
本文要点
DuckDB 是一款专为分析数据管理设计的开源 OLAP 数据库,与 SQLite 类似,这是一款可被嵌入到应用中的进程中数据库。
进程中的数据库引擎处于应用之中,允许同一内存地址空间内的数据传输,不再需要通过套接字复制大量数据,从而提升了性能。
DuckDB 利用矢量处理查询,允许在 CPU 缓存中的有效操作,最小化函数调用开销。
DuckDB 所使用的小块数据驱动(Morsel-Driven)的并行,允许在多个核心上有效并行化的同时,保留对对核心处理的认知。
我为什么要踏上这条构建新数据库的旅程?这还要从著名统计学家和软件开发者 Hadley Wickham 的一句话说起:
把能放到内存中的数据放到数据库中是没有任何好处的,只会更慢更让人头疼。
这句话对我们这些数据库研究者而言既是打击也是挑战。是什么让数据库变得慢且头疼呢?罪魁祸首首先要数客户端 - 服务器模式。
在进行数据分析、将大量数据从应用转移至数据库,或者是将数据从数据库中提取到 R 或 Python 这类分析环境中时,整个过程可能会慢到折磨。
我曾试图理解客户端 - 服务器这一架构模式的起源,并撰写了论文《不要挟持我的数据——客户端协议重设案例》。
我对比了各类数据管理系统中的数据库客户端协议,计算了在客户端程序和不同数据库系统中,传输固定大小数据集所需要的时间。
我以 Netcat 工具通过网络套接字传输相同数据集的情况作为基准:
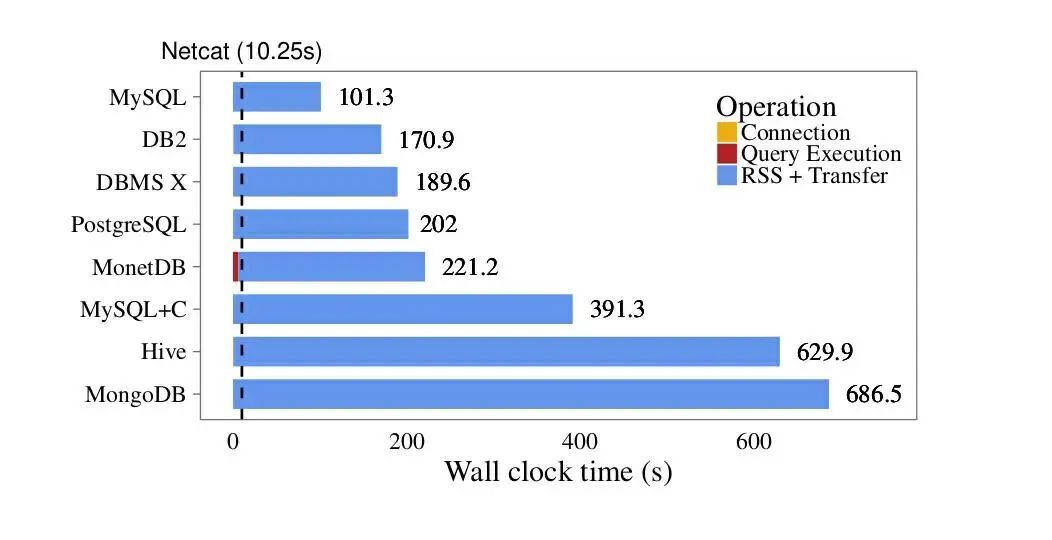
图一:不同客户端的对比,虚线为 Netcat 传输 CSV 数据所需的实际时间
对比 Netcat,MySQL 传输同样大小的数据需要十倍长的时间,Hive 和 MongoDB 则需要超过一个小时的时间。这个客户端 - 服务器模式似乎充满了问题。
SQLite
我又想起了 SQLite,坐拥数十亿份拷贝的 SQLite 无疑是世界上使用最为广泛的 SQL 系统。它们几乎时无处不在,人们每天都在与几十、乃至上百的实例打交道,但却意识不到。
SQLite 在进程中运行,这种不同以往的架构方式将数据库的管理系统直接整合到客户端应用之中,避免了传统的客户端 - 服务器模式。数据可直接在同一内存地址中进行传输,不再需要通过套接字复制和序列化大量数据。
然而,SQLite 并不是为大规模数据分析而设计,它的主要目的是为处理事务性工作负载。
DuckDB
几年之前,Mark Raasveldt 和我一同开始研究新数据库 DuckDB。DuckDB 是完全由 C++ 编写数据库管理系统,采用矢量执行引擎,作为一款进程中数据库引擎,我们常常称其为“分析性 SQLite”。该项目在极其宽松的 MIT 许可下发布,由基金会管理运作,而不是传统的风险投资模式。
DuckDB 的交互是什么样的?
import duckdbduckdb.sql('LOAD httpfs')duckdb.sql("SELECT * FROM 'https://github.com/duckdb/duckdb/blob/master/data/parquet-testing/userdata1.parquet'").df()在这短短几行中,DuckDB 以 Python 包的形式导入,加载了一个扩展以实现与 HTTPS 资源的通信,通过 URL 读取了一份 Parquet 文件并将其转换为 Panda 数据框架(DF)。正如这个例子中所示,DuckDB 可直接支持 Parquet 文件,我们将其视作是新版 CSV 文件。LOAD httpfs 调用则展示了 DuckDB 是如何通过插件进行扩展。
DF 的转换过程中隐含了许多复杂的工作,涉及到一个可能包含几百万行结果集的传输。但由于是在同一地址空间内进行的操作,我们可以绕过序列化或套接字传输,让整个过程快到难以置信。
我们还开发了一个具备查询语句自动完成和 SQL 语法高亮等功能的命令行客户端。例如,我在电脑上启动一个 DuckDB shell,读取同一个 Parquet 文件:
如果想用这条查询语句:
SELECT * FROM userdata.parquet;会发现传统的 SQL 系统在这里通常不太行。userdata.parquet 是个文件而不是表,没有 userdata.parquet 这张表,但却有这个 Parquet 文件。如果找不到叫这个名字的表,DuckDB 会搜索该名称的其他实体并执行查询语句,如 Parquet 文件。
进程中分析
从架构的角度来说,DuckDB 有一个新的数据管理系统类别:进程中 OLAP 数据库。
SQLite 是面向 OLTP(在线事务处理)的进程中系统,但对于传统 OLTP 客户端 - 服务器架构而言,PostgreSQL 反而是更常见的选择。
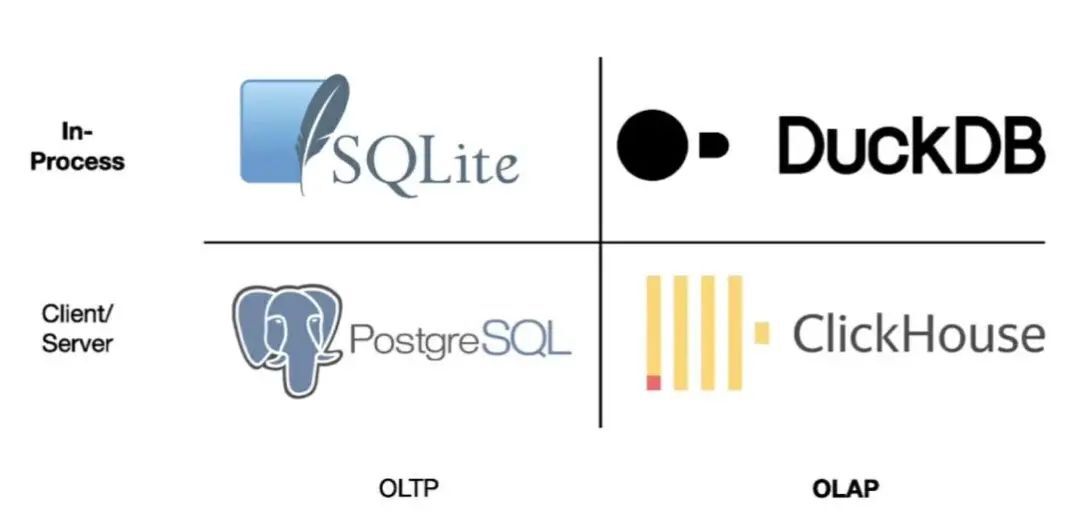
图二:OLTP 对比 OLAP
对于 OLAP 而言,客户端 - 服务器系统有不少的可选项,其中便有最为公认的开源选项 ClickHouse。但在 DuckDB 出现之前,进程中 OLAP 还没有任何选项可言。
DuckDB 的技术方面
让我们来看看 DuckDB 的技术层面,从下面这条 SQL 语句的处理阶段开始:
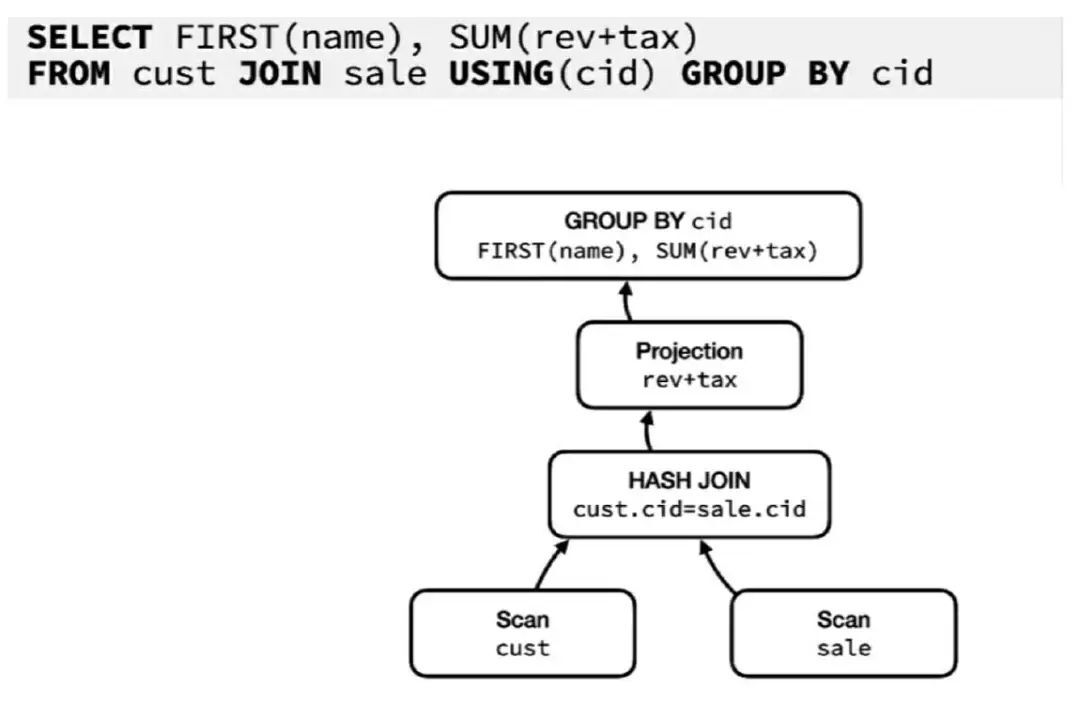
图三:DuckDB 中的一条简单选择语句
在这段示例中,我们从共用 cid 列的 customer 和 sale 这两张表的 JOIN 中选择名字和总和,通过将客户(customer)的所有收入和交易的税金相加,从而计算每个客户的总收入。
在运行这条语句时,系统会将两张表相连(JOIN),根据 cid 列的值对客户进行汇总。随后系统会计算对应的 revenue + tax,再按照 cid 进行分组聚合,从而得出名字和最终总和。
DuckDB 对这条语句的处理有如下几个标准阶段:查询规划、查询优化、物理规划。其中查询规划阶段又被进一步划分为所谓的管道。
举例来说,这段查询有三个管道,由它们在流中运作的方式定义。流在中断操作符,也就是需要取回全部输入时结束。
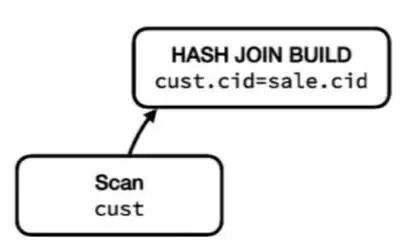
图四:第一管道
首条管道负责扫描 customer 表并构建一个哈希表。哈希的连接(join)被分为两个阶段,构建哈希列表和探测。哈希表的构建通常需要能接触到 join 左侧的所有数据,也就是说 customer 表必须全部被执行并输入到 hash join build 阶段。这一管道完成后,我们将进入第二管道。
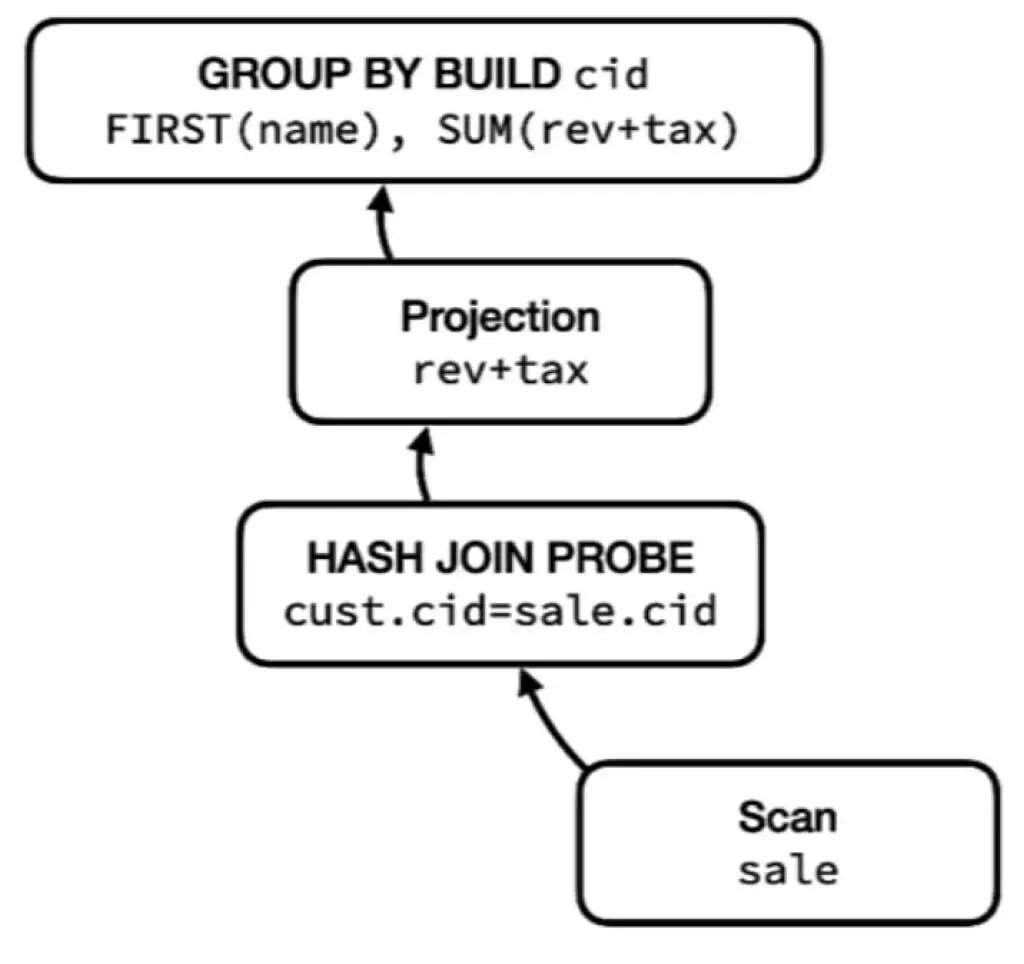
图五:第二管道
第二条管道更大且包含更多流运算符:可扫描 sales 表,查看上一步构建的哈希表,从 customer 表中找到相连的伙伴,随后对 revenue + tax 一行进行对应并执行聚合以及中断操作符,最后再执行 group by build 阶段从而完成第二管道。
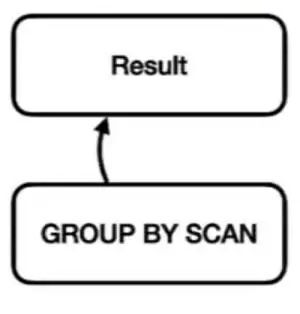
图六:第三管道
我们可以让第三和最后一条管道,使其读取 GROUP BY 的结果并输出最终结果。这是段非常标准的过程,许多数据库都采取了类似的查询规划方法。
一次一行
要想理解 DuckDB 对查询语句的处理,让我们先看看传统火山迭代模型是如何在一系列迭代器中,让所有操作符都以一个迭代器为输入的同时暴露另一个迭代器。
语句的执行从最上层的运算符读取开始,也就是例子中的 GROUP BY BUILD 阶段。但此时因为还没有任何数据进入,所以它还读取不到任何东西。这也就触发了对其子运算符(映射)的读取请求,后者再从它自己的子运算符 HASH JOIN PROBE 中读取,该过程会逐级向下,直到最终的 sale 表。
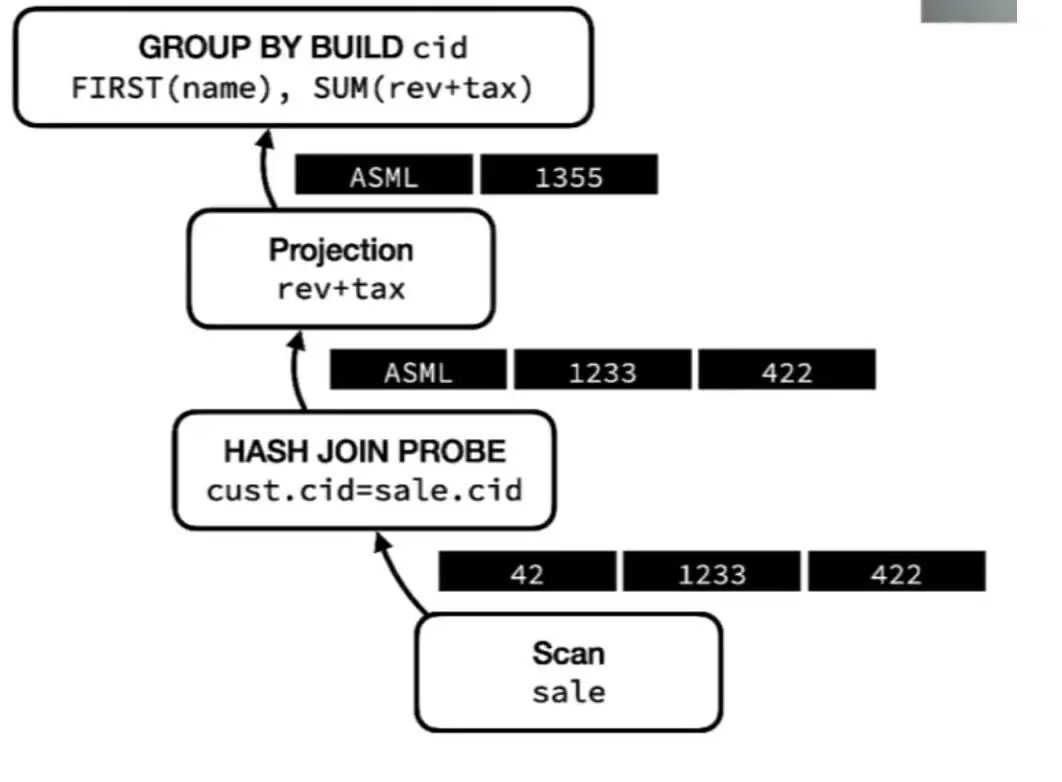
图七:火山迭代模型
sale 表会生成一个元组以代表 ID、收入(revenue)以及税款这三列,比如 42、1233、422。该元组会向上移动到 HASH JOIN PROBE 并查询其建立的哈希表。比如,在知道 ID 42 对应的是 ASML 公司后,它会生成新的一行作为连接结果,也就是 ASML、1233、42。
新生成的这一行随后会被下一个运算符处理,映射运算符会将最后两列相加,从而生成新的一行:ASML、1355。这一行最终会进入 GROUP BY BUILD 阶段。
这种一次一个元组、一次一行,以“行”为重点的方式在 PostgreSQL、MySQL、Oracle、SQL 服务器,以及 SQLite 等众多数据库系统中都很常见,在事务性用例中非常有效,但却在数据分析处理方面存在一个明显的弱点:在运算符和迭代器之间的不断切换,会产生巨大的开销。
理论上来说是可以通过及时(JIT)编译整条流水线,这条方案虽然可行,但却不是唯一的解决方案。
一次一矢量
让我们考虑简单的流式运算符操作,比如映射。

图八:映射的实现
我们将传入一行和部分伪代码:input.readRow 会读取一行输入,将第一个数值不变,但输出的第二个值会变成输入的第二和第三个相加之和,随后这行输出会被写入。这种方式虽然实施起来简单,但由于每一次数值读取都需要函数调用,因此会产生巨大的性能成本。
这种“一次一行”模型可优化为“一次一矢量”模型,该模型概念首次于 2005 年的“MonetDB/X100:超管道查询执行”中被首次提出。
对这类模型而言,每次处理的不再是单一的值,而是被统称为矢量的几列;每次处理的也不是一行中的一个值,而是列中的多个值。类型的切换是在多个值的矢量中进行,而不是单行数值上,因此这种方式可减少开销。
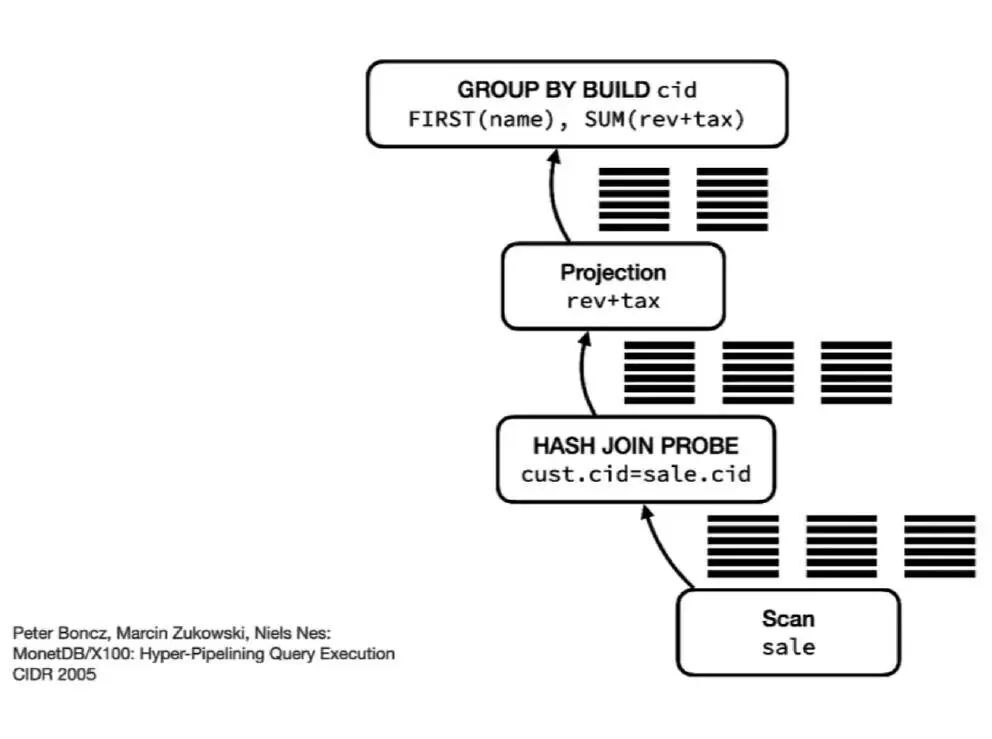
图九:“一次一矢量”模型
“一次一矢量”模型在列和行的执行之间找到了平衡点。按列执行的高效性是以内存为代价的,通过将列的数量控制在一定范围内,这种“一次一矢量”模型能避免 JIT 编译的同时,促进局限性缓存,后者对效率而言是至关重要的。
在著名的“人人都应知道的延迟数据”中展示了缓存局限性的重要性。
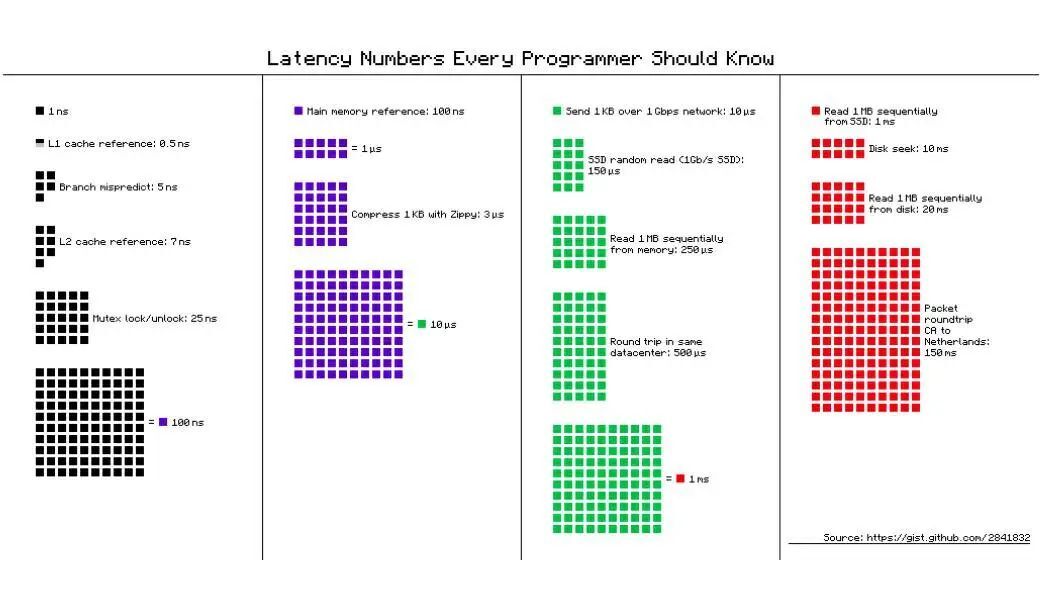
图十:人人都应知道的延迟数据
这张图由谷歌的 Peter Norvig 和 Jeff Dean 提出,高亮了 L1 缓存引用(0.5 纳秒)和猪内存引用(100 纳秒)之间差距为 200 倍。而考虑到 1990 年起 L1 的缓存引用就已经快了 200 倍,而内存引用只加快了两倍,将操作放在 CPU 缓存中是具有极大优势的。
这也就是矢量查询的魅力所在。

图十一:通过矢量查询处理实现映射
让我们再回到之前的 revenue + tax 映射例子。这次我们不再只取一行,而是用三个矢量值作为输入,两个矢量作为输出。我们读取的不再是之前的一行,而是一小块数据(多个矢量列的集合)。第一个矢量保持不变,并被重新分配至输出;随后再创建新的结果矢量,对 0 到 2048 范围内的每一个单独值进行加法运算。
这种方式允许编译器自动插入特殊指令,仅在矢量级进行的数据类型解释和转换也避免了函数调用的开销。这就是矢量处理的核心所在。
并行交换
单 CPU 的高效率对矢量处理而言还不够好,它还需要能在多个 CPU 上有良好的表现。我们又是如何支持并行的呢?
谷歌首席科学家 Goetz Graefe 在他的论文《火山——可扩展的并行查询评估系统》中描述了交换器并行的概念。
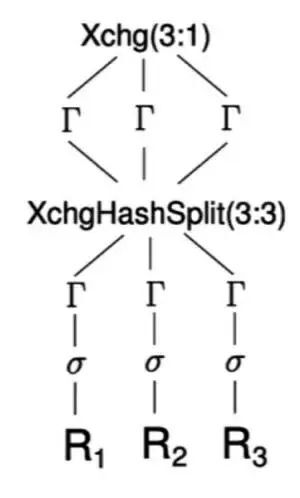
图十二:交换运算符的并行
在这个例子中,三个分区同时读取。应用过滤器、数据预聚合,之后再哈希。数据根据哈希值被分割,进一步聚合、重聚合,最后输出被合并。这样一来,查询的大部分都能被有效地并行化。
举例来说,这种方式在 Spark 执行简单语句时就有用到。在完成文件扫描后,一个哈希聚合器会执行 partial_sum,随后一个独立的操作会对数据进行分割、重聚合从而计算出总和。然而,这在很多情况下有被证明是会出问题的。
小块数据驱动的并行
在 SQL 引擎中实现并行化更为现代的模型是“小块数据驱动(Morsel-Driven)的并行”。与前文提到的方式类似,输出层面的扫描被分割,从而实现部分扫描。在我们的第二条管道中,我们有两次对 sale 表的部分扫描,第一次扫描前半部分,第二次扫描剩下半部分。
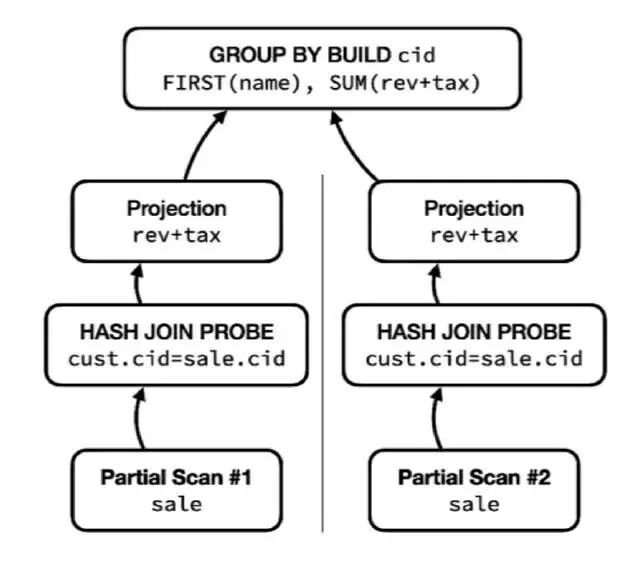
图十三:小块数据驱动的并行
其中,HASH JOIN PROBE 维持不变,因为它是从两条管道中对同一哈希表进行操作。映射操作独立进行,所有结果都会被同步到 GROUP BY 操作符中,也就是我们的阻塞操作符。注意看,这里我们没有用到任何一个交换操作符。
与基于交换操作符的传统模型不同,GROUP BY 知道并行的存在,且可有效地管理不同线程读取可能存在冲突的分组所导致的问题。
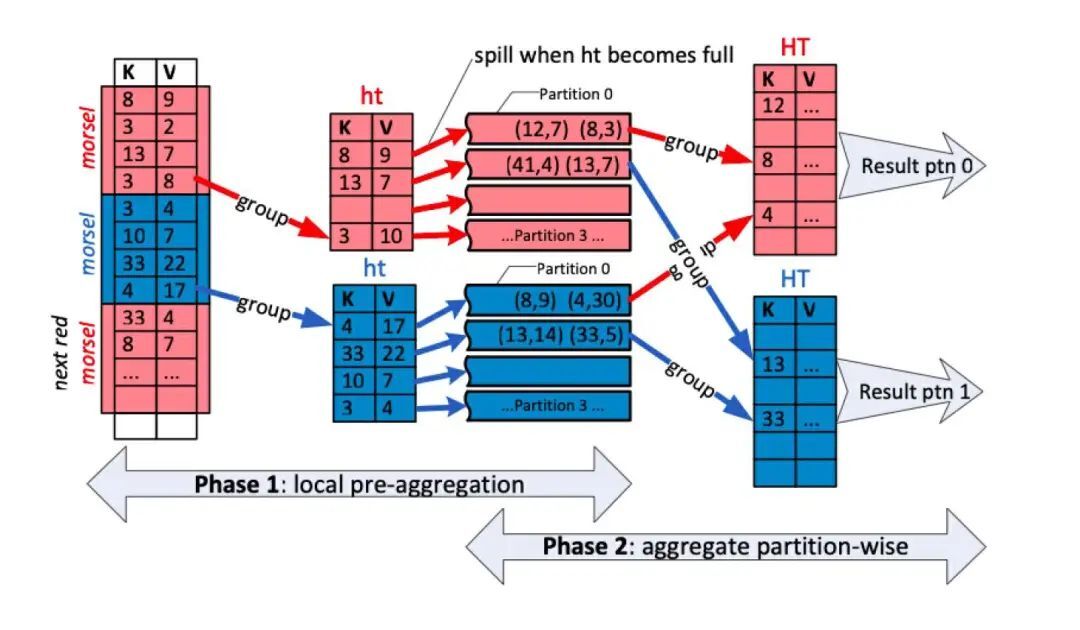
图十四:分割哈希表以实现并行合并
在小块数据驱动的并行中,每个线程都会在流程开始时(第一阶段)预先聚合其数值,输入数据的独立子集活小块数据会被构建在独立的哈希表中。
下一阶段(第二阶段)中涉及分区聚合:在本地哈希表中,数据根据组键的基数进行分区,以确保每个哈希表中不会包含其他哈希表中的键值。在读取完成所有数据后,就可以最终确定哈希表和聚合,我们从每个参与的线程中选择相同的分区,并规划更多的线程将其全部读取。
虽然整体过程比标准的哈希表聚合还要复杂,但这却能允许小块数据为驱动的模型实现极大的并行性。该模型可有效地在多个输入上构建聚合,避免了交换操作符所带来的相关问题。
简单的基准测试
我通过文中演示的查询示例,再加上 ORDER BY 和 LIMIT 子句进行了一个简单的基准测试。SQL 语句从 customer 和 sale 表中选择 name 和 revenue + tax 的综合,这两张表通过 customer 进行分组和连接。
实验涉及两张表,其中一张有一百万的客户数,另一张则有上亿条销售记录。相当于 1.4 GB 的 CSV 数据,数据大小刚刚好。

图十五:简单的基准测试
DuckDB 只需要半秒就可以在我的笔记本上完成查询,但 PostgreSQL 却在我优化了配置后花费 11 秒才完成任务,默认配置下则需要 21 秒。
虽然 DuckDB 的查询处理速度比 PostgreSQL 快 40 倍左右,但别忘了这种对比并不公平,PostgreSQL 主要还是为 OLTP 工作负载而设计的。
结论
本文是为解释 DuckDB 的设计、功能和原理而编写。作为一款封装紧实的数据引擎,Duck DB 可以库的形式直接与应用程序相连,它的足迹小且无依赖性,允许开发人员将其轻松继承为一个可用于分析的 SQL 引擎。
我着重强调了进程内数据库的强大之处在于,其能有效将结果集转移至客户端并将结果写入数据库。
DuckDB 设计的一个重要组成部分在于矢量查询处理,这种技术允许高效的缓存内操作,消除了函数调用所带来的开销负担。
最后,我对 DuckDB 的并行模型也有谈及。小块数据驱动的并行模型允许跨任意数量核心的高效并行化的同时,也能维持对多核处理的认知,有助于提高 DuckDB 整体的性能和效率。
原文链接:
https://www.infoq.com/articles/analytical-data-management-duckdb/




