
神经网络可以非常出色地执行某些任务,但它们做出决策的方式——例如,图像中的哪些信号导致模型认为它属于一类而不是另一类——通常是一个谜。如果能解释神经模型的决策过程,可能会在某些领域产生重大的社会影响,例如医学图像分析和自动驾驶等;在这些领域,人工监督是至关重要的。这些见解还有助于指导医疗保健服务方、揭示模型偏差、为下游决策者提供支持,甚至能帮助科学发现过程。
以前对分类器进行视觉解释的方法(例如Grad-CAM这样的注意力图)会强调图像中的哪些区域影响分类结果,但它们没有解释这些区域中的哪些属性决定分类结果,例如,是它们的颜色?它们的形状?还有一类方法通过在一类和另一类之间平滑转换图像来提供解释(例如GANalyze)。然而,这些方法往往会同时改变所有属性,因此难以隔离影响个体的属性。
在 ICCV 2021 上发表的“Explaining in Style: Traininga GAN to explaina classifier in StyleSpace”这篇文章中,我们提出了一种视觉解释分类器的新方法。我们的方法名为 StylEx,可自动发现和可视化影响分类器的解耦(disentangled)属性。它允许通过单独操作这些属性来探索单个属性的影响(更改一个属性不会影响其他属性)。StylEx 适用于广泛的领域,包括动物、树叶、面部和视网膜图像。我们的结果表明,StylEx 找到的属性与语义属性非常吻合,可生成有意义的、特定于图像的解释,并且在用户研究中可以被人们解释。

例如,要了解一个猫与狗的分类器在给定图像上的效果,StylEx 可以自动检测分离的属性,并通过可视化展示操作每个属性是如何影响分类器概率的。然后用户可以查看这些属性并对它们所代表的内容进行语义解释。例如,在上图中,可以得出“狗比猫更容易张开嘴”(上图 GIF 中的属性 #4)、“猫的瞳孔更像狭缝”(属性 #5)、“猫的耳朵不倾向于折叠”(属性 #1),等等结论。
下面的视频提供了该方法的简短说明:
StylEx 的工作原理:训练 StyleGAN 来解释分类器
给定一个分类器和一个输入图像,我们希望找到并可视化影响其分类的各个属性。为此,我们使用了StyleGAN2架构,该架构以生成高质量图像而闻名。我们的方法包括两个阶段:
第 1 阶段:训练 StyleEx
最近的一项工作表明,StyleGAN2 包含一个名为“StyleSpace”的解耦潜在空间,其中包含训练数据集中图像的单个语义上有意义的属性。但是,由于 StyleGAN 训练不依赖于分类器,它可能无法代表那些对我们要解释的特定分类器的决策很重要的属性。因此,我们训练了一个类似于 StyleGAN 的生成器来满足分类器,从而鼓励它的 StyleSpace 适应分类器特定的属性。
这是用两个附加组件训练 StyleGAN 生成器来实现的。第一个是编码器,与具有重建损失的 GAN 一起训练,它强制生成的输出图像在视觉上与输入相似。这允许我们将生成器应用于任何给定的输入图像。然而,图像的视觉相似性是不够的,因为它可能不一定捕获对特定分类器(例如医学病理学)重要的细微视觉细节。为了确保这一点,我们在 StyleGAN 训练中添加了一个分类损失,它强制生成图像的分类器概率与输入图像的分类器概率相同。这保证了对分类器很重要的细微视觉细节(例如医学病理学)将包含在生成的图像中。
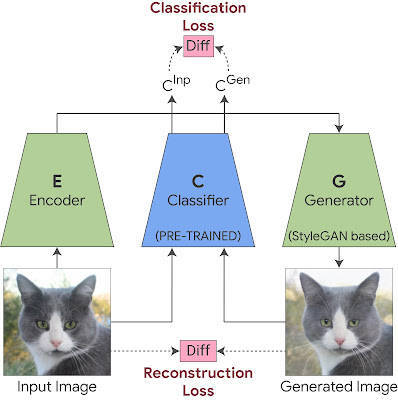
TrainingStyleEx:我们联合训练生成器和编码器。在生成的图像和原始图像之间应用重建损失以保持视觉相似性。在生成图像的分类器输出和原始图像的分类器输出之间应用分类损失,以确保生成器捕获对分类很重要的细微视觉细节。
第 2 阶段:提取分离的属性
训练完成后,我们会在经过训练的生成器的 StyleSpace 中搜索显著影响分类器的属性。为此,我们操纵每个 StyleSpace 坐标并测量其对分类概率的影响。我们寻求使给定图像的分类概率变化最大化的顶级属性。这样就有了 top-K 图像特定属性。通过对每个类的大量图像重复这个过程,我们可以进一步发现 top-K 类特定属性,这告诉我们分类器对特定类是如何理解的。我们称我们的端到端系统为“StylEx”。
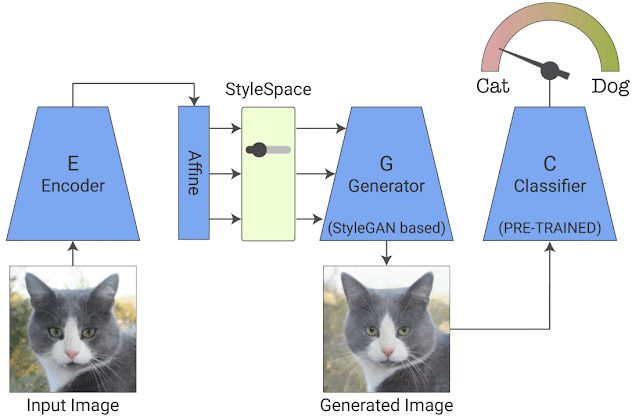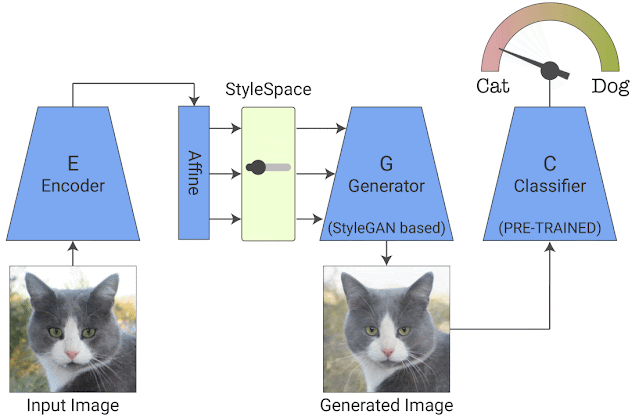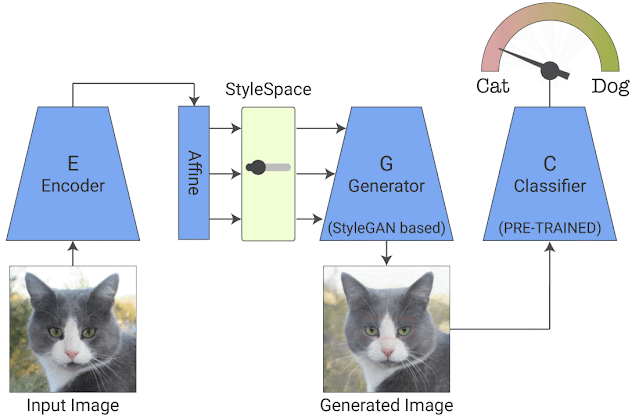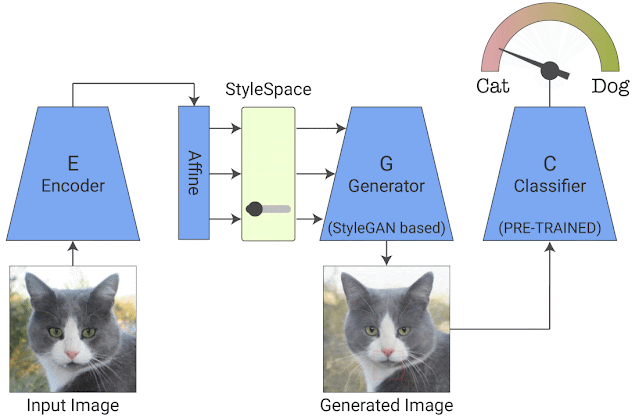
图像特定属性提取的可视化说明:一旦训练,我们搜索对给定图像的分类概率影响最大的 StyleSpace 坐标。
StylEx 适用于广泛的领域和分类器
我们的方法适用于各种领域和分类器(二元和多类)。下面是一些特定类的解释示例。在所有测试的领域中,我们的方法检测到的顶级属性在由人类解释时对应于连贯的语义概念,并通过人类评估得到验证。
对于感知的性别和年龄分类器,以下是每个分类器检测到的前四个属性。我们的方法举例说明了自动选择的多个图像上的每个属性,以最好地展示该属性。对于每个属性,我们在源图像和属性操作图像之间来回切换。操作属性对分类器概率的影响程度显示在每个图像的左上角。


请注意,我们的方法解释的是分类器,而不是现实。也就是说,该方法旨在揭示给定分类器从数据中是如何学会所利用的图像属性的;这些属性可能不一定代表现实中的类别标签(例如年轻或年长)之间的实际物理差异。特别是,这些检测到的属性可能会揭示分类器训练或数据集中的偏差,这是我们方法的另一个关键优势。它可以进一步用于提高神经网络的公平性,例如,通过增加训练数据集的示例来补偿我们的方法揭示的偏差。
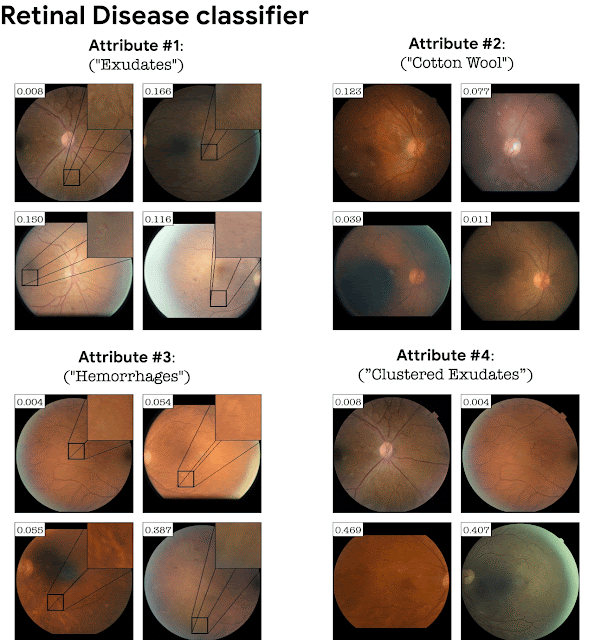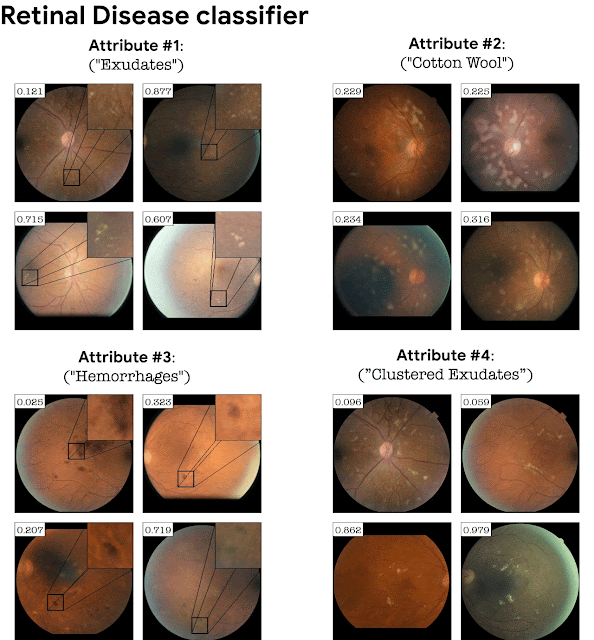
在分类过程依赖于精细细节的领域中,将分类器损失添加到 StyleGAN 训练中是非常重要的。例如,在没有分类器损失的情况下在视网膜图像上训练的 GAN,不一定会生成与特定疾病相对应的精细病理细节。添加分类损失会导致 GAN 生成这些微妙的病理学信息作为分类器的解释。下面以视网膜图像分类器(DME疾病)和病/健康叶子分类器为例。StylEx 能够发现与疾病指标一致的属性,例如“硬渗出物”(这是众所周知的视网膜 DME 标记),以及叶子疾病的腐烂现象。
自动检测到的病/健康叶子图像分类器的 Top-4 属性。
最后,该方法也适用于多类问题,如 200 路鸟类分类器所示。

在CUB-2011上训练的 200 路分类器中,自动检测到的(a)“brewer blackbird”类和(b)“yellow bellied flycatcher”类的 Top-4 属性。事实上,我们观察到 StylEx 检测到与 CUB 分类中的属性相对应的属性。
更广泛的影响和后续计划
总的来说,我们引入了一种新技术,可以为给定图像或类上的给定分类器生成有意义的解释。我们相信,我们的技术是朝着检测和缓解分类器和/或数据集中先前未知的偏差迈出的有希望的一步,符合谷歌的 AI 原则。
此外,我们对基于多属性的解释的关注是提供关于以前不透明的分类过程的新见解和帮助科学发现过程的关键。最后,我们的 GitHub存储库包括了一个 Colab 和我们论文中使用的 GAN 的模型权重。
原文链接:https://ai.googleblog.com/2022/01/introducing-stylex-new-approach-for.html




