
本文整理自字节跳动基础架构 / 服务框架团队尹旭然在 QCon 2024 的分享,主要介绍了服务框架团队编译期合并服务的技术实践和经验总结。
字节跳动微服务过微的背景
截止 2023 年底,字节跳动内部微服务的数量超过了 30 万,而且这个数字还在快速的增长当中,每个季度仍然会新增上万个微服务。伴随着海量的微服务,微服务过微带来的编解码、序列化、网络和服务治理开销过大问题也愈加凸显,在一些性能敏感、QPS 大的的服务上急需优化。于是极致的微服务合并方案合并编译应运而生。目前公司内采用合并编译方式合并的服务超过 300w core,取得的 CPU Quota 收益超过 40w core,接口时延根据包大小有 2-15 ms 不等的优化。
合并编译如何解决微服务过微的问题
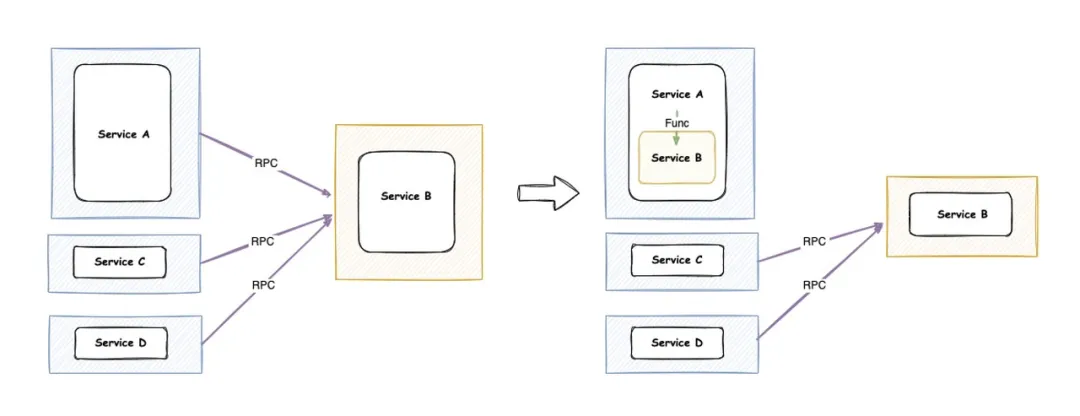
合并编译是将两个(或多个)微服务,在编译期间合并为一个二进制,以一个进程的方式运行。如果当前存在 A -> B 这样一个调用关系,A B 合并之后,将以一个二进制的方式呈现。A 原来通过 RPC 方式调用 B 的逻辑,将转变为 A 在进程内部通过函数调用 B 实际的处理函数。
流量比例 A : C : D = 8 : 1 : 1 示意图
合并编译优势相比 RPC 调用是非常明显的。
在性能方面:RPC 调用时的「编解码、服务治理、网络」的开销在合并后将完全的「减少到零」
在研发效率方面:合并编译仍然能够「保留微服务研发的优势」,在日常开发的时候还是 A 服务的团队去维护 A, B 服务的团队去维护 B,只有在上线时才会合并在一起,并不会对研发效率造成影响
在灵活性方面:合并编译能够做到「灵活地合并与拆分」,如示意图所示,A 和 B 就合起来了, C 和 D 并不接入合并编译,仍然以 RPC 的方式去调用真正部署的 B
在稳定性方面:合并后的服务的「稳定性也会相应地提高」,合并编译不再经过网络也意味着微服务带来的超时、过载等问题将不复存在。
不过,合并编译还是有一点劣势的。首先,在运行时隔离性上,微服务带来的资源的隔离、故障隔离在合并后将不复存在;第二个点是版本管理,在合并之后,如果要更新 A 进程中依赖的 B 的版本,需要将 A 重新编译上线。我们也做了大量的工作去减少这些弊端对业务的影响。
合并编译面临的挑战
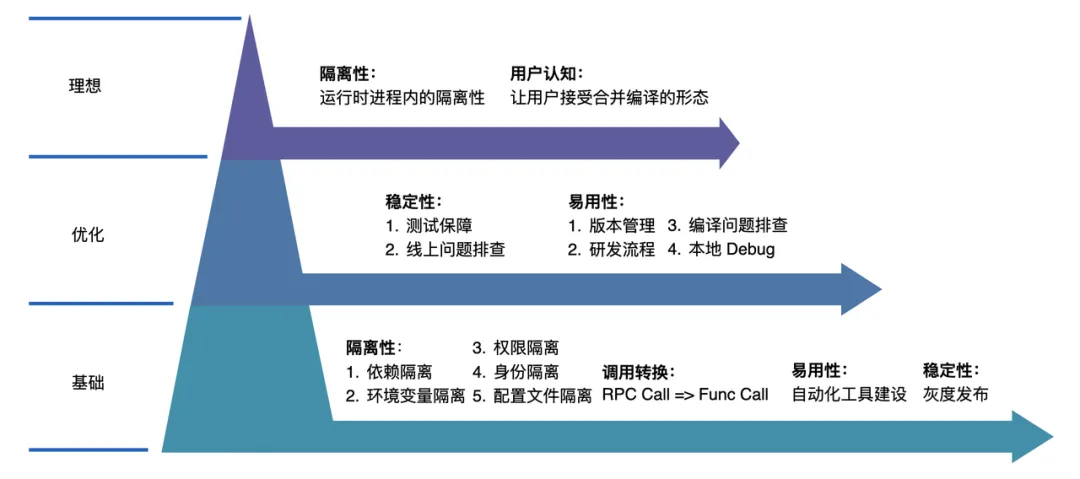
合并编译在研发过程中也面临非常多的挑战,我们将这些挑战分成了三大类:基础挑战,可优化的点以及理想形态。基础挑战是合并编译必须要解决的问题,否则在上线过程中可能会出现很多问题;而优化项则是能够让用户更友好的使用合并编译,减少合并编译对用户的影响;最后是合并编译的理想形态,也是目前合并编译还没有解决的一些点。
合并编译面临的挑战
在基础挑战方面,主要包括四大类:
在隔离性上:
依赖隔离:两个服务依赖了不兼容的依赖版本,该如何解决冲突?
环境变量隔离:两个服务依赖了相同的环境变量但是不同的值,该如何隔离环境变量?
权限的隔离,合并后的服务如何仍然拥有原本的身份呢?
身份的隔离:合并后的服务如何按照原有的身份进行打点和上报呢?
调用转换:如何自动化地将 RPC 的方式去转换为 Func call 的方式?
易用性上:合并编译需要一个自动化的工具去自动的完成这一次的合并。
稳定性上,合并编译改造完成后,如何进行第一次的上线,最好还能有一些灰度的逻辑呢?如何保障在后续迭代过程中的稳定性呢?
在可优化项当中,主要包括两大类:
稳定性:合并后该如何测试才能保证合并后的稳定性呢?以及如果线上出现了问题,该如何快速的定位到问题,让相应的同学快速止损和排查呢?
易用性上:
版本管理:下游怎么知道上游用了哪些版本?上游又怎么知道自己该使用下游哪个版本呢?
研发流程:上游有上游的研发流程,下游有下游的研发流程,那合并后的研发流程应该是什么样子的呢
编译问题排查:合并后的服务,如果遇到编译问题用户就会找上来,如何让用户能够拥有一定的排查能力呢?
本地 Debug:用户是没有合并后代码的,在本地用户该如何进行断点调试呢?
以上的这些问题合并编译都一一的解决了,不过针对最后一个大类理想层面,目前还没有很好的解决方式。第一类是集中在运行时进程内的隔离性,如何将资源、Panic 进行隔离;第二类是如何让用户接受和理解合并编译的形态,就好像接受和理解微服务一样。
###合并编译如何解决技术挑战
依赖隔离
Go 采用 Go Module 的方式进行依赖管理,不同的 import path 代表不同的依赖,比如
import ( "namespaceA/github.com/cloudweGo/kitex" "namespaceB/github.com/cloudweGo/kitex")代表两个依赖。同时 Go Module 支持 replace 的方式,将远端依赖替换到本地目录当中,并按照路径进行寻址。比如
replace github.com/cloudweGo/kitex => /tmp/kitex那么,代码中引用的 github.com/cloudweGo/kitex/client 会去 /tmp/kitex/client 路径下寻找对应的代码。
于是合并编译利用这两个特性进行了依赖隔离:首先将每个服务的依赖下载下来分别放到隔离后的目录内,如下图所示
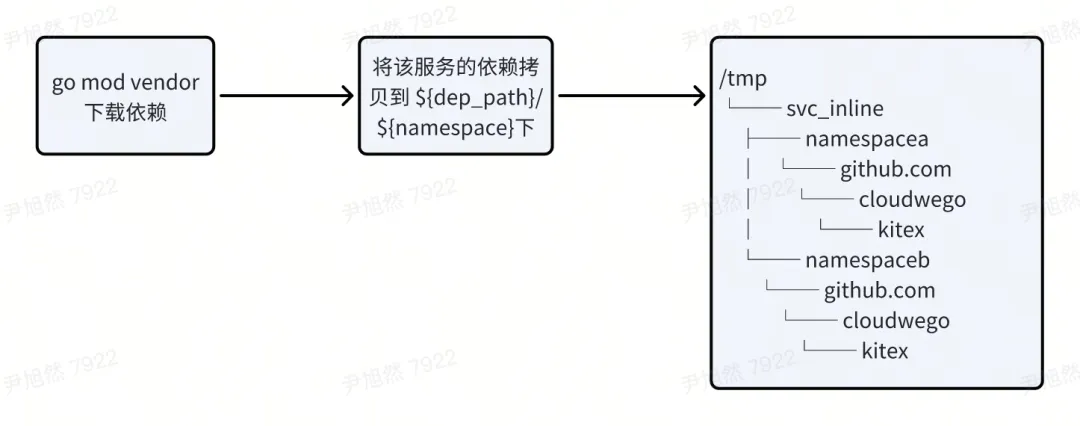
之后对不同的服务内的每个 import path 添加相对应的前缀,并使用 replace 将前缀指向对应的本地目录。
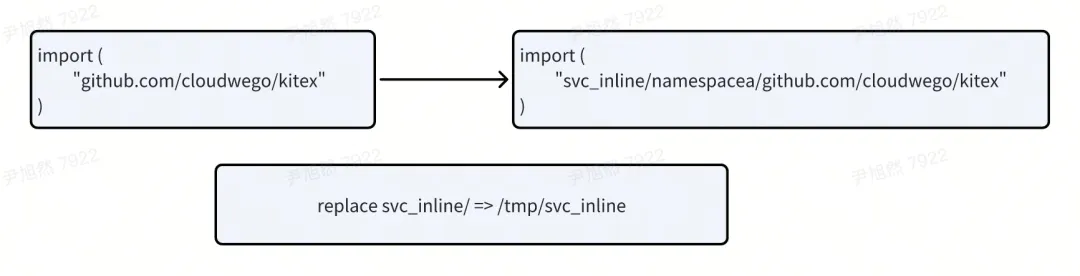
通过这种方式,合并编译实现了完全的依赖隔离。有了依赖隔离作为基础,其他的环境变量的隔离、权限的隔离、身份的隔离等等都很容易能够解决了。
调用转换
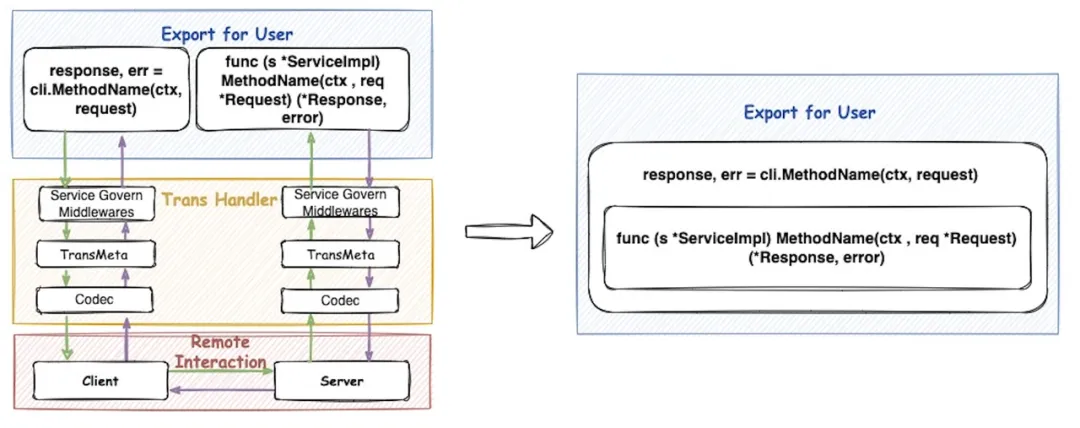
调用转换
左边是一个 RPC 方式的调用图,Client 发起一次调用,需要经过服务治理的中间件、传输的元信息和编解码部分,再通过网络传输到对端, Server 也需要进行一次同样的一些操作。合并编译希望做到右边的这种形式,Client 发起一次调用,它调用的是进程内的 Server 的对应的方法。实现这样的转换需要两步,第一步需要获得 method 实现;第二步将实现去注入到 Client 当中去。
为了获得 Server 暴露的接口,合并编译做了下图所示的处理。左边这张图是一个正常的 Kitex 服务的初始化和启动,它会执行一些初始化的逻辑,然后初始化并且启动 Server。在合并编译场景下,这部分的逻辑变成了右图。合并编译将 main 函数变成了一个可导出的内函数,可导出了才可以让 Client 去调用。第二个合并编译给这个函数增加了返回值,表示 Server 的元信息。
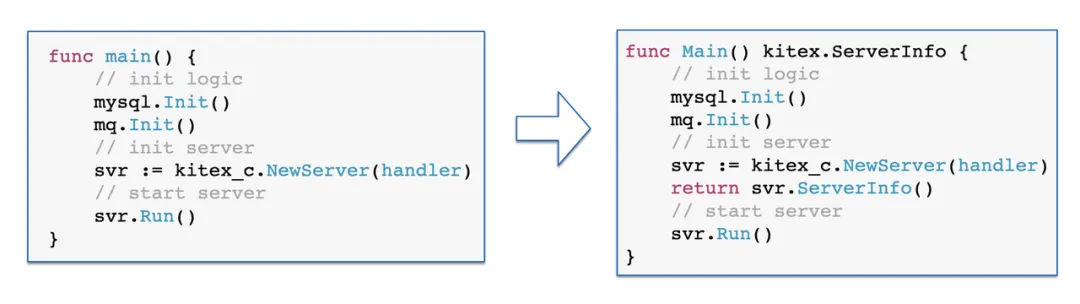
获取接口的信息
得益于 Kitex 良好的扩展性,Kitex 将 Client 抽象为了一个接口,只要实现这个 Call 方法,就可以实现一个 Kitex 的 Client,也是得益于这个抽象,使得合并编译注入 Server 实现非常容易。
type Client interface { Call(ctx context.Context, method string, request, response interface{}) error}一个普通的 RPC Client 的初始化只需要这一次 RPC 的信息就可以了。那针对合并编译 ServiceInlineClient 的初始化,还需要增加 Server 的元信息参数。这个信息就是通过上文对改造后的 main 函数调用获得的。
serverInfo := server.Main()kc, err := client.NewServiceInlineClient(serviceInfo(), serverInfo ,options…)第二步合并编译需要为 ServiceInlineClient 实现 Call 方法,使得它在 Call 的时候不去走 RPC 的逻辑,而是去走本地调用,在 ServerInfo 里找对应的方法。Kitex 针对合并编译做了一些特殊的支持,以上的这部分代码的实现在 CloudweGo Kitex 当中以上代码,感兴趣的小伙伴可以参考 Kitex 中合并编译部分。
版本管理
合并编译和 SDK 版本管理的痛点有点相似,比如:
下游升级时,上游感知不到,会造成版本的不一致
下游并不知道上游依赖的是自己的哪个版本,也就无法告知上游升级
版本选择复杂,上游也不知道这次升级需要选择下游的哪个版本
于是,合并编译针对具体的业务场景做了梳理,并与研发流程与发布平台做了联动,平台提供了基础的能力,减少用户对合并编译的学习成本。

针对最终一致性,下游可以在镜像平台上配置好上游依赖的默认版本,下次上游上线的时候可以默认带上去,也不用上游主动去选择该使用的版本。针对强一致性可以通过一条流水线,同时升级上下游;也可以拥有上游权限的团队直接去升级上游服务。除此之外,平台上也会收集版本的元信息,用户可以很直观的看到自己依赖了哪些版本,以及自己的哪些版本被依赖了。
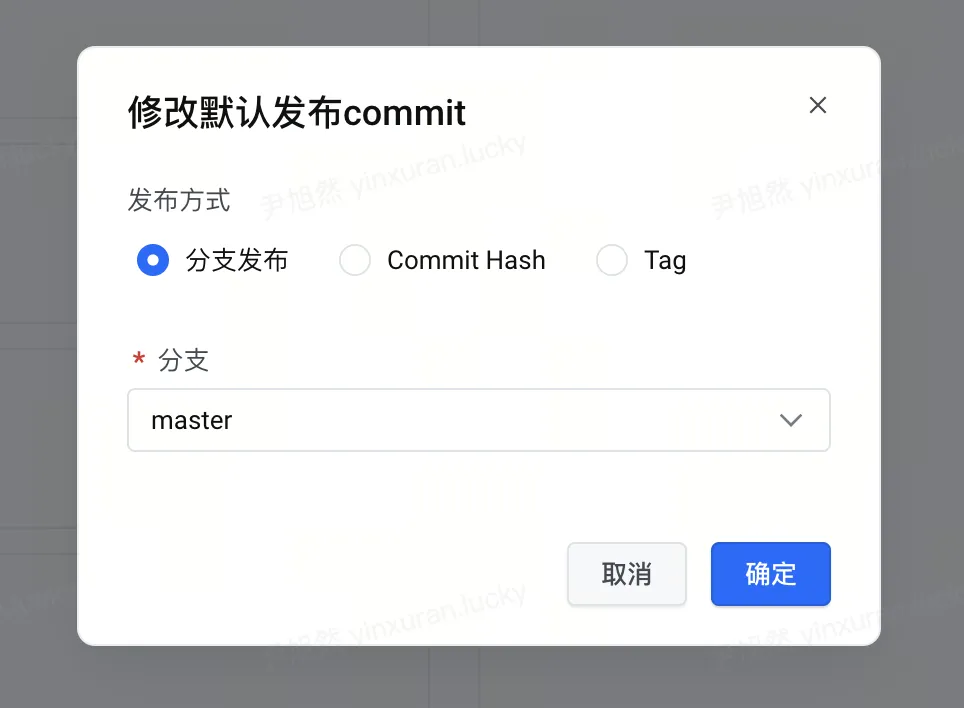
修改默认发布的版本
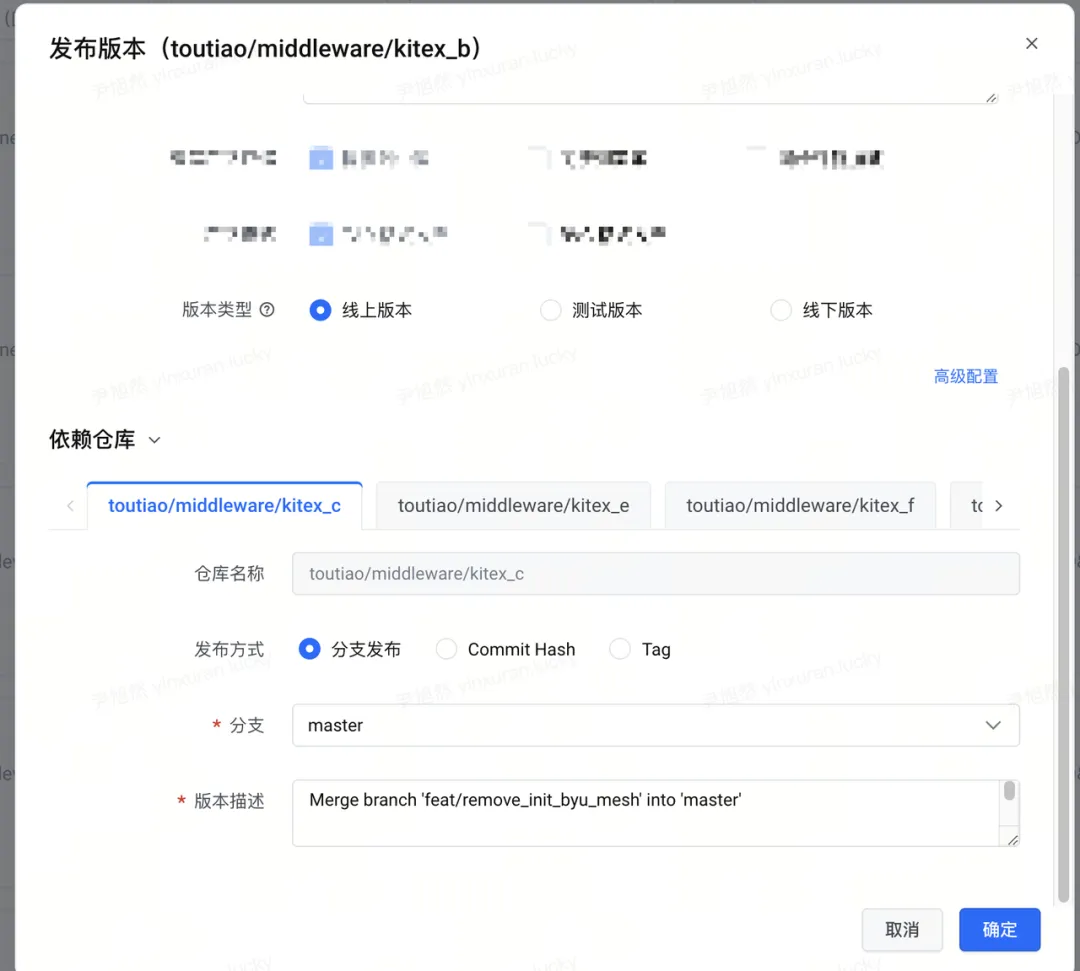
上游选择下游的版本
服务接入
合并编译主要解决微服务过微带来的性能问题,其收益公式如下
Benefit = Downstram Quota * MergeRatio * (CodecRatio + Service Governacne Ratio) * 2
DownstreamQuota 指下游服务的资源申请量;MergeRatio 指合并的比例;Codec Ratio 指编解码的开销;ServiceGovernaceRatio 指服务治理的开销。
从收益公式中可以看到,合并编译应该聚焦于「资源量大、调用关系密切、编解码开销大」的服务,才能够拿到较大的收益。为了能够快速筛选出适合接入的服务,合并编译团队从 Trace 流量表、Quota 资源表出发,对全公司内的服务进行筛选,筛选条件为:从 Server 视角看,来自单一最大上游的流量占总流量的比例超过 30% 或者从 Client 视角看,来自单一最大下游的流量占总流量的比例超过 30%。之后再和 Quota 表做关联,按照 Client + Server 总 Quota 降序排列,于是就得到了一张公司内大致适合合并的链路表。该表是合并的必要条件,还要满足:
非缓存、固定开销类型的服务:这类型的服务在合并后因为实例数增加会导致开销增加。
容器负载太高的服务:容器负载高的服务本身就不是很稳定,合并可能会加剧。除此之外,内存很高的服务没法合并,合并是内存直接相加,但是容器规格是有上限的。
编解码大于 3% 的服务:编解码大于 3% 合并后比较稳妥的可以看到收益,如果低于 3% 的话服务是很重计算型的服务,不一定适合合并。
案例分析
下面是从链路表中筛选出的一对比较适合合并的服务。从 Server Ratio 中 0.962 中可以看出,这个下游 96% 的流量都是来自这一个上游,流量的亲和度非常高;同时 Client Quota 和 Server 的 Quota 相差不多,那这一对就是潜在的适合合并的服务。

之后再结合火焰图上寻找 Kitex 的编解码开销,一般来说编解码开销在 3% 以上合并是有收益的,开销在 5% 以上的收益比较大。像下面的这个服务编解码占到了近 10%(包非常大),这样的服务合并的收益是非常大的。
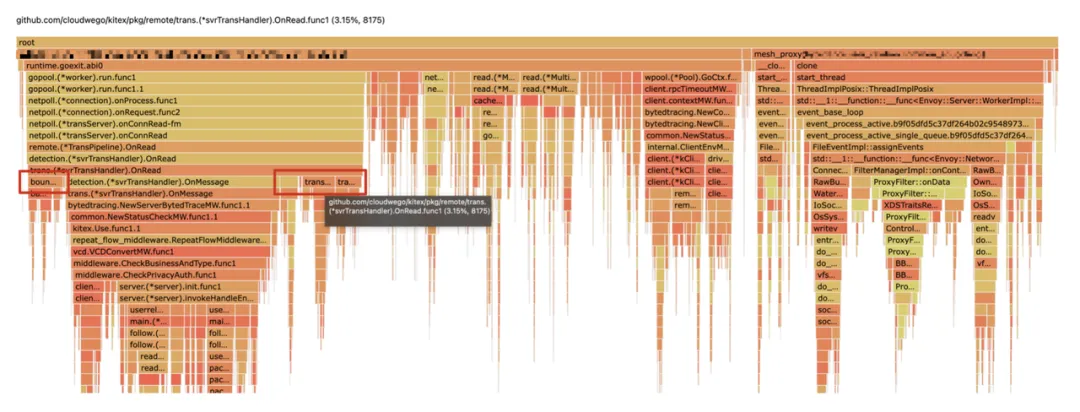
火焰图编解码开销
结合流量关系表和火焰图的筛选,这对服务取得了 4w+ 核的收益。
除此之外,除了拿到 CPU 收益,针对时延、SLA 等也拿到了不小的收益,甚至在很多非 CPU 收益的场景,合并编译继续发挥它的价值,比如:
大上游 + 小下游:防止突发流量导致下游过载,常态预留较多资源又会造成浪费。合并后使得小下游可以使用整个服务的资源。
利用合并编译做 RPC 权限收敛:下游每新增一个上游就要为这个上游添加访问权限、配置限流等等,而利用合并编译多身份的能力,用户添加了一个 proxy 层,并将多个上游与该 proxy 进行合并编译,大大减少了配置的成本。
合并规模
根据链路表中的数据,粗筛公司内部一共有 1.8w 条链路可以合并,链路总核数约 2.6 亿核。抽样 500 条链路,其中能够合并的服务链路条数为 13 条。按照合并后 10% 的收益统计,合并编译可以带来的 CPU 收益约为 67w core。
目前,合并编译采用重点服务点对点跟进的策略,公司内部已经完成合并编译的 CPU 核数超过 300w core,取得了超过 40w core 的收益,接口时延也有 2-15ms 不等的收益。
总结与展望
合并编译能够在字节跳动内部大规模落地,证明了合并编译这种形态在架构上的可行性。目前,合并编译推进方式是点对点的,针对的是已有的服务,在降本增效的背景下,如果合并后有性能和成本的收益,则会尽可能的推动业务进行合并。不过,这样的推进缺乏全局统一的视角,对业务架构的演进帮助不大,且效率相对比较低。未来,我们希望自顶向下的平台化地推进。
这与团队内发起的业务域体系构建项目不谋而合。业务域项目针对目前面临的业务架构混乱、链路复杂、架构复杂度高等问题,推出一套完善的平台和产品,帮助业务完成业务域的自动划分和分层。业务域项目会借助合并编译和流量治理等工具和能力,从更高的视角去做架构复杂度治理,包括「链路治理」和「过微服务治理」:
链路治理:对于链路过深的场景,可以借助合并编译完成上下游的合并,降低链路深度;未来合并编译也将探索循环依赖、相互依赖场景下多个微服务合并能力。
过微服务治理:对于微服务拆分过细、服务的资源 Quota 低的场景,合并编译将支持多个 Server 的合并,合并后以一个进程的方式对外提供服务,方便统一进行治理和管控。
可以期待的是,结合合并编译这一成熟且高效的工具,业务域的架构师在「不修改代码」的情况下,可以快速、自动化完成不同场景下的微服务合并,「极大降低架构优化和业务改造的成本」,从而缩减低价值服务,沉淀高价值服务,最终形成清晰的业务架构。微服务的合并并非是对微服务的全盘推翻,而是重新对业务架构进行审视和治理,结合当前业务的规模和研发效率对其进行优化,朝着理想架构演进。
Reference
CloudWeGo: https://www.cloudwego.io
Kitex:https://github.com/cloudwego/kitex
会议推荐
InfoQ 将于 10 月 18-19 日在上海举办 QCon 全球软件开发大会 ,覆盖前后端 / 算法工程师、技术管理者、创业者、投资人等泛开发者群体,内容涵盖当下热点(AI Agent、AI Infra、RAG 等)和传统经典(架构、稳定性、云原生等),侧重实操性和可借鉴性。现在大会已开始正式报名,可以享受 9 折优惠,单张门票立省 480 元(原价 4800 元),详情可联系票务经理 17310043226 咨询。





