
本文整理自字节跳动技术专家刘成清在 ArchSummit 杭州 2022 全球架构师峰会的演讲分享,主题为“字节跳动 APM 线下性能归因实践”。
分享主要从四个部分展开:第一部分介绍线下工具的发展史,分析线下工具有哪些共同目标和痛点;第二部分分别以各种常见的性能问题为大家介绍归因这类问题的常见解决思路,同时也会穿插讲解一些字节内部的实际案例;第三部分就 iOS 部分能力为大家介绍实际的工作原理;最后是本次分享的总结。
在分享开始前,首先看下本次分享能给大家带来哪些收益?
第一,本次分享主要介绍移动端 iOS 与安卓的性能归因手段,从系统层面分析 App 性能。
第二,介绍如何使用 iOS 的后门服务,像安卓使用 adb atrace 一样进行性能归因。
第三,通过性能归因实战,看如何使用线下工具为卡顿、内存、功耗等问题进行归因提效。
线下工具的前世今生
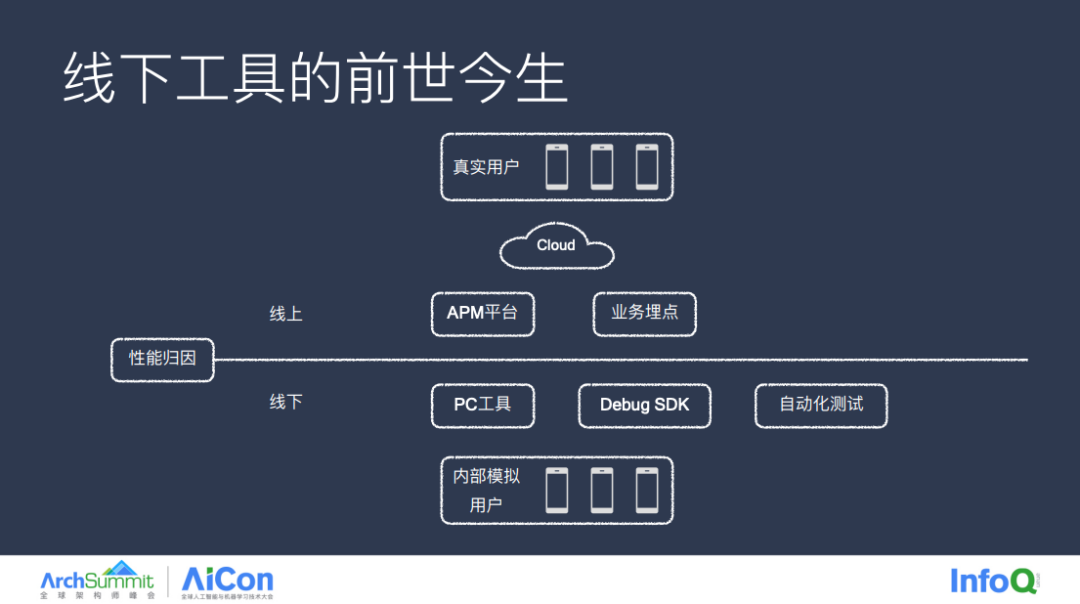
性能归因如同 App 健康监测,根据用户群体的不同,可分为线上和线下,线上通过性能 SDK 采集实际用户的真实数据,APM 平台通常的能力有卡顿监控、LPS 监控、OOM 监控等,但由于权限等原因,线上 SDK 往往无法采集部分深度数据,而线下通过 PC 工具,内部 Debug SDK 对线下模拟的用户进行分析,拥有足够大的权限,所以可以采集一些深度的数据用于一些深度的性能归因分析。两者相辅相成,线下是线上分析的补充,线上是线下测试的兜底,如今部分线下能力也在往线上迁移,如字节的 memory graph,既能采集到线上的真实数据,也能使用丰富的分析能力,而业内对于线上已经有大量的 show case 案例。今天的主题还是线下归因分析,看看线下都有哪些被大家忽视的优秀能力,帮助大家将问题的发现前置,避免漏到线上。
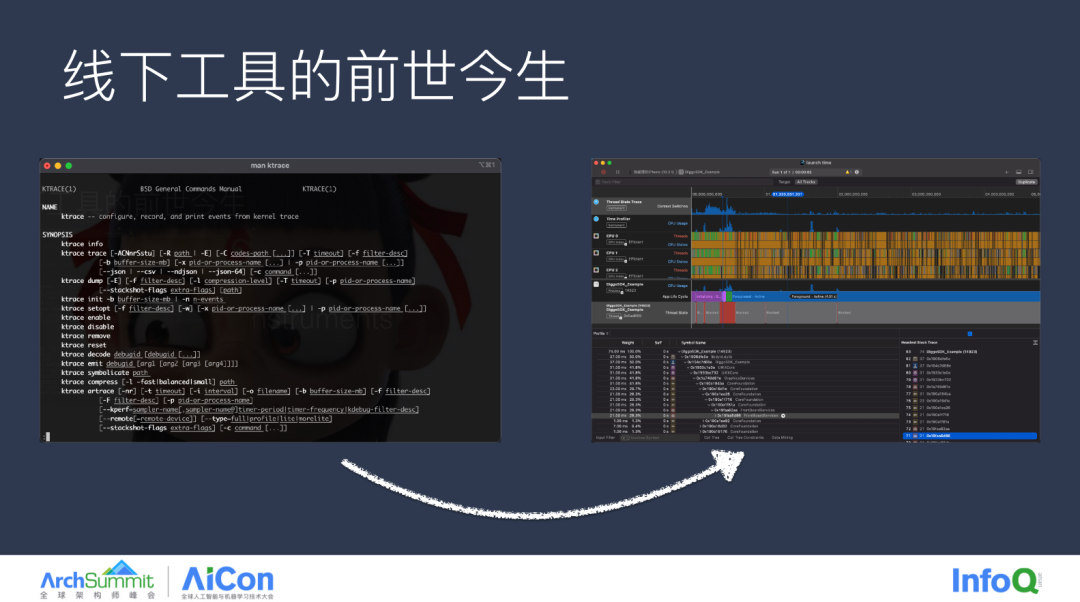
左侧是 ktrace 命令行分析工具,了解 iOS 性能优化的同学都知道,ktrace 的丰富能力如同安卓的 system chains 一样强大,可以采集大量的内核数据,但由于门槛较高,部分研发同学并不能轻松驾驭。右侧是 Apple 提供的 Instruments,可见数据更为直观,并且 Instruments 每年的 WWDC 依旧会更新新的能力,Google 的 Perfetto 亦是如此,从中我们得知,工欲善其事,必先利其器。

这是性能归因的三部曲,即生产、采集与消费。而我们引入工具的目的就是为了提升归因的效率,我们希望把效率从天级别降低到分钟级别,而使用门槛也从专家级降到小白级。在命令行时期,工具只能提供采集能力,我们需要手动模拟场景,通过工具采集数据,并且根据经验进行性能分析,但往往性能问题的归因的时效性需要数天,甚至需要立项解决,而到了 GUI 时期,工具虽然提供了采集和图形化相关的一些能力,一定程度上简化了流程,但 Perfetto 与 Instruments 依旧有一定的使用门槛,如果工具能结合数据生产、采集、消费,并且能以部分范式的经验聚类数据,就能让常见的问题做到自动归因,将性能问题的发现与解决前置到业务开发当中,也能降低问题的复工率,同时还能与 CICD 结合,作为准入的一个卡口,提升性能问题的拦截率。目前这两种形式分别以不同的形态落地了字节,服务于 RD、QA,提升了各个产品形态的研发效率。
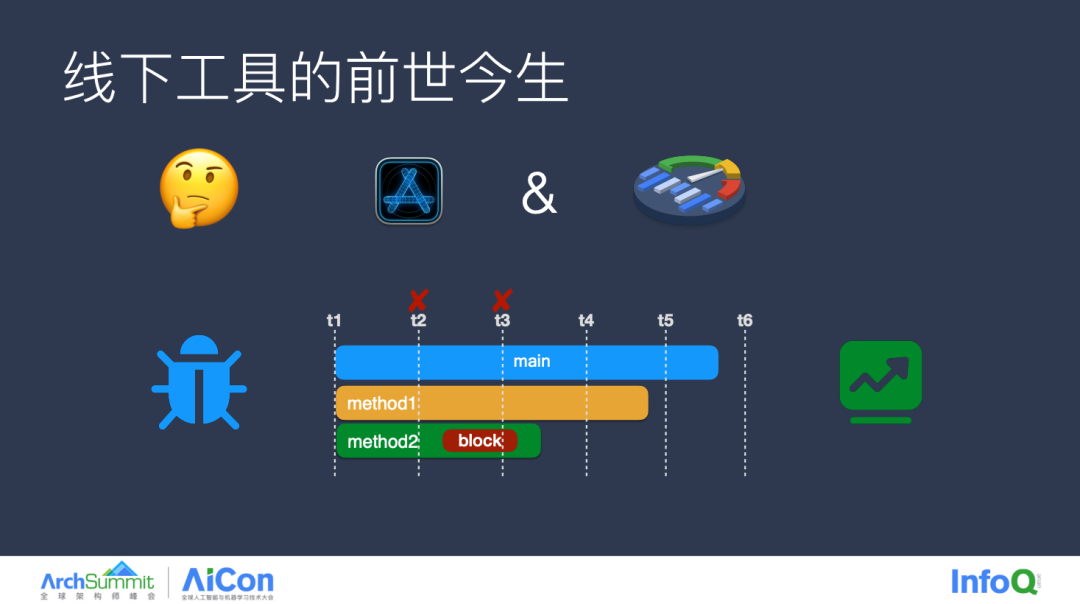
Instruments 和 Perfetto 都提供了相应的能力,那么我们为什么还需要去做一个自己的工具?原因有三,第一 Instruments 和 Perfetto 对包的限制还是比较苛刻的,大部分功能只适用于 Debug 包,当 QA 用内测包反馈一些性能问题的时候,我们并没有办法直接使用工具进行归因分析。第二涉及数据的精度,本身采样工具都会有精度的丢失,以 Instruments 为例,假设 T2、T3 时刻丢失了采样,整体会影响到对函数耗时的统计,但这些问题我们都会通过聚类算法进行规避。第三,Instruments 没有一些火焰图的展现形式,并且不支持一些自定义的指标水位,我们要做自动归因的话,也需要对原始数据进行二次分析。
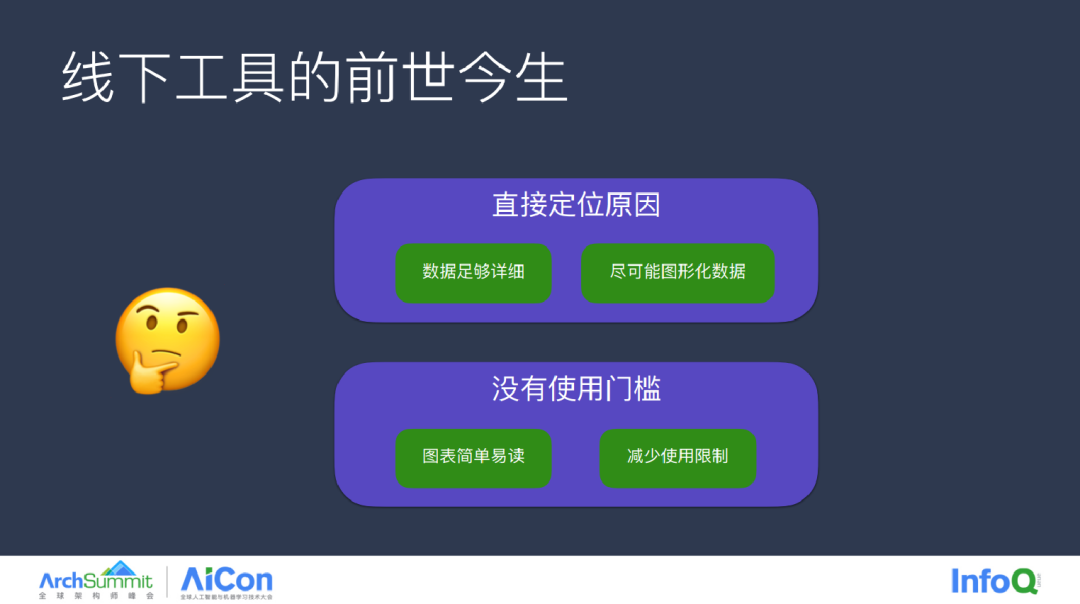
总结一下我们要做的工具需要达到的几个目标,数据要足够详细,尽可能地图形化数据,尽可能地降低使用门槛。
性能归因的降本增效
有了目标,接下来我们看看基于这些目标,在呈现性能问题上的提效手段和落地的效果。
首先先来看一下效果。当我们发现性能问题,且上下文信息不足以归因时,我们可能需要切换到可调试的包,或反复埋点分析,这无异于增加了归因的链路,且可能导致问题不再复现,这时我们可以直接分析 Store 上的线上包,大部分能力是无需接入 SDK 的,也无需重启 App,直接保留现场,即插即用,可视化的分析数据几分钟就能定位到大部分问题的具体原因。具体效果如视频所示。
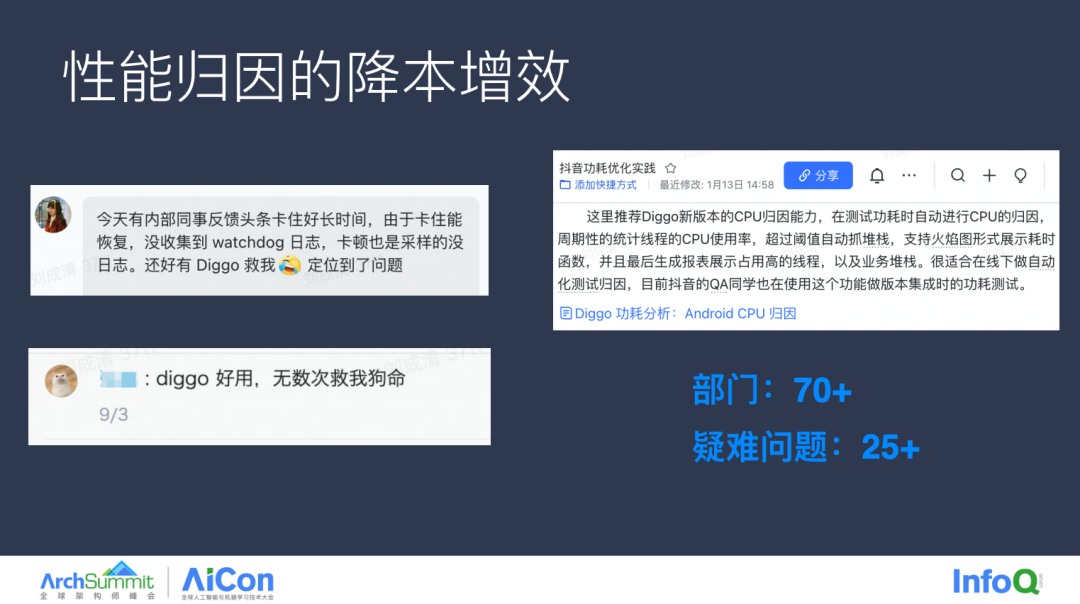
上图是字节内部对这个工具的一些反馈情况。
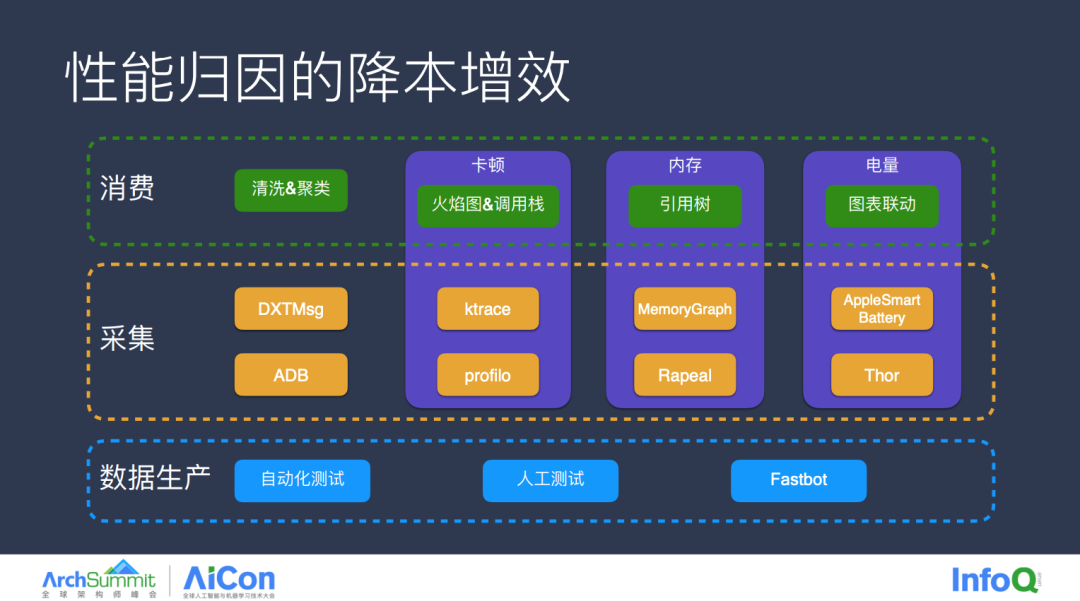
接下来我们看一下如何进行归因提效。最下层的数据生产,大家常用的有自动化测试和人工测试,而字节采用的最有效的提效手段就是 Fastbot,既通过 AI 驱动操作 App,而中间层的数据采集分别使用的是 DXTMsg 与 ADB 进行数据进行数据通信,以及 ktrace、profilo 的能力进行数据采集,其中也包含了一些字节已经开源的 SDK 能力,上层消费侧则是将采集的数据进行清洗与聚类,分别以更直观的方向展现出来,我们将这些能力进行整合,从而减少使用链路,提高效率。
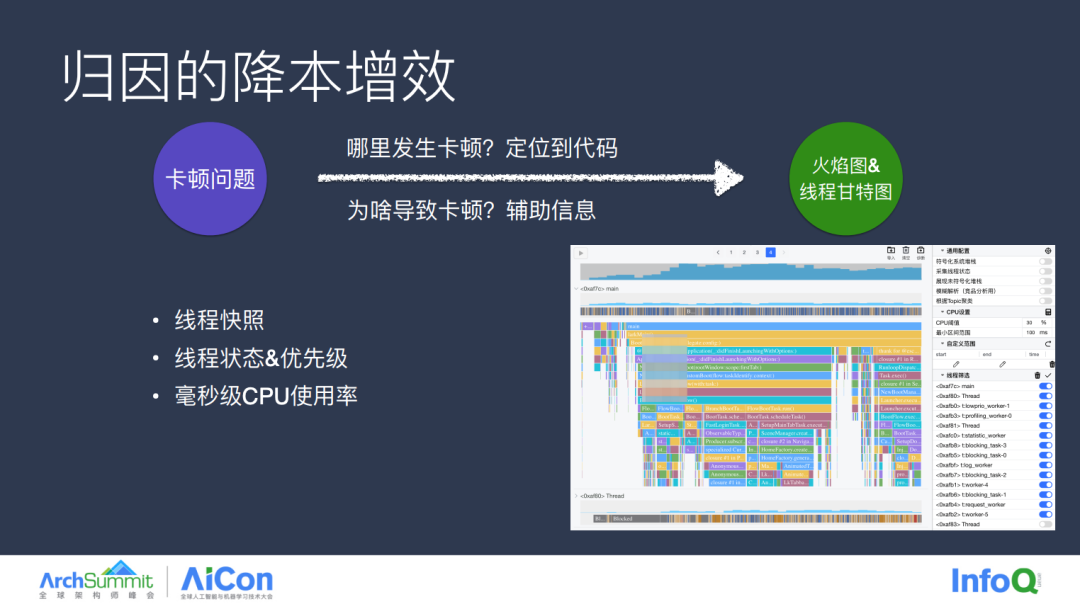
接下来我们分别从卡顿、内存、电量这三个问题展开介绍。首先是关注度比较高的卡顿问题,如同人体骨折,无法使人箭步如飞,早期只能凭借老医生的经验判断,当有了 CT 之后,我们只需要拍一张 CT 的片子,就算是没有任何医学经验的普通人也能看懂哪里发生了骨折,以及严重的程度如何,而面对卡顿问题,我们也需要一张这样的 CT 片子,能直观地告诉我们哪里发生了卡顿,以及导致卡顿的原因。通过收集线上快照,线程状态优先级,以及毫秒级的 CPU 使用率,这些信息就能绘制出右侧的时序效果图,往往就能直观地定位到 80% 的卡顿问题,而剩下的 20% 则还需要深度分析。

接下来我们看看这 80% 的问题是如何定位的,当我们发生卡顿的时候,我们通常的排查手段是通过察看日志,如果日志能直接归因,我们这个问题就结束了,如果无法直接归因,我们就需要通过埋点、重新打包、重新复现、再分析数据进行归因,如果这时能完成归因,当前问题也能直接结束,但如果无法正常归因,我们还需要重复性的进行埋点并重新打包这个链路,而引入工具的目的就是为了能在发生卡顿时,直接使用工具进行问题的归因。
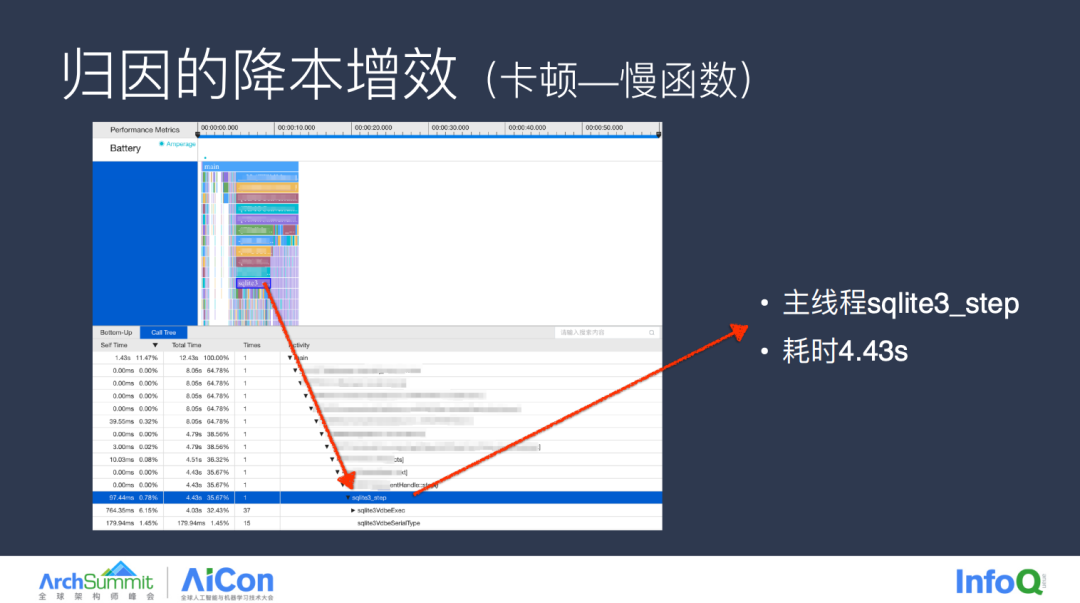
首先是慢函数,这也是最容易被发现的卡顿问题,也就是一个函数执行耗时过长,这是某 App 私信场景下的一个卡顿 case ,通过火焰图我们能直接定位到卡顿的调用栈,也就是在主线程执行了一些 DB 的操作,而这类问题很容易被发现,为什么还会遗漏到线上?主要原因还是因为其使用场景的隐秘性,在这个场景中,DB 与私信消息是有关的,当私信条目不多时并不会暴露,就算 QA 发现了这类问题,我们也无法直接定位问题,因为可进行函数分析的 Instruments 对非 Debug 包的支持欠佳,往往我们还是需要通过埋点、重新验证等反复操作的方式才能进行问题的验证。
为了解决这个问题,我们将工具的使用范围从 Debug 包拓展到所有包,就算是线上包我们也可以通过无侵入的方式直接采集线上快照,从而将问题的归因时效从小时级降到分钟级,而 Lark 和头条先后使用该能力,也解决了线上的一些卡顿问题。虽然慢函数这类问题可以通过线上的 APM 进行采集,但由于本身的采样率、性能损耗和阈值等原因,可能会丢失一些相关数据,这导致用户反馈的问题无法及时排查,而这个工具就能高效的保证排查的效率。
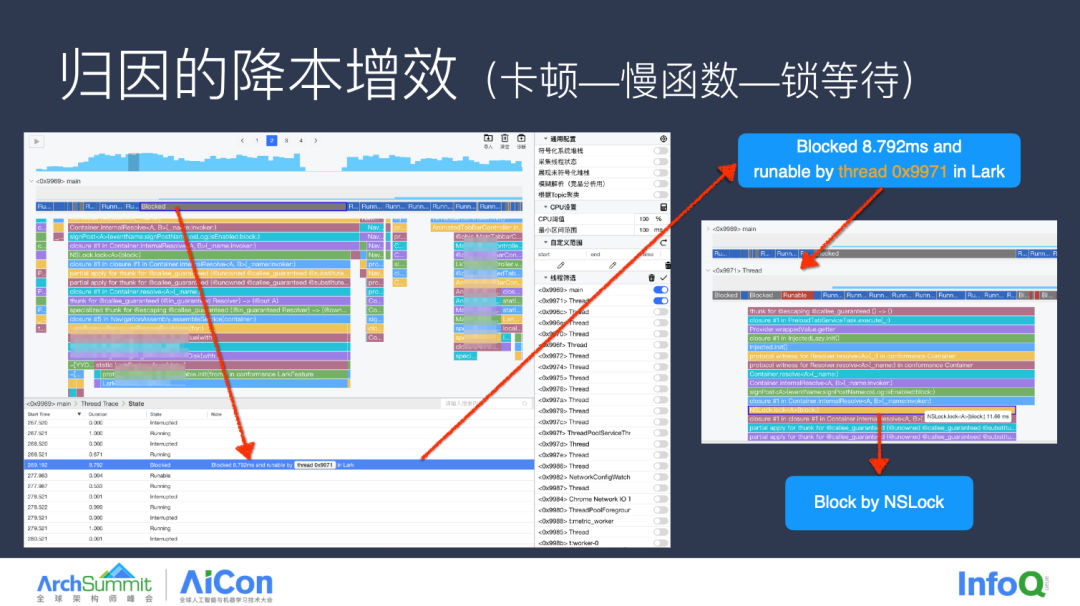
以上介绍了使用场景的提效,接下来我们看看功能上的提效。依旧是慢函数,当我们通过函数名无法定位具体原因时,即这个函数确实应该在主线程执行,但为什么执行这么慢?我们可以结合一些辅助信息,比如说线程状态,通过上图可以看到,慢函数期间有 80% 的线程状态都是 Blocked,我们通过对应线程 Blocked 的一些信息,以及对应的一个子线程,当前时刻的一个调用栈可以发现,主线程正在等待子线程的 NSLock 的操作,排查到这里,基本上问题的原因也确定了。
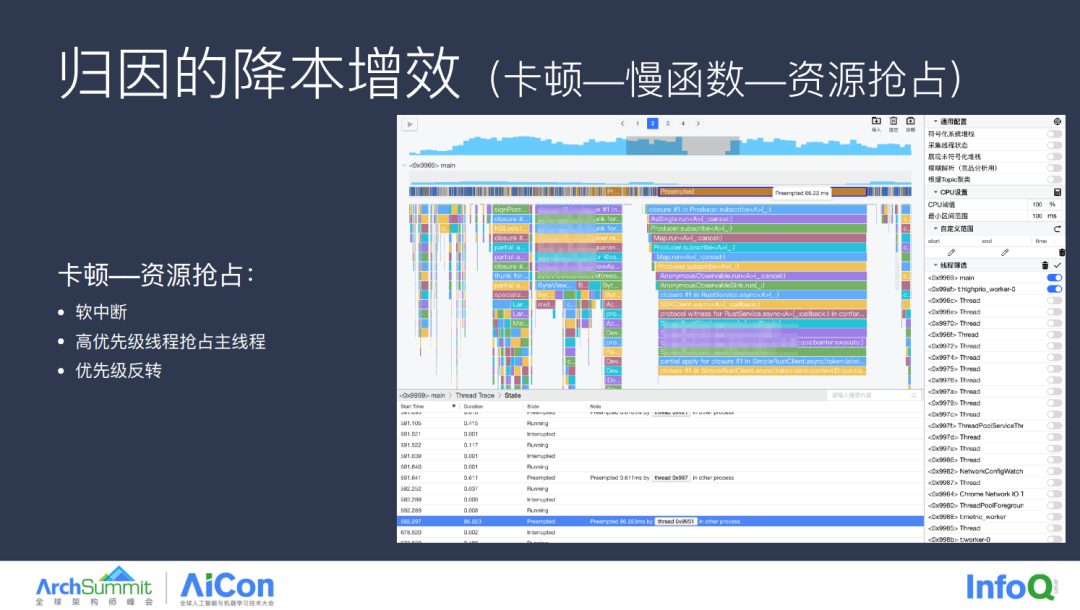
除了锁等待,还有一种导致慢函数原因的就是资源抢占,而这类问题也是隐匿性最强的慢函数问题,在线程状态中它的体现是 Preempted 的,而这类问题的分析就得 case by case 的处理了,触发的常见原因有软中断、高优先级抢占主线程资源或者优先级反转等,目前本工具已经支持了优先级反转场景的识别。
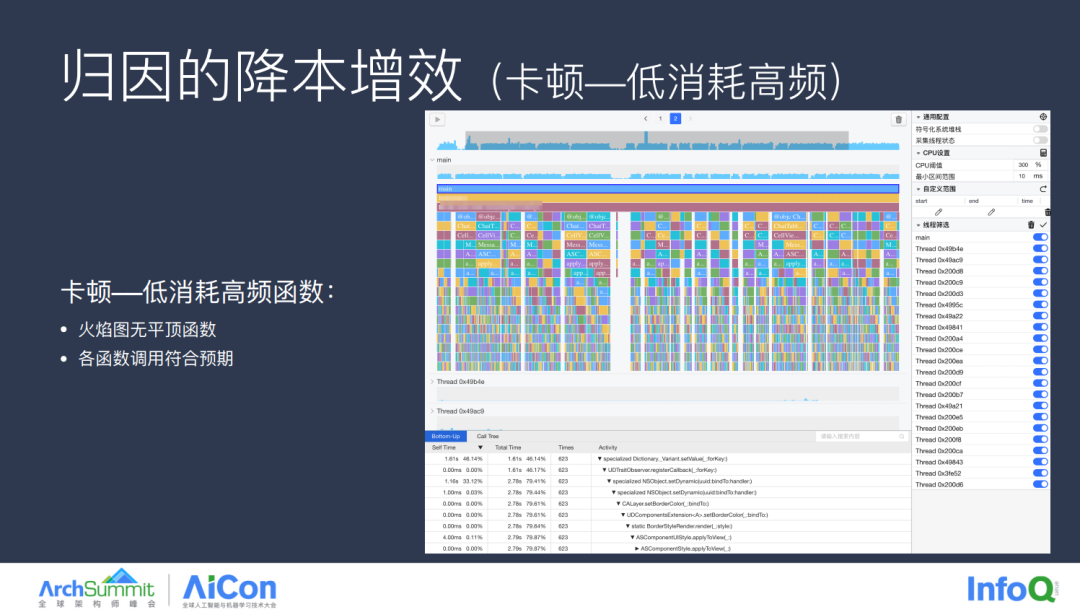
以上是直接定位到卡顿慢函数的场景,而导致卡顿的原因是在一个渲染周期内执行时间过长,无法及时渲染,可能不是由于一个函数引起,比如这个卡顿场景通过火焰图无法直接查到卡顿的慢函数,但实际场景确实发生了卡顿,这就是典型的低消耗高频的卡顿场景。

我们通过反转调用栈,并且聚类底层函数可以发现,CALayer.setBorderColor 这个函数调用了 623 次,总计消耗了 2.78 秒,而这个函数本身执行耗时不长,但是是在一个渲染周期内执行次数过多导致的,最后通过调用关系会受到调用这个函数的业务代码发现,这属于业务逻辑处理不当导致过度调用引发的卡顿问题。

以上是函数层面引起的卡顿,导致卡顿的原因还有很多,这是安卓的一个实际案例,在某个 App 下发现当进入某一场景下,会有大量的类加载。大家也知道,当程序需要读取一块未被加载的内存时,会发生页中断,也就是导致这个卡顿的原因,这边通过 JVMTI 监控到当前场景下确实有大量的类加载,而解决这类问题的办法也很简单,就是通过收集这些类信息,生成一个新的 profile 再基于这个 profile 进行预加载,从而规避卡顿的风险。
启动是卡顿的一个特殊场景。作为 App 的第一印象,业内早已经把启动作为 P0 的任务处理了,相应的监控和优化方案也层出不穷,当然也有需要改进的一些点,比如横向对比,我们在优化到一定地步之后,更想知道的是自己与竞品之间的差距,看看自己的优势,或者是可优化的空间在哪,但由于各个厂商之间都有自己的一些统计规则,虽然原理大同小异,但依旧无法完全一致,并且我们也无法直接拿到其它产品的统计指标。其次,当这个数据波动了,厂商也意识到 App 起动性能对手机自身体验的影响,所以在系统层面也做了一些缓存优化,比如说 Apple 的 dyld cache,这些对于统计引擎性能也是有数据波动的影响的。
最后就是监控的粒度,监控细了本身也会影响启动的性能,监控粗了也无法直接归因到一些具体的原因,而这里通过收集系统内核的一些信息,可将任意 App 在该设备上启动各阶段的耗时进行展现,从而做到横向的对比,分析各个 App 的优劣情况。
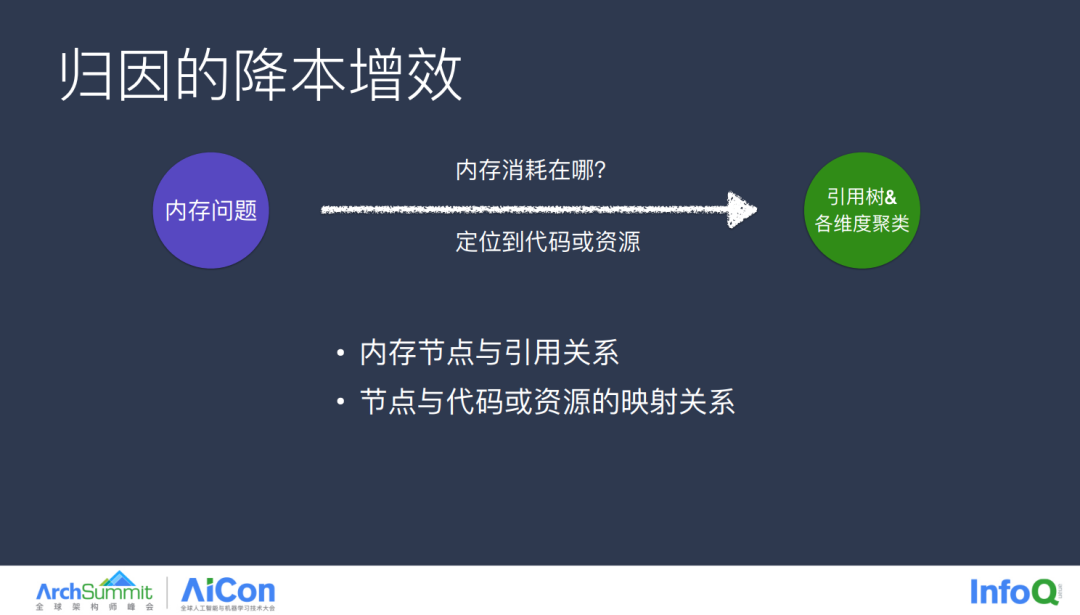
介绍完卡顿问题,接下来就是内存问题了,线上 OOM 也是一个比较棘手的问题,我们看看如何线下提前分析这类问题,避免遗漏到线上。当我们去处理内存问题的时候,常常会问到一个问题,就是内存消耗在哪里?而我们的归因手段就是通过收集内存节点和引用关系,在保留基本的引用关系的情况下,尽可能的将多而杂的节点进行聚类,从而将问题进行暴露。
这边双方的手段略有不同,安卓分别使用 adb、profile 获取 Java 与 Native 内存信息,而 iOS 则是在 MemoryGraph 的基础上进行二次消费数据,从而将数据的粒度最大化。
常见的 case 有在某一个场景下内存居高不下,还有就是进入到某个场景之后内存激增,针对这两类场景我们的解决方案分别是:对于内存居高不下的场景进行内存快照的采集,但由于快照之间有上百万个内存节点,我们并没有办法直接归因一些问题,我们会对相应的节点进行聚类以及排序,同时对聚类比较高的节点信息进行补充,从而能通过这些节点信息归因到具体调用的情况,而对于内存激增的情况,我们更多使用对比的方式。
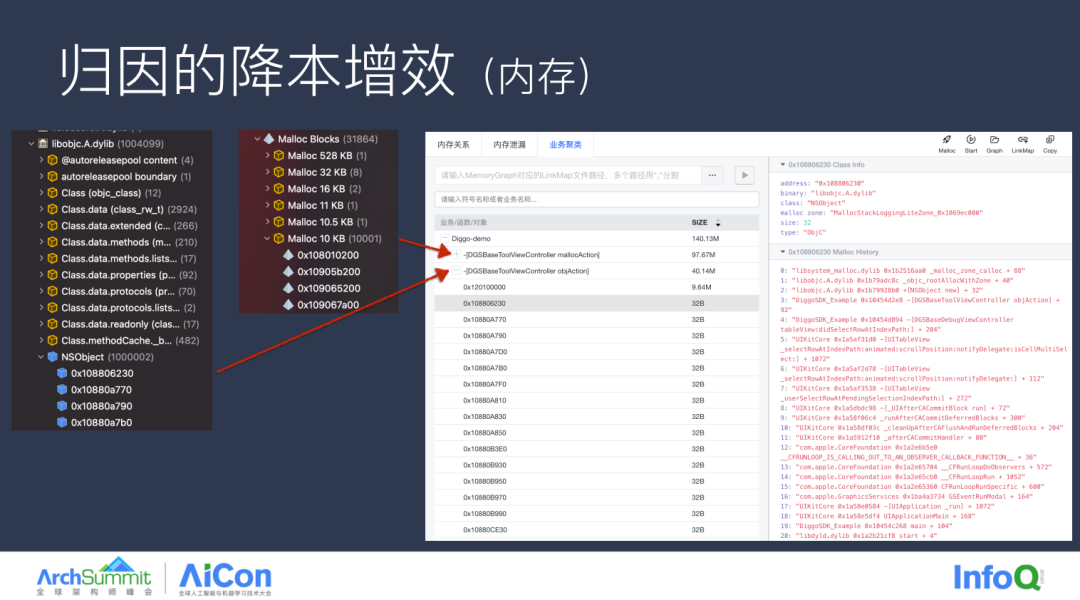
以下是这些功能的具体使用情况,如图所示是 iOS 的一个案例,我们通过将 Malloc History 与 LInkMap 的数据进行关联,可以将零散的节点聚类到 Class 或者 Function 的维度,在前期排查问题的时候,就能将问题聚焦到一定范围。通过该图左侧的聚类信息,我们可以得到,是哪个方法申请的内存较大,再结合右侧 Malloc History 的信息我们可以得到它原本的调用栈是怎样的,这些信息都能有效的帮助我们去定位一些内存问题。
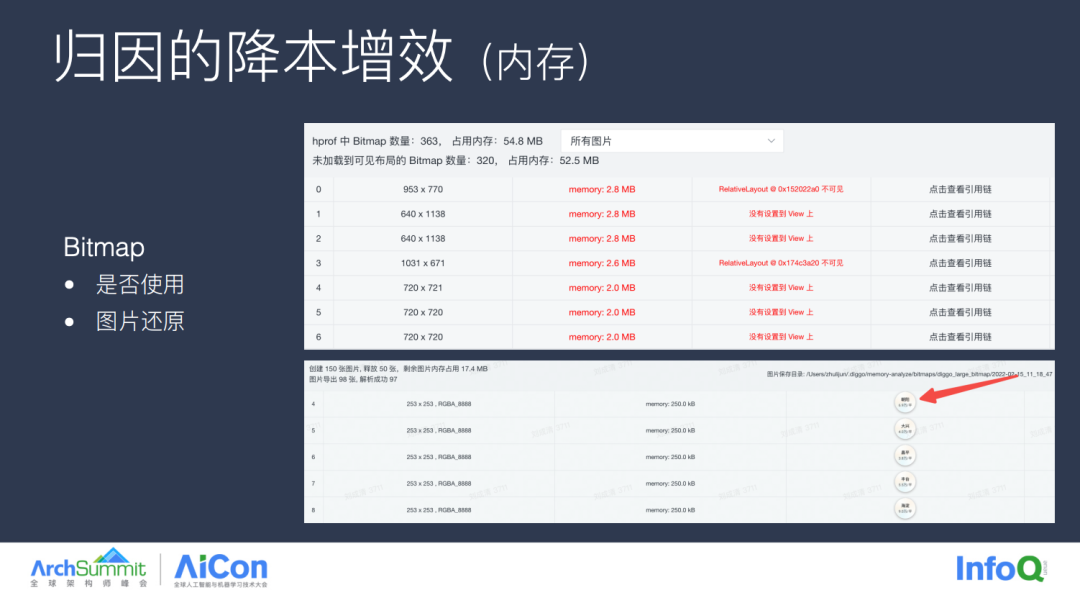
有时我们通过堆栈也无法确定问题的具体原因,如图所示安卓的一个 case ,内存分配中有大量的 Bitmap 的使用,单看这些信息远远不够定位问题,我们这边通过将 Bitmap 的数据进行了还原,问题就比较直观了,最终原因就是地图 Icon 的内存泄漏导致的问题。

最后一个手段就是数据对比了,由于对比可以把聚类的范围限制在 diff 内,这样的话,内存的变量就会被放大,从而有利于我们分析内存问题,如图所示,我们进入特定场景之后进行 diff,发现红框内线程的栈内存增量最为显著,这也就是我们归因这个问题的突破口。
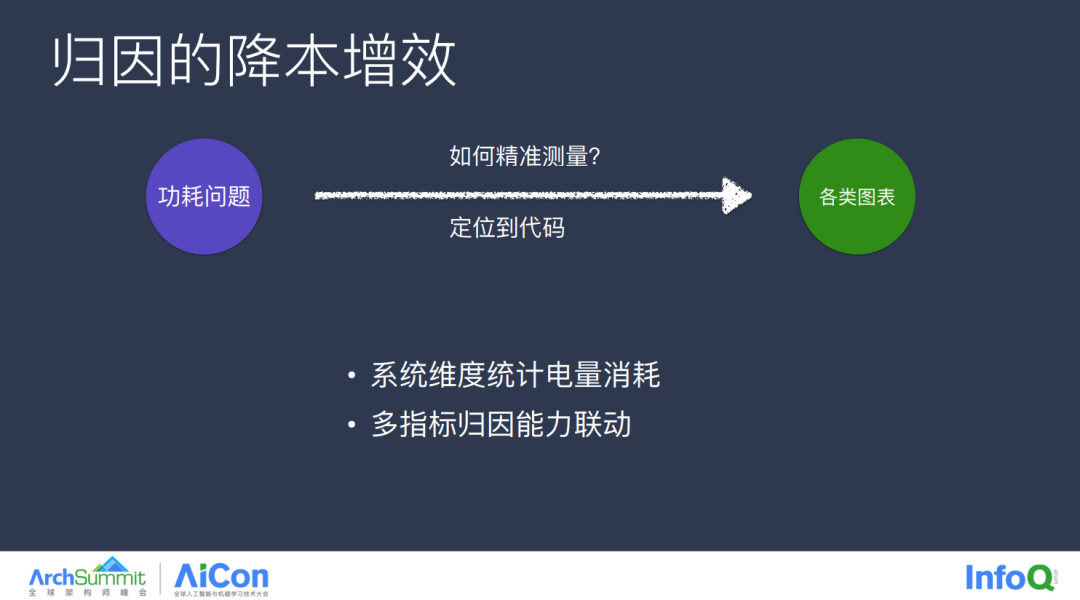
第三类问题就是功耗问题了,由于前两类问题各厂早早就开始布局了,大部分问题都通过线上或者线下方式进行了一些修复,已经达到了可预期的水平,而功耗相对来说起步较晚,但它是近期大家比较关注的指标,并且功耗是由共同因素影响的,比如 CPU、WiFi 等,所以精准测量功耗还是有可待提升的空间。同样归因这类问题也需要结合其它模块的归因能力进行原动分析。
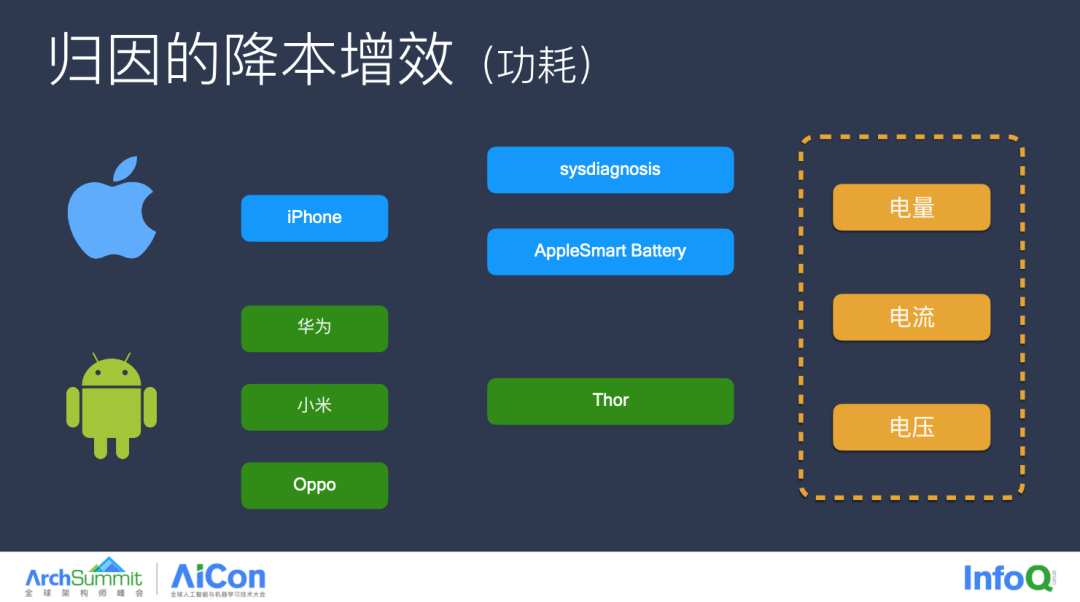
以下是具体的手段,因为 iOS 只有 Apple 一个厂商,只需要从 Smart Battery 以及 sysdiagnosis 里获取数据即可,而安卓的厂商较多,字节这边也是单独开发了一个 SDK,兼容了各个厂商的计算规则,并与厂商之间对齐过电量统计的规则算法,一定程度上保证了功耗指标统计的准确性。

有了指标之后就是归因了,如左侧流程图所表示,我们定时采集功耗指标,当发生异常时便会自动开启 CPU 线程快照及网络数据采集,将这类信息通过时间维度聚类到一起,如右图所示,再结合上文中提及的分析手段,我们就能逐步进行问题的归因,而抖音业务线也使用该工具成功发现和优化了一些功耗相关的异常问题。

介绍完采集和消费流程上的降本增效,最后再简单看一下数据生产上的提效,字节这边自研了一套自动化测试服务,既通过 AI 识别视图中的元素,以更接近人类操作的方式驱动 Web Agent 进行自动化测试,相比传统的 Monkey,无论是场景覆盖率,还是代码覆盖率上都有显著的提升,数据如图所示,结合 Fastbot 的数据生产,加上上文提及到的归因手段,我们整体的效率都有了一定的提升。以上为大家介绍了从数据生产、采集、消费全链路上的归因提效手段,虽然这些归因手段目前只是在线下使用,但部分能力也可以逐步迁移到线上,以丰富线上的归因能力。
原理分析
介绍完手段和效果之后,大家可能会对其中的一些实现原理有一定的好奇。接下来主要针对线上快照的采集与消费进行原理介绍,看看如何在无侵入的方式下获得线上快照,我们也利用这个方式成功分析过一些竞品 App 的运行逻辑。
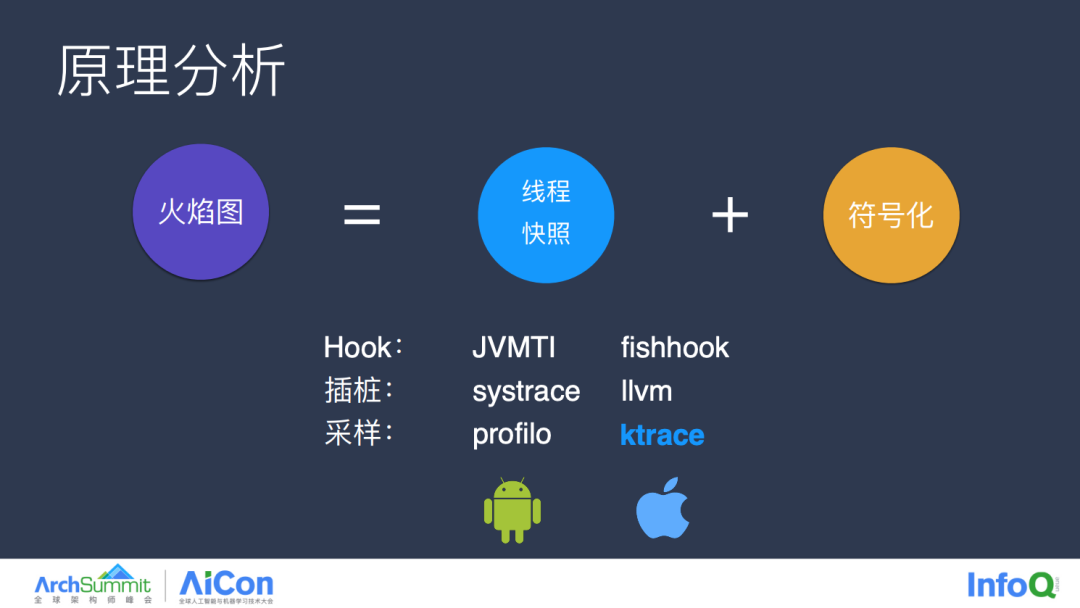
以卡顿分析的火焰图为例,我们只需要采集线上快照和符号化两步就能够让 App 的运行流程毫无保留的暴露在我们面前,而采集线上快照,我们常用的方式有 Hook 与插桩,安卓与 iOS 都有各自的一些解决方案,但这两种方式都需要侵入 App,其本质都改变了 App 本身,故无法测试 Store 上的正式包,所以我们采用的是 Ktrace 的采集方案。

首先我们看看 KDebug 能力,KDebug 类似于安卓的 systemtrace,用于收集内核事件,通过日志的形式暴露出来,看过 XNU 源码的同学可能都见过它的身影,比如线程调度的源码中,线程的 Block、Unblock 都会通过 KDebug 进行一些日志的记录,并通过唯一的 Event Code 标识各类事件,据不完全统计,目前已经有 2300+ 个 Event Code 正在使用当中。而最新的 iOS16 提供了 Run Loop 的调度监控也是通过 KDebug 补充的新能力。
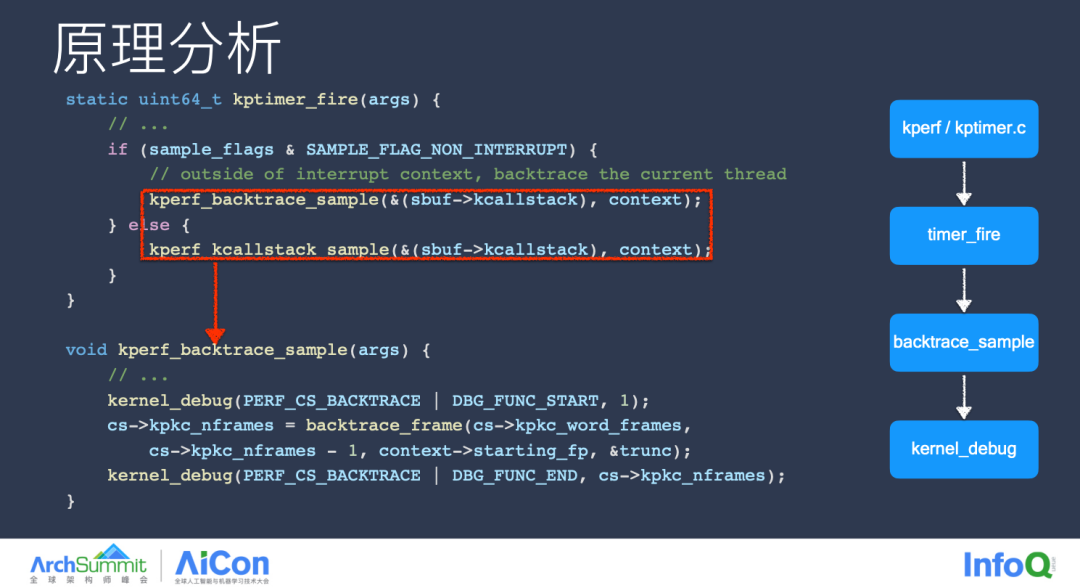
其次就是 KPerform,作为 Ktrace 第二大工程,它有定时采集线程快照的能力,并将快照以日志的形式保留下来,看到这是不是感觉我们平时做得拆装、Hook 相关的一些工作系统早已经在内核层面帮我们预置了,并且由于是在内核层面采集的,这些数据用于 App 的性能分析完全如同降维打击一般,我们几乎无须担心数据的准确性,以及采集工具的性能损耗,我们只需要打开开关,过滤出你所关心的 App 对应的数据,即可进行问题的分析与归因。

那么我们如何访问这些数据?有些同学可能会猜测,既然是内核数据,是不是就需要获取越狱权限才行?其实不然,Apple 早已经为我们开启了后门服务,大家先记住这个端口号,62078,这个端口曾经也被黑客当作漏洞一样使用,但它就是达摩克利斯之剑,既是漏洞,也是福利,它主要的能力也类似于 adb,如同 adb 一样,我们在 ESB 建立连接并试用后就可以通过 Socket 通信进行数据访问了,而这个后门服务目前已经在业内的各大开源库中正常使用,如比较有名的 mobiledevice、 Facebook 的 idb,以及阿里的 tidevice 都在使用这个后门进行数据通信。
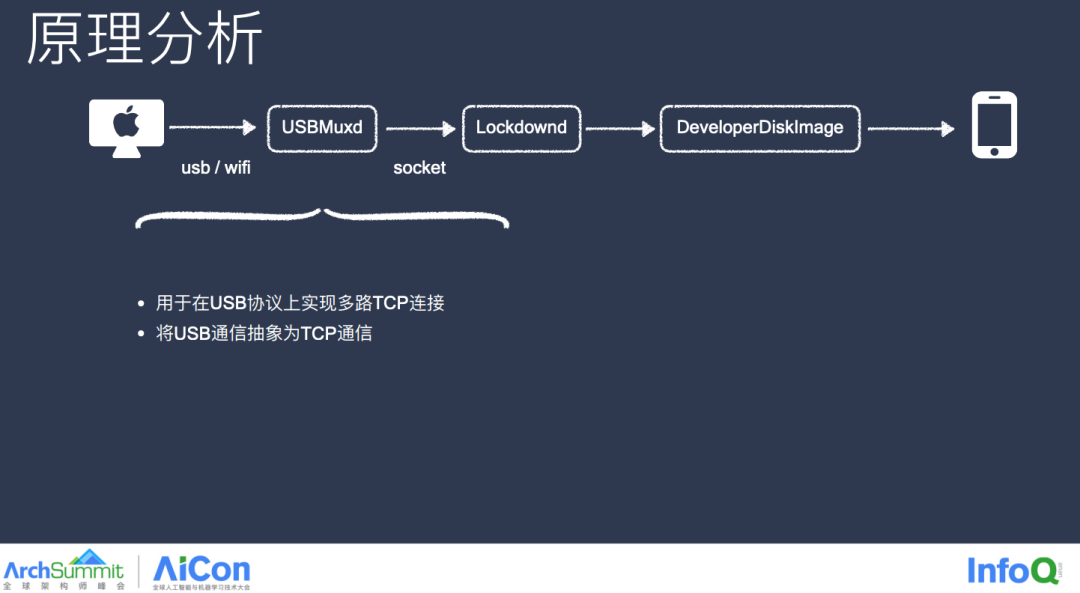
接下来我们简单看一下这个后门服务是如何运转的。通信之前,我们首先得建立连接,在 Mac 上使用的是 USDMuxd 这个服务进行数据通信,USDMuxd 本质是 USB 协议上的一个多路 TCP 连接,既将 USB 抽象成 TCP 通信,使用它,我们可以通过 Socket 与设备进行连接,连接有了,接下来我们看看消息是发到哪里才能被设备响应的?
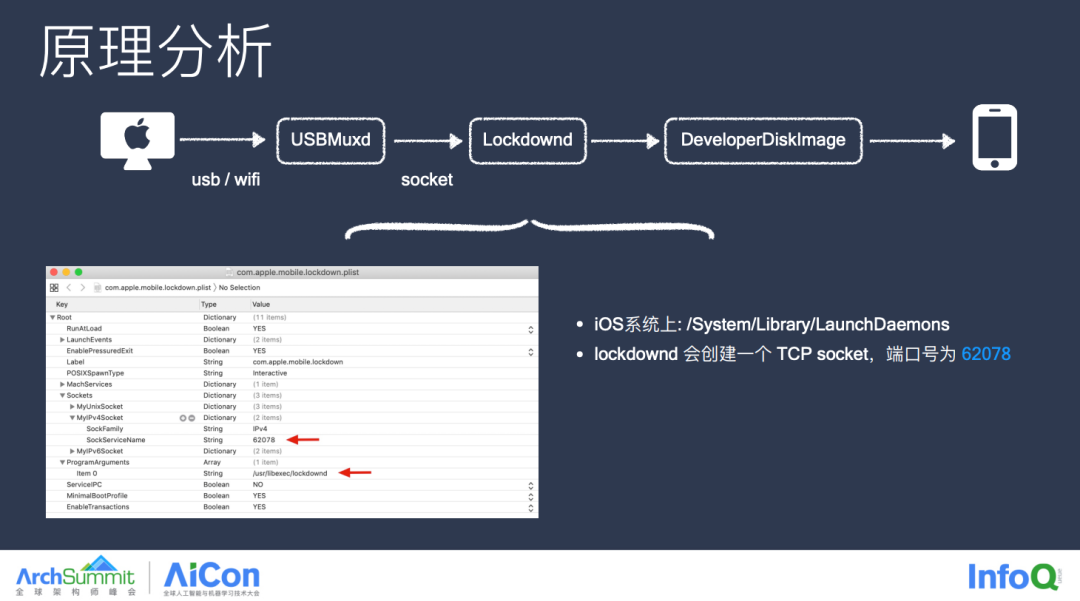
这里首先介绍一下 Lockdownd 这个守护进程,简单理解,你可以把它类比成手机端接收远程消息的一个网关,拦截各种非法消息,在 System 路径下我们可以找到 Lockdownd 这个 Plist 描述文件,可见 Lockdownd 这个守护进程会创建一个端口号为 62078 的 TCP Socket,也就是前文中提及的那个后门的端口号,有了这个 Socket 以及端口号,我们就可以发送消息了,但具体发送什么消息才算合法的?设想一下,如果是你设计这个通信方案,你需要远程执行一些设备端的能力,你的消息体会包含哪些信息?
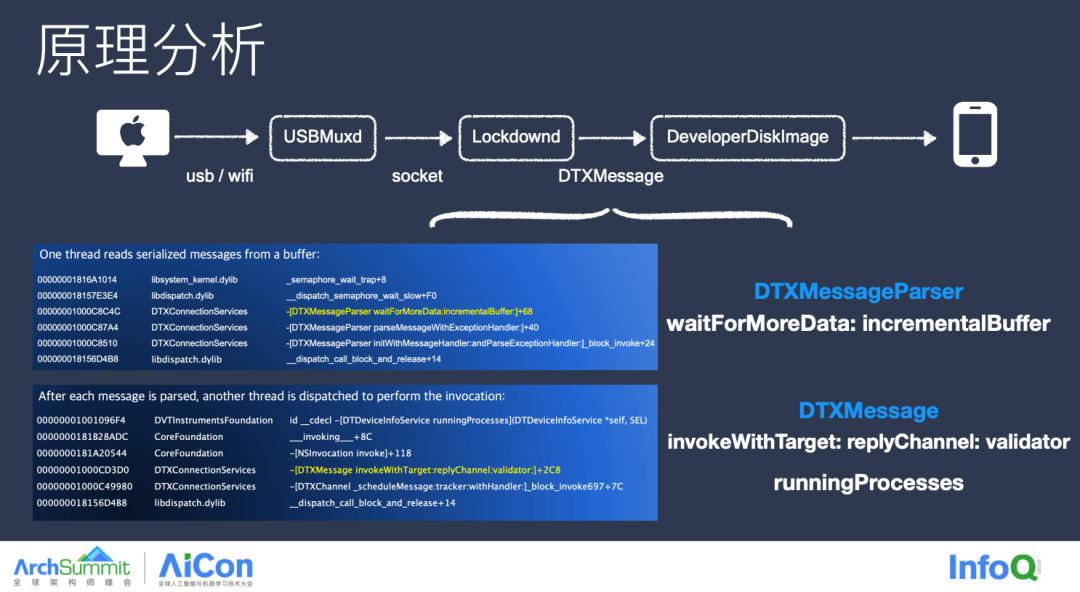
我们需要的是类名、方法名和具体的参数,当然苹果也是这么设计的,这里通过捕获两个手机端的堆栈可以看到,第一个堆栈是 DTXMessage 用来解析 Buffer 消息,而第二个堆栈是 DTXMessage invokeWithTarget,这个 API 是否很像消息转发的 API?通过堆栈可以看到 DTXMessage 最后执行了 Running Processes 这个能力,既获取当前设备的活跃进程信息,我们只要知道这个 DTXMessage 数据格式就能发送对应的消息了,而这个数据格式目前在开源库中都已经提供出来了。

有了通道,有了所发消息的格式,最后我们就来看一下消息发送之后,手机端是如何响应的,大家都知道 iPhone 升级系统之后 XCode 需要添加对应设备的 Device Support 才能继续调试,有没有想过这个 Device Support 是干吗的?这边展开来看可以发现里面有大量的私有库,通过名字我们可以大胆的猜测,它就是 Instruments 和 GPU Tools 等工具的一些具体实现,它也就是前文中提及到的后门服务的具体实现,我们通过将这些 Image 挂载到手机上就能访问对应的一些能力了,这个设备重启之后,这些挂载的 Image 就会自动卸载,一定程度上也保障了 iPhone 设备的安全性。
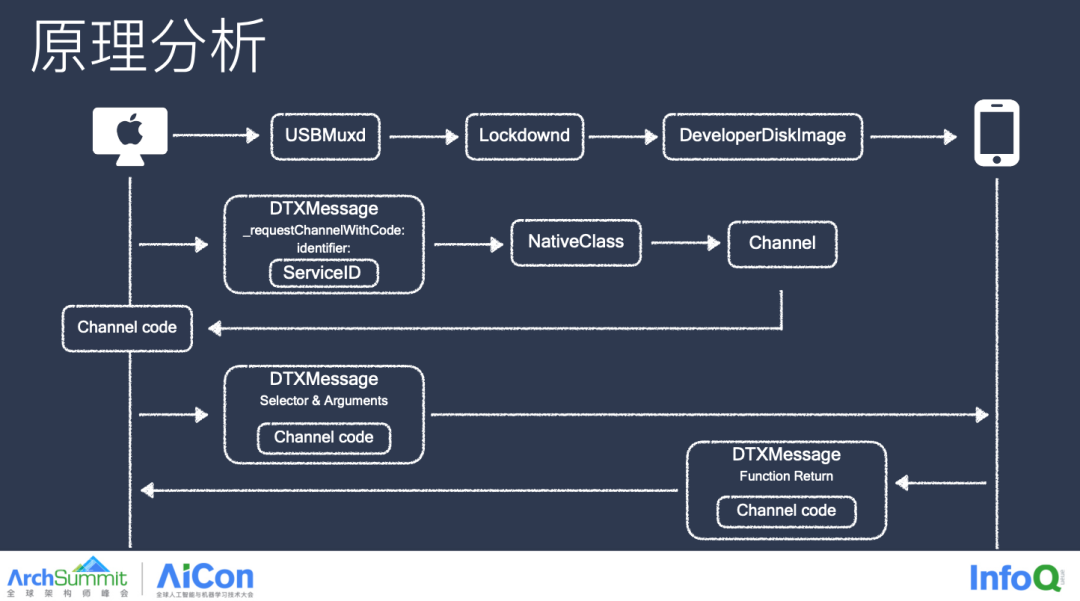
接着我们回顾一下通信的整个流程,首先我们会携带 ServiceID,发送 requestChannel 的消息,获取刚刚看到的各种 Framework 中 Class 与 Channel 的绑定关系,返回一个 Channel Code,这个 Channel Code 就是我们下次访问消息所需要的 Token 信息了,我们通过 Channel Code 再拼接我们刚才所说的 Selector 和 Arguments 的一些参数就能远程调用设备端的一些能力了,而设备那边执行完成之后,也会通过 Channel Code 返回执行的结果,从而完成一次完整的通讯链路,有了这个链路我们就能直接和内核层进行数据通信了。
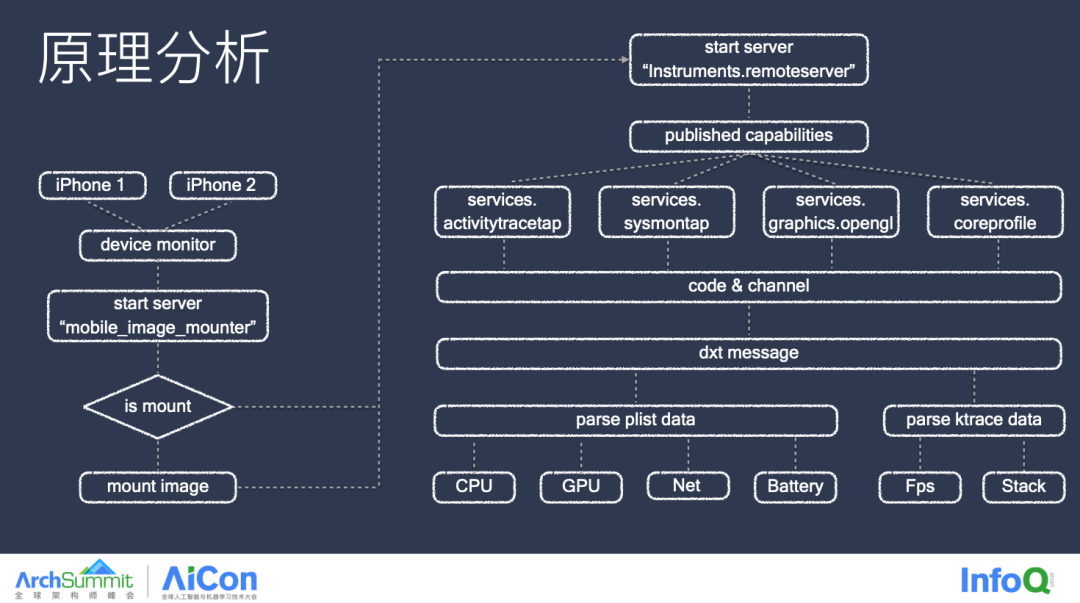
最后我们再回顾一下整体的流程图,当手机连接工具的时候,我们会将 Image 进行判断,并且挂载到手机上,挂载完成之后我们就能访问对应的后门服务了,我们通过这个后门服务能访问大量内核层的数据,将这些数据进行清洗封装之后,我们就能获得各个的指标数据,以及线程快照的一些数据了。
总结回顾
接着我们做一个简单的回顾,本次分享首先介绍了工具的发展史,并确定了工具的目标,然后我们分别从卡顿、内存、功耗三类场景介绍了归因提效的手段,以及如何使用 FastBot 提高数据生产的效率。最后我们通过火焰图的采集消费为例,介绍了使用 iOS 后门和 Ktrace 采集线程快照的基本原理。我们创作这个工具的初衷是让工具变得更简单,使归因不再有门槛。
最后感谢字节 AppHealth 以及各个业务方同学的技术方案以及落地实践,同时也感谢主办方以及老师的指导意见,以上所介绍的功能能力都源于字节内部的 Diggo 项目,目前也正在计划将这些能力以 Anytrace 的这个项目逐步提供给大家使用,感兴趣的同学可以关注一下,共同交流,谢谢大家。




