
感知准确是无人车算法的基础
感知在自动驾驶中是一个比较直观的模块,即根据传感器(如激光雷达、相机、毫米波雷达)信息对周围的物体进行理解和抽象,输出所有交通参与者的位置、速度、大小等属性,下游模块(预测、规划)根据这些抽象信息进行运算和决策;感知如果遗漏了物体,对自车来说是“视而不见”的状态,会造成严重的安全风险。因此,感知信息的准确度是无人车算法的重要基础。
进化的感知发展路径
自动驾驶的最低要求是能识别到面前的物体,不撞上它。这个要求通过激光雷达就可以实现,因为它可以准确地估计物体的 3D 位置,并刻画其轮廓。但真实世界并非都是静态障碍物,比如在跟车的场景下,前车的速度是我们考量是否需要减速或刹车的重要因素。同时,面对一个在向自车靠近的行人,和一个静止的行人,自车对他的反应是截然不同的。
▍1. 第一阶段:基于规则的点云分割算法和物体追踪
在第一阶段,除了需要识别静态障碍物,我们也需要识别常见交通参与者(车、行人、自行车)的类别、朝向和速度,以帮助自车做出决策。在深度学习出现之前,其实通过基于规则的点云分割 / 分类算法¹,再加上物体追踪,就可以做出一个基础的版本。在这一阶段,针对处理不好的问题需要专家设计规则和专门的算法进行处理,然而,许多情景我们难以设计规则处理。
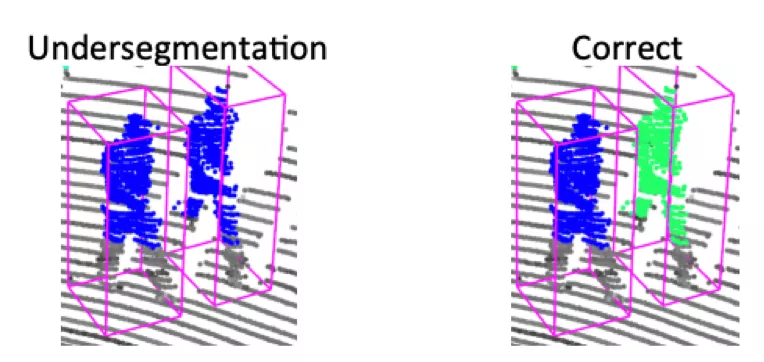
对于并行走的行人
很难设计人工规则把两者分开²
▍2. 第二阶段:大规模数据标记和深度学习
深度学习的出现和发展大幅度提高了感知的效果。面对规则难以处理的感知任务,我们可以运用大规模数据标记及训练深度学习模型。我们不再依赖专家针对问题设计算法,而是从大量数据中萃取出经验和知识。在这一阶段,感知算法的设计更加数据驱动。感知通过收集更多的数据,设计更好的模型进行迭代。但深度学习准确率也有上限,且泛化性(在非典型样本上的表现)、可解释性都存在问题。因此在自动驾驶这个场景中,深度学习并不是感知唯一的组件。
▍3. 第三阶段:可扩展性和自学习性的长尾数据处理系统
第三阶段,需要做更细粒度的识别,以及解决更多长尾问题,如各种奇怪的大车、地上的塑料袋、行人更细粒度的意图(如是否在打电话)等。这一阶段要求系统有更强的可扩展性、自学习性。长尾问题绝对量占比小,但并不容易解决。其难度可以用九九定律³来刻画:剩余 10% 的问题,还需要额外 90% 的时间才能解决。理想情况下,长尾问题应该有自动的流程进入到模型框架中自动进行学习,而不是简单地靠堆人力来改善这些问题,甚至人过多会使进展变慢⁴。现在学术界在研究的 multi-task learning⁵, AutoML⁶等技术对这一阶段的感知发展有极大的启发。但因为数据的价值边际效用递减,及下文会提到的深度学习的限制,目前业界也还在探索状态,没有特别成熟的思路能达到仅靠数据流就能使系统不断进化的状态。

长尾问题:识别到椎桶在卡车上,无需刹车
实现完全无人驾驶对感知存在多重挑战
▍1. 深度学习模型存在缺陷
深度学习模型虽然效果显著,但最先进的模型的效果也无法达到无人车感知的要求,且深度学习算法缺乏泛化性和可解释性。许多研究已经证明了深度学习远不如人类智能通用,如通过加人类无感知的噪声,就可以误导模型对结果的分类;对于罕见的数据(如一个穿着很奇怪衣服的人),深度学习也容易犯错误。简单来说,深度学习模型只是以一种生硬的方式在“记忆”训练数据⁷。而且其记忆能力有限,在模型学习达到饱和后,学习新的样本可能造成已有能力产生退化⁸。如何结合深度学习模型和基于规则的白盒算法,同时保障感知的召回率和效果,是感知系统面临的一大挑战。综合考量以上缺陷,我们不能仅依赖深度学习模型。
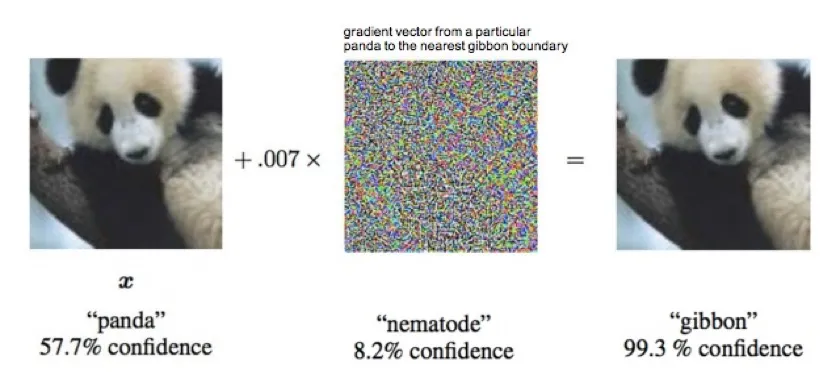
通过添加人眼无法辨别的噪声
深度学习模型就可以被误导⁹
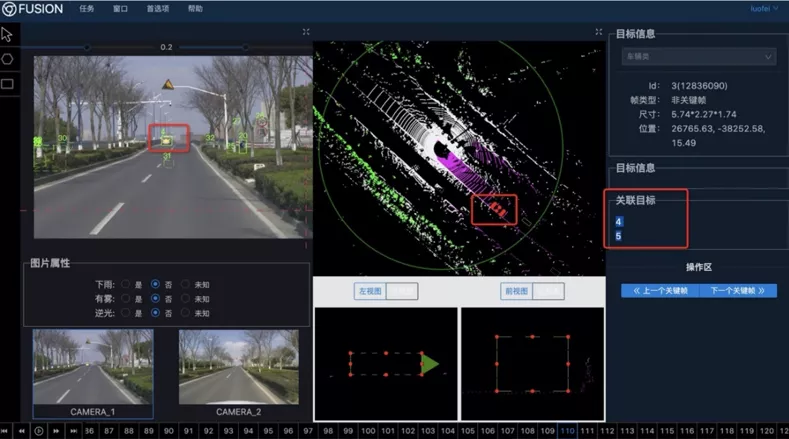
感知自建的数据标注系统
▍2. 多传感器需要进行扬长避短的融合
传感器是感知能力的上限,不同的传感器有不同的优缺点。激光雷达能对物体轮廓进行较准确的刻画,同时能准确地得到物体的 3D 位置信息,但缺乏相机所能得到的丰富色彩信息,同时对雨雪天气较敏感;相机对 3D 位置的估计稍差;而毫米波雷达精度一般,但感知距离远,且能直接得到物体纵向的速度。下图更全面地反映了这些优缺点。感知系统需要针对不同的任务,扬长避短地使用多种传感器信息。同时,多传感器的融合也对标定的精度、可扩展性提出了较高要求。
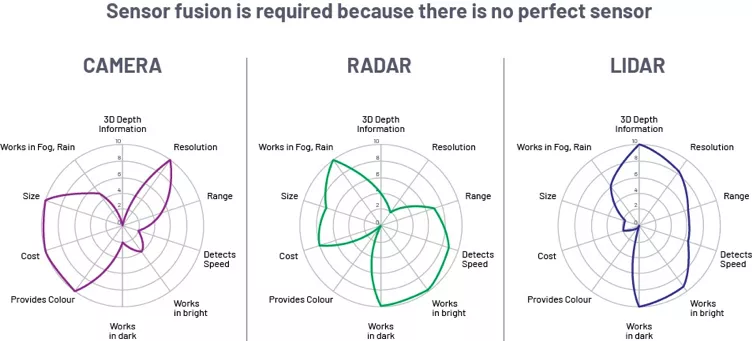
不同传感器的优劣势对比¹⁰
▍3. 低延迟要求和有限算力间的矛盾
无人车是一个实时计算系统,无法像 Web 后端系统一样通过增加服务器来进行算力拓展。同时车载系统对能耗、散热也有约束,这间接约束了感知能使用的算力。在有限算力下部署复杂模型,感知输出延迟较大,会造成安全隐患及各种问题。我们需要通过模型压缩、神经结构搜索、代码优化的方式更巧妙地利用有限的算力资源,达成最佳的效果。
▍4. 难以准确表征和处理不确定性
感知的输出是带有不确定性的¹¹,一个近处物体,在无遮挡的情况下,我们对其估计较为确定;而一个远处物体,激光雷达打上的点少,我们对它的类别、位置的不确定性都较大。一般来说,我们需要输出一个最置信的类别和位置信息,但此时该信息的不确定性是极大的,而感知内部或下游往往会直接忽略这种不确定性。如何更好地融合不确定性信息,需要感知内部和下游模块从底层进行更好的思考。

不确定性:例如在遮挡严重的情况下
我们对物体的类别、位置、速度等信息变得不确定
充满挑战的进阶之路
在外界看来,无人车感知似乎是一个较容易的问题,使用先进的深度学习模型就可以解决得不错。但无人车对安全性有极高的要求,同时路测出现的场景千奇百怪,这对感知的挑战是巨大的。无人车感知是一个需要综合算法、工程、数据的系统工程。算法方面,我们需要针对问题,组合、定制已有算法,同时紧跟学术界/业界进展,引入新思路。工程方面,我们需要让系统能够吞吐更大量的数据;同时不断完善系统,减少工程师在解决问题需要投入的时间。数据方面,我们需要利用路测数据积累对长尾数据的认知和评估,同时形成模型-路测-数据标注闭环,增加数据的量级和利用率。在这一方面,我们复用了滴滴已有的成熟基础架构进行二次开发,因此可以较快建立感知的体系。
一个更高层次的要求是自学习性。如果系统有更好的自学习性,仅需一些数据标注和自动学习,系统就可以适应一个新的环境。当前,我们的感知系统部署到一个环境变化的新城市,还需要投入一些人力进行重新开发和调整。这是一个需要努力的方向,完善的数据和算法架构是重要的基础。
目前为止,无人车感知虽然已经取得了极大进展,但遗留的难题还很多。以上只是一些宏观层面的思考,但细节决定成败,每个难题的攻克需要二三素心人的潜心钻研。期待无人车的未来进阶之路上早日迎来技术的跃迁。
头图:Unsplash
作者:滴滴自动驾驶
原文:https://mp.weixin.qq.com/s/ZvW1HZo8Qg39jYiCU-8IdA
原文:自动驾驶在挑战中进化的感知能力
来源:滴滴技术 - 微信公众号 [ID:didi_tech]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




