
背景介绍
近年来,AI 行业蓬勃发展,变化日新月异,每一次突破都令人振奋,推动着我们不断迈向真正的人工智能时代。而这一切的实现,离不开计算机系统强大的算力支持、海量的数据积累以及先进的算法。从一年多以前 ChatGPT 问世以来,全球更是陷入了一场大语言模型(Large Language Model, LLM)的热潮。随着 LLM 的规模不断扩大,算力资源的需求也与日俱增,为 LLM 推理带来更大的挑战。如今,如何降低推理成本,提高推理效率,是 LLM 推理面临的重要问题。
为此,英特尔推出了一个名为 xFasterTransformer [1]的 LLM 推理加速框架,旨在帮助 AI 开发者在英特尔®至强®平台上提升 LLM 推理性能,最大化利用硬件资源,通过简单的使用方式就能帮助用户在 CPU 上实现高效的模型部署。
xFasterTransformer
项目架构
xFasterTransformer [1] 是英特尔开源的推理框架,其遵循 Apache2.0 许可,为 LLM 在 CPU 平台上的推理加速提供了一种深度优化的解决方案。xFasterTransformer 支持分布式推理,支持单机跨 socket 的分布式部署,也支持多机跨节点的分布式部署。并提供了 C++和 Python 两种 API 接口,涵盖了从上层到底层的接口调用,易于用户使用并将其集成到自有业务框架中。xFasterTransformer 支持 BF16,FP16,INT8,INT4 等多种数据类型及多种 LLM 主流模型,比如 ChatGLM,ChatGLM2/3, Llama/Llama2,Baichuan,QWEN,OPT 以及 SecLLM(YaRN-Llama)等。其框架设计如图 1 所示。
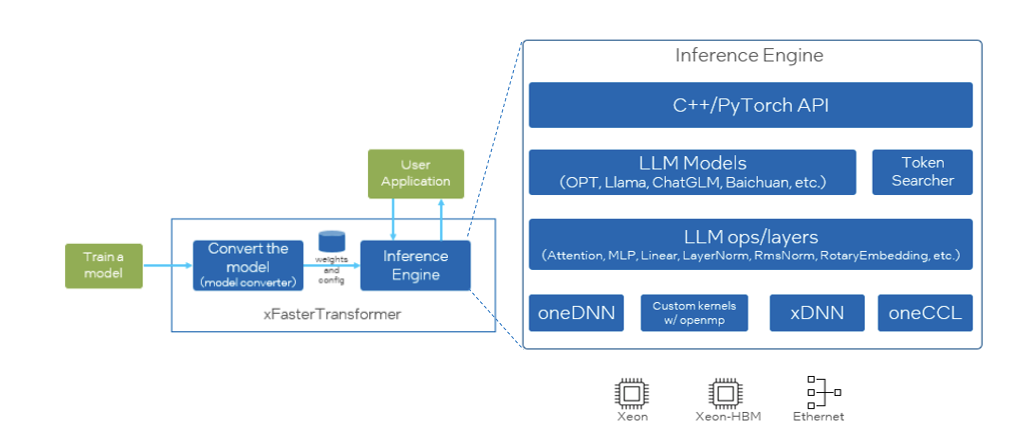
优化策略
xFasterTransformer 优化自上而下采用了多种优化策略,包括张量并行(Tensor Parallelism)和流水线并行(Pipeline Parallelism),使用硬件加速指令 AMX、AVX512 向量化优化,避免冗余计算,多种低精度量化相结合等方式。下文将展开说明这些优化策略。
分布式推理优化
我们知道分布式推理过程中,通信延迟对推理性能的影响较大。项目在使用高效的通信库 oneCCL 基础上,优化通信实现,降低通信量。比如,在每轮推理的初始阶段,我们推荐的实现方式是广播 token ID,而不是广播根据 token ID 查出来的 Embedding 的值。在每轮推理结束时,直接对所有 token 的 logits 进行 reduce 并不是最优选择。更有效的方法是,让各个 worker 计算出 topk 后再进行 reduce 操作。
此外,我们还需要根据模型本身的结构来优化通信方式,比如像 gptj,falcon 这样的模型,attention 部分和 feed forward network 是并行的,我们完全可以做到每一个 decoder layer 只做一次通信,也就是一次 reduce add。
另外,计算模块和通信模块在交互的时候,往往会涉及到数据拷贝,一种更激进的优化方式可以尝试省去这些拷贝,也就是计算模块在做通信前的最后一次运算的时候,直接将结果写到通信模块所在的位置,从而达成零拷贝的实现。

高性能的计算加速库
项目集成了 oneDNN、oneMKL 以及定制化优化矩阵计算库实现。通过多个计算库的结合,为用户自动选择最优实现,并提供了大量的基础算子优化,如矩阵乘法、softmax 和常用的激活函数等等,为大语言模型推理提供基本的 kernel 支持。通过使用这些计算库,可以将 LLM 中的操作加速到更高的性能水准,从而提高整体计算效率。此外,在支持高级矩阵扩展 AMX[2]技术的平台上, xFasterTransformer 会自动识别并使用 AMX 对矩阵运算进行加速,从而大大提升推理性能。
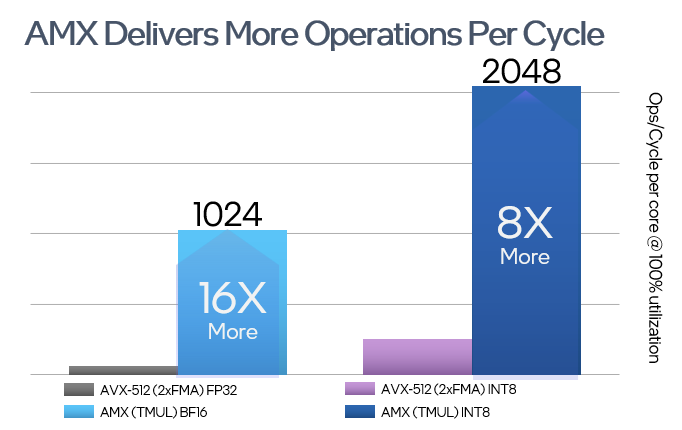
优化 LLM 实现
算子融合,最小化数据拷贝和重排操作,内存的重复利用也都是常用的优化手段。通过有效地管理内存可以最大限度地减少内存占用,提高缓存命中率,从而提升整体性能。此外,仔细分析 LLM 的工作流程,不难发现计算过程种存在的一些不必要或重复的操作,我们可以减少这些不必要的计算开销,提高数据重用度和计算效率。
以 Attention 为例,Attention 是 Transformer 模型的关键热点之一。我们知道 Attention 机制消耗的资源跟序列长度的平方成正比,所以 Attention 的优化对于长序列的输入尤为重要。针对不同长度的序列,保证访存效率最高,项目会采取不同的优化算法来进行优化。
低精度量化和稀疏化
通过使用低精的数据类型,或者是将权重进行稀疏化,都可以有效地降低对内存带宽的需求,从而在推理速度和准确度之间取得平衡。xFasterTransformer 支持多种数据类型来实现模型推理和部署,包括单一精度和混合精度(首包和后面的生成 token 精度可以不一样,任意组合)充分利用 CPU 的计算资源和带宽资源,来提高大语言模型的推理速度。
使用方式及性能效果
使用方法
接下来将以 Llama 为例,讲述如何使用 xFasterTransformer 这个高效的推理性能加速框架来启动一个 web demo。当然,如果你需要采用其他启用及使用方式,都可以从开源项目 xFasterTransformer[1]中的使用说明找到你想要的答案。
假设开发者已经有了 Llama-2-7b-chat 预训练模型[3],接下去只需简单几步就可以采用 xFasterTransformer 帮助你在 CPU 上完成高效的推理加速。我们推荐使用第四代及以上的英特尔®至强®平台。
1、获取并运行 xFasterTransformer 容器
docker pull intel/xfastertransformer:latestdocker run -it \ --name xfastertransformer \ --privileged \--shm-size=16g \intel/xfastertransformer:latest2、转换模型格式
下述命令将帮助你将已有的 HuggingFace 格式的模型转换成 xFasterTransformer 可应用的格式,如需转换 Llama 以外的模型,可以从 xFastertranformer[1]使用说明中获得更多帮助。
python -c 'import xfastertransformer as xft; xft.LlamaConvert().convert("${HF_DATASET_DIR}","${OUTPUT_DIR}")'3、安装相关依赖启动 web demo
pip install -r examples/web_demo/requirements.txtLD_PRELOAD=libiomp5.so python examples/web_demo/Llama2.py \ -d bf16\ -t ${TOKEN_PATH} \ -m ${MODEL_PATH}通过这样简单的步骤,使用者将轻松的启动一个 web demo,与该聊天助手交谈。
如果开发者需要采用其他启用及使用方式,都可以从开源项目[1]中的使用说明获得相应的帮助。
性能结果
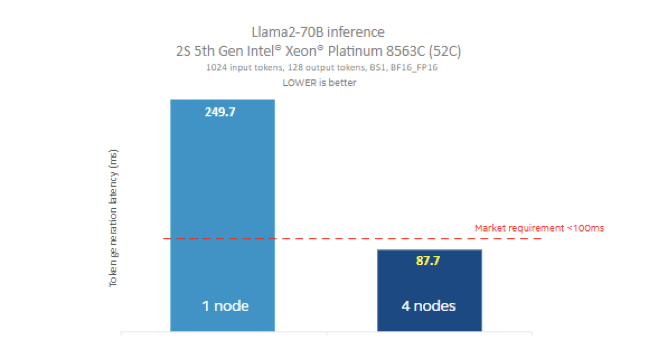
采用四台双路英特尔® 至强®8563C 进行测试,在输入大小为 1024 、输出大小为 128 时,运行 Llama2-70B[4]大语言模型的 16 位精度推理仅花费了 87ms 的延时(生成 token 的测试结果)。
最后,欢迎广大 AI 开发者试用 xFastertranformer[1],在英特尔®至强 平台上实现更高效的 LLM 推理性能优化。更诚邀大家一起交流,向开源项目仓库中反馈问题及提交代码,共同推动大模型推理性能的优化之路。
[1] xFasterTransformer 项目开源地址: https://github.com/intel/xFasterTransformer
[2] AMX 简介:https://en.wikipedia.org/wiki/Advanced_Matrix_Extensions
[3] Llama-2-7b-chat 预训练模型: https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
特别致谢:
在此致谢为此篇文章做出贡献的英特尔公司工程师李常青、王杜毅、余伟飞、刘晓东、孟晨、桂晟。
作者简介:
英特尔公司 AI 软件工程师黄文欢,英特尔公司资深架构师周姗,英特尔公司首席工程师何普江,都在从事人工智能及性能优化相关工作。




