数据迁移是指在系统软件开发中,将具有实际业务价值的数据,依据功能需求或系统开发的要求,在不同存储媒介、存储形式或计算机系统之间转移的过程。
数据迁移是系统开发经常涉及到的一项工作。在企业级应用系统中,新系统的开发,新旧系统的升级换代,以及正常的系统维护,不可避免地涉及到大量的迁移工 作。而在一个以数据为核心的业务系统中,数据的迁移更是无处不在。比如:在以数据仓库为架构原型的系统设计中,ETL(抽取,转换,装载)部分的实现就是 一种数据迁移;对大型数据系统的分布式实施,数据迁移就是整个实施过程的主要部分。而在敏捷实践中,渐进式的数据库开发,更是涉及到大量的数据迁移和同步 工作。
我们时常会听到用户提出这样的要求“我们并不过于关心应用的好坏,但需务必保证数据准确”。的确,在以数据为运营基础的行业里,数据质量本身就是软件质量 的权重部分,尤其在电信、金融和控制领域里,这一特征表现的格外明显。数据迁移也是敏捷开发中相当重要的环节,它影响着各个发布版本的数据质量,而数据质 量又决定着系统的有效性和可靠性,因此高质量地完成数据迁移不容忽视。
数据迁移往往被视为一件很简单的工作。在很多人眼里,数据迁移仅仅是用 sql 语句向相应数据表装载数据的过程。但在实际操作中,数据迁移涉及到很多层面的 因素,如用户需求,系统功能,数据库建模等,若出现问题,将导致开发进展缓慢或质量不高。常见问题有业务系统逻辑模糊、脏数据、遗留系统的技术债和管理债 等。那么如何有效的避免这些问题,提高迁移质量呢?
本文将以 ThoughtWorks 中国公司与客户合作的 CRM 项目为背景,为读者介绍如何在敏捷开发中高质量地处理数据迁移工作,从而在数据层面提高系统质量。
开发背景
A 系统(旧系统)是客户原有的一套 CRM(客户关系管理)系统。系统采用 B/S 架构,使用 sql server 2005 做为后台数据库。旧系统的数据建模设计采用了高度范式化的设计思路,其目的是极度追求灵活性。业务数据被大量拆分并散布存储在上百张数据表里。数 据表内和表之间不存在参照约束。大量的业务逻辑采用存储过程封装以提高效率。存储过程体系相当庞大,且存在复杂的相互调用。数据库中存在一些脏数据,可能 是长期的使用、维护或误操作导致,但没人知道它们有多少,具体存在哪里。应用界面可用性不理想而且系统效率较低,用户常抱怨系统反映迟缓或无反应。数据库 存储的业务数据约 50G 左右。
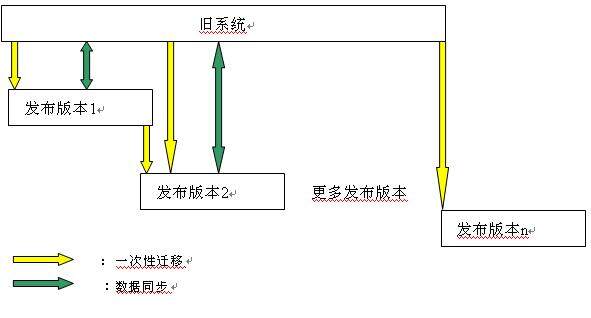
ThoughtWorks 团队将为客户提供一套新的 CRM 系统用以替换旧系统主要功能。新系统精简整理旧系统功能,并整合了客户的最新需求。在设计上做了巨大变更,以改善界面可用 性,同时为了保障终端用户对系统服务的需要,新旧系统要求能够同时运行并实现数据同步,当终端用户全部过度到新系统后,终止旧系统。在这个过程中,DBA 团队需给予足够的数据保障。
以下为项目版本的发布图。
数据迁移开发方法
1. DBA 需要制定目标并且管理自己的任务
尽管在每个迭代中,团队都会讨论决定如何组织‘需求故事’(story),但是 DBA 仍然需要有自己的‘故事墙’(story wall),并且花时间组织自己的 story。在实际开发中,数据迁移仅仅是 DBA 工作的一部分,DBA 还要完成相应的 story 开发和数据分析,有时还 要给开发人员提供数据支持。混乱的管理会带来开发上的冲突。因此,有效管理任务是做好数据迁移的首要环节。
故事墙是管理这些任务的最好方法。尽管这个故事墙对客户提供的商业价值是间接的,但从整个团队角度来看,任何需要数据的人或程序都是 DBA 的用户, 故事墙有利于管理每个 story 包含的数据需求,避免数据迁移任务与其它数据库开发任务之间的冲突,从而减少重复性工作或修复性工作。DBA 有必要将这种 方法引入到数据库开发中。
DBA 要从商业价值角度决策数据迁移的需求。系统开发中,客户和开发员常常会向 DBA 提出自己的数据迁移要求,但往往这些要求并不具有全局性和决定性,毕 竟他们仅仅是针对一个 story 的需要而提出。如果 DBA 盲目执行,将起到事倍功半的效果。DBA 应当积极参加 IPM(迭代计划会议。它是在每个迭代开始 时的会议,全体成员共同讨论 story 计划完成数量)。无论是直接与用户交互,还是参与团队合作,DBA 有必要将每个 story 内容了解的清清楚楚。通 常,DBA 可以不必像开发人员一样去了解 story 的开发细节,但通过与业务分析师和开发员的沟通,潜在的数据需求自然浮出水面。针对这些数据需求,通过 再次组织并加以优先级,我们很容易回答这些问题:接下来应该完成的任务是什么?它的实际商业价值是什么?谁将需要它?什么时候需要?实践证明,多花些时间 和团队或客户沟通是事半功倍的好方法,而且 DBA 通过了解业务数据可以给开发员更好的指导,减少开发员对数据的误解,有利于提高整体团队的开发效率。
通过对每个 story 的了解,我们总结并制定了针对当前发布版本需要的 7 个数据迁移 story,并且确认了它们的确不存在任务上的重复,也邀请项目经理和客户一起确认了这份计划。如此我们的目标已经制定。
2. 思考实施策略
我们已经管理好所有数据迁移的任务,接下来考虑如何实现。通过以往的经验,我们发现如果没有仔细思考全局和细节问题而直接编写代码,带来的后果是无 法控制的。我们应该首先充分了解这个过程可能存在的风险,然后决定采用什么样的策略,是否可以借助工具提高效率。这里的潜在风险主要包括:
2.1 数据质量
旧系统的数据库建模是一个高度范式化的结构,每个表之间存在相当大的依赖关系。一旦一个表存在脏数据,我们如何保证得到正确的查询结果?
2.2 对原有系统的了解
旧系统的应用程序引入了面向对象的设计方法,并且继承关系数据也被存储在若干张数据表里,如何正确区分这些业务对象和关系,保证在迁移过程中不会制造脏数据?
2.3 业务数据映射
旧系统和新系统之间存在着相当大的业务逻辑差异,我们是否能够将业务逻辑、数据映射到新系统?是否存在不可实现的转换?
在未充分了解这些问题之前,我们无法进一步制定计划,即时给予客户反馈是解决这些问题的最好方法。经过进一步沟通后,我们发现问题的复杂程度远远超过想象,尽管客户对旧系统非常了解,但他们对于某些数据也不能给出明确答案。鉴于这些情况,我们制定了初步的解决策略:
- 更多的了解旧系统,即时给予反馈。对于那些无法找到答案的问题,考虑是否可以寻求其它资源或忽略没有价值的数据。
- 尽量细化分割每一个复杂需求,形成多个任务。小粒度任务能够帮助暴露更多问题。
- 采用测试驱动,确保一套可靠的测试机制。
- 制定实现框架和阶段性目标。
- 不要过于乐观的估计进展,每一阶段要留有充分的单元测试。
- 调整每个迭代的内容,对有较强依赖关系的任务可以放在今后的迭代周期里。
3. 实施数据迁移
新系统的数据迁移包含两个部分:一次性数据迁移和数据同步迁移
一次性数据迁移
一次性数据迁移指仅仅发生在某一个发布版本上线安装时,新旧系统同时处于脱机状态,一部分数据将从旧系统中转移到新系统的过程。
数据同步迁移
数据同步迁移过程发生在新系统运行时,新旧系统同时处于工作状态,双方通过交换数据保证彼此数据的一致性。
同为数据迁移,但因两类迁移各具特点,因此在共同的处理方式上也略有不同。
一次性数据迁移
数据同步迁移
特点
-
数据量大。
-
使用频率低(一次性使用)。
-
转换逻辑复杂,需大量定制映射转换数据。
-
数据量小
-
使用频率高(以分钟为单位,周期性运行)。
-
转换逻辑复杂,少量定制映射转换数据。
-
需要事务处理以保证数据一致性
共同处理方式
- 细化任务。
- 测试驱动。
- 持续集成
不同处理方式
-
在执行测试驱动中,应侧重数据质量的测试。应依据不同环境的测试结果,增强测试体系。
-
工具选择。避免使用第三方工具,直接使用 sql 脚本以提高迁移效率。
-
保留中间处理结果
-
在执行测试驱动中,应侧重逻辑映射方面的测试。
-
工具选择。可考虑使用第三方工具,增强事务控制。
-
可不保留中间结果
-
细化任务
依据最初制定的开发策略,当我们遇到复杂的迁移需求时,首先分解每个需求为若干个模块,然后画出整体结构图。以下是某一处数据迁移脚本的模块分割:
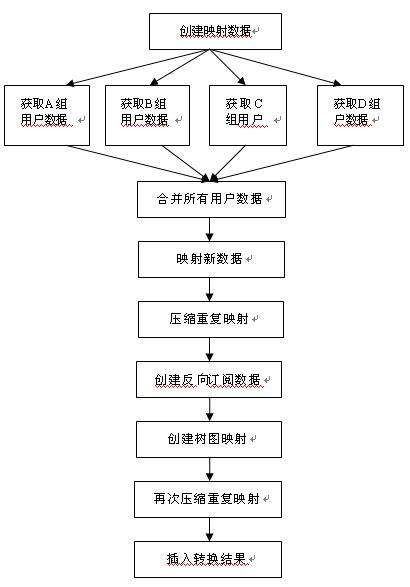
最初由于这个部分的迁移逻辑过于复杂,以至于客户对它的处理结果没有信心。但当共同完成这个图表后,大家一致认为它没有像想象中的困难。总而言之,立刻解决一个复杂的问题很困难,但解决其中一个小问题却很容易。
- 测试驱动
如同编写程序代码一样,我们不仅为实现数据迁移脚本使用了测试驱动,还引入了针对数据库设 计的一些方法。在程序设计中,当代码本身结构良好,单元(类、方法)之间关系清晰,可以直接添加单元测试。现在,我们有了很好的脚本逻辑结构,可以很容易 添加每一步结果的单元测试,这就如同形成了一道安全网,保证异常数据出现时,能够立即发现并加以处理。在实际编写迁移脚本之前,应首先明确测试内容,准备 好测试脚本。
测试内容包括:
- 应产生的符合期望的数据
基于给予的原始测试数据,这一测试过程测试脚本的数据转换逻辑是否正确。以下举例说明:
测试环境:旧系统中存在某个名为’Jason’的客户信息,他的 personId 是 1000101 。
测试目的:当某一客户的信息迁移到新系统的 CUSTOMERS 表后,新系统应该存在该客户信息。
新系统上要运行的测试代码:
<p>DECLARE @personName NVARCHAR(250),</p><p>SELECT</p><p>@personName = personName</p><p>FROM</p><p>CUSTOMERS</p><p>WHERE</p><p>personId = 1000101</p>
<p>IF (@personName <> 'Jason') or (@personName is NULL)</p><p>BEGIN</p><p>INSERT INTO LoadTestErrorLog (errorDescription)</p><p>VALUES ('personName for personId 1000101 is not Jason')</p><p>END</p><p>Go</p>
这里常用的原则是:一段 sql 语句仅用来测试一处期望数据,这样可以减少代码之间的相互依赖性,更准确的定位错误数据。
- 不应当产生的异常数据
异常数据指在迁移过程中出现的不符合逻辑的数据。理论上讲,迁移过程不应当出现异常数据,然而现实情况中,迁移结果总会出现我们不需要的数据。其原因包括 数据源出现异常、实现过程中的误操作、系统应用的 bug 等。总而言之,为了保证这些错误不会出现在最终结果,相应的测试脚本必不可少,也是防止问题进一步 扩大的有效举措。这一测试过程常被用来发现在生产环境中可能出现的问题。以下举例如何测试异常数据:
测试环境:全部或部分生产环境数据
测试目的:将某个客户的信息迁移到新系统的 CUSTOMERS 表后,数据表不应该具有顾客名字为空的记录,如果出现将视为迁移过程的错误。
新系统上要运行的测试代码:
<p>DECLARE @isExistPersonNameWithNULL INTEGER</p><p>SELECT</p><p>@isExistPersonNameWithNULL = count(*)</p><p>FROM</p><p>CUSTOMERS</p><p>where personName is null</p><p>IF (@isExistPersonNameWithNULL> 0)</p><p>BEGIN</p><p>INSERT INTO LoadTestErrorLog (errorDescription)</p><p>VALUES ('personName doesn't contain legal information')</p><p>END</p><p>Go</p>- 数据表的数据量是否符合期望
当数据被迁移至新系统后,应当确保迁移数据量符合应期望值。实现方法多种多样,较简单的方法是直接比较数据迁移前后的数据记录数是否在数值上相等。以下举例说明:
测试环境:全部或部分生产环境数据。
测试目的:客户数据被迁移后,应当确保客户数据没有丢失。
新系统上要运行的测试代码:
<p>DECLARE @NumberofCustomerinOldDB INTEGER</p><p>DECLARE @NumberofCustomerinNewDB INTEGER</p><p>SELECT</p><p>@NumberofCustomerinOldDB = count(*)</p><p>FROM</p><p>oldDB.dbo.persons -- 这是在旧系统中定义的客户表 </p><p>...</p>–省略复杂的过滤逻辑
<p>SELECT</p><p>@NumberofCustomerinNewDB = count(*)</p><p>FROM</p><p>newdb.dbo.CUSTOMERS -- 这是在新系统中定义的客户表 </p><p>where personName is null </p>
<p>IF (@NumberofCustomerinOldDB<>@NumberofCustomerinNewDB )</p><p>BEGIN</p><p>INSERT INTO LoadTestErrorLog (errorDescription)</p><p>VALUES ('not all customers are migrated ')</p><p>END</p><p>Go</p>
最终当把测试 sql 代码片段组装在一起后,我们获得了一批测试脚本,并按照以下流程,通过使用 NANT 工具实现自动化:
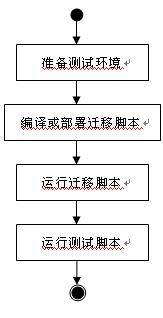
NANT 中的实现方法:
<target name="-init " … />
该任务负责初始化测试环境
<target name="-parseDbScripts " … />
该任务负责编译并部署迁移脚本
<target name="-resetTestData " … />
该任务负责重置测试数据
<target name="-executeMigrationScripts " … />
该任务负责执行迁移脚本
<target name="-testMigration " … />
该任务负责执行迁移测试脚本
该任务将成为持续集成调用的入口
- 持续集成
为完成持续集成测试,测试沙盒必不可少。“沙盒“是一个完整的功能环境,在这里脚本能够被编译,测试和运行。
-
在开发沙盒中,我们准备了少量的核心数据,用以测试 sql 脚本的质量。
-
在系统级集成测试沙盒中,我们还准备了一个小型数据库,这个数据库包含了一部分核心数据,着重测试数据迁移过程的逻辑转换。
-
在生产环境级测试沙盒中,由于数据库来源于实际数据备份,因此数据处于不断变化状态,这就更需要不断运行测试脚本,避免脏数据和数据丢失。由于生产环境数 据量相对大了许多,我们可以适当减少测试次数以减少对开发资源的消耗。同时,其它测试脚本,如变更数据库结构的脚本,都可以和数据迁移脚本组织在一起,一 次性完成测试。
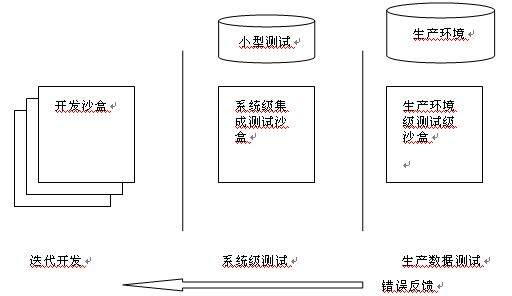
同样,我们采用自动化机制维护这些开发测试沙盒。
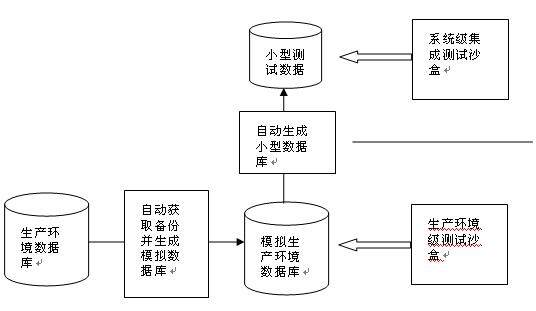
将测试置于持续集成环境中,下图是处于持续集成环境的测试任务。

- 工具选择
选择数据迁移工具应当以帮助提高工作效率和数据迁移运行效率为原则。通常最直接的方法是编写 sql 脚本,借助其它工具也能起到很好的效果,比如 MS SSIS 等。然而我们发现,过多的引入第三方工具往往带来的麻烦也多,例如,我们不得不花时间来学习这些工具的某些特殊用法,有时工具也会产生 bug,以 至于不得不再花时间解决这些 bug,而这与最初的开发目标相背离。因此,有效的方法是尽量使用 sql 脚本执行所有的迁移工作,同时也得到了最佳的执行效 率。
- 保留中间结果用于脚本调试
相比设计语言,Sql 语句较难调试,即使有些数据库产品提供了调试工具,但是调试数据结果 集仍然是项挑战性的工作。尤其在旧系统到新系统的迁移过程中,业务逻辑发生巨大变化,客户经常要求提供某些证据,来解释他们对数据迁移结果的怀疑。保留中 间环节数据, 不仅方便调试,也方便数据追溯,为开发带来更高效率。以下举例说明:
<p>SELECT</p><p>...</p><p>into debug_allpersonhistroy</p><p>FROM</p><p>oldDB.dbo.personhistory -- 这是在旧系统中定义的业务存储表 </p><p>...</p><p>-- 省略复杂的过滤逻辑 </p><p>select column1...columnN</p><p>into debug_allpersonhistroy_aftermapping -- 保留这一步数据集合 </p><p>from debug_allpersonhistroy inner join mappingtableBtwOldandNew</p><p>...</p><p>-- 省略复杂的过滤逻辑 </p><p>SELECT</p><p>...</p><p>FROM</p><p>newdb.dbo.contactHistory -- 这是在新系统中定义的业务存储表 </p><p>...</p><p>-- 省略复杂的过滤逻辑 </p><p>Go</p>### 典型问题
数据迁移在不同的场景往往出现不同的问题,单凭经验也不能全部解决。运用头脑风暴,集中团队中所有力量思考所有可能出现的问题并加以避免。有时开发员遇到的问题也帮助 DBA 少走弯路。最终,头脑风暴能够提供我们的是一份有价值的列表,里面包含各种问题和注意事项:
- 一致性检查
一致性检查包括:字符编码检查、语言设置、环境参数设置等。
迁移过程常出问题的是字符集,它带来的问题是数据乱码。不同系统在最初设计时应用的字符集或编码格式未必相同。在迁移过程中,单凭缺省设置是不够不安全的。有效的办法是在项目伊始,即确认系统间环境一致性。在新系统中采用兼容性的 unicode 编码也能够解决这些问题。
- 控制 NULL 的使用
由于旧系统本身很少使用约束,以至于在表连接查询中出现大量无法得到正确匹配的数据。在 sql 中,当我们试图使用自然连接,我们发现某些数据丢失了,如果使用外连接,这将会带来一种新的脏数据:NULL。从数据库设计角度,NULL 不代表任何含义,而实际情况中,很多数据库建模往往给 NULL 赋予含义,甚至多种含义,以至于不同的查询需求要视不同的业务逻辑对待。在旧系统里,这种现象比比皆是,无疑给迁移带来了不少麻烦。
解决方法:不为 NULL 赋予逻辑上的定义。尽量少使用外连接运算。
例如:
旧系统定义如下父子结构表:
<p>objectId, parentObjectId,objectType …</p><p>------------------------------------</p><p>Null Null ‘root’</p><p>1 Null ‘contactManager’</p><p>2 1 ‘contact’</p><p>3 1 ‘contact’</p><p>4 Null ‘orgnisation1’</p><p>…</p>
显然,系统希望构建如下对象树图:
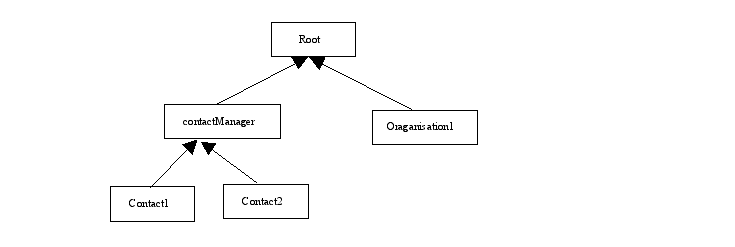
然而,当程序试图遍历所有对象时发现:NULL 无法参与计算。因为 NULL 与任何数据的计算结果都是 NULL。程序必须增加额外代码来处理特殊情况。
- 代码复用,降低依赖性
迁移脚本应当遵循与编码同样的规则,高内聚,低耦合,能够被重复利用的代码需尽量被封装成单元,重复拷贝并不是迁移脚本应当采用的方法。
解决方法:使用临时存储过程实现某些公用代码的复用,简化调用接口。
- 新问题,新测试
当我们遇到新的问题时,常忙于解决问题,给出解释。然而当这一切完成后,并不意味着问题已经全部被解决。因为这些问题仍然可能再次发生,也说明目前测试不足。
解决方法:当新问题出现后,暂停当前的工作,立刻针对这种情况写出测试。为其花费些时间意味着不会让技术问题债台高垒。
例如:在新系统的数据库里,QA 发现了一组不符合逻辑的数据:记录的结束时间 (EndTimestamp) 早于开始时间 (startTimeStamp)8 个小时。它的实际期望结果是:记录的结束时间必须晚于开始时间。
<p>ID, startTimestamp, EndTimestamp, createDate …</p><p>-----------------------------------------------------</p><p>11020011 2008-12-14 09:23:00 2008-12-14 01:23:00 2008-12-14 09:23:00</p>
显然程序在插入数据时用错了时区。在 bug 被修复之前,立刻加入一个数据库测试以保障今后不会再次出现。
测试代码如下:
DECLARE @CNT INTEGER
select @CNT=COUNT(*) from tableA where startTimestamp> EndTimestamp
IF @CNT>0
BEGIN
INSERT INTO LoadTestErrorLog (errorDescription)
VALUES (’ EndTimestamp should be late than startTimestamp ')
END
GO
- 目标制定者和开发者应该保留的心态
数据迁移是一件看似简单但具有挑战的工作。因此,我们常常过于乐观估计开发效率。然而这里的风险在于我们仅仅看到了处理逻辑,而没有看清楚数据质量,以至于盲目写出的迁移脚本可以在测试环境中工作,但无法在生产环境中运行。
解决方法:无论多么简单的数据迁移,应首先与客户或业务分析师沟通业务逻辑,确保对数据质量的了解。
结论
数据迁移是一项看似简单却蕴含巨大挑战的工作。它不仅包含了具体技术问题,而且要求 DBA 具有较好的沟通能力,深入的了解业务逻辑。通过旧系统到新系统的 数据迁移工作,我们逐渐地将精益软件设计思想深入到细节,并且取得了很好的效果。当数据迁移完成后,我们完成了近 6000 行的迁移脚本,迁移结果通过了客 户方的抽样测试,最终确保了整个系统的正常运行。
相关阅读:[ ThoughtWorks 实践集锦(1)] 我和敏捷团队的五个约定。
给 InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家加入到 InfoQ 中文站用户讨论组中与我们的编辑和其他读者朋友交流。




