【编者的话】 Spotify 是全球最大的正版流媒体音乐服务平台。Spotify 提供的服务需要一个巨大的基础设施平台作为支撑,而监测这个平台的运行显得至关重要。Spotify 实验室的 John-John Tedro 近日对 Spotify 的监测进行了一个简单的介绍。在上一篇文章中,John 讨论了操作监控的历史。作为该系列文章的下半部分,本文介绍了免费、可扩展的时间序列数据库——Heroic。
Heroic 是 Spotify 公司内部使用的时间序列数据库。在大规模搜集和呈现近实时数据时,Spotify 公司曾面临着巨大挑战。Heroic 就是该公司用来应对这些挑战的工具。其内部包含了两个核心技术——Cassandra 和 Elasticsearch。其中,Cassandra 负责存储,而 Elasticsearch 负责索引所有的数据。Spotify 公司目前使用分布在全球各地的集群所运行的、超过 200 个的 Cassandra 节点,来服务超过五千万的时间序列。
作为一个商业公司的团队,他们清楚知道 Elasticsearch 在数据安全方面一直表现不好,因此采取了应对措施——在系统发生故障后,公司可以从数据流水线或 Cassandra 中迅速重建索引。
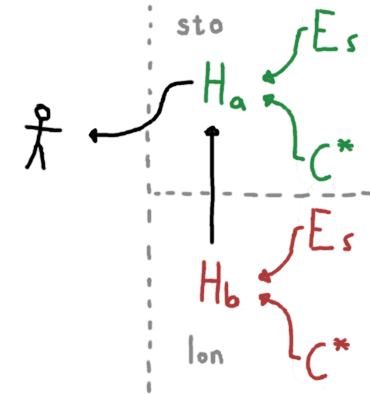
Heroic 的关键特性就是全球联合。不同的集群可以相互独立运行,而且可以把请求转移到其他集群来形成一个全球的接口。一个地区节点的失效只会造成该地区的数据无法访问,而不影响其他节点的数据。这种跨地域的联合使得集群拥有更好的性能。
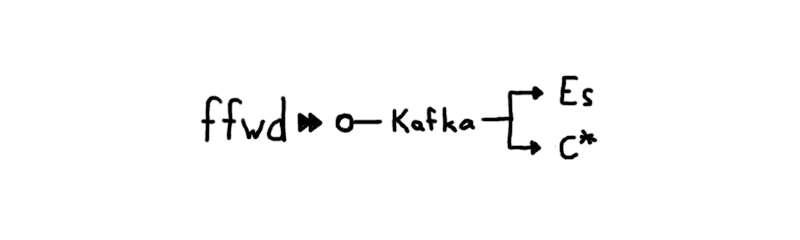
框架中的每一个主机都会运行一个负责接收和转发统计数据的 ffwd 代理。输出统计数据的进程负责将其发送到 ffwd 代理。这就使得 Spotify 工程师可以轻松调度运行在一个主机上的任何东西。库文件也可以直接假设主机上已经存在 ffwd 代理,并且基本上不需要配置。由于延迟很小,该代理大大减轻了低效率客户端所带来的影响。ffwd 所收集的统计数据最后会输出到每个地域的 Kafka 集群中。
这样的配置使得 Spotify 团队可以利用服务拓扑进行实验。而 Kafka 提供了一个缓冲,使得团队成员在 Cassandra 或 Elasticsearch 出现问题时得以继续工作。其中,每一个组件都可以根据需求扩展或缩减。
在后端,所有的数据都如同提供给代理一样进行存储。如果需要任何 downsampling,使用 Dropwizard metric 等库就可以在数据进入代理之前进行执行。工程师还可以利用 Heroic API 对存储的数据执行额外的聚合操作。但是,Spotify 团队采用了一种合理的采样密度——一般情况下,每 30 多秒对每个时间序列进行采样。这种方法有效避免了非稳定状态的处理流水线所遇到的延迟和复杂度问题。
在使用 Heroic 时,Spotify 团队能够利用相同的接口来构建定制化的显示板和警告系统。它使得团队可以基于相同 UI 内的图来定义警告,大大简化了工程师构建的难度。但是,原有的问题不可能一次性就可以完全解决。该团队发现,拥有第二种方法来监控某些部分工作状态非常有必要。其长期目标仍然是更多的转向可视化警告方面。
现在,Heroic 的所有部分都已经免费。用户可以直接通过 Github 来下载源码。文档和项目的相关信息也可以在官方网站中找到。
编后语
《他山之石》是InfoQ 中文站新推出的一个专栏,精选来自国内外技术社区和个人博客上的技术文章,让更多的读者朋友受益,本栏目转载的内容都经过原作者授权。文章推荐可以发送邮件到editors@cn.infoq.com。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 (已满),InfoQ 读者交流群(#2))。
(已满),InfoQ 读者交流群(#2))。




