
作者 | 王亚伟、Pavel Petrochenko、Olga Lukianova
2023 年 3 月,GitHub 推出了升级产品 Copilot X,这是 Copilot 代码补全工具的新版本,并宣布正式接入 GPT-4。同时,他们还推出了一系列诸如聊天、文档检索、代码合并等王炸特性。其中,以代码为中心的聊天式开发模式可以实现对选中的代码片段进行解释、单元测试和 Bug 修复等新颖功能。这种颠覆式的智能化开发体验确实让我们研发开发者工具同行们感到深深的困扰。
以我最近与世界顶尖 IDE 公司 JetBrains 的技术专家 K 交流为例,他跟我分享了一个困扰他很久的问题:随着大语言模型变得越来越强大,一款支持多编程语言的 IDE,是否还需要对每种编程语言实现对应的代码模型以及适配不同构建系统呢?
这个问题的背景是他的团队正在打造一款多语言 IDE 内核来支持 JetBrains 的下一代 IDE 产品 Fleet,而 Fleet 的定位是轻量级、智能化、分布式。然而,如果一款 IDE 内核同时支持多种编程语言和构建系统,那么它就很难做到轻量。于是,他提出一种可能的替代方案:用户本地只运行编辑器,用户代码作为纯文本输入到云端的大语言模型,由大语言模型完成各种补全、构建等操作。
如果这个方案能够实现,那么就意味着已经存在了 30 年的架构将被彻底颠覆,各大 IDE 厂家的业务版图会被 AI 抢走,大家可能一下子都会陷入迷茫,不知道还有什么有意义的工作可做,这能不让人焦虑么?
这位专家的问题听上去似乎很难回答,我们先不着急讨论。先科普下如果需要适配多语言、多构建系统,那么 Fleet 的内核要做什么事情?首先它需要对每种编程语言构造对应的代码模型 。代码模型的作用简单来说就是帮助 Fleet 理解所开发程序的所有编译和统计信息,包括项目依赖组件、源代码、编程语言的语法和语义。传统 IDE 的代码补全、语义高亮、浏览导航等特性都离不开它。
IDE 智能化历史
1996 年,第一代基于代码模型的代码补全技术发布于 Visual Basic 5.0。可以说这是智能感知技术的前身,也是 IDE 智能化技术的鼻祖。2001 年,首次发布的统一 Visual Studio .NET 集成开发环境把智能感知技术带到了一个新高度,支持的语言也进一步扩充。随后,Visual Studio 的每一次版本迭代都展现了智能感知技术的进步。
智能感知包含一系列的功能,包括代码补全/提示,快捷信息(QuickInfo),参数信息(Parameter Info),错误检测等。其中,代码补全和提示可以根据输入的关键字、类型、函数、变量名称等编译器可识别程序元素,主动补全剩余单词字符。智能感知的补全内容主要来自于代码模型,结果以单词或单符号为主。虽然只能补全单个符号,但这并不代表智能感知是落后的技术,相反,即使是放在大模型满天飞的今天,智能感知还是整个开发者内环体验的根基,是整个开发者工具领域最有技术含量的特性之一。
说它有技术含量是因为它要解决的问题复杂且用户敏感。举例来说,智能感知系统通常在用户编码过程中被调用提供实时辅助,而此时的代码可能根本不在一个可编译的状态,传统编译器前端只能对完整代码进行解析,所以如何对不可编译代码进行语法语义分析是智能感知系统首先要解决的问题。第二点就是性能和稳定性,理想情况下智能感知要在 50ms 之内给出结果,并且稳定运行。第三点是结果的准确性。不管是参数帮助、快速信息还是错误提示,结果必须保持准确。
时间来到了 2018 年,随着人工智能技术层面的应用持续发展,产业界意识到机器学习可以用来提升 IDE 智能化体验,IntelliCode、Codota、Kite 和华为云的 SmartAssist 等一众基于预测机器学习模型(Predictive ML Model)的技术层出不穷。这类技术提供的代码智能补全的能力与传统智能感知类似,即开发者在编辑代码时,机器学习模型根据当前代码编辑的上下文特征生成 API 推荐列表并对其进行排序,供开发者选择。
这类技术能对单符号至整行代码进行补全,补全效果(数量、质量)比智能感知有大幅提升。
在 2021 年 10 月 GitHub Copilot 出现之前,事实上大语言模型(Large Language Model,LLM)已经展示出来其在自然语言和代码片段生成方面的强大能力。2022 年底发布的 ChatGPT 是一个集大成者。作为一个烧掉了数百亿美元、背靠 1,750 亿参数大语言模型的产品,ChatGPT 极致的自然语言处理能力和高质量生成结果,使得人工智能的发展终于实现了阶跃式的突破。
这一切的背后都是一种称为 Transformer 的深度学习模型。与循环神经网络(RNN)类似,Transformer 模型可以处理自然语言等顺序输入数据,但与 RNN 不同的是,Transformer 模型的架构允许它并行处理所有输入数据。自 2017 年谷歌大脑团队推出 Transformer 模型以来,它已经成为了自然语言处理的首选模型。
有了 Transformer 模型之后我们离开发一个类似 Copilot 的产品还有多远呢?
首先,我们需要大量高质量的源代码数据和 GPU 资源来训练模型,训练是为了让模型学习源代码数据中的程序固有的标准模式和结构。在训练过程中,模型摄取输入序列(例如表示部分代码片段的标记),并根据上下文预测下一个最可能的标记。其次,训练过程需要对生成的代码准确率不断优化,通常使用无监督学习和最大似然估计等技术进行模型微调。随着时间的推移,生成的代码还需要不断通过用户反馈进行改进。当用户选择或修改代码建议时,这些改变就可以用于更新模型的参数。最后,需要开发云服务来部署模型并提供服务。虽然 Copilot 可以独立工作,但通常被集成到开发者的内环作业流,成为智能代码补全的搭档。
从上述训练过程可以知道,基于 LLM 生成的代码来源于已有代码中固有的标准模式和结构数据,因此不可避免会遇到一些问题。事实上,业界对于 Copilot 这类工具普遍存在如下担忧:
1)错误或恶意代码:当面对新颖或不可预测的情况时,LLM 倾向于猜测并给出错误的推荐,这些错误显著减慢开发速度,因为开发者需要花时间验证建议并删除任何不正确的部分。更糟的情况是导致未被发现的问题、不安全或恶意代码。
2)非最优代码:LLM 生成的一些代码可以工作,但在性能或效率方面不是最优的。根据我们的实战,这类问题非常常见。LLM 通常缺乏对算法或优化技术的深刻理解,它可能会生成计算成本高或效率低的代码,并且生成的代码可能并不总是遵循最佳编码实践或行业标准。
3)伦理考虑:使用 LLM 进行代码生成会引起伦理方面的关注,例如潜在的剽窃或侵犯知识产权。如何确保生成的代码不违反任何法律或道德界限成为一个至关重要的课题。
下图是用Codeium生成的一段代码,作用是连接字符串数组并以大写形式返回结果。这段代码初看起来语法功能都没问题,但却是一段不折不扣的低效代码 :循环中使用‘+’连接字符串的效率十倍低于 StringBuilder。
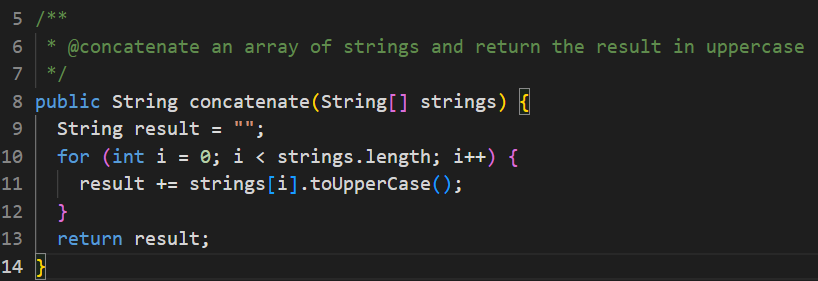
遗憾的是,上述 3 大痛点问题暂时没有特别有效的解决方案。
所以回到开篇那位专家 K 的问题,答案显而易见:用 LLM 重构 IDE 架构,把所有开发者内环作业流的核心工作都交给 LLM 是不现实的。至少在可预见的未来,AI 编程工具只能作为常规开发作业的辅助工具,成为开发者的编程副驾驶员,而代码模型、构建、调试系统对于一款 IDE 产品仍然是必须且至关重要的。
智能感知 2.0
那么,如果 LLM 短时间无法解决上述问题,特别是 1)和 2)两个影响开发效率的问题,有没有技术能与 LLM 一起工作来减轻上述问题产生的负面效果?作为一支为华为生态系统打造一流工具和服务的团队(CodeArts),我们有一些探索和技术可以与大家分享:我们的思路是通过静态代码分析、人工神经网络和代码模型等手段来增强 IDE 中智能感知的能力,实现开发态的全方面的智能化融入,我们称之为智能感知 2.0。智能感知 2.0 不仅仅提供代码生成的辅助,在一些问题场景中,当我们的工具感知到开发者需要帮助时,还可以提供诸如调试断点、热替换、搜索、浏览、检查提示等辅助。
下面以代码生成为例介绍智能感知 2.0 是怎么工作的。比如我希望写一个函数,它返回一个空列表。于是给 LLM 一个输入:生成一个不接受参数并返回空列表的方法。LLM 输出如下一段代码。
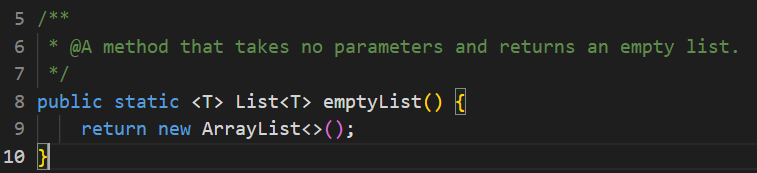
其中在第 9 行,Collections.emptyList()或 new ArrayList<>()都是对的,但如果碰巧我需要的是一个 Immutable 列表,Collections.emptyList()就是最优推荐。此时 LLM 已经无能为力,但智能感知 2.0 可以对这个推荐进行替换。它虽然并不知道我需要的是 Immutable 列表,但当光标移动到第 9 行时,它能动态感知并理解上下文的语义——返回一个空列表,从而给我若干可能正确的推荐,Top1 的推荐就是 Collections.emptyList() (因为 new ArrayList<>()已经被过滤)。
智能感知 2.0 的代码生成技术跟前辈的主要区别是它更多关注结构化的原子建议(proposal)而非单个的符号(token)。在这个例子中,Collections.emptyList() 和 new ArrayList<>() 就是两个独立的原子建议。如果基于单个符号进行推理,则完成上述代码片段需要由代码模型生成 5-6 个符号,并且在预测 Collections 符号的阶段,就需要知道之后预测的 emptyList(),并生成语法上有效的代码。这除了会显著增加推理模型的特征数目之外,还要求我们时刻跟符号组合中的错误语法问题作斗争。此外,智能感知 2.0 使用了一些非常简单的模型来过滤掉不相关的原子建议,确保用户看到的是最可能的推荐和最短的建议列表。
推荐引擎
智能感知 2.0 的代码生成采用了我们全新设计的推荐引擎。该推荐引擎设计采用了顺序推荐系统(Sequential Recommender System,SRS)的思想:假如一个购物网站基于顺序推荐系统给用户提供购买建议,当用户购买了肥皂、洗发剂之后,它接下来可能会给用户推荐牙膏、毛巾等物品。它将(用户,物品)的交互序列作为输入,通过建模来描述嵌入在(用户,物品)交互序列中的复杂顺序依赖关系,来预测将来可能发生的交互中的(用户,物品)组合。
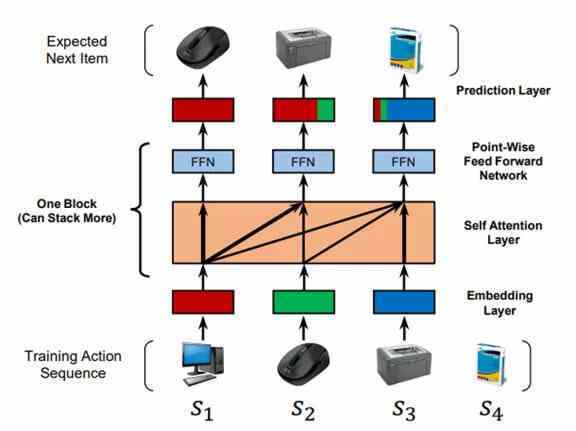
消费品顺序推荐系统
这个思想应用到代码生成中就是,通过已有代码中的原子建议的序列(已购买物品),比如“Socket”,“new PrintWriter()”,推测接下来的原子建议(未来可能购买的物品)。如下这个例子中,光标位置在“B”,光标之前是用户输入或 LLM 生成的代码,光标之后灰色代码是推荐引擎生成的补全或替换代码。至于是补全未知代码还是替换已有代码要取决于用户的场景:开发新代码还是修改/更正已有代码。

推荐引擎的架构
类似循环神经网络,它的设计初衷就是要求小而快,不能占用太多资源 - 因为它只能运行在用户本地环境。根据我们实测,它可以做到比某些 LLM 快 100 倍以上。该架构主要模块有:图卷积模块(Graph Convolution)和记忆单元模块(Memory Cell)。图卷积模块的一个作用是对代码上下文的抽象语义图(Abstract Semantic Graph,ASG)数据进行特征抽取处理,这里代码上下文即上图中白色代码部分,属于已经存在的代码。为什么要用抽象语义图而不是直接使用抽象语法书作为输入?因为抽象语义图包含更丰富的控制流图和程序依赖图的信息(包含共享子项),对结果准确性帮助很大。
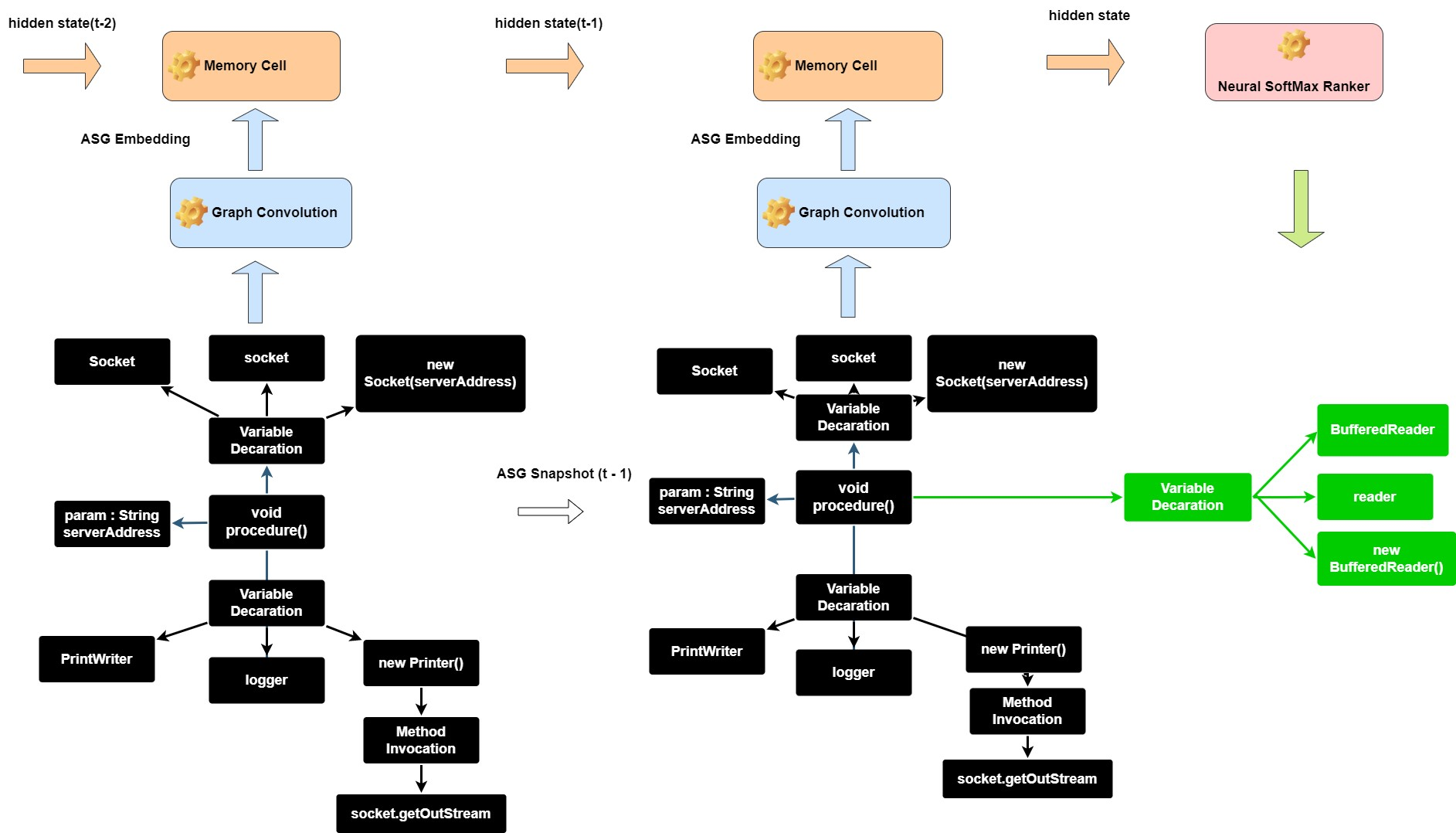
智能感知 2.0 推荐引擎架构
推荐引擎的工作流水线运行时就类似一个顺序推荐系统,抽象语义图的快照(snapshot)在每个时间步会被预测的建议而修改,图卷积模块、记忆单元模块分别对其空间结构和生长过程的动态时间状态进行评估。以抽象语义图作为主要数据结构贯穿整个推荐引擎工作流是整个架构的重大设计之一,也是“重原子建议轻符号”思想的主要技术承载。

抽象语义图(ASG)
原子推荐来源于统计代码分析知识库,这是一个在项目初始化阶段由代码模型构建的数据库。生成器基于知识库生成符合语法和语义规则的原子建议,这些原子建议基于抽象语义图中时间上下文信息组合成最终结果,并融合进新的抽象语义图的快照中。
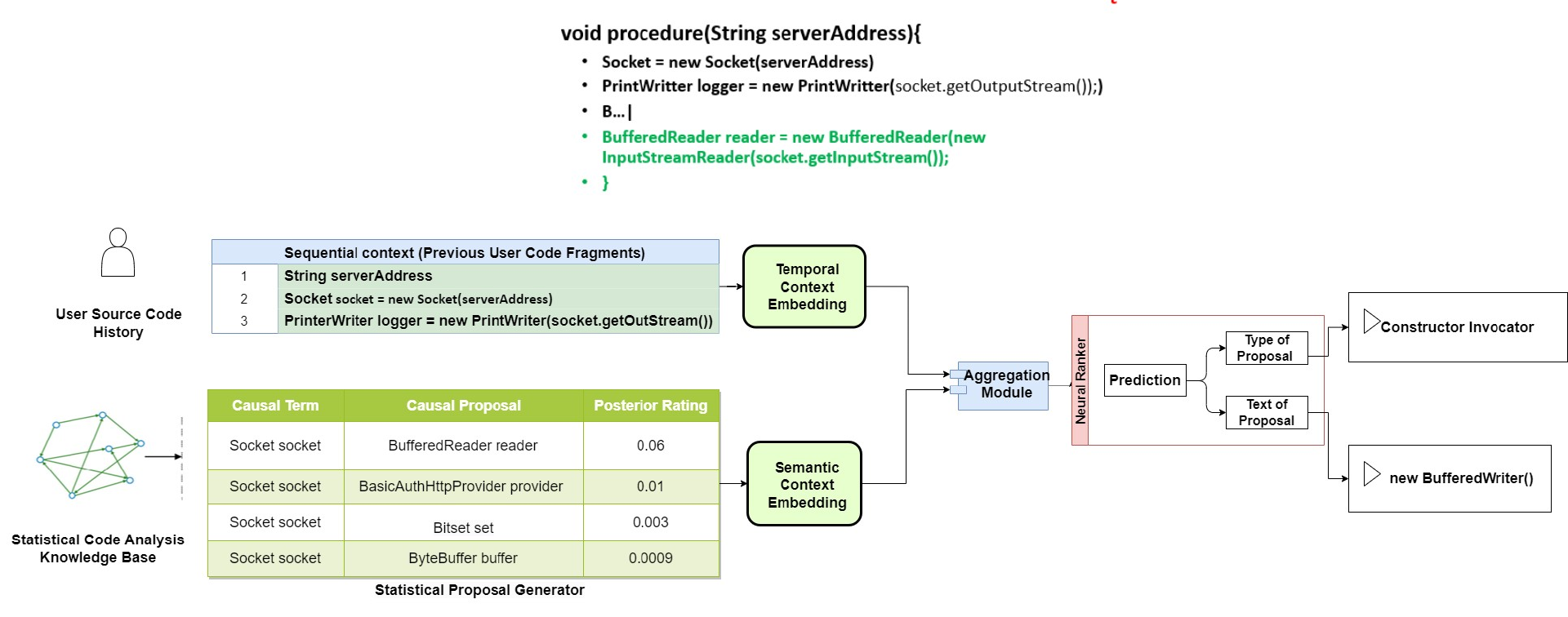
原子建议生成器
“No Silver Bullet”
LLM 问世之后,特别是 GitHub Copilot、Copilot X 这样的现象级产品出现以后,不单给我们带来了困扰,更把焦虑甚至恐惧带给了所有软件开发者。“我会被 AI 取代么?”这样的问题相信在很多人的脑海中浮现过,计算机程序员似乎正在成为被 AI 取代的高危职业之一。另外,又有报告认为,到 2030 年 AI 编程工具有望将软件开发者的生产力将提高 10 倍。然而,上述这些观点,基本都属于定性判断——基于个人的主观想象、见闻而非具体数据。
那么,AI 编程工具到底能否成为软件开发的“银弹“?我认为 Frederick P. Brooks的“没有银弹”的观点现在还是正确的,即使是高度智能化的开发工具也不是软件开发的“银弹”,因为软件开发的困难不仅仅在于如何开发程序(How & When),更在于理解要做什么以及其价值(What & Why)。即使是开发程序本身(How & When),如何运行好一个软件开发团队,让整个团队变得更高效,其中的分工、组织、协调等问题比编写代码本身更关键。
智能化的工具可以全面提升个人的开发速率,这点是毋庸置疑的。工具的智能化体验也应该是全方位和立体的,各种技术能全面融入到代码开发的各个环节。我们团队致力于做一款优秀的智能化 IDE,能让代码在指尖欢快的流淌,能让每个开发者心中的一团锦绣呼之欲出。.
作者简介:王亚伟,华为云开发工具和效率领域首席专家,华为软件开发生产线 CodeArts 首席技术总监,当前领导一支国际化软件专家团队负责华为云 CodeArts IDE 系列产品的研发和华为云开发者生态能力建设。加入华为前,曾任微软开发者事业部资深开发经理,在微软全球多个国家地区工作 13 年。近 20 年的云和开发工具的行业经验让他具备从底层技术、产品规划到开发者生态建设洞察的能力。王亚伟先生发表和被授予 20 多项软件开发技术相关的发明专利。
Pavel Petrochenko,华为俄罗斯新西伯利亚软件开发工具云技术实验室主任,首席架构师,
20 年开发者工具构建经验,曾是一家 IDE 和语言工具初创公司的创始人兼首席技术官。Eclipse DLTK Committer,Eclipse Nebula Committer,Apache Harmony Contributor。
Olga Lukianova,华为俄罗斯圣彼得堡软件开发工具云技术实验室主任,首席架构师,2006 年入职 JetBrains 圣彼得堡,历任软件工程师,首席软件工程师、Resharper 项目负责人,精通 Compilers,Parsers,Code Analysis 等技术。
延伸阅读:




