
随着近年来自然语言处理技术的飞跃式发展,许多之前很难实现的自动化效果被逐步用于互联网业务生产实际中,给我们带来了高效便捷的服务体验。本文记录了好大夫在线在搜索业务上优化问答搜索相似性效果的探索。
搜索引擎中,召回和排序是搜索流程的重要组分。当用户进行查询检索时,搜索引擎首先会检索召回大量的文档,然后根据候选文档的文本相关性、内容质量等特征,综合计算出每一个文档的排序分值,最终展现给用户,其中的核心问题包括:
理解用户在找什么;
哪些文档是和用户意图真正相关的;
哪些信息是可以信赖的优质内容;
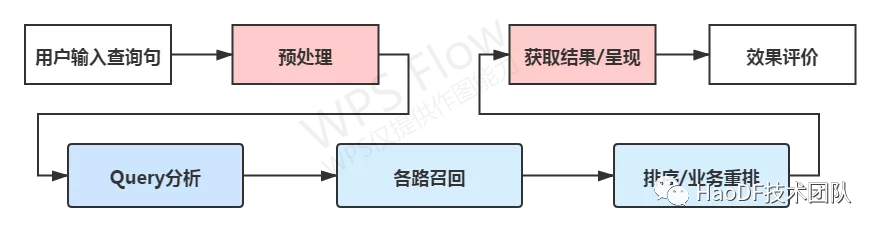
图 1:搜索流程简图
要理解这些查询,提供更好的搜索体验,用最小的成本找出用户想要的相关文档,并尽可能的把找到的相关度好的结果放到前面,让用户一眼能看到自己想要的结果(手气不错),或者让用户走火入魔陷入点了还想点的境地。
一、好大夫搜索现状和难点
在好大夫在线的搜索业务中,我们需要理解用户的检索意图,并在站内收录的病程/文章/介绍中,返回用户真正想要的结果。比如,用户在检索“感冒了能不能吃西瓜”时,除了返回“感冒”和“西瓜”相关的条目外,还应该理解用户是在找感冒条件下一些相关的科普或者提问,应该触类旁通,返回类似 “感冒了能不能吃水果” 或者 “感冒饮食禁忌” 之类的条目。
好大夫在线搜索业务的特点:
集中在医疗垂类,描述性查询非常多,涉及大量实体和知识的不规范表述(口语化);
收录的内容绝大部分经过了严格的审核,很少出现标题党和歪曲事实的东西。
传统的搜索相关性技术中,最经典的是 bm25,根据 TF-IDF 来计算查询和文档的相似度,主要考虑在词级别上的匹配,但是需要维护实体词和同义词词表,同时如果用词索引无法召回相关性好的文档,比如一些用户记不清实际的名字(如西药药品)错字少字或者描述性表示(胳臂上有好多个红点),展示出的效果就不够好,对于非专业用户来说易用性也比较差。
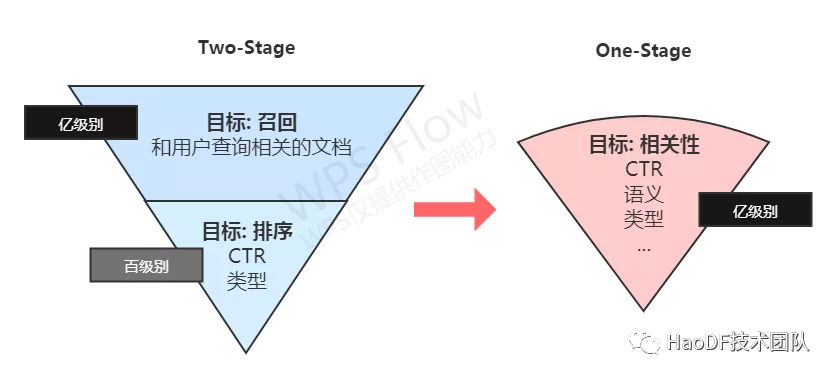
图 2:搜索召回排序的新发展方向
我们面临的难点包括并不限于:
医学知识专业性强、涵盖广泛,由于人力成本高昂,很难去发掘和标注更好的专业知识和语料;
数据基础建设不足,搜索业务积累数据少;
描述性文本的非标准化性高,真实的全召回评价标准比较难建立;
线上召回和排序响应时间需要足够短等。
二、相关性优化的目标
什么才是好的相关性?
两句话出现了很多一样的字符,有很大的概率它们是相关的,这样的结果很少;
相应句法结构上出现了同义词,也有可能是相关的,这样的依赖同义词的积累;
虽然没几个词相同,但是讲了差不多一个意思或是想要的答案,更有可能是相关的;
进一步理解用户的潜在意图,扩展到同类别或者总结性的知识,也可能是用户想要的。
所以,如果能有一种方式把语义相近的句子放在一堆,不受字符和词的约束,检索的时候去相应的堆里找,会有很大概率获得效果的提升。
于是,我们就需要一个相关性打分模型,可以输入两个句子/文档对,很快的输出一个相关性得分,语义相近的得分较高。 这样就可以把模型认为的结果放在前面让用户看到。例如判断 “手心肿痛” 跟 “手掌心肿痛” 相似性要高于 “手心起红色点,又肿又疼”,还高于 “手痒痛手臂麻”。这个排序模型要能足够准确的衡量相关性。
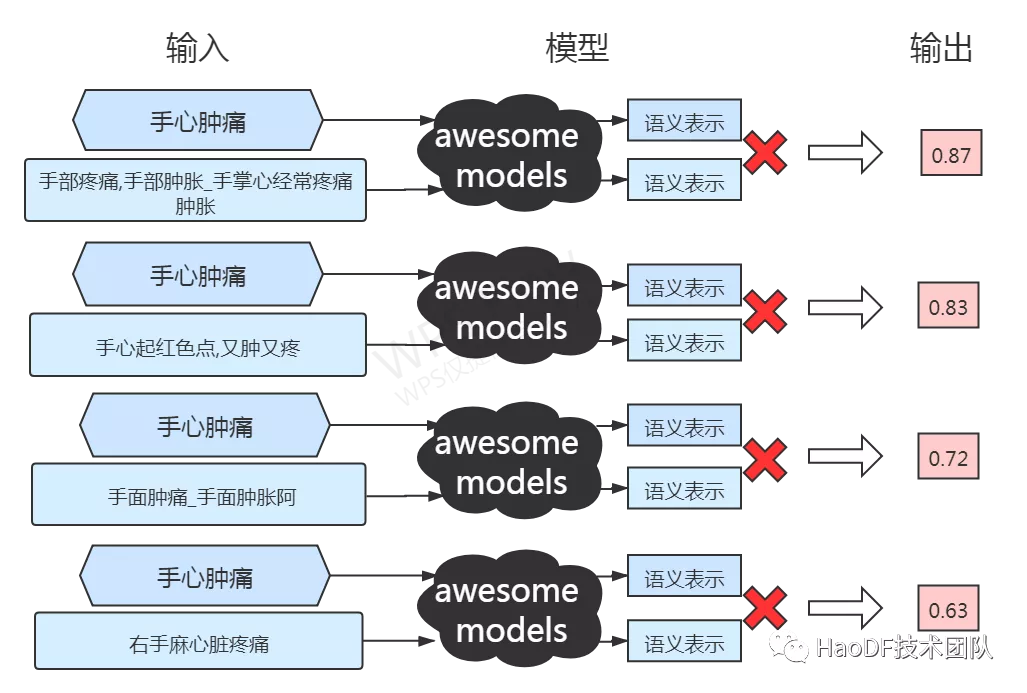
图 3:相关性优化任务示意
相似度模型训练初探索
飞速发展的自然语言处理技术已经在语义表示领域被广泛使用,可以实现类似的效果,就是把一段文本通过模型编码成一个向量,相近的意思得出的编码向量可以比较接近。从最开始的让词义相近 Word2vec 到 zero-shot 预训练模型 FLAN,模型越做越大,语义表示做的越来越好,在搜索实际业务中使用这些技术是需要一定的适配和取舍的。
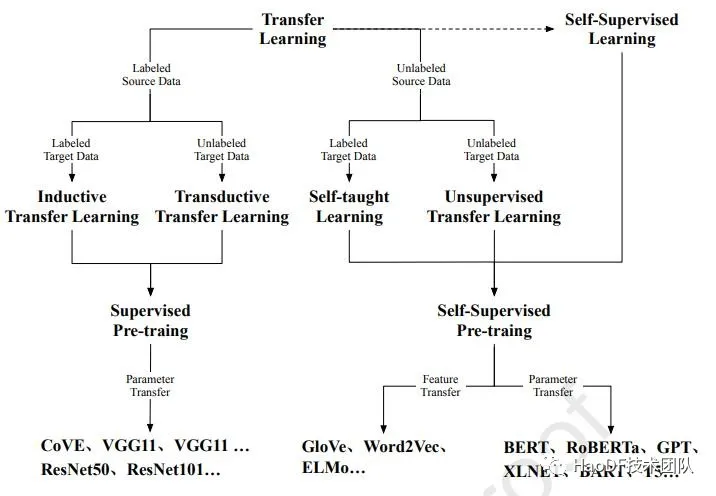
图片来源: Xu H, Zhengyan Z, Ning D, et al. Pre-Trained Models: Past, Present and Future[J]. arXiv preprint arXiv:2106.07139, 2021.
业务数据
首先是数据,数据是人工智能的基石,模型拟合的就是输入的训练数据,没数据再好的算法也出不来效果。
那么如何找到搜索需要的讲了同一个意思或者答案的句子? 搜索问答类场景下用户有明确的搜索目标,会对需求进行显式的描述,每个人的表述可能不尽相同。用户很可能会对返回的想要的结果进行点击进一步查看,所以从点击日志来的数据可以作为初步的数据。当然,这些数据存在一些问题,比如头部点击过度(排的越靠前的被点的概率越大),暴露偏差 expose-bias(展现列表没出现的不会被点击),以及获取信息后进一步决策(想找一个看乳腺结节的医生,搜索乳腺疾病医生排行,然后点了一个医院知名度高的医生)等,需要一定的清洗和处理。
我们的优势在于公司已经积累了大量医学相关的文本数据,我们都可以用来进行领域垂类预训练,以加强预训练语言模型的表示能力。
模型结构
然后是模型结构,搜索场景对服务延时有很高的要求,大模型固然效果好,从 Roberta-large 到 GPT-3 人尽皆知,但动辄上亿的参数对于我司 CPU 的线上推理十分不友好。需要相对取舍,用小的模型进行快速计算,知识蒸馏如 DistilBERT[2]/参数空间搜索 AutoTinyBERT[3]类似的操作和推理优化如 TVM[4]是少不了的。
训练任务
更重要的是训练模型的任务,让模型学什么? 如何让模型尽可能多的贴合相关性打分实际? 从 Pointwise 到 Pairwise 到 Listwise,Pointwise 方法预测每个文档和查询间的相关分数,为了学到不同文档之间的排序关系,Pairwise 方法将排序问题转换为文档间的两两比较,Listwise 方法则学习更多的文档排序之间的相互关系。从 sentence-bert[5]到 SimCSE[6],文档和查询间交互和对比的方式也在不断变化,我们对这些任务也进行了一定的试验,选用与 SimCSE 类似的对比学习正负样本方案。
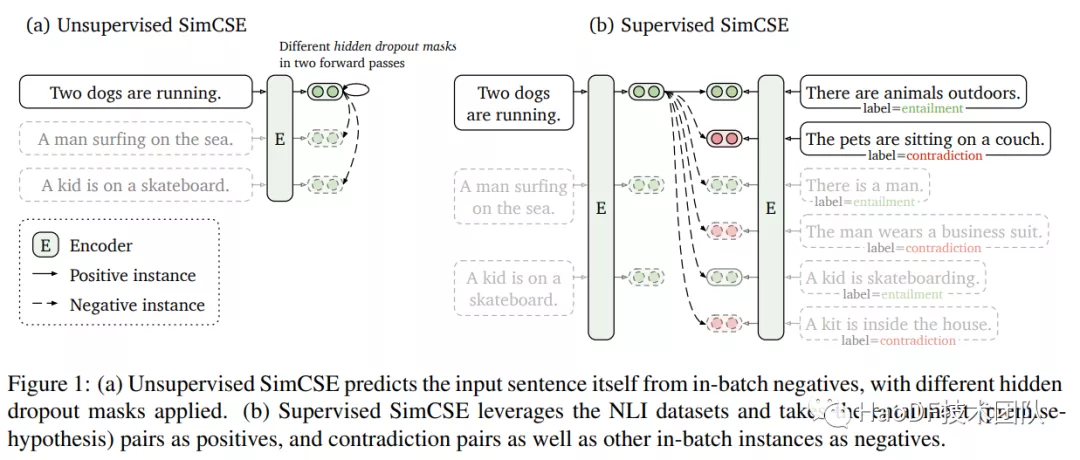
图片来源: Gao T, Yao X, Chen D. SimCSE: Simple Contrastive Learning of Sentence Embeddings[J]. arXiv preprint arXiv:2104.08821, 2021
同时参考 sentence-bert 中 embedding 话题交互带来更好的表示效果,我们也加入了一些别的模块来控制 embedding 符合相应的疾病主题或者内容主题。
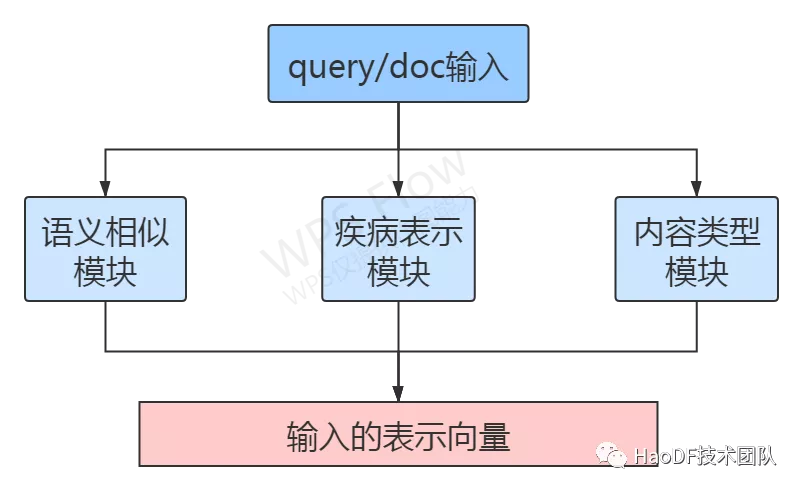
图 4:模型任务模块示意
同时一些训练技巧也是可以事半功倍的利器,如大的 batchsize,虚拟对抗训练[7](Virtual adversarial training),花式 dropout(ConSERT[8]),配合好相应的损失函数如 InfoNCE[9]/Tripletloss,都可以带来肉眼可见的鲁棒性和指标提升。
相似度模型训练优化
经过前期试验,我们用骨感的数据制作了一版模型,可以对描述性的文本做较好的近似,把相关的和不是很相关的文档区别开来。但是同时也遇到了一些问题:一些长尾的词模型不认识,如一些药品名,模型在判断相似的时候不知道应该跟哪个药品相似;还有一些查询中有好多词,模型对重要的词和可以舍弃的词理解不深,出现了一些捡了芝麻的 badcase,在虽然主题能找准,但是还不够好。
更强的训练任务
现在需要小小模型承担更强的功能,需要更严苛的训练任务承载实际的业务经验和垂类知识。受苏剑林大神[10]和 google 的 MUM 描述的启发,充分利用现有数据,从现有数据中设计出更多可能对下游任务有帮助的任务进行训练。可以利用业务数据设计任务进行无监督或者半监督学习,来提升模型的深层表示能力。考虑现在欠缺的实际,需要认识各种类别的词和相应的知识关系,在文档/查询句中找到重要的词,要分清哪些是重要的,哪些可能是可以舍弃的,对于错的词是否可以被纠正,一个文档是否可以找到最接近的查询句,查询句怎么和查询句做好负样本...
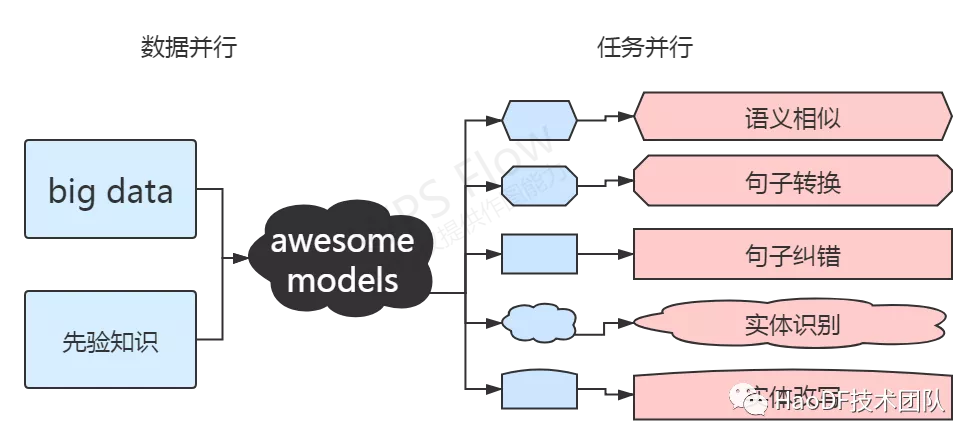
图 5:模型训练任务改进示意
于是我们根据基础数据和知识,设计了文档和查询句中相关实体的检出/替换纠错/改写对比等任务。在模型中用对比学习方式进行任务并行训练,把需要处理的各种类别文本映射到同一个抽象语义空间里,配合(am-softmax[11]/加入 KL 散度的 Regularized Dropout[12])等 loss,尽可能减小设定为相似的样本间的交互结果,扩大设定为不相似的样本之间的交互结果。
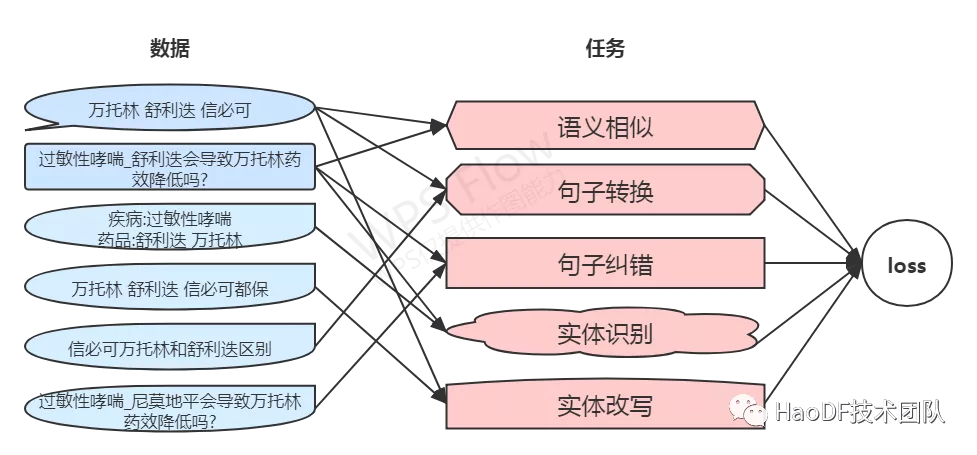
图 6:训练样本和任务示意
实体级别的意思和类别得到了更好的表示,取得了更好的效果。


图 7/8:简单效果示意
实际效果
优化上线后,用户对于问答类搜索结果的页面点击率提升了 4.6%,表明用户更愿意点击返回的搜索结果(搜索召回了更相关的结果),如图:
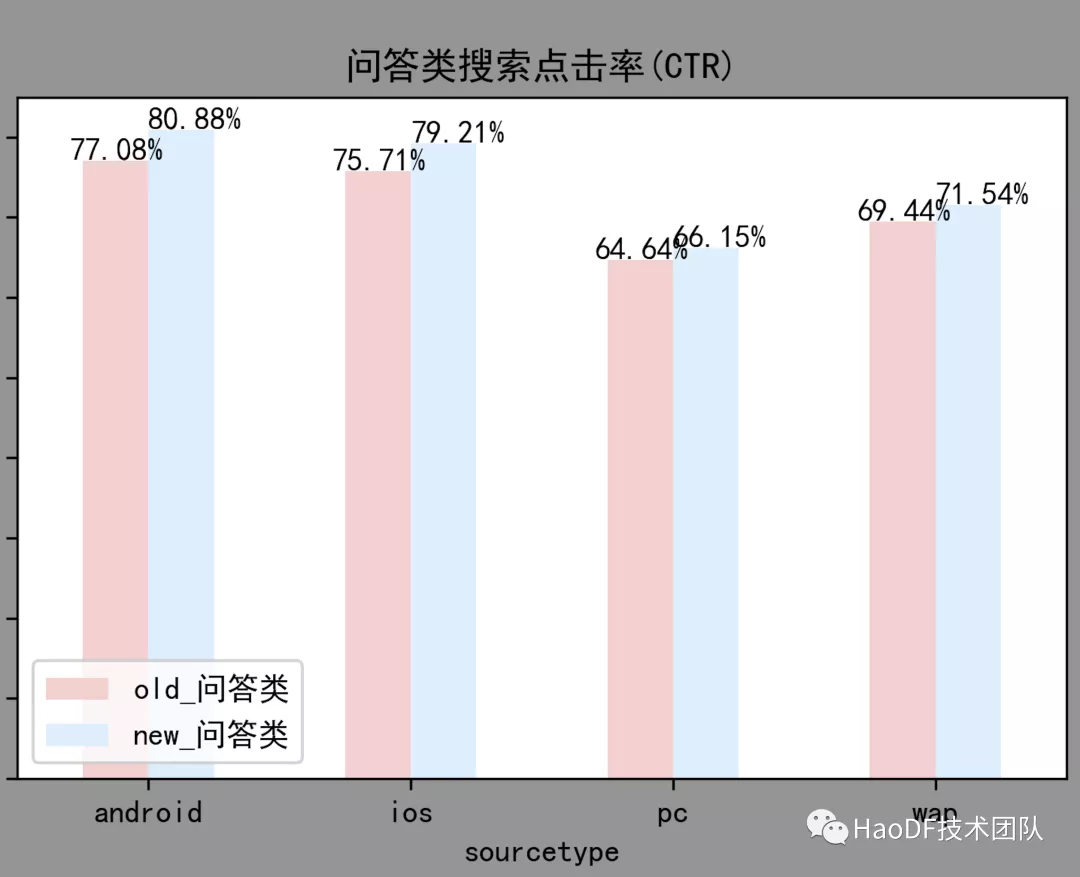
图 9:上线前后问答类点击率变化效果
此外,用户在问答类搜索结果页面的行为长度(如搜 1 次点 3 次,即行为长度为 4),也相应增加了 8.5%,表明用户点击了更多的结果(搜索结果的相关性更好),如图:
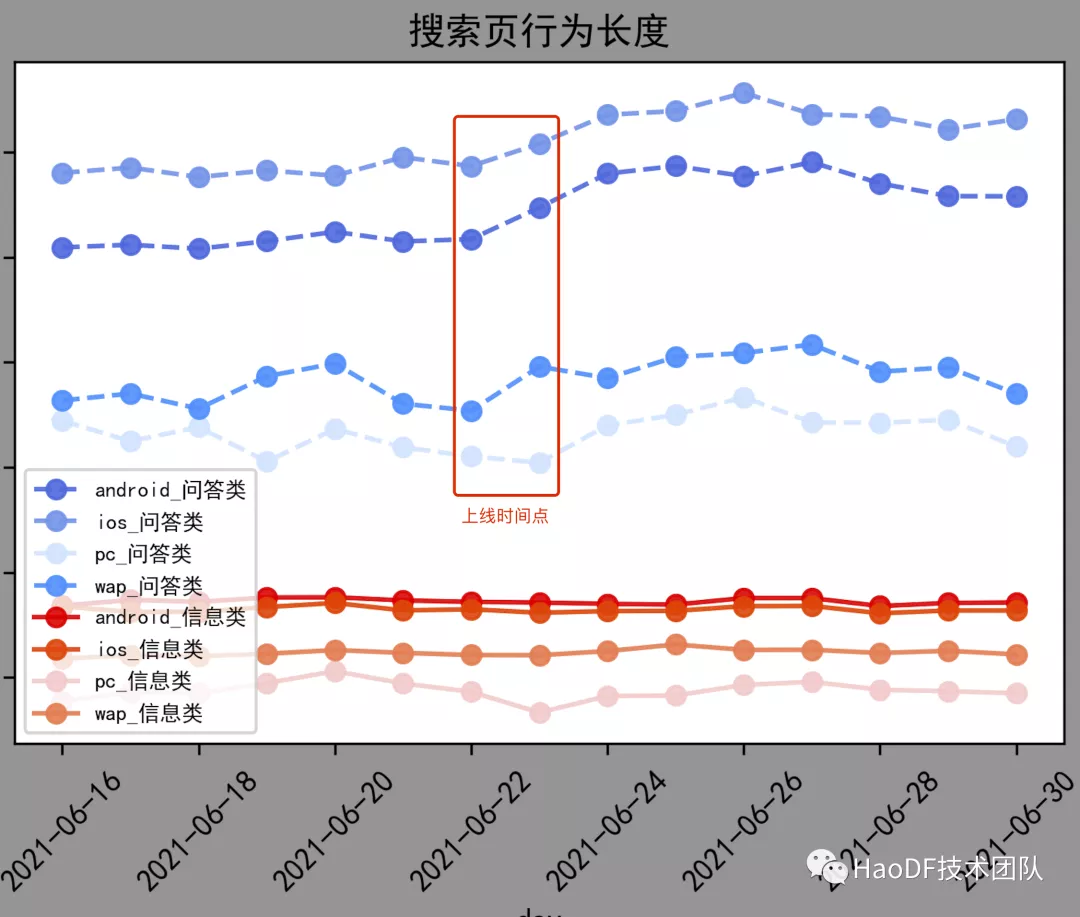
图 10:上线前后用户搜索页行为长度变化(问答类、信息类)
三、接下来的挑战
语义相似度优化上线后,通过主动用户评测及用户点击数据分析,证明我们这个优化方向是 ok 的。接下来,我们会持续以医疗相关领域知识为基础,不断完善相关的数据及模型能力。
当然,除了相似度算法模型以外,好大夫搜索还有很长的道路要走。我们希望以好大夫 15 年来积累的海量医疗内容为基础,为用户打造“最实用的医疗搜索”,做用户“简单可信赖”的小伙伴。
参考文献:
1.Xu H, Zhengyan Z, Ning D, et al. Pre-Trained Models: Past, Present and Future[J]. arXiv preprint arXiv:2106.07139, 2021.
2.Sanh V, Debut L, Chaumond J, et al. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter[J]. arXiv preprint arXiv:1910.01108, 2019.
3.Yin Y, Chen C, Shang L, et al. AutoTinyBERT: Automatic Hyper-parameter Optimization for Efficient Pre-trained Language Models[J]. arXiv preprint arXiv:2107.13686, 2021.
4.Tianqi Chen, et al. “TVM: An Automated End-to-End Optimizing Compiler for Deep Learning.” 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), 2018.
5.Reimers N, Gurevych I. Sentence-bert: Sentence embeddings using siamese bert-networks[J]. arXiv preprint arXiv:1908.10084, 2019.
6.Gao T, Yao X, Chen D. SimCSE: Simple Contrastive Learning of Sentence Embeddings[J]. arXiv preprint arXiv:2104.08821, 2021.
7.Miyato T, Maeda S, Koyama M, et al. Virtual adversarial training: a regularization method for supervised and semi-supervised learning[J]. IEEE transactions on pattern analysis and machine intelligence, 2018, 41(8): 1979-1993.
8.Yan Y, Li R, Wang S, et al. ConSERT: A Contrastive Framework for Self-Supervised Sentence Representation Transfer[J]. arXiv preprint arXiv:2105.11741, 2021.
9.Hjelm R D, Fedorov A, Lavoie-Marchildon S, et al. Learning deep representations by mutual information estimation and maximization[J]. arXiv preprint arXiv:1808.06670, 2018.
10.苏剑林. (Jun. 11, 2021). 《SimBERTv2 来了!融合检索和生成的 RoFormer-Sim 模型 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/8454
11.Wang F, Cheng J, Liu W, et al. Additive margin softmax for face verification[J]. IEEE Signal Processing Letters, 2018, 25(7): 926-930.
12.Liang X, Wu L, Li J, et al. R-Drop: Regularized Dropout for Neural Networks[J]. arXiv preprint arXiv:2106.14448, 2021.
作者简介:
曹腾:好大夫在线算法工程师,专注于自然语言处理相关技术的研究与业务落地。




