
本文最初发布于 Sotergreco 博客。
作为一名独立开发者,随着职业生涯的发展,我不得不尝试 Kubernetes。到目前为止,当我创建软件并为每个客户管理多个实例,而客户需要一个子域时,我都是手动进行垂直扩展。
此外,在规模比较大时,使用相同的数据库为所有人提供服务并不是个理想的选择。单实例很脆弱,因为一旦它出现了问题,就什么都出问题了。
想象一下,如果 linktr.ee 宕了,那么它的所有子域或处理就都会出问题。为了解决应用程序面临的这个问题,我设法完成了 Docker 化,并在我所有的服务中添加了 Kubernetes。
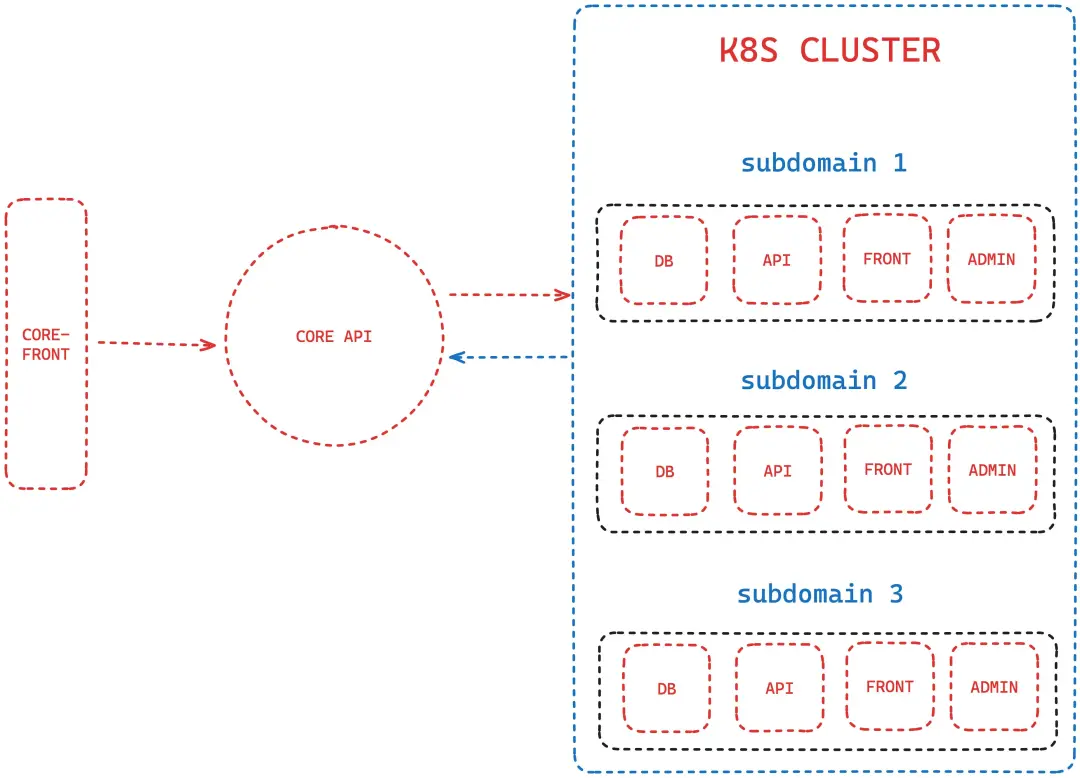
在深入讨论之前,让我们先看下我设计的架构。我有一个核心 API 和用于处理支付和订阅的前端,一个管理面板,以及针对每个客户的前端和 API。
每个客户都有自己的服务,这些服务都在他们自己的 Pod on Kubernetes 里运行。
基础设施
首先,在开始实现任何东西之前,我得寻找 K8S 部署解决方案。一开始,我考察了 AWS 和谷歌云。虽然这两家提供商都非常可靠,但也非常昂贵。
所以,我决定使用 Vultr 和 VKE K8S 引擎,它们的价格相对便宜,但有一些缺点。
最重要的问题(我通过一个变通方法快速地解决掉了)是默认存储选项不支持 ReadWriteMany for Block 和对象存储,这是使用我的 Postgres 数据库所必需的。
关于这一点,让我来进一步说明一下。当我创建多个副本时,一次只能有一个副本可以访问数据库,而不能所有副本同时访问同一个数据库。
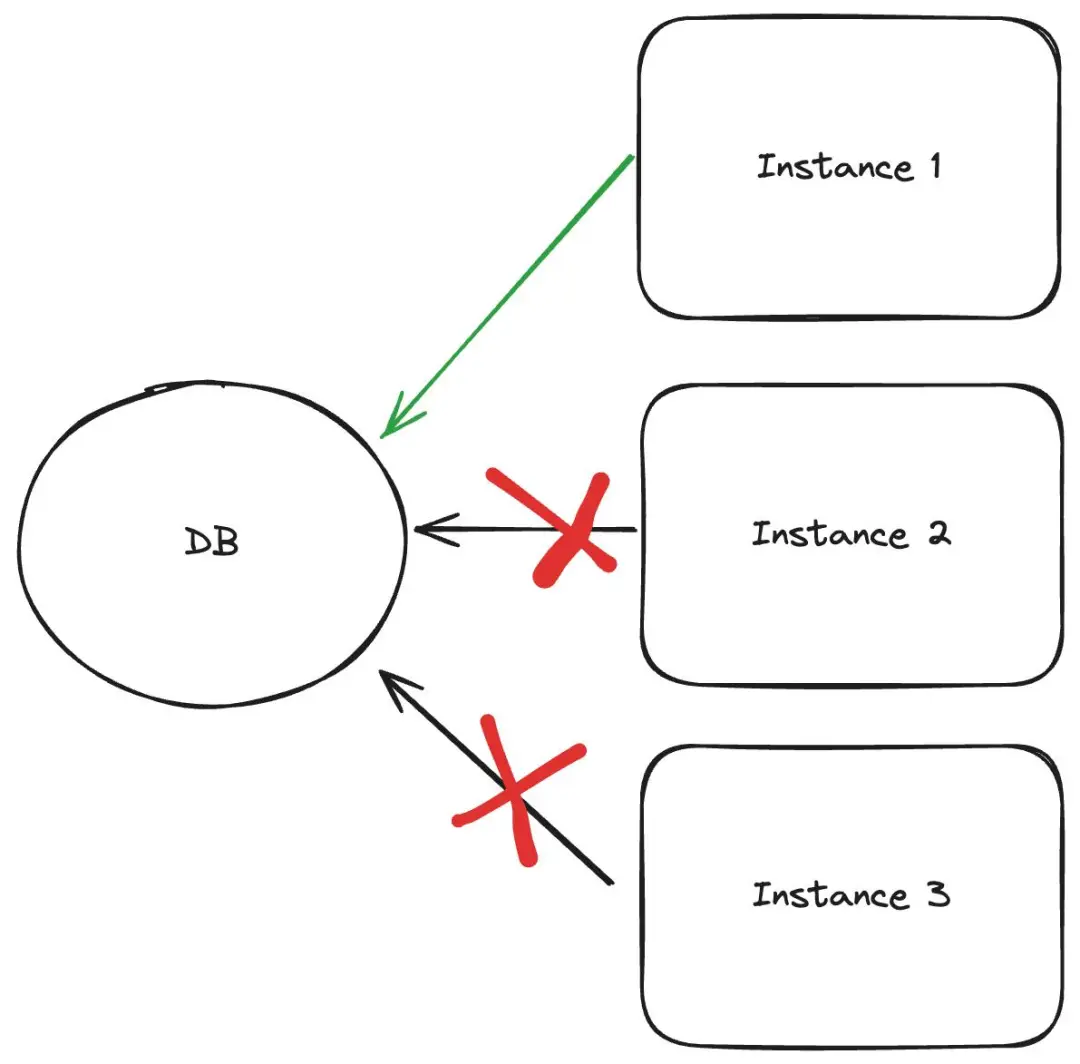
我借助 Longhorn 解决了这个问题。那是一个 Kubernetes 原生分布式块存储,默认支持 RWM,而不只是 RWO(ReadWriteOnce)。
另一种选项是创建多个数据库副本,但我现在还不想这样做,因为我的项目对数据完整性要求不是那么高。此外,我使用一个 Object Storage API 每天一次备份我的数据库。
数据库备份
我的做法很简单。我在实例的 Laravel API 中安装了一个包ayles-software/laravel-mysql-s3-backup,它提供了一个命令用于在类似 S3 的存储系统上备份数据库。
下面是配置信息:
// .envAWS_API_KEY=7ZS5446GRW9T56XPHI2AWS_API_SECRET=NFaJs89kNc4EuOFElkfgCjFJK43561LXl3TAzzCAWS_S3_BUCKET=testAWS_S3_REGION=ams1AWS_ENDPOINT=https://ams1.vultrobjects.com/BACKUP_FOLDER=store-core<?phpclass Kernel extends ConsoleKernel{ /** * 在这里定义 cron 作业命令 */ protected function schedule(Schedule $schedule): void{ $schedule->command('db:backup')->daily()->at('01:00'); }}Kubernetes 配置
K8S 使用 YAML 配置文件。因为每个存储都需要自己的 YAML 配置,所以我在我的一个 Laravel 服务中用编程的方式创建它。让我们来具体看一下。
请求有两种类型。第一种是客户注册并使用 stripe 支付,另一个是你出于某种原因想更新存储配置。
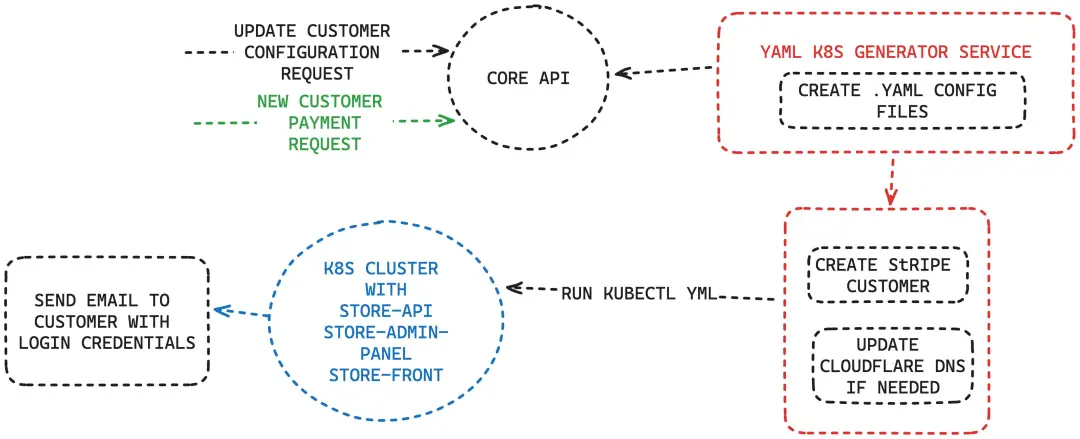
在 Core API 完成支付验证后,YAML K8S Generator Service 会创建 YAML 文件,并运行以下命令:
kubectl apply -f namespace.ymlkubectl apply -f sql-persistant-claim.ymlkubectl apply -f storage-persistant-claim.ymlkubectl apply -f service.ymlkubectl apply -f deployment.ymlkubectl apply -f configmap.ymlkubectl apply -f configmap-admin.ymlkubectl apply -f configmap-web.ymlkubectl apply -f configmap-nginx.yml我们还通过 Cloudflare API 进行连接,以便创建的子域可以指向由负载均衡器生成的具体 IP。我们像下面这样从 K8S API 获取这个 IP。
$response = Http::withOptions([ 'verify' => false, 'cert' => $clientCertPath, 'ssl_key' => $clientKeyPath, ])->withHeaders([ 'Content-Type' => 'application/json', ])->get("$apiEndpoint/api/v1/namespaces/" . env('APP_NAME') . "-$store->domain/services/" . env('APP_NAME') . "-service");return json_decode($response->body(), true)['status']['loadBalancer']['ingress'][0]['ip'];最后,我们给客户发送一封电子邮件,通知他们集群已就绪。通常,创建集群需要 2 到 3 分钟,而电子邮件则是在他们注册后 10 分钟发送。
最终的系统类似下面这样:
为什么不要这样做
对于一名独立开发者来说,这个系统太复杂了。所以在讨论它的好处之前,我要先说一下它的缺点以及你为什么不应该这样做。
在一些特定情况下,确实需要使用 Pod 来管理不同的子域,像 Shopify 那样。其中一个情况是拥有庞大的客户群,并且需要为所有客户提供高可用性。如果你不需要高可用性,那么它就毫无意义。对我而言,我需要提供高可用性,但我没有那么多客户,所以从长远来看,那可能不值得。
另外一件事是,准备这个基础设施的过程非常复杂,不值得花那么多时间。我花了大约 10 天的时间来设置所有这些系统,而我还是一名拥有多年经验的高级工程师。
最后,很重要的一点是成本。运行两个集群(一个用于生产,一个用于准生产)的成本可能非常高。相反,将所有内容托管在非常大的 VPS 或 Vercel 上,对于微型 SaaS 来说可能更值得。
在讨论它的优点之前,我还想说最后一件事:维护部分的工作。当我合并一个新功能时,我需要将更新传递给所有存储。至于我是如何做到的,则需要另一篇文章了。大体来说,我创建了一个完整的机制,将 GitHub Actions 与我的 CORE API 连接起来,用于重新生成 YAML 文件,然后部署它们。
优 点
唯一的好处是我学会了不要再做这样的事。对于一名独立开发者来说,没有理由设置所有这些内容。只有当你每个月的会话达到数百万次时,才值得这么做。因此,对于任何人来说,你可以尝试学习 Kubernetes 是如何工作的,以及如何使用大数据,但不要轻易认为那么做是值得的。
不得不说,在实现这些系统的过程中,我学到了很多东西。从时间的角度来看,这可能不值得,但从学习的角度来看,这是值得的。如果你不怕在服务器和 CI/CD 成本上”浪费掉”50 个小时和几百美元,就可以这么做。
小 结
总之,虽然 Kubernetes 为管理具有高可用性的大规模应用程序提供了一个健壮的解决方案,但它可能并不适合所有 SaaS 业务,特别是对于独立开发者或较小的项目来说尤其如此。
除非你有庞大的客户群以及特定的高可用性需求,否则这样做所带来的复杂性、成本和维护开销可能会超过收益。
然而,在实现这样一个系统的过程中所获得的学习经验是无价的。最后,在深入研究 Kubernetes 项目之前,请务必针对你的特定需求和资源进行评估,这一点至关重要。
原文链接:
https://sotergreco.com/why-kubernetes-was-a-mistake-for-my-saas-business
声明:本文为 InfoQ 翻译,未经许可禁止转载。




