
作者 | 马迎伟 / 明巍、黎槟华 / 临城、李永彬 / 水德
解决真实 GitHub issue 能力进化,通义灵码团队最新论文《An Open Development-Process-Centric Language Model for Automated Software Improvement》提出了面向程序改进的软件工程大模型通义灵码 SWE-GPT。

「开源模型首次在 SWE-bench Verified 基准上自动解决超过 30% 的真实 GitHub issue」
利用软件工程过程数据训练,在自动解决真实 issue 中首次接近闭源模型,展示了强大的软件修复和改进能力。
概述
📔 随着 Devin 的发布,国内外 AI 程序员迅速发展,引起了产业界和学术界的广泛关注。AI 程序员通常利用 LLM-based agent 实现,称之为软件工程智能体(Software Engineering agent, SE agent)。
📐 SWE-bench 是一个用于评估软件工程智能体的权威 benchmark,评估 SE agent 在端到端软件维护(例如,修复软件问题)和演化(例如,添加新特性)方面的能力,它的输入为真实存在的 Github issue 和对应的 codebase,要求 SE agent 生成对应的 pull-request,然后运行开发者编写的单测 / 集成测试验证 patch 是否解决了当前的 issue 同时不影响其他功能。与 HumanEval 不同,该 benchmark 具有挑战性,要求 agent 同时具有包括存储库理解、故障定位、代码生成和程序修复等多种功能,从而端到端地解决一个现实的 issue。
然而虽然一系列研究工作 (如 SWE-agent) 在该基准上取得较好结果,但当前的研究仍然面临两大挑战。
首先,最先进的性能主要依赖于闭源代码模型,如 GPT-4o/Claude 3.5 Sonnet 等,极大限制了技术的可访问性和在多样化的软件工程任务中的定制化潜力。这种依赖性也带来了数据隐私的担忧。
其次,这些模型主要基于静态代码数据进行训练,缺乏对软件开发过程中动态交互、迭代问题解决和演化特性的深入理解,影响了其在真实场景中的实用性。
🌟 为应对这些挑战,作者从软件工程的角度出发,认识到实际的软件维护和演化过程不仅涉及静态代码数据,还包括开发者的思维过程、外部工具的使用以及不同职能人员之间的互动。为此,作者推出了 Lingma SWE-GPT 系列,包括 Lingma SWE-GPT 7B 和 Lingma SWE-GPT 72B。通过学习和模拟真实的代码提交活动,Lingma SWE-GPT 模型实现了对软件改进流程的更全面理解。
论文在 SWE-bench-Verified 基准(包含 500 个真实的 GitHub 问题)上进行了实验评估📊,该基准最近由 OpenAI 提出。结果显示,Lingma SWE-GPT 72B 成功解决了 30.20% 的 GitHub 问题,相较 Llama 3.1 405B 的性能提升了 22.76%,接近封闭源模型(GPT-4 解决 31.80% 问题)的表现。值得注意的是,Lingma SWE-GPT 7B 解决了 18.20% 的问题,超过了 Llama 3.1 70B 的 17.20% 解决率,展示了小型模型在 AI 软件工程师中的应用潜力。
Lingma SWE-GPT 方法介绍
方法包括三个主要阶段:
问题数据收集(Figure 1)
训练软件工程模型的基础在于利用高质量的真实软件开发数据。GitHub Issues 是理解缺陷、功能请求和增强的重要资源,通常提供问题或期望功能的自然语言描述。Pull-Request(PR)则包含与这些问题相关的代码更改,包括提交历史和代码差异,直接解决所提出的问题。通过利用这些数据的组合,SWE-GPT 能够模拟真实的编程场景,捕捉代码修改背后的上下文和推理过程。
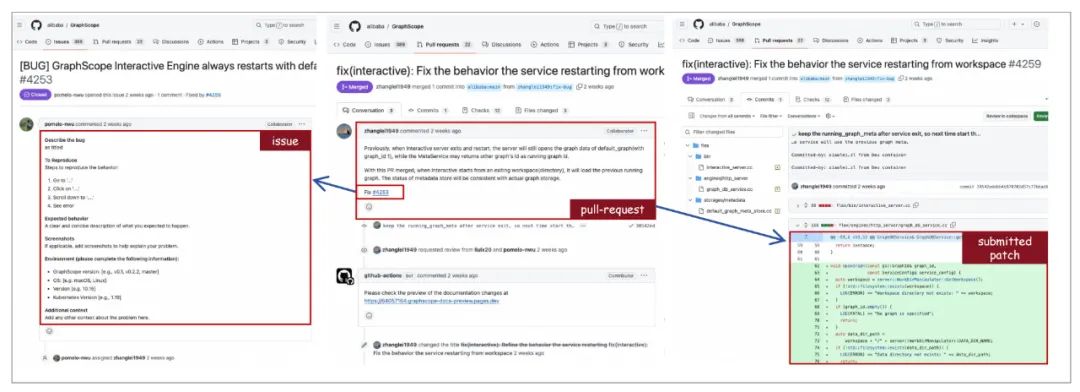
Figure 1 问题和相应的拉取请求数据采集过程示例
数据爬取:论文从具有至少 50 个星标的 GitHub 仓库开始选择,以确保社区的基本认可和活跃度。同时为了避免潜在的数据泄露,作者仔细过滤了在 SWE-bench 中涉及的仓库。对于每个选定的仓库,作者检索所有问题及其关联的 PR,特别关注那些已由开发者合并的 PR。作者使用 GitHub 的 API 获取状态为“已合并”的 PR 及其状态为“已关闭”的关联问题,确保捕获到的都是已完成和批准的代码更改。此外,作者还在 PR 时刻存储代码库的快照,以提供足够的上下文信息。
数据过滤:为确保问题和 PR 的质量,作者应用了一套启发式过滤规则。对于 issue,仅保留文本描述至少包含 20 个字符的项,从而排除琐碎或详细程度不足的问题。此外,为了避免那些主要引用外部资源而未提供足够上下文的问题,作者过滤掉了包含超过三个超链接的问题。经过这些过滤标准后,作者构建了一个包含约 90,000 个 PR 的数据集,这些 PR 来自 4,000 个仓库。值得注意的是,这里处理的代码库通常相当庞大,往往包含数百个文件,反映了现实软件改进的复杂性。
开发过程数据合成 (Figure 2)
在全面的问题数据收集的基础上,作者引入了一种新颖的数据合成过程(SoftWare Engineering process data Synthesis and Inference workflow, SWESynInfer),旨在捕捉软件开发的动态特性。该过程解决了当前基于 LLM 的方法的局限性,通过模拟真实软件维护和演化中复杂的交互方面来增强模型能力。数据合成方法模仿专家程序员的认知工作流程,分为三个关键阶段:仓库理解、故障定位和补丁生成。
仓库理解阶段专注于理解代码仓库的结构和内容,这是问题解决所需上下文的基础。仓库理解代理(RepoUer)采用层次化的方法,使用三种关键工具:仓库结构工具、导航仓库工具和代码压缩工具。首先,RepoUer 使用仓库结构工具创建简洁的目录结构表示。接下来,导航仓库工具用于遍历仓库并定位相关文件。然后,代码压缩工具将这些文件转换为骨架格式,保留全局引用、类定义、函数签名、相关注释和变量声明,从而有效减少上下文长度,同时保持必要的结构信息。最后作者根据文件形式定位潜在的故障位置,并生成最后的分析和规划。
故障定位阶段旨在识别代码库中的特定问题区域。该阶段使用故障定位器(FLer),模拟开发者在解决问题时的诊断步骤,结合工具使用与迭代问题解决。具体来说,FLer 首先使用专门的搜索 API 检索相关代码片段(比如 search_function('init')),然后执行 API 工具获取对应的代码片段并进行上下文分析,理解代码库内的关系和依赖。最后 FLer 自主进行多轮关键信息的搜索直到定位到具体的故障位置。
补丁生成阶段由补丁生成代理(Coder)执行,生成并应用补丁以解决定位的问题。该过程涉及补丁的生成以及使用 git 相关操作和代码检查工具来实施和验证更改。Coder 首先根据问题描述和已识别的故障代码片段生成具体解决方案。若生成的补丁未符合规定格式或在应用时存在语法错误,Coder 会根据错误类型进行调试,直至生成正确格式的补丁或达到最大重试限制。
通过增强每个阶段的详细中间推理步骤,并结合开发实践的软件工具,SWESynInfer 为软件维护和演化过程提供了更全面和现实的模拟。这种方法能够生成高质量的训练数据,捕捉软件开发中复杂的交互特性。
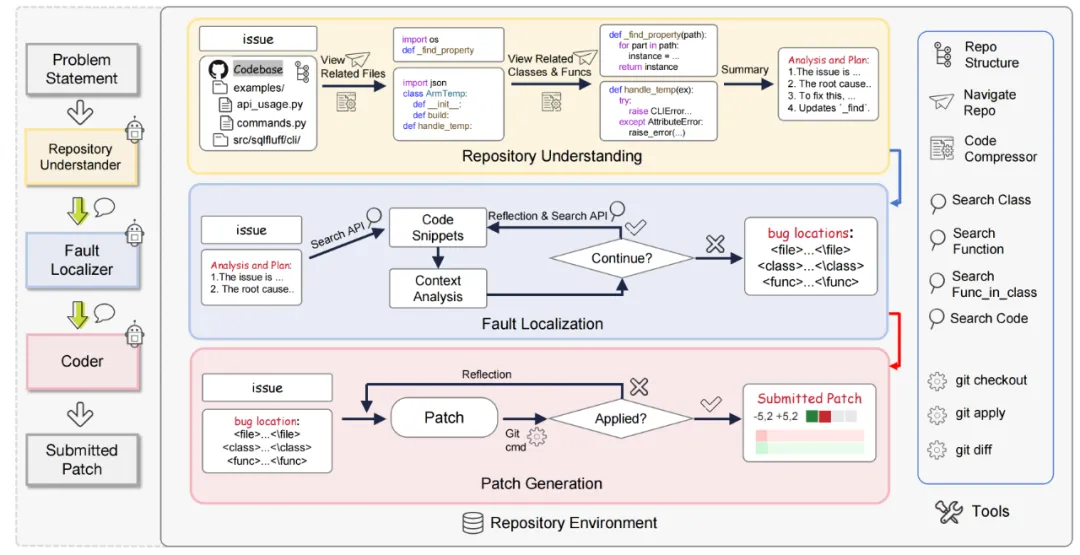
Figure 2 问题和相应的拉取请求数据采集过程示例
模型训练 (Figure 3)
在收集了一组训练样本后,作者实施了一种迭代优化策略来训练模型。在每次迭代中,模型通过最大化生成目标链式推理和相应动作的条件概率来优化其性能。为了增强训练过程的鲁棒性,作者采用了课程学习的方法,随着迭代的进行,逐步加入当前模型未能解决的问题,逐渐提高训练样本的复杂度。这种方法使模型在处理更复杂的挑战之前,先在简单任务上建立稳固的基础。
作者还采用了一种拒绝采样过程,以确保合成数据的质量,选择保留与现实世界软件开发实践高度相似的高质量实例,保证训练数据的可靠性。拒绝采样基于故障定位准确性和补丁相似性两个关键指标对数据实例进行筛选。
故障定位准确性
作者首先评估模型预测的故障位置与实际故障位置之间的相似性。具体步骤如下:
提取实际故障位置:从提交的补丁中提取修改位置,作为实际故障位置。这一过程包括将补丁映射到当前版本的代码库,并使用抽象语法树(AST)提取相应的函数和类。对于全局代码修改,作者选择修改行的上下三行作为修改位置。
计算准确性:作者使用 Jaccard 相似性系数来量化故障定位的准确性,即计算两个修改位置集合的交集大小与并集大小的比率。如果计算得出的比率超过预设阈值,则认为故障定位足够准确。
补丁相似性
为了评估模型生成的补丁与开发者提交的补丁之间的相似性,作者采用了以下步骤:
规范化补丁:首先,对模型生成的补丁和开发者撰写的补丁进行规范化,以忽略表面差异(如额外空格、换行和注释)。
相似性计算:使用 n-gram 和 CodeBLEU 分数来评估两者之间的相似性。如果任一相似性得分超过预设阈值,将保留该补丁。
🔐 满足上述两个标准的数据实例将被添加到训练批次。对于那些能够准确定位故障但生成不相似补丁的实例,作者保留故障定位步骤,同时移除与补丁相关的操作,从而保留有价值的中间推理。通过这些严格的过滤标准,保证合成数据与现实软件开发实践紧密相关,并确保中间推理过程的可靠性。
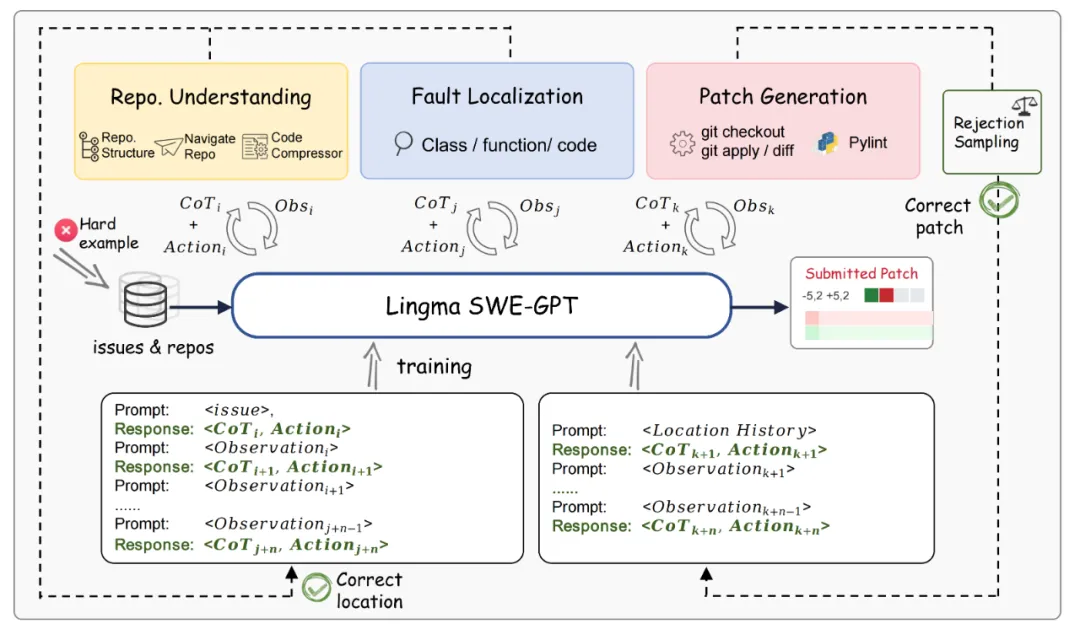
Figure 3 模型训练过程示例
实验结果
为了评估 Lingma 语言在解决现实世界 Github 问题中的能力,作者回答了以下研究问题。
RQ1:Lingma SWE-GPT 在解决 Github issue 能力上与最先进的模型相比如何?
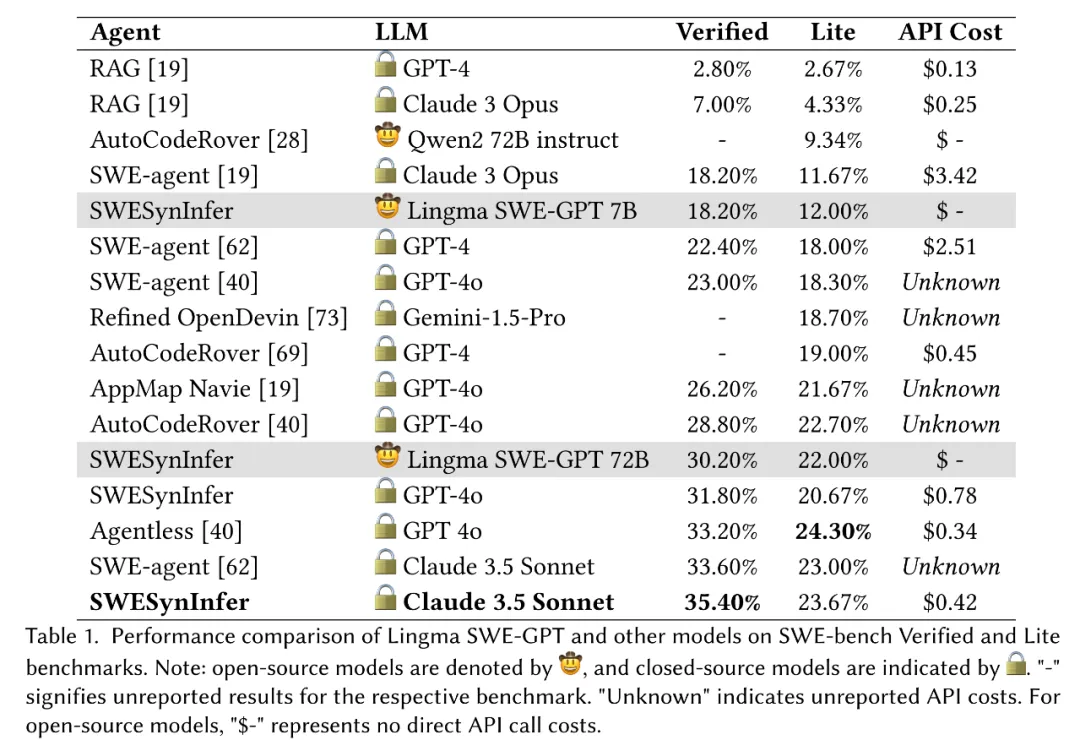
Table 1 展示了 Lingma SWE-GPT(7B 和 72B)与各种最先进模型在 SWE-bench Verified 和 SWE-bench Lite 上的综合表现。实验结果揭示了一些重要的发现。
开源 vs. 闭源模型
从表 1 可以看到,表现最好的大多数提交模型都是基于闭源模型。例如,基于 Claude 3.5 Sonnet 的 SWE-agent 在 Verified 和 Lite 基准上的成功率分别达到了 33.60% 和 23.00%;同样,结合 GPT-4o 的 Agentless 在 Verified 上解决了 33.20% 的问题,在 Lite 上解决了 24.30%。这些结果凸显了闭源模型在复杂软件工程任务中的主导地位。相比之下,开源模型的表现往往逊色于闭源模型。例如,AutoCodeRover 使用 Qwen2 72B instruct 在 SWE-bench Lite 上的成功率仅为 9.34%,而在相同框架下使用 GPT-4o 时则能解决 22.70% 的问题,显示出显著的性能差距。
Lingma SWE-GPT 结果表现
Lingma SWE-GPT 72B 在性能上表现出与最先进闭源模型具有一定的竞争力。在 SWE-bench Verified 基准测试中,它成功解决了 30.20% 的问题,接近 GPT-4o 在相同推理过程中的 31.80% 的成功率。这是首次有开源模型在解决这些复杂软件问题时超过 30% 的成功率。作者会继续推动 Lingma SWE-GPT 开源模型的持续改进。
RQ2:与开源模型相比,Lingma SWE-GPT 在自动程序改进任务上的性能如何?
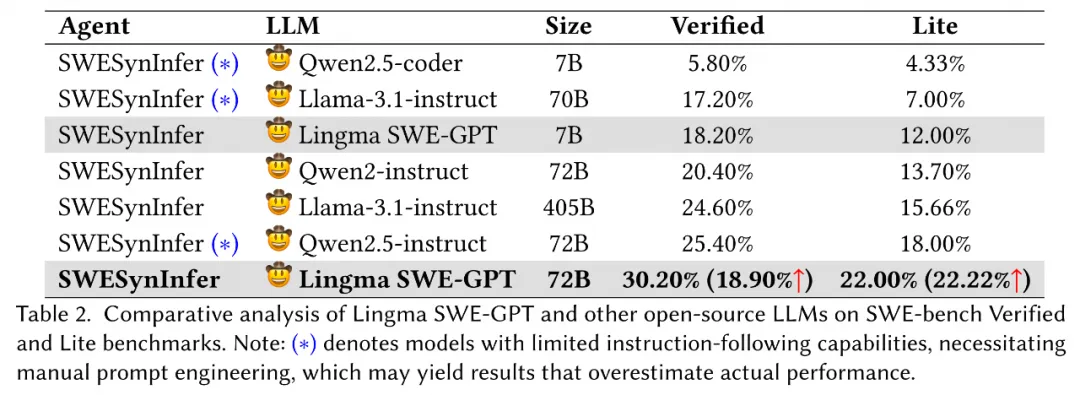
为了评估 Lingma SWE-GPT 在自动化程序改进任务中相对于当前最先进开源模型的性能,作者在不同模型上采用了相同的推理过程(SWESynInfer)进行全面分析。表 2 展示了该对比的整体结果。
实验挑战与设置
在评估过程中,作者遇到了开源模型的一些挑战,主要是它们在执行复杂任务时的指令跟随能力较差。为了更好地评估这些模型在软件工程任务中的有效性(而非其一般的指令跟随能力),作者对 SWESynInfer 针对部分开源模型进行了特定的提示工程和工具定制。表 2 中的 (∗) 表示经过了调整的推理流程。
SWE-bench Verified 上的结果
实验结果显示,Lingma SWE-GPT 72B 在性能上显著超越了最新的开源模型,包括 Qwen2.5-instruct 70B 和最大的开源模型 Llama-3.1-instruct 405B。在 SWE-bench Verified 上,Lingma SWE-GPT 72B 的成功率达到了 30.20%,相较 Qwen2.5-instruct 72B 的 25.40% 相对提高了 18.90%,相较 Llama-3.1-instruct 405B 的 24.60% 相对提高了 22.76%。
值得注意的是,即便是较小的 Lingma SWE-GPT 7B 模型也超过了 Llama-3.1-instruct 70B(在 SWE-bench Verified 上为 18.20% vs 17.20%,在 SWE-bench Lite 上为 12.00% 对 7.00%)。这一结果表明,经过高质量的过程导向数据训练的较小模型也能实现有竞争力的性能。
模型的互补性
图 3 展示了不同模型在解决问题时的重叠和独特性,呈现为维恩图。Lingma SWE-GPT 72B 独立解决了最多的独特问题(34 个),展现了其在软件工程流程中的优异理解和分析能力。此外,Lingma SWE-GPT 7B 解决了 7 个其他模型未解决的任务,超越了 Llama 3.1 70B-instruct 的 5 个独立解决任务,显示出小型模型的潜力。维恩图还揭示了不同模型间的一定互补性,每个模型都解决了一些独特的问题。这表明未来在模型集成方面有进一步的研究潜力。
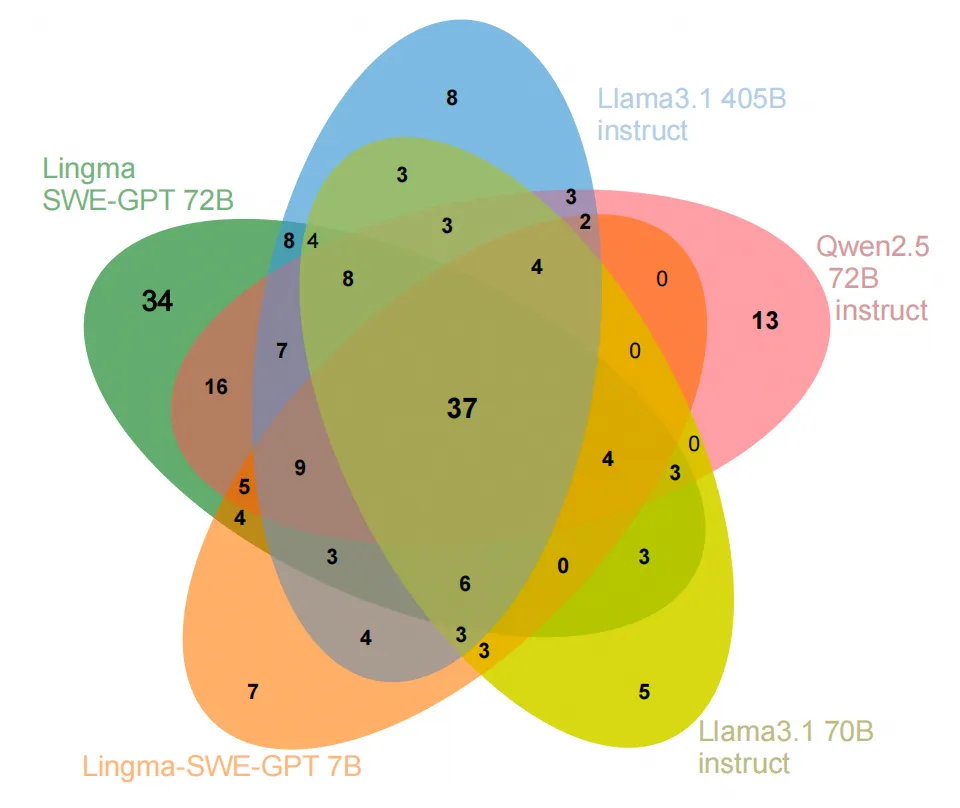
Figure 3 不同模型解决任务实例的分布
RQ3:Lingma SWE-GPT 在解决问题所需的关键步骤(故障定位)中能力如何?
故障定位是解决实际开发场景中软件问题的关键步骤。准确识别编辑位置不仅对自动化问题解决至关重要,还能为人类开发者提供调试任务的有效支持。为了评估 Lingma SWE-GPT 的故障定位能力,作者进行了全面分析,将各模型生成的补丁位置与实际补丁位置进行了对比。
评估方法
作者采用了一套严谨的流程确保评估的全面性。首先,将补丁映射到仓库的当前版本,利用抽象语法树(AST)提取对应于修改位置的函数和类。在代码块级别的分析中,作者不仅关注函数 / 类的修改,还包括全局代码更改的位置。具体来说,作者将修改行的上下三行视为全局代码修改位置。虽然故障代码可以在与实际补丁不同的位置修复,但与实际补丁位置的对比可以作为一种有效的近似衡量标准。表 3 展示了各模型在代码块、函数和文件级别的定位准确率。
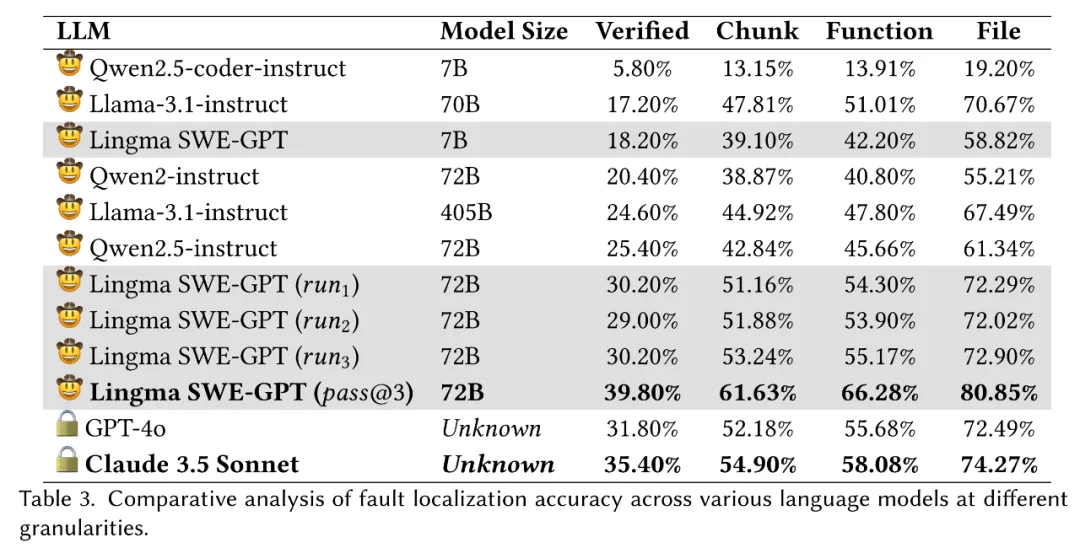
实验结果与分析
Lingma SWE-GPT 在所有粒度级别(代码块、函数和文件)上的故障定位能力显著优于其他开源模型,且其表现接近闭源模型 GPT-4o,进一步证明了其在故障定位方面的有效性。此外,作者观察到故障定位成功率与问题解决率之间存在正相关关系,这表明准确的故障定位对成功解决问题起着至关重要的作用。
然而,即使是表现最佳的模型 Claude 3.5 Sonnet,在代码块和函数级别的定位准确率也只有 54.90% 和 58.08%。这一观察表明,故障定位仍然是自动化问题解决中的一大挑战。未来的研究可以在此基础上进一步提升故障定位技术,比如通过增强代码理解机制或采用更复杂的静态和动态分析方法,来提升模型在实际开发场景中的表现。
后续工作
未来,作者计划进一步扩展 Lingma SWE-GPT 的功能和应用范围。首先,增加对更多编程语言的支持,包括 Java、JavaScript(JS)和 TypeScript(TS),以覆盖更广泛的软件开发场景。其次,作者还将探索支持更多的端到端软件工程任务,不仅限于问题修复和功能增强。这些改进将使 Lingma SWE-GPT 更加通用和强大,能够在多种开发环境和任务中提供全面的智能支持,从而更好地满足开发者的需求,推动 AI 辅助软件工程的进一步发展。
结论 - Lingma SWE-GPT 为 AI 辅助软件工程带来的创新
在本文中,作者介绍了 Lingma SWE-GPT,一款专为解决复杂软件改进任务设计的开源大型语言模型系列。该系列包含两个不同的模型版本:Lingma SWE-GPT 7B 和 Lingma SWE-GPT 72B,分别满足不同的计算资源需求,同时保持高效性能。通过专注于模拟软件开发的动态特性,包括工具使用推理和交互式问题解决能力,Lingma SWE-GPT 与仅依赖静态代码数据训练的模型区别开来。
作者在具有挑战性的 SWE-bench Verified 和 Lite 基准测试上验证了 Lingma SWE-GPT 在自动化软件改进中的有效性。Lingma SWE-GPT 72B 一直优于现有的开源模型,并接近闭源模型的表现,在 SWE-bench Verified 上达到了 30.20% 的成功率。值得注意的是,7B 版本解决了 18.20% 的问题,展示了小型模型在资源受限环境中的潜力。
Lingma SWE-GPT 在代码块、函数和文件级别上展现了出色的故障定位能力。模型在多次运行中保持稳定性能,并通过 pass@3 方法显著提升,凸显了其可靠性及在自动化软件工程中的模型集成潜力。随着通义灵码团队持续优化和扩展其能力,Lingma SWE-GPT 将在支持开发者、提升生产力和改善软件质量方面发挥越来越重要的作用,推动 AI 辅助软件工程领域的发展。
详细方案请参考论文:
Lingma SWE-GPT: An Open Development-Process-Centric Language Model for Automated Software Improvement
arxiv📄: https://arxiv.org/pdf/2411.00622




