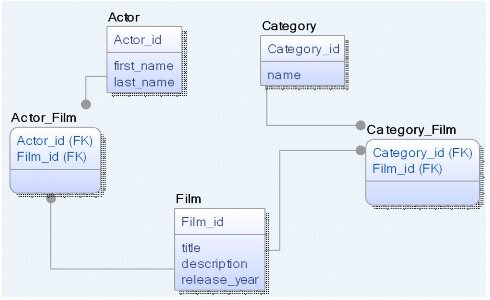
图 4,以传统 ER 图表现的 RDBMS 物理模型
不过,现有的 ER 图并不足以对 NoSQL 数据进行描述。因此,我们创建了 Unified Modelset,以支持对于 RDBMS 与 NoSQL 的数据建模工作。它能够对业务模型、查询模式与数据生成模式进行描述。该模型由一个逻辑模型及多个物理模型组成。
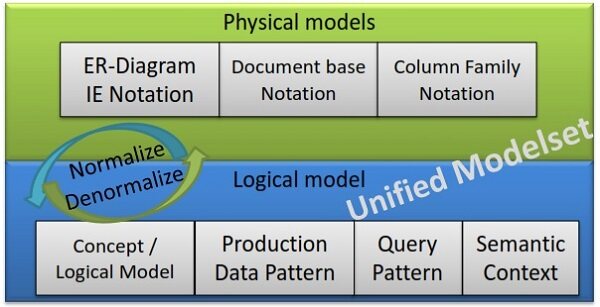
图 5,Unified Modelset 定义
图 6 是上文所述的电影资料库这一示例的逻辑模型,在实体与属性中还附加了一些标签,以描述数据的查询模式与生成模式。
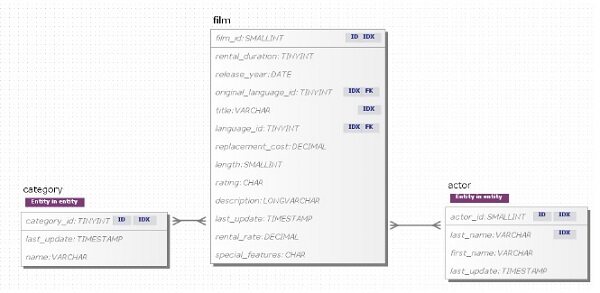
图 6,使用 Unified Modelset 表示法表现的逻辑模型
文档数据库物理模型在 Unified Modelset 中的表示法
在 MongoDB 或 Couchbase 这种文档型数据库中,与数据库对象相关的一切都被封装为一个文档对象。
- 集合对应着实体
- 嵌套文档对应着实体
- 文档的嵌套对应着嵌套文档与父文档之间的关系
- 数组对应着一对多的关系
- 引用对应着关系
图 7 是文档型数据库的物理模型图。它的表示法表现出了真实的数据结构(文档与嵌套文档)。图 8 展现了对应 MongoDB 所设计的模型中的真实数据,例如 Actor 和 Category 文档就嵌套在 Film 文档中。

图 7,基于文档的物理模型
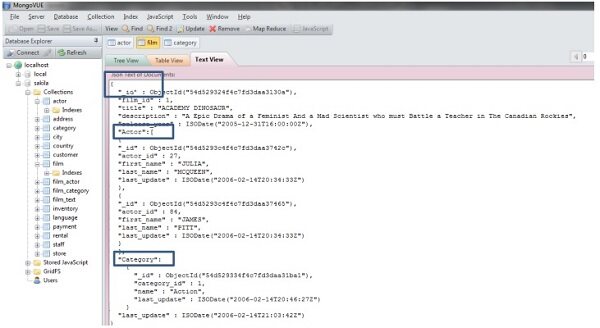
图 8,对应 MongoDB 所设计的模型中的实际数据
列族数据库物理模型在 Unified Modelset 中的表示法
列族数据库也是 NoSQL 数据库中的一种,它以列的形式描述了相关的数据。可以理解为在一个元组(对)中包含了一个键值对,其中每个键都映射到一个值,而这个值是由列的集合所组成的。
- 列族(CF)对应着实体
- 表对应着实体,它与父列族所对应的实体之间存在着关系
- 列修饰符(qualifier)对应着属性或索引(标签)
- 跨多个列族的一行对应着跨多个实体的关系
图 9 是上文所述的电影资料库这一示例的物理模型图。
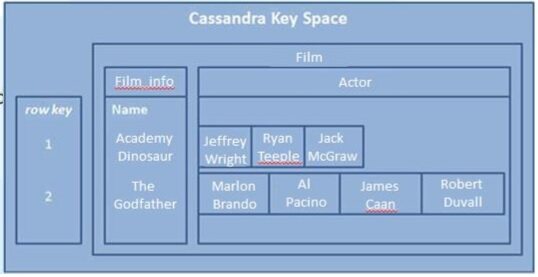
图 9,列族数据库物理模型
Unified Modelset 中的查询模式
查询模式对于 NoSQL 数据建模来说至关重要。如何将逻辑模型反范式化为物理模型取决于数据的查询方式。因此必须在数据模型中描述查询模式,而在数据模型中经常对多个实体一起进行查询。这些实体需要在 NoSQL 物理数据存储引擎中进行聚合。
- 聚合,聚合数据是指组合了多种度量了数据。当数据被聚合之后,所观察到的数据组将按照观察的方式被转换为汇总统计结果。它能够对实体进行描述。
- 一对一,这是一种描述关系的方式。数据库表中的每一行将对应,并且仅对应另一张表中的一行。它表现了 RDBMS 中的外键(FK)约束。在文档数据库中,相关的行可以嵌套在对应表的文档,或是同一张表的其他文档中。
- 一对多,也是一种描述关系的方式。数据库表中的每一行都可对应关联表中的多个行。比方说,一位母亲可以有多个孩子,但每个孩子只能有一位母亲。它表现了 RDBMS 中的外键(FK)约束。它可以嵌入在对应表的文档中。
- 多对多,描述关系的另一种方式。数据库表中的一行或多行可以对应关联表中的 0 行、1 行或多行。比方说,一段视频可以被多位客户租用,而一位客户也可以租用多段视频。它表现了 RDBMS 中的附加表。在文档数据库中,这种关系可以表现为在对应文档,或是在额外的文档中所建立的引用。
- 频繁的查询,描述关系的另一种方式。在频繁的查询中,应尽可能将相关的实体聚合在一起,成为一个单一的组合实体。在物理数据库中最好能够为其创建索引。
Unified Modelset 中的生产环境数据模式
生产数据模式是用于描述数据库在生产环境中的物理特征的一种方式。
- 大数据量(Big Volume),用于描述实体,包括那些包含大量记录的实体。因此,最好能够设计一种聚合的实体。
- 强一致性与最终一致性,用于描述实体。可用于进行数据转换的校验。如果某个实体是“强一致性”的,那么应避免将其嵌入其他实体,并且避免分发。
- 只读 / 附加 / 更新,用于描述实体。经常会更新的数据应避免将其嵌入其他实体,因为对分布式的实体进行更新可能会导致对大规模的数据加锁。而“只读”或“附加”实体可以任意选择是否要嵌入其他实体。
Unified Modeler 中的模式推断
由于 NoSQL 数据库不支持模式,因此数据模式必须从原始数据中进行推断,而不是直接从 RDBMS 等数据库中直接抽取出来。模式推断的方法有以下几种:
- 记录统计的模式涵盖,包含以下查询的统计:
- 数据库中的所有记录
- 前 N 条记录
- 全部记录中的某个百分比
- 经过 N 层递归的记录
- 机器学习、收集 UI 的反馈信息、分类的维度生成、以及对于模式推断过程的准确度进行持续的改进。
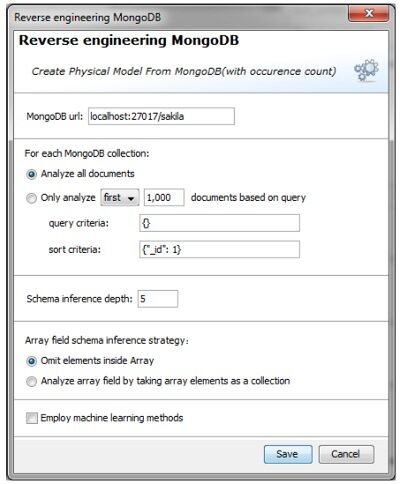
图 10,在 Unified Modeler 中对 MongoDB 数据库进行反向工程
Unified Modeler 中的 UDBC(统一数据库连接)
我们现在已经可以用 Unified Modelset 描述企业数据架构,包括逻辑模型中的业务需求以及物理模型中的数据模式了,现在我们要进一步扩展其能力,基于数据模型实现数据发现。UDBC(统一数据库连接)为我们提供了一种接口,以描述基于 Unified Modeler 的外部企业数据。
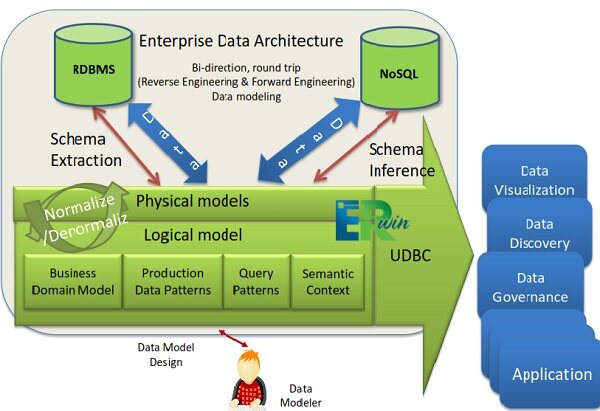
图 11,UDBC(统一数据库连接)架构
关于作者
 王峥(Allen Wang)是来自CA technologies 公司ERwin 研发团队的总监,负责ERwin 在全球范围内的研发以及ERwin Unified Modeler 产品的管理。他领导团队成功地发布了自8.0 开始的8 个重要版本。他还是工业标准委员会OMG 与DAMA 的成员。他策划和建立了CA 与清华大学合作的大数据研究项目,致力于帮助产品进入新兴市场,专注于企业中复杂的大数据环境,通过统一模型与数据挖掘等技术管理数据。他还提交了5 个关于数据建模与NoSQL 方面的专利。此外,他还是复旦大学的客座教授,开办了大数据方面的硕士研究生课程。本文的顺利发布还要感谢ERwin 开发团队的贡献与Xiaoyuan Yuan 的编辑。
王峥(Allen Wang)是来自CA technologies 公司ERwin 研发团队的总监,负责ERwin 在全球范围内的研发以及ERwin Unified Modeler 产品的管理。他领导团队成功地发布了自8.0 开始的8 个重要版本。他还是工业标准委员会OMG 与DAMA 的成员。他策划和建立了CA 与清华大学合作的大数据研究项目,致力于帮助产品进入新兴市场,专注于企业中复杂的大数据环境,通过统一模型与数据挖掘等技术管理数据。他还提交了5 个关于数据建模与NoSQL 方面的专利。此外,他还是复旦大学的客座教授,开办了大数据方面的硕士研究生课程。本文的顺利发布还要感谢ERwin 开发团队的贡献与Xiaoyuan Yuan 的编辑。
查看英文原文: Unified Data Modeling for Relational and NoSQL Databases




