
一、TarsBenchmark 是什么
1. 常见测压工具

我们在服务后台的一些 APP 上线之前,通常会做一些性能的评估,然后会评测一下。例如开发的项目大概可以服务多少用户,以及能够承担多大的并发量?
(1)Apache Bench
经典的性能评测工具 AB,也叫 Apche Beach,它是一个 http 协议服务的压测工具,也是众多 WebAPP 的经典压测工具,采用 C 语言开发,方便易用也具备较好的性能。
但是它也有不足的地方,主要在于它采用的是单线程模式,而我们现在后台的服务器很多都是多核,因此它不能发挥我们服务器的全部性能。
(2)Wrk
新的压测工具 Wrk,它弥补了 AB 单线程设计的不足。它采用的网络是事件驱动的方式,在网络 IO 方面有比较好的表现。
另外它支持脚本语言。可以在 lua 生成一些随机内容。现在大部分后台的服务都是采用分布式的部署,如果仅对某一个请求不断的重放,容易导致单机高负载,而不能反应真实集群的服务能力。而 wrk 在这两方面进行了改进,因此它的应用非常地广泛。
(3)GHZ
在微服务里还有一个很典型的压测工具 GHZ,他是 GRPC 框架下的一个压测工具,开发语言是 golong,因此具备很好的并发能力。
它的用例采用 JSON 的格式组织,它利用 PB 良好的反射特性很容易将 JSON 的用例转换成网络传输所需要的二进制方式,因此使用起来也非常方便。
(4)JMeter
最后给大家介绍一下 JMeter 工具,它是采用 Java 语言开发,提供了图形界面交互形式,支持分布式部署,可以弥补单机性能的不足。
但是因为 JMeter 相当于采用线程的模型,用一个线程模拟一个用户请求,实际上当线程积累到一定的数量之后,线程调度和竞争会带来一些额外的 CPU 开销,所以它的单机性能存在一些不足。
2. TarsBenchmark 是什么?
常见的压测工具可能还有很多,这里就不一一展开,下文主要介绍 TarsBenchmark,看看这款压测工具到底有哪些特性?
(1)单机运行的压测工具
TarsBenchmark 是基于 Tars 生态的一个压测工具,它主要服务 Tars Service,而 Tars 是腾讯开源的多语言、高性能、易运维的微服务框架,它的通讯协议采用 Tars,而 Tars 是类似于 PB 二进制的一种传输的协议,并且它是由腾讯完全自主研发的。目前参与的开发人数已经快接近 300 人了,在 Github 上你输入 TarsCloud 就可以进入官方介绍文章了解我们的 Tars。
Tars 支持 C++等多种开发语言,Tars 相对其他开发框架比如 PRPC 等,还提供一个服务平台,并且可以帮助开发者和企业快速构建稳定可靠的分布式微服务应用,开发人员只需要关注业务逻辑,从而提高研发和运营效率。
(2)一个支持云端压测平台
TarsBenchmark 不仅可以在单机上运行,它还提供一个云端的压测 Web 平台,即可以支持分布式压测,让开发者可以很方便从容进行 TarsService 压测,来评估 Tars 服务的性能。
(3)不仅仅 ForTarsService
当你的团队里面使用非 Tars 协议服务,它也可以很容易满足。在后面的 TarsBenchmark 使用中,我会为大家介绍怎样去开发非 Tars 协议,用我们的工具很容易满足第三方协议的压测。
3. 解决了哪些问题 ?
那么 TarsBenchmark 到底解决了哪些问题呢?主要在于以下三点:
高性能:充分发挥多核 CPU 计算能力,8 核机器可输出 40Wtps 能力;
高扩展性:支持任意一个 Tars 接口压测,友好支持非 Tars 协议;
简单易用:用例采用 JSON 格式,编写便利,支持线上云压测 。
二、TarsBenchmark 原理
1. 工具压测原理
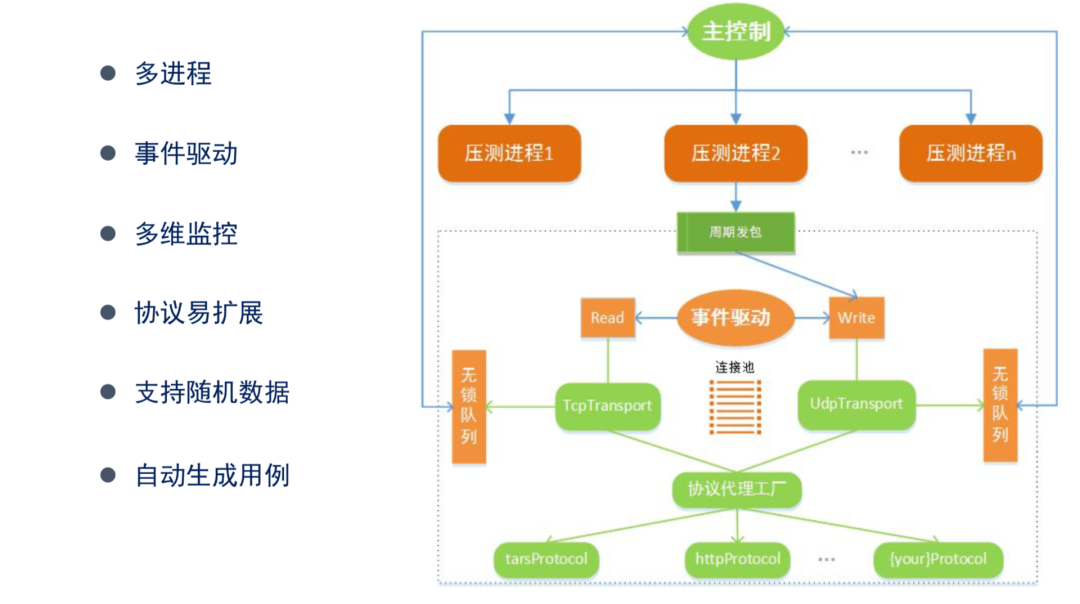
(1)多进程
首先来介绍高性能设计的实现,我们在上文也分析了 AB 和 Wrk,其中 Wrk 对 AB 的升级主要在于采用多线程实现,而 TarsBenchmark 也是采用多进程的方式。
在主进程上我们会根据服务器的物理核数去 fork 相等数量的压测进程,各压测进程之间是完全隔离的,也就是独立去运行,避免了进程与进程之间互相争夺临界资源。当然这个压测进程数是可以通过参数指定的,默认会根据 CPU 的有效核数去 Fork 对应的一个进程。
(2)网络处理
在网络方面采用的是事件驱动的方式,就是通过定时发包器发包,基于网络事件收发,有效避免网络 IO 的阻塞。
另外在连接方面我们采用连接池,在连接池对每个连接采用连接复用的方式。在我们分析 AB 压测原理的时候发现:当 AB 链接建立起来并发完一个报文出去的时候,收到这个报文之后才会发起下一个报文,因此在这个链接中它会有等待操作,不能完全的把链接利用起来和匀速产生 QPS。
而 TarsBenchmark 是基于连接复用方式,不依赖于对端是否返回。对于外部服务返回这个场景,当我们在用 AB 压测的时候,有时候会发现服务器的返回非常及时,那么这个时候 AB 就可以达到很高的一个输出能力;但是当服务端返回耗时较高的时候,AB 输出能力就会出现乘数级的下降。
例如: CGI 在 20ms 的返回和 200ms 的返回,相同链接数会影响 AB 十倍的性能输出差异,因此我们觉得链接设计方式是一种浪费。
在 TarsBenchmark 设计的时候考虑到这一点,它基于协议包的序号可以做到不依赖服务端回包时机去选择下一个报文发送时间,通过返回包序号去定位到发包的时间,从而计算压测过程当中的状态信息。
(3)多维监控
我们的压测进程和主进程之间有一些通讯,是通过无锁队列来完成信息交互,包括上文提到的耗时的统计、错误码的统计都是通过无锁队列来完成的。
(4)协议扩展
另外在协议这一块,我们采用的是协议代理工厂这种模式,TarsBenchmark 默认提供的是 Tars 协议的压测。但是如果你有一些私有协议,可以参考 Tars 协议的实现,也可以集成进来,代理工厂可以自动识别新增加的协议。
(5)支持随即数据
在 Tars 协议压测中,TarsBenchmark 可以支持随机数据的生成,另外也提供随机函数,它可以有效避免压测过程中对唯一的请求进行重放。
(6)自动生成用例
在 Tars 协议这一块,我们还提供一个工具,用以自动生成 Tars 服务所需的测试用例。TarsBenchmark 的测试用例采用的是 JSON 格式,用户只需要编辑 Value 可以很轻松得发起压测。
2. 分布式压测原理
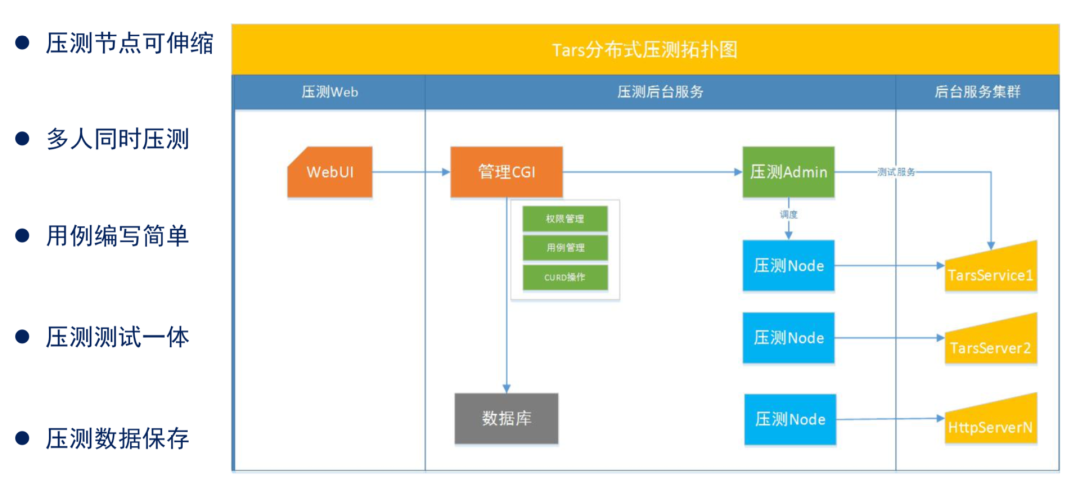
分布式压测主要是解决同时多人使用平台的问题。它的主要部件由四个部分组成。
第一部分是 WebUI 入口,它集成在 Tarsweb 上面,提供了一套非常简单的交互。
第二部分是 CGI,主要做测试用例的管理,其中包括数据库的 CRUD 操作、权限的控制。
第三、四部分是后台服务,包含一个压测 Admin 服务和 Node 服务(压测 node)。Node 服务负责执行具体的压测任务,使用工具压测结束之后随系统自动销毁,而在分布式压测的时候,是依赖压测 admin 来进行销毁的。
为降低复杂度,TarsBenchmark 在设计的时候采用的是多线程方式(linux 系统调度 CPU 资源是以线程为单位)。压测 admin 会接受 CGI 的指令,比如用户在输入的 QPS 调度所需的压测 node 时,因为压测 node 调度最小单元是线程,一个线程可以设置 3~5 万的输出能力,然后根据这种单线程能力我们再计算需要的线程数,最后把它分配到我们的压测 node 里面去执行压测。
TarsBenchmark 会把这些数据会暂存在压测 Admin 里面,压测 Admin 服务一般推荐主备部署的模式,分布式压测用例编写也是采用 JSON 格式,后台有个工具对每个接口帮助用户自动生成 demo 用例。用例的编写也非常的简单。TarsBenchmark 也会提供测试功能,方便用户压测的时候去验证当前功能是否正常。
3. 协议转换
我们知道 Tars 是一种二进制、可扩展的跨语言的协议,它支持 C++、PHP、Java 和 Node,其本质是 TLV 的协议。但是整个压测,如果采用 JSON 这种组织,如何转成二进制?这可能是整个压测最大的一个难点,那么 TarsBenchmark 是怎么去解决这个问题的呢?
首先我们分析一下 Tars 的协议编解码原理,T 包含 Tag 和 Type,传输的时候二进制前面有四个 bit ,表现为一个 Tag。接下来是表示数据的 Type, Tars 协议最多可以支持 16 种数据类型,目前已经编到 14 种。这是 Tars 最开始的时候就这样设计的,目前我们数据的类型并没有超出我们的编码,说明当时的这种设计还是具备一定的前瞻性。
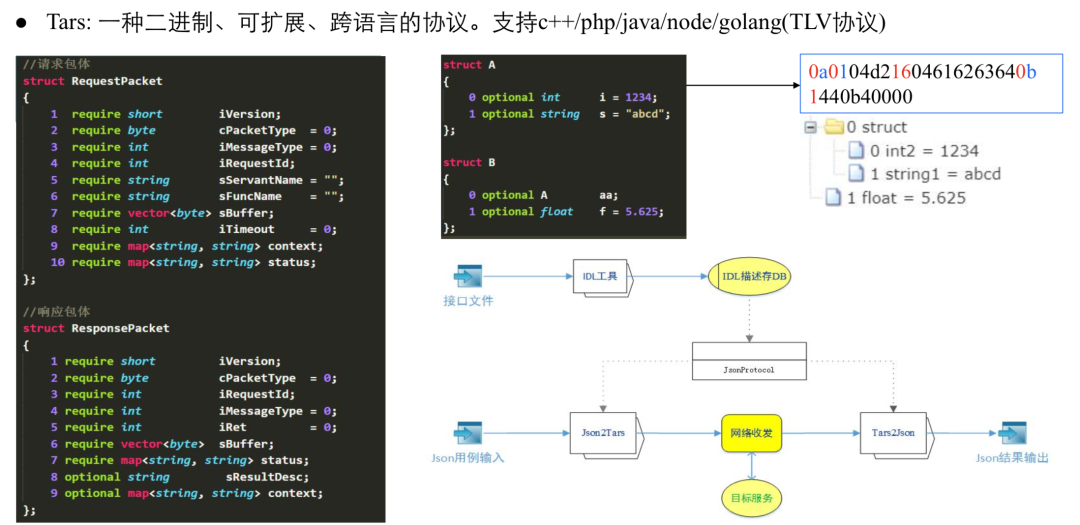
这其中有七种基本类型,还有三类复杂类型。举个例子,以很常见的两个结构体嵌套为例,它编出来的二进制结果如上图所示,最右边是最终编码出来的一个效果,首先我们看到这个是 B 结构体二进制编码的效果,从第一个 0 开始,代表了它就是这个 a 变量的一个 Tag,我们查找 a,发现它是结构体的起始,进入到 a 结构体之后第一位也是 0 ,tag 对应的是 int 数据,然后是两个字节的数据,4 进 2 的话对应 1、2、3 和 4。
16 我们可以看到 1 是它的 bits1,对应 s 的变量,6 是代表它的实俊,它的字节长度是 4,我们可以看到是跟的 616、63 和 64,对应就是 abcd,然后 0p 结束代表这个结构体已经结束了。接下来就是 14,我们发现 1 是代表这种 float 数据类型,然后 4 对应的是四个 bits 的数据,反序列化以后对应这样的一个结构体,跟我们中间这个结构体对应起来。
如果采用编辑二进制去压测我们的 Tars,我想大部分人都会崩溃,一个简单的结构体可能还可以写出来,但是当你结构体的成员很多或者超过了十个,或者结构体里面又嵌套结构体,估计大部分开发都会抓狂,因此利用这种方式编辑显然是不可取的。
那么 TarsBenchmark 是怎么做的呢?我们会根据 Tars 的接口文件,利用 IDL 工具,首先将这种语法数生成一个描述文件,描述文件包含三个部分:Tag、Type 和 Name。对于 Web 平台会存到 DB 里面去,采用 RPC 调用的 Tars 在 body 之外还有一层 head,它有四个关键信息: 一个请求 id, 服务名称,函数名称,以及参数二进制 body。
在实现的 TarsBenchmark 会去查这个描述文件的 Name,然后通过 Name 获得 Tag 和 Type,再从用例里面获得 Value,再通过 Tars 的编解码规则写入二进制 Buffer 里面,最终完成了 JSON to Tars 的这种转换。
它的逆向转换其实道理是相通的,我们首先把它从二进制还原成 Tars 的 Tag 和 Type,然后我们通过 Tag 在描述文件中查到 Type 和 Name,然后通过 Name 和 Value 还原 JSON 的格式,以上是一个 RPC 调用过程在客户端的协议转换流程。
4. 第三方 Service 压测

如果采用第三方协议其实也很简单,实现四个函数接口就可以完成对于非 Tars 协议的支持。
这四个函数接口分别是是初始化接口,断包接口(采用 TCP 长链接的流式格式,响应包到哪截止,在这个 input 函数里面去实现就可以),编码接口,解码接口。
请求编码接口的实现,这里面有一个很重要的参数 id,我们系统每次请求会生成一个 id,如果这个接口支持就可以把 id 返回回来。
以我们的 Tars 为例,我们在 head 里面有一个 id 填充进去,RPC 响应回来的时候会携带同样的 id,TarsBenchmark 会根据这个请求应答,计算这个请求的耗时和成功率。如果第三方服务不支持返回序号,需要在 isSupportSeq()返回 false,它就进入无序模式,无法做到链接复用。
以上就是 TarsBenchmark 的设计原理。
三、TarsBenchmark 的使用
1. 代码目录结构

源码路径:
https://github.com/TarsCloud/TarsBenchmark。
首先看一下 TarsBenchmark 的代码结构,主要分为四个部分,从下往上看最开始的是工具,服务,公共模块和资源文件。重点介绍一下公共模块,主要是 3 部分:协议,网络和监控。
协议支持: 默认会支持两种协议,一种是 HTTP 协议,一种是 Tars 的协议。
监控: 压测共同的数据都是通过监控器暂存,无锁队列通信也在此实现。
网络: 采用事件驱动方式,非阻塞 Socket 模式设计。
2. 代码编译

代码编译主要是两个部分,一个是 TarsCpp,如果有云端压测的需求,TarsWeb 也是依赖项。
编译的步骤也很简单,首先将代码克隆下来,新建一个临时目录通过 cmake 完成编译,就可以生成三个程序,分别是 tb、nodeserver 和 adminserver。很多时候最小的需求只需要一个工具 tb,工具可以直接在单机执行,而当你有云端压测需求,执行一下 install 安装脚本,一键安装到 Tarsweb 中去。
这里主要有几个参数,一个是 web 的 host,adminserver 推荐和 Tars 基础服务部署在一起,因为它本身不会消耗太多的 CPU,但是 nodeserver 不同,推荐单独部署,并且它是可以水平扩展的。
3. 单机工具压测
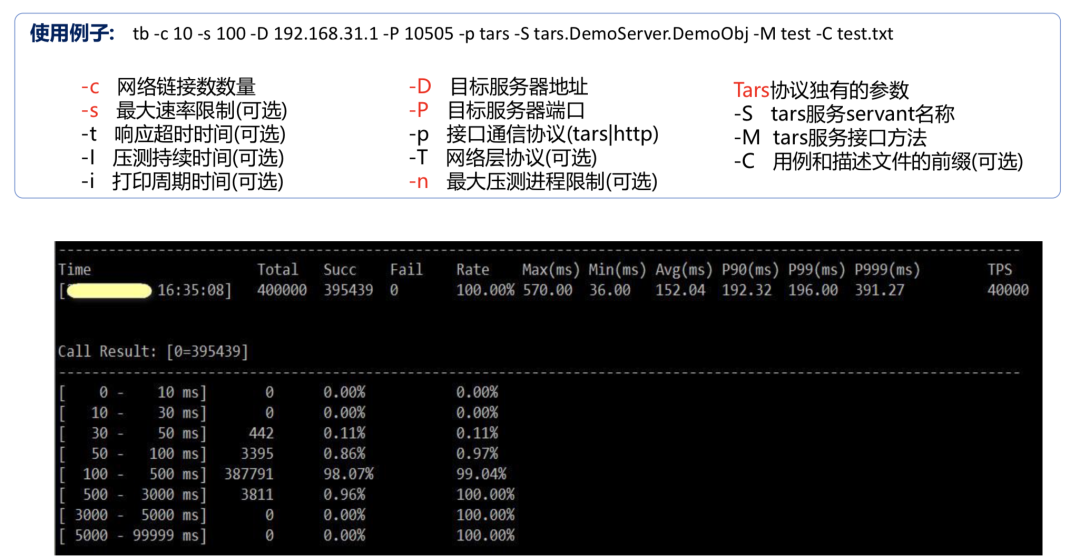
对于单机工具的压测使用,有如下参数可以根据实际情况调整:
-c 是压测的链接数,-s 是最大的 qbs 的限制,如果没有指定-s 就会尝试探测服务端最大性能去实现压测;
-D、-P 压测目标服务器的端口,目标服务器可以执行多个地址,通过逗号进行区隔;
-n 参数: 指定压测的进程数。-T 指定 TCP 或者 UDP,默认 TCP;
-p 参数: 接口通讯协议,如果是自己的私有协议,可以改成私有协议的名字。
每次压测的周期里面,都会有一些耗时的分布、成功率的统计、平均耗时的 P99 或者 P90 的这种统计信息,可以周期性的打印出来,避免出现压测过程当中不了解当前服务的情况,还有就是持续的这种压测时间也是可以通过-i 参数去指定的。
4. 云端分布式压测
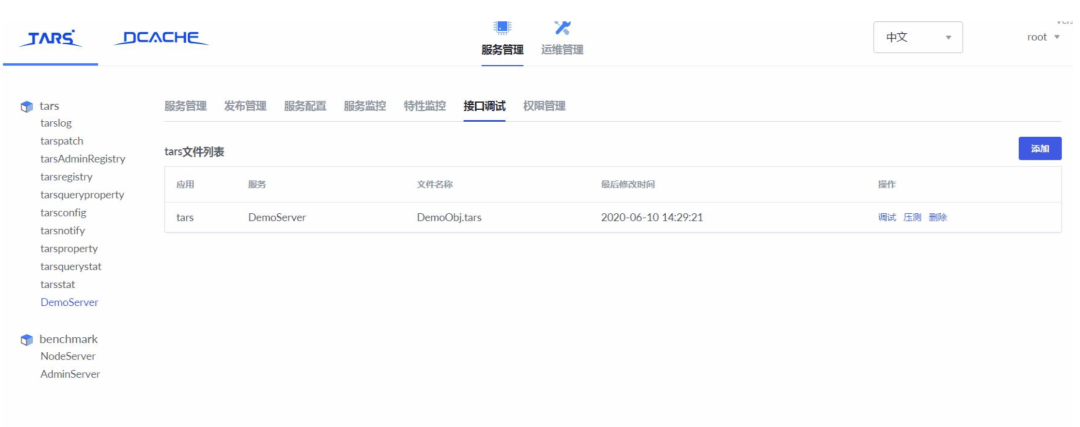
云端压测使用十分简单,在 TarsWeb 接口调试里有一个压测入口,用例可以看出来,你新增的时候会自动生成这些用例,当你压测的时候,你只需要指定这些压测目标 IP,QPS 就可以随时随地发起压测,并可以看到压测过程中的服务表现。
四、TarsBenchmark 成果
1. 发展历程

我们是在 2016 年的时候在腾讯内部开源,最开始它只是一个工具,支持的协议也很少,主要是 Tars,而 Tars 在内部是叫做 taf 协议。
在 2018 年之后支持协议数变得非常丰富,之前很古老的服务都可以通过这个工具支持到,目前在内部使用还是十分广泛的。另外它支持云端 Web 压测,每周大概使用的人数也超过了数百人,不需要登录到 IDC 机器上,随时随地都可以发起。
今年 4 月份我们也把它贡献给开源社区 TarsCloud,造福社区的小伙伴,欢迎大家多多提出指教。
2. 同类型对比
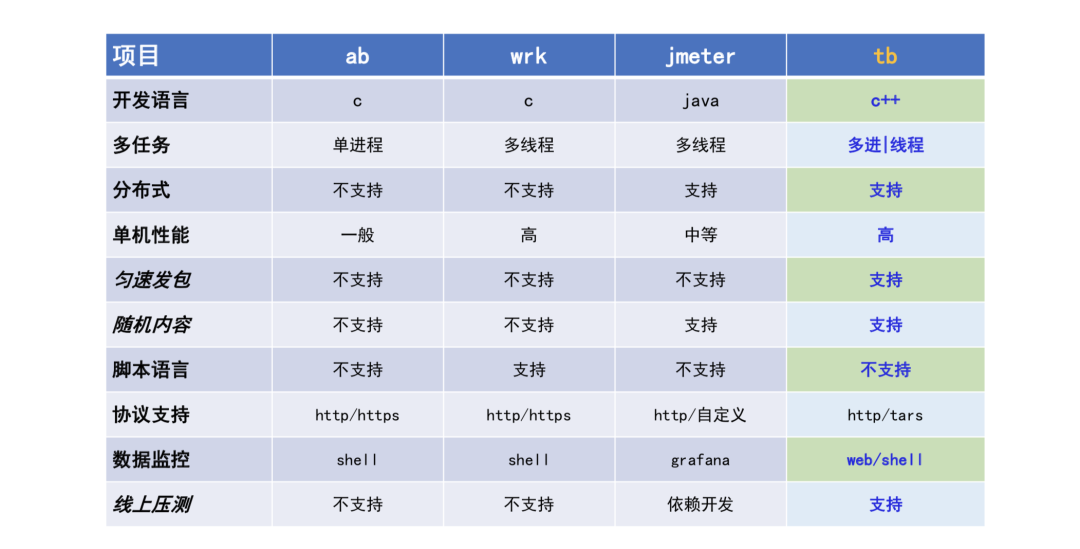
目前使用的反响非常不错,相对于其他的一些开源工具,这个工具是采用 c++语言开发的,有两种模式,一种是多进程,也就是工具采用多进程的模式,在云端压测是采用线程池的模式,支持分布式的压测,单机性能相对 AB 和 Wrk 也有一个很好的表现。
最重要的是 TarsBenchmark 支持匀速的发包,因为它基于连接复用的方式,在连续发送上不依赖请求返回,因此可以做到匀速的发包,也支持随机内容的生成。另外它还支持线上的压测,这也是 TarsBenchmark 的一个很重要的亮点。
以上就是今天的分享内容,欢迎各位小伙伴们前来参与生态贡献。另外如果对我们的岗位有需求,可以直接发简历到我的邮箱里面来: linfengchen@tencent.com 。
五、Q&A
Q:wrk 和 TarsBenchmark 之间的区别是什么?如何做压测选型?
A: 这个问题很好,刚才我们说 wrk 相对来说跟我们的 TarsBenchmark 的网络模型其实是一样的,它是基于多线程以及网络附用的模式。但是 wrk 是纯 http 的协议压测工具,http 协议可以理解为无序的模式,无法做到链接复用,性能还有一些制约,也没法做到匀速发送。
另外一方面,wrk 主要是一个纯 HTTP 协议,它并不能支持到私有的协议,私有的协议用起来还是有一些费劲,我们的 TarsBenchmark 在协议扩展性方面会表现的会更好一点。
Q:我们现在 TarsBenchmark 代码量是多少?
A: 我们还是很轻量的,我们统计有效代码是几千行左右。
我印象当中好像 3000 到 4000 行之间,是代码量非常少的工程,学习曲线也是非常平缓的,不会太复杂,只要有一些 C++语言基础就可以很快的上手。
Q:TarsBenchmark 以及 TarsJMeter 的区别?
A: 刚才暖场的时候也说,我们的 JMeter 是采用线程的模式去模拟用户,在一个线程里面执行一个用户的请求响应,这种线程的调度开销还是非常大的,你试想一下在一个机器上起一万个线程的规模,线程之间因为线程调度依赖操作系统,因此像 JMeter 的网络模型的性能不会很好。
当然也有一些人对这种 JMeter 做了一个扩展,因为 JMeter 最大的应用是具备很好的扩展性,它支持分布式压测,单机不行,可以分布式弥补,这是 JMeter 比较大的优点。
另外它的上报都是插件的设计思想,还是蛮先进的,比如说我们一些结果的数据,我们可以上报到其他的一些 UI 语言上面做一些呈现,这一块是 JMeter 很大的一个优势,我们在做市面上常见的几款压测工具调研的时候,把它们架构的长处融合在一起就最终形成我们的 TarsBenchmark。
总结下来,TarsBenchmark 有更好的单机性能表现。
Q:是为什么不用 golong 语言开发
A: 这个有一些背景,我们最开始是在 2015 到 2016 年做的这款产品,Tars 那个时候的生态,在我们内部主要是以 C++为主,golong 在网络这一块其实做了很多底层的能力支持,我们内源版本也有 golong 的实现,但是目前没有开源出来。
通过对比发现 C++的性能会比 golong 的网络模型好一点点,主要是体现在编解码这一块效率会更高一点。
Q:Tars 支持哪些接口,http 支持吗?
A: 这个是支持的,你用最新版的 Tars 开发框架是可以写自己的接口,所以我们的 TarsBenchmark 本身的话也是支持 http 协议的压测。
Q:是不是支持这种 kafka 做一些压测?
A: kafka 这些组件基本上都有自己的一些压测工具,其实我个人建议,你用它框架组件的一些压测工具就可以满足了,当然你自己有兴趣去研究一下我们的 TarsBenchmark,按我刚才说的思路实现三个函数、四个函数,也可以去完成对你 kafka 提取的一个压测。
Q:为什么效率会这么高?还可以提高吗?
A: 刚才在工具里面我也跟大家介绍了一下,主要是四个方面,一个就是多进程,充分发挥 CPU 的计算效率。第二方面是我们采用这种非组装的网络模型,第三是基于这种网络链接附用的方式避免链接在那里闲置,第四是所谓的这种通讯都是采用非阻塞的。
还有没有办法继续提高?我们现在也发现了,比如说我们在复杂的 Tars 接口的编解码效率这块还是会有一些问题,所以如果说还有什么提高的话,主要就是在编解码这块要考虑零拷贝的思想,我们的操作系统和压缩工具之间尽量零拷贝去缓冲区的操作,包括这种二进制的协议以 Tars 为例,我们把它转换成 Tars 尽量采用更高效的编解码的效率工具,目前我们在尝试做进一步的提升。
Q:TarsBenchmark 目前在腾讯云上面看到相关的产品和解决方案,未来会不会上腾讯云?
A: 目前,主要是以开源的这种形式去共建,以开源的方式提供,目前没有上云的计划,如果采用 Tars 的生态,我们可以免费提供给广大的用户去使用,包括企业和个人。
Q:采用的是 C++ 11 标准设计的吗?
A: 这个是对的,我们是采用 C++ 11 的标准去完成的。另外我也受 Tarscloud 官方委托,如果大家对 Tars 的比较关注,可以关注它的官网,它的源码就是在刚刚的 PPT 里面,大家可以关注云+社区的公众号回复线上沙龙就可以获取。代码结构可以在我们这个上一期节目,就是 Tarscloud 能力以及它的参数的一个目录,你可以自己去找相应的你感兴趣的资料去学习或尝试。
Q:大数据产品是否可以压测?
A: 你说的大数据产品指的是 idp 的压测?目前像这种大数据也有自己的一套通讯协议,如果你抓住这个通讯协议的规律,或者你了解它的一些协议设计的方式,其实也是可以的。
作者介绍:
陈林峰,腾讯专家工程师
陈林峰,腾讯专家工程师,TarsBenchmark 项目负责人。深入过多次 QQ 春节红包项目的开发,在高性能后台服务设计方面积累了丰富的经验,在服务性能评测有比较深刻的体会。目前负责 QQ 社交娱乐业务的后台开发和团队管理。
本文转载自公众号云加社区(ID:QcloudCommunity)。
原文链接:




