
据 Anthropic 称,最新版本的 Claude 大模型为企业提供了许多“关键特性方面的进步,包括行业领先的 200K token 上下文窗口、模型幻觉率显著降低、系统提示词以及我们新开发的测试功能:支持外部工具”。Anthropic 还宣布了降价措施,以提升各款模型用户的成本效益。
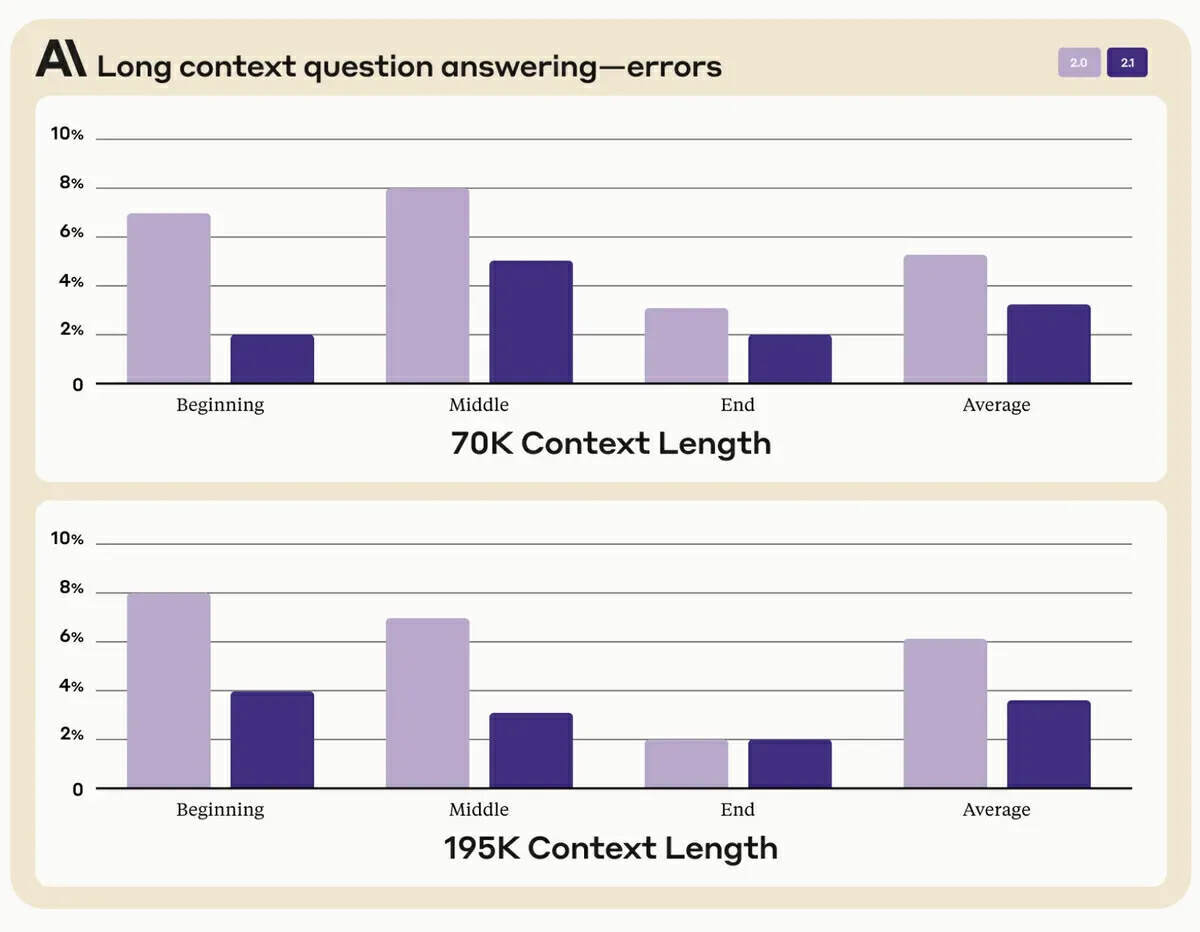
增强的上下文窗口是 Claude 2.1 的一项亮点特性,其拥有 200,000 个 token 的容量,超过了 OpenAI 的 GPT-4,后者提供了 128,000 个 token 的窗口。Anthropic 表示,与之前的模型相比,新模型输出虚假陈述的可能性更小。Claude 2.1 会试图避免不正确的答案并承认一些问题存在不确定性,它输出相关答案时一般会选择提出质疑,而不是提供不正确的信息。Anthropic 表示,该模型输出的错误答案减少了 30%,并且模型错误地作出缺乏信源的判断的比率大大降低。
另一个值得注意的新增特性是 Claude 2.1 使用工具并与 API 交互的能力。该功能让模型能够利用计算器、数据库等外部资源,甚至执行网络搜索来更有效地响应查询。它还可以集成到用户的技术栈中,从而在各个领域中实现更多样化的应用。
此外,Claude 2.1 引入了系统提示词,使用户能够为其请求设置特定的上下文。此功能可确保模型的响应更加结构化且前后一致。现在模型的价格定为输入的提示词每百万 token 8 美元,模型输出则是每百万 token 24 美元,这样包括开发人员和企业在内的很多用户群体都能负担得起了。
一些用户对新模型的评价褒贬不一。从积极的一面来看,一些用户发现 Claude 2.1 非常适合聊天和摘要等任务,并赞扬了它的进步和功能改进,特别是在摘要任务方面。然而,其他用户也对该模型的拒绝响应情况和严格的审查表示失望,一些用户认为这让这款工具的实用性和自主性打了折扣。此外,由于严格的安全协议和内容指南,人们担心 Claude 在处理某些内容(例如学术或研究材料)方面存在局限性。

发现:
在 200K 个 token(近 470 页)的情况下,Claude 2.1 能够回忆起某些文档级深度的事实
文档最顶部和最底部的事实被回忆的准确率接近 100%
位于文档顶部的事实的回忆性能低于底部(类似于 GPT-4)
从 ~90K token 开始,文档底部的回忆性能开始变得越来越差
无法保证短上下文长度下的性能 - Greg Kamradt
Anthropic 及时推出 Claude 2.1 的时机恰逢 OpenAI 的内部冲突时期,后者导致 ChatGPT Plus 订阅暂停购买,首席执行官 Sam Altman 也陷入了风波。尽管如此,Devin Coldewey 写道,“不管怎样,GPT-4 仍然是代码生成领域的黄金标准,Claude 处理输入请求的方式与竞争对手是不一样的,有些更好,有些更差。”
想要了解更多关于 Claude 2.1 细节的用户可以参考 Anthropic 网站上的模型介绍页面。 Anthropic 还制作了一个示例存储库,演示如何使用工具功能。
原文链接:
https://www.infoq.com/news/2023/11/anthropic-announces-claude-2-1/




