【编者的话】A /B 测试曾在多个领域产生深远的影响,其中包括医药、农业、制造业和广告。 在软件开发中, A/B 测试实验提供了一个有价值的方式来评估新特性对客户行为的影响。在这个系列中,我们将描述 Twitter 的 A/B 测试系统的技术和统计现状。
本文是该系列的第三篇,介绍了一种自动检测分桶不平衡问题的实验技术。
注:本文最初发布于 Twitter 博客,InfoQ 中文站获得作者授权,对文章进行了翻译。
正文
在前面的文章中,我们讨论了 Twitter 进行产品 A/B 测试的动机, A/B 测试如何帮助我们创新,和 A/B 测试框架 DDG 是如何实现的。本文我们将介绍一种自动检测潜在“错误(buggy)”实验的简单技术:对用户进入“实验桶(experiment bucket)”的不平衡进入率进行检验。
触发分析
A/B 测试将用户映射到“实验桶(treatment bucket)”。“控制桶(control bucket)”(“A”)是当前产品体验;实验桶(“B”)实现被测试的变更。你可以构建多个实验桶。
选择展示哪个桶似乎很简单:随机和确定地将所有用户 ID 分配到一些整数空间,并指派空间到桶的映射。
但是考虑到许多实验变更只是推送给一部分用户。例如,我们可能想对 iSO 应用程序中的照片编辑体验做些变动——但是不是所有的用户都使用 iOS,同时也不是所有的 Twitter iOS 用户都编辑照片。
包括所有用户,无论他们是否“触发”实验都会造成“稀释(dilution)”。即使你的特性是在被推送用户行为之下变更的,其实大部分都不是,所以影响很难观测。因此,需要通过只观测触发变更的用户来缩小分析。但是,这么做可能有危险,因为有条件地选择进入实验的用户易使我们有偏见。由于实验配置的微妙之处,使得不同实验桶样本总量不具有可比性,进而导致结果无效。
一个简单例子
让我们想象一下,工程师需要实现特定于美国的实验。通过使用以下(伪)代码,她确保实验桶不会推送给美国之外的用户:
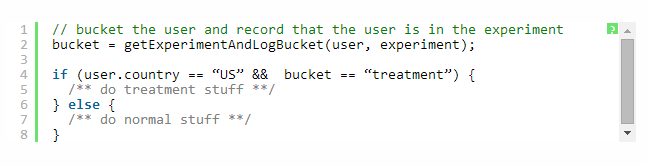
由于所有国家的用户会被记录进控制桶或者实验桶,但是事实上只有美国 “实验桶”用户能够看到实验桶,这就产生了稀释实验。
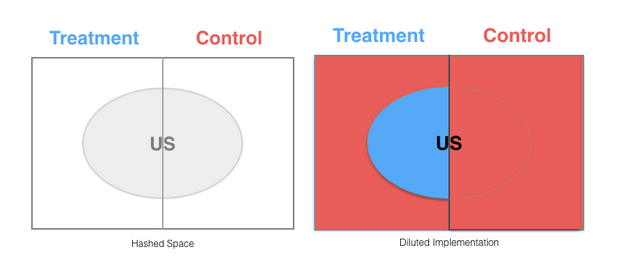
在这一点上不存在偏差——仅仅是稀释。但是当在代码评审中指出时,代码变成如下:
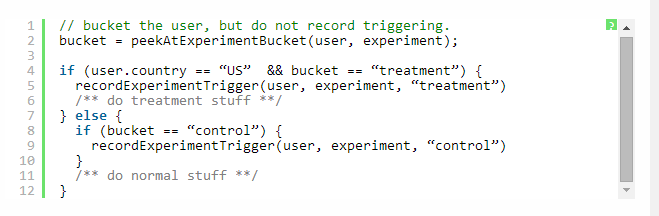
新版本看上去避免了稀释问题,因为即使用户触发了实验桶,只要他们没有看到,他们就不会被记录。但是它有一个 bug——实验存在偏差。实验桶仅仅记录美国用户,而控制桶可以记录所有国家的用户。应用程序没有被破坏,但是两个桶不具有可比性。
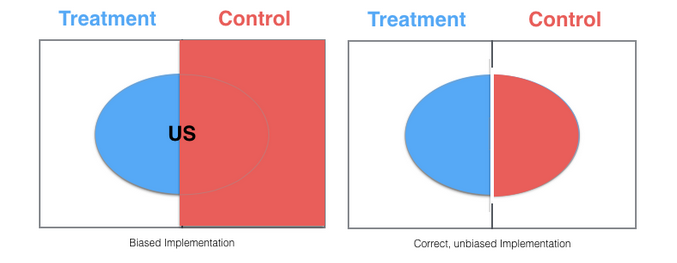
无偏差的解决方法如下所示:

并非所有的分桶不平衡都有如此显而易见的原因。最近我们遇到一个实验,从客户端 Javascript 触发用户分桶日志异步调用。该实验中,实验桶需要加载某些额外资源,并进行其它调用,这会导致低速连接用户的分桶日志调用不太可能成功。这就造成偏差:控制桶比实验桶更可能推送给低速连接用户,会轻微扭曲结果。
识别分桶不平衡
有效检测分桶偏差的方法是对不平衡的桶的大小进行检验。我们的实验框架会使用两种方法自动检验桶的大小是否与预期大致一致。首先,我们使用多项拟合优度检验执行整体“健壮性检查(health check)”。健壮性检查会检查观测的桶的分配是否匹配预期流量分配。如果整体健壮性检查不理想,我们还会对每个桶执行二项检验,精确查明哪个桶可能有问题,显示新分桶用户的时间序列,以防实验者希望进一步挖掘。
使用多项检验执行整体健壮性检查
想象一下,某个实验分成 _k_ 个桶,其中向第 _i_ 个桶推送 p% 的流量(不同桶之间的 _p_ 可以不一样)。假定我们知道实验中分桶用户的总量,我们可以将每个桶中的用户数量共同建模为多项分布。此外,我们可以执行拟合优度检验,观察实际观测到的计数是否偏离预期计数。如果发现流量分配显著偏离预期,这就说明流量分割有问题或者分割存在偏差。
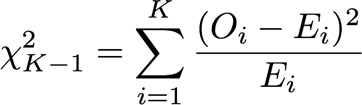
这里 ,_O_ 代表第 _i_ 个桶中观测到的分桶用户数量,_E_ 代表每个桶预期的分桶用户数量。统计数据捕获每个桶偏离其预期值的程度,总和数据捕获总体偏差。该检验统计遵循卡方分布(自由度为 k-1),所以我们可以判断,观测的偏差是否与桶分配的当前样本 _p_ 值一致。
需要注意的是,“多项检验(multinomial test)”是泛化的二项检验(通常用于只有一个控制和实验组的测试)。过去,我们使用二项检验将每个桶与其预期的桶计数对比。但是,在实验中有多个桶的情况下,我们很快就会遇到多重假设检验问题。接下来,我们根据 1 - (1 - p)^k,其中 _p_ 是获得假阳性的概率(通常设置成 5%),将假阳性作为独立桶数量的函数,绘制获得至少一个假阳性的概率图。即使是配置合理的试验,当拥有多个桶时,其假阳性率增加得相当快:在零假设、5 个桶的情况下,其中一个桶不平衡的概率超过 20%。
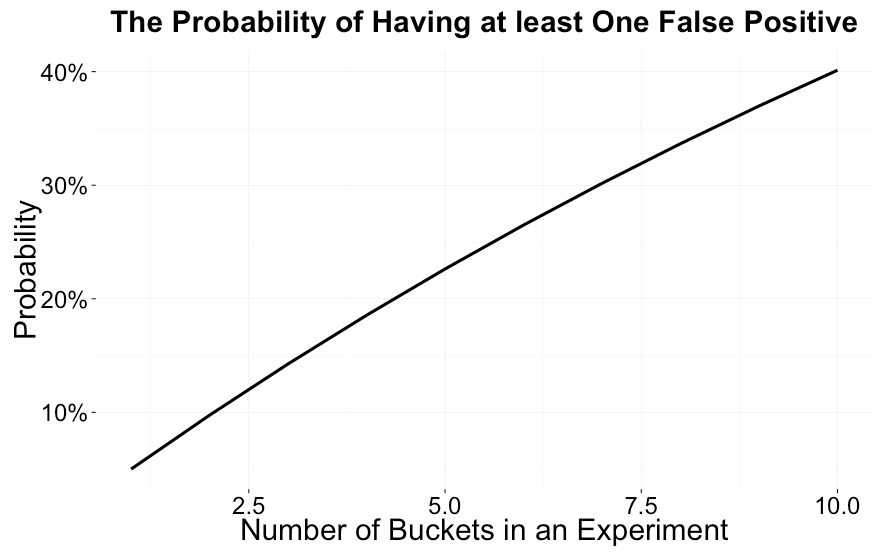
假阳性会浪费很多调查时间,会降低对工具的信任。为了说明这个问题,我们对二项检验切换成多项检验的改进进行了评估。
我们对 179 个实验做了元分析,并对多项和二项检验的桶的健壮性结果进行了对比。在二项检验的情况下,至少有一个桶的 p_<_0.05,实验就被视为不健壮,而在多项检验情况下,只有整体桶的 p<0.05,实验才会标记为不健壮。
我们发现有些实验的二项检验结论是不健壮,而多项检验的结论相反。我们检验了所有此类实验,发现它们有着共同的特征:
-
所有实验中只有一个实验,并且只有一个桶的二项检验小于 5%。剩下的桶往往拥有一致的、健壮的 _p_ 值。
-
所有被标记的实验至少有 4 个桶。
这些特征表明,二项结果可能是假阳性。接着,我们手动验证所有实验的配置都是正确的。切换到多项检验,提高了整体实验的健壮性,降低了估计 25% 的假阳性率。
标记独立的桶
多项检验可以让我们免受多重假设检验的困扰,但是它有一个缺点:它不能告诉我们哪个桶有问题。为了提供更多的指导,我们在多项检验的情况下还进行了另外的二项检验运行。
DDG 使用二项式分布的正态逼近来执行双面二项检验。

二项检验可以检查时刻 _t_ 的流量分配是否大致均衡,当实际流量在预期流量 95% 置信区间之外时,它会标记出异常的桶。
桶计数的时间序列
在最低粒度水平下,我们的工具也能够在 8 小时的批处理时间窗下呈现桶计数的时间序列。如下两个例子:健壮的时间序列和不健壮的时间序列
实例 1:健壮的时间序列
(点击放大图像)

在上述例子中,时间序列表明,不同桶之间每个桶的用户数量是均衡的,除了一小批次(颜色标签是基于每个时间段 _t_ 的二项检验)。其中的两个不平衡的批次不会产生影响:当显著性水平设置成5% 时,每20 个测试中会有一个假阳性。多项检验影响不明显。总体而言,我们没有看到有分桶偏差的任何证据。
实例2:不健壮的时间序列
(点击放大图像)

在这个实例中,我们看到实验开始几天后,新用户的数量开始偏离预期流量,表明出现 分桶偏差。看看右上角的整体桶健壮性,多项检验也表明测试不健壮。在这种情况下,工具会提醒用户在分析之前先调查设计。
相比任何一种类型的检验单独检测,批次层级和全局检验的结合,可以让我们检测出更多精细问题。
基于用户检验,而不是印象
由于实验效果或者实现细节,合理的设计和实现的实验可以让不同的桶拥有分桶印象整体数量。与研究总触发或者总访问相比,基于特别分桶用户对比桶不平衡,是更好的检验方法。
需要注意的是,在我们的时间序列检验中,我们基于第一次用户分桶检查桶不平衡,而不是分桶事件。实验本身可以引导用户继续触发实验,或者低于控制桶。这使得后验印象数据对比不恰当。在整个检验中,我们只对整体用户分桶数量进行对比,而不是记录桶之间的整体印象。
结论
分桶不平衡检测非常强大,它是一种判断实验是否正确配置的简单易行的方法。要验证实验结果,这是头等大事,将其内置到工具链中,可帮助我们节省大量的调查和分析时间。通过自动检查带有明显偏差证据的实验,大幅降低了检测问题所需的时间,同时增强了实验者对实验结果的信任度。
编后语
《他山之石》是InfoQ 中文站新推出的一个专栏,精选来自国内外技术社区和个人博客上的技术文章,让更多的读者朋友受益,本栏目转载的内容都经过原作者授权。文章推荐可以发送邮件到editors@cn.infoq.com。
查看英文原文: Detecting and avoiding bucket imbalance in A/B tests
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




