
问题来了
笔者近期在工作中遇到这样一个问题:某客户新上线了一个 Elasticsearch 应用,但运行一段时间后就变的特别慢,甚至查询超时。重启后服务恢复,但每隔 3~4 小时后问题重现。
针对这个问题,我身边的同事也帮忙做了简单分析,发现存在大量 Merge 的线程,应该怎么办呢?根据我之前定位问题的经验,一般通过 Thread Dump 日志分析,就能找到问题原因的正确方向,然后再分析该问题不断重复的原因。按着这个思路,问题分析起来应该不算复杂。But,后来剧情还是出现了波折。
困惑的堆栈日志
因网络隔离原因,只能由客户配合获取 Thread Dump 日志。并跟客户强调了获取 Thread Dump 日志的技巧,每个节点每隔几秒获取一次,输出到一个独立的文件中。集群涉及到三个节点,我们暂且将这三个节点称之为 39,158, 211。问题复现后,拿到了第一批 Thread Dump 文件:
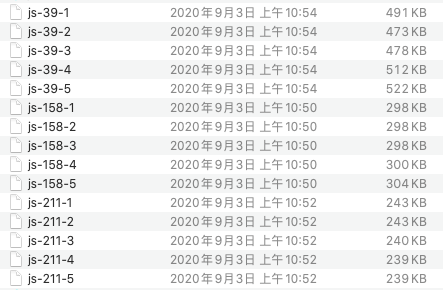
从文件的大小,可轻易看出 39 节点大概率是一个问题节点,它的 Thread Dump 日志明显大出许多:查询变慢或者卡死,通常表现为大量的 Worker Thread 忙碌,也就是说,活跃线程数量显著增多。而在 ES(Elasticsearch,以下简称为 ES)的默认查询行为下,只要有一个节点出现问题,就会让整个查询受牵累。
那么我们先对三个节点任选的 1 个 Thread Dump 文件的线程总体情况进行对比:
再按线程池进行分类统计:
可以发现:39 节点上的 Lucene Merge Thread 明显偏多,而其它两个节点没有任何 Merge 的线程。
再对 39 节点的 Thread Dump 文件进行深入分析,发现的异常点总结如下:
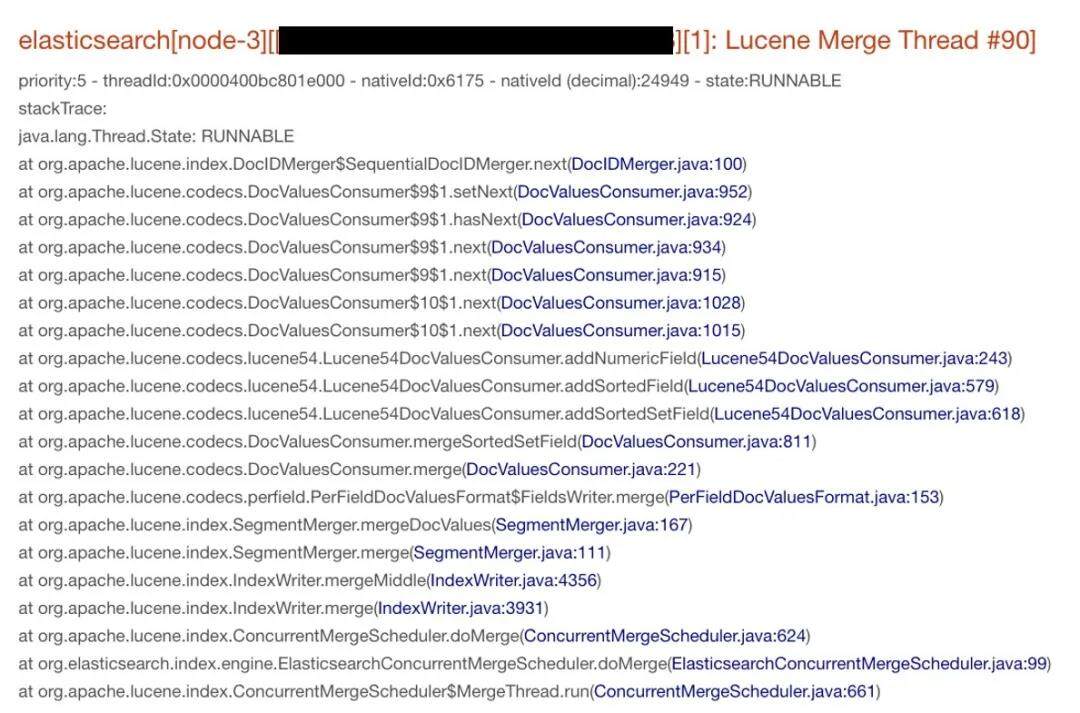
Lucene Merge Thread 达到 77 个,其中一个线程的调用栈如下所示:
有 8 个线程在竞争锁定 ExpiringCache:

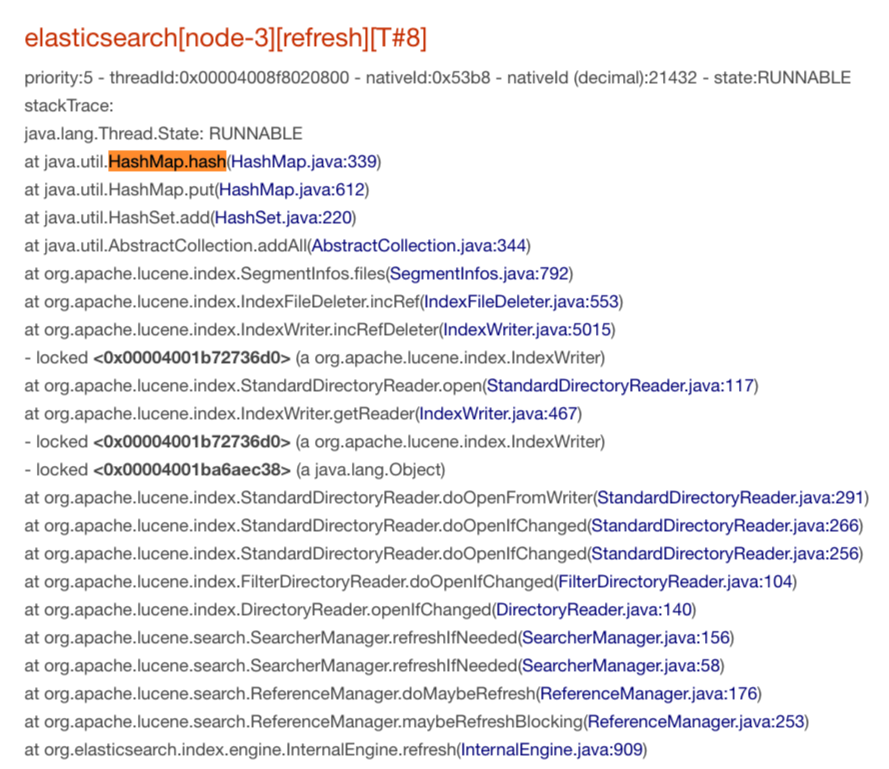
有 8 个线程都在做 HashMap#hash 计算:
现象 1 中提到了有 77 个同时在做 Merge 的线程,但无法确定这些 Merge 任务是同时被触发的,还是因为系统处理过慢逐步堆积成这样的状态。无论如何这像是一条重要线索。再考虑到这是一个新上线的应用,关于环境信息与使用姿势的调研同样重要:
集群共有 3 个节点,目前共有 500+个 Indices。每个节点上写活跃的分片数在 70 个左右。
按租户创建 Index,每个租户每天创建 3 个 Indices。上线初期,写入吞吐量较低。每个索引在每分钟 Flush 成的 Segment 在 KB~数 MB 之间。
我开始怀疑这种特殊的使用方式:集群中存在多个写活跃的索引,但每分钟的写入量都偏小,在 KB 至数 MB 级别。这意味着,Flush 可能都是周期性触发,而不是超过预设阈值后触发。这种写入方式,会导致产生大量的小文件。抽样观察了几个索引中新产生的 Segment 文件,的确每一次生成的文件都非常小。
关于第 2 点现象,我认真阅读了 java.io.UnixFileSystem 的源码:
UnixFileSystem 中需要对一个新文件的路径按照操作系统标准进行标准化。
标准化的结果存放在 ExpiringCache 对象中。
多个线程都在争相调用 ExpiringCache#put 操作,这侧面反映了文件列表的高频变化,这说明系统中存在高频的 Flush 和 Merge 操作。
这加剧了我关于使用姿势的怀疑:"细雨绵绵"式的写入,被动触发 Flush,如果周期相同,意味着同时 Flush,多个 Shard 同时 Merge 的概率变大。
于是,我开始在测试环境中模拟这种使用方式,创建类似的分片数量,控制写入频率。计划让测试程序至少运行一天的时间,观察是否可以复现此问题。在程序运行的同时,我继续调查 Thread Dump 日志。
第 3 点现象中,仅仅是做一次 hash 计算,却表现出特别慢的样子。如果将这三点现象综合起来,可以发现所有的调用点都在做 CPU 计算。按理说,CPU 应该特别的忙碌。
等问题在现场复现的时候,客户协助获取了 CPU 使用率与负载信息,结果显示 CPU 资源非常闲。在这之前,同事也调研过 IO 资源,也是非常闲的。这排除了系统资源方面的影响。此时也发现,每一次复现的节点是随机的,与机器无关。
一天过去后,在本地测试环境中,问题没能复现出来。尽管使用姿势不优雅,但却不像是问题的症结所在。
诡异的 STW 中断
通过 jstack 命令获取 Thread Dump 日志时,需要让 JVM 进程进入 Safepoint,相当于整个进程先被挂起。获取到的 Thread Dump 日志,也恰恰是进程挂起时每个线程的瞬间状态。
所有忙碌的线程都刚好在做 CPU 计算,但 CPU 并不忙碌。这提示需要进一步调查 GC 日志。
现场应用并未开启 GC 日志。考虑到问题当前尚未复现,通过 jstat 工具来查看 GC 次数与 GC 统计时间的意义不太大。让现场人员在 jvm.options 中手动添加了如下参数来开启 GC 日志:
8:-XX:+PrintGCDetails8:-XX:+PrintGCDateStamps8:-XX:+PrintTenuringDistribution8:-XX:+PrintGCApplicationStoppedTime8:-Xloggc:logs/gc.log8:-XX:+UseGCLogFileRotation8:-XX:NumberOfGCLogFiles=328:-XX:GCLogFileSize=32m添加 PrintGCApplicationStoppedTime 是为了将每一次 JVM 进程发生的 STW(Stop-The-World)中断记录在 GC 日志中。通常,此类 STW 中断都是因 GC 引起,也可能与偏向锁有关。
刚刚重启,现场人员把 GC 日志 tail 的结果发了过来,这是为了确认配置已生效。诡异的是,刚刚重启的进程居然在不停的打印 STW 日志:
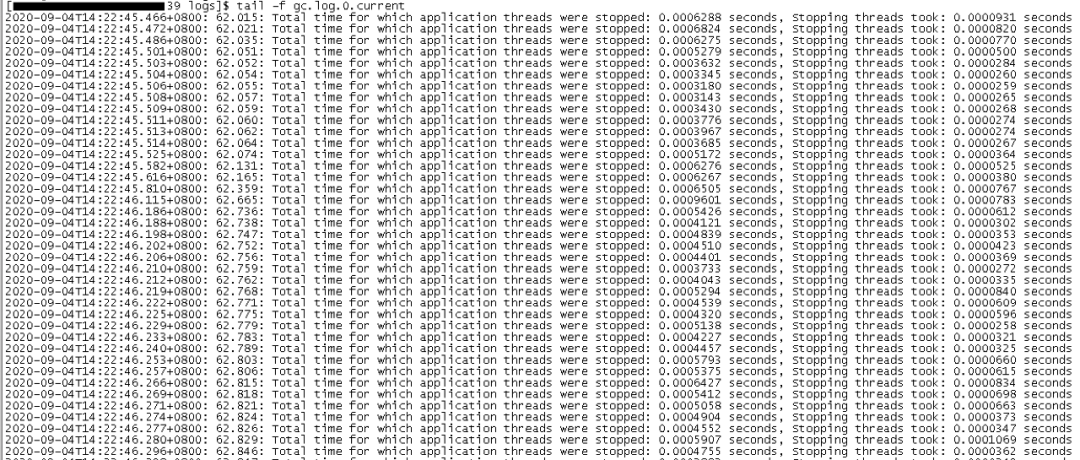
关于 STW 日志(”…Total time for which application threads were stopped…”),这里有必要简单解释一下:
JVM 有时需要执行一些全局操作,典型如 GC、偏向锁回收,此时需要暂停所有正在运行的 Thread,这需要依赖于 JVM 的 Safepoint 机制,Safepoint 就好比一条大马路上设置的红灯。JVM 每一次进入 STW(Stop-The-World)阶段,都会打印这样的一行日志:
2020-09-10T13:59:43.210+0800: 73032.559: Total time for which application threads were stopped: 0.0002853 seconds, Stopping threads took: 0.0000217 seconds在这行日志中,提示了 STW 阶段持续的时间为 0.0002853 秒,而叫停所有的线程(Stopping threads)花费了 0.0000217 秒,前者包含了后者。通常,Stopping threads 的时间占比极小,如果过长的话可能与代码实现细节有关,这里不过多展开。
回到问题,一开始就打印大量的 STW 日志,容易想到与偏向锁回收有关。直到问题再次复现时,拿到了 3 个节点的完整的 GC 日志,发现无论是 YGC 还是 FGC,触发的频次都很低,这排除了 GC 方面的影响。
出现的大量 STW 日志,使我意识到该现象极不合理。有同学提出怀疑,每一次中断时间很短啊?写了一个简单的工具,对每一分钟的 STW 中断频次、中断总时间做了统计:
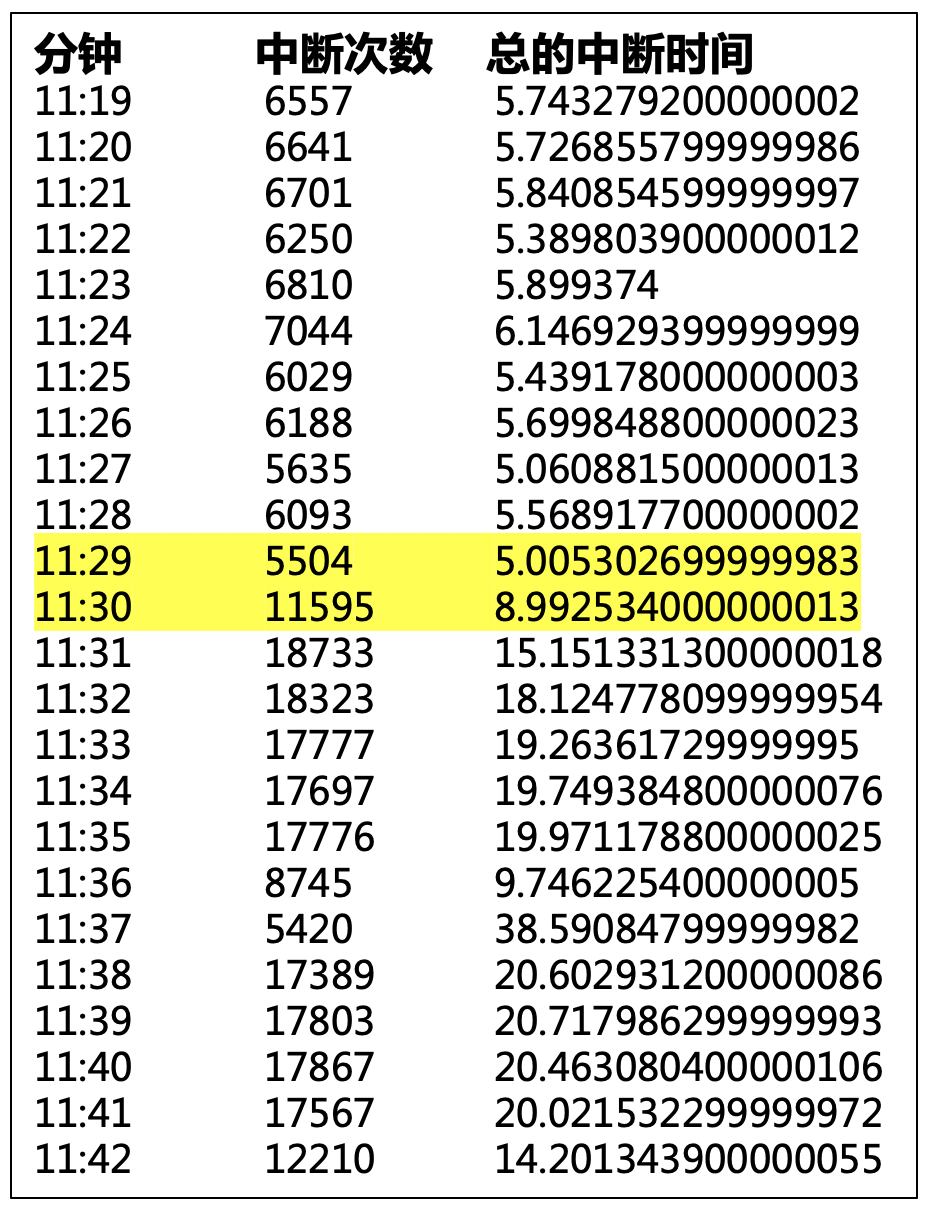
统计结果显示:
正常每分钟都有 5 秒左右的中断。
在 11:29~11:30 之间,中断频次陡增,这恰恰是问题现象开始出现的时间段。每分钟的中断总时间甚至高达 20~30 秒。
这就好比,一段 1 公里的马路上,正常是遇不见任何红绿灯的,现在突然增加了几十个红绿灯,实在是让人崩溃。这些中断很好的解释了“所有的线程都在做 CPU 计算,然而 CPU 资源很闲”的现象。
关于 Safepoint 的调查
Safepoint 有多种类型,为了确认 Safepoint 的具体类型,继续让现场同学协助,在 jvm.options 中添加如下参数,打开 JVM 日志:
-XX:+PrintSafepointStatistics-XX:PrintSafepointStatisticsCount=10-XX:+UnlockDiagnosticVMOptions-XX:-DisplayVMOutput-XX:+LogVMOutput-XX:LogFile=<vm_log_path>等待问题再次复现的过程中,我基于 ES 运行日志中统计了每一分钟的读写请求频次:

读写请求次数是相对平稳的,这排除了用户请求陡增方面的原因。
拿到 JVM 日志时,看到大量的 Safepoint 类型为 ForceSafepoint:
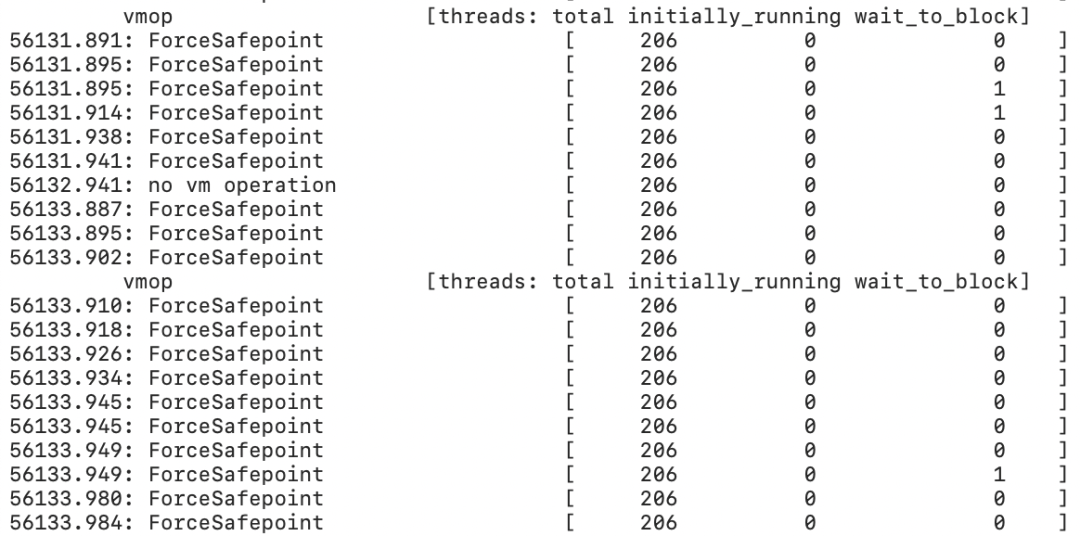
而偏向锁回收相关的 Safepoint 却应该是长这样的:

这让我疑惑了。开始在网上搜索 ForceSafepoint 的触发原因,结果,一无所获。
查看 hotspot 的源码,发现至少有 5 种相关场景:
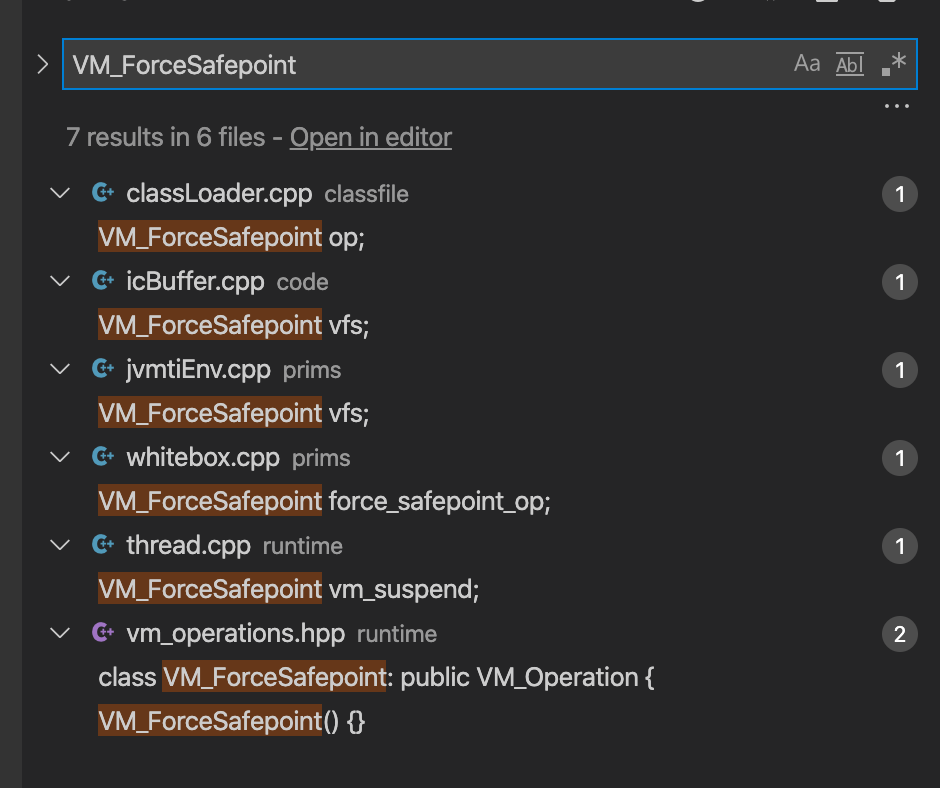
可见,ForceSafepoint 是一个“杂烩”,就像统计图中的“Others”一项。从这里开始,我将 JDK 加入到了“重点嫌疑人”清单中。
继续分析 JVM 日志。在每一条 Safepoint 日志中,同时记录了当时的线程总数(threads: total 一列):

回顾一下,出现问题时,三个节点的线程总数有明显出入,问题发生后,线程总数是增多的,尤其是 Lucene Merge Threads。
“多个 Lucene Merge 任务”与“陡增的 ForceSafepoint/STW 中断”,哪个是“因”哪个是“果”?
依据 JVM 日志中统计了每一分钟的 ForceSafepoint 次数,以及线程总数的变化。将两条曲线叠加在一起,得到下图:
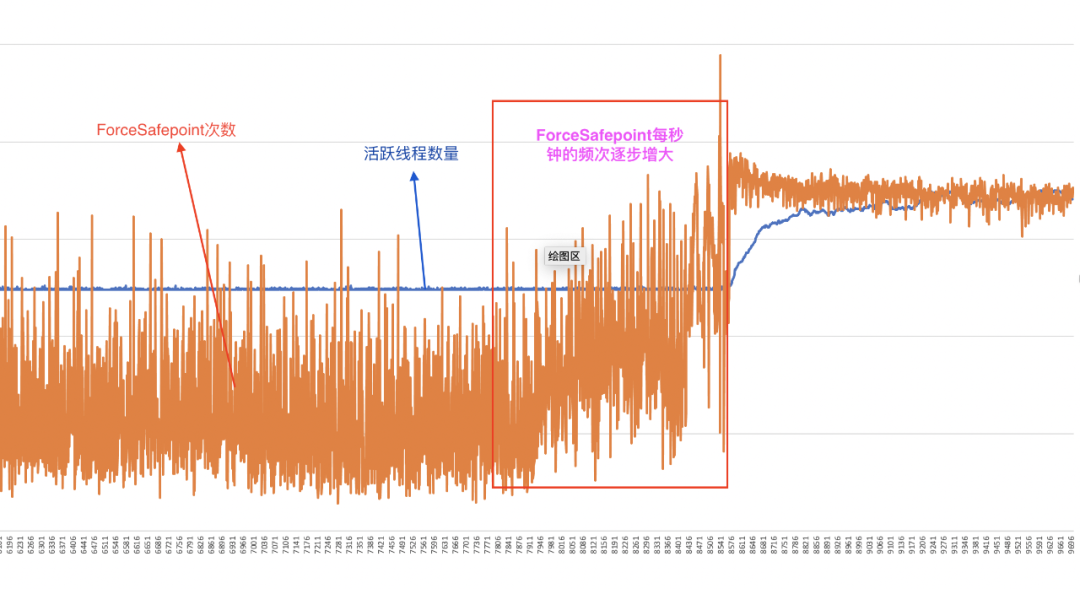
从图中来看,似乎是 ForceSafepoint 逐步增多在先,后面的线程才逐步增多。也就是说,STW 中断变多在先,然后多个 Merge 任务线程才开始逐步积累,就好比,一条目录上突然增设了多个红绿灯,然后这条目录逐步变得拥堵。
此时,开始请教 Kona JDK 团队的同学,我把 GC 日志以及 thread dump 日志分享给了他,并把我目前为止的发现都告诉了他,最大的怀疑点就是这些不正常的 ForceSafepoints,我需要了解 ForceSafepoints 的原因。
过了一段时间后,他回复我:这个是 arm 版本的 jdk。因缺乏 arm 编译机应急柜,暂时没法给我提供一个 debug 版本的 arm jdk。
突然明白,我犯了"先入为主"的错误,尽管一开始就意识到需要对环境进行调查。
难怪在本地 X86 环境中始终无法复现。难怪网上搜索 ForceSafepoint 时一无所获。
接下来和客户电话会议沟通时,获知:
类似的业务,在另外一套 X86 环境中,没有发现此类问题。
在这套 arm 环境中,还有另外一个 Elasticsearch 集群,请求量更低,但没有发现此类问题。
环境中使用的 arm jdk 是从网上下载的,背后支持的厂商未知。
关于第 2 点提到的这套环境中的另外一个 Elasticsearch 集群,我更关心的是它的 GC 日志中是否存在类似的现象。至于没有发生此类问题,容易理解,因为这类问题往往是业务负载特点与环境多重因素叠加下的系统性问题。现场同学配合打开了这个 Elasticsearch 集群的 GC 与 JVM 日志,现象同在,只是 ForceSafepoint 的频次低于出问题的集群。
至此,问题原因清晰的指向了 arm 环境与 JDK 版本。
后来,微服务平台 TSF 团队的臧琳同学介入,他提供了一个添加了 debug 信息的 Kona JDK 版本,尽管这个版本比正常版本慢了许多,更换以后,我们发现问题重现的周期明显变长。
拿到最新的 JVM 日志后,臧琳同学分析这些 ForceSafepoint 都与 Inline Cache Buffer 有关。当然,这可能是 arm 环境下所有 JDK 版本的共性问题,也可能仅仅是之前下载的 JDK 版本存在问题。
接下来,我们将环境中的 JDK 版本替换成正式 Release 的 Kona JDK。再后来,问题始终没有复现。也就是说,替换成 Kona JDK 后,问题解决了。
我统计了一下使用 KonaJ DK 后的 STW 中断次数与中断时间,发现有数量级的提升:
原 JDK 版本:每分钟 STW 中断 5000 次~18000 次,每分钟中断总数据可能达到 10 秒~30 秒。
Kona JDK: 每分钟 STW 中断在个位数,每分钟中断总时间在 100~200ms 之间。
可见,Kona JDK 比原来的问题 JDK 版本在性能上有了数量级的提升。
总结回顾
我们再来梳理一下整个问题的分析思路:
1. 通过堆栈分析,发现大量的线程都在做 CPU 计算,但 CPU 资源较闲。关于大量 Merge Threads 的现象带有一定的迷惑性,但它是问题的“果”而非“因”。
2. 通过 GC 日志分析,发现 GC 频次与 GC 时间都很低,但 GC 日志中存在大量的 STW 相关日志,需要确认关联的 Safepoint 类型。
3. 通过 VM/Safepoint 日志分析,确认了 Safepoint 的类型为 ForceSafepoint。通过不同环境与不同集群的现象对比,开始怀疑 JDK 版本存在问题。
4. 更换 Kona JDK 后,ForceSafepoints 频次由每分钟 5000 多次降低到个位数,问题解决。
通过本次问题的分析,得到一个教训:问题分析初期应该认真调研集群环境。当然,最大的教训是:千万不要乱下载 JDK 啊!
头图:Unsplash
作者:毕杰山
原文:不要再乱下载JDK了:Elasticsearch在国产化ARM环境下的首个大坑
来源:腾讯云中间件 - 微信公众号 [ID:gh_6ea1bac2dd5fd]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




