
背景:
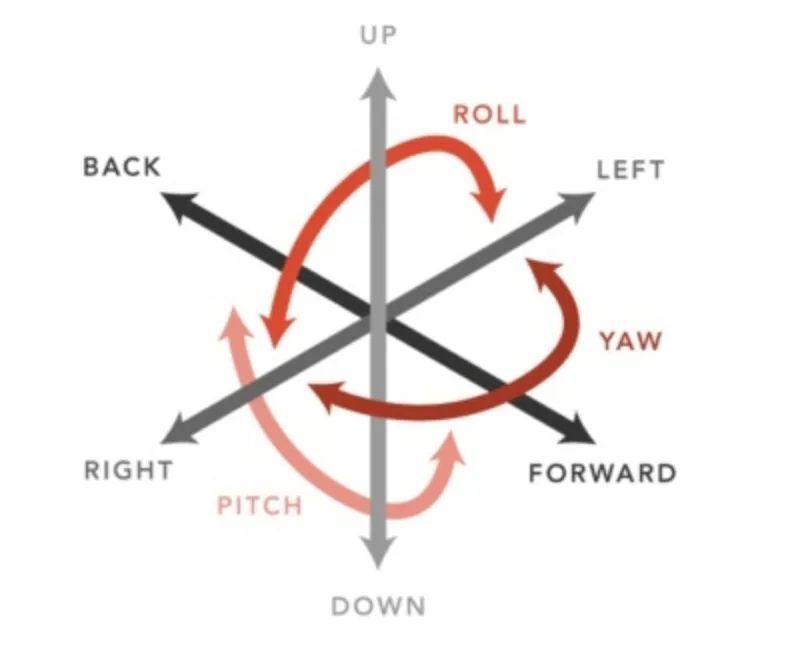
全景视频技术是 VR/AR 领域实现 3D 视频中的一项重要技术,而传统的全景视频仅具有三自由度( 3DOF ),即观察者的位置是固定的,只能体验到偏航( yaw ),俯仰( roll )和侧倾( pitch )这三个自由度。而当允许六自由度( 6DOF )的时候,观察者可以在有限的空间内自由移动,可以充分体验到偏航,俯仰,侧倾,以及前/后,上/下和左/右,如下图所示。
全景视频的内容分为计算机图形学渲染图像和拍摄的实景。对于后者来说,实拍视频摄像机位置都是确定的,在观看时如果移动视角,对应的新位置存在数据缺失的问题,从而导致观看图像的不规则拉伸变形,如下图(图 1 )。如果每个视点都采集一副全景图片的话,数据量过于庞大。为了解决数据量过于庞大的问题,过往方法中的六自由度的全景视频都会引入深度来解决,深度获取上,往往需要构造彩色或/及深度相机的阵列来得到。
本文提出了一种低成本且易用的六自由度全景视频技术。我们引入深度神经网络,不仅可预测全景视图的深度视图,而且可自动智能填补移动视角时候出现的数据缺失,从而使观察者可以在一定范围内的自由空间“随便走“,并且观看图像不变形,如下图(图 2 )。特别的,本文的方法可以很好的估计全景视图的深度视图,不依赖于深度摄像机,所以使用范围不受限,同时包括室内和室外。

图 1

图 2
技术介绍:
全景视频中的深度信息:
首先,我们先看一下什么是全景视频中的深度信息。深度信息是指视频/照片中每个像素在具有色彩信息以外,还带有一个深度信息,即我们通常所说的 RGBD 中 D/Depth ,它表示的是该像素距离相机成像平面的距离。而全景视频的深度信息则是周围 360 度空间中所有的像素点,都带有距离信息,所以提供了丰富的 360 度场景结构信息。
深度信息的捕获一般分为主动(结构光, ToF )和被动(计算机视觉计算 Multi View Stereo :通过多张照片来计算深度)两种。主动的方式需要深度获取设备,而设备存在室外影响、多设备多径干扰等问题。另一方面,被动的方式需要复杂的计算,鲁棒性很难达到标准,尤其对于低纹理、重复纹理、透明纹理和高光纹理等情况。
全景视图深度估计模型:
我们提出采用深度学习的方法来估算全景视图所对应的深度视图,深度网络采用经典的编码器-解码器模型,其中编码器可采用常用的 backbone 模型,如 ResNet , VGG 等;深度解码器会将输出转换为深度值的输出。为了满足高分辨率的全景视频的深度估计,我们将各个尺度的损失合并在一起,做多尺度的估计,可以实现对目标全景视图的高分辨率深度重建。
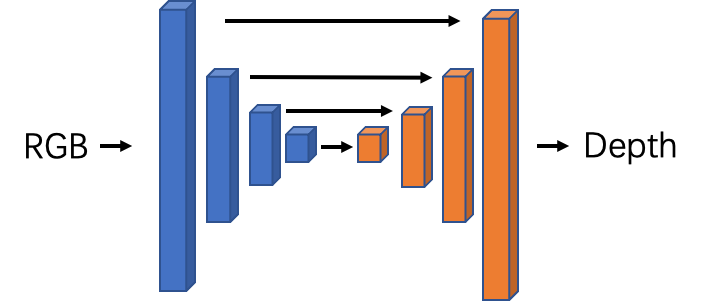
全景视图深度估计模型
采用我们的训练模型进行预测,如输入下图的全景视图,就可以输出相对应的深度视图的结果,如下两组图片所示:




全景视图及其对应的深度视图结果
RGB+D 训练数据:
上述的全景视图深度估计模型需要大量的 RGB+D 训练数据,而这方面的公开数据集较少。我们采集并生成了两大类训练数据(作为我们自研的全景视图 RGBD 数据集),包含利用自建设备搭建去采集得到的 groudtruth 数据,以及 Computer Graphics 生成的 groudtruth 数据两种,来构建全景视图及其对应深度视图的自有训练数据库。

采集设备
一、 我们搭建了全景视图及其深度视图的采集设备,深度采集使用 ToF 相机,如上图所示。使用消费级手机、 ToF sensor 、云台、三脚架及专用采集 APP 来获取,可同步获取颜色和深度信息。专业云台可以固定角度间隔拍摄多张 RGB 和 D 的图像对。这里,为了改善 ToF 相机拍摄结果的质量不足,尤其是过曝和欠爆导致的黑洞,我们提出了实时低成本的深度补全算法,来增强原始拍摄深度图的质量,如下图流程及结果(左:拍摄深度图的 warp 变换结果;右:增强深度图结果)所示。
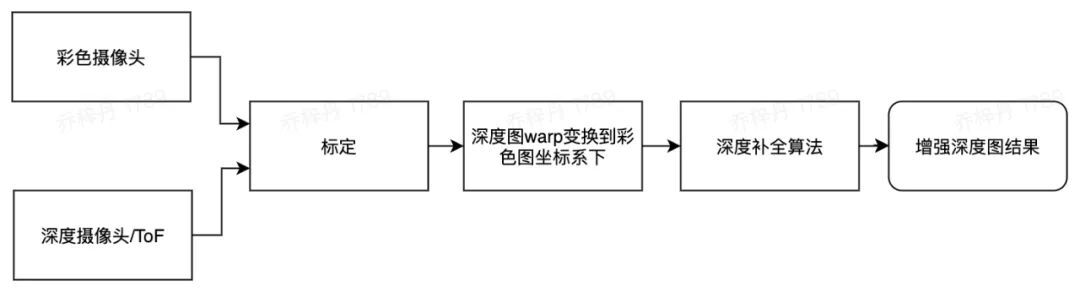
RGB+D 图像对生成算法

深度补全算法
由上面的流程图可以看出,彩色图和深度图可以借助标定算法进行对齐,称为 RGB+D 图像对。对于多个 RGB+D 图像对,我们采用经典的全景视图拼接算法,即通过特征点匹配的方式,获取精确的相机位姿,并进行拼接、后处理得到最终的全景视图及其对应的深度视图,来作为我们训练的 groudtruth ,如下图所示。


采集得到训练数据
二、 我们采用图形学的方式构造了一批模型场景数据,并通过 Unreal/Unity 等渲染引擎,渲染得到全景视图及其对应的深度视图,增加训练数据,补充自有数据库的不足。
全景视图填补技术:
如前面所述,由于实拍全景视频的摄像机位置都是确定的,在观看时如果移动视角,对应的新位置存在数据缺失的问题。为了解决这一问题,本文提出了全景视图填补技术,通过计算深度视图的不连续处(阈值判断),并在不连续处做膨胀计算,即从不连续处像背景做膨胀,然后将膨胀结果处理成二值图作为填补/ inpainting 模型的输入 mask ,去填充并修复得到 mask 区域的彩色像素,从而获取背景填补(填充修补)结果,很好的解决了视角固定下前景遮挡背景导致的背景像素缺失问题。
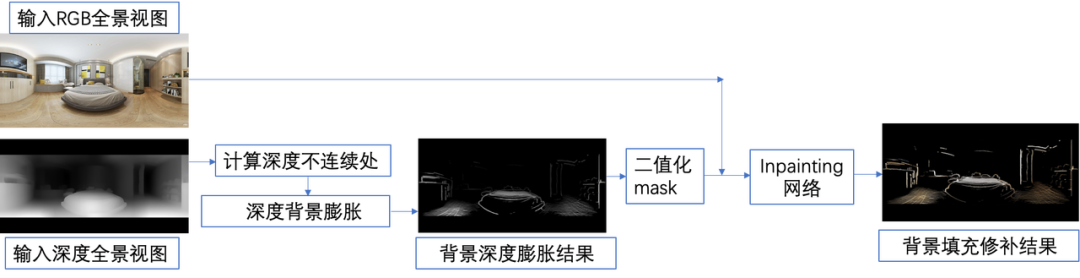
全景视图填补技术

填补结果的细节(左)及对应的深度膨胀结果(右)(上图中:电视机下的书架处)
自由视点漫游绘制:
当获取全景视图、全景视图对应深度视图、背景填补视图、以及背景填补视图对应深度视图后,我们就可以按自由视点漫游的方式,绘制得到六自由度的全景视频。我们的绘制流程如下:
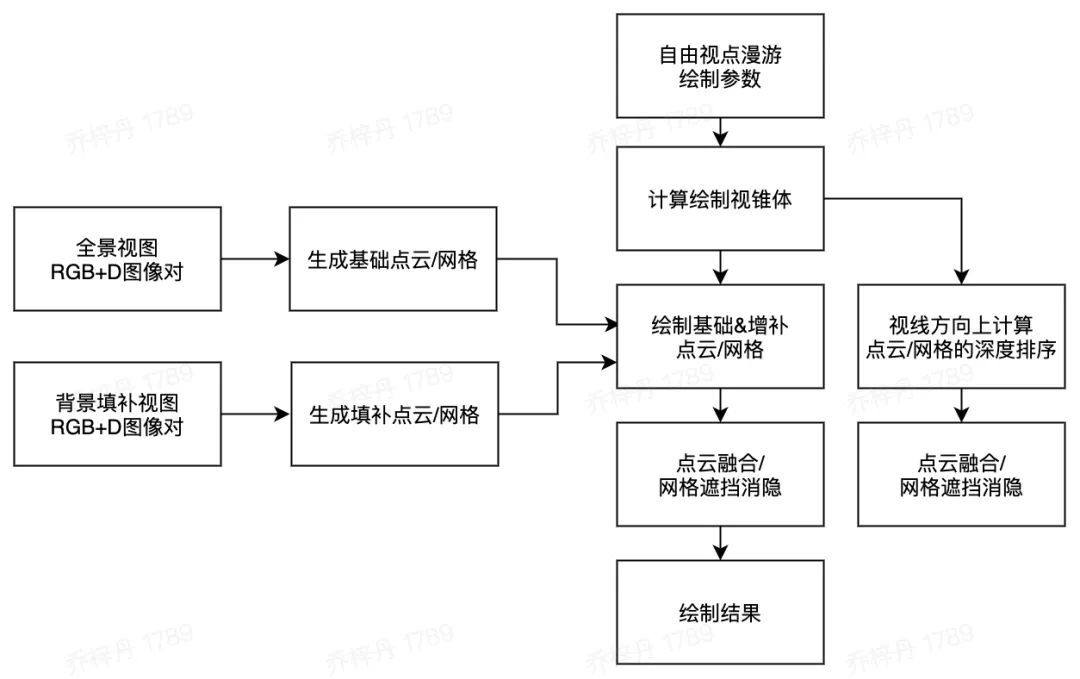
绘制流程
在本文的方法中,用户可选取自由视点,即可改变视点三维位置及视线的三维朝向,绘制得到具备六自由度的全景视频。我们的优点是我们可以绘制得到无拉伸变形的高质量结果,并且该结果具备运动视差( motion parallax ),这是因为我们在全景视图中加入计算了深度信息;另外,我们估计并预先生成了背景缺失部分的填补像素( RGB+D ),可以很好的填补空洞,弥补采集数据的不足,最终达到低成本、高质量的六自由度全景视频。
整体解决方案:
本文介绍的六自由度全景视频解决方案,包含全景图( RGB+D )采集设备,算法 SDK (后续可灵活部署为云服务):全景视图拼接、全景视图估计深度、背景填补模型,以及可以进行自由视点漫游绘制的用户端播放器。
我们的整体解决方案可以用于各项 VR/AR 及各类型 6DoF 视频(包含:子弹时间、自由视点视频等)。特别的,我们的方案采用端-云结合的计算框架(下图),首先在云端存储六自由度全景视频相关数据,客户/用户端在播放器发起观看参数的交互修改,并更新计算自由漫游视点的绘制参数,上传该绘制参数到云端进行全景视频的绘制,并下发当前的高清绘制结果到用户处的播放端显示。
端-云结合的计算框架,可以让我们利用云端的计算设备(如 GPU ),高效地绘制 10K-16K 分辨率的全景视频数据( RGB+D ),获取高分辨绘制结果( 1K-2K )后,可下发至用户处客户端。该框架可以有效的结合端-云的优势,得到低延迟高质量的六自由度全景视频。
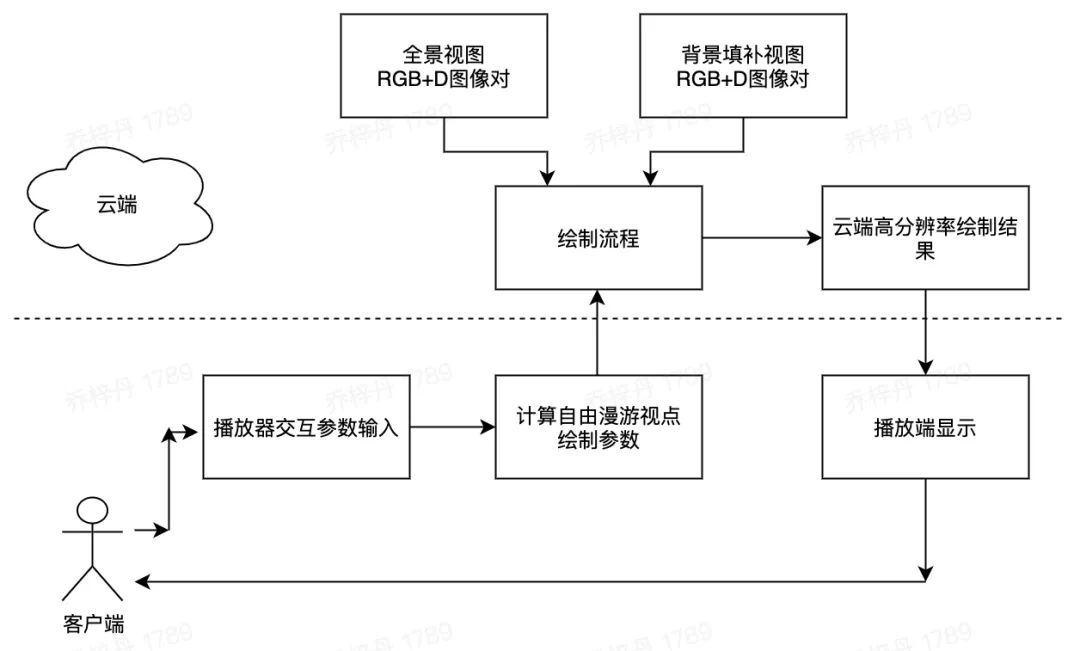
端-云结合的计算框架
总结:
本文所介绍的六自由度全景视频非常的先进,结合深度学习技术,可以低成本的生成传统全景视频对应的深度视频,并且高质量的填补被前景遮挡的背景像素( RGB+D ),从而在自由视点的漫游过程中,生成无变形拉伸,且具备运动视差的六自由度视频。而且本文的解决方案,包含自研硬件采集设备以及端-云结合的计算框架,可以在实际应用中,低延迟生成高清结果,用于 VR/AR 及下一代 6DoF 视频中。




