
本文整理自 Zilliz 合伙人、工程总监\LF AI & Data 基金会技术咨询委员成员栾小凡在 DIVE 全球基础软件创新大会 2022 的演讲分享,主题为“基于云原生向量数据库 Milvus 的云平台设计实践”。
以下为整理内容。
什么是向量数据库
在现实生活中非结构化数据的体量变得越来越多,所谓结构化数据指的是像音频、视频、图片,包括用户信息、分子式、时序数据,地理位置数据等,这些数据相比传统的结构化数据更贴合人的需求,它的描述能力更强,同时处理难度也更高。根据 IDC 的调查显示,未来 80% 以上的数据可能都是非结构化数据。但目前非结构化数据并没有被很好地利用起来。

传统上非结构化数据往往都是通过 AI 去处理,各种各样的非结构化数据通过深度学习模型转化成 vector Embedding,即一组高维的稠密的数据,这组数据通过他们最近邻的关系,就可以演化出一些新的知识或者想法。
随着纬度变得越来越高,向量表达原始数据的能力就会变得越来越强。当然,维度无限的变大,也会造成很多处理上的困难:第一个困难是高维空间下,数据通常更加的稀疏;第二个问题是高维数据的计算量会比较大;第三个问题是维度高了,传统的数据库不再有效。
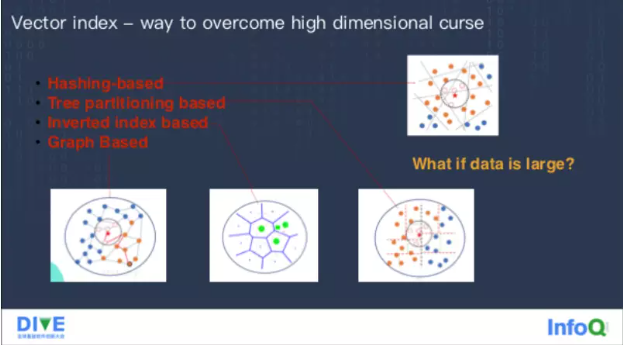
所以在这个基础上,我们演化出了所谓的 Vector Index,帮助你快速做高维数据处理的算法,常见的算法有以下几种。
第一种 Hashing-based,它的思路很简单,找到一组哈希函数,哈希高维空间里的一些点,那个值依然能表示出它的近邻关系,用这个哈希函数把这个空间分成很多份,在查询的时候,根据要查的数据先做一个哈希,找到对应的桶里面去,计算量就可以大大减少。
第二种 Tree partitioning based,它基于解释空间划分的一个思想,按照不同的纬度把空间进行多次划分,最终做成一个树结构。
第三种 IVF,它本质上就是做一个聚类,然后在这个聚类当中找到每个聚类中间点,查询的时候去跟这些中间点做比较,距离比较近的就认为可能有最近邻的数据,只去搜索其中的一部分数据。
第四种 Graph based index,它的实现方式是构建近邻图,在高维空间下构建这张图的时候,通过一种算法去找到一些最近邻,在查询的过程中,从图上任意一个点出发,不停地通过最近邻找到最近的节点,发现周围没有更优解了,它就是局部最优,如果扩散的节点数足够多,最终召回率相对比较高。这种图结构索引相对执行速度比较快,但占有内存相对会大一些。
前两种做法它都存在一个比较大的问题,就是召回精度不够,随着纬度变大,召回精度可能会变得越来越低,现在在工业中主要是采用的后两种做法。

这些向量都在解决怎么去索引高维数据的问题,但是没有解决一个很核心的问题:如果数据量变得很大,内存会放不下,查询性能也达不到预期。
所以我们做了向量数据库去索引并存储 Vector embedding,让你能够去做比较快的相似查询,它要实现的功能主要有几个:第一个是管理非结构化数据,支持 CRUD、导入导出、Backup、Snapshot;同时作为一个数据库,我认为现阶段要有很高的拓展性,同时又得有可用性;当然还有持久化能力,要保证用户写入的数据不丢,这个也是传统的这个向量索引所不具备的;随着用户对实时性要求的增高,Data freshness 也变得很重要;最后是易用性。
云原生数据库设计实践
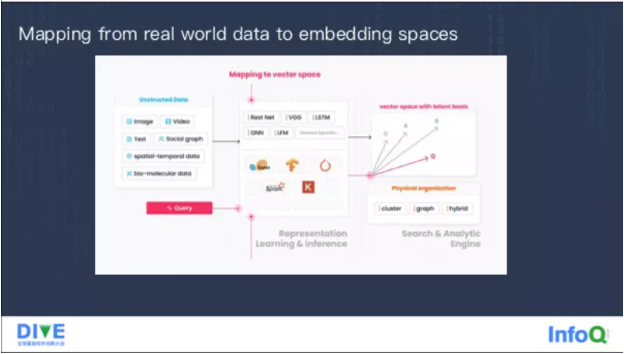
Vector database 到底是什么?接下来聊一聊,我们是怎么做云原生数据库的。这张图是 Milvus 的常见场景,最左端是一些非结构化数据,通过各种各样的模型或框架转换转换到高维的向量空间里面,然后对高维空间里的这些数据构建索引,去查询对应的图片或者文本,而多模态的查询取决于模型本身是不是有这个能力支持。

这个系统有哪些要点?
一、Data freshness versus Efficiency,数据的可见性和查询的效率之间会存在冲突,两者难以兼得。怎么去解决这个问题?我们引入了批流一体化,对于 Data freshness 我们用流式数据去解决,它可以提供实时的查询能力;对于 Efficiency 我们用批式插入的方式,导入的数据会写在对象存储上,我们会对它构建索引或者提供服务。如果流数据多了,我们会动态转化为批式方式,从而保证效率。
二、Performance versus Accuracy,所有高维度的查询不能做到百分之百的精确,除非去做暴力检索,比如我要 Top100 的结果,可能最终只搜出来 95 个。但是本质上,有一个通过 Performance 去换查询性能的逻辑,如果 BFS 每次读的点更多,可能相对精确度就会更高。我们通过 Tunable 来解决这个冲突,给用户提供不同的索引类型,也提供了很多查询的参数,让用户可以基于这些查询参数自己去做 Performance 与 Accuracy 之间的转化。
三、lteration efficiency versus Runtime efficiency,就是迭代效率和执行效率,我们有一个权衡,所有分布式这一层用 Go 去写,所有底层的执行引擎用 C++ 去写。大家一看应该就会清楚,Go 更偏向于系统的迭代效率,而 C++ 更偏向于系统的执行效率。
四、Scale versus Easy to maintain,很多人看来这个并不是权衡,但是我们发现 80% 易于维护的开源产品扩展性就有很大的问题,那么相反扩展性做得比较好的系统,它的维护成本都会比较高,我们的解决办法是拥抱云原生,后面会进一步介绍。

左边这张图是我们系统的框架图,我们是个比较复杂的系统,上面有八种不同的节点,Coordinator 是传统系统里的 Master 角色,做一些管理逻辑,node 主要是执行不同的操作。底层还有三种依赖,一种是做流式存储的,一种是做对象存储的,还有一种是做元数据存储的,有了这三种依赖之后,整个 Milvus 就可以完全做到无状态,很大的好处就是它可以很容易的去跟 Kubernetes 结合,可以很快做动态的扩缩容,弹性相对较好,这个也是我们认为这是一个云原生系统的原因。相对 MicroService 服务模式,另外的一个好处是可以按需做扩容。
右边这张图是以日志为核心构建的一个系统,我们并没有采用现在数据库当中比较主流的同步协议,而是用这个 Pulsar 或者 Kafka 作为日志的存储,最核心的原因是减少系统的复杂度。因为我们作为一个 AI 系统,对一致性的要求并不是特别的高,写入链路的延迟也并不是特别的高,Pulsar 和 Kafka 已经可以很好地满足我们的需求了。
这是整个系统的大图。最左侧有一个 Proxy 作为代理节点,同时支持 restful 和 gRPC 两种协议。根据不同的数据类型,比如在执行 Query 的时候,会把请求发到 Query node,在执行写入的时候,会先把数据写到 Log Sequence 里,Log Sequence 会被 Data node 和 Query node 订阅,Query node 负责查询,DataNode 负责流批的转化,把数据转化成一个更大的批式数据,把它放到 S3 上去,Index node 负责把批式数据转化成索引文件,再 Load 回这个 Query node 来提供历史数据的查询能力,以提升整体效率。
在资源调配时,我们遵循了几个原则:第一个是 Pooling,尽可能做池化,为未来变成一个更大的系统做一些铺垫;第二是按照功能去做组件的切分,跟传统模式不同,我们把系统分成了读写和索引几种不同的节点,因为系统里对读写还有索引的要求是截然不同的;第三是可以针对不同的类型按需扩缩容。

Milvus 的引擎层用 C++ 写的,中间通过 CGO 对接 Quary 节点和 Index 节点、Data 节点,它里面大概分成两个部分,一是标量,一是向量。向量的引擎叫 Knowhere,里面支持像 FAISS、HNSW、ANNOY 这种主流的向量索引,当然我们也做了大量的改造和性能上的调整。标量存储原始的数据,同时还可以对它构建倒排索引,帮助用户比较快的去做标量的过滤。在这之上有一个 Parser 解析用户的查询,把它转化成 LogicalPlan,再通过 Optimizer 转化成 PhysicalPlan 做具体的执行。
通常的查询,用户一般都是同时去查标量和向量,标量承担过滤的作用,向量做检索的任务。在最底层我们也对硬件做了很多封装,包括我们现在可以支持 X86,正在做 GPU 的支持,未来也会针对异构算力去做更多的支持。
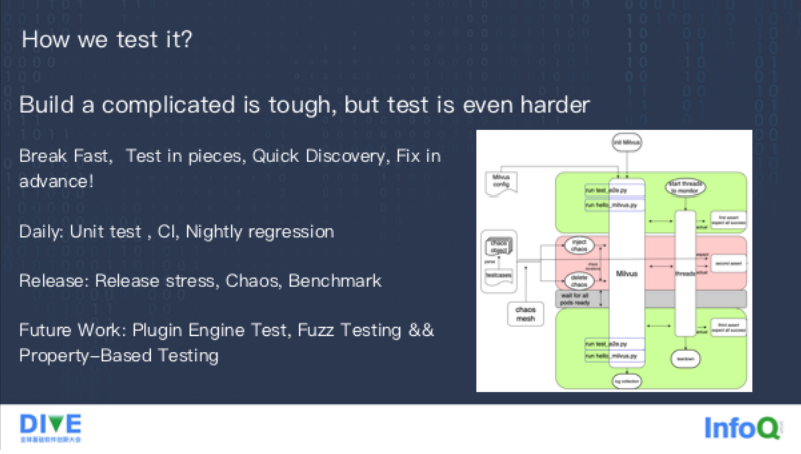
这么复杂的系统,除了开发上的挑战以外,测试是一件更加困难的事,我们遵循的测试原则叫做:Break Fast, Test In Piece,Quick Discovery, Fix Agilely,也就是希望在日常的过程中尽可能多的对它造成一些破坏和测试,尽可能把每个模块分开去测,在遇到问题的时候能够快速发现,然后在版本发布之前提前修复,而不是把问题堆到线上。
因此,测试流程也分成了以下几大块。
第一块是日常测试,所有的代码在提交之前,有比较完整的单元测试和这个集成测试,每天晚上做回归测试,通常情况下百分之八九十的代码问题可以在这个过程中发现。去年我们把单元测试覆盖率提升到了 85,发现了很多很多的问题。我们计划再进一步提升到 90% 以上;
第二块是在发布的时候去做的,包括压力测试、混沌测试。右图是我们混沌测试的框架,不仅仅去做我们自己组件的测试,也做了很多依赖的测试。这其实帮我们发现了很多故障以后恢复不了的问题。过去基本上是发版本的时候会做基准测试,但我们发现如果不持续做,到发版本的时候性能基本上都会有一些回退。所以我们最近很重要的一个任务就是去构建长期执行的基准测试,可以及时发现到底是哪个版本引入的问题。

接下来的测试包含插件引擎测试,就是对包括向量索引、依赖的存储之类的底层去做一些单独的测试,以及模糊测试和基于参数的测试,因为当系统发展到一个阶段以后,传统的测试很难轻易对它造成破坏,可能引入一些随机测试会比较好地解决这个问题。
发布版本以后,用户很自然会问这么复杂的系统,怎么去部署、运维呢?我们的原则是 Cloud As first citizen,就是以云作为第一优先级。这一原则有很多要点。
1. 怎么去发行它,我们很依赖 Kubernetes 的能力,因为整个系统本身已经非常复杂,而且又依赖了很多不同的角色,尝试过线下部署发现很难实现;
2. 系统要足够的健壮,未来我们做主备集群、数据同步,可能整个可用性相对更高一些;
3. 弹性,依赖于 Milvus 侧没有任何的状态,所以可以比较快地扩缩容;
4. 交付,在交付的过程中要能比较快速地执行完成;
5. 诊断,我们花了很多精力去做可视化的工具,包括整个监控系统,把全链路的一些比较重要的指标完整地去梳理了一遍,希望能够更多地帮助大家做 Milvus 性能的观测和排查。
向量数据库即服务
为什么我们要做这个服务?第一因素是因为我们是一家商业公司。我们除了做开源以外,也得把开源的能力变现。我们认为 Cloud service 一定是一条很长久的路,核心的原因是用户在使用一个产品的时候,成本会分为三个部分:第一个叫 Human labor cost,就是运维人员和开发人员的成本;第二叫 machine runtime cost,就是运行需要多少机器;第三个叫 opportunity cost,可能大部分人都没有很好地考虑机会成本。
我们处理 Multi cloud 的一个原则是说首先会选择一些云中立的一些协议,这样无论在哪个云上,你都可以找到对应的实现;第二是如果找不到很好的云中立的协议,我们会选择云中立的供应商;第三个是为云服务做一些定制化。
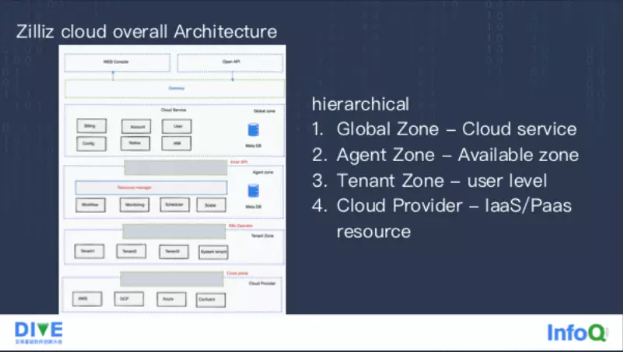
整个云服务架构最上面是暴露给用户使用的 Web Console 和 OpenAPI,中间通过一层 Getway 隔离前端和后端。后端分成四层架构:第一层叫做 Global Zone,是每一套 Cloud service,比如中国可能一套、美国可能一套,每套 Cloud service 里维护类似于账户、用户信息密码,还包括一些通知系统、配置系统的信息,可能不需要去做这个跨云跨机房的容灾部署;第二层叫做 Agent Zone,它其实是在每个 Avaliable Zone 里面都会有一套,主要做一些真正的管控,比如执行工作流启动服务起来、任务的调度、动态的扩缩容、监控;第三层叫做 Tenant Zone ,按照租户去做一个隔离,里面有一些类似于日账、日志采集、账单的逻辑;第四层叫做 Cloud Provider,包含了一些 IaaS 和 PaaS 服务。
最后简单讲讲我们的一些使用场景。
第一个是做搜索和推荐的场景,用户是东南亚非常大的一个电商,他们主要是用 Milvus 来做基于语义的推荐,有些单词一眼看上去不像是近义词,但通过模型向量化分析会发现它们是相近的,比如 bread 和 toast。
第二个是 Chatbots,是国内一个比较知名的银行在用,传统意义上的 Chatbots 基本上都是关键词的召回,有的时候如果用户的问题没有那么清晰,或者说很长有很多上下文的时候,那么这种关键词检索可能就不能特别好的帮助用户去检索到核心的信息,因此他们做了多路召回,用 Milvus 做语义理解,然后进行关键词的检索,效果还是非常不错的。
第三个是以图搜图的服务,先是在图片上找到具体的物体,再做向量化把它放到 Milvus 里面,然后再去对它做一些检索。像图片检索、声文检索、指纹检索,都是 Milvus 比较常见的一些应用场景。
相关阅读:




