
开源模型疑似泄露,开发者纷纷下场测试
近日,一则关于“Mistral-Medium 模型泄露”的消息引起了大家的关注,该消息在 Hacker News 和 X(原 Twitter)上持续发酵。
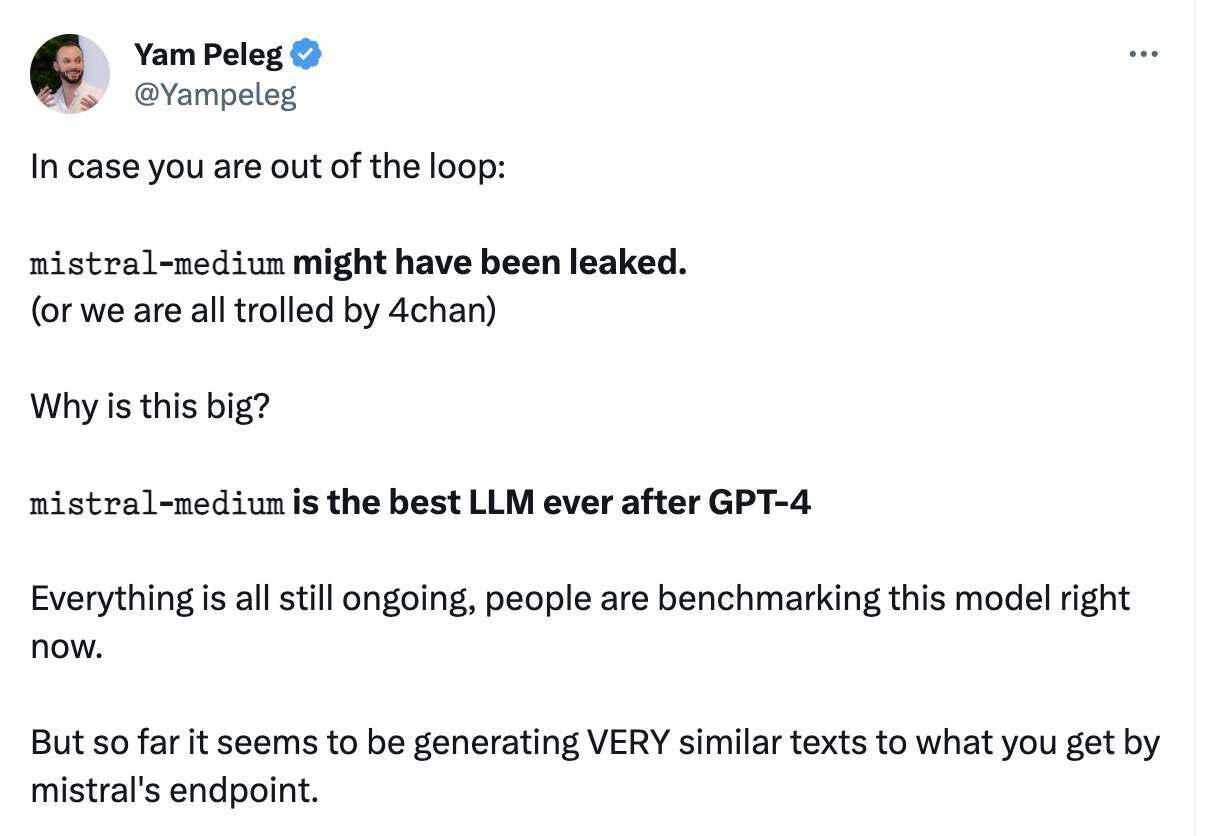
此消息之所以受到这么多关注,与一款叫做“Miqu”的神秘模型有关。
1 月 28 日左右,一位名为“Miqu Dev”的用户在开源 AI 模型和代码共享平台HuggingFace 上发布了一组文件,这些文件共同构成了一个看似新的开源大语言模型,名为“miqu-1-70b”。
开源地址:https://huggingface.co/miqudev/miqu-1-70b
在 Hugging Face 平台的 miqu-1-70b 项目上,多条内容指出这款新的大语言模型的“提示格式”以及用户与其交互的方式与 Mistral AI 公司正在研发中的 Mistral Medium 模型相同。同一天,4chan 上的一位匿名用户(可能是“Miqu Dev”)在 4chan 上发布了 miqu-1-70b 文件的链接,该项目的受关注程度逐渐升高。
模型放出后,有业内人士猜测,这个神秘泄露的 miqu-1-70b 可能就是 MistralAI 模型的 Medium 或者过往混合专家测试版本。
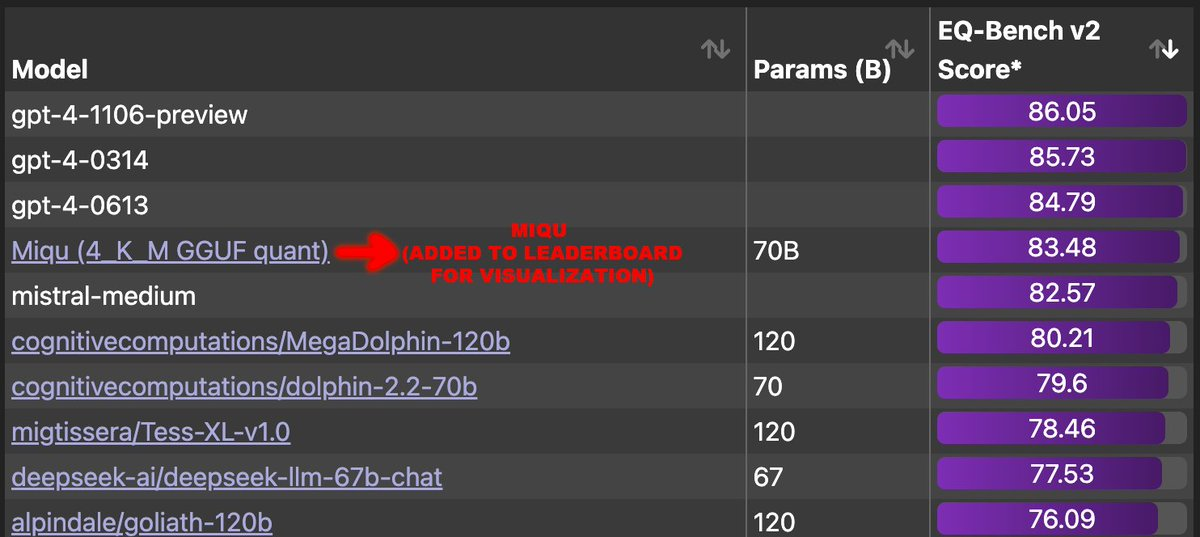
一些人用户在 X 上分享了该模型的发现,以及该模型在常见 LLM 任务(通过称为基准的测试来衡量)上表现出的异常出色的性能,甚至接近了 OpenAI 的 GPT -4 在 EQ 工作台上的表现。
有用户测试了这款神秘模型和 Medium 模型后表示:“尽管可能有些晚了,但现在我 100%确信 miqu 与 Perplexity Labs 上可访问的 Mistral-Medium 模型是同一个模型。该用户还称:“它似乎知道标准谜题,但如果是恶作剧者,根本不可能将其调整为同样用俄语回答。”
这款备受瞩目的生成式 AI 新星——miqu-1-70b 自然要被拿来与各位前辈进行一番比较。有测试者用 4 项德国数据保护测试对这款神秘模型做了更深入的测试,方法如下:
这里通过 4 项德国在线数据保护培训/考试,对这套新模型的表现加以验证。
测试数据、问题及所有说明均为德语,而答题卡则为英语。这考察了模型的翻译能力和跨语言理解能力。
在提供信息之前,测试者会用德语指示模型:接下来向你提供一些信息,请记住相关内容,并回答“确定”以确认已经理解其内容。这一步是为了测试模型的指令理解与遵循能力。
在提供关于某个主题的全部信息之后,测试者会向模型提出测试问题。这是一套包含三个选项的多选题,但首题采用 A/B/C 选项,末题为 X/Y/Z 选项。每项考试包含 4 至 6 道题,测试流程总计 18 道选择题。
根据模型给出的正确答案数量进行排名,先测试事先提供课程内容后的成绩,再测试没有提供信息下的盲答成绩(作为决胜局)。
所有测试均单独运行,每次测试间会清除上下文,保证会话之间的记忆/状态不相互干扰。
还进行了包括SillyTavern前端、koboldcpp后端(对于 GGUF 模型)在内的其他测试,另外还预先设置确定性生成,以尽可能消除随机因素并进行有意义的模型间比较,也包括注明官方提示词格式。
以下为详细注释、排名基础和其他评论与观察发现:
miqudev/miqu-1-70b GGUF Q5_K_M, 32K 上下文, Mistral 格式:
❌ 正确回答了 4+4+4+5=17/18 道选择题,而在盲答阶段,正确答案题为: 4+3+1+5=13/18。
❌ 未能按照要求用“确定”来回应数据输入。
经过了多项测试后,结果显示 miqu-1-70b 的效果着实不错,测试者出于个人猜测,miqu-1-70b 可能是一套外泄的 MistralAI 概念验证旧模型,从开发次序来讲应该不会比 Mixtral 更晚。此外,测试者也表示,在测试过程中注意到了几个有趣的点,从这几个方面来看,miqu-1-70b 跟 Mixtral 存在诸多相似:
优秀的德语拼写与语法能力。
支持双语,可在回复中添加翻译。
能够为回复添加注释和评论。
但测试者也表示,在测试中,miqu-1-70b 仍无法与 Mixtral-8x7B-Instruct-v0.1(4-bit)相媲美,不过性能仍比 Mistral Small 和 Medium 更好(亲自测试 Medium 时其表现相当糟糕,可能是 API 的问题)。但与测试者每天都在使用的 Mixtral 8x7B Instruct 相比,miqu 也没有好太多。
在这场 miqu 和 Mistral Medium 模型对比测试中,前阵子号称要干掉谷歌搜索的 Perplexity 印度创始人 Aravind Srinivas 也在 X 上发表了自己的观点:
很多人问我 Mistral 的所有模型是否都基于 Meta 的 Llama。特别是因为 Mistral Medium 在 Perplexity Labs 上的输出与 miqu 非常相似,而这种相似性是通过测试发现的。Mistral 的 CEO Arthur 已经提供了一个清晰的解释,并确认这是一个来自早期访问客户的泄露。
此外,Perplexity 从未获得过 Mistral Medium 的权重访问权限。所以,当你在 Labs 上使用 Mistral Medium 时,我们只是将你的请求路由到 Mistral 支持的有效端点,而没有访问权重。泄露的权重实际上是量化版本,与 NVIDIA TensorRT 不兼容。
此外,很多人在看到这个消息是本能地反应会认为 Mistral 不知道如何进行预训练,只是在 LLama 2 上构建。这是明显不真实的。Mistral 7b 是一个由 Mistral 团队从头开始训练的模型,而 Mistral 8x7b MoE 也是通过使用他们自己的 7b 作为每个专家的初始化来训练的。所以很明显,这个团队知道如何从零开始训练自己的模型。Mistral Medium 是从 LLama 后期训练的,可能是因为迫切需要一个接近 GPT-4 质量的 API,以便早期客户使用。但是一个能够在计算和时间投入远少于 Gemini Pro 的情况下取得胜利的团队,现在他们有了更多的资金和计算资源,显然能够做到 GPT-4 级别的质量。
当然,泄露是不好的。Mistral 的胜利对社区来说是一件好事:无论是对学术界还是对初创公司。支持他们!
Mistral AI 高层发声:是泄露了,但只是个旧版本
在 Mistral AI 的新模型遭泄漏这一话题热度不断上涨之时,据外媒最新消息,Mistral AI 联合创始人兼 CEO Arthur Mensch 在 X 上澄清:
“一个我们早期客户的热情员工泄露了一个我们公开训练和发布的老模型的量化(带水印)版本。为了尽快与一些特定的客户开始合作,我们在获得整个集群访问权限后立即从 Llama 2 重新训练了这个模型——预训练在 Mistral 7B 发布的那一天完成。自那时以来,我们取得了很好的进展——敬请期待!”
有趣的是,Mensch 并没有要求删除 HuggingFace 上的帖子,而是留下那些评论说发帖者“可能会遭到模型所属公司追责”的评论。
Mistral AI 创始团队成员均来自谷歌和 Meta
Mistral AI 是一家总部位于巴黎的欧洲公司,由 Arthur Mensch 和 Guillaume Lample 以及 Timothée Lacroix 于 2023 年 2 月联合创立,并于去年 12 月 10 日宣布筹集了 3.85 亿美元,仅半年多的时间,该公司估值近 20 亿美元。Mistral AI 在刚成立且没有任何产品时就已筹集了 1.05 亿美元。
因此,它也成为继德国 Aleph Alpha 在去年 11 月筹集了 5 亿欧元之后,第二家筹集到如此多资金的欧洲人工智能初创公司。
Mistral AI 一直在研究如何提高模型性能,同时减少为实际用例部署 llm 所需的计算资源。Mistral 7B 是他们创建的最小 LLM,它为传统的 Transformer 架构带来了两个新概念,Group-Query Attention(GQA)和 Sliding Window Attention(SWA)。这些组件加快了推理速度,减少了解码过程中的内存需求,从而实现了更高的吞吐量和处理更长的令牌序列的能力。
Mistral AI 首席执行官 Arthur Mensch,31 岁,在 Google 人工智能实验室 DeepMind 工作了近三年。Mistral 的科学总监 Guillaume Lample 是 Facebook 母公司 Meta 在 2 月份推出的 LLaMA 语言模型的创建者之一。Timothée Lacroix 是 Mistral AI 的技术总监,也是 Meta 的研究员。
参考链接:
https://twitter.com/Yampeleg/status/1751837962738827378
https://analyticsindiamag.com/mistral-ai-challenges-dominance-of-openai-google-meta/




