作者 | 林琳、王小童
华为是全球领先的 ICT(信息与通信)基础设施和智能终端提供商。终端业务是华为三大业务之一,其产品全面覆盖手机、个人电脑和平板电脑、可穿戴设备、移动宽带终端、家庭终端和消费者云等。华为终端云服务是为华为终端用户提供围绕数据、应用、出行、娱乐等众多场景的数字生活体验的功能与服务的统称,其业务覆盖华为云空间、华为智能助手、华为应用市场、Huawei Pay、华为天际通、华为视频、华为音乐、华为阅读、华为主题和生活服务等智慧云服务。
华为云终端将消息系统从 Kafka 迁移到 Pulsar,并基于 Pulsar 打造中台应对消息系统面临的挑战。本文整理自 ApacheCon Asia 2022 上,来自华为终端的林琳、王小童关于《华为终端云基于 Apache Pulsar 的消息队列演进》的分享,将介绍 Apache Pulsar 在华为终端云中台建设部署实践的过程中面临的挑战与解决方案。
面临的挑战
华为终端云选择消息系统面临的挑战主要有:
1. 多集群的运维复杂度高。我们需要满足多样化业务场景需求(手机推送、游戏中心、应用市场等),但团队不想维护多种类型的消息队列集群。理想的消息队列集群应该具备出色的性能,并能具备足够多的高级业务特性,如:
延迟消息——实现任意时间维度的消息延迟投递;
死信消息——消息被多次消费失败后,自动投递到其他队列,避免阻塞当前队列消费;
海量分区——单集群能承载海量分区,避免分区过多影响性能。
2. 集群应该具备与云原生环境适配的伸缩能力:
在云原生环境下做到秒级伸缩;
伸缩过程对业务无感知,不会影响业务;
伸缩过程避免数据复制,即使有复制也不能影响集群可用性。
3. 容灾建设困难:
在单集群跨 AZ(Availability Zone,可用区)容灾场景中,存在因网络延迟导致的性能下降的问题;
在多集群跨 AZ 主备容灾场景中,资源闲置率很高。
4. 资源利用率低:
计算资源利用率低:为了解决不同业务间相互影响的问题,通常不同的业务会使用不同的集群实现物理隔离,而单个集群的平均计算资源利用率很难提升;
存储资源利用率低:为了避免出现因业务突发流量导致磁盘空间不足的问题,每个集群都需预留冗余磁盘空间,导致整体磁盘利用率不高。而消息系统又是磁盘消耗大户,导致整体建设成本居高不下。
华为终端云做了很多优化工作应对上述挑战。接下来我们逐一分析。
基于 Apache Pulsar 的解决方案
消息队列中台化
当前,华为终端云的消息队列广泛应用于服务间的生产系统。常见业务场景包括服务间异步解耦、 海量 Topic、大数据日志流接入与分析等。我们希望使用一套架构应对大部分业务场景,减少消息平台的开发维护投入。因此我们基于 Apache Pulsar 构建了消息队列中台,实现了一套集群支持多种客户端接入。该中台具备以下特性:
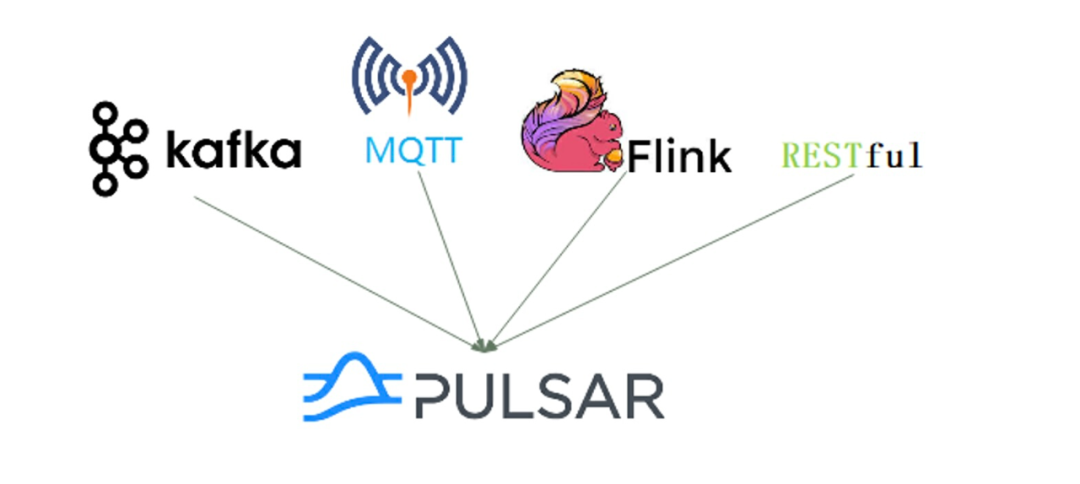
1. 多场景适配:基于 Pulsar 构建的消息中台支持 Kafka、Flink、RESTful 等多协议接入,只需维护一套 Pulsar 集群。中台还支持各个数据接入源的常用认证鉴权机制。
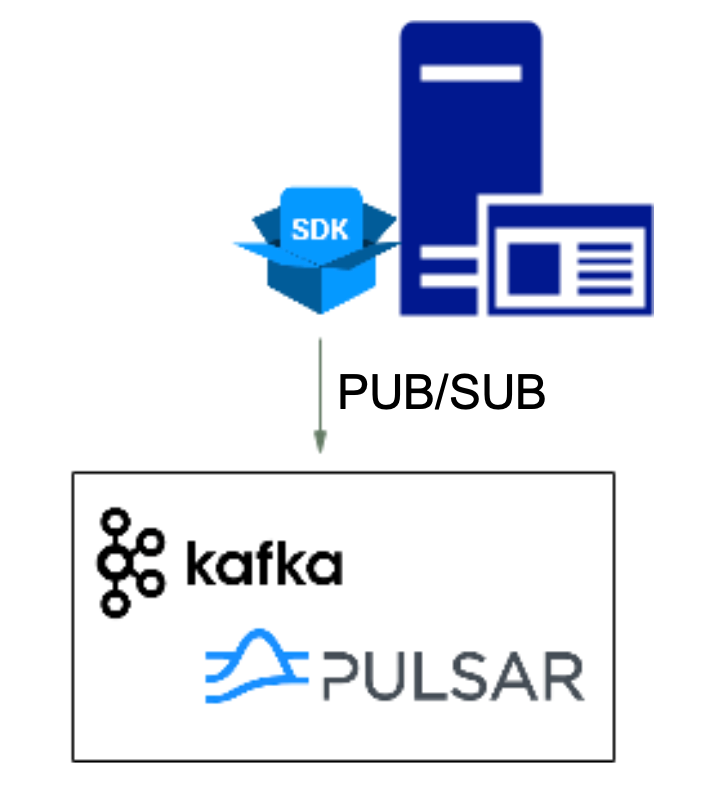
2. SDK 接口统一:为了避免不同协议客户端导致业务复杂度上升,我们提供了一个统一的 SDK,封装了标准 PUB/SUB 等接口,业务无需感知服务端是使用 Kafka 还是 Pulsar。后续即使更换消息中间件内核也不涉及业务代码的修改。
3. 提供高级业务特性:此前,业务为了保证消息系统的高性能,又想使用高级业务特性,如延迟消息、死信消息等,不得不维护多种消息系统各司其职。而切换到 Pulsar 后,除了能保证不逊色于 Kafka 的高性能,还天然支持各种高级业务特性。我们还一直与社区保持沟通,正在支持超大量级延迟消息。
适配云原生环境
之前我们采用 Kafka 承载消息队列平台,但随着平台的全面容器化, Kafka 逐渐无法适应当前的需求,特别是 Kafka 扩容节点需要人工干预、迁移分区数据才可释放存储空间。这意味着数据量越大,耗时越长,且与业务争抢资源,影响客户端消息读写,整个迁移过程都需要人工值守。
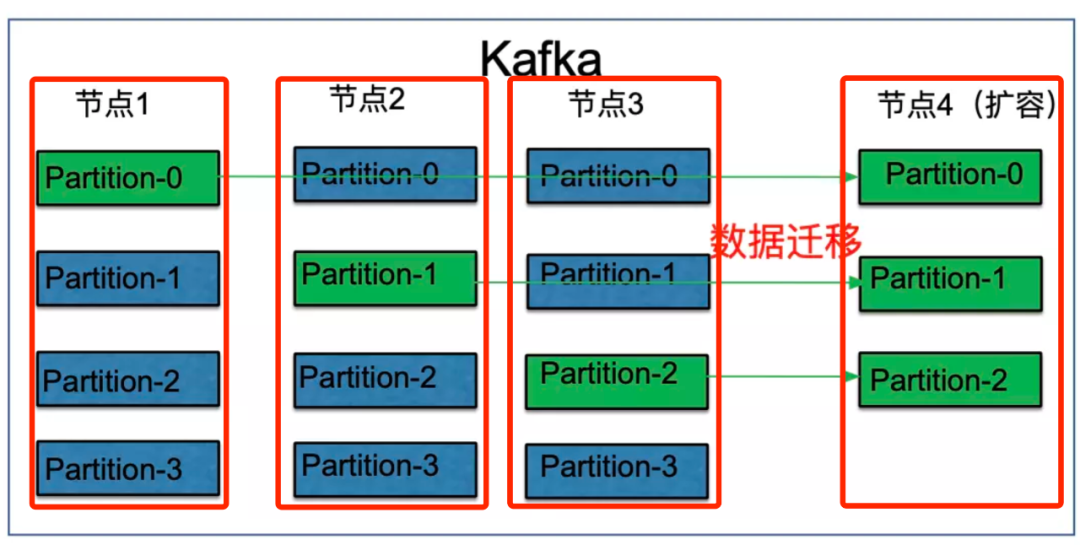
相比之下,Pulsar Bookie 节点扩容无需迁移数据,新的数据可以直接选择新的 Bookie 节点写入,且写入的 Bookie 节点会从 Bookie 池选择,均衡分配到所有节点,老节点的数据可通过等待数据过期后平滑删除。相比 Kafka 扩容迁移数据数小时的耗时,Pulsar Bookie 节点扩容只需几分钟的时间。
在流量动态均衡方面,Kafka 分区 Leader 与 Broker 节点绑定,流量不均衡时需要人工进行迁移分区副本、修改分区 Leader 等操作。Pulsar Broker 可根据平均值、最大阈值等算法动态均衡分区,确保流量在集群内相对均衡。但在实践中,我们发现基于均值的均衡模式也存在一些问题。例如重启节点会持续空闲无流量等。目前团队已针对该场景优化了算法,待内部测试验证效果后,将提交到社区。
更简单的容灾建设
使用 Kafka 时的容灾方式没有太多的选择,平台使用默认 3 副本 + “Ack = All” 的方式。Broker 集群分布在 3 个 AZ 上,并开启机架感知。每个 Topic 的副本均匀分布在 3 个 AZ 对应的 Broker 上。这意味着 3AZ 都涉及跨 AZ 数据同步,且数据写入需要等待所有跨 AZ 数据同步完成后才返回响应。这一设计的优点是高可靠,但缺点也十分明显,跨 AZ 同步的性能和时延存在较大波动。
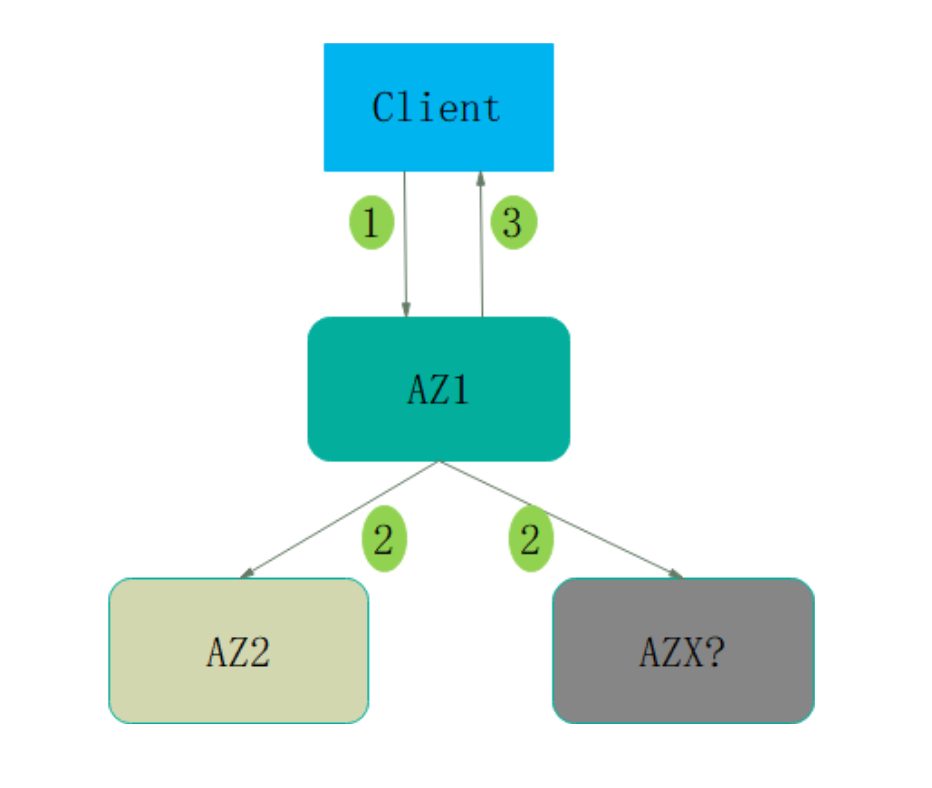
以下是 Pulsar 高可靠组网(跨 3AZ)的架构:
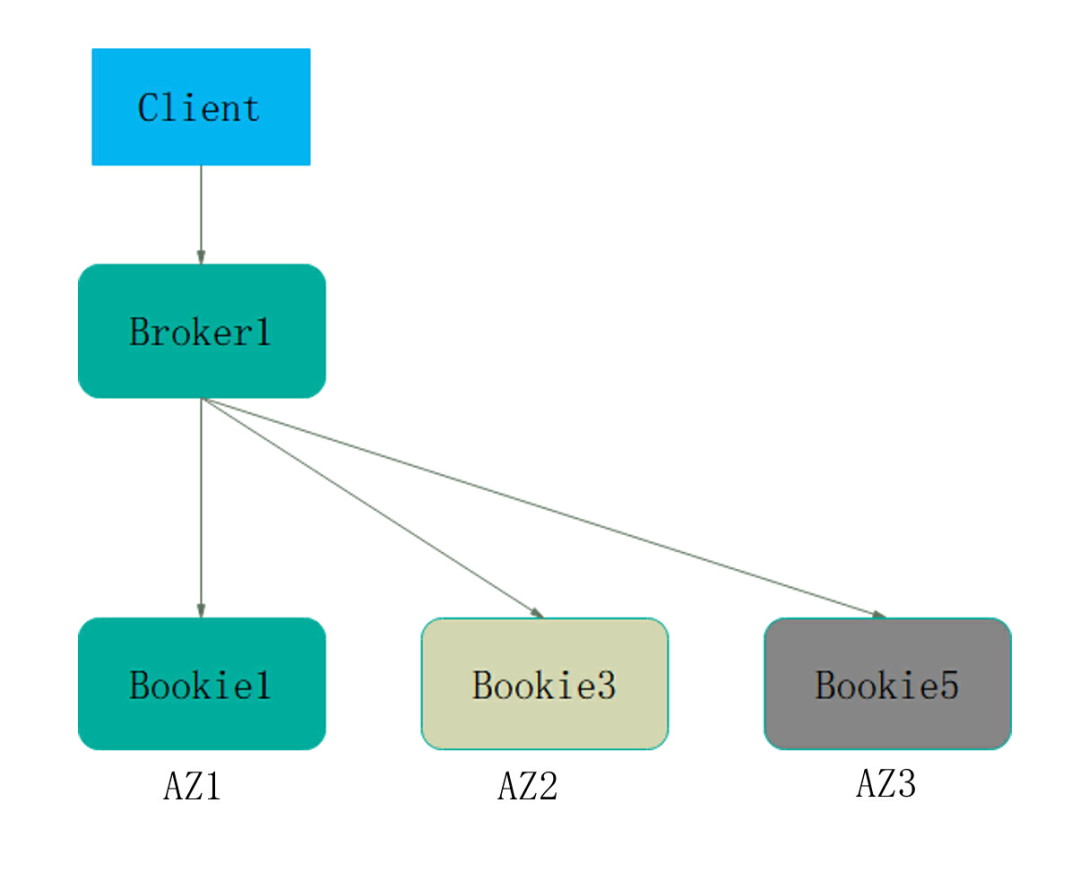
当 Broker 保存数据时,Bookie 选择规则是:任意选择一个可用 Bookie 为 Bookie1;排除 AZ1 的 Bookie,从 AZ2 和 AZ3 中任意选择 1 个 Bookie 为 Bookie3;排除 Bookie1 和 Bookie3 对应的 AZ1 和 AZ2,从剩余的 AZ3 中选择 Bookie5。三个 Bookie 分别落在三个 AZ 上。在 AZ1(Bookie1)、AZ2(Bookie3)、 AZ3(Bookie5)、Ack = 2 的情况下,数据写入到 2 个 AZ 后才认定成功。
我们在 Pulsar 已有机架感知的基础上又做了优化:
1. 在社区版本的基础上优化了跨 AZ 的标签能力,支持给 Broker 添加 AZ 标签,进而在选择 Bookie 时可支持单元化能力
2. 在 AZ 级故障场景中发生单 AZ 故障时,数据分布选举自动降级为 2 个 AZ 选 3 个副本
3. 允许从少于过半数的 Bookie 节点集合中读取数据
相比此前需要 3 个 AZ 全部写入成功,Pulsar 受 AZ 间网络波动的影响也会更小。
资源利用率提升
共享逃生池
无论跨多少 AZ,当出现集群级别的软件故障时,整个集群都是不可用的。因此有些对可用性要求很高、但允许少量数据不一致的业务,会在一个独立 AZ1 中部署一套集群,并在另一个 AZ2 中部署对等的逃生集群,保证 AZ1 故障时消息队列通道可用。当 AZ1 故障时客户端主动切换到 AZ2 逃生通道集群,AZ1 恢复时再回切。这两个集群默认不做数据同步,不保证数据一致性。
逃生通道仅用于节点出现不可自动恢复的软件故障、磁盘满未及时扩容和多 AZ 机房故障等问题下的紧急逃生,确保业务消息队列通道可用,不阻塞业务调用。这样虽然可以保证超高的可用性、性能以及时延稳定,但容灾成本较高。
Pulsar 社区版本 SDK 已经支持集群级别的切换,但是 1:1 的对等逃生集群成本仍然无法控制。针对上述业务需求,华为终端云消息中台基于 Pulsar 重新完善了集群切换能力。Pulsar 的容灾逃生架构如下:
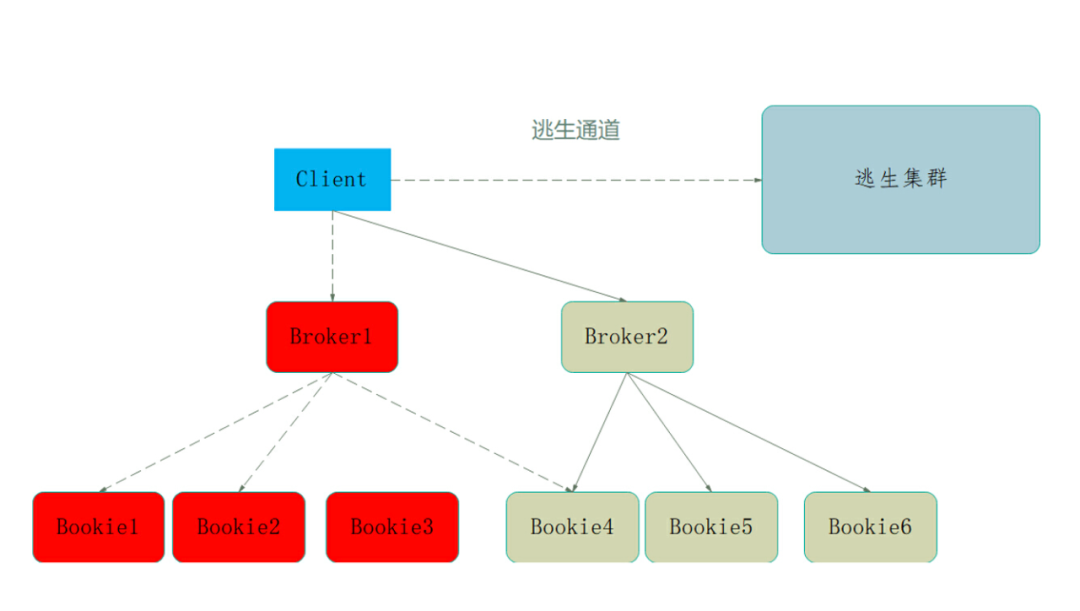
Pulsar 集群虽然是跨 AZ 部署,但是配置了机架感知,要求必须有副本落入另外一个 AZ 才算写入成功。由于提供了标准 SDK,在此基础上很容易就实现了逃生集群的池化。同个服务可以多套主集群共享一套逃生集群,无需 1:1 建设,可以是 2:1、3:1 …,根据实际负载情况评估即可。相比 Kafka 容灾方案,Pulsar 方案的 CPU 使用率提升了 10% 以上,减少了空闲的容灾集群,且逃生集群池化后,其成本也下降了 20% 以上。
容器化与共享存储池
为了进一步的提升集群资源利用率,我们进行了容器化与共享存储池的探索。
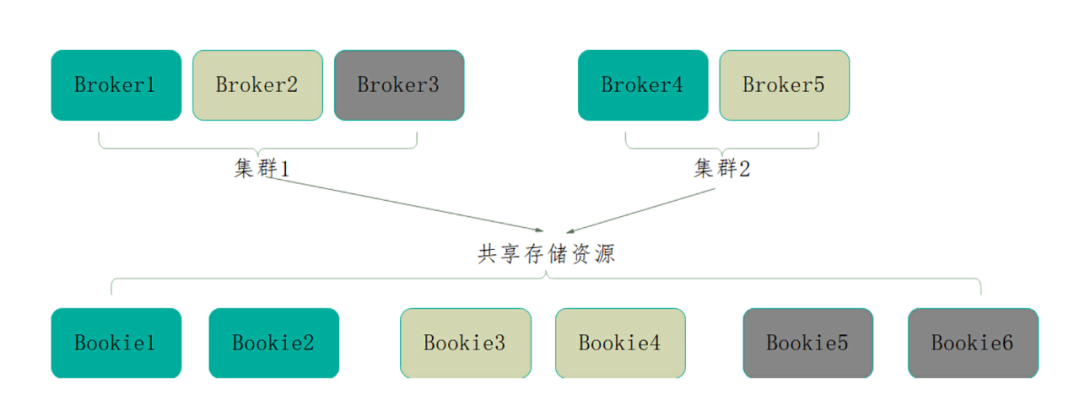
此前,服务有扩容需求时需要新搭集群,因此同一个服务可能有多套集群,各个集群的规格也不一定一致,不同集群间物理隔离,资源无法共享,因此单个集群的计算与存储资源利用率不足,且难以应对突发流量,经常需要人工进行集群调整。
借助 Pulsar 的存算分离架构(计算节点 Broker 无状态)很容易实现容器化管理。有状态的 Bookie 节点相对 Broker 而言是外部服务,数据存储在 Bookie 节点是通过元数据的方式保存在 ZooKeeper 中。
在此基础上可以实现 Bookie 存储资源的池化,并快速动态伸缩 Broker、Bookie 集群规模和节点规格,从而提升资源利用率。华为终端团队计划未来为 Pulsar 搭建统一的 Bookie 存储池,通过池化存储充分利用同一个服务下的存储资源,提升集群应对突发流量的弹性能力。
总 结
为了应对旧消息系统运维复杂度高、云原生环境适配难、容灾建设复杂、资源利用率低等问题,华为终端云从 Kafka 切换到 Pulsar 打造消息队列中台,成功实现了中台化、快速容灾建设、共享逃生池和容器化管理等功能,极大降低了消息系统的使用成本、提高系统性能。
作者简介:
林琳,华为终端 SDE 专家,Apache Pulsar PMC 成员,拥有 10 多年中间件与基础架构设计经验,致力于打造稳定可靠的基础设施。
王小童,华为终端云服务基础云平台资深工程师,负责分布式消息队列、分布式网关的设计演进。
今日好文推荐
腾讯QQ空间技术总监、47岁T13级前端专家被裁;GPT-4下周发布,支持视频、更具颠覆性;我国拟组建国家数据局 | Q资讯
马斯克被Twitter脆弱的代码“逼疯”,要求全部重写!网友:重构是空降领导了解当前系统最快的方式?