
💡 近年来,开发者正迈入一个由 AI 引领的“大模型时代”,IDE 开发工具快速崛起,大语言模型在代码生成领域取得了令人瞩目的进展。本文整理自豆包MarsCode 开发工具技术专家李文超在 QECon 2024 全球软件质量 &效能大会 · 北京的演讲《豆包 MarsCode AI 编程助手提效实战》,内容围绕豆包 MarsCode AI 编程助手的背景与发展历程、豆包 MarsCode 在 AI Coding 领域的探索、分享者对 AI 编程助手的思考与展望三部分展开。
分享人介绍
李文超,豆包 MarsCode 开发工具技术专家,目前主要负责豆包 MarsCode AI 插件工程,包括 VSCode、JetBrains 等的插件体系,毕业后从事过多年的客户端基础技术、开发工具等研发工作。目前聚焦 IDE 开发工具、AI Coding 等方向。
分享回顾
首先回顾一下 IDE 智能化的进程,最近两年大模型特别火爆,其中就有关注大模型的应用 Copilot,在 AI 编程领域 Copilot 也逐渐成为我们日常开发的好帮手,通过 AI 辅助我们的编码效率有了 20%甚至更多的提升。豆包 MarsCode 来源于字节内部的孵化项目,早期基于静态分析和机器学习探索编码提效工具,有了大模型之后,我们带着提升开发者编码效率和体验的初心,在 AI Coding 领域做了一番探索。作为探索的成果,我们在 24 年 6 月在国内发布了豆包 MarsCode 编程助手这款产品。
豆包 MarsCode 编程助手发展历程
我们最早从 22 年开始探索基于大模型的代码补全能力,在这个过程中,我们自研的代码 LLM 评测集和自动评测系统,帮助我们高效地离线评测我们的模型、工程策略的效果,构建相关工程链路和线上 A/B 验证体系,辅助我们更快地验证和迭代。后来,仅具备代码补全能力已不足以覆盖用户更多的研发需求,因此我们引入了基于对话的编程助手。直到最近,我们还探索了更高自动化水平的编码能力 - 代码补全 Pro,能够预测下一步想修改的代码,并给出推荐结果。
不过,AI Coding 的产品体验仍需继续优化,我们需要从工程和算法方面提升 AI Coding 的能力,比如补全这个课题,E2E 延时的优化。如何让补全更快,辅助用户更流畅地编码,这里还有很多细节工作要做。此外,对于模型和 Agent 领域的进步,我们也在思考什么样的产品形态能更好地辅助开发者编码。
AI Coding 的探索
接下来,我将围绕豆包MarsCode 代码补全和代码补全 Pro 这两个能力来展开介绍我们在这方面的探索与思考,然后会简要分享如何利用豆包 MarsCode 帮助我们提高编码和学习效率。
代码补全
代码补全的核心机制在于预测下一个字符,这要求模型不仅要理解现有代码的上下文,还要预测开发者想续写的逻辑是什么样的,最终才能准确地为开发者推荐结果。实现这一突破的关键在于两点:一是模型需要具备强大的性能,以确保快速且准确地生成代码建议;二是 Prompt 工程设计的重要性,即如何构建有效的输入提示,让模型能准确捕捉开发者的意图。
评测体系:CPO - 更科学的指标 (Codeium)
补全的工程链路是非常复杂的,影响因素众多,涵盖模型、Prompt、前后处理等方面。那么,我们应如何科学地衡量并指导代码补全优化工作呢?若没有指标衡量,就难以实现更好的优化,所以我们需要指标体系来助力迭代和优化效果。
早期,我们通过采纳率来衡量代码补全的效果,采纳率指的是用户采纳补全的次数除以推荐的次数。例如,向用户推荐了 10 次补全,用户仅采纳 3 次,那么采纳率就是 30%。采纳率在一定程度上能够体现模型推荐的质量,然而过度追求这一指标往往容易产生误导。比如,通过减少某些场景的推荐次数来提升采纳率,我们也曾陷入类似的误区。实际上,减少推荐这类策略需要谨慎对待,过度减少推荐会导致用户侧的反馈往往是“补全提示变少,存在感很低”,用户的体感会变差。并且,采纳率这一指标不易拆解与分析,也无法较好地归纳整个补全链路的问题和优化路径。
CPO (Character per Opportunity) = (尝试率) * (反馈率) * (采纳率) * (每次采纳平均 token 数) * (token 平均字符长度)
CPO 越高,代表 Al 贡献越大,但也不能一味追求
采纳率意味着用户对 Al 推荐的满足感
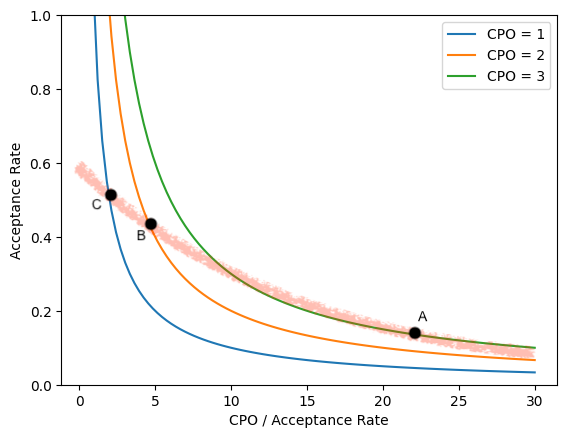
在此,我较为推荐的是 CPO,也就是每次敲键盘触发补全机会的平均字符数。CPO 的公式为:尝试率 * 反馈率 * 采纳率 * 每次采纳平均 token 数 * token 平均字符长度。这么说可能有点绕,不过我们可以这样理解,CPO 表示用户每触发一次编写, AI 带来的字符数(价值)有多少。但需要注意的是,CPO 越高,代表 AI 的贡献越大,但也不能一味追求。从图中可以看出,CPO 增高,采纳率会下降。对于用户体感而言,过高的 CPO 会造成干扰,因此需要在此方面寻求平衡。
Prompt 工程
在豆包MarsCode编程助手上,我们基于用户行为进行了一系列探索来构建 Prompt 。比如,在编写调用一个函数的过程中,通常会查看相关文件的类、函数定义、注释,以了解函数的调用方式。用户打开文件的行为与当前需要补全的代码存在一定的相关性,因此我们需要检索到这些代码片段,并将其作为上下文提供给模型。
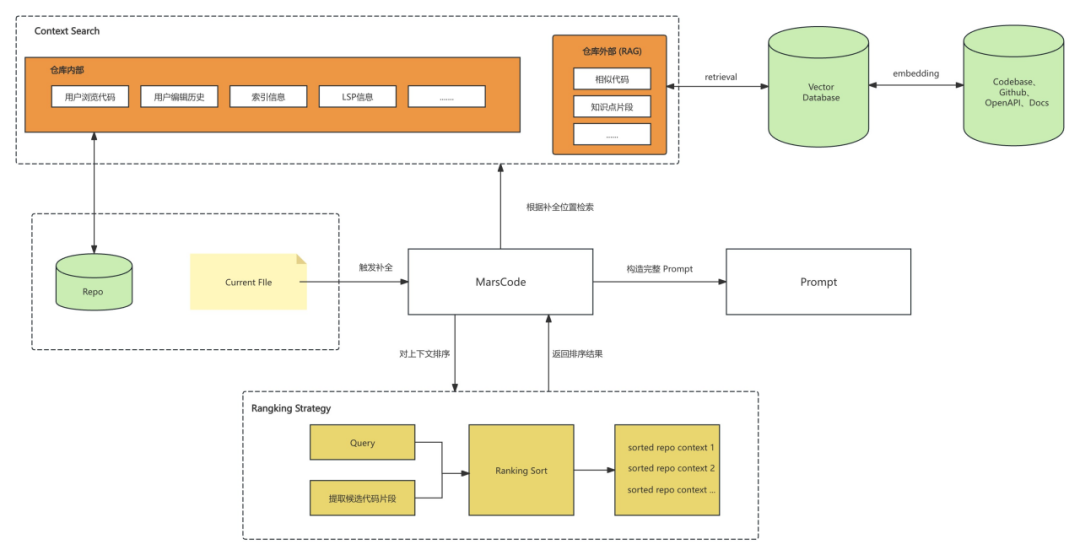
其次,我们还探究了编辑历史对代码补全效果的促进作用。在日常编码过程中,编码的顺序是具有相关性的。例如,在类中先定义了函数 A ,在下一个函数的续写过程中,很可能会调用 A 函数。所以,编码的历史行为也能够作为上下文让模型理解用户的意图。经过我们的验证,用户的编辑历史策略使线上的采纳率有了几个百分点的提升。
仓库外检索增强方面,我们探索了仓库以外的知识库。比如,在编写 UI 组件时,使用了字节的 Arco design 组件库,而这块知识模型可能并不了解,因此我们需要借助仓库外的检索能力,帮助我们找到相关的代码知识,最后告知模型正在编写的是 Arco design 的 UI 代码。
虽然有了众多的上下文,但模型的输入是有限的。所以,我们需要将与当前补全代码更相关的上下文提供给模型,这样模型才能更好地理解用户的意图。具体而言,我们设有 ranking 策略。在 ranking 过程中,首先需要依据补全的位置,提取用户意图的关键信息,例如,用户是在续写函数,还是续写 for 代码块,需要识别出这类关键信息。获取到关键信息后,我们能够通过语义化、相似度匹配的关键代码,对用户浏览的代码、用户编辑历史等上下文进行排序,最终筛选出相关度高的上下文。
前后工程链路
在前处理链路上,我们也做了一些优化。用户频繁输入字符,如果每次都触发请求,会很浪费资源,所以合理地请求模型推理,在补全链路上是一个重要的课题。


除此之外,有些低质量的推荐和 prompt 的质量是相关的。所以在请求模型前,我们也会针对低质量 Prompt 进行过滤。比如代码中存在无意义的变量名,开发者定义 String a 的变量,再让模型进行推理,模型比较难理解开发者定义的 String a 之后的意图是什么,因此大多数情况下推荐出来的结果也是比较差的,这个时候请求会被过滤。而模糊意图也会被过滤。
模型推荐出来后,补全的结果也存在幻觉、重复结果等 badcase,后处理链路会专门优化这类的 badcase。比如用户已经输入过推荐的结果,那就没必要再给用户显示了,用户也不会采纳。我们也会通过 AST 进行截断,避免模型推荐不完整的代码块等问题。
代码补全 Pro
代码补全更适用于续写和编写全新代码的场景。在研发过程中,经常会碰到修改、编辑已有代码的情况。
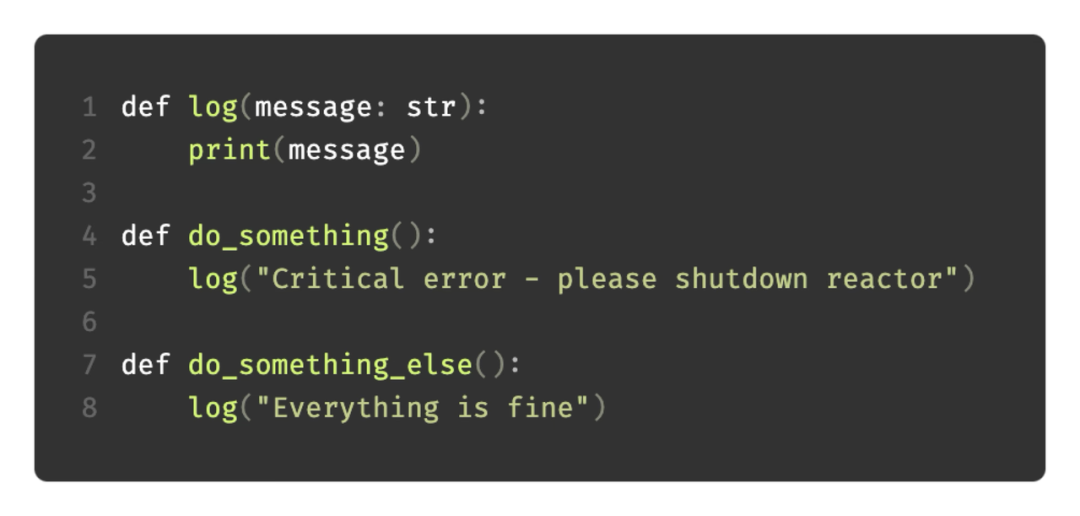
比如在 Python 中,打印日志的场景下,开发者已经实现了一个 log 函数,并在 do_something 和 do_something_else 两个函数中调用;接下来要给 log 函数增加 sourceMethod 和 level 两个参数。原来的做法是,在 log 函数中逐个输入,然后在 do_something 和 do_something_else 中将新的参数补上。
在这个增加参数的场景中,为何不让 AI 来帮忙完成修改呢?AI 能够预测,并且能更自动地在 do_something 和 do_something_else 两个函数中,将参数补齐。
技术原理
在数据的构造方面,Git 仓库中大量的 commit 记录包含了众多用户的编辑行为信息,但 Git commit 数据中也存在不少噪音,例如 .so、.zip 的变更对模型意义不大。所以,需要构建一系列的启发式规则,用于提取出有关联的修改记录。接着,通过 CT、SFT 让模型能够理解 diff 格式的数据,当触发编辑代码的请求时,就能推理出下一个光标的需要修改的行为。
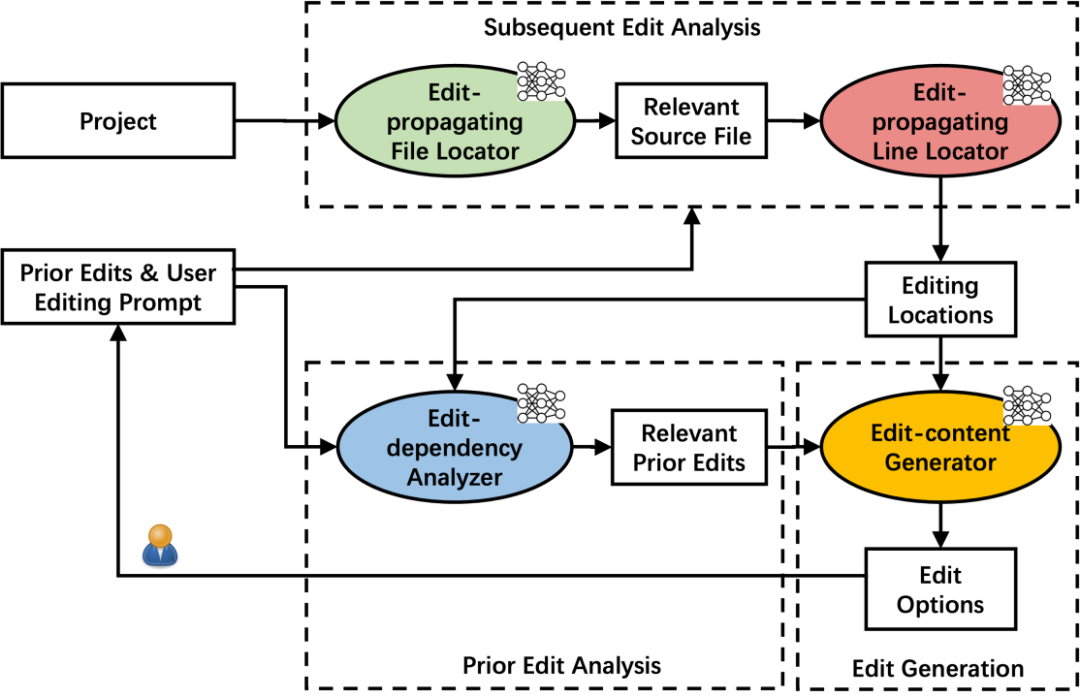
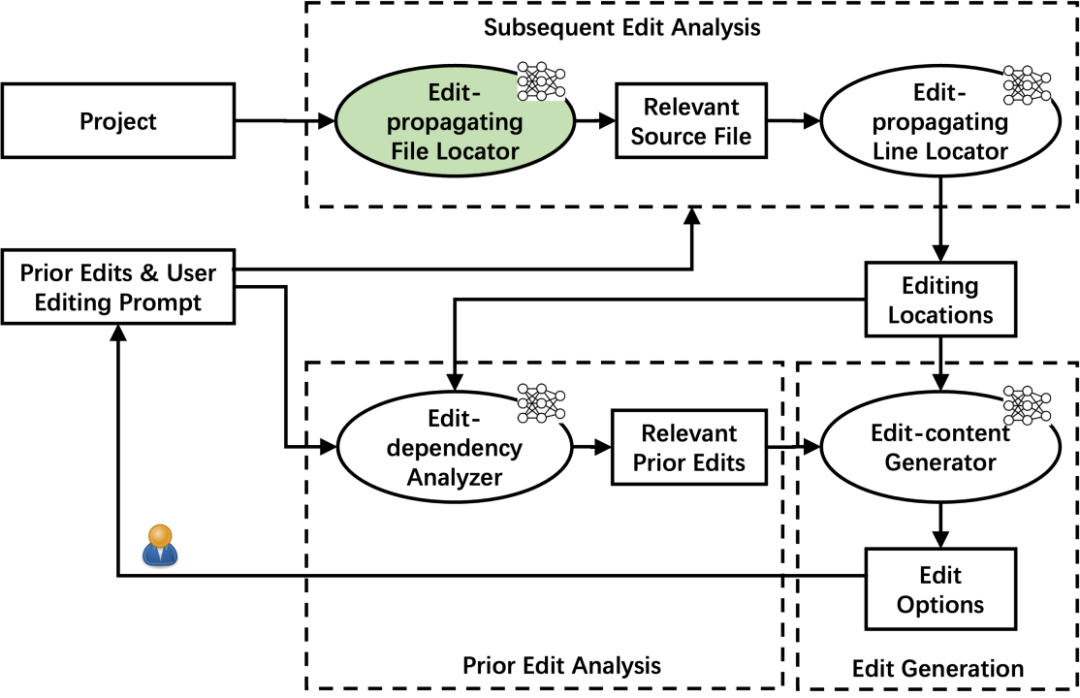
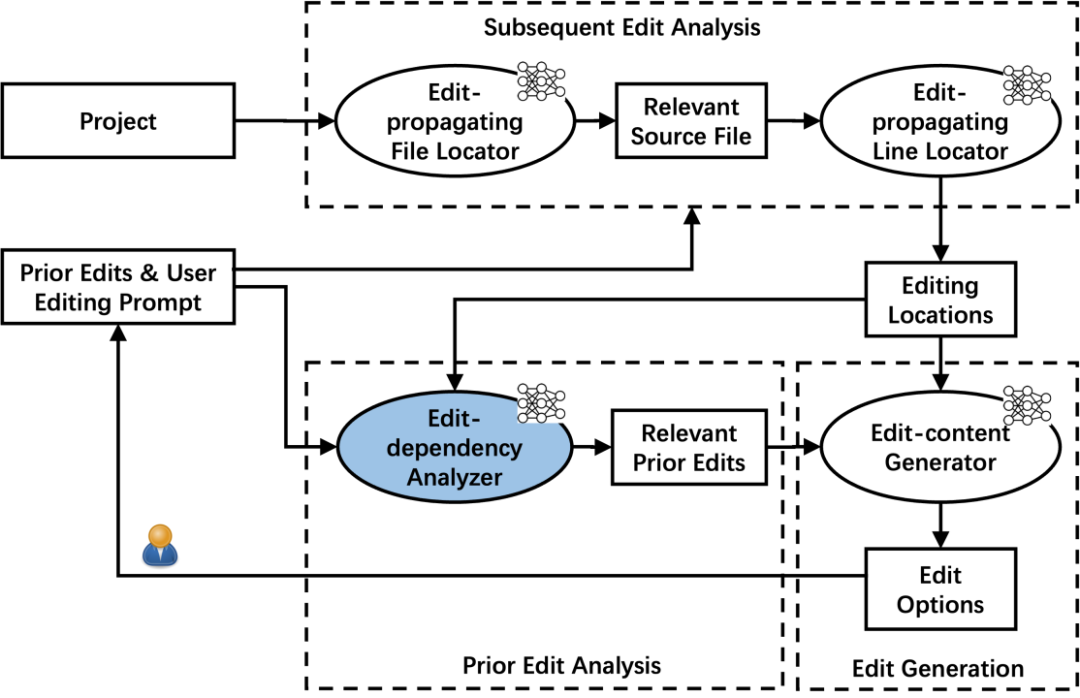
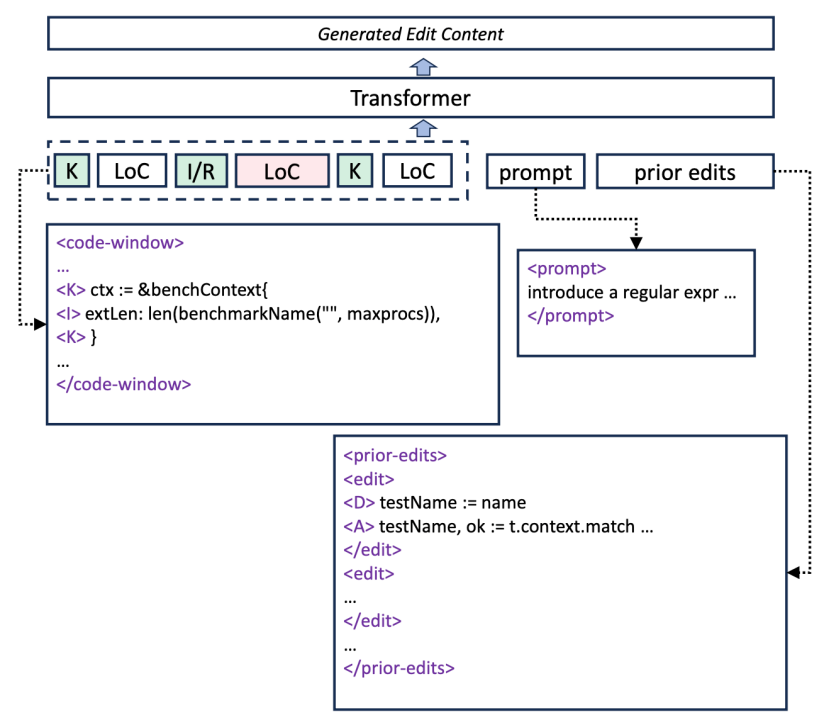
详细来说,代码补全 Pro 整体的流程,涵盖 Subsequent edit analysis、Prior edit analysis、Edit generation 这三大步骤。Subsequent edit analysis 流程要解决的问题是,当用户编辑完代码后,需要预测用户下一个要改的代码是什么。因此首先要通过文件级别的粒度,预测用户下一步需要编辑的文件,然后在具体的某个代码文件中,还需继续预测用户具体需要变更的代码行的位置。接下来 Prior edit analysis 阶段需要分析用户的编辑行为的依赖关系,把更相关的编辑代码告知模型。最后,在 Edit generation 阶段,根据预测的位置、相关的编辑历史的代码。
技术原理论文详情🔎:https://arxiv.org/pdf/2408.01733
Edit-Propagting File Locator
这里主要涉及两个部分,第一是文件依赖的分析,需要模型去理解代码的依赖关系,通过提取代码依赖关系和指令微调,让模型能够理解用户的编辑代码 e 会影响到 f ,接着从语义上分析,编辑 e 和代码文件 f 的相似度如何,通过这两个方法,模型能初步理解出用户下一个究竟想改哪个代码文件。
Edit-Propagting Line Locator
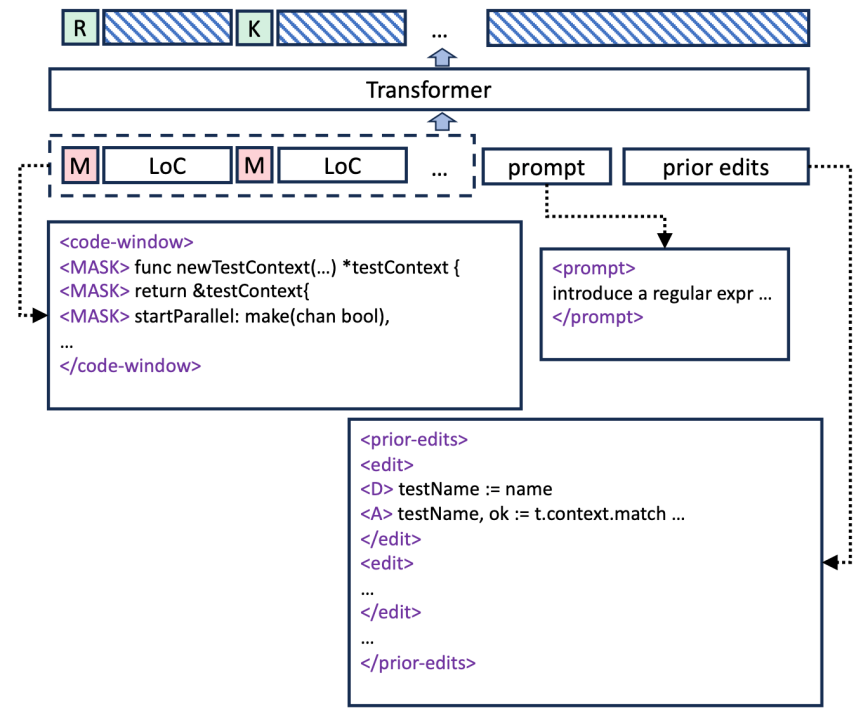
在代码行的编辑预测中,模型需要预测用户下一行的编辑操作是什么,这里在训练数据上,基于 Masked language modelling (MLM) ,给这些数据进行打标,主要包括 keep(某一行代码不应被更改)、Insert(某一行代码需要插入新的代码行)、Replace(某一行应该被删除或更新)
经过这些数据训练后,就有一个模型,它能够预测接下来用户要编辑的位置在哪里。
Prior edit analysis
知道编辑位置后,模型还需要用户的编辑历史,才能理解用户之前如何编辑代码,从而更好地预测出用户下一次要编辑的代码。在这里首先要知道编辑历史对待预测代码的可能性,用户写了较久的代码,可能整个编辑的历史代码很长,而模型的输入有限,因此这里也需要对编辑历史上下文进一步分析,获取更相关的上下文。首先会通过语义相似度,评估编辑历史和目标代码的语义相关性,接着还需要通过相似度算法,评估编辑历史和目标代码的相似度,最后得出相关的编辑历史的序列。
基于 LLM 最终生成编辑操作
有了位置和编辑历史上下文,最后只需将这些上下文提供给模型,模型就能推荐接下来用户需要编辑的代码是什么。这里,在给模型推理前,也需要给模型能够理解的数据格式,通过 Code Window(插入、保留的格式)来构造,Selected Prior edits - 用户代码编辑历史,最后就是用户自己的 Query,通过这三部分,可以构造出完整的模型输入,接下来交给模型生成结果,然后返回到插件并进行显示。
提效实战
好的,听了这么一大段原理介绍,接下来咱们来点实际的,我们可以怎么用豆包MarsCode AI 编程助手来提高效率呢?
编码场景
在编码场景中,这里主要通过代码补全和代码补全 Pro 来举例。在代码补全方面,包括我自己在内的用户都有一些不错的实践场景,比如我会先写好注释,然后让模型帮忙推荐接下来要写的函数;又或者我在开发前端,写 React 组件时,让模型生成 props 。而在代码补全 Pro 方面,举两个场景:当我们期望实现多语言功能,原本只返回了英文,当我们写 locale 时,豆包MarsCode 会把我所有需要更新为多语言的函数都一一进行修改。
学习场景
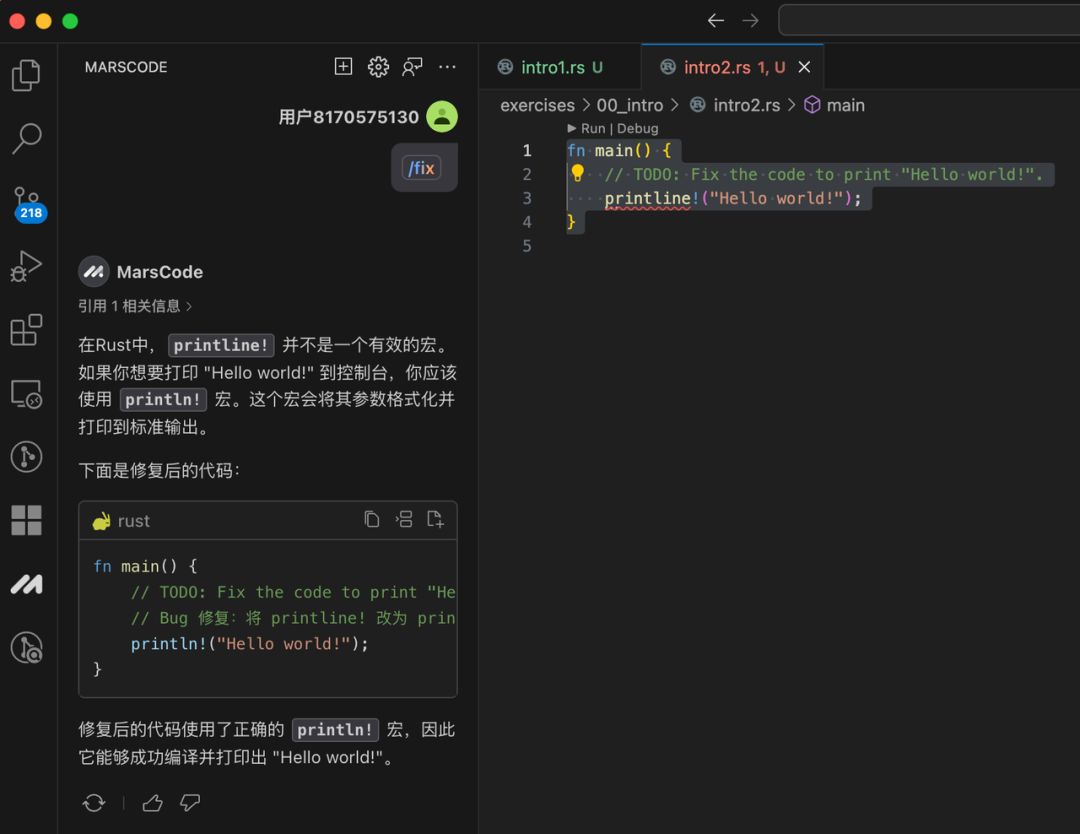
在学习场景中,最近我也在用豆包MarsCode AI 编程助手来学习 Rust ,有了它我能轻松上手。首先我找了一个学习 Rust 的练习题,这些练习题主要是编译报错或者单测不通过的题目。遇到编译报错的练习题,我会先用豆包 MarsCode AI 编程助手的 fix 功能,让它帮我解决错误,解决后,我会看看豆包 MarsCode AI 编程助手的解释。当我遇到一些不熟悉的术语,比如 Rust 的借用,我还会让豆包 MarsCode AI 编程助手进一步解释。
而在单测不通过的题目中,我会使用豆包 MarsCode 的代码补全、代码补全 Pro 来辅助修改,或者通过 /fix 功能,明确告诉豆包 MarsCode 单测跑不过的错误是什么,然后让它帮忙解决。通过豆包 MarsCode ,我三天就上手了 Rust。
思考与展望
在 AI 编程助手领域,其发展可谓是日新月异。就模型而言,指令追随和语义理解能力将会变得更强。比如说,之前我有将中文转换成 unicode 编码的需求,让 GPT3.5 或者 GPT4 来完成时,模型的回答不够精确,常常推荐的是教你如何使用 python 去转换,而我实际需要的是模型能直接为我输出 unicode 编码。但现在去体验目前较为出色的代码模型,它是能够直接转换成 unicode 编码的,也就是说模型越来越听得懂人话了。
而在产品方面,我也留意到了一些趋势。AI 与 IDE 原有的能力深度融合,例如在 Editor 中支持输入自然语言就能生成代码;另外,模型具备更强的代码编辑能力,能够支撑修改更多更长的代码片段,编码的自动化水平也更高。业界也正在探索问答场景下的智能编辑代码和应用能力,只需在输入框向模型提出,帮我优化一下变量名,或者帮我优化一下任意函数,模型就能领会你的意图,并能依据你的意图修改相应的代码以及修改的位置。
总结
最后来总结一下,本次介绍了豆包 MarsCode 的背景和历程,接下来重点展开聊了我们在 AI Coding 的探索,其中着重分享了代码补全和代码补全 Pro 的实现原理是怎样的,最后也畅想了 AI Coding 的未来,包括模型更强的指令追随和代码编辑能力,以及 AI Coding 的交互展望。
豆包 MarsCode 的代码补全 Pro 已处于 beta 阶段,欢迎进入豆包MarsCode 中文官网下载体验。豆包 MarsCode 团队仍在持续探索未来研发的新模式与交互形态,欢迎大家的持续关注。




