
Google 于 2017 年 2 月 16 日(北京时间)凌晨 2 点在美国加利福尼亚州山景城举办了首届 TensorFlow 开发者峰会。Google 现场宣布全球领先的深度学习开源框架 TensorFlow 正式对外发布 V1.0 版本,并保证 Google 的本次发布版本的 API 接口满足生产环境稳定性要求。前言
TensorFlow 在 2015 年年底一出现就受到了极大的关注,经过一年多的发展,已经成为了在机器学习、深度学习项目中最受欢迎的框架之一。自发布以来,TensorFlow 不断在完善并增加新功能,直到在这次大会上发布了稳定版本的 TensorFlow V1.0。这次是谷歌第一次举办的 TensorFlow 开发者和爱好者大会,我们从主题演讲、有趣应用、技术生态、移动端和嵌入式应用多方面总结这次大会上的 Submit,希望能对 TensorFlow 开发者有所帮助。
TensorFlow: 为大众准备的机器学习框架
TensorFlow 在过去获得成绩主要有以下几点:
- TensorFlow 被应用在 Google 很多的应用包括:Gmail, Google Play Recommendation, Search, Translate, Map 等等;
- 在医疗方面,TensorFlow 被科学家用来搭建根据视网膜来预防糖尿病致盲(后面也提到 Stanford 的 PHD 使用 TensorFlow 来预测皮肤癌,相关工作上了 Nature 封面);
- 通过在音乐、绘画这块的领域使用 TensorFlow 构建深度学习模型来帮助人类更好地理解艺术;
- 使用 TensorFlow 框架和高科技设备,构建自动化的海洋生物检测系统,用来帮助科学家了解海洋生物的情况;
- TensorFlow 在移动客户端发力,有多款在移动设备上使用 TensorFlow 做翻译、风格化等工作;
- TensorFlow 在移动设备 CPU(高通 820)上,能够达到更高的性能和更低的功耗;
- TensorFlow ecosystem 结合其他开源项目能够快速地搭建高性能的生产环境;
- TensorBoard Embedded vector 可视化工作;
- 能够帮助 PHD/ 科研工作者快速开展 project 研究工作。
Google 第一代分布式机器学习框架 DistBelief 不再满足 Google 内部的需求,Google 的小伙伴们在 DistBelief 基础上做了重新设计,引入各种计算设备的支持包括 CPU/GPU/TPU,以及能够很好地运行在移动端,如安卓设备、ios、树莓派等等,支持多种不同的语言(因为各种 high-level 的 api,训练仅支持 Python,inference 支持包括 C++,Go,Java 等等),另外包括像 TensorBoard 这类很棒的工具,能够有效地提高深度学习研究工作者的效率。
TensorFlow 在 Google 内部项目应用的增长也十分迅速:在 Google 多个产品都有应用如:Gmail,Google Play Recommendation, Search, Translate, Map 等等;有将近 100 多 project 和 paper 使用 TensorFlow 做相关工作。

TensorFlow 在过去 14 个月的开源的时间内也获得了很多的成绩,包括 475+ 非 Google 的 Contributors,14000+ 次 commit,超过 5500 标题中出现过 TensorFlow 的 github project 以及在 Stack Overflow 上有包括 5000+ 个已被回答的问题,平均每周 80+ 的 issue 提交。
过去 1 年,TensorFlow 从最开始的 0.5,差不多一个半月一个版本:

TensorFlow 1.0 的发布
TensorFlow1.0 也发布了,虽然改了好多 api,但是也提供了 tf_upgrade.py 来对你的代码进行更新。TensorFlow 1.0 在分布式训练 inception-v3 模型上,64 张 GPU 可以达到 58X 的加速比,更灵活的高层抽象接口,以及更稳定的 API。
New High Level API
对于新的抽象接口,TensorFlow 相对于其他 DeepLearning FrameWork 做的比较好,layers 能让人很容易 build 一个 model,基于 layer 之上的包括 TF.Learn 里面仿照 scikit-learn 风格的各种 estimator 设计以及之后将融入 TensorFlow 官方支持的 Keras,能够让小伙伴用几行配置模型结构、运行方式、模型输出等等 ; 在这层之上就有 canned Estimator,所谓的 model in box,比如 lr,kmeans 这类。
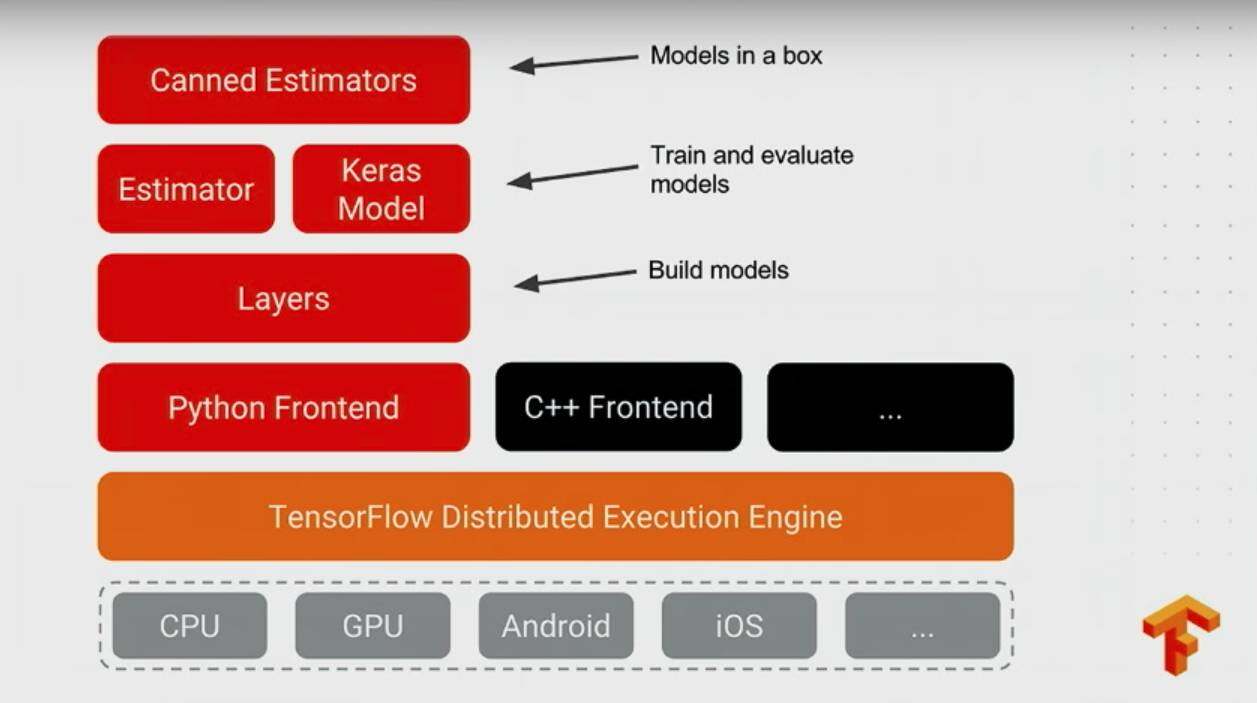
Broad ML Support
在 TensorFlow 中有一些高兴的机器学习的算法实现,如 LR, SVM、 Random Forest,在 TF.Learn 中有很多常用的机器学习算法的实现,用户可以很快的使用,而且 API 风格和 scikit-learn 很类似,而且在后续的 video 提到会有分布式的支持。
XLA: An Experimental TensorFlow Compiler
TensorFlow XLA 能够快速地将 TensorFlow 转成比较底层的实现(依赖 device),后面也有 talk 详细讲述了 XLA。
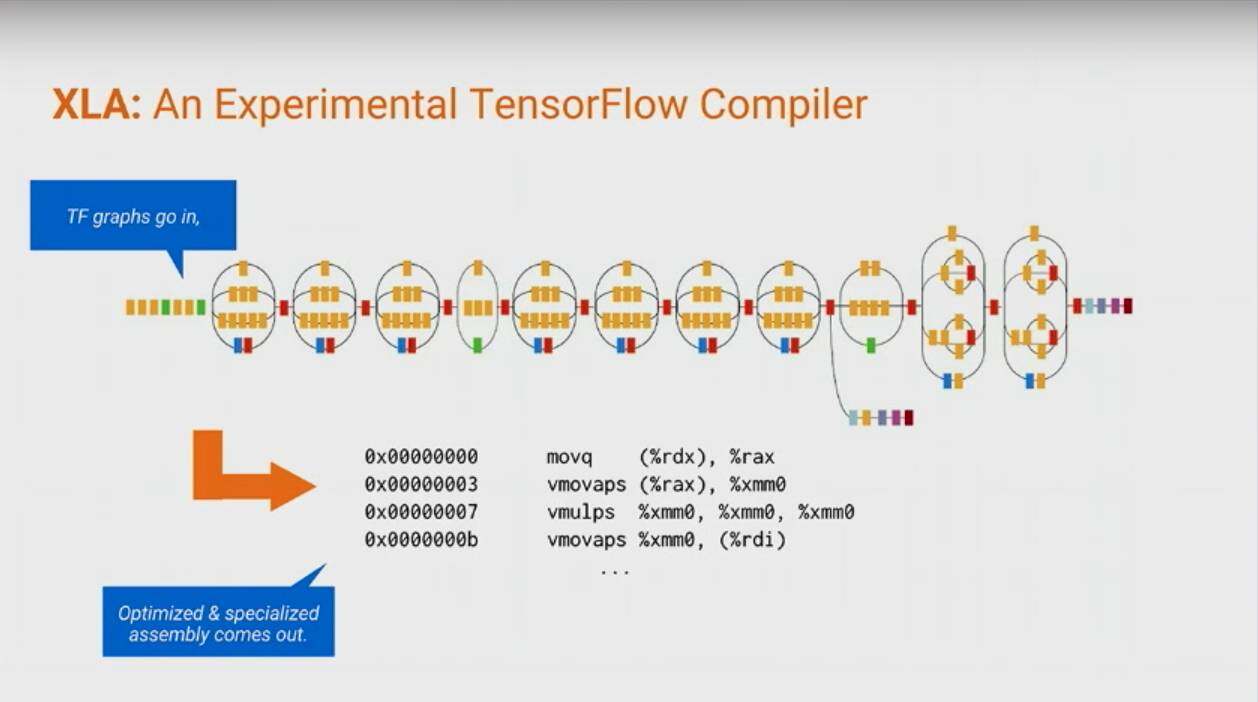
广泛的合作
- Included in IBM’s PowerAI
- Support movidus myriad 2 accelerator
- Qualcomm’s Hexagon DSP (8 倍加速,这里还请了 Qualcomm 的产品负责人来站台)
TensorFlow In Depth
TensorFlow 在 research 和 production 上有很好的优势,如下图:

在模型训练上,1 机 8 卡的性能无论是在一些标准的基准测试或者是真实数据上都有比较好的加速比:
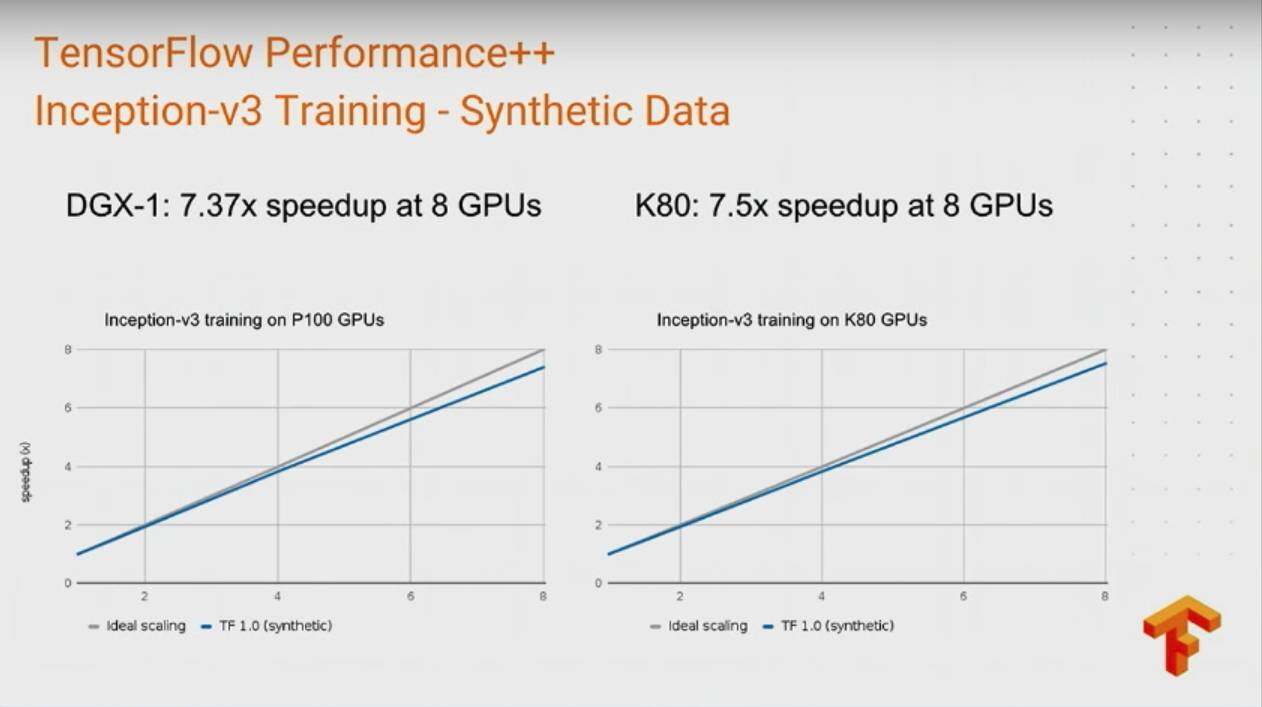
当然在多机分布式训练上,能够达到 64 张 GPU 上 58 倍的加速比: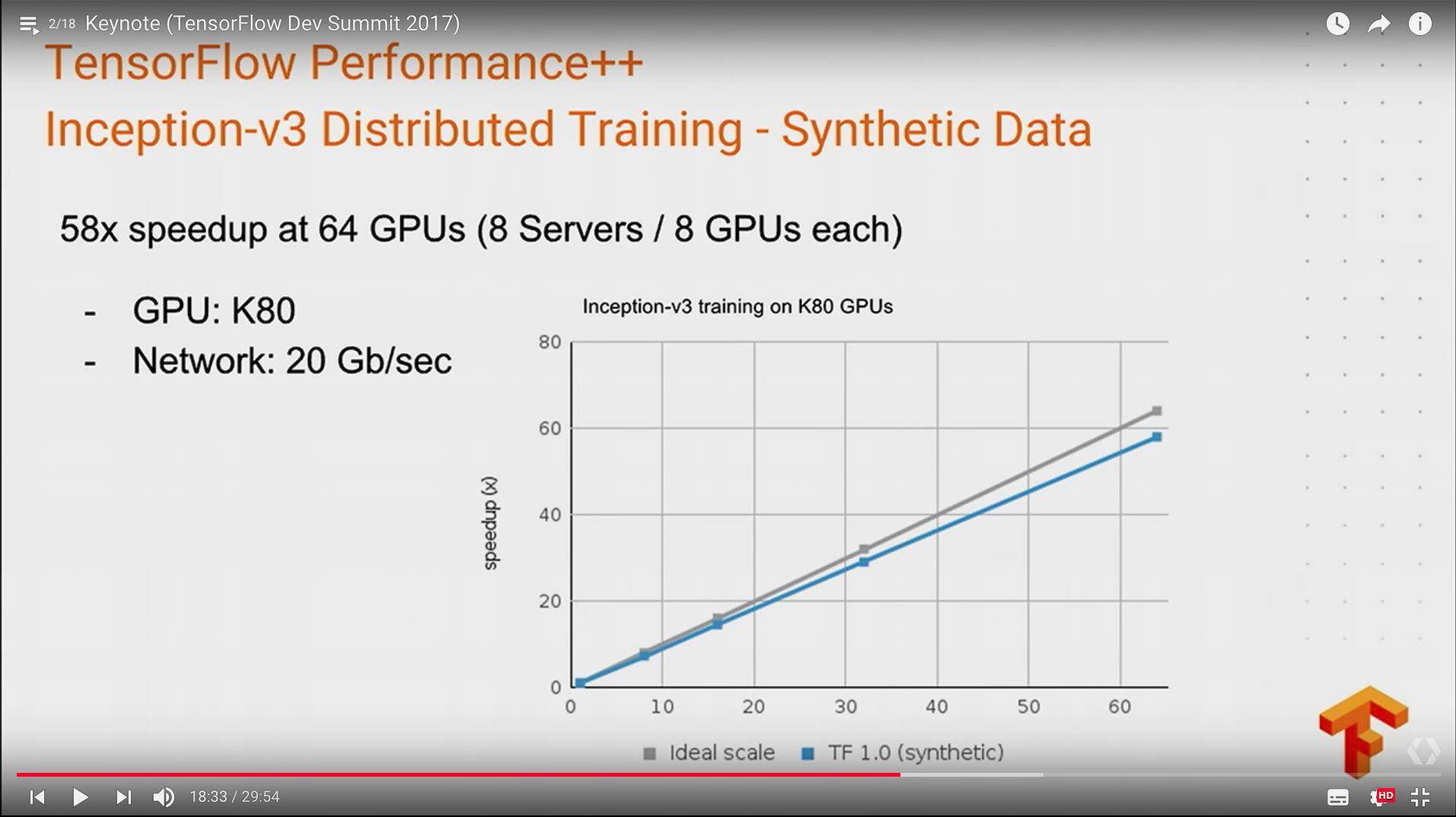
TensorFlow 被一些顶尖的学术研究项目使用:
- Neural Machine Translation
- Neural Architecture Search
- Show and Tell
当然 TensorFlow 在生产上也被广泛应用:
如 Mobile Google Translate,Gmail 等等,也被国内外很多大厂使用做为模型训练的工具。
这些都是 Jeff Dean 在 Keynote 的内容讲到的内容,内容有点多,而且个人感觉这群 google 的小伙伴的 ppt 做的有点任性,不过谁叫他们牛逼呢,接下来几个 talk 比较有技术含量,相信各位会更加有兴趣。
有趣的应用案例 皮肤癌图像分类
首先我们说下两个数据:1. 医疗机构统计皮肤癌在早期的治愈率是 98%;2. 在 2020,预计全球有 61 亿台智能手机。
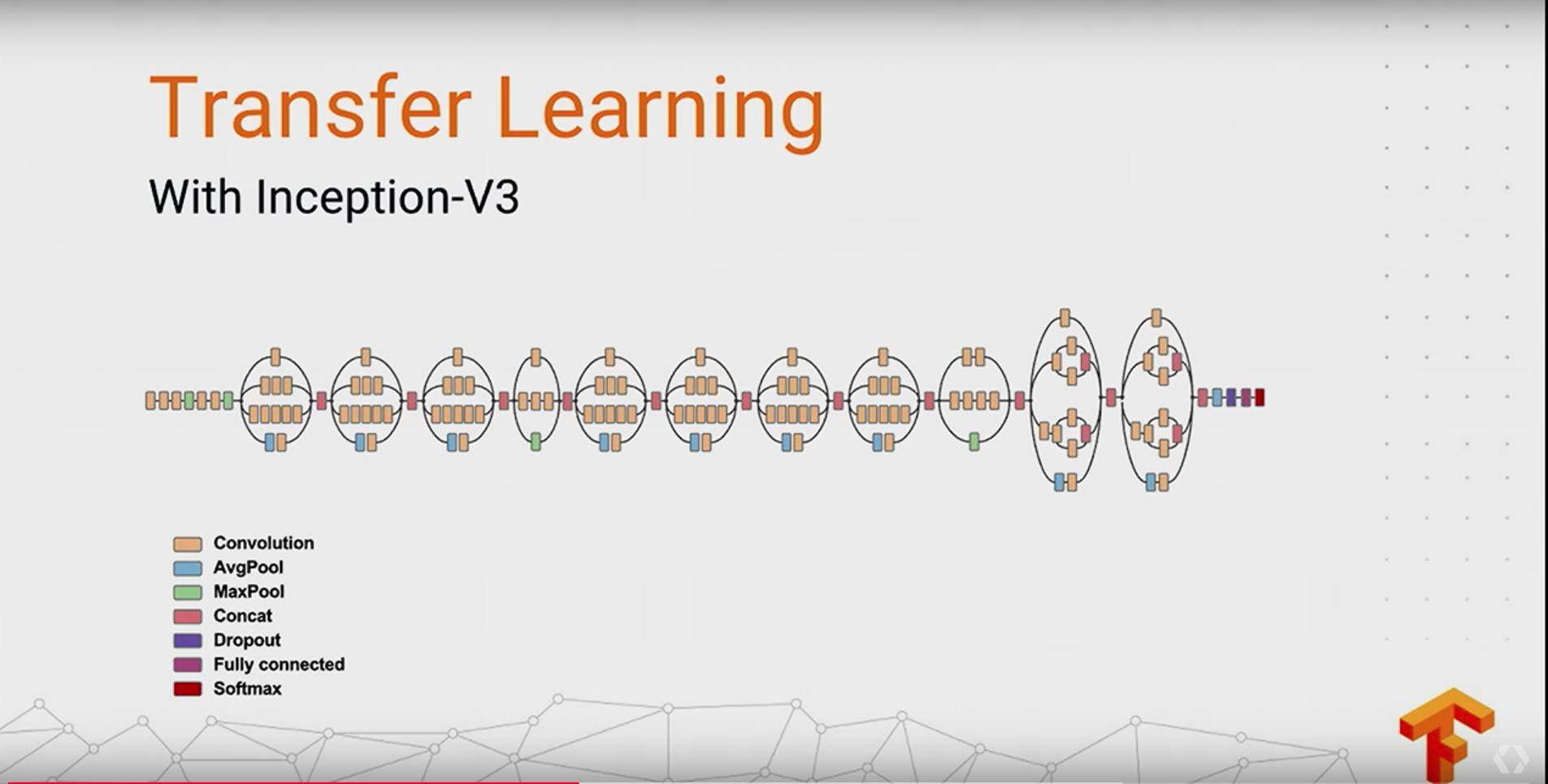
这位小哥做的工作是啥呢,他拿到了一批皮肤癌的数据,然后使用一个 pretrained 的 inception-v3 对数据来做一个 inference:
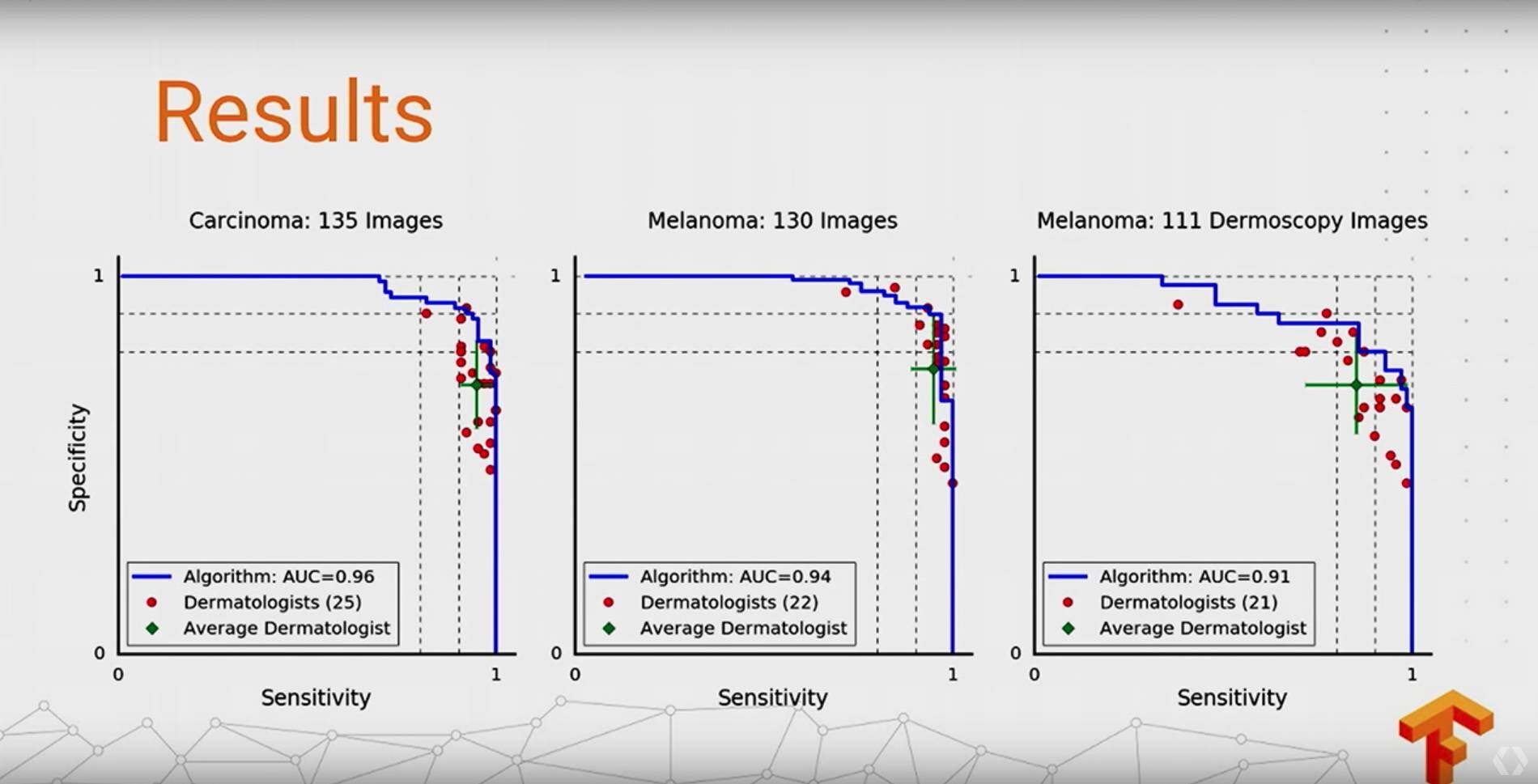
最终结果:
而且在手机上很容易搭建,完成一个 app 用来做早起皮肤癌的检测:
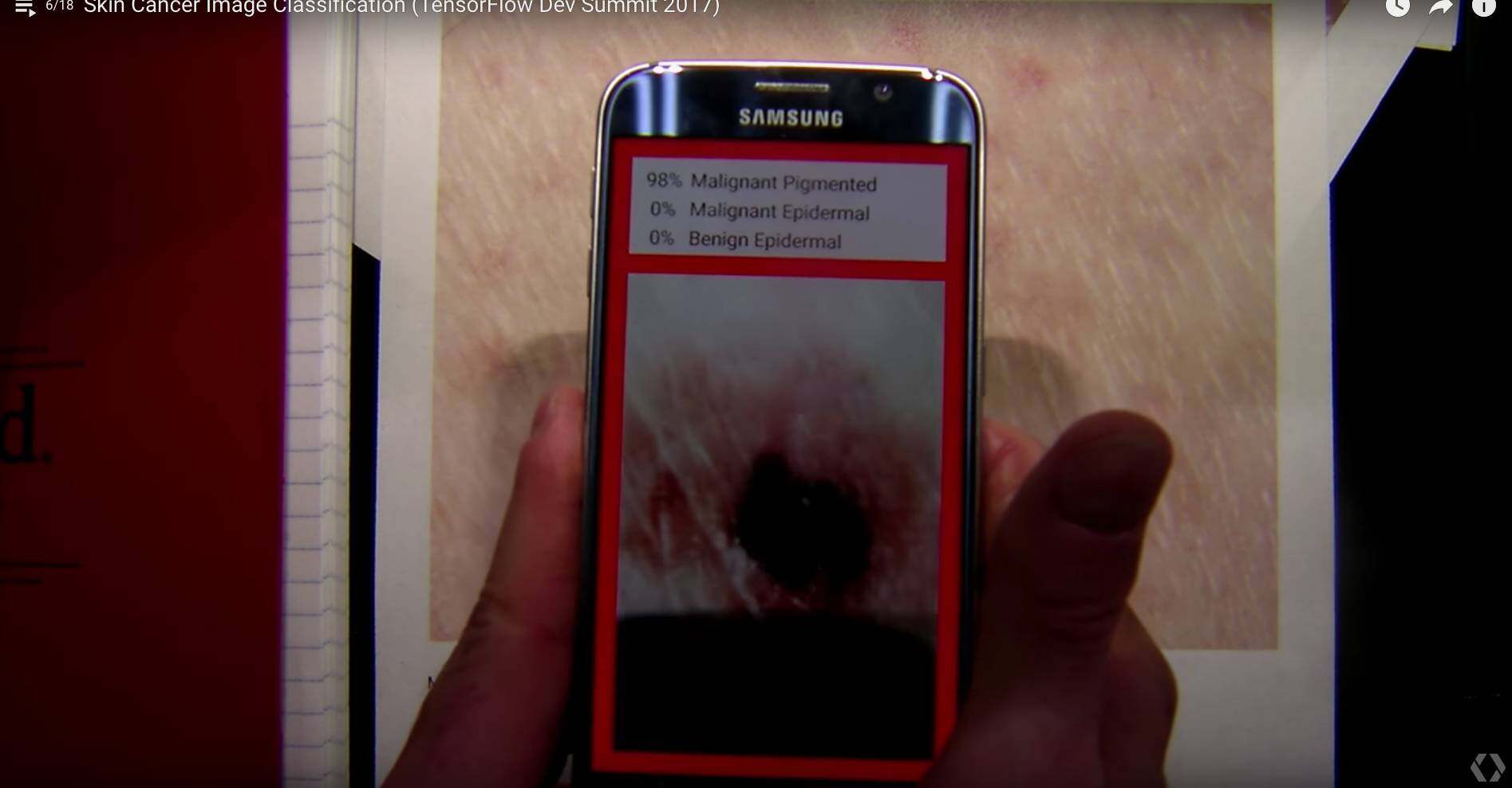
最终相关成果发表在 Nature,而且在 Nature 的封面,这是一个特别成功地通过计算机视觉及深度学习相关的技术,利用廉价的移动设备,能够很有效地检测是否有皮肤癌,大大节省了医疗检测的成本,相信在未来会有更多相关的技术出现。

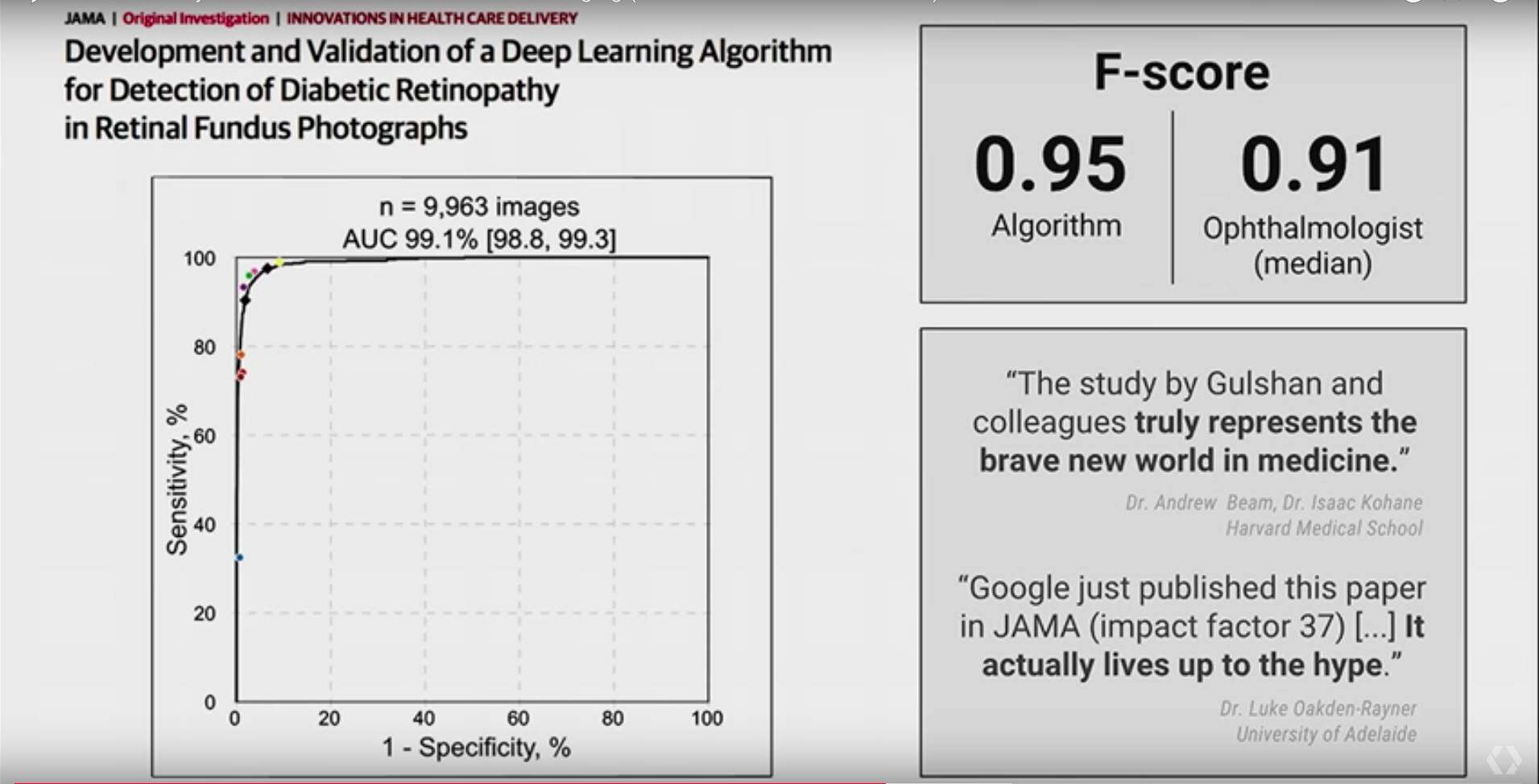
利用 AI 预测糖尿病,预防失明
这个 talk 讲的前面也提到的通过视网膜图像预测糖尿病,预防失明:
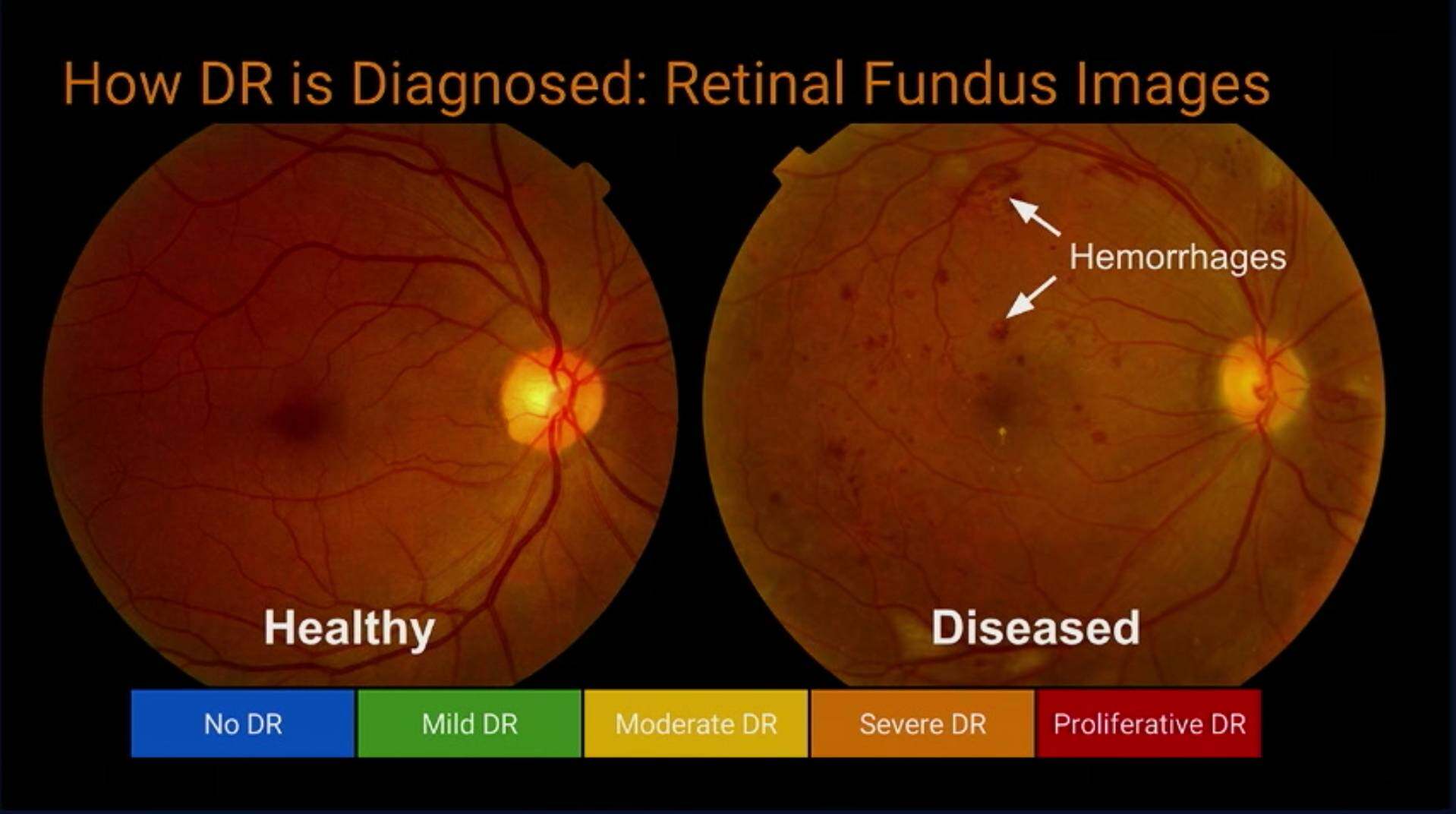
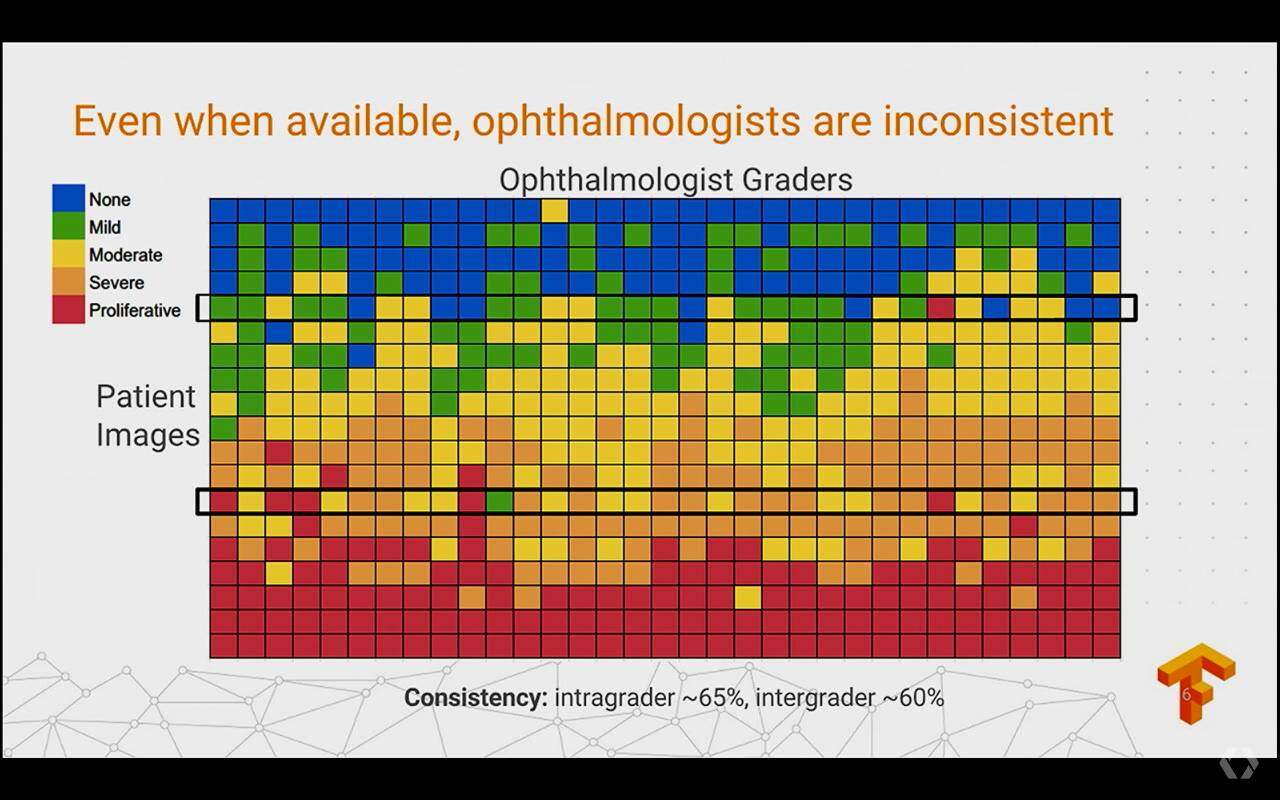
通过视网膜图片预测糖尿病是一个困难的问题,即使是专业的医生,也很难去判断,但是深度学习却可以帮助我们:
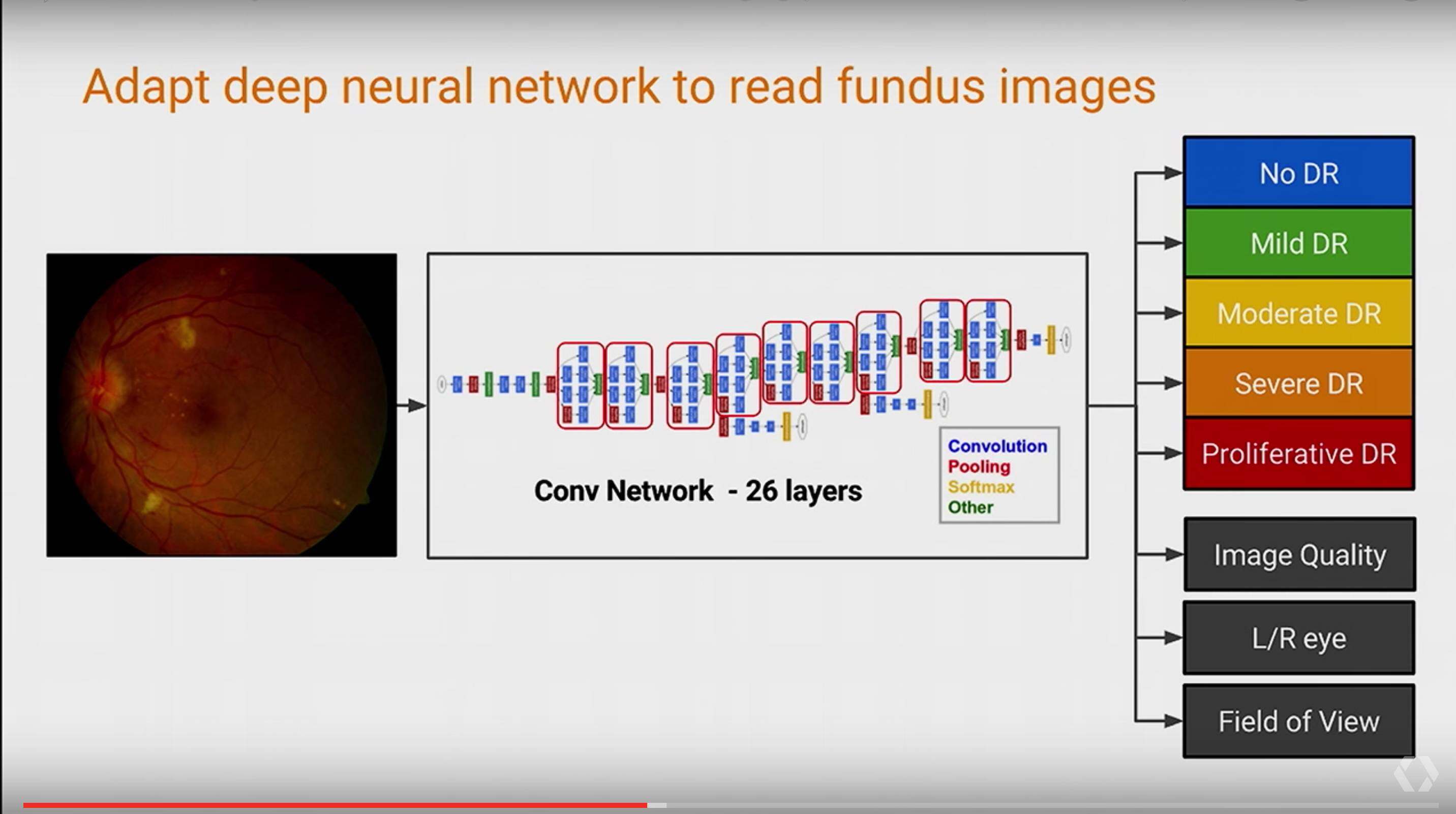
通过收集适量的医疗数据,构建一个 26layers 的深度卷积网络,我们可以让网络自动学习这些图像中的 feature,来获得较高的分类准确率,而这个是人眼很难解决的。
这里有一个 demo 的演示:
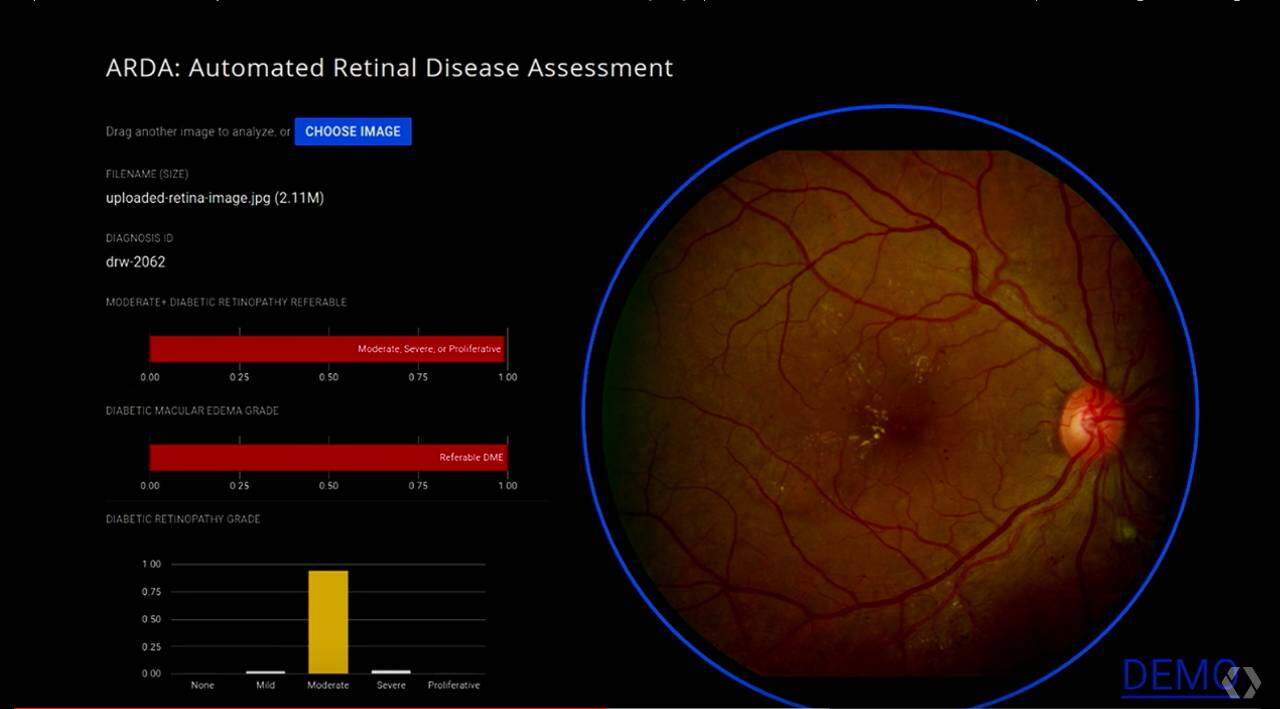
模型最后的评估比专业医生对比,F-score 为 0.95,比专业医生的中位数 0.91 还高,这个太厉害了,相信不久会看到深度学习在医疗,尤其是这种病症图像分析上有很多惊人的成果。
Wide & Deep In Google Play
这项技术有段时间特别火,被用来做推荐相关的应用,首先解释下 Memorization 和 Generalization:

模型的基本结构如下:
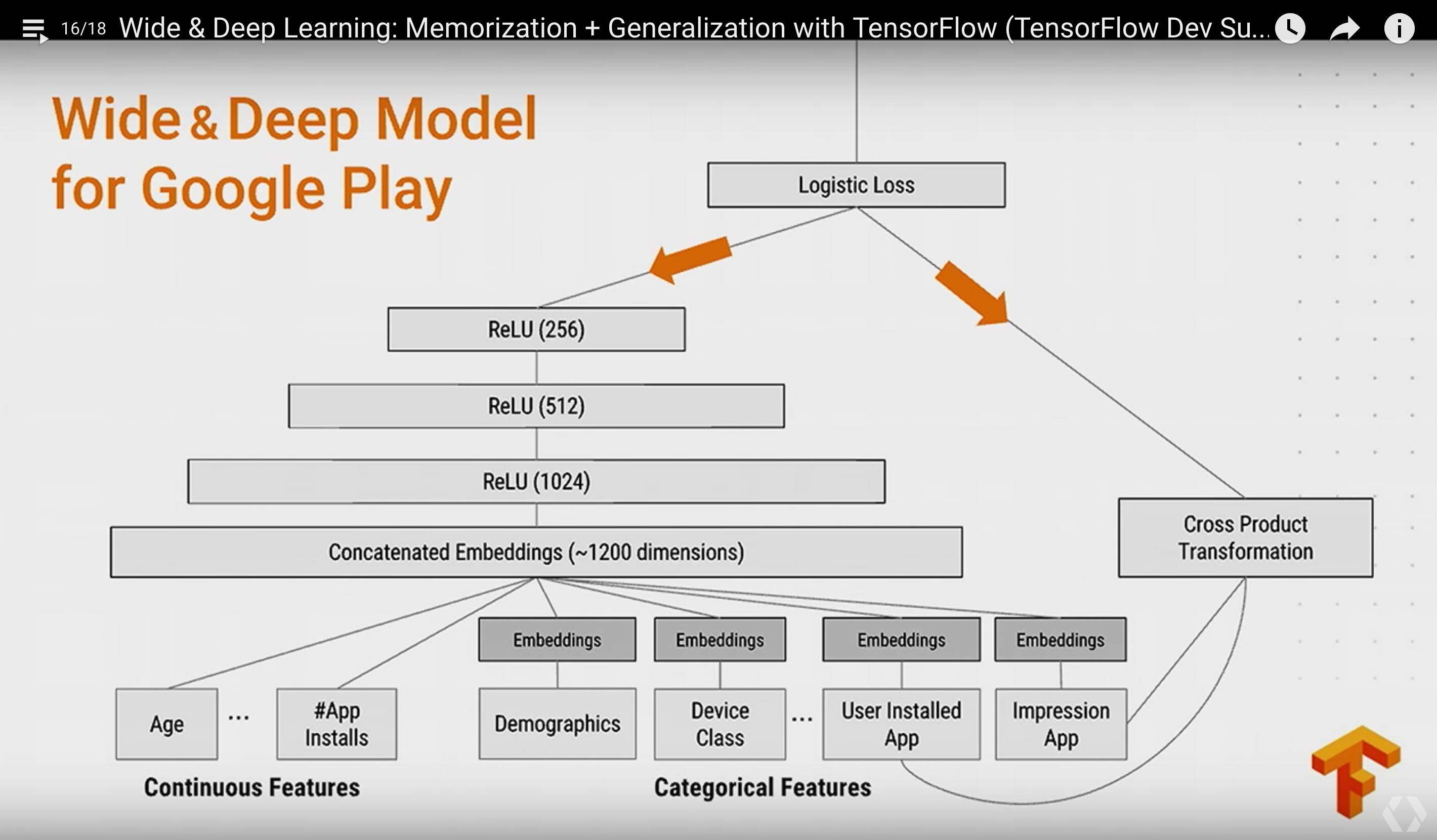
整个推荐会同事考虑到商品的相关性以及一些推理关系,例如老鹰会飞、麻雀会飞这类逻辑属于 Memorization, 而说带翅膀的动物会飞这属于 Genralization。
在具体的应用场景,如 Google Play 的 App 推荐:
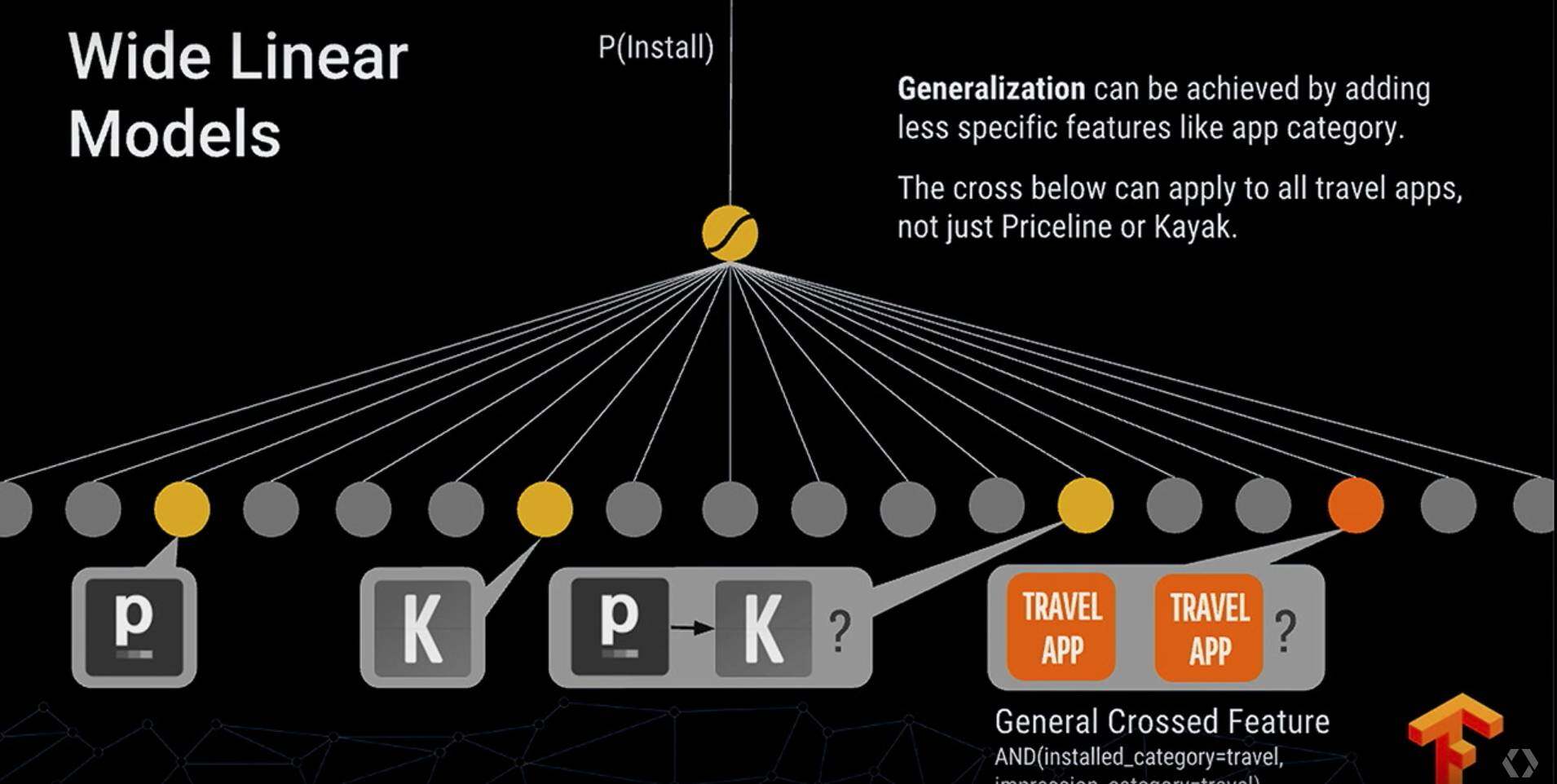
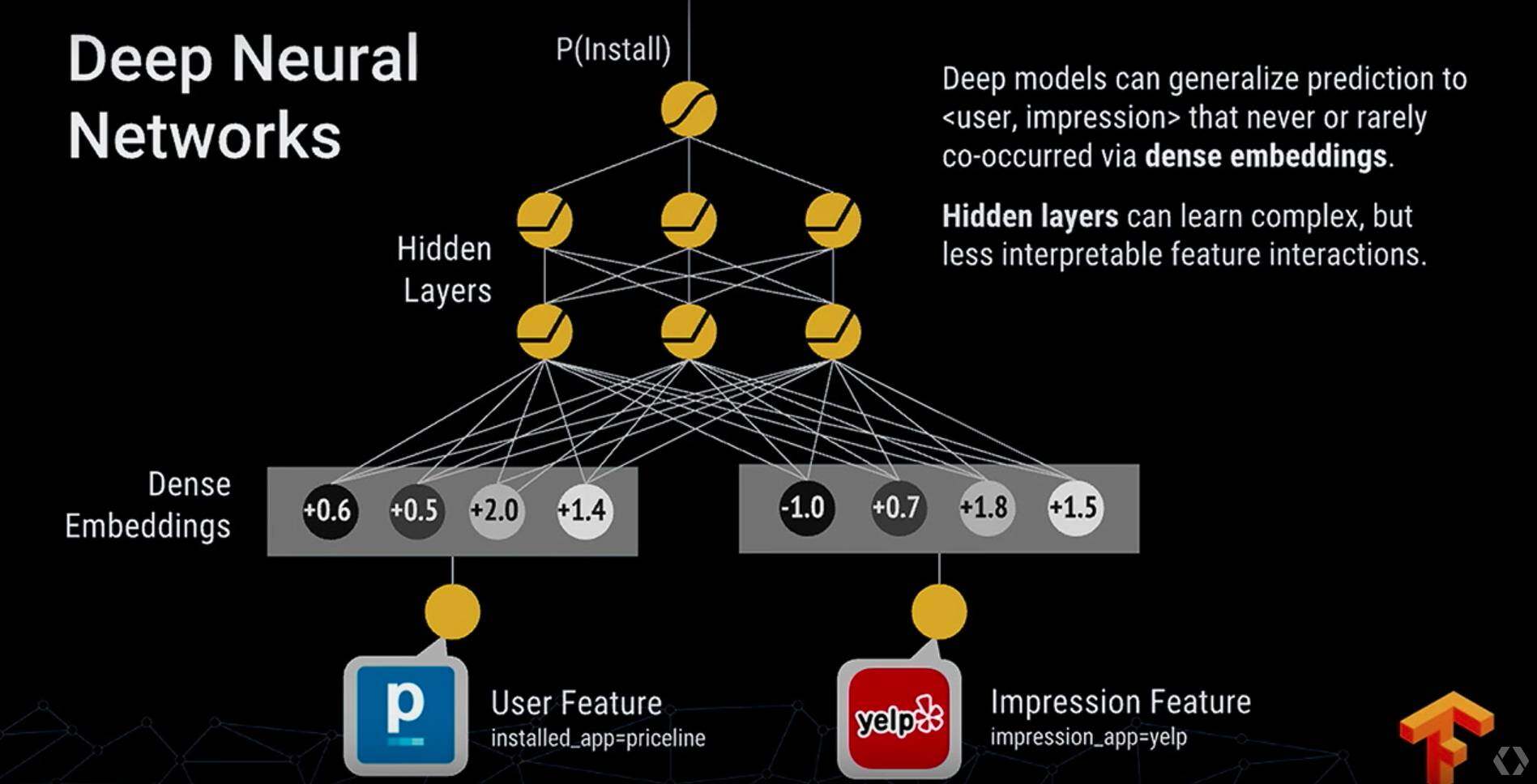
这里构建一个如下图的网络来进行训练 (joint training):
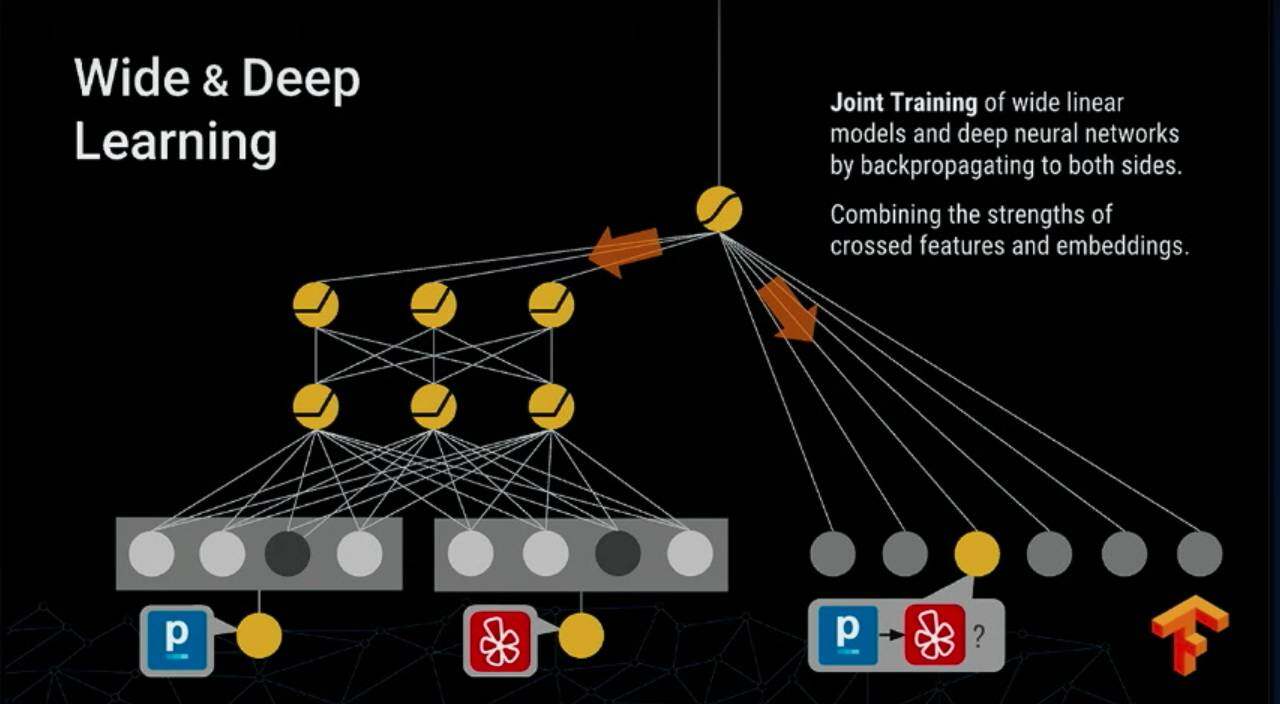
为啥要 joint training,而不是直接用 deep 和 wide 的来做 ensemble 呢?
这里做这个给出一个解释,因为 wide 和 deep 会相互影响,最后精确度会高,并且 model 会比较小:

而上面提到的 Wide & Deep Learning Model 在 Tensorflow 下仅仅只需要 10 行代码来实现 (突然想起了那个 100 美元画一条线的故事):

Magenta: 音乐和艺术生成
这个项目讲的是利用深度学习来做一些艺术相关的工作,项目地址: https://github.com/tensorflow/magenta 有一些很好玩的东西,如风格化,生成艺术家风格的音乐,利用深度学习模型模拟人类对艺术的想象力,创造出属于 DeepLearning 的艺术风格。
DeepMind 团队所做的一些开发工作
DeepMind 在被 Google 收购之后,也选择 TensorFlow 作为其深度学习相关研究的平台,然后做了很多很有意思的东西。
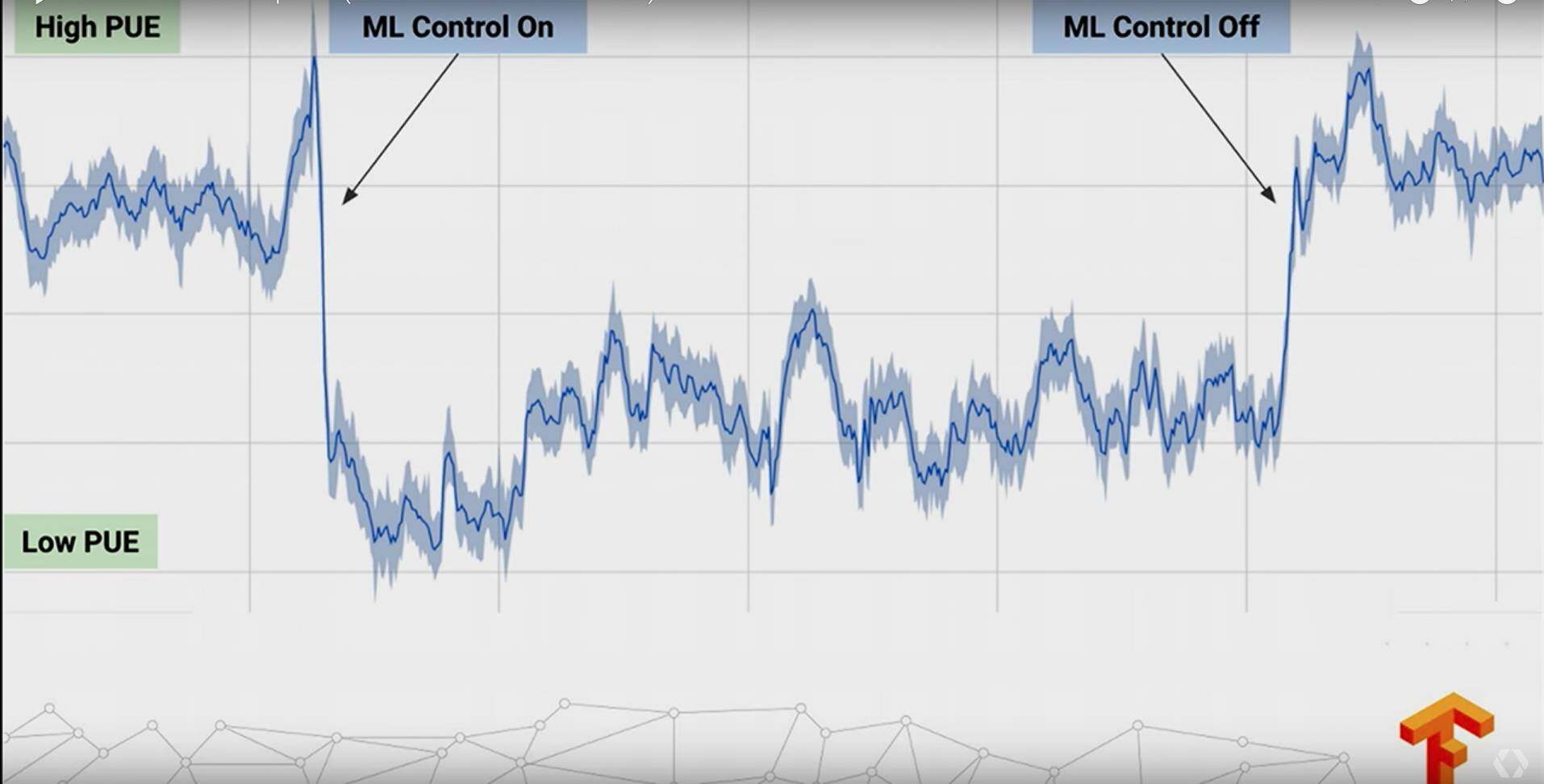
Data Center Cooling
这是 Google 在全世界各地若干个数据中心之一:

然后这群 Google 的小伙伴做了些什么事情呢?

Google 的小伙伴利用强化学习,是的!你没有听错,应用在 AlphaGo 上的一种技术来做数据中心冷却设备的自动控制, 并且效果十分显著:
Gorila
Gorial 是 DeepMind 下的一个强化学习的框架,基于 TensorFlow 的高级 API 实现,很稳定,只需要更改其中极少部分代码就可以完成新的实验,支持分布式训练,十分高效,并且训练好的模型可以通过 TensorFlow Serving 快速地部署到生产环境。
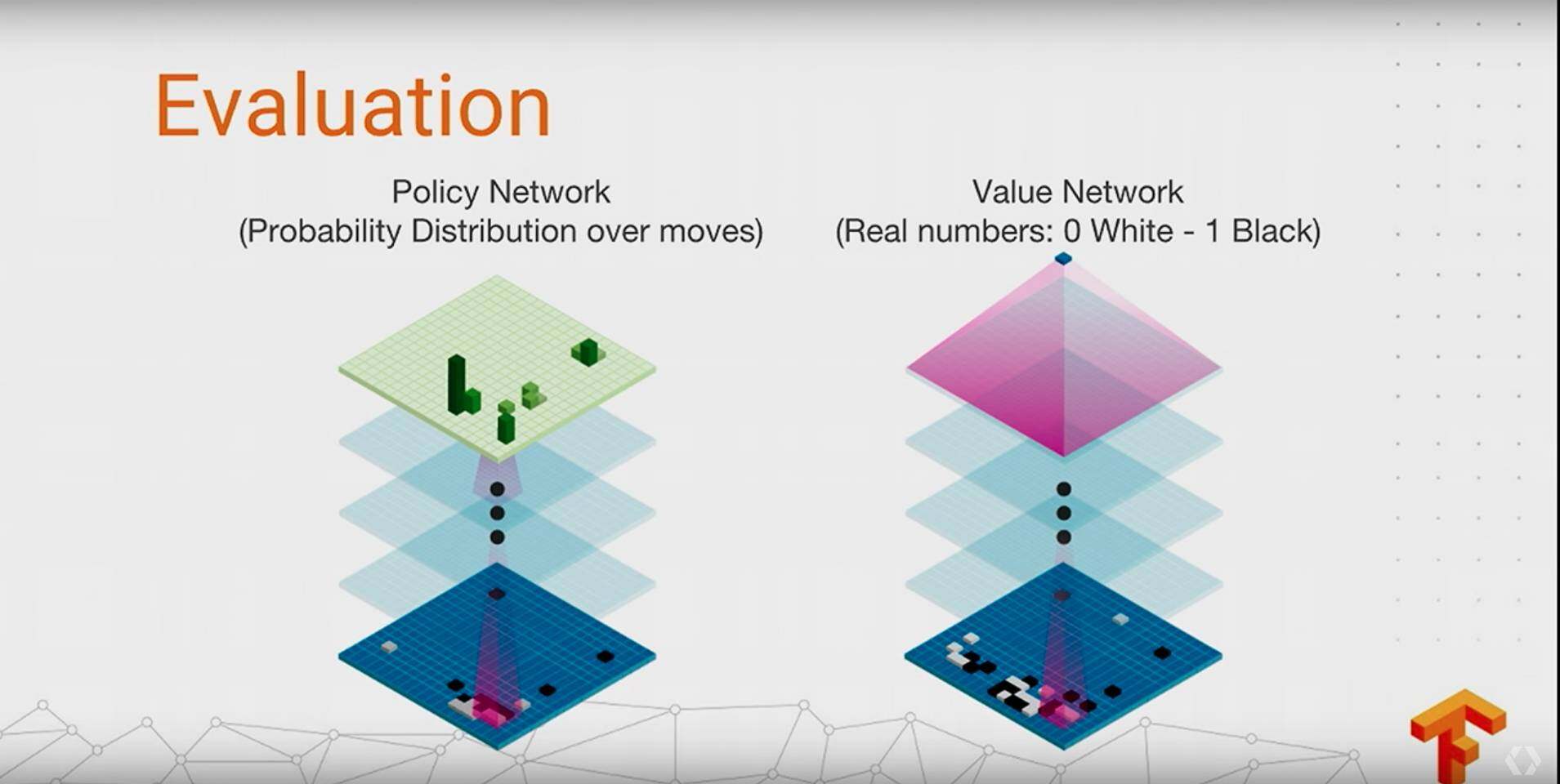
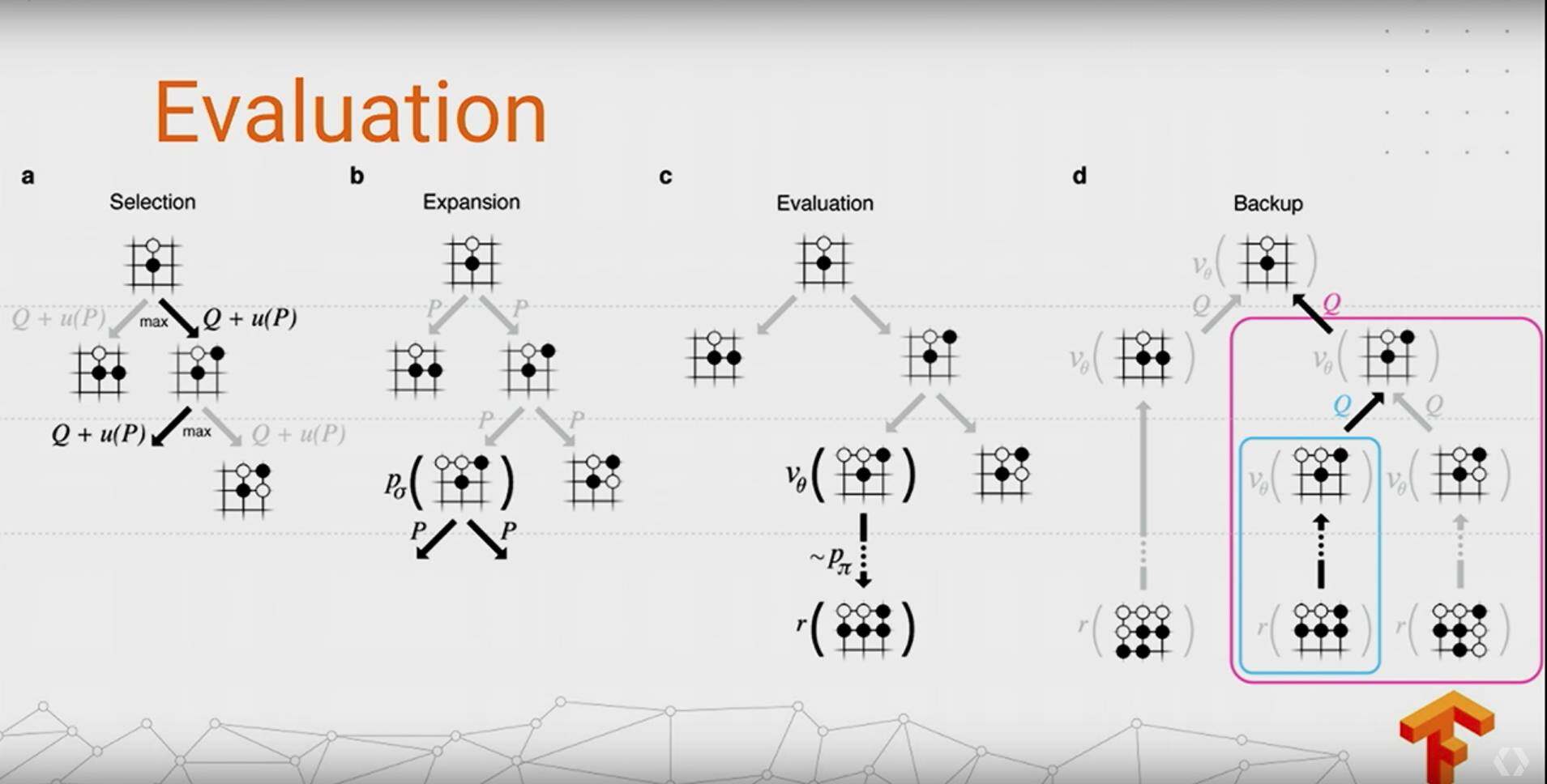
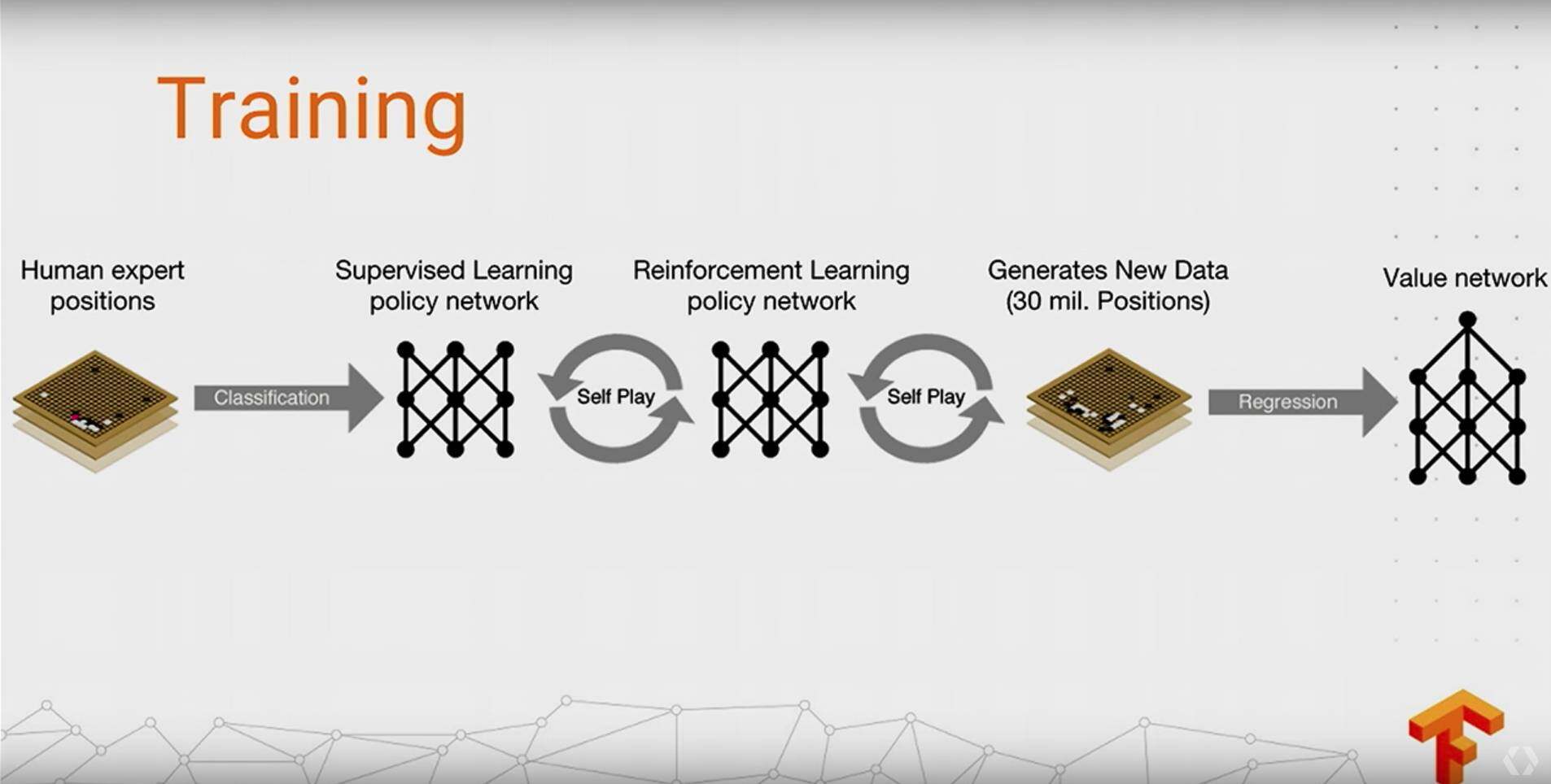
AlphaGo
这个相信不说,大家都知道的,第一次在围棋上打败人类,然后升级版的 Master 连续 60 盘不败,原理不说了,网络上很多分析文章,贴两张图聊表敬意:

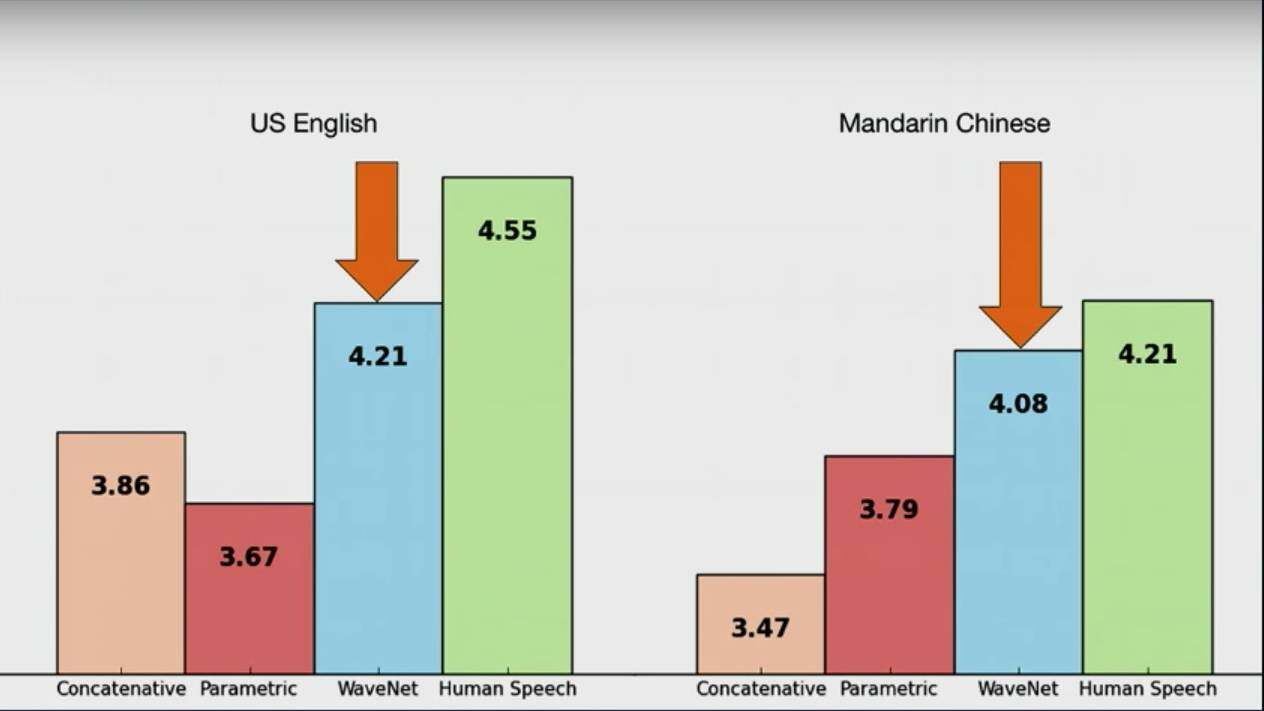
WaveNet:语音音频合成
这里 DeepMind 的小哥演示了 WaveNet 的一些 demo, 具体的可以参见 ( https://deepmind.com/blog/wavenet-generative-model-raw-audio/) 来了解。贴一些效果对比:
XLA 以及 Keras 与 TensorFlow 的融合 XLA 与 TensorFlow 的结合
TensorFlow 的各方面的优势都很突出,除了在速度这块有些不足,如果,TensorFlow 能在速度上做进一步优化,会怎么样呢 ?
 是的,Google 的开发者也意识到这个问题,于是有了这个 XLA, XLA 的优势:
是的,Google 的开发者也意识到这个问题,于是有了这个 XLA, XLA 的优势:
- 提高执行速度,编译子图会减少生命周期较短的 op 的时间,来至少 TensorFlow 执行是的时间;融合 pipelined 的 op 来减少内存的开销;
- 通过分析和调节内存需求,来减少很多中间结果的缓存;
- 减少定制化 op 的依赖,通过提供自动化融合底层 ops 的性能来达到原先需要手工去融合定制化 op 的性能;
- 减少移动设备的内存占用,使用 AOT 编译子图来减少 tensorflow 执行时间,能够共享 object/header file pair 给其他应用,能够在 Mobile Inference 上减少几个数量级的内存占用;
- 提高了程序的可移植性,能够在不改变大部分 tensorflow 源码的前提下,很容易地更改以适应新的硬件设备,
XLA 主要包括两种使用方式:JIT(Just in time) 能够自动将 Graph 中的部分子图通过 XLA 融合某些操作来减少内存需求提高执行速度;AOT(Ahead of time) 可以提前将 Graph 转换为可以执行的源码,减少生成的可执行文件的大小,减少运行的时间消耗,一个很明显的应用场景是模型在移动设备上的 Inference 优化。
因为 XLA 原理涉及到编译器,这块不是我擅长的地方,所以这里就这样过了, 如果有兴趣的小伙伴可以关注下 ( https://www.tensorflow.org/versions/master/experimental/xla/) 还有此次 TensorFlow Dev Submit 上 XLA 的 talk( https://www.youtube.com/watch?v=kAOanJczHA0&index=2&list=PLOU2XLYxmsIKGc_NBoIhTn2Qhraji53cv#t=108.706756 )
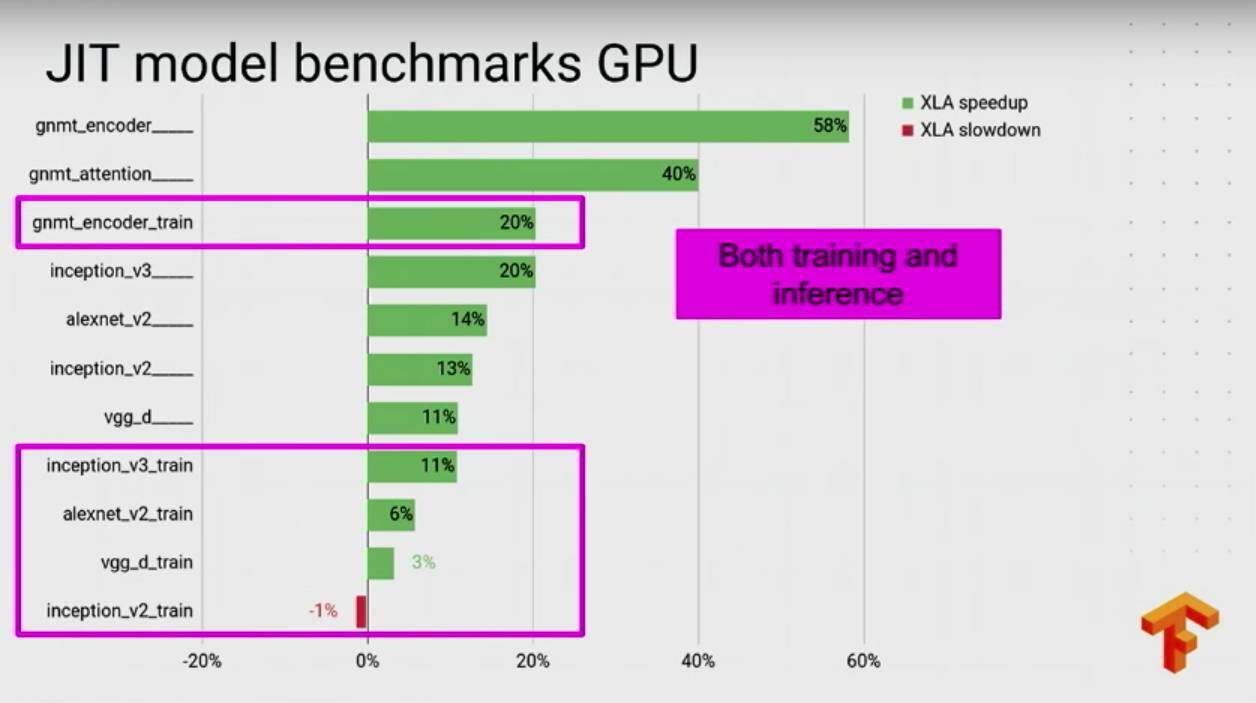
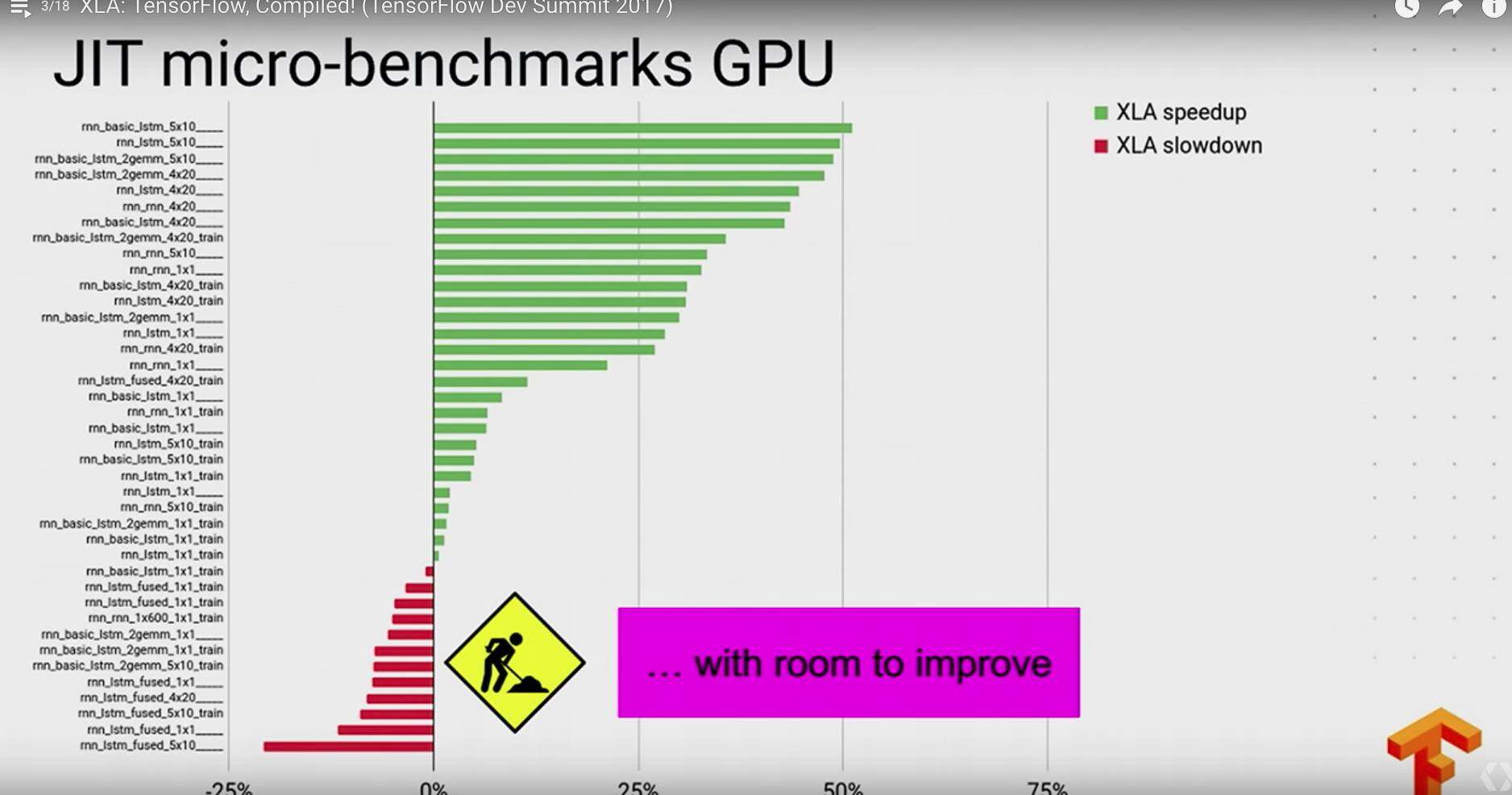
最后贴几张 XLA 的一些评测性能:
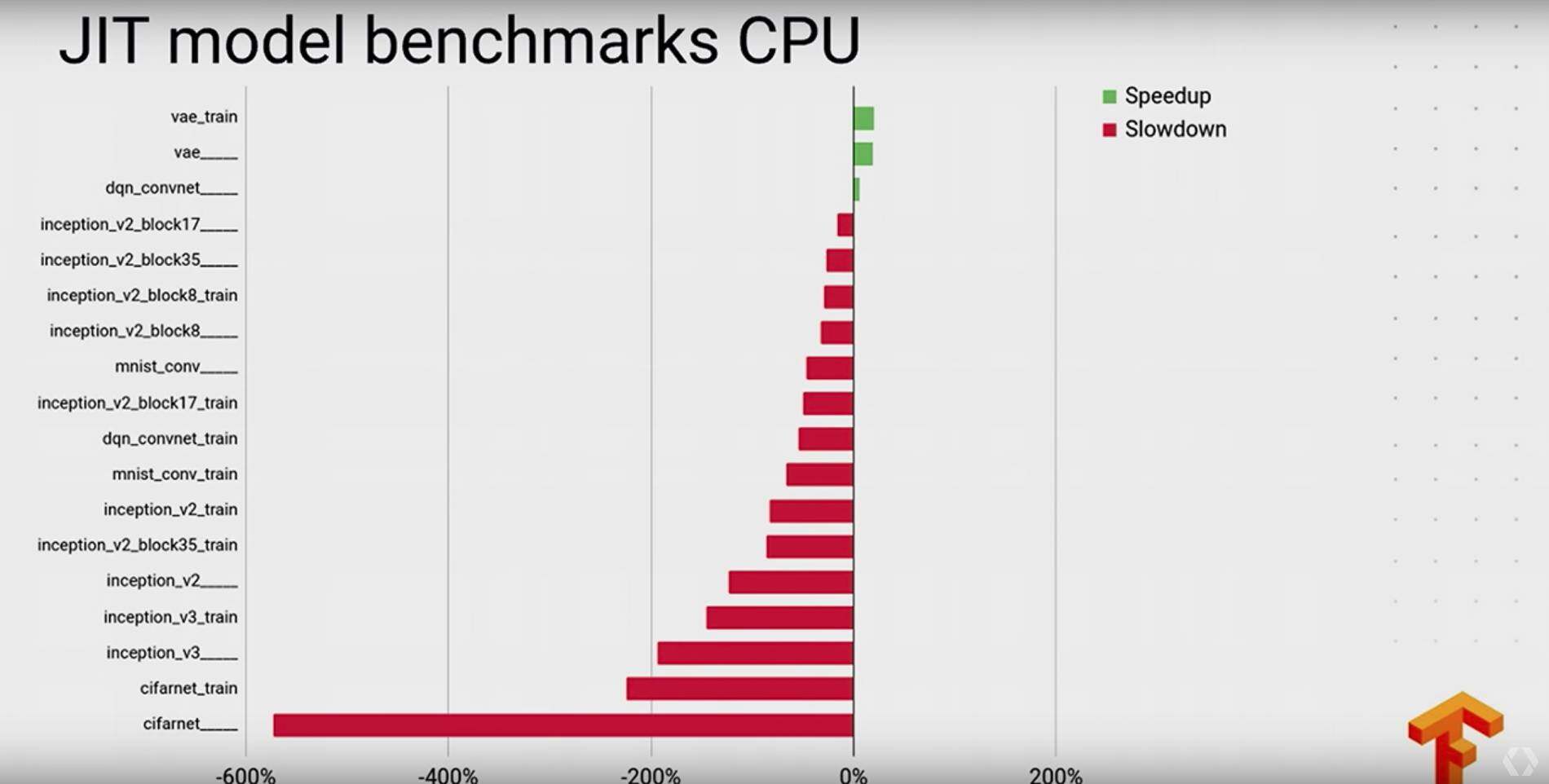
Keras 与 TensorFlow 的集成
Keras 是一个可以在很多平台上应用的深度学习框架,“An API Specify for building deep learning models across many platforms”。
TensorFlow 已经会在官方 TensorFlow 支持,1.1 会在 tf.contrib,1.2 会 tf.keras,而且会支持 TensorFlow Serving,是不是很心动。
Keras 的作者在 TensorFlow Dev Submit 上讲了以下内容:

所以之后 Keras 的用户可以更快的在 TensorFlow 的框架下做出相应地模型,能更方便地进行分布式训练,使用 Google 的 Cloud ML, 进行超参,还有更更重要的:TF-Serving。这些 feature 现在好像还没有支持,不过应该很快了,大家可以期待下。
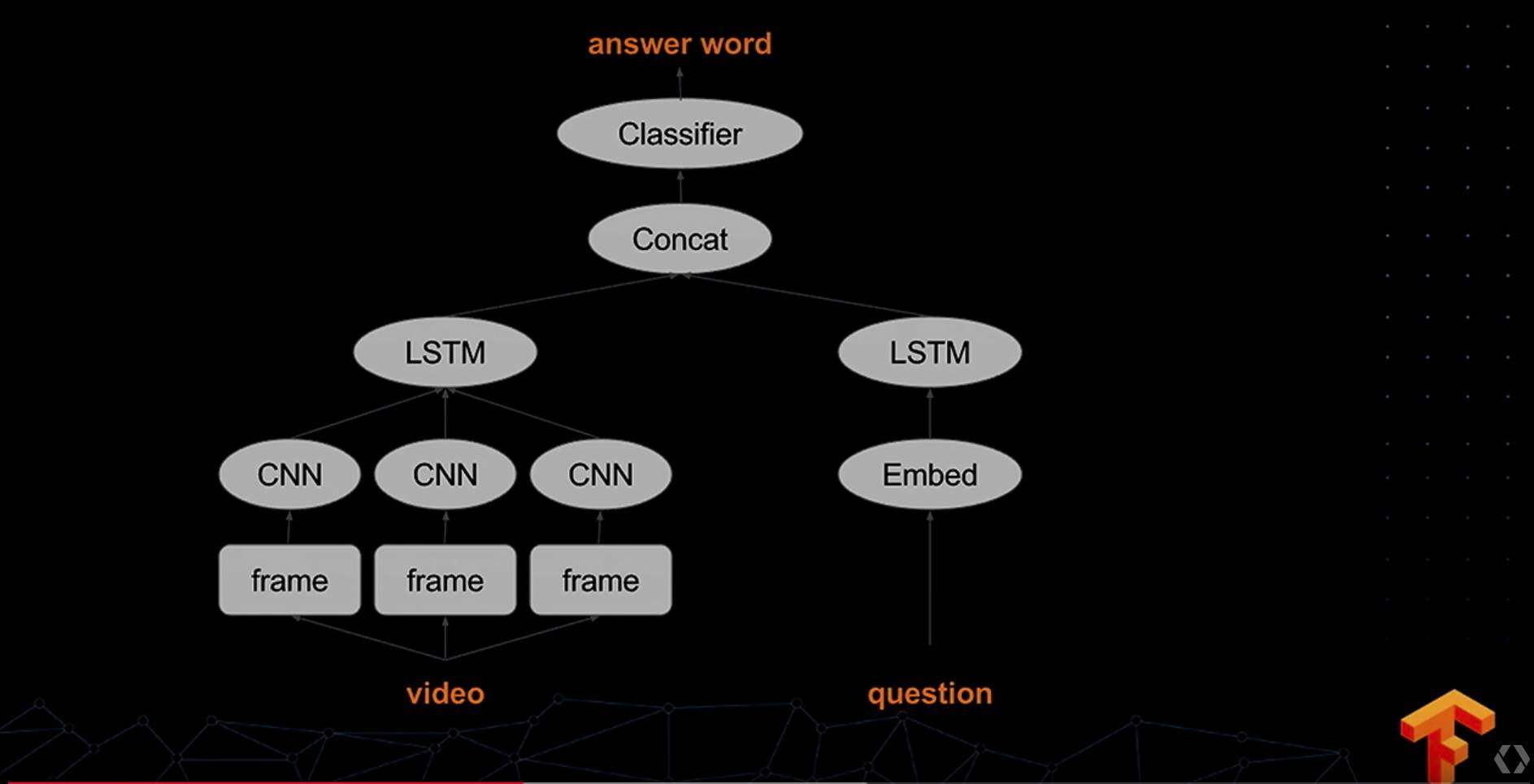
这里,Francois Chollet 使用 Keras 构造了一个 Video-QA 的 model,这个模型在 Keras 的官方文档也有描述,具体可以去那边看看,大概是这样一个场景:

这样一个场景,利用原生的 python 构造太难了,但是用 Keras,只需要考虑设计你的模型,如何来完成类似的功能,完全不用担心 coding 的实现,如图是一个类似问题的一个简单地模型设计:
更详细一点:
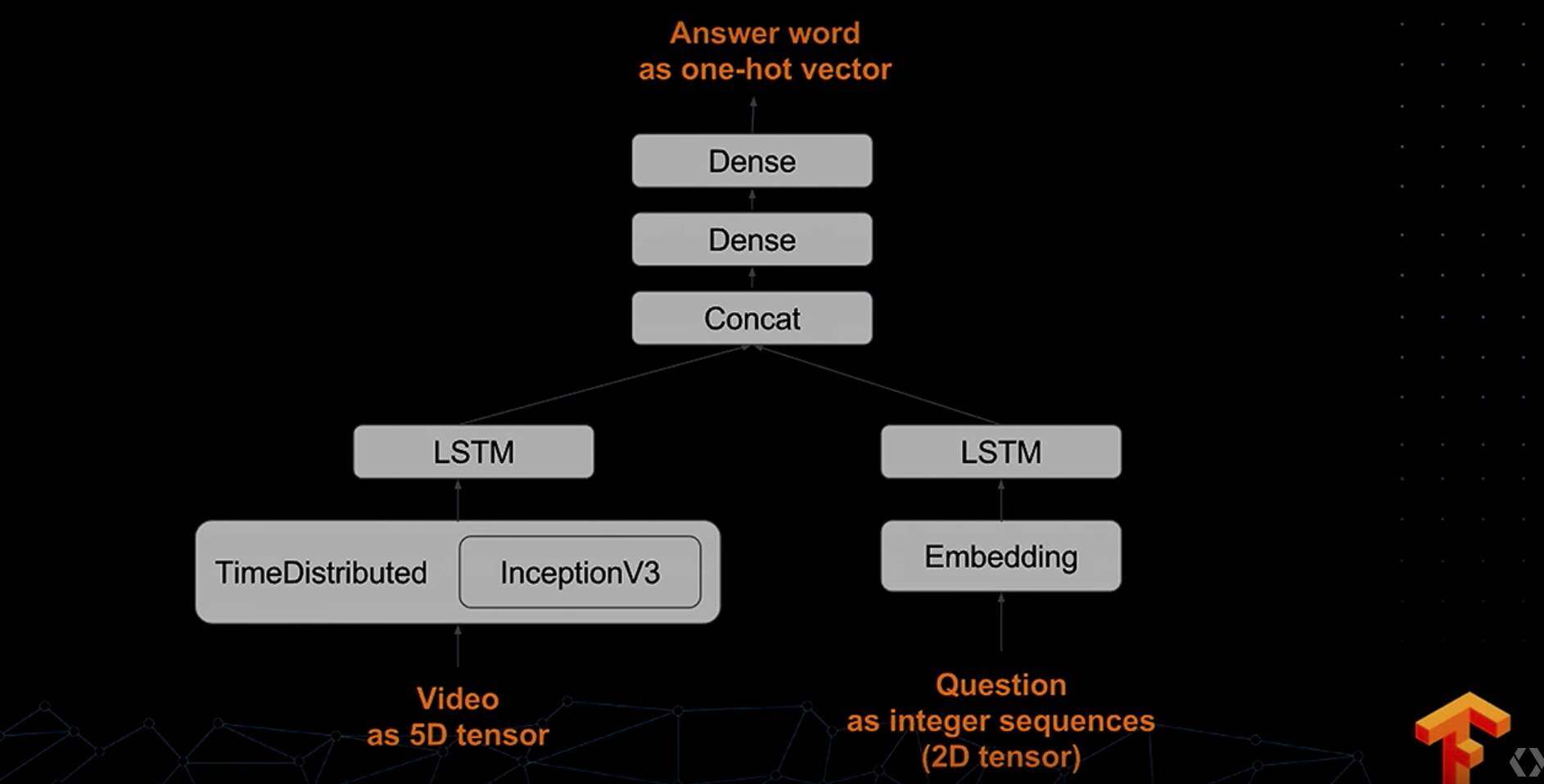
而在 Keras 中如何实现呢?
video = tf.keras.layers.Input(shape=(None, 150, 150, 3))
cnn = tf.keras.applications.InceptionV3(weights='imagenet', include_top=False, pool='avg)
cnn.trainable = False
encoded_frames = tf.keras.layers.TimeDistributed(cnn)(video)
encoded_vid = tf.layers.LSTM(256)(encode_frames)
question = tf.keras.layers.Input(shape=(100), dtype='int32')
x = tf.keras.layers.Embedding(10000, 256, mask_zero=True)(question)
encoded_q = tf.keras.layers.LSTM(128)(x)
x = tf.keras.layers.concat([encoded_vid, encoded_q])
x = tf.keras.layers.Dense(128, activation=tf.nn.relu)(x)
outputs = tf.keras.layers.Dense(1000)(x)
model = tf.keras.models.Mode([video, question], outputs)
model.compile(optimizer=tf.AdamOptimizer(), loss=tf.softmax_crossentropy_with_logits)
这里代码是无法在现在的 tensorflow 版本上跑的,如果想了解下 keras 上构建上述模型的简便性, 可以看看 Keras 的文档 ( https://keras.io/getting-started/functional-api-guide/)。Keras 在构造深度模型的方便是大家众所周知的,值得期待之后 Keras 在 TensorFlow 的更新:

TensorFlow High-Level APIs: Models in a Box
TensorFlow 在灵活性、可扩展性、可维护性上做的很好,但是现在在高级 api、模块式算法这块原先都还不足,但是 Google Brain 的工程师在这个 talk 上介绍了一些 High-level API 的相关工作。
- layers: 封装了一些层的操作,简化用原生 TensorFlow 源码,比如 new 一个 variable 来做 weight 等等;
- Estimator or Keras: 封装了一些更高层的操作包括,train 和 evaluate 操作,用户可以通过几行代码来快速构建训练和评估过程;
- Canned Estimators: 更高级 API,所谓的 Models in a box
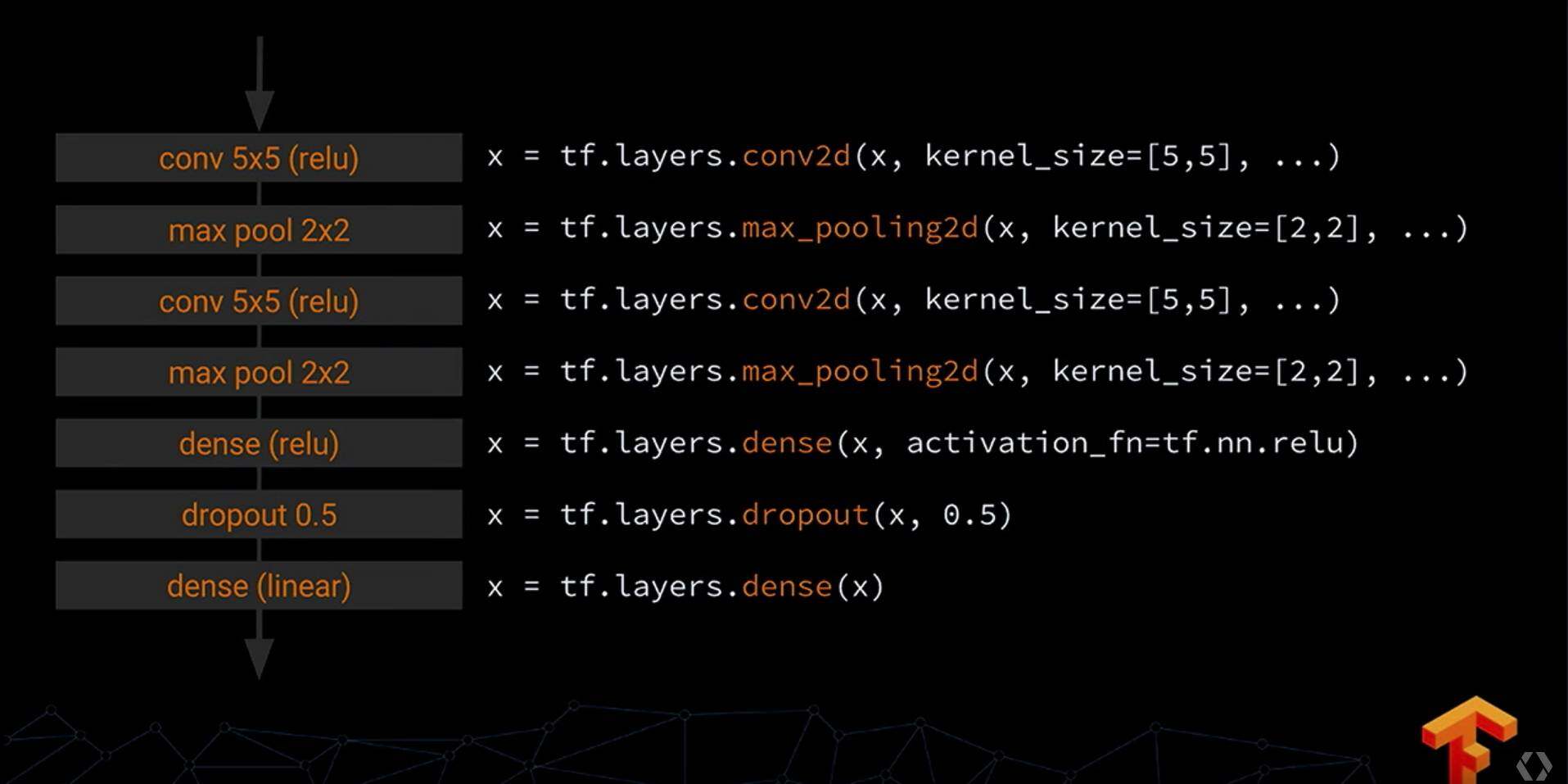
构造左图中所示的深度网络只需要如图右中的七行代码同样,构建训练、评估、预测也很快可以通过 api 调用完成:
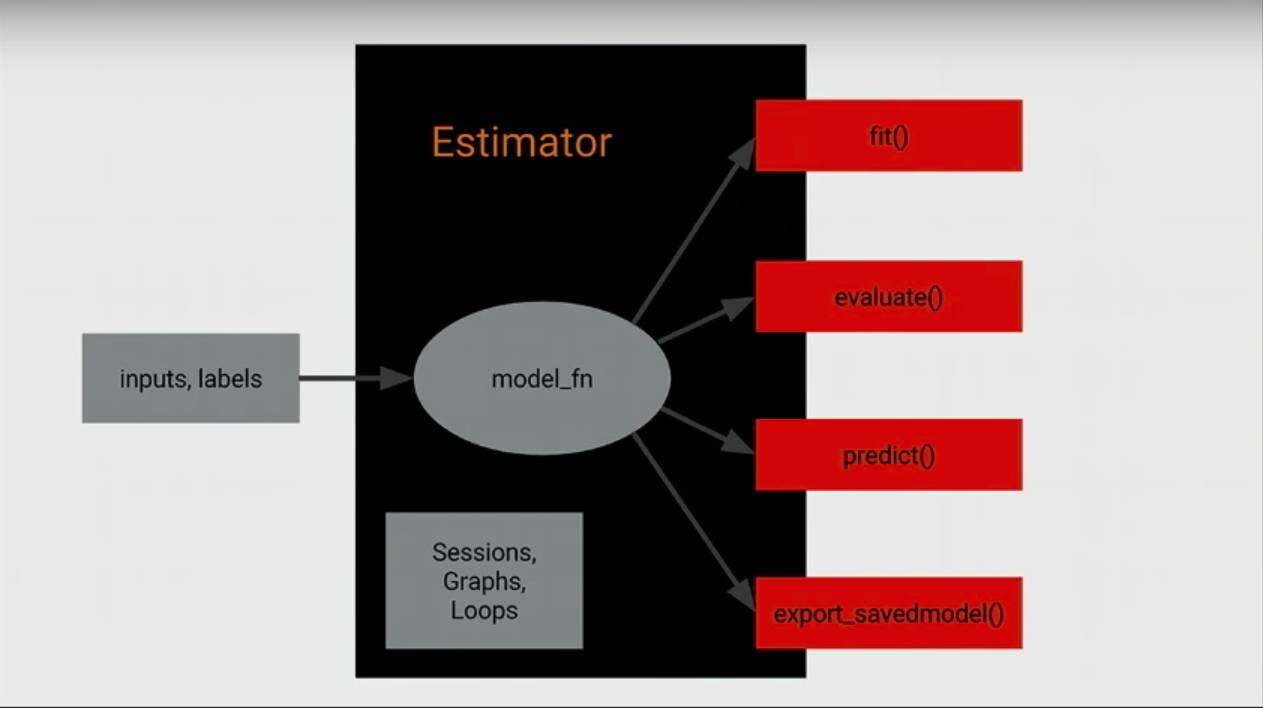
最后是 Model in a Box
area = real_valued_column("square_foot")
rooms = real_valued_column("num_rooms")
zip_code = sparse_column_with_integerized_feature("zip_code", 100000)
regressor = LinearRegressor(feature_columns=[area, room, zip_code])
classifier.fit(train_input_fn)
classifier.evaluate(eval_input_fn)
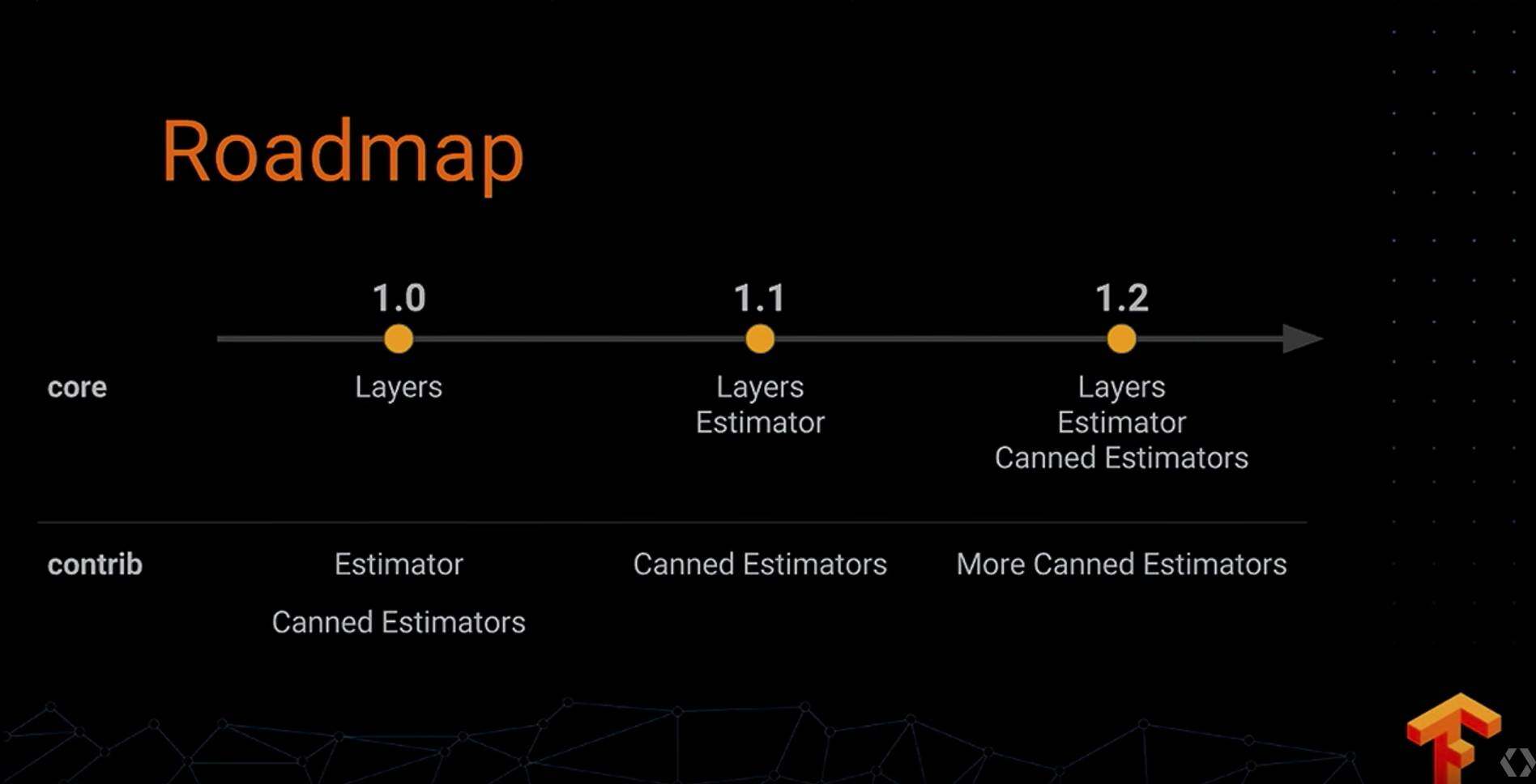
一些其他技术以及生态 ML Toolkit
TensorFlow 可能最开始被人知晓,就是因为大家都觉得他是一个深度学习的框架,其实不是,现在 TensorFlow 上还有很多机器学习的算法集成:

而且算法 API 的开发都是仿照 scikit-learn 的风格,有 Python 下做机器学习的小伙伴,可以很快的适应。
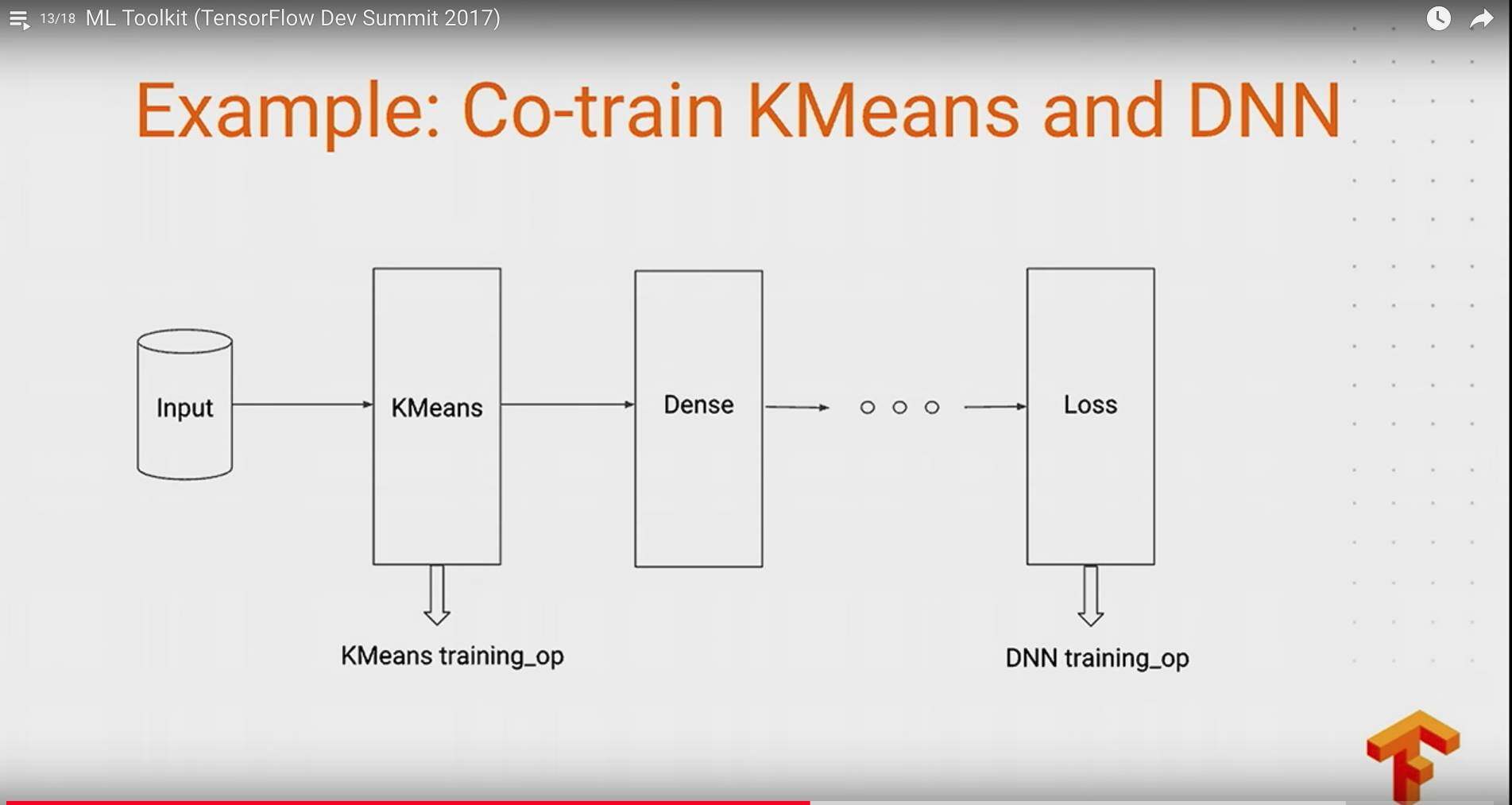
这里值得提出的,有趣 TensorFlow 对机器学习和深度学习模型的支持,小伙伴们可以特别容易地结合传统的机器学习方法和深度学习模型来一起训练:
分布式 TensorFlow
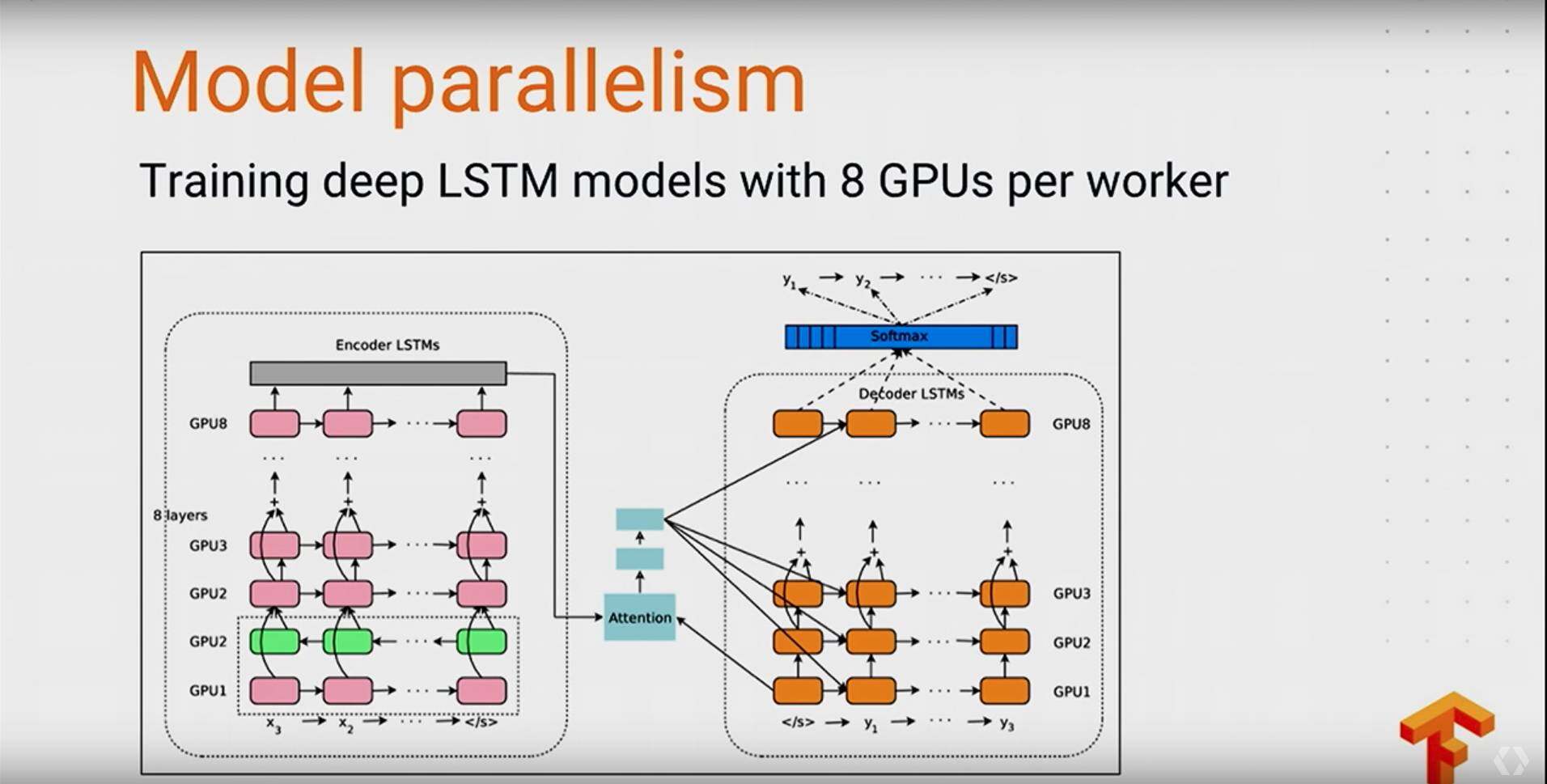
TensorFlow 在分布式性能上,前面也提到了,在 1.0 版本上有了很大的提升可以做到 64 块 GPU 上达到 58 倍的加速,这里先基本介绍下数据并行和模型并行:
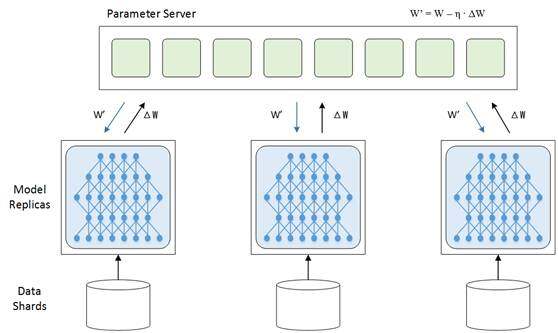
- 数据并行 每一个 worker 上有完整的模型,部分数据,参数的更新传给 Params Server;
- 模型并行 每一个 worker 上有部分的网络模型 ;
怎么在 TensorFlow 写分布式代码,这里我就不说了,很简单地配置,这里我讲下,可能大部分像我这样的小伙伴之前不太了解的一些彩蛋。在 TensorFlow 中做分布式训练的一些技巧,有过分布式 train 的经验应该会很感激这些黑科技:
- Round-Robin variables
- Load balancing and partitioning
上面说的是啥呢? Params Server 在保存模型的参数时,默认是每一个 ps 存一个 variable,然后下一个到下个 ps 上存,但是就会存在很多问题,可能这个 variable 很小,但是另一个很大,这样你会发现 ps 和 work 之间的带宽的占用差距很多,怎么解决呢?看下面几张图。



说点题外话,为啥我在看到这里的时候特别激动呢,笔者之前在开展团队内部的分布式训练平台时就遇到这个问题,我们在测试 AlexNet 模型时,发现多个 ps 上的带宽占用差别极大,原因在与 AlexNet 模型的最后三个全连接参数太多,造成了 ps 的不均衡。
上面说了下 Distributed TensorFlow 我特别激动的东西,之后 talk 的就是比较简单的了,如果在 TensorFlow 做分布式的 job,文档里面都有,很简单,这里不提了不对,这里还必须说下 TensorFlow 对于容灾的一个支持。
下图是几种分布式下机器挂掉的情况:
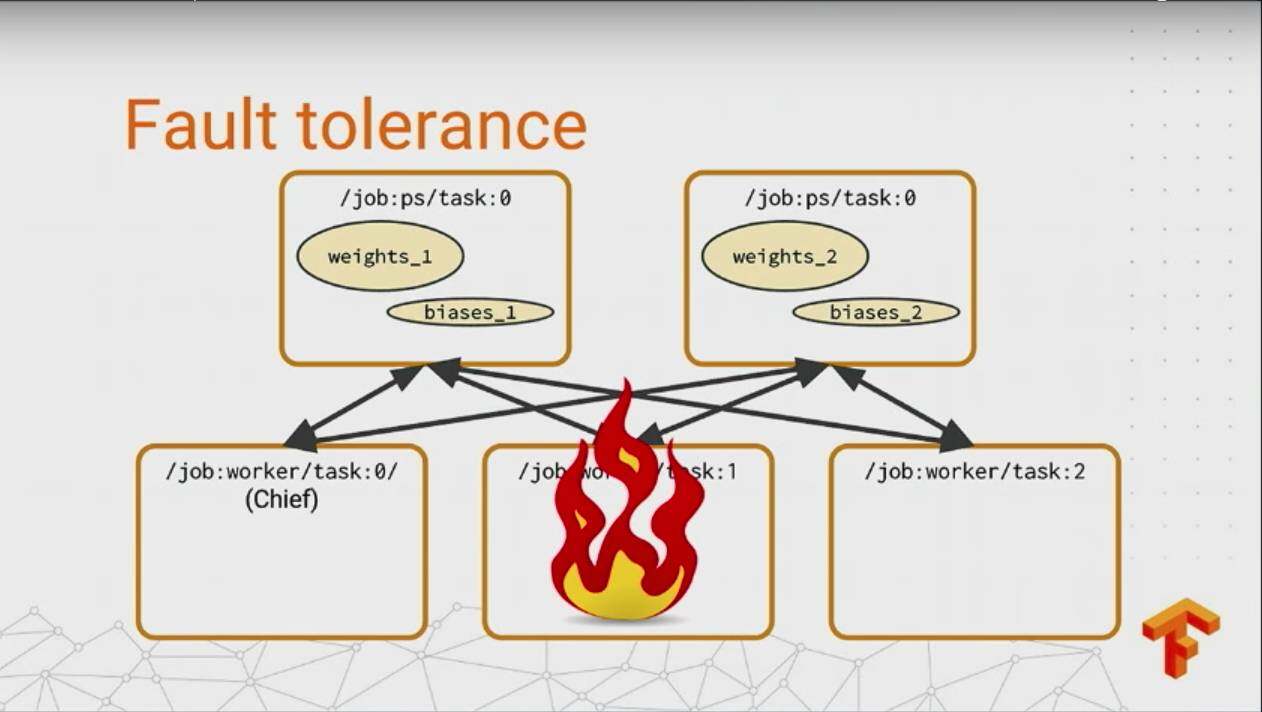
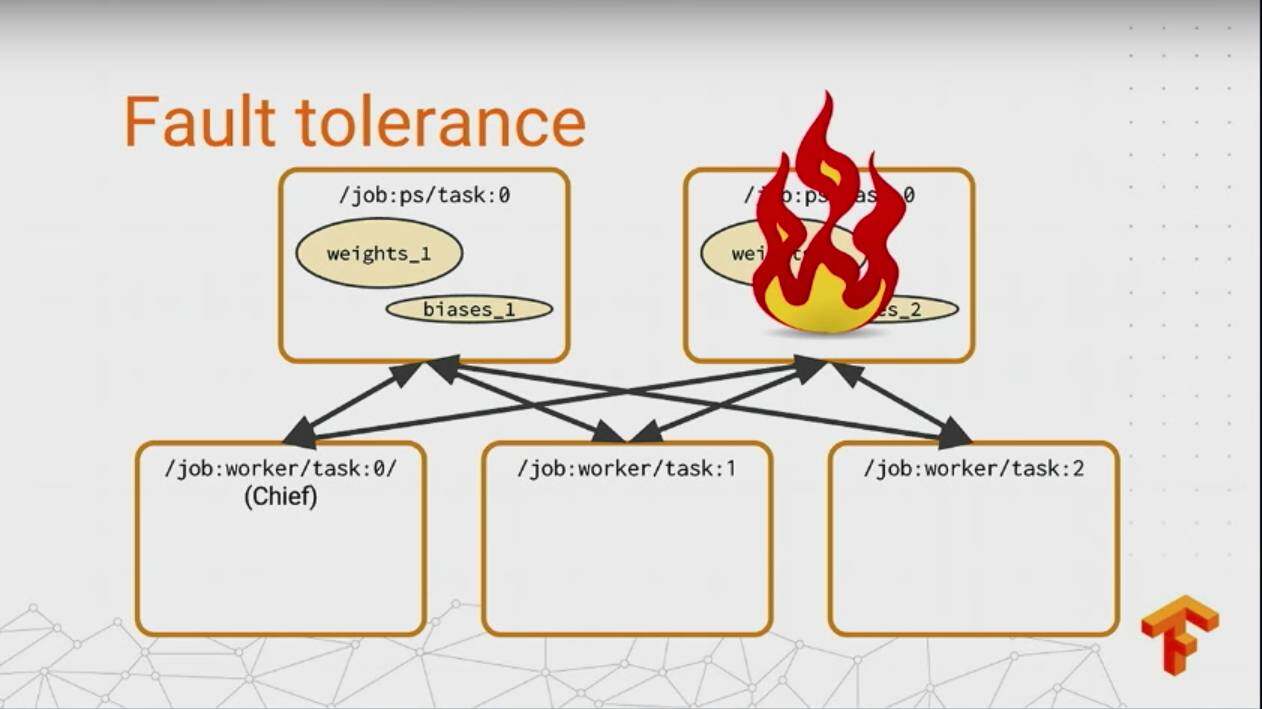
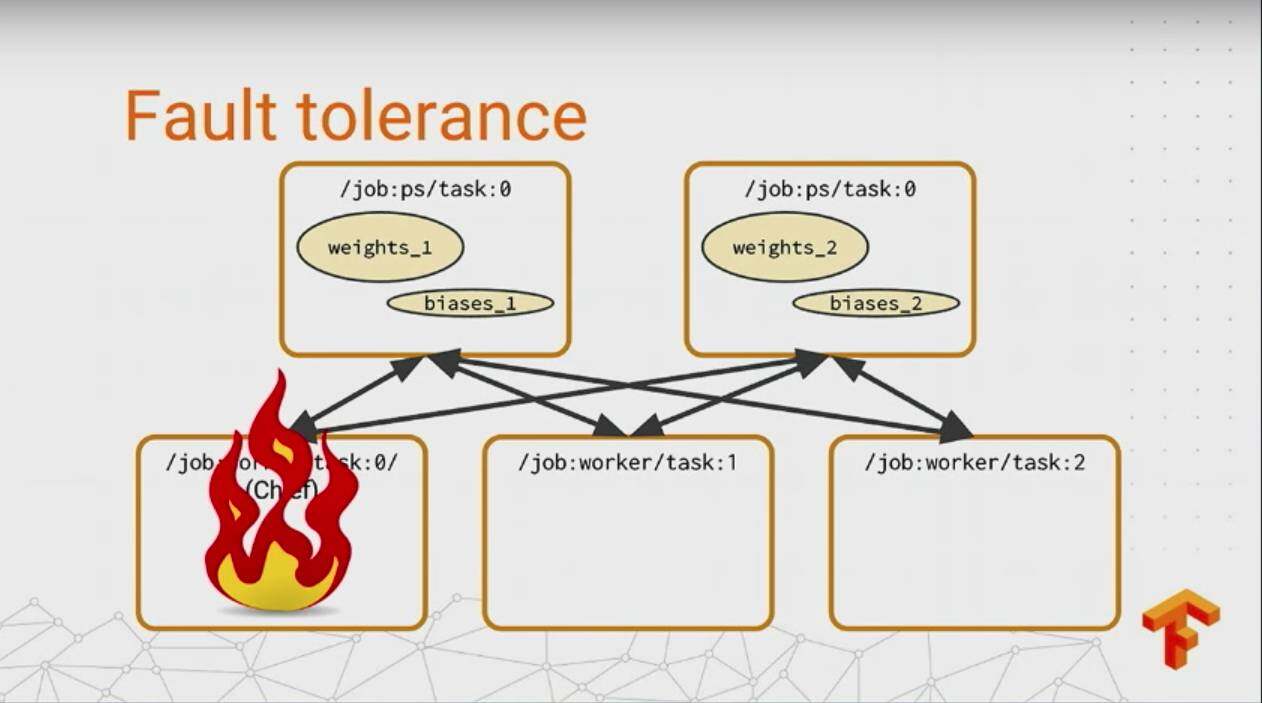
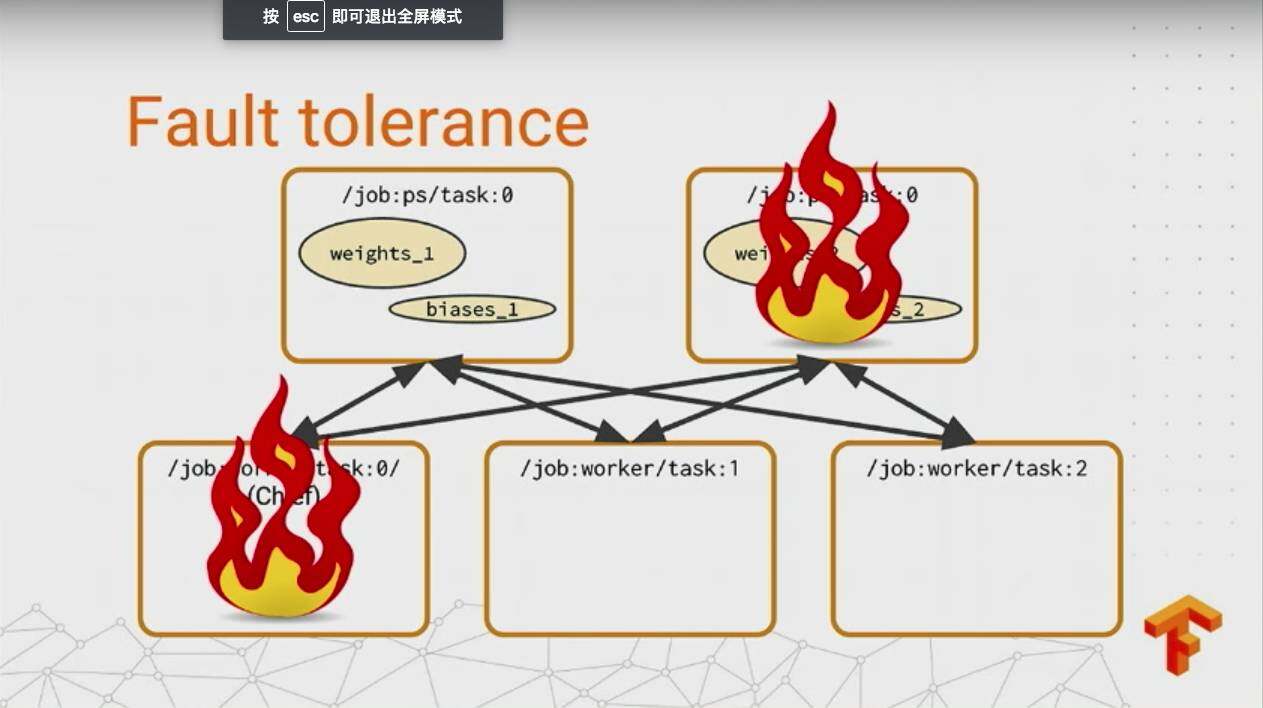
多麻烦是吧,但是没有关系,在 TensorFlow 下能够自动对这些进行一个快速的恢复,只需要更改一行代码:

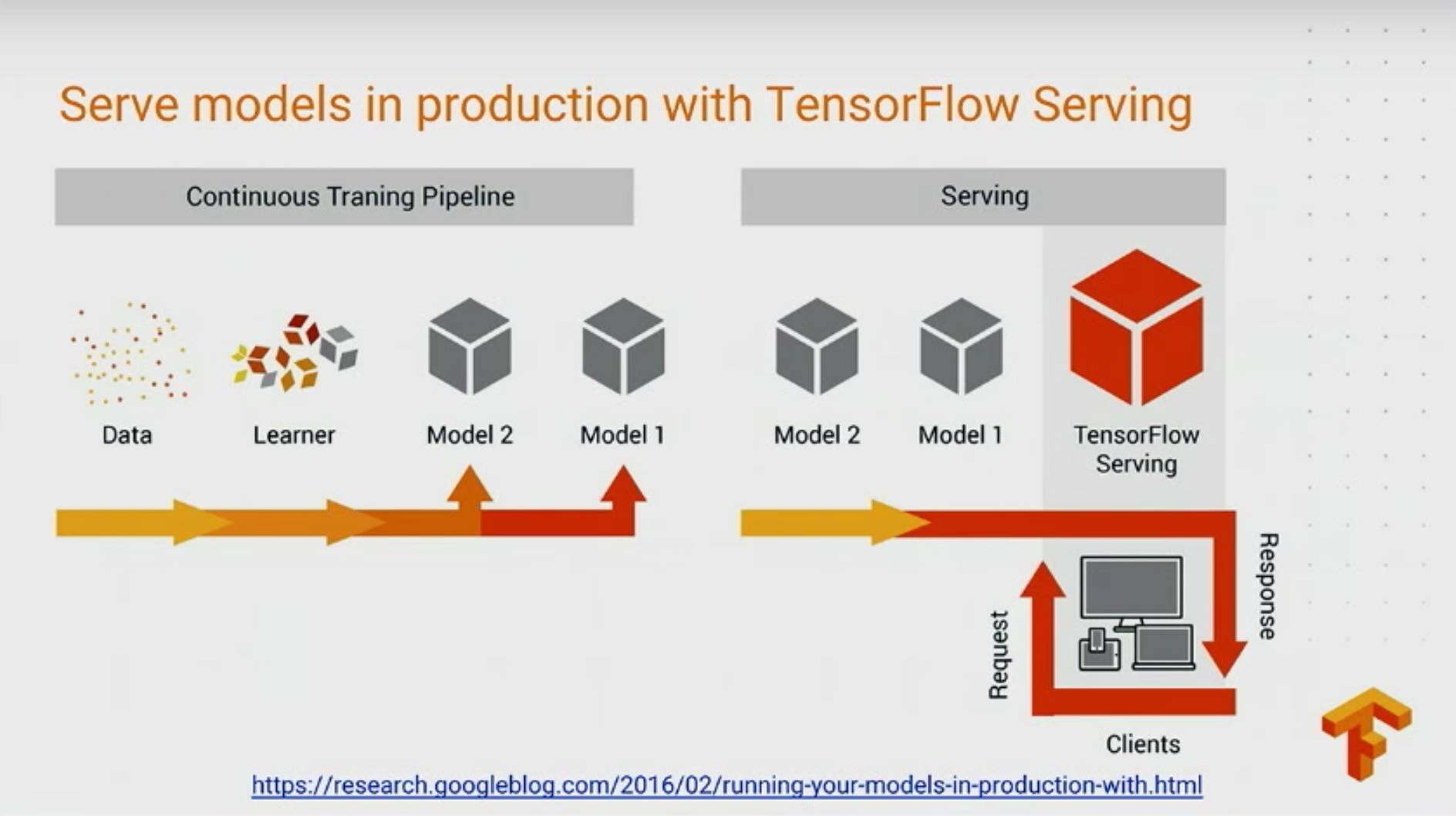
将模型布入生产环境
如何把训练好的模型快速部署在生产环境提供可用的服务,TensorFlow Serving 就是专注在这块,我这里简单介绍下吧:
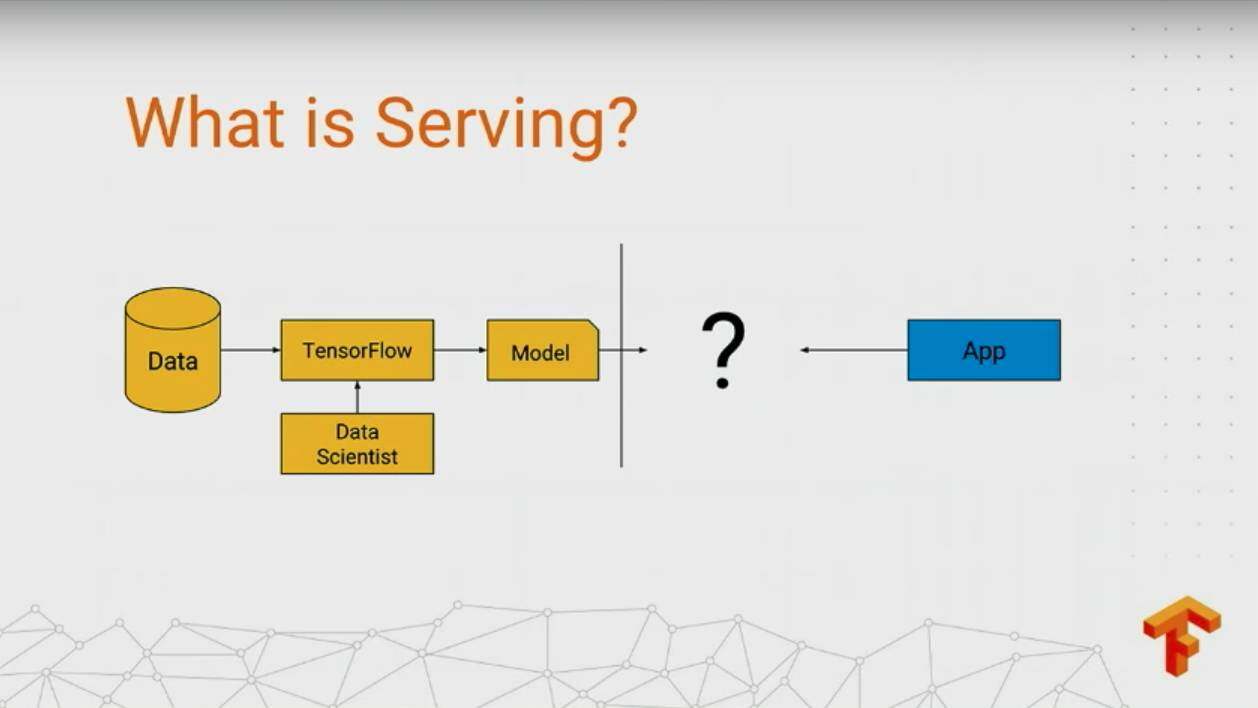
把训练好的模型提供生产环境可用的服务,通常有以下几个需求:
- 长期稳定服务,低时延
- 支持多个模型服务
- 支持同一模型多版本
- 保证计算时耗尽量小以保证一些实时性需求
- mini-batching 的支持,以提高效率
TensorFlow Serving 的设计就是为了解决这些需求,而且 TensorFlow 基于 gRPC,支持多种语言。
TensorFlow 生态
这部分讲了如果利用 TensorFlow 生态结合一些流程的框架比如 Spark、Hadoop 等等来更好地使用 TensorFlow。
数据准备工作
支持的数据读取方法,从快到慢依次是:
- tf.Example, tf.SequenceExample 对象;
- 原生的读取 CSV,JSON 的 OP;
- 直接从 Python feed 数据(最简单)。
如何在其他如 Hadoop, Spark 上支持 TFRecords(Beam 原生支持) 见 (github.com/tensorflow/ecosystem)
集群的管理
TensorFlow 支持以下多种框架:

分布式存储
容器支持

模型导出
- SavedModel: 1,TensorFlow 模型的标准保存格式;2,包括以下必须的 assets,比如 vocabularies(不太会翻,啥意思);
- GraphDef: 通常在移动设备的模型保存比较通用。
移动端以及嵌入式应用 Mobile and Embedded TensorFlow
Pete Warden 介绍了怎么在移动设备比如安卓、IOS 设备、树莓派上面怎么使用 TensorFlow 来做一些开发,具体的可能对移动设备程序开发的小伙伴们比较有用,有兴趣的可以去看看 https://www.youtube.com/watch?v=0r9w3V923rk&index=9&list=PLOU2XLYxmsIKGc_NBoIhTn2Qhraji53cv
Hands On TensorBoard
这个 talk 主要是介绍了 TensorBoard 的一些应用,很多用法以前都没有尝试过,听演讲者描述之后受益匪浅。
# Define a simple convolutional layer
def conv_layer(input, channels_in, channels_out): w = tf.Variable(tf.zeros([5, 5, channels_in, channels_out])) b = tf.Variable(tf.zeros([channels_out])) conv = tf.nn.conv2d(input, w, strides=[1, 1, 1, 1], padding="SAME") act = tf.nn.relu(conv + b) return act
# And a fully connected layer
def fc_layer(input, channels_in, channels_out): w = tf.Variable(tf.zeros([channels_in, channels_out])) b = tf.Variable(tf.zeros([channels_out])) act = tf.nn.relu(tf.matmul(input, w) + b) return act
# Setup placeholders, and reshape the data
x = tf.placeholder(tf.float32, shape=[None, 784])
y = tf.placeholder(tf.float32, shape=[None, 10])
x_image = tf.reshape(x, [-1, 28, 28, 1])
# Create the network
conv1 = conv_layer(x_image, 1, 32)
pool1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
conv2 = conv_layer(pooled, 32, 64) pool2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
flattened = tf.reshape(pool2, [-1, 7 * 7 * 64])
fc1 = fc_layer(flattened, 7 * 7 * 64, 1024)
logits = fc_layer(fc1, 1024, 10)
# Compute cross entropy as our loss function
cross_entropy = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y))
# Use an AdamOptimizer to train the network
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# compute the accuracy
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# Initialize all the variables sess.run(tf.global_variables_initializer())
# Train for 2000 steps for i in range(2000):
batch = mnist.train.next_batch(100)
# Occasionally report accuracy
if i % 500 == 0: [train_accuracy] = sess.run([accuracy], feed_dict={x: batch[0], y: batch[1]}) print("step %d, training accuracy %g" % (i, train_accuracy))
# Run the training step
sess.run(train_step, feed_dict={x: batch[0], y_true: batch[1]})
很多小伙伴都写过类似的代码,构造网络,然后设定训练方式,最后输出一些基本的结果信息,如下:
step 0, training accuracy 10%
step 500, training accuracy 12%
step 1500, training accuracy 9%
step 2000, training accuracy 13%
TensorFlow 给你的不仅仅是这些,有一个特别棒的工具 TensorBoard 能够可视化训练过程中的信息,能让人直观的感受,当然需要一些简单的配置:
写入 Graph
writer = tf.summary.FileWriter("/tmp/mnist_demo/1")
writer.add_graph(sess.graph)
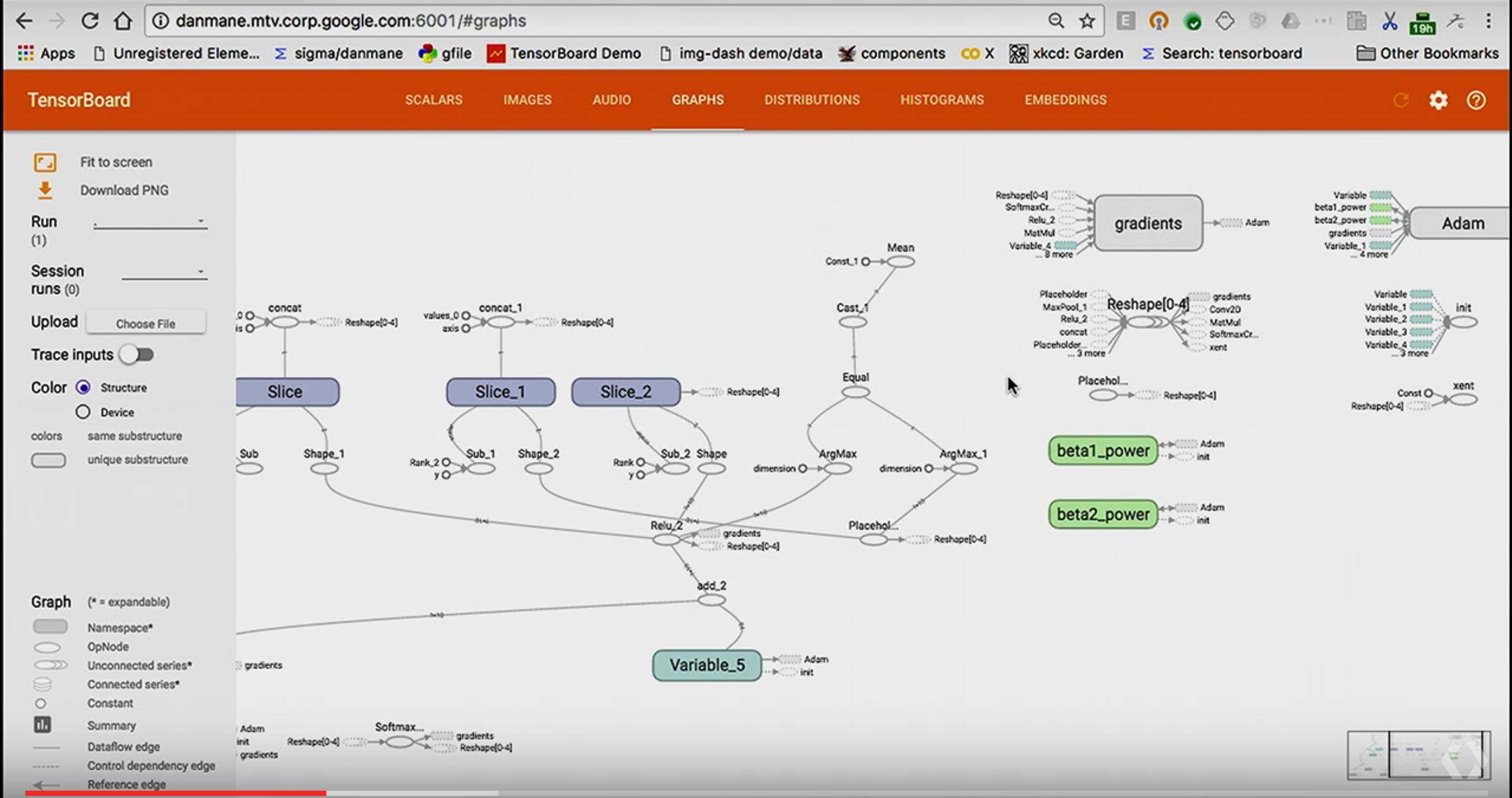
这里虽然能够可视化 Graph,却感觉很杂乱,我们可以通过给一些 node 增加 name,scope,让图变得更好看点:
def conv_layer(input, channels_in, channels_out, name="conv"): with tf.name_scope(name): w = tf.Variable(tf.zeros([5, 5, channels_in, channels_out]), name="W") b = tf.Variable(tf.zeros([channels_out]), name="B") conv = tf.nn.conv2d(input, w, strides=[1, 1, 1, 1], padding="SAME") act = tf.nn.relu(conv + b) return tf.nn.max_pool(act, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
def fc_layer(input, channels_in, channels_out, name="fc"): with tf.name_scope(name): w = tf.Variable(tf.zeros([channels_in, channels_out]), name="W") b = tf.Variable(tf.zeros([channels_out]), name="B") return tf.nn.relu(tf.matmul(input, w) + b)
# Setup placeholders, and reshape the data
x = tf.placeholder(tf.float32, shape=[None, 784], name="x")
x_image = tf.reshape(x, [-1, 28, 28, 1])
y = tf.placeholder(tf.float32, shape=[None, 10], name="labels")
conv1 = conv_layer(x_image, 1, 32, "conv1") conv2 = conv_layer(conv1, 32, 64, "conv2")
flattened = tf.reshape(conv2, [-1, 7 * 7 * 64])
fc1 = fc_layer(flattened, 7 * 7 * 64, 1024, "fc1")
logits = fc_layer(fc1, 1024, 10, "fc2")
with tf.name_scope("xent"): xent = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y))
with tf.name_scope("train"): train_step = tf.train.AdamOptimizer(1e-4).minimize(xent)
with tf.name_scope("accuracy"): correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(y, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
writer = tf.summary.FileWriter("/tmp/mnist_demo/2")
writer.add_graph(sess.graph)
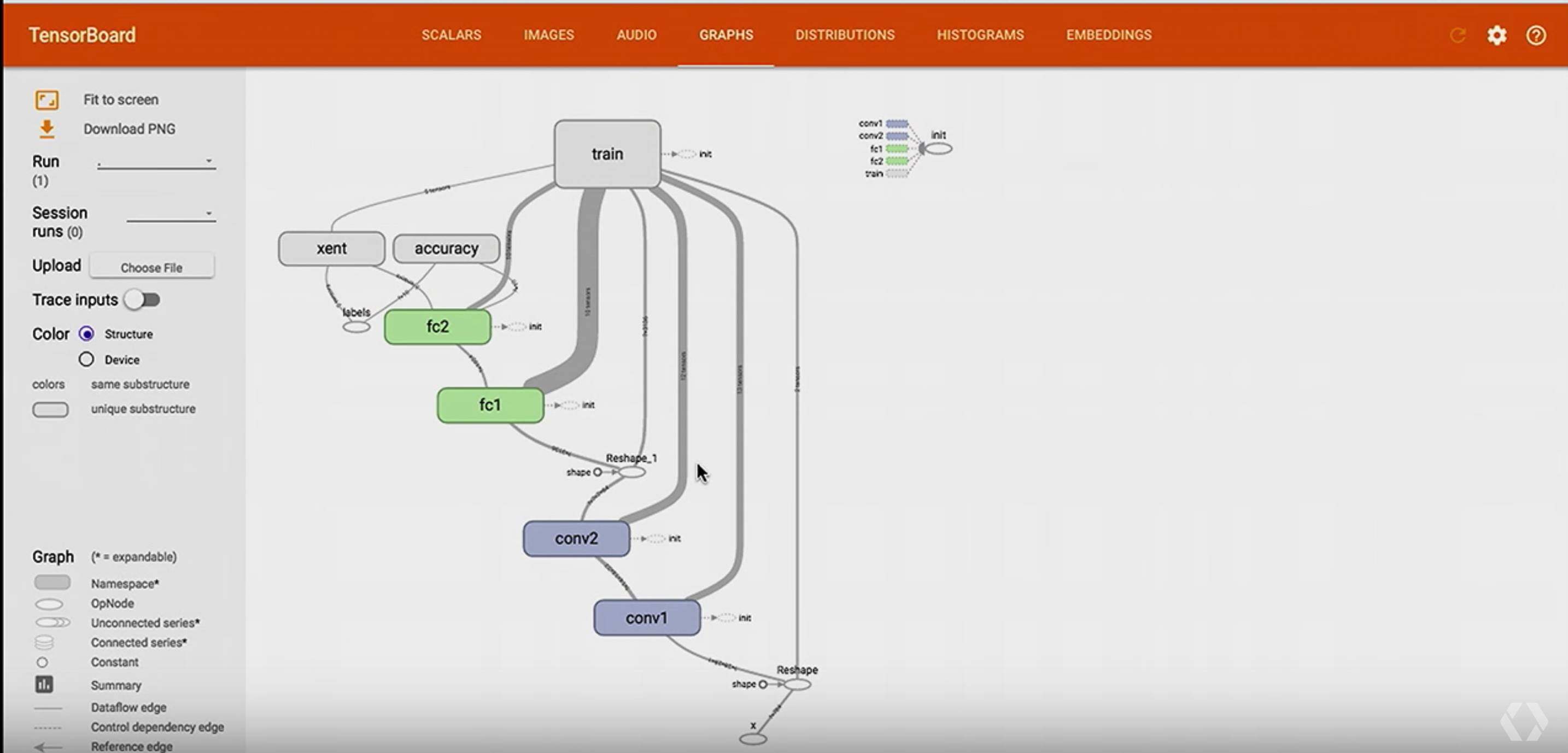
通过 TensorFlow 的 api,收集更多的数据记录显示在 TensorBoard 中:
tf.summary.scalar('cross_entropy', xent)
tf.summary.scalar('accuracy', accuracy)
tf.summary.image('input', x_image, 3)

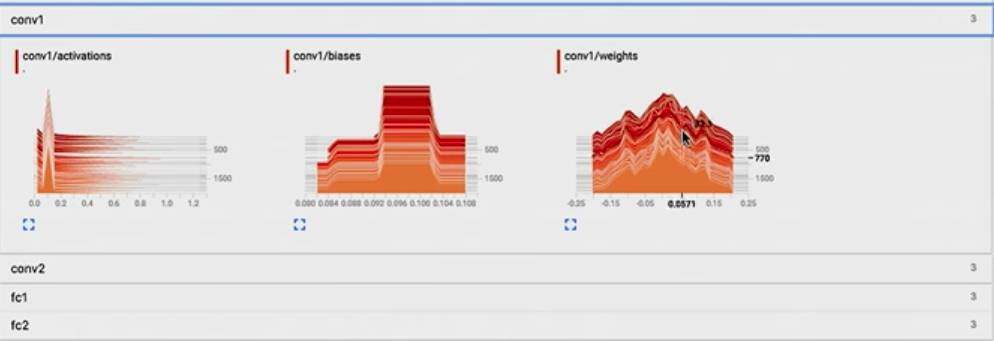
修改 Conv 的代码,将 Weight,bias,act 加入到 histogram 中:
def conv_layer(input, channels_in, channels_out, name="conv"): with tf.name_scope(name): w = tf.Variable(tf.zeros([5, 5, channels_in, channels_out]), name="W") b = tf.Variable(tf.zeros([channels_out]), name="B") conv = tf.nn.conv2d(input, w, strides=[1, 1, 1, 1], padding="SAME") act = tf.nn.relu(conv + b) tf.summary.histogram("weights", w) tf.summary.histogram("biases", b) tf.summary.histogram("activations", act) return tf.nn.max_pool(act, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
配置将训练过程中的数据写入:
merged_summary = tf.summary.merge_all()
writer = tf.summary.FileWriter("/tmp/mnist_demo/3")
writer.add_graph(sess.graph)
for i in range(2001): batch = mnist.train.next_batch(100) if i % 5 == 0: s = sess.run(merged_summary, feed_dict={x: batch[0], y: batch[1]}) writer.add_summary(s, i) sess.run(train_step, feed_dict={x: batch[0], y: batch[1]})

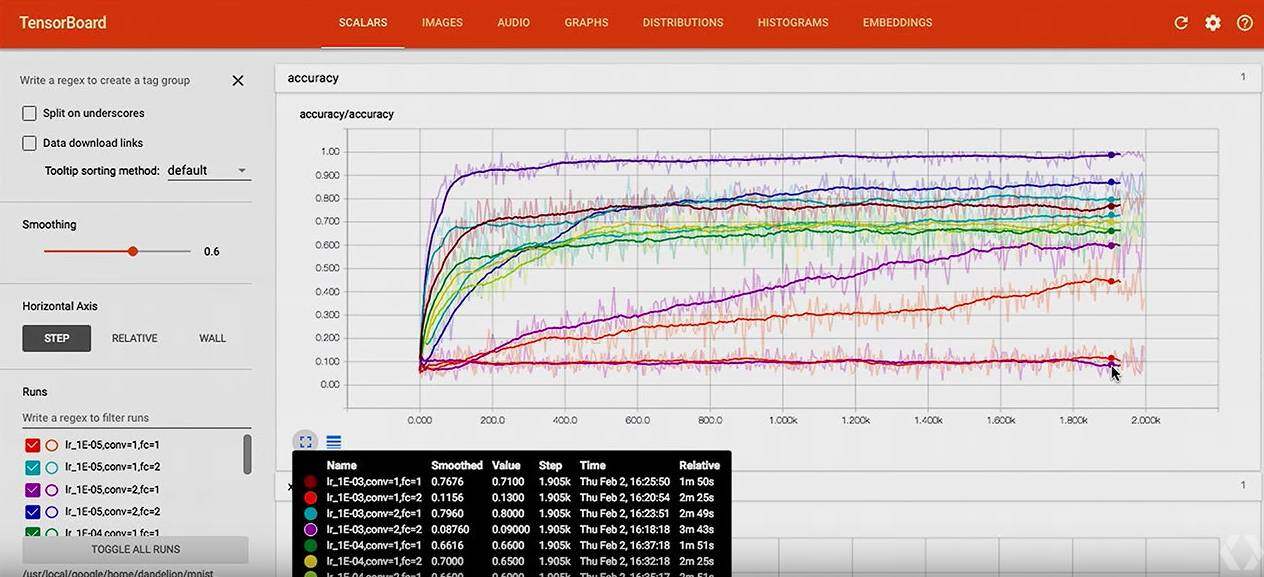
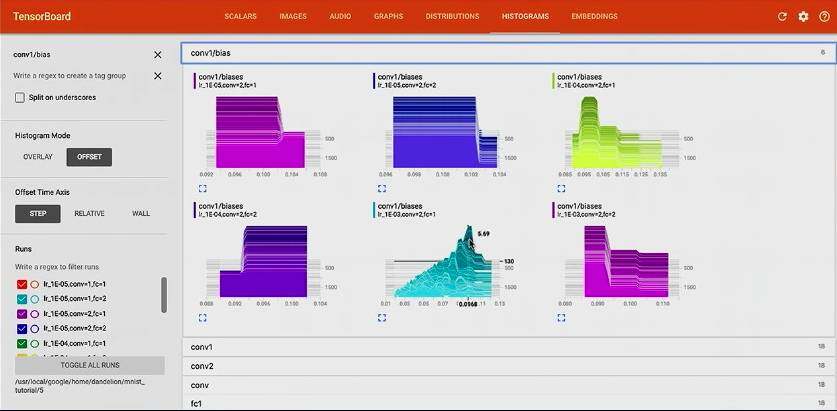
Hyperparameter Search
这次这个 TensorBoard 的 talk 给我最大的收获就是用 TensorBoard 做 Hyperparamter Search 是这么的方便, 这次 talk 中主要演示超参的两个方面:
- 不同学习率
- 不同网络结构
# Try a few learning rates
for learning_rate in [1E-3, 1E-4, 1E-5]: # Try a model with fewer layers for use_two_fc in [True, False]: for use_two_conv in [True, False]: # Construct a hyperparameter string for each one (example: "lr_1E-3,fc=2,conv=2) hparam_str = make_hparam_string(learning_rate, use_two_fc, use_two_conv) writer = tf.summary.FileWriter("/tmp/mnist_tutorial/" + hparam_str) # Actually run with the new settings mnist(learning_rate, use_two_fully_connected_layers, use_two_conv_layers, writer)
tensorboard --logdir /tmp/mnist_tutorial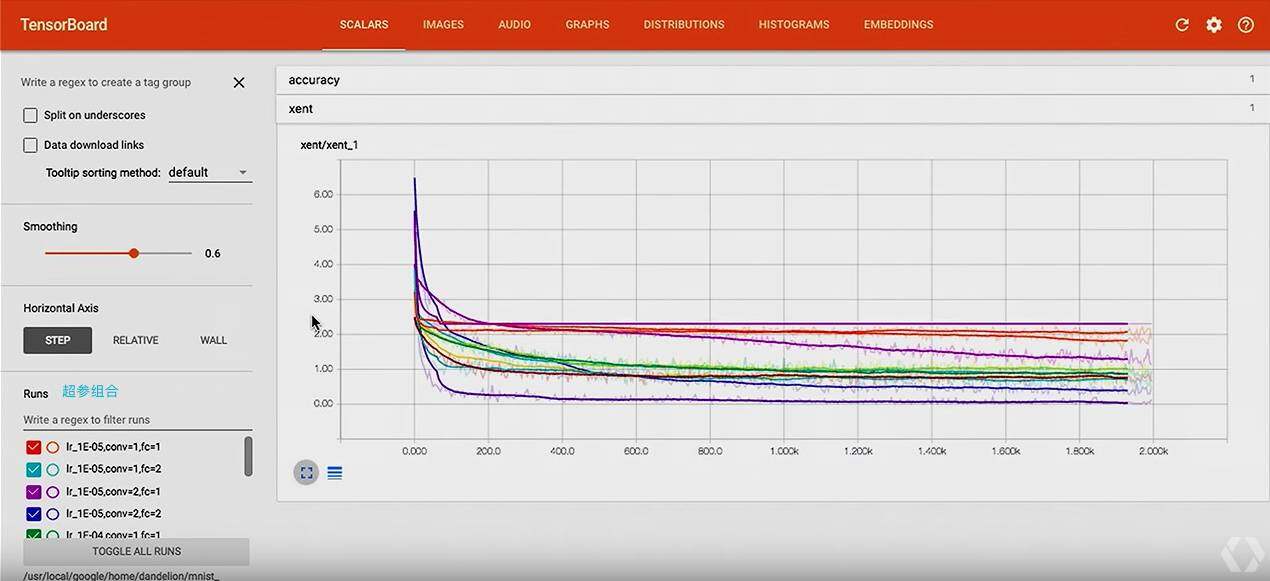
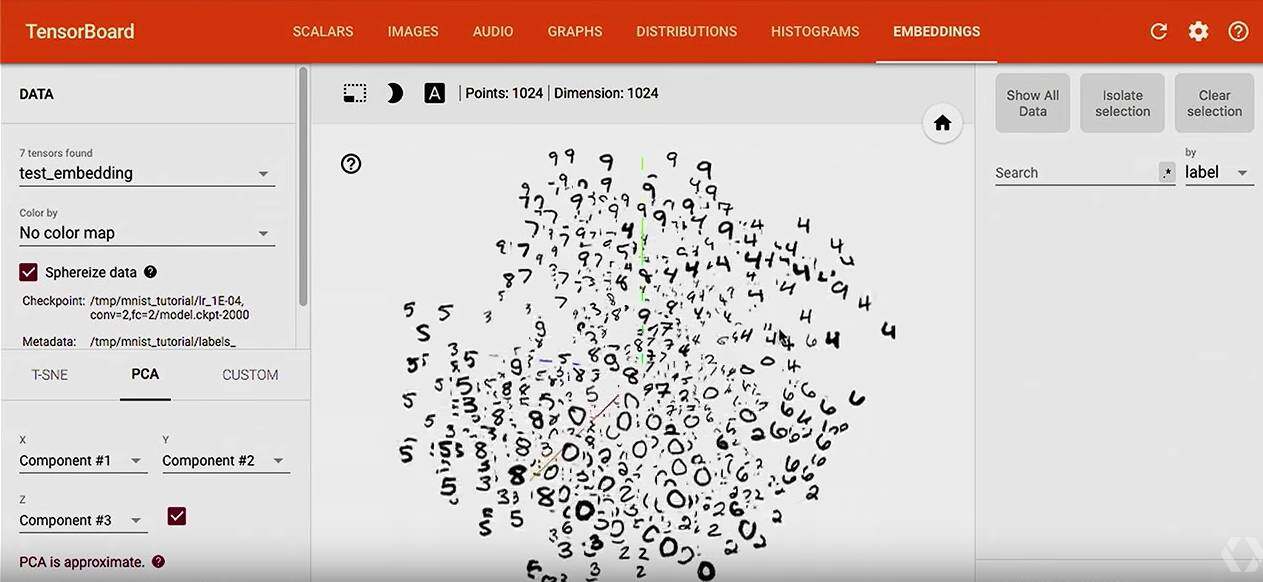
Embedding Visualizer
embedding = tf.Variable(tf.zeros([10000, embedding_size]), name="test_embedding")
assignment = embedding.assign(embedding_input)
config = tf.contrib.tensorboard.plugins.projector.ProjectorConfig()
embedding_config = config.embeddings.add()
embedding_config.tensor_name = embedding.name
embedding_config.sprite.image_path = os.path.join(LOG_DIR, 'sprite.png')
# Specify the width and height of a single thumbnail.
embedding_config.sprite.single_image_dim.extend([28, 28])
tf.contrib.tensorboard.plugins.projector.visualize_embeddings(writer, config)
for i in range(2001): batch = mnist.train.next_batch(100) if i % 5 == 0: [train_accuracy, s] = sess.run([accuracy, summ], feed_dict={x: batch[0], y: batch[1]}) writer.add_summary(s, i) if i % 500 == 0: sess.run(assignment, feed_dict={x: mnist.test.images, y_true: mnist.test.labels}) saver.save(sess, os.path.join(LOG_DIR, "model.ckpt"), i) sess.run(train_step, feed_dict={x: batch[0], y_true: batch[1]})
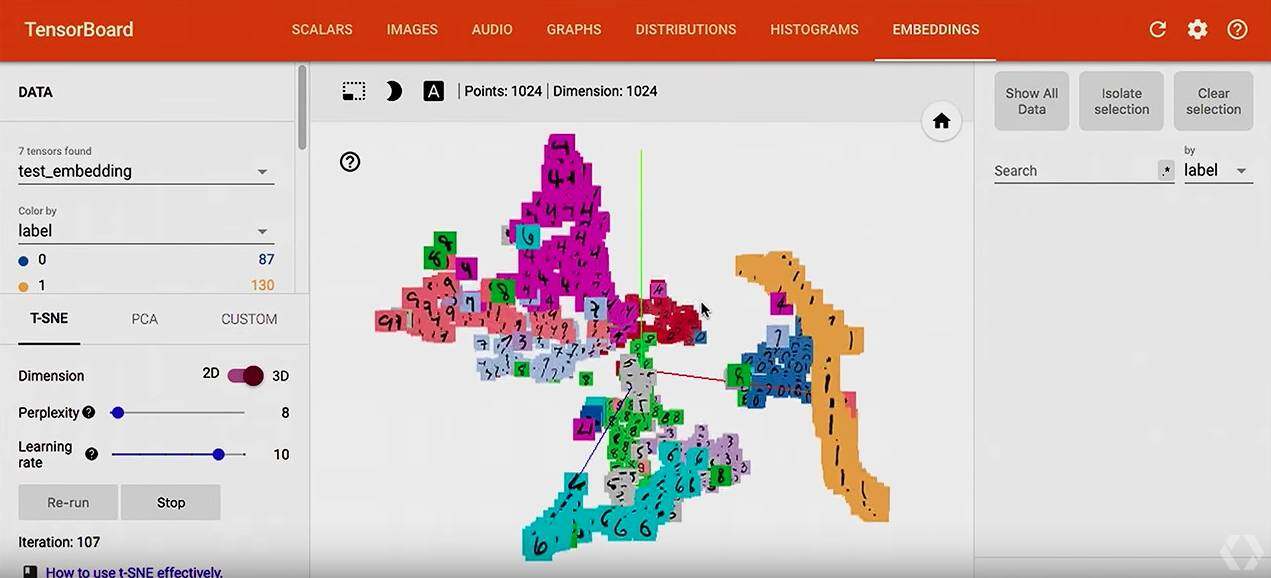
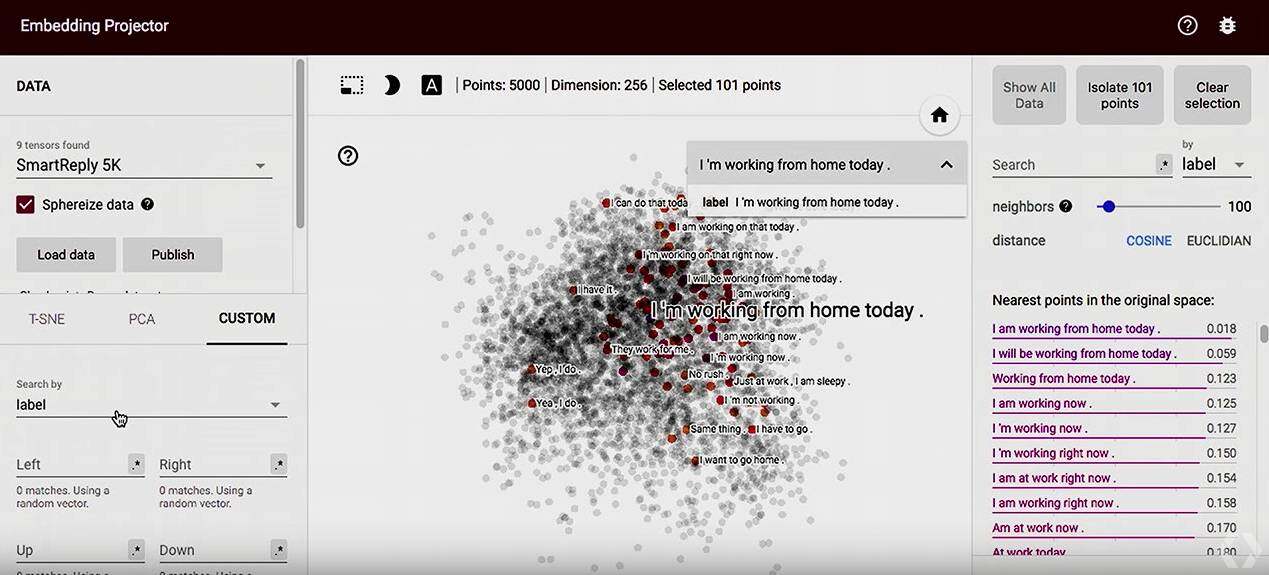
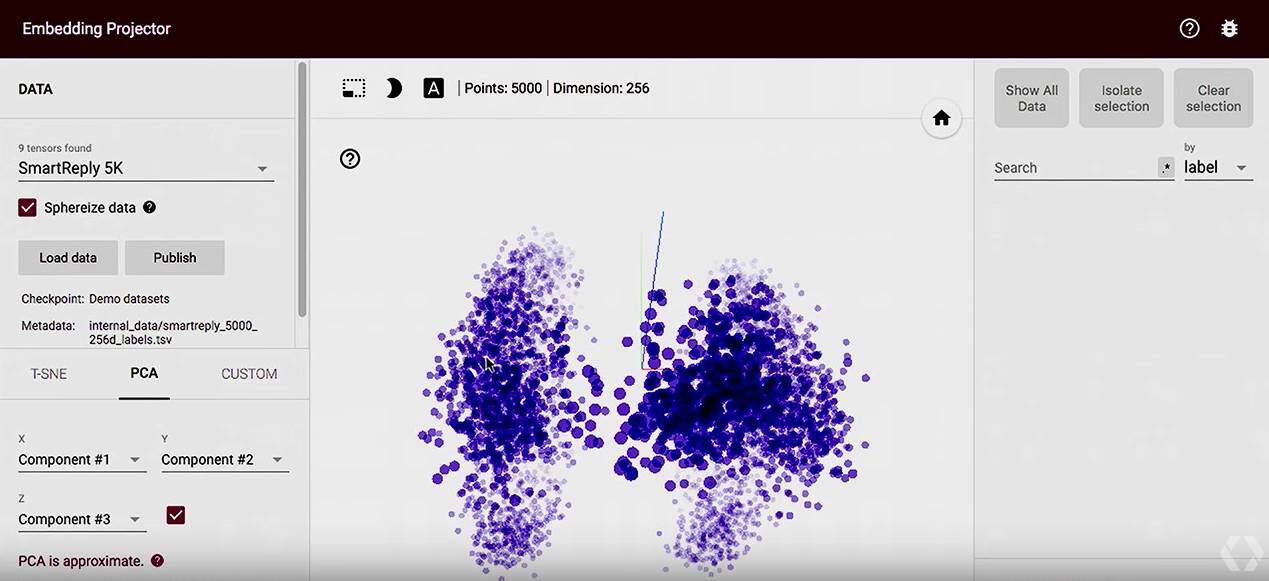
Future for TensorBoard
未来 TensorBoard,会在以下三个方面来做一些提升:
- 在 TensorBoard 上集成 Tensorflow 的调试
- 增加插件的支持
- 企业级 TensorBoard 的支持
总结
照例总结下,从上面不难看出 TensorFlow 在过去一年的时间里确实做了很多很有意思的工作,无论是在 Reasearch 还是 Production 上,包括各种有意思的工具,其中收获最大的是利用 TensorFlow 来做超参的调节、还有 Keras 的新的支持、分布式的各种模型变量保存的优化方法、分布式容灾、XLA 的支持是的模型更快,那么花在看这些演讲上的时间感觉没有浪费,但是因为个人知识有限,如上面有错误或者不周到的地方,欢迎指出,敬请谅解。
作者介绍
段石石,UCloud 创新产品线 AI Group 深度学习研发工程师,CV 算法出身,主要负责 UCloud 算法相关产品,现阶段主要负责 UCloud Ai 平台的设计、开发工作,对云环境下的分布式深度学习平台有较深的理解,工作之余还是喜欢做些技术相关的工作,读读 paper, 跑跑算法, 喜欢开源 (TFLearn Contributor, MXNet Contributor, TensorFlow Contributor), 平时会把工作学习中的一些内容分享到个人博客: http://hacker.duanshishi.com。




