
引言
如果你在使用 Elasticsearch 的过程中,还在为构建 Elasticsearch 的 DSL 语句而苦恼,还在为构建复杂冗长的条件而头疼,还在为一次次的响应提取而奔溃,那你这时候需要一个简单方便上手的 Elasticsearch ORM 框架:ebatis!
一、背景
满帮车货匹配底层搜索引擎基于 Elasticsearch 实现,Elasticsearch 是一个分布式的开源搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。Elasticsearch Java client 方面,一般有官方提供的 Transport Client(Transport Client 在官方 7.0.0 文档中声明过时并将在 8.0.0 版本不再提供支持),Java Low Level REST Client,Java High Level REST Client(基于 Java Low Level REST Client 封装),还有 Spring 提供的 Spring Data Elasticsearch。
但我们在具体实践中使用 Elasticsearch 客户端进行搜索和迁移时,遇到了一些痛点问题,一是原有的一些旧的服务搜索基于 Transport Client 开发,因为 Transport Client 在官方 7.0.0 文档中声明过时并将在 8.0.0 版本不再提供支持,所以这些旧的服务要进行 Client 端升级改造和选型。二是进行版本的迁移,一些较新的服务的 Elasticsearch 的 Client 使用 Java High Level REST Client,原 Elasticsearch 集群使用的是 5.6.1 版本,准备升级成 7.5.1 版本集群,所以 Client 方面也需要进行相应的升级,但是在升级过程中发现 Elasticsearch Client 不同版本之间差异过大,而且目前的需求还需要继续在原有旧版本的客户端上进行开发,后续升级还需要进行一次改造,综合这些原因无法做到最终升级可以一键无缝切换。
所以目前摆在我们眼前的可选的 Client 只有 Java High Level REST Client 和 Spring Data Elasticsearch 两个 Client 可供选择,但是 Java High Level REST Client 版本之间不仅差距过大而且构建深层次复杂条件时候较为麻烦,Spring Data Elasticsearch 使用 JPA 语法,在简单的搜索场景下使用方便,但是复杂的搜索场景需要自己手动构建 DSL 语句。因此我们需要一种 Client 框架,可以帮助我们屏蔽底层 Elasticsearch 不同版本的差异和避免手动构建复杂的 DSL 语句。
基于以上背景,我们决定自研一套 Elasticsearch 框架,于是 ebatis 诞生了,目前 ebatis 已经在满帮业务系统上稳定运行近一年,承载着每日上亿次搜索服务。
二、ebatis 使用简介
ebatis 基于 Java High Level REST Client 开发,采用和 MyBatis 类似思想,只需要定义接口,便可访问 Elasticsearch,隔离业务对 Elasticserach 底层接口的直接访问。如此以来,数据访问的时候,不需要自己手动去构建 DSL 语句,同时,当升级 Elastisearch 版本的时候,只需要升级 ebatis 到相应的版本即可,业务可以完全不用关心底层 Elasticsearch 驱动接口的变动,平滑升级,并且在搜索时,以 ORM 的形式与思想构建我们的条件,极大的提升开发效率,下面我们用简单的例子先快速入门 ebatis。
创建索引
PUT /recent_order_index
{ "settings": { "number_of_replicas": 0, "number_of_shards": 1 }, "mappings": { "properties": { "cargoId": { "type": "long" }, "driverUserName": { "type": "keyword" }, "loadAddress": { "type": "text" }, "searchable": { "type": "boolean" }, "companyId": { "type": "long" } } }}增加测试数据
POST /recent_order_index/_bulk
{"index":{}}{"cargoId": 1, "driverUserName":"张三", "loadAddress": "南京市玄武区", "searchable": true,"companyId": 666}{"index":{}}{"cargoId": 2, "driverUserName":"李四", "loadAddress": "南京市秦淮区", "searchable": false,"companyId": 667}{"index":{}}{"cargoId": 3, "driverUserName":"王五", "loadAddress": "南京市六合区", "searchable": true,"companyId": 668}{"index":{}}{"cargoId": 4, "driverUserName":"赵六", "loadAddress": "南京市建邺区", "searchable": true,"companyId": 669}{"index":{}}{"cargoId": 5, "driverUserName":"钱七", "loadAddress": "南京市鼓楼区", "searchable": true,"companyId": 665}POM 依赖(目前也支持 6.5.1.1.RELEASE)
<dependency> <groupId>io.manbang</groupId> <artifactId>ebatis-core</artifactId> <version>7.5.1.3.RELEASE</version></dependency>创建集群连接
@AutoService(ClusterRouterProvider.class)public class SampleClusterRouterProvider implements ClusterRouterProvider { public static final String SAMPLE_CLUSTER_NAME = "sampleCluster"; @Override public ClusterRouter getClusterRouter(String name) { if (SAMPLE_CLUSTER_NAME.equalsIgnoreCase(name)) { Cluster cluster = Cluster.simple("127.0.0.1", 9200, Credentials.basic("admin", "123456")); ClusterRouter clusterRouter = ClusterRouter.single(cluster); return clusterRouter; } else { return null; } }}定义 POJO 对象
@Datapublic class RecentOrder { private Long cargoId private String driverUserName; private String loadAddress; private Boolean searchable; private Integer companyId;} @Datapublic class RecentOrderCondition { private Boolean searchable; private String driverUserName;}定义 Mapper 接口
@Mapper(indices = "recent_order_index")public interface RecentOrderRepository { @Search List<RecentOrder> search(RecentOrderCondition condition);}测试接口
@Slf4jpublic class OrderRepositoryTest { @Test public void search() { // 组装查询条件 RecentOrderCondition condition = new RecentOrderCondition(); condition.setSearchable(Boolean.TRUE); condition.setDriverUserName("张三"); // 映射接口 RecentOrderRepository repository = MapperProxyFactory.getMapperProxy(RecentOrderRepository.class, SampleClusterRouterProvider.SAMPLE_CLUSTER_NAME); // 搜索货源 List<RecentOrder> orders = repository.search(condition); // 断言 Assert.assertEquals(3, orders.size()); // 打印输出 orders.forEach(order -> log.info("{}", order)); }}ebatis 版本使用 xx.xx.xx.xx.RELEASE 表示,前三位代表 Elasticsearch 适配集群的驱动版本,后一位代表 ebatis 在此版本上的迭代。例如 7.5.1.3.RELEASE 表示 ebatis 在 Elasticsearch 7.5.1 版本上迭代的第三次版本。
三、其他 Client 的对比
目前,主流操作 Elasticsearch 的四种驱动方式
下面,我们用满帮车货匹配一个默认排序场景来比较一下,看看不同的驱动方式,如何进行复杂搜索操作。搜索 DSL 语句如下:
{ "query": { "bool": { "must": [ { "bool": { "must": [ { "bool": { "should": [ { "terms": { "startDistrictId": [ 684214, 981362 ], "boost": 1.0 } }, { "terms": { "startCityId": [ 320705, 931125 ], "boost": 1.0 } } ], "adjust_pure_negative": true, "boost": 1.0 } }, { "bool": { "should": [ { "terms": { "endDistrictId": [ 95312, 931125 ], "boost": 1.0 } }, { "terms": { "endCityId": [ 589421, 953652 ], "boost": 1.0 } } ], "adjust_pure_negative": true, "boost": 1.0 } } ], "adjust_pure_negative": true, "boost": 1.0 } }, { "range": { "updateTime": { "from": 1608285822239, "to": null, "include_lower": true, "include_upper": true, "boost": 1.0 } } }, { "terms": { "cargoLabels": [ "水果", "生鲜" ], "boost": 1.0 } } ], "must_not": [ { "terms": { "cargoCategory": [ "A", "B" ], "boost": 1.0 } }, { "term": { "featureSort": { "value": "好货", "boost": 1.0 } } } ], "should": [ { "bool": { "must_not": [ { "terms": { "cargoChannel": [ "长途货源", "一口价货源" ], "boost": 1.0 } } ], "should": [ { "bool": { "must": [ { "term": { "searchableSources": { "value": "ALL", "boost": 1.0 } } }, { "bool": { "must": [ { "terms": { "cargoChannel": [ "No.1", "No.2", "No.3" ], "boost": 1.0 } }, { "term": { "securityTran": { "value": "平台保证", "boost": 1.0 } } } ], "adjust_pure_negative": true, "boost": 1.0 } } ], "adjust_pure_negative": true, "boost": 1.0 } } ], "adjust_pure_negative": true, "boost": 1.0 } } ], "adjust_pure_negative": true, "boost": 1.0 } }, "_source": { "includes": [ "cargoId", "startDistrictId", "startCityId", "endDistrictId", "endCityId", "updateTime", "cargoLabels", "cargoCategory", "featureSort", "cargoChannel", "searchableSources", "securityTran" ], "excludes": [] }, "sort": [ { "duplicate": { "order": "asc" } }, { "_script": { "script": { "source": "searchCargo-script", "lang": "painless", "params": { "searchColdCargoTop": 0 } }, "type": "string", "order": "asc" } } ]}直接使用原生 Java High Level REST Client 接口方式:
final BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();final TermsQueryBuilder startCityId = QueryBuilders.termsQuery("startCityId", Lists.newArrayList(320705L, 931125L));final TermsQueryBuilder startDistrictId = QueryBuilders.termsQuery("startDistrictId", Lists.newArrayList(684214L, 981362L));final TermsQueryBuilder endCityId = QueryBuilders.termsQuery("endCityId", Lists.newArrayList(589421L, 953652L));final TermsQueryBuilder endDistrictId = QueryBuilders.termsQuery("endDistrictId", Lists.newArrayList(95312L, 931125L));final BoolQueryBuilder startBuilder = QueryBuilders.boolQuery();startBuilder.should(startCityId).should(startDistrictId);final BoolQueryBuilder endBuilder = QueryBuilders.boolQuery();endBuilder.should(endCityId).should(endDistrictId);final BoolQueryBuilder cityBuilder = QueryBuilders.boolQuery();cityBuilder.must(startBuilder);cityBuilder.must(endBuilder);queryBuilder.must(cityBuilder);final RangeQueryBuilder rangeBuilder = QueryBuilders.rangeQuery("updateTime");queryBuilder.must(rangeBuilder.from(1608285822239L));final TermsQueryBuilder cargoLabelsBuilder = QueryBuilders.termsQuery("cargoLabels", Lists.newArrayList("水果", "生鲜"));queryBuilder.must(cargoLabelsBuilder);final TermsQueryBuilder cargoCategoryBuilder = QueryBuilders.termsQuery("cargoCategory", Lists.newArrayList("A", "B"));final TermQueryBuilder featureSortBuilder = QueryBuilders.termQuery("featureSort", "好货");queryBuilder.mustNot(cargoCategoryBuilder);queryBuilder.mustNot(featureSortBuilder);final BoolQueryBuilder cargoChannelBuilder = QueryBuilders.boolQuery();queryBuilder.should(cargoChannelBuilder);final TermsQueryBuilder channelBuilder = QueryBuilders.termsQuery("cargoChannel", Lists.newArrayList("长途货源", "一口价货源"));cargoChannelBuilder.mustNot(channelBuilder);final BoolQueryBuilder searchableSourcesBuilder = QueryBuilders.boolQuery();cargoChannelBuilder.should(searchableSourcesBuilder);final TermQueryBuilder sourceBuilder = QueryBuilders.termQuery("searchableSources", "ALL");searchableSourcesBuilder.must(sourceBuilder);final BoolQueryBuilder securityTranBuilder = QueryBuilders.boolQuery();searchableSourcesBuilder.must(securityTranBuilder);securityTranBuilder.must(QueryBuilders.termsQuery("cargoChannel", "No.1", "No.2", "No.3"));securityTranBuilder.must(QueryBuilders.termQuery("securityTran", "平台保证"));SearchSourceBuilder searchSource = new SearchSourceBuilder();searchSource.query(queryBuilder);searchSource.fetchSource(new String[]{"cargoId", "startDistrictId", "startCityId", "endDistrictId", "endCityId", "updateTime", "cargoLabels", "cargoCategory", "featureSort", "cargoChannel", "searchableSources", "securityTran"}, new String[0]);searchSource.sort("duplicate", SortOrder.ASC);ScriptSortBuilder sortBuilder = SortBuilders.scriptSort(new org.elasticsearch.script.Script(ScriptType.INLINE, "painless", "searchCargo-script", Collections.emptyMap(), Collections.singletonMap("searchColdCargoTop", 0)), ScriptSortBuilder.ScriptSortType.STRING).order(SortOrder.ASC);searchSource.sort(sortBuilder);使用 Spring Data Elasticsearch 方式:
@Repositoryinterface CargoRepository extends ElasticsearchRepository<Cargo, String> { @Query("{\"match\": {\"name\": {\"query\": \"?0\.............."}}}") List<Cargo> findByCargoCondition(List<String> startCity, List<String> StartDistrictId /*,...*/);}final List<Cargo> cargos=cargoRepository.findByCargoCondition(Lists.newArrayList(320705L, 931125L),Lists.newArrayList(684214L, 981362L).........);因为 @Query 需要将整个 DSL 语句填入,篇幅有限而且长度过长,所以省略展示 。
ebatis
// 1. 创建搜货条件POJO对象@Datapublic class CargoCondition implements SortProvider { @Must private City city; @Must private Range<Long> updateTime; @Must(queryType = QueryType.TERMS) private List<String> cargoLabels; @Must private Boolean searchable; @Must private CargoLines cargoLines; @Should private CargoChannel cargoChannel; @MustNot(queryType = QueryType.TERMS) private List<String> cargoCategory; @MustNot private String featureSort; private static final Sort[] SORTS = new Sort[]{Sort.fieldAsc("duplicate"), Sort.scriptStringAsc(Script.inline("searchCargo-script", Collections.singletonMap("searchColdCargoTop", 0)))}; @Override public Sort[] getSorts() { return SORTS; } @Data public static class City { @Must private StartCity startCity; @Must private EndCity endCity; } @Data public static class StartCity { @Should(queryType = QueryType.TERMS) private List<Long> startDistrictId; @Should(queryType = QueryType.TERMS) private List<Long> startCityId; } @Data public static class EndCity { @Should(queryType = QueryType.TERMS) private List<Long> endDistrictId; @Should(queryType = QueryType.TERMS) private List<Long> endCityId; } @Data public static class CargoChannel { @MustNot(queryType = QueryType.TERMS) private List<String> cargoChannel; @Should private Security security; } @Data public static class Security { @Must private String searchableSources; @Must private SecurityChannel securityChannel; } @Data public static class SecurityChannel { @Must(queryType = QueryType.TERMS) private List<String> cargoChannel; @Must private String securityTran; } @Data public static class CargoLines { @Must(queryType = QueryType.TERMS) private List<String> cargoLines; @Must private CargoLabel cargoLabel; } @Data public static class CargoLabel { @Must(queryType = QueryType.TERMS) private List<String> cargoLines; @Must(queryType = QueryType.TERMS) private List<String> cargoLabels; }}// 2. 创建搜索接口@Mapper(indices = "cargo")public interface CargoMapper { @Search List<Cargo> searchCargo(CargoCondition condition);} // 3. 拼装搜获条件final CargoCondition cargo = new CargoCondition();CargoCondition cargo = new CargoCondition();final CargoCondition.City city = new CargoCondition.City();cargo.setCity(city);final CargoCondition.StartCity startCity = new CargoCondition.StartCity();city.setStartCity(startCity);startCity.setStartCityId(Lists.newArrayList(320705L,931125L));startCity.setStartDistrictId(Lists.newArrayList(684214L,981362L));final CargoCondition.EndCity endCity = new CargoCondition.EndCity();city.setEndCity(endCity);endCity.setEndCityId(Lists.newArrayList(589421L,953652L));endCity.setEndDistrictId(Lists.newArrayList(95312L,931125L));cargo.setUpdateTime(Range.ge(System.currentTimeMillis()));cargo.setCargoLabels(Lists.newArrayList("水果","生鲜"));final CargoCondition.CargoChannel cargoChannel = new CargoCondition.CargoChannel();cargo.setCargoChannel(cargoChannel);cargoChannel.setCargoChannel(Lists.newArrayList("长途货源","一口价货源"));final CargoCondition.Security security = new CargoCondition.Security();cargoChannel.setSecurity(security);security.setSearchableSources("ALL");final CargoCondition.SecurityChannel securityChannel = new CargoCondition.SecurityChannel();security.setSecurityChannel(securityChannel);securityChannel.setCargoChannel(Lists.newArrayList("No.1","No.2","No.3"));securityChannel.setSecurityTran("平台保证");cargo.setCargoCategory(Lists.newArrayList("A","B"));cargo.setFeatureSort("好货");// 4. 执行搜索final List<Cargo> cargos = cargoMapper.searchCargo(condition);从以上对比可以看出 ebatis 与 Spring Data Elasticsearch 相对原生 Client 构建搜索条件要方便很多,实际应用中,在复杂搜索场景条件多变的情况下,如果使用 Spring Data Elasticsearch 构建条件,在条件复杂场景下,需要自己构建原始 DSL 语句,例如:@Query("{"match": {"name": {"query": "?0.............."}}}"),在复杂场景下条件的构建会非常复杂且难以直观的定位。使用 ebatis 最大的优点在于可以直观的以 ORM 形式构建我们的搜索条件,以面向对象的思想面对我们复杂的搜索场景,无论是条件的构建还是问题的定位,都相比 Java High Level REST Clien 和 Spring Data Elasticsearch 方便的多。
还有,搜索条件总是在变的,要调整的话,如果是原生接口和 Spring,需要你不断的调整语句,甚至修改接口,但是 ebatis,只需要你正常的修改一个 POJO 对象的属性,非常的高效。
四、ebatis 进阶使用
执行类图
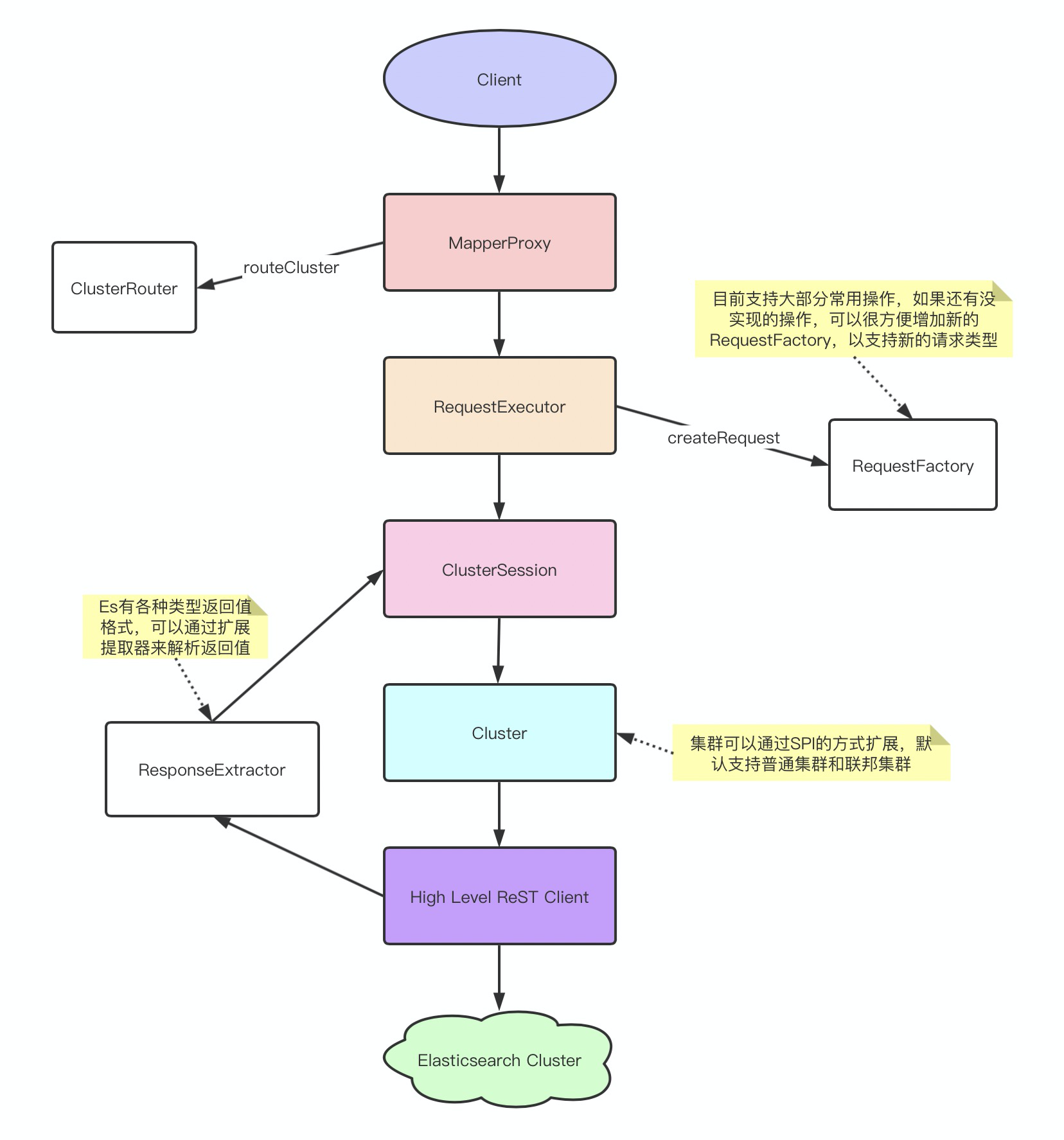
RequestExecutor:请求执行器,负责整个 Elasticsearch 请求的执行流程。
RequestFactory:求工厂接口,根据请求的方法定义和实参,创建 ES 请求。
Cluster:集群,负责 Elasticsearch 集群请求。
ResponseExtractor:响应提取器,提取 Elasticsearch 响应,构造返回体。
Interceptor:拦截器,负责 ebatis 调用过程的拦截。
Cluster
Cluster 代表一个 ES 集群实例,ebatis 内建了两个实现:SimpleCluster,FixWeightedCluster 和 SimpleFederalCluster。 SimpleCluster 和 FixedWeightedCluster 的区别在于,后者是带固定权值的值,在对集群做负载均衡的时候,可以通过权值来控制负载的比例。SimpleFederalCluster 的特殊地方在于,在一批集群上做批量操作,同步一批集群,一般用于一批集群数据的增删改,不适用于查。
ClusterRouter
ClusterRouter 用于路由出一个可以访问 Cluster,内部是通过负载均衡器 ClusterLoadBalancer,来同一组集群中,选中一个集群的。根据不同的负载均衡器,ebatis 内建了多个对应的路由器,默认提供的有随机负载均衡器,轮询负载均衡器,单集群均衡器,权重负载均衡器,当然也可以通过 ebatis 提供的接口,定制自己的策略均衡器。
接口定义支持的请求类型及响应类型
Entity 指具体的实体类型
以上是目前支持的搜索类型,其他的请求类型还需后续的迭代支持。
异步支持
Mapper 搜索方法支持异步操作,只需要将 Mapper 接口返回结果定义为 CompletableFuture
拦截器
ebatis 中拦截器的加载通过 SPI 方式实现,只需要提供的目标类实现 io.manbang.ebatis.core.interceptor.Interceptor 接口,并且在/META-INF/services 目录下提供 io.manbang.ebatis.core.interceptor.Interceptor 文件,内容为提供的目标类的全限定名。也可以在目标类上加上注解 @AutoService(Interceptor.class),由 auto-service 替我们生成。拦截器的不同接口在请求的整个生命周期的不同阶段调用,可以自定符合自己业务逻辑的拦截器。
@Slf4j@AutoService(Interceptor.class)public class TestInterceptor implements Interceptor { @Override public int getOrder() { return 0; } @Override public void handleException(Throwable throwable) { log.error("Exception", throwable); } @Override public void preRequest(Object[] args) { ... //通过ContextHolder可以跨上下文获取绑定的值 String userId = ContextHolder.getString("userId"); } @Override public <T extends ActionRequest> void postRequest(RequestInfo<T> requestInfo) { ... } @Override public <T extends ActionRequest> void preResponse(PreResponseInfo<T> preResponseInfo) { ... } @Override public <T extends ActionRequest, R extends ActionResponse> void postResponse(PostResponseInfo<T, R> postResponseInfo) { ... }}与 spring 的集成,首先增加 POM 依赖
<dependency> <groupId>io.manbang</groupId> <artifactId>ebatis-spring</artifactId> <version>7.5.1.3.RELEASE</version></dependency>增加 Config
@Configuration@EnableEasyMapper(basePackages = "io.manbang.ebatis.sample.mapper")public class EbatisConfig { @Bean(destroyMethod = "close") public ClusterRouter clusterRouter() { Cluster cluster = Cluster.simple("127.0.0.1", 9200, Credentials.basic("admin", "123456")); ClusterRouter clusterRouter = ClusterRouter.single(cluster); return clusterRouter; }}五、总结
ebatis 更详细使用文档可见:https://github.com/ymm-tech/ebatis,如果需要更多的帮助请联系我们,如果觉得 ebatis 帮到了您,请给我们的 github 点点⭐。
胡维龙:现为满帮中间件二组研发工程师,参与满帮基础设施建设,目前负责满帮重力系统建设。
章多亮:现任满帮应用层云原生领域负责人,主导满帮混沌工程和服务网格技术发展与落地,致力于满帮稳定性的确定性,极致开发体验和效率。
如果大家对云原生感兴趣,想追求更高更有趣的挑战,愿意与团队一起成长,想参与满帮集团的基础建设,并且认可我们的愿景---让公路物流更美好,请将简历发送到邮箱:weilong.hu@amh-group.com
duoliang.zhang@amh-group.com




