在前段时间的一次沙龙分享上,来自 TalkingData 负责企业大数据产品研发的研发总监张宁,分享了题为《海量数据 OLAP 分析实践——TD Atom Cube》的演讲。主要涉及点包括移动 App 数据统计分析、Web 网站数据统计,以及用于企业自有数据和第三方数据管理和应用的 DMP。
本次分享主要分为五个部分:
- 实时 OLAP 架构
- TD 业务场景分析(以滴滴打车和全民枪战为例)
- 基数计算
- Bitmap 测试
- 测试结果分析
从 2011 年 9 月份成立的 TalkingData,目前正打算做一些统计分析的事情,协助开发者收集数据、分析数据,并提供在特殊场景用特殊的做法来解决问题的方案。此外,TalkingData 的研发部门还在调研开源的 OLAP(On-Line Analytical Processing 联机分析处理)框架。

实时 OLAP 架构
OLAP 可分为两类,一类是 MOLAP,多维交叉,其技术特点是“按最小粒度聚合,预建索引”。另一类是 ROLAP 交互式分析。而众所周知的 MOLAP 又有三种:Kylin、Pinot 和 Druid。这三种当中,druid 目前还不能提供不同应用场景的结合点。Kylin 是 eBay 开发出来的,核心开发团队在国内,也有中文版。
ROLAP 主要用在交互式查询上。据了解,分布式 SQL 查询引擎 Presto 性能最好,京东和美团都在用。Spark 现在发展特别快,新的内存分布式文件和 Spark 结合之后,性能和 Presto 不相上下。

来看(如上图)实时 OLAP 架构,撇开交互式场景而论,典型业务场景和多维交叉场景还是会用实时 OLAP 架构的,下面的分支是流式的,这样的架构是把在海量数据上构建数据仓库的传统概念落地实施。
张宁介绍说,目前 TalkingData 的业务覆盖了几千款 App,例如植物大战僵尸、全民枪战等等,开放的技术平台则是面向所有开发者的。
TalkingData 业务场景分析(以滴滴打车和全民枪战为例)
ETL(数据仓库技术)是英文 Extract Transform Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)和加载(load)至目的端的过程。ETL 较常用在数据仓库,但其对象并不限于数据仓库。张宁解释说,数据分析前都会经过 ETL 过程,将数据清洗成一个比较结构化的事实表,这是一个扁平的模式,首先要考虑的就是日志发生时间。随后还要考虑各种维度:手机机型类型是什么?它适用于哪款应用?这里拿滴滴打车和全民枪战为例,对数据清洗之后再做计算使用时长,全民枪战用了 1800 秒。(如下图)

再来看第二类事实表。表里面的最后一列是具体事件,包括游戏充值、支付、登录和注册等等,这些都是通过对收集上来的数据进行清洗之后呈现出来的。统计全民枪战在不同机型上使用时长的分布,不能把事实表放在存储里,如果是面对客户的话,就一定要生成数据方 (Cube)。(如下图)

时间也是一个非常特殊的维度,所有数据查询到最后分析都是基于时间。中间一列是典型的维度,可能还有其它分辨率,包括运营商等等。最后一列里做了计算,这个表聚合成一个典型的 Cube 之后,数据量是没有多少的。这也为后面再做查询提供了便利,如果数据量有两个数量级的减少的话,不管是查询还是多维交叉分析都会非常快。所以还是拿全民枪战开发公司和滴滴打车这样数量级很庞大的公司来说,不管怎么存储,存储在哪里,都不是大问题,按时间分片放在列数存储,聚合之后没多少数据,能满足每个用户的实时查询需求,方法很简单:优化+提前聚合+生成 Cube+去掉维度。(如下图)

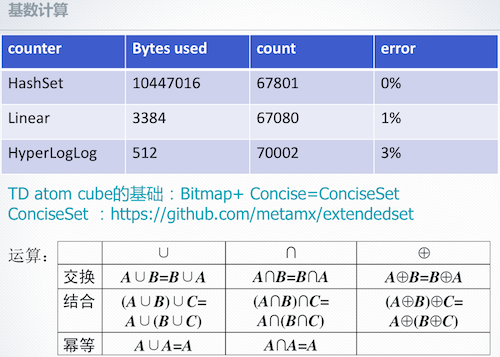
基数计算
这里介绍最简单的三款计算器:HashSet、Linear 和 Hyperloglog,如果只为估算之用,Hyperloglog 是最优选择。如果真要做到精准的排重,那一定是业务场景需求。像面对滴滴打车、手游这种客户,就一定要做到数据精准。
Bitmap 测试
Bitmap 是什么?就是一个位,每个设备可以用一个整型表示,在这个位里面如果出现了就设成 1,用一个一个位表示数据收集的做法,是 1 就有,非 1 就是无,但是这种做法会导致数据量特别大,所以要用压缩算法把这些位连接 1 连接 0 压缩起来,存储和内存所占空间都很小。
所以针对上述三款计算工具做了一些测试,测试数据集在 1 万、100 万、1 千万、1 亿进行对比。主要对比传统的 HashSet 和底 Hyperloglog 之间的区别,结果显示差距还挺大。HashSet 在一万数据的时候,表现还不错。Hyperloglog 在指标上比 HashSet 优秀,分统越多性能越快。到 100 万的时候,Bitmap 的优势显现,特别是在空间复杂度上,比 Hashset 高了一个数量级,和 Hyperloglog 类似。

1000 万的时候还是 Bitmap 处于优势。但是到了一个亿,Hashset 在离散的情况下最极端的离散是 101010,压缩性能最低,内存使用应该是 215 兆。得出的结论是,Hyberloglog 等数量级消耗的时间和资源都是最优的,但如果是精准统计基数的话,就不一定了。

测试总结:
- HyperLogLog Counting 对同等体量数据集计算时所消耗的计算资源和内存资源全面优于 Bitmap 方法和 Hashmap 方法。
- HyperLogLog Counting 的精度大体上与 bucket 数成正比。对于百万至千万级别的数据集 1024 基本满足需求。
- 百万级别数据集如果需要高精度的基数,使用 Bitmap 完全可以满足需求。
百万级别的数据集 Bitmap 表现特别优异,所以 TalkingData 最后选择了 Bitmap 这种方式。
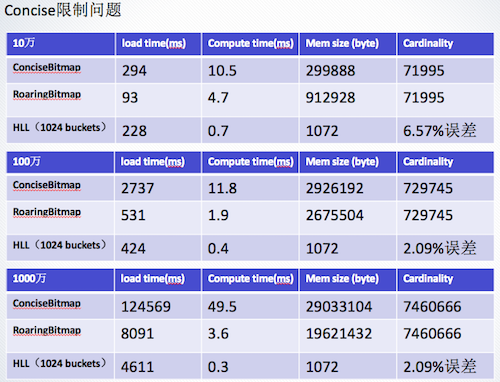
随后,张宁也介绍了 TalkingData 自己开发的 TD Atom Cube,因为受 Concise 算法的限制,再加上团队数据体量的不断增加,所以团队从 0 开始,做交叉从上层分开来做。但是后来发现 Roaring Bitmaps 没有上限,同时也使用了 Spark 和 Join,但是 Bitmap 场景不是用 Bitmap,而是用 Cude,用 Bitmap 来做 future。后来通过测试,发现计算时间和存储时间都优于 Concise,但这只是实验阶段测。在其他测试中发现海量数据没有一万的数据,这种场景几乎很少存在,用 Roaring Bitmaps 是比较合适的。
测试总结为:
- Hyberloglog 误差还是很大。
- Roaring 没有上限,可以避免上一层的工作。
- 在大数据集上超过一百万,无论在加载时间、计算更快,使用空间更少。
将来怎么做?张宁说一直也在关注其它的开源框架,希望能够结合开源工具来解决非精准基数计算。同时也想办法把 Atom Cube 这种能力集成进去,在一些精准基数计算场景下用 Bitmap 来做 Cube,非精准计算用原生 Druid 做法,包括 Hyperloglog 计算。




