
最近,微软发布了 Logic Apps Standard 内置的文档解析和分块操作的公开预览版。这些操作旨在简化生成式 AI 应用基于 RAG 的摄取。借助这些操作,该公司进一步增强了其低代码产品的人工智能功能。
按照微软的说法,通过这些开箱即用的操作,开发人员可以轻松地将文档或文件(包括结构化和非结构化的数据)摄取到 AI Search 中,而无需编写或管理任何代码。新增的 Data Operations 操作可以进行“文档解析”和“文本分块”,将 PDF、CSV 和 Excel 等格式的内容转换为标记化的字符串,并根据词元的数量将其拆分为可管理的块。该功能可以保证与 Azure AI Search 和 Azure OpenAI 兼容,因为它们需要标记化的输入并且有词元限制。
Divya Swarnkar 是微软的一名项目经理,他写道:
这些操作基于 Apache Tika 工具包和解析器库而构建,使开发人员能够解析多种语言的数千种文件类型,包括 PDF、DOCX、PPT、HTML 等。你几乎可以无缝地读取和解析任何来源的文档,而无需自定义逻辑或配置!
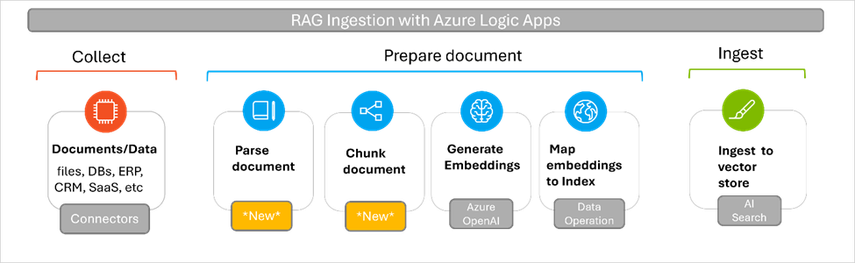
(图片来源:技术社区博客)
关于微软新推出的这些操作,Rubicon 云架构师 Wessel Beulink 在一篇博文中总结道:
Azure Logic Apps 的文档解析和分块功能带来了许多自动化的可能性。从法律工作流程到客户支持,这些功能使企业能够利用人工智能进行更具创新性的文档处理。利用低代码 RAG 摄取,组织可以简化 AI 模型的集成,实现更平滑的数据摄取、增强的可搜索性以及更有效的知识管理。
在这篇博文中,他提到了各种用例,包括将解析功能集成到人工智能工作流中从而简化文档处理,使人工智能聊天机器人能够获取和检索相关信息从而提供客户支持,以及将数据分解为可管理的片段来改善知识管理和可搜索性。
此外,Logic Apps 为 RAG 摄取提供了现成的模板,使开发人员可以更便捷地连接到他们熟悉的数据源,如 SharePoint、Azure File、SFTP 和 Azure Blob Storage 等,从而帮助他们节省时间并根据自己的需要定制工作流。
数据科学硕士研究生 Kamaljeet Kharbanda 在发表于 Medium 的一篇博文中指出,RAG 通过将深厚的知识库与大语言模型(LLM)的强大分析能力相结合,改变了企业处理数据的方式。这种协同作用使复杂数据集的高级解释成为可能,这对于在当今的数字生态系统中发展竞争优势至关重要。
低代码 / 无代码平台(如 Azure AI Studio、Amazon Bedrock、Vertex AI 和 Logic Apps)简化了高级 AI 功能的使用。除了这些云解决方案,LangChain 和 Llama Index 等工具还提供了健壮的环境,可以通过代码密集型方法实现定制化的人工智能功能。
原文链接:
https://www.infoq.com/news/2024/09/logic-apps-rag-ingestion-preview/




