
1. 背景
机器翻译系统是使用深度学习技术从其支持的语言中翻译大量文本的服务。服务将 "源" 文本从一种语言转换为不同的 "目标" 语言。
机器翻译技术背后的概念和使用它的接口相对简单,但背后的技术是极其复杂的,并汇集了一些前沿技术,特别是深度机器学习、大数据、语言学、GPU 加速计算等。
大规模商业化使用的机器翻译主要经历了 SMT 与 NMT 阶段:
1.1 统计机器翻译(SMT)
机器翻译行业使用的比较早的技术是统计机器翻译 (SMT)。SMT 采用统计分析方法,根据源语言的语境,利用已有的双语语料学习到的短语翻译知识,将源语言的分隔片段短语转化为对应的目标短语,最后利用语言模型估计出一个句子的最佳可能译文。SMT 也是最早商用的机器翻译系统。
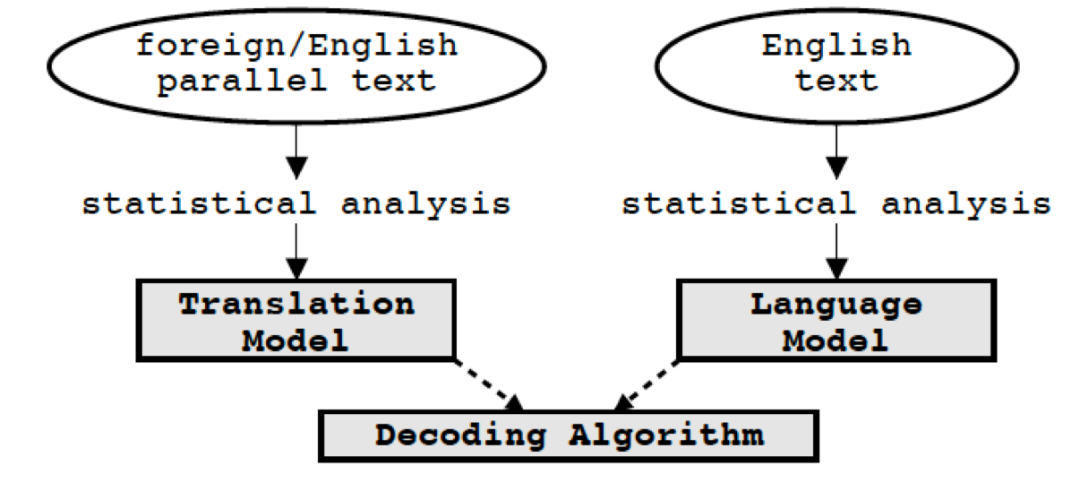
统计机器翻译结构
1.2 神经机器翻译(NMT)
神经机器翻译是利用深度神经网络将源句子进行编码,再进行解码翻译为目标语言。2016 年,Google 发表 GNMT[1],改变了 SMT 的地位,使翻译技术发生了根本性的转变,自此进入 NMT 时代,并且有了现在更高的翻译质量。
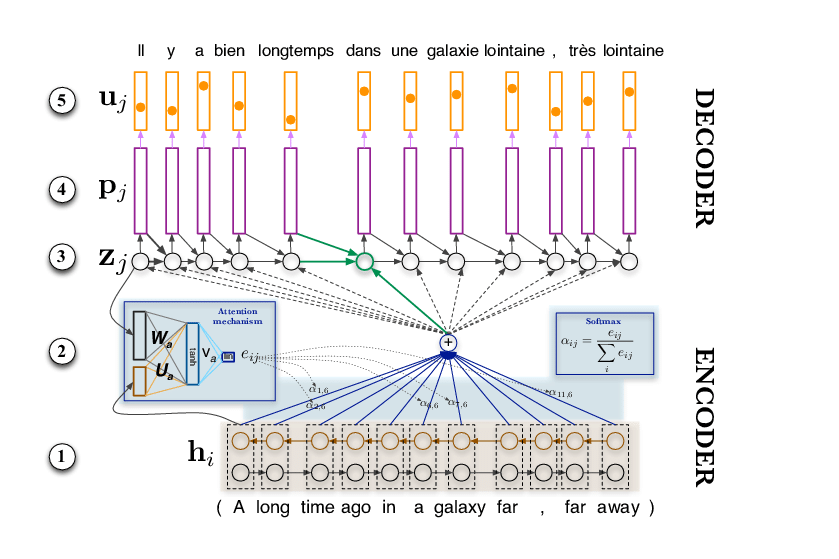
神经机器翻译结构
1.3 SMT 与 NMT 的相同点
两者都需要大量的标注数据(人类翻译内容 )来训练翻译系统。
两者不能用做双语字典。翻译是基于潜在翻译列表翻译单词,并根据句子中使用的单词的上下文进行翻译。
2. 评价指标 (BLEU)
对于机器翻译的结果,可以采用人工评估的方法,但是比较受限。首先是人工评估具有一定的主观性,其次每次训练结果需要人工评估成本较高。
因此诞生了一些使用机器进行评估的方法,评测关键就在于如何定义翻译译文与参考译文 (Reference) 之间的相似度。目前比较常用的方法为 BLEU[2] (Bilingual Evaluation Understudy),该方法由 IBM 提出,BLEU 采用的方式是比较并统计共现的 n-gram 词的个数,即统计同时出现在翻译译文和参考译文中的 n 元词的个数,最后把匹配到的 n 元词的数目除以翻译译文的单词数目,经过几何平均以及短句惩罚得到评测结果。这种方法的打分越高,则认为翻译系统的译文越接近人工翻译结果,即机器翻译系统的翻译质量越高。以下为标准的 BLEU score 的计算公式。

3. Transformer
3.1 简介
目前 NMT 的基本上都是 Encoder(源端语言编码)- Decoder(目标语言解码)框架,应用广泛的是 transformer[3]模型。Transformer 的编码器 Encoder 由 6 个相同的编码叠加而成,Encoder 中的每层包含 2 个子层:multi-head self-attention 和 FFN(Feed-Forward Network)。解码器 Decoder 也是由 6 个相同的编码叠加而成,每层包含 3 个子层:masked multi-head attention、multi-head attention 和 FFN。Transformer 结构参考下图:
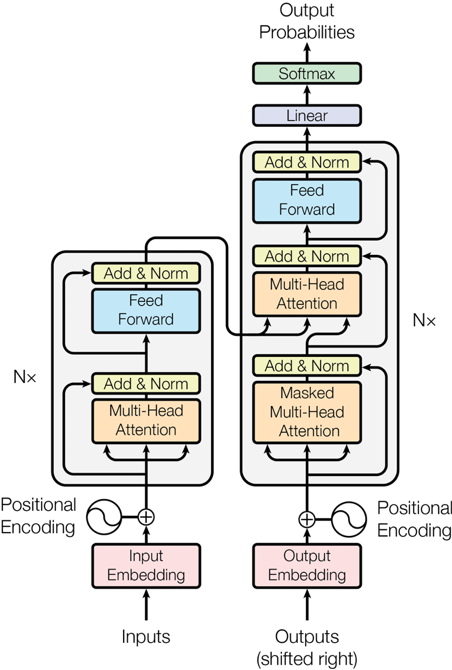
3.2 Transformer With Relative Position Representations
传统的 Transformer 通过将绝对位置嵌入作为输入的方式利用位置信息,这种方式并未在其结构中明确捕获信息。Shaw[4] 等人提出了将 Transformer 中的注意力机制和相对位置表达结合起来,并且在两个翻译任务上取得了比较好的翻译效果。我们进行了消融研究,发现具有相对位置嵌入的模型比传统的模型具有更快的收敛性和更好的性能。
3.3 Transformer with Larger FFN Size
在实际翻译模型中,采用了更大的 FFN size (8,192 or 15,000)。并且在实验中发现,在可控的网络大小的同时,模型的性能有了合理的提升。由于更大的 FFN size 容易过拟合,我们将 dropout rate 设置为 0.3。
4. 滴滴翻译实践
滴滴翻译主要以 Transformer-big (6 layers encoder & decoder, hidden size: 1,024, FFN size: 4,096, number of heads: 16) 结构作为基础模型,在此模型之上进行一系列的优化。以下为滴滴翻译整体框架图:
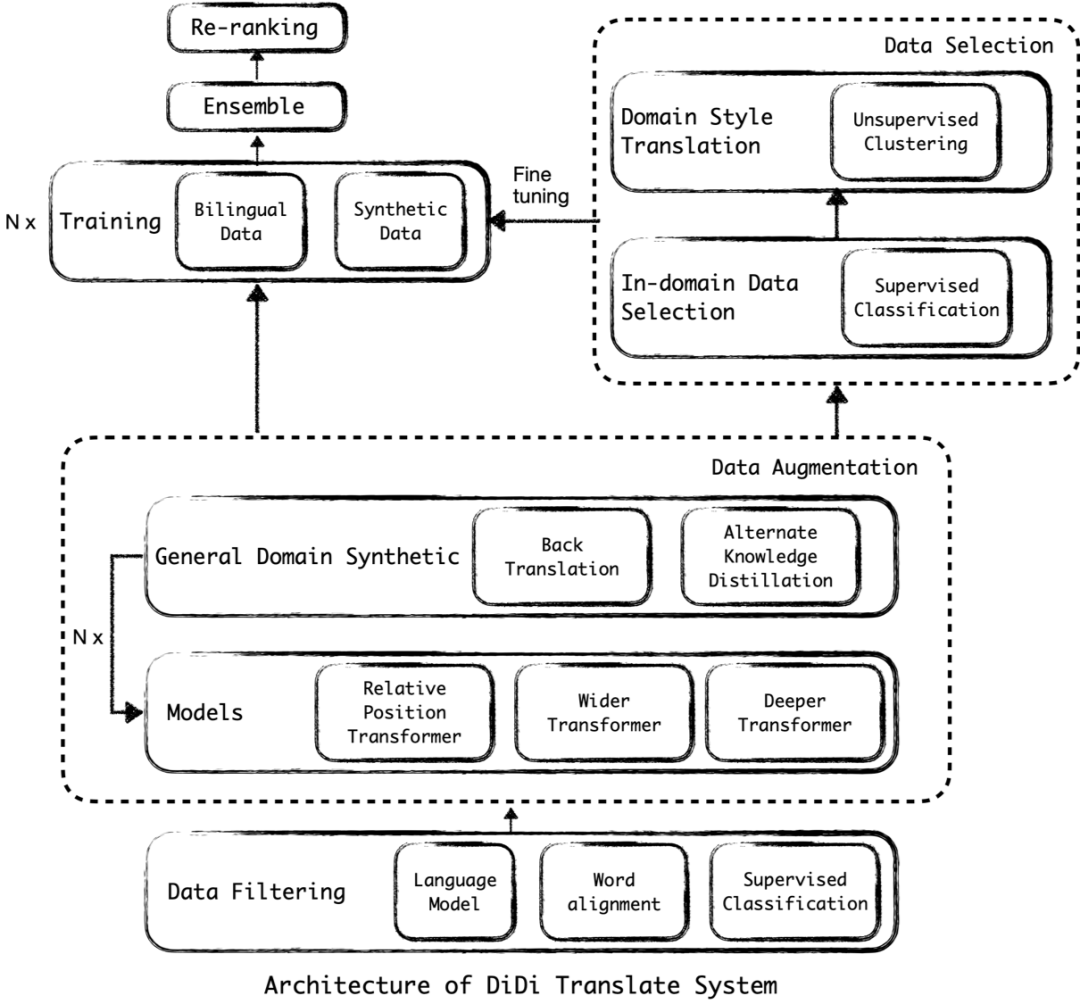
滴滴翻译整体框架图
4.1 数据准备
在机器翻译任务中,最重要部分就是对齐的双语语料,即需要原文与参考译文这种成对的双语数据。通常情况下,网络上存在的大都是单语语料。所以在任务开始之前,最主要的工作就是准备平行语料。
在滴滴翻译任务中,数据采集框架示意图如下图所示。
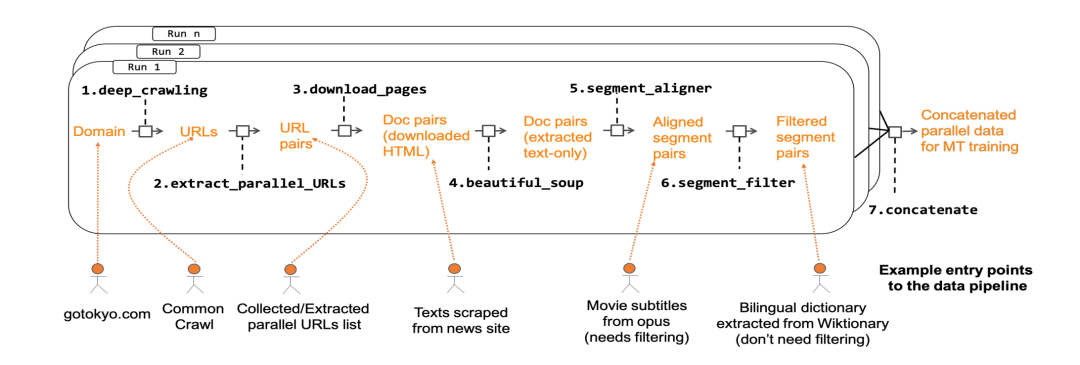
数据采集框架示意图[5]
数据准备工作主要分两大部分:
4.1.1 数据过滤
滴滴翻译会通过数据预处理 pipeline 在网络上收集原始的平行语料。对语言对使用 language model, alignment model[5] 进行打分,对于分数较低的语言对直接过滤,不参与后续的训练
4.1.2 数据增强
训练 NMT 模型需要大量的平行语料。但是,平行语料相对于网络上常见的大量单语数据要有限地多。Edunov[6] 等人在相关研究中展示了如何通过仅利用目标语言来提升模型的翻译性能,并且表明利用大量的相关数据可以大幅提升模型准确度。
通过单语语料提升模型效果的最有效的方法就是 back translation,假设目标是训练一个中译英模型,要利用 back translation,需要先训练一个英译中的模型,利用该模型将所有的单语目标语言(英语)翻译为中文获得新的平行语料,然后将该语料应用到中译英模型上。
在实际应用中,滴滴翻译采用了迭代式回译技术,以提高平行语料的质量。具体而言,在每次迭代中,目标语言到源语言模型负责使用目标语言单语数据为源语言到目标语言模型生成平行训练数据。同时,使用源语言到目标语言模型来使用源语言单语言数据为目标语言到源语言模型生成平行训练数据。目标语言到源语言模型和源语言到目标语言模型的性能都可以迭代地进一步提高。当无法实现进一步的改进时将停止迭代。
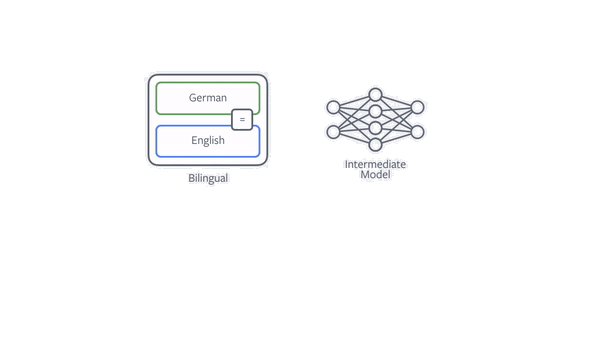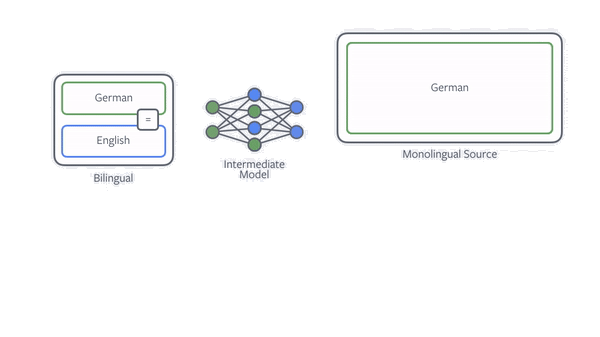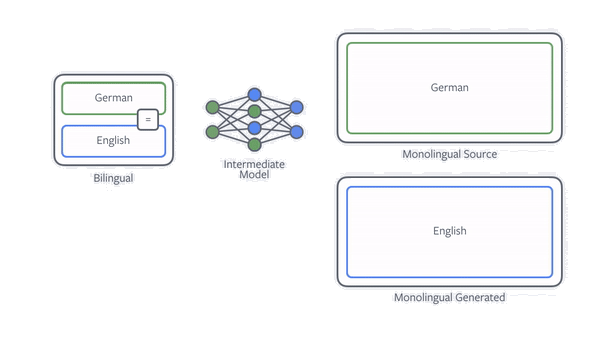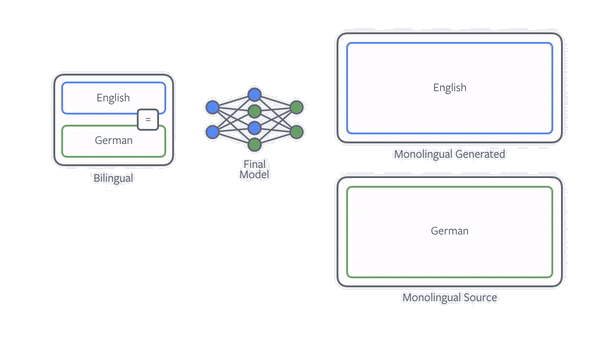
回译技术示意图
4.2 模型训练
4.2.1 交替知识蒸馏
滴滴翻译采用了交替知识蒸馏和迭代集成,以进一步提高单个模型的性能。滴滴翻译使用集成模型作为教师模型,并通过数据增强来提升单学生模型的效果。考虑到较差的老师模型会降低学生模型的效果,所以我们采用的是集成模型的方式训练学生模型。假设训练好三个单模型 (A, B, C) 之后,使用单模型 A&B ensemble 生成平行语料指导 C 模型的训练,同理使用迭代方式对三个学生模型进行蒸馏学习以达到最好的单模型效果。
4.2.2 Fine-tuning
在滴滴国际化消息翻译场景中,获得相关的翻译平行语料,利用 fine-tuning 的方式可以将 base model 快速的迁移到新领域,并且可以达到较高的模型效果。
4.2.3 Ensemble
模型集成是常见的提高模型效果的方案,该方案可以利用各个单模型的优势已达到最好的效果。在机器翻译的实践中,模型集成在序列预测的每个步骤中,将不同模型的目标词表的全部概率分布组合在一起进行投票。在初始模型较多的情况下,滴滴翻译使用 greedy search 的方式选择最优的单模型组合。
由于模型和数据的多样性是集成模型的重要因素,我们采用了不同的初始化种子,不同的参数,不同的 Transformer 变种和不同的训练数据集来训练各个单模型。
4.3 模型预测
4.3.1 模型训练与模型部署的区别
部署阶段的网络权值已经固定,无需反向传播过程
模型固定,可以对计算图进行优化 (TensorRT 会对一些网络层进行合并计算)
推断过程可以使用低精度的技术,可以加速推断,并减小模型大小。(FP32 -> FP16 Quantization)
4.3.2 模型预测加速
TensorRT 是 NVIDIA 推出的深度学习优化加速工具,采用的原理如下图所示:
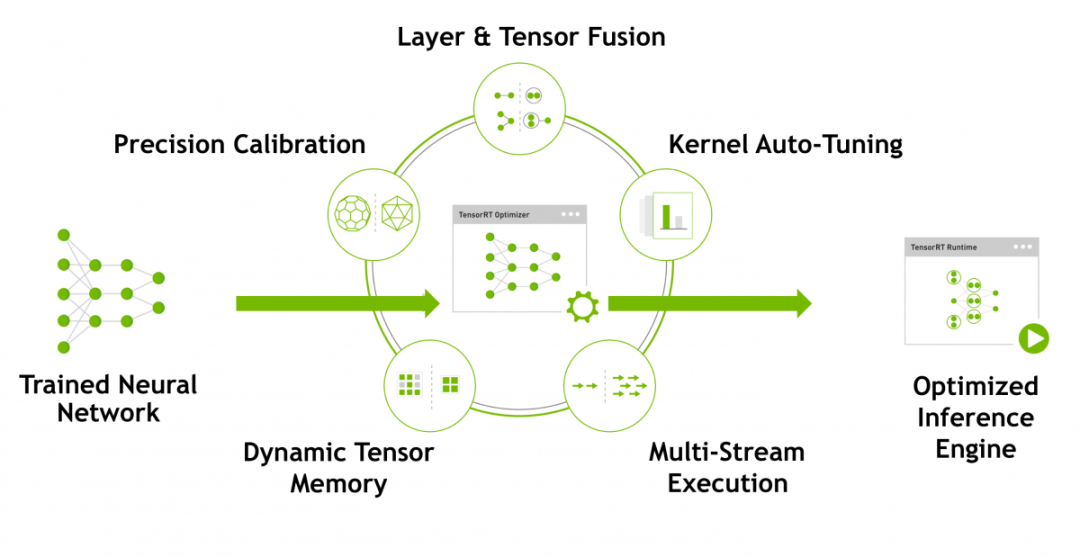
TensorRT 示意图
针对网络复杂,推理速度慢的问题,滴滴翻译将 Transformer 模型改造成支持 TensorRT 加速推理的框架。在实践中基于 TensorRT 框架的推理速度相较于原生 TensorFlow 模型提升了 9 倍。
5. WMT2020 机器翻译比赛
WMT (Workshop on Machine Translation) 是机器翻译领域认可度最高的国际顶级评测比赛,是由国际计算语言学协会 ACL(The Association for Computational Linguistics)举办的世界最具影响力的机器翻译大赛。从 2006 年创办至今,每年都会吸引包括微软、Facebook、DeepMind、百度、华为、腾讯、清华大学、上海交通大学、约翰霍普金斯大学、剑桥大学、爱丁堡大学等全球企业、科研机构以及顶级高校的参与。每次比赛都是各家机器翻译实力的大比拼,也见证了行业机器翻译技术的不断进步。
滴滴 NLP 团队参与的是 WMT2020 新闻机器翻译赛道(Shared Task: Machine Translation of News)。该赛道共设置了 22 项不同语言之间的翻译任务,其中,中文到英文翻译是竞争最激烈的任务,共吸引了 DeepMind、腾讯、华为、清华大学、上海交通大学等四十多支全球参赛团队参与,在 6 月 24 日至 6 月 30 日为期七天的比赛时间里,参赛团队累计共提交了近 300 次数据。
与往年不同,今年新闻中译英比赛参赛方均为匿名提交,比赛期间只能看到自己成绩以及其他匿名参赛方成绩,并且每个参赛方最多可以提交 7 次翻译结果,比赛结束后各参赛方不可再次提交,各参赛方从所有提交中选择其中一个提交结果作为 Primary Submission 供人工评估使用。
WMT 组委会为每个语言赛道提供指定的双语的训练集以及单语语料。参赛方可以根据自己的模型利用相关的训练集。比赛开始后组委会提供的单语的测试集 (Source),参赛方利用自己的模型对测试集的语言进行预测,然后提交至 OCELoT 系统。组委会利用 SacreBLEU1 指标对参赛方提交的译文与组委会未公开的标准答案 (Reference) 进行计算,分数越高代表翻译效果越好。
在本次中译英赛道中,滴滴 NLP 团队在技术上以 Transformer 结构作为基础,在结构上引入 Self-Attention, Relative Positional Attention, Larger FFN Size 等变化,利用迭代式回译技术 (Iterative Back-translation) 和交替知识蒸馏 (Alternate Knowledge Distillation) 方法生成高质量的合成语料,结合数据清洗、数据选择、模型集成等技术提高翻译质量。考虑到翻译话题对于翻译质量的影响,滴滴翻译还采用了领域迁移、话题挖掘和个性化加权的方式,使得翻译结果更加个性化。此外,我们还通过 EDA、权重剪枝等技术增强翻译模型的鲁棒性。最终滴滴翻译高效准确的进行完成 WMT2020 中译英赛道翻译任务,并且最先获得 36.6 的高分,最终获得第三名的成绩,充分彰显了滴滴在机器翻译领域的技术实力。
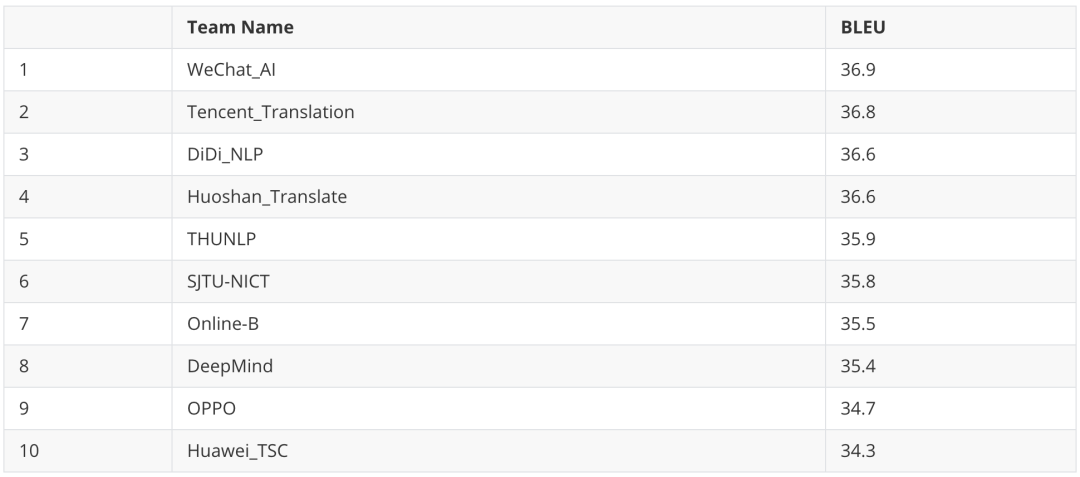
BLEU 指标评估排名前十的参赛团队
相关研究 Paper 已经提交至 EMNLP2020 Workshop,具体 Paper 可以参考 arXiv(https://arxiv.org/abs/2010.08185)。
参考链接:
Wu, Yonghui, et al. "Google's neural machine translation system: Bridging the gap between human and machine translation." arXiv preprint arXiv:1609.08144 (2016).
Papineni, Kishore, et al. "BLEU: a method for automatic evaluation of machine translation." Proceedings of the 40th annual meeting of the Association for Computational Linguistics. 2002.
Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems. 2017.
Shaw, Peter, Jakob Uszkoreit, and Ashish Vaswani. "Self-attention with relative position representations." arXiv preprint arXiv:1803.02155 (2018).
Zhang, Boliang, Ajay Nagesh, and Kevin Knight. "Parallel Corpus Filtering via Pre-trained Language Models." arXiv preprint arXiv:2005.06166 (2020).
Edunov, Sergey, et al. "Understanding back-translation at scale." arXiv preprint arXiv:1808.09381 (2018).
作者介绍:
WeiWei,滴滴专家算法工程师
2016 年 2 月份加入滴滴,目前担任滴滴 NLP 团队负责人,主要负责滴滴 NLP 在客服智能化、国际化网约车、内容安全、中台服务等场景的相关算法研究与落地。今年带领团队首次参加机器翻译大赛(WMT2020)并获得机器评估世界第三名的成绩。
本文转载自公众号滴滴技术(ID:didi_tech)。
原文链接:




