
背景
深度学习是一种使用神经网络的机器学习,正迅速成为解决从文本分类到推荐系统等许多不同问题的有效工具。然而,将训练好的神经网络模型部署到应用程序和服务中可能给算法从业人员带来不小的挑战。算法框架的不同、计算资源稀缺和缺乏标准实现等挑战都可能导致模型部署的失败。
作业帮的业务体量较大,需要部署大量的深度学习模型应对不同的任务。为满足实际使用,我们部署的模型服务需要具有以下特点:
高并发
低时延
模型多
更新快
业务方多
结合任务特点与实际应用场景,我们还面临以下问题:
数据预处理模块与模型版本强耦合,部署时需保持同步。
多个版本的预处理模块相互之间易冲突。
模型太多,如果全部加载至 GPU 浪费资源。
因此,本文将以上述场景作为对象,阐述三种不同的解决方案,并对比它们的性能指标。最终目标是找到一个适合作业帮任务的模型部署方案,在合理占用资源的情况下,满足不同业务方的需求。
模型部署方案
1. Gunicorn + Flask + Transformers
Transformers 是一个十分方便的自然语言处理库,它的宗旨是让最先进的 NLP 技术人人易用。通过 Transformers 可以轻松地实现模型的训练、加载和推理。此外,使用 Flask 框架部署深度学习模型是最简单快捷的方式。但是 Flask 自带的 Web 服务性能极不稳定,无法满足高并发、低延迟的需求。因此,我们通过 Gunicorn 框架提供的 WSGI 服务来部署 Flask 的接口,也就是将 Flask 代码部署在 Gunicorn 提供的 WSGI 服务上,可以显著提升服务的并发能力和稳定性。
本部署方式的整体框架如下图所示:
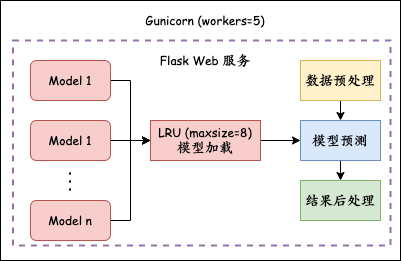
利用 Transformers 加载所需模型,但通过 LRU 机制控制加载在内存中的模型数量最大为 8,防止内存多大。
通过 Flask Web 框架构建模型预测服务,包括数据的预处理、模型预测和结果后处理等步骤。
最后用 Gunicorn 启动 Flask 服务,设置 worker 数量支持异步处理请求,提高并发能力。
Flask 服务的构建十分简单,具体如下图所示。实现一个模型预测函数,并将其与’predict’接口绑定即可。另外,需注意的是线上服务需要实现’ready’接口返回 200 和’ok’以执行健康检查。

采用 Gunicorn+Flask+Transformers 部署深度学习服务的初衷是,该方式与我们的训练框架较为耦合,实现起来比较简单。但在使用线上服务的实际场景中,遇到了以下问题:
在每个 worker 中,执行模型的预测会有 100+线程,导致资源的挤兑。
Gunicorn 确实提高了 Flask 服务的并发能力,但在并发请求较多时,并不能解决健康检查超时的问题,使得 pod 摘流并增加预测时延。
Transformers 模型推理方式的时延较长。
LRU 机制的存在使得模型需要重新加载,而模型加载比较慢导致预测时延增加。
最后,这种通过这种部署方式部署至 serverless,共 6 个 pod,每个 pod 的资源是 16 核 16G 的情况下,能达到 150QPS。
2. Tornado + PyTorch
Tornado 是使用 Python 编写的一个强大的、可扩展的 Web 服务器。它在处理严峻的网络流量时表现得足够强健,在创建和编写时又足够轻量,并能够被用在大量的应用和工具中。Tornado 在设计之初就考虑到了性能因素,支持异步非阻塞,可以接受多个用户的并发请求。本方案采用 Tornado 代替 Flask 以实现更好的异步通信。
本部署方案直接采用PyTorch模型预测的方式代替 Transformers,避免 Transformers 内 Trainer 的冗余操作以减少预测时间。此外,将每个模型分开部署至子服务,取消模型的动态加载机制,避免模型切换造成的耗时。同时,这种方式也避免了模型过多导致的资源挤占问题。
本部署方式的整体框架如下图所示:
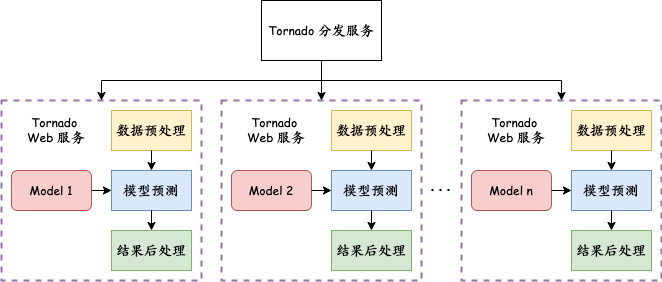
每个模型通过 Tornado 包装成子服务,包含数据预处理,模型预测和结果后处理。
分发服务负责接收所有请求,并根据数据类别将其分发至对应的模型预测服务进行预测。
子服务的预测结果返回至分发服务,由分发服务返回所有数据的预测结果。
Tornado 部署 Web 服务同样十分便捷,同时可通过’async’和’await’关键字轻松实现异步。
采用 Tornado+PyTorch 的方案部署模型的原因是,组里同事有 Tornado 的踩坑经验,方便实现性能上的优化(如异步)。此外,本方式仍与训练框架有联系,从训练到部署的链路仍比较完整。然而在上线测试后,发现本部署方式仍有以下问题:
PyTorch 预测时启动大量线程的问题仍未解决。
模型多的情况下,需要申请大量模块并部署,管理太繁杂。
没有动态 Batching 功能,无法更好地发挥机器性能。
3. 单模型性能测试
为更方便地进行性能测试,我们采用单个模型进行性能的测试。通过不同部署方式在单模型上的性能进行对比,以挑选最优的部署方案。本节中,我们采用了 ONNX 和 TorchScript 两种模型格式,并分别用 Tornado 和 Triton Inference Server 进行部署。
ONNX (Open Neural Network Exchange)是一种针对机器学习所设计的开放式文件格式,用于存储训练好的模型。它使得不同的人工智能框架可以采用相同格式存储模型数据并交互。对于我们的场景,其优势在于可以控制线程数防止资源挤占。
Triton 是英伟达等公司推出的开源推理框架,为用户提供在深度学习模型部署的解决方案。其主要职责和服务紧密相关,服务中常见的需求需要它做处理。比如 Batching,Sequence,Pipeline 和模型仓库的管理等
我们将各个服务部署在 Docker 中,限定 CPU 核数为 16 来模拟线上模块的资源。通过 Locust 工具进行压测,具体结果如下表所示:
在不考虑预处理的情况下,Triton + TorchScript 的部署方式是最优的。Triton 的动态 Batching 功能极大地提升了并行预测的功能。但是在我们的场景中,数据预处理与模型预测强耦合。于是,尝试利用 Python Backend 将预处理部分同样集成在 Triton 中,实现完整的模型预测服务。但在实际测试过程中,发现集成预处理的 Triton 服务效果并不理想,怀疑是预处理的串行使得模型预测时无法进行动态 Batching。因此,我们最终决定将部署方式确定为 Tornado Web 服务和 Triton Inference Server。
本节对 ONNX 的处理比较粗糙,可能并没有发挥其优势。但 Triton + TorchScript 的方式已经满足业务需求,并没有对 ONNX 的实验进行深究。
4. Tornado + Triton
本节介绍最终确定的模型部署方式:Tornado + Triton。通过将不同版本的预处理模块打包成不同的 Python 模块解决版本冲突问题。另外,针对业务方多且需求不一致的问题,我们通过写多个接口的方式解决。比如,’/category_predict’支持单条预测,’/category_predict_nlp’支持批量预测。于是,本部署方式如下图所示:

其中,Tornado Web 服务接收应用方的请求,对数据进行预处理,然后异步调用 Triton 进行模型预测,最后对预测结果进行后处理并返回结果。
本节中通过题型预测任务对新的部署方式进行测试,将对应的 21 个模型部署至限定 16 核的 Triton Inference Server。产生随机数据模拟线上请求并用 Locust 工具进行压测,具体结果如下:
通过结果可以发现,将数据预处理和结果后处理集成在 Web 服务中并通过 Triton 进行模型部署的方案在我们复杂的业务场景下是最优的。这种方式不仅通过动态 Batching 的方式增加并发降低时延,并且方便了模型的管理与更新。其唯一的缺陷是无法解决预处理模块和模型版本强耦合的问题,在部署时需保持同步,且时间点最好是在服务低谷期。
总结与展望
本文涉及的场景比较复杂,主要有以下几个问题:
模型多,不同任务的模型总数接近 100 个,且更新频率随业务节奏变更。
易冲突,数据预处理和模型版本强耦合,且不同版本预处理模块易冲突。
性能要求高,任务面向用户,在部署至 CPU 环境下要求高并发和低时延。
因此,本文从实际应用场景触发,设计并尝试了多种部署方式,对比其在线上使用过程中的表现。经过几次实验后,找到了一种适用于我们复杂场景的深度学习模型部署方式,在不依赖 GPU 资源的情况下满足业务方的需求,并为后续的模型部署提供了一种可行的部署方案。
然而,由于业务节奏,本文在实验过程中仍忽略了一些问题。比如,ONNX 格式的模型部署在 Triton 中的性能为何不如部署在 Tornado Web 服务中,或许是 ONNX 在 Triton 中需要一些特殊的配置。另外,数据预处理和模型版本强耦合的问题仍未得到合理的解决方案,目前的处理方式仍有版本对不齐的风险。本文未对这些问题进行深入研究,留待后续探讨。




