
2024 年 6 月 14 日,当红视频生成大模型「Sora」团队的负责人 Aditya Ramesh 在 2024 智源大会开幕式上发表了题为「Language as the Scaffolding for Visual Intelligence」的主旨演讲。他介绍了生成式建模领域近年来的发展历程以及未来的前进方向,分享了 OpenAI 从研发 DALL·E、iGPT、CLIP 到 Sora 的一次次研究指导思想的转变,讲述其团队为何一步步将生成式模型做向极致。站在人工智能 3.0 的拐点,Aditya Ramesh 的宝贵经验具有巨大的启发意义。
下面是智源社区对 Aditya Ramesh 演讲主要内容的编译:
大模型初探:DALL·E——扩展模型规模的启示
2021 年 2 月,我们发布了著名的「文生图」人工智能系统 DALL·E,它是一个同时使用文本和量化压缩后的图像以自回归方式训练的 Transformer 模型。该系统可以将文字描述映射为量化的创作各种风格的逼真图像。之所以决定开展该项目,是因为我们看到使用 Transformer 训练的大语言模型在诸多场景下都取得了成功,我们希望探索将相同的技术拓展到其它的模态上。
给定一段语言 Prompt,我们用通用的语言模型对其进行建模,我们还训练了一个用于图像的 VQ-VAE 编码器,图像块的嵌入会被语言的嵌入增强。
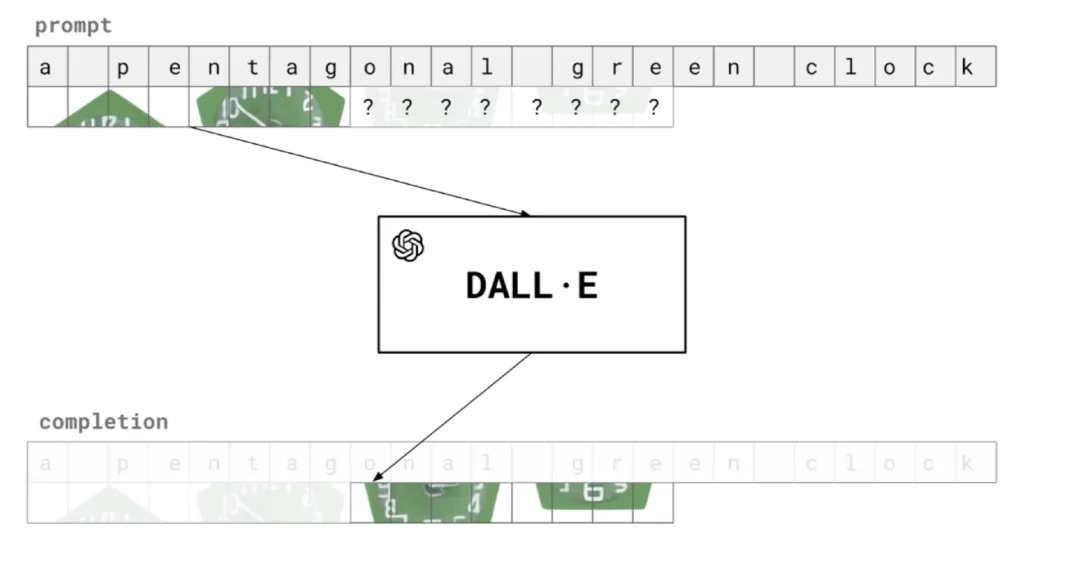
最初,我们训练一个小规模的模型,可以在该模型生成的图片中看到光照和反射、重复的物体,以及给物体上色的能力。接着,我们训练一个规模稍大的模型,该模型可以绘制具有多个属性(例如,不同艺术风格)的物体。通过继续加大模型的规模,我们还可以实现上下文渲染和对图像的上下文学习。那么继续加大模型的规模,还会发生什么呢?
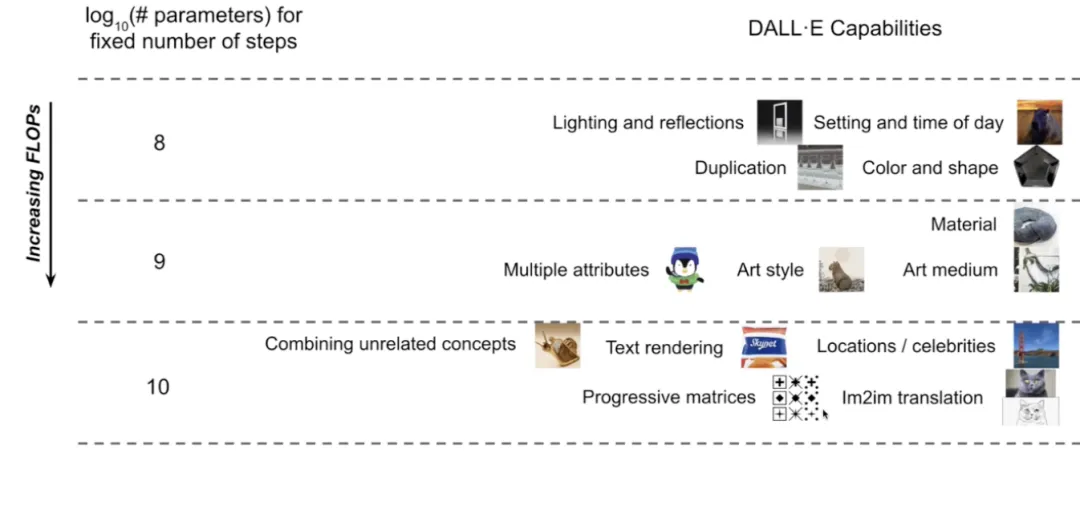
从 DALL·E 到 CLIP:语言引导的高效视觉智能提取

在发布 DALL·E 后,我一直在思考:这是一条学习智能的好路径吗?
实际上,在 DALL·E 发布之前,我们就在 iGPT 中探索了无条件的自回归图像 Transformer,我们发现将一切信息压缩起来,可以学到很好的表征。iGPT 可以被视作一个图像生成或理解模型,我们将图像压缩成一系列「马赛克」色块,从而激进地得到了一些可以通过类似于 GPT 的自回归方法处理的序列。这项研究的亮点在于,我们可以通过压缩后的图像,学习到潜在的结构信息。
而在与 DALL·E 同期发布的 CLIP 中,我们通过对比损失尝试学习成对的文本-图像数据集之间的共有信息,其计算效率比 iGPT 高出几个数量级。我们认为,在提取智能的过程中,与压缩所有像素的信息相比,使用自然语言引导视觉世界中的学习,可以大大提升计算效率。可见,尽管 DALL·E 是一项有趣的探索工作,但压缩所有像素并非从视觉世界中提取智能,从而通向 AGI 的关键路径。
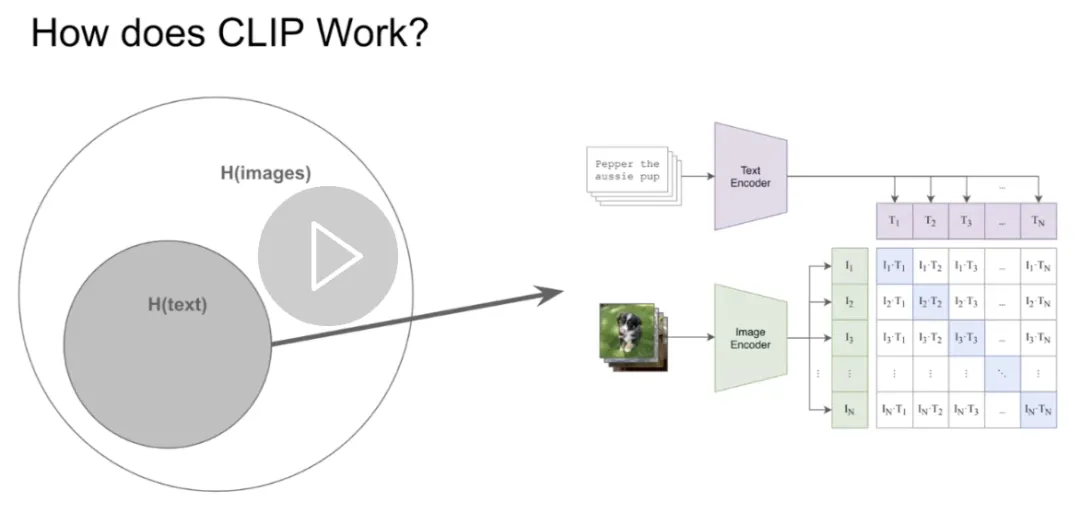
CLIP 模型包含一个图像编码器和一个文本编码器。文本编码器的输入为一段 prompt 文本,而图像编码器的输入为一张图像。在 CLIP 的训练过程中,我们向模型输入一个包含「图像-描述文本」对的数据列表作为训练数据。
文本编码器对所有的描述文本进行编码,而图像编码器对所有的图像进行编码,对比损失优化两个编码器从而对齐每个「图-文」对的表征。
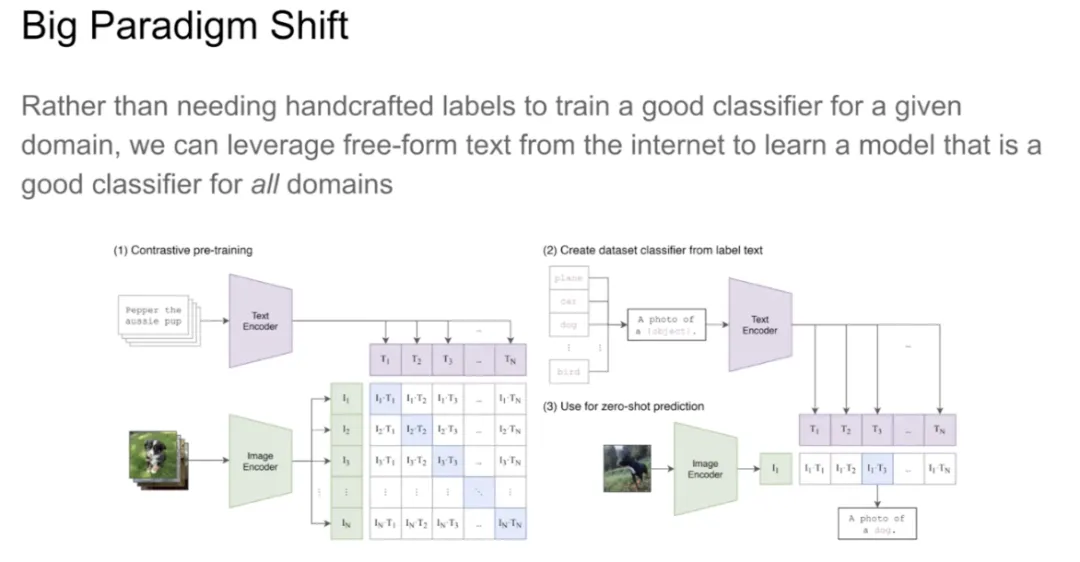
CLIP 模型的出现,标志着重大的范式转变。我们不再需要人工标注的标签来为某个域的数据训练一个优秀的分类器。我们可以利用互联网上海量的廉价文本来训练一个模型作为所有数据域上的优秀分类器。这样一来,如果我们想要对动物进行分类,只需要基于所有动物类别构造一个 Prompt 列表,然后将想要分类的图像的嵌入与列表中的所有文本描述做点乘,取该点积的 Softmax 分数的最大值对应的类别作为分类结果。
图像表示学习的发展历程

图像表示学习似乎是深度学习成功的领域之一,在图像表示学习发展的早期,分类模型仅仅学习到手动标注的标签和视觉世界之间的交集;多年后,CLIP 的诞生标志着我们可以学习互联网上的自然语言和视觉世界之间的交集;紧接着,图像描述器也成为了可扩展的视觉学习器。
为了建模文本和图像之间的交集。我们可以训练一个图像编码器感知模型,并利用视觉世界中的知识重建自然语言,这种根据图像预测文本的方法与语言模型十分类似。那么,随着算力预算的不断升级,图像表示学习最终形态会是怎样?
在上述过程中,图像表示学习的目标函数在不断改变,我们学习图像的方式也在改变。随着我们算力的增加,似乎事情变得越来越简单。
以文本为条件的图像表示学习
iGPT 的成功说明,尽管效率不高,但大规模生成模型会学习数据的底层结构,因此最终可以得到很好的图像表征。同样的情况是否也适用于「图-文」对模型?
答案是肯定的。

在论文「Your Diffusion Model is Secretly a Zero-Shot Classifier」中,作者 Li 等人指出,一个预训练好的「文生图」模型可以被用做类似于 CLIP 的零样本分类器。给定图像和候选的文本描述,我们可以使用扩散模型计算文本对匹配的损失,只不过衡量图文数据相似度的函数更加复杂。
这样一来,我们就可以从以图像为条件预测标签的训练范式转向以文本为条件,预测图像的训练范式。但是,这样做的计算效率仍然不能保证。
DALL·E 3:更高效的「压缩一切」

通过 DALL- E 3 项目,我们发现,当用于训练的文本更具描述性时,即使文本较短,训练「文生图」模型的效率也会更高。这启发我们,即使在推理时无法使用具有描述性的文本,也可以使用具有较强描述性的文本作为训练的框架得到更好的无条件模型。

如上图所示,我们向中间一列图像中加入了不同程度的噪声。这些噪声代表我们建模图像的不确定的信息。最右边一列代表解释保留的信息所需的最少的文本描述。对于第一行不包含噪声的图片,我们需要描述每个像素的颜色。
假设为这样的图像训练一个「文生图」模型,图像中没有任何的不确定性,我们可以根据文本描述读出像素质,这里不需要使用深度学习模型;如果我们向图像中加入少量噪声,去掉一些图像表面的细节和纹理,就引入了一些不确定性,模型需要学习的东西也不多。保留下来的图像可以被极具描述能力的文本来表示;如果向图中加入大量的噪声,只需要很短的描述就可以表示保留下的图像。当通过扩散模型向图像加噪至图像成为纯噪声,就没有文本可以描述剩下的图像,此时任何图像都有可能。
如最左侧一列所示,当不加入任何噪声,模型将每个点的像素值转化为图像,模型不会学到任何知识;当我们拥有更大的算力,加入少许噪声,留下的图像对应的文本十分具有描述性,模型学到的知识变多了。随着加入噪声变多,图像数据的不确定性递增,留下的图像对应的文本描述性下降,以文本为条件模型学到的知识变多。当我们拥有大量算力时,可以建模没有任何条件下的图像的熵。
我们认为,利用极具描述性的文本训练,有助于在小规模模型上补充感知相关的先验。在参数量较大,即模型规模较大时,模型可以学习到语言无法描述的知识。当我们拥有的算力越大,就可以使用越少的补充语言描述。

在 DALL·E 3 中,训练范式从「给定图像重建文本」转向了「给定极具描述性的语言重建图像」。当然,此时的计算效率可能并不会提升。最终,如果我们扩展一个极具描述性的文本补充下训练的网络,其无条件建模的能力也会增加。
起初,我们并没有用太多的文本,我们只能预测少量的信息从而构建图像分类器。接着,我们通过类似于 CLIP 或图像描述器的方式使用了较多的文本。后来,我们发现可以像在 DALL·E 3 和 Sora 中一样使用极具描述性的文本来训练生成式模型。最后,我们发现随着模型规模的扩大, 语言可以作为一种训练的框架,在推理时可以被丢弃。而视觉有时比语言更具通用性。
我们不妨转换一下思路,冻结目标函数和模型架构,然后优化数据集,而不是冻结数据集的条件下优化目标函数和模型架构。这样一来,我们也可以扩展模型的规模。此时,目标函数可以是简单的的极大似然,架构可以是 Transformer 我们试图重建所有模态的信息,转而优化使用的数据。
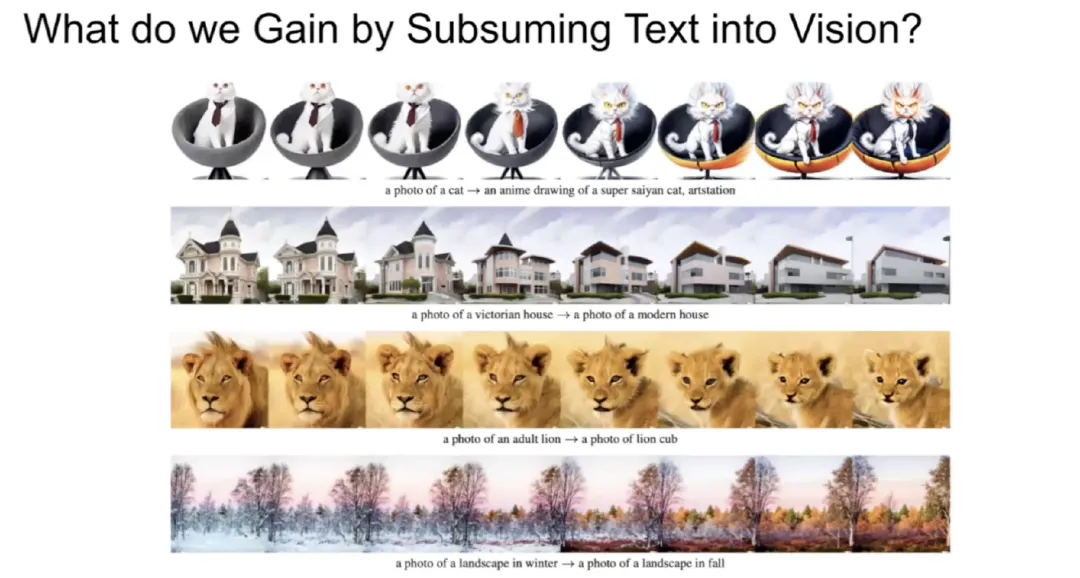
如上图所示,我们可以通过 CLIP 等模型将极具描述性的文本注入视觉世界,在 DALL·E 2 上实现类似风格转换的任务。

视觉上下文学习似乎也能赋予 DALL·E 1 一些「生命」迹象。例如,给出图像的上半部分,让模型绘制出图像的下半部分。当上半部分变化时,绘制出的下半部分也会变化,而模型从没有在这些任务上训练过。这可能是实现通往所有类型应用的一条可行路径。未来,我们可以向模型输入一张图像,要求其生成满足我们任意要求的视频。
结语
在 Aditya Ramesh 看来,将一切信息「压缩」起来可能是当下最正确的研究思路,而语言则是实现这一目标的必要「框架」。当然,我们也许还需要一些加快计算效率的方法。当多模态训练达到一定规模时,语言智能就会融入到视觉智能中。这样一来,我们就有了一条获得世界模拟器的路径,我们可以通过这样的模拟器得到我们想要的任何东西。
巅峰对话:Aditya Ramesh 对话 DiT 作者、纽约大学助理教授谢赛宁
谢赛宁:您曾在 X 上发帖说:“语言模型被高估了”。作为一个有视觉背景的人,我很喜欢这个说法。您还将 Sora 比作 GPT 模型的视觉对应物,目前处于 GPT-1 阶段。您认为扩展像 DALL·E 和 Sora 这样的视觉生成模型能否引领我们走向通用人工智能(AGI)?您如何看待建模人类语言与建模包含丰富感官数据的现实世界之间的关系?
Aditya:我坚信不疑。在视频中,我们可以获取大量的信息,而其中有些信息不容易用语言来表示。对于构建更加智能的具有推理能力的系统来说,语言模态确实也是十分重要的。但从某种意义上来说,将语言信息以某种通用接口融入视觉信号中或许可以实现模拟任何事物的能力。随着模型规模的增大,其对于语言的依赖也会降低。
谢赛宁:让我们聊聊 Sora 背后的天才。Sora 作者 Bill 在他的博士最后一年和我一起开展了 DiT 的研究,而 Tim 在他的博士期间致力于生成视频。Bill 和 Tim 两人都是刚获得博士学位不久,他们能产生如此大的影响,这真的很了不起。您能分享一下这究竟是如何运作的吗?您团队或 OpenAI 的文化中支持并赋予年轻研究人员发挥他们的热情和过去经验的秘密是什么?是什么驱动了新的研究突破?
Aditya:首先,OpenAI 的招聘政策与其它机构相比十分与众不同。Bill 和 Tim 都获得了博士学位,也有很不错的成果发表。但我们过去也招聘过一些没有机会获得正式的学术成绩但极具潜力的人。例如,DALL·E 3 的负责人 James 就是这样。
其次,我们奉行不会随波逐流的长期主义的研究目标。我们会设定一个在未来足够遥远的研究目标,但这个目标是根据先前的工作制定的可实现的目标。
最后,当然让每个人有充足的 GPU 使用也十分重要。
谢赛宁:OpenAI 中也有一些非常成功的研究人员并没有接受过所谓的传统研究训练范式,博士学位是否被高估了?你对未来的 AI 工作者有何建议?
Aditya:我们现在通过 Transformer 统一了可扩展的计算范式,也知道了如何表征数据,很多技术都趋同化了。因此,学术研究的一些焦点改变了,可解释性是我们追求的一个方向。对于现在攻读博士学位的人来说,期望做出 SOTA 的工作十分困难了,因为这比之前需要的资源大大增加了。
谢赛宁:我们很喜欢 Sora,以及您在社交媒体上分享的视频,但遗憾的是,我们无法访问它。您可能也看到了一些新发布的同类产品,例如:短视频公司快手的 Kling 模型和 Luma AI 的 Dream Machine。虽然我不认为它们超越了 Sora,但它们确实呈追赶之势。您如何看待视频生成领域的竞争?有没有关于 Sora 最新研发进展的消息?
Aditya:我们目前最关心的是视频生成模型的安全性及其对社会的影响。我们希望人们不要用 Sora 来发布错误的信息,也希望模型的行为符合人类的期望。我们很开心看到有其它的实验室和公司同样从事视频生成模型的研发,有大量的人尝试使用不同的方法对于激发艺术和扩散模型领域的创新很重要。
谢赛宁:我最近参加了一个纽约的 AI 电影节,并与一些电影导演和艺术家进行了交谈。我问了他们同样的问题:他们最希望从视频生成模型中获得的特性是什么。令人惊讶的是,他们都回答:“更好的可控性。”虽然语言提示很有用,但有时它们无法捕捉到人类经验、情感和叙事的细微差别。这是下一代 Sora 旨在解决的关键问题吗?您认为实现更高可控性水平的最佳媒介是什么?语言会是「终极」媒介吗?
Aditya:是的,我在之前的演讲中讲了很多关于语言在这些模型中的作用。我认为,提高可控性和减少随机性可能是我们从合作方那里收到的最重要的功能需求。我确实认为,拥有这种能力并重用之前场景中的角色、资产和其他元素将是一个重大变革。这只是因为,这似乎是最重要的一点,它将使视频生成模型在实际生产环境中变得有用。我觉得这有点有趣,因为我说过,我们很早就看到了 DALL·E 1 中就出现了这些上下文学习能力。而现在,这些能力正在逐步投入生产。
谢赛宁: 您提到 Sora 的目标是模拟现实以构建 AGI。我认为一个主要挑战是准确的物理建模。Sora 在这方面取得了很大进步,但仍然存在一些错误。许多人认为这需要基于第一原理和系统的泛化。您认为当前的互联网视频是否足以支持这一目标,还是我们可能需要寻找其它数据源和传感媒介?
Aditya:我认为现有的数据已经足够让我们取得更大的进展。既然有这么多数据可用,我们只需扩大模型规模就能继续取得很大进展。但我认为,一旦模型强大到足以成为独立的世界模拟器,许多有趣的事情就会发生,你就可以开始在视频生成模型内部进行接触、模拟等操作。这样我们就可以开始融入现实世界中所有多样化和有趣的约束,并开始学习有趣的东西。




