
本文整理自 2023 年 2 月 QCon 全球软件开发大会(北京站) 中 「AI 基础架构」专题下百度资深研发工程师孙鹏的同名主题分享,点击下载完整幻灯片。
ChatGPT 、Bard 以及将和大家见面的“文心一言”等应用,均是基于各厂商自己推出的大模型进行构建。GPT-3 有 1750 亿参数,文心大模型有 2600 亿参数。
以使用 NVIDIA GPU A100 对 GPT-3 进行训练为例,理论上单卡需要耗费 32 年的时间,千卡规模的分布式集群,经过各种优化后,仍然需要 34 天才能完成训练。
此次演讲介绍了大模型的训练对基础设施的挑战,比如算力墙、存储墙、单机和集群高性能网络设计、图接入和后端加速、模型的拆分和映射等,分享了百度智能云的应对方法和工程实践,构建了从框架到集群、软硬结合的全栈基础设施,加速了大模型端到端训练。
近两年对 AI 技术架构影响最大的就是大模型。在大模型产生、迭代和演进的过程中,它对底层的基础设施提出了新的挑战。
今天的分享主要分为四个部分,第一部分是从业务视角来介绍大模型带来的关键变化。第二部分分享是在大模型时代,大模型训练对基础设施提出的挑战以及百度智能云的应对方法。第三部分是结合大模型和平台建设的需求,讲解百度智能云所做的软硬结合的联合优化。第四部分则是百度智能云对大模型未来的发展、对基础设施新要求的一些思考。
GPT-3 开启大模型时代
大模型时代是由 GPT-3 开启的,该模型有如下几个特点:
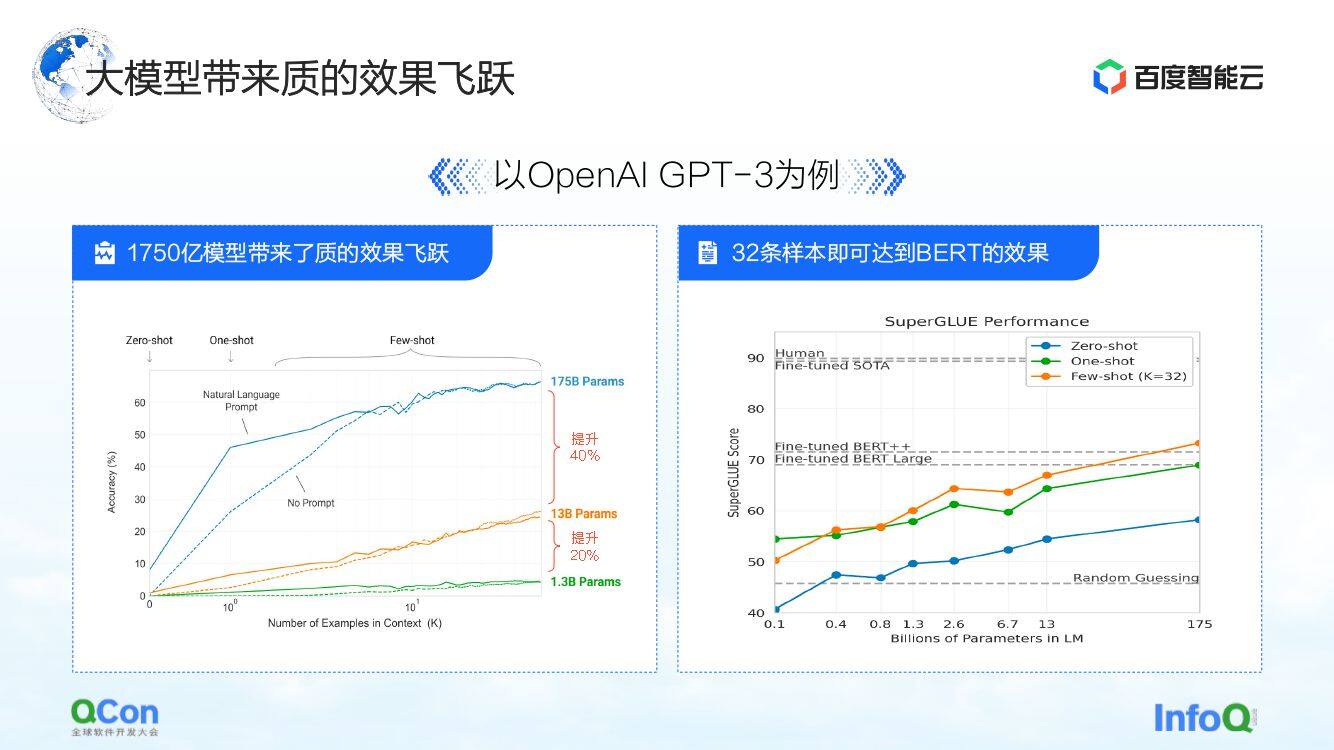
第一个特点是该模型的参数有极大的提升,单个模型达到了 1750 亿的参数,这也带来了准确性的大幅提升。从左边图中我们可以看到,随着模型参数越来越多,模型的准确性也在不断提升。
右边图则展示了它更令人震惊的特点:基于预训练好的 1750 亿参数的模型,只需要通过少量样本的训练,就可以接近 BERT 使用大样本训练后的效果。这在一定程度上反映了模型的规模变大,就可以带来模型性能和模型通用性上的提升。
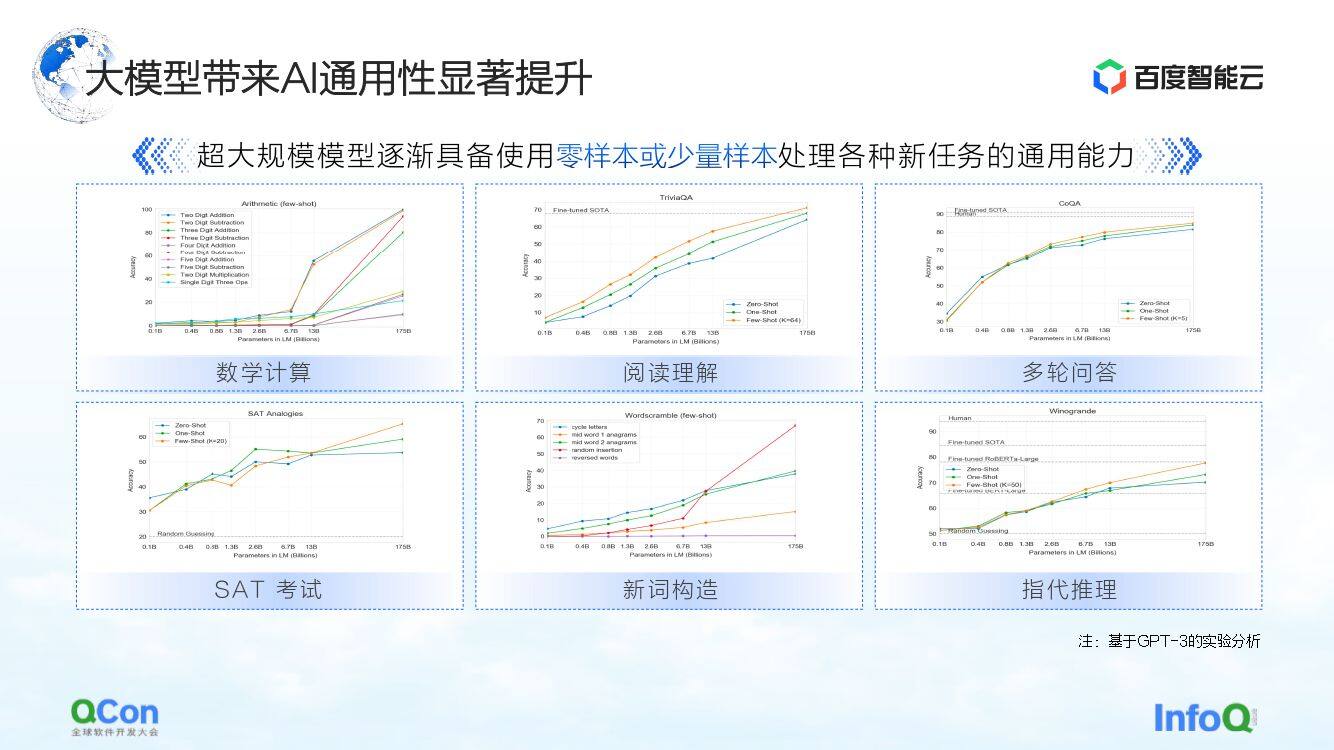
除此之外,GPT-3 还在数学计算、阅读理解、多轮问答等任务上均表现出了一定的通用型,仅通过少量样本就可以让模型达到较高的、甚至近似于人类的准确度。
正因此,大模型也给 AI 整体研发模式带来了新的变化。在未来,我们可能会先预训练一个大模型,再针对具体的任务,通过少量的样本做 Fine-tune,就可以得到不错的训练效果。而不需要像现在训练模型时,每个任务都需要从零开始,完整地做迭代和训练。
百度很早就开始训练大模型,拥有 2600 亿参数的文心大模型就是在 2021 年发布的。现在随着 Stable Diffusion、AIGC 文生图,以及最近大火的聊天机器人 ChatGPT 等受到整个社会的关注,让大家真正意识到大模型时代到了。
各厂商也在布局大模型相关的产品,Google 此前刚发布了 Bard,百度也即将在 3 月份推出“文心一言”。
大模型训练究竟有什么不同的特点呢?
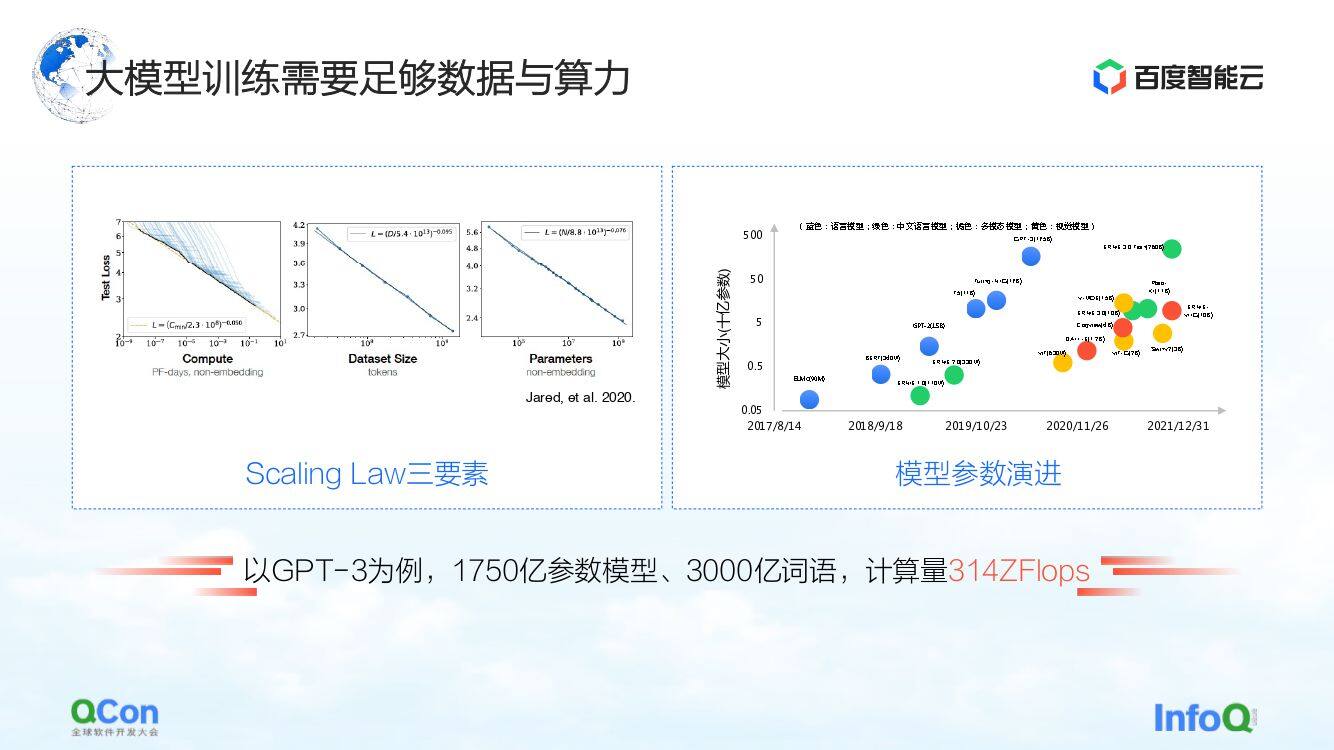
大模型有一个 Scaling Law,如左边图所示,随着模型的参数规模和训练数据越来越多,效果就会越来越好。
但这里有个前提,参数一定要足够大,并且数据集足以支撑整个参数的训练。而这带来后果就是计算量呈指数上升。对于一个普通的小模型来说,单机单卡就可以搞定。但对于大模型来说,它对训练量的要求就需要有大规模的资源去支撑它的训练。
以 GPT-3 为例,它是一个有 1750 亿参数的模型,需要 3000 亿条词语的训练才能支撑它达到一个不错的效果。它的计算量在论文里面评估是 314 ZFLOPs 。对比 NVIDIA GPU A100,一张卡还是只是 312 TFLOPS 的 AI 算力,这中间绝对数值相差了 9 个数量级。
所以为了更好地支持大模型的的计算、训练和演进,如何去设计、开发基础设施就成了非常重要的问题。
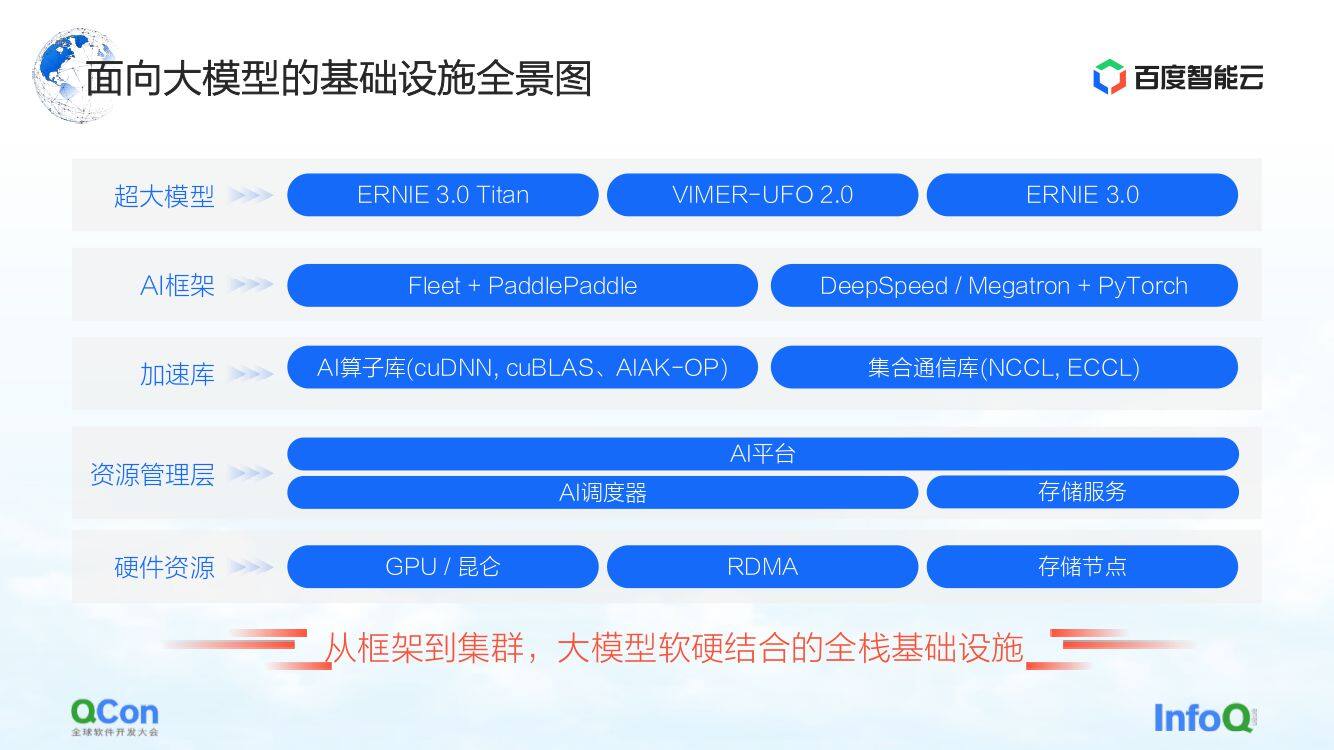
大模型基础设施全景图
这是百度智能云面向大模型的基础设施全景图。这是一个覆盖了从框架到集群,软硬结合的全栈基础设施。
在大模型中基础设施不再仅仅涵盖底层的硬件、网络等传统的基础设施。我们还需要把所有的相关资源都纳入到基础设施的范畴之中。
具体来说,它大概分为几个层级:
最上面的是模型层,包括内外部发布的模型和一些配套组件。比如百度的飞桨 PaddlePaddle 和 Fleet ,Fleet 是在飞桨上做的分布式策略。同时在开源社区,比如 PyTorch 有 DeepSpeed/Megatron 等一些基于 PyTorch 框架做的大模型训练的框架和加速能力。
在框架之下我们还会做加速库的相关能力,包括 AI 算子加速、通信加速等。
再下面是一些偏资源管理或者偏集群管理的相关能力。
最底下是硬件资源,比如单机单卡、异构芯片、网络相关的能力。
以上就是整个基础设施的全景。今天我会先重点从 AI 框架入手,接着再延伸到加速层和硬件层,分享百度智能云的一些具体工作。
首先从最上面的 AI 框架入手。
对于传统的在单卡上进行的小模型训练,我们使用训练数据不停做前向、反向梯度更新就可以完成整个训练。而大模型的训练,主要存在两点挑战:算力墙和存储墙。
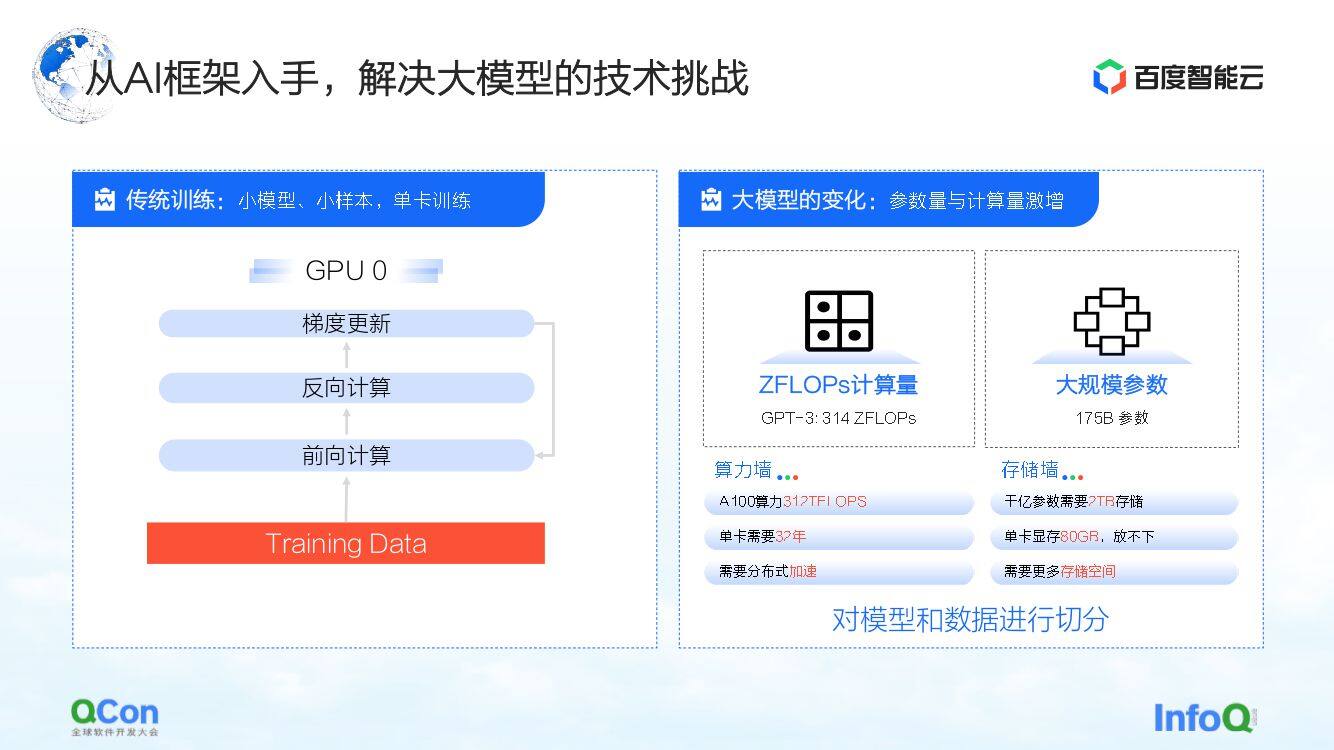
算力墙指的是如果要完成 GPT-3 这种需要 314 ZFLOPs 算力的模型训练,而单卡只有 312 TFLOPS 算力时,我们如何通过分布式的方法去打破单算力时间太长的问题。毕竟一张卡训练一个模型耗时 32 年,明显是不可行的。
其次是存储墙。对大模型来说这是更大的挑战。当单卡放不下模型的时候,模型一定要有一些切分的方法。
举个例子,千亿级别大模型的存储(包括参数、训练中间值等)需要 2 TB 的存储空间,而单卡的显存目前最大只有 80 GB。因此,大模型的训练需要一些切分策略以解决单卡放不下的问题。
首先是算力墙,即解决单卡算力不足的问题。

一个很简单也是大家最熟悉的想法就是数据并行,将训练样本切到不同的卡上。整体来说,我们现在观察到的大模型训练过程中,主要采用的是同步的数据更新策略。
重点来说说存储墙问题的解决。其中关键就是模型切分的策略和方法。
第一个切分方法是流水线并行。我们用下图的例子来做一个说明。
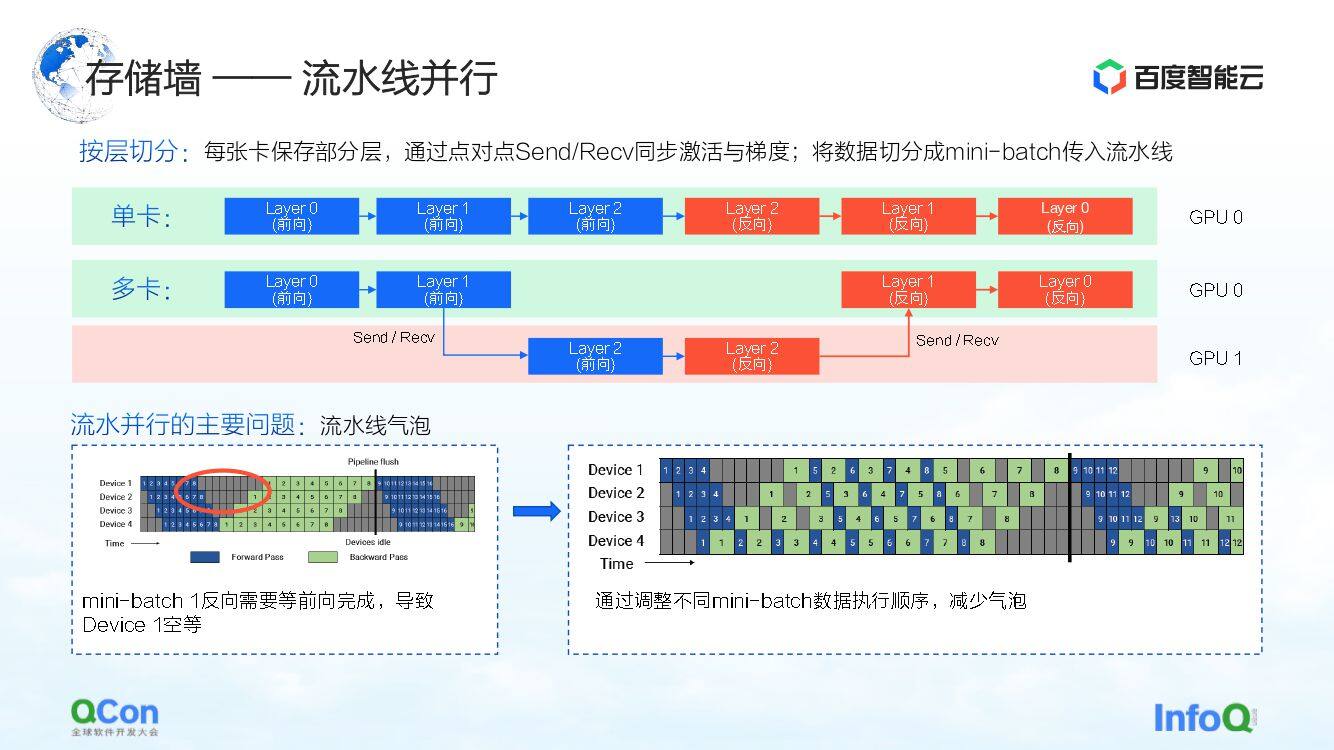
对于一个模型来说,它是由很多层组成的,训练时先做前向,再做反向。比如图中 0、1、2 三层在一张卡上放不下,我们按层进行切分后,会把这个模型中的某些层放到第一张卡上。比如下图中,绿色区域代表 GPU 0,红色区域代表 GPU 1。我们可以将前几层放到 GPU 0 上,其他几层放到 GPU 1 上。数据在流动的时候,会先在 GPU 0 上做两次前向,然后在 GPU 1 上做一次前向和一次反向,再返回到 GPU 0 上做两次反向。由于这个过程特别像流水线,所以我们把它叫做流水线并行。
但流水线并行有个主要的问题,即流水线气泡。因为数据间会存在依赖关系,梯度依赖于前面层的计算,所以在数据流动的过程中,就会产生气泡,也就造成了空等。针对这样的问题,我们通过调整不同 mini-batch 的执行策略来减少气泡的空等时间。
上面是算法工程师或者框架工程师的视角来看该问题。而从基础设施工程师的视角来看,我们更关注的是它会给基础设施带来何种不同的变化。
这里重点关注它的通信语义。它在前向和反向之间,它要传递自己的激活值和梯度值,这就会带来额外的 Send/Receive 操作。而 Send/Receive 是点到点的,我们在后文中会提到应对的办法。
以上就是第一种打破存储墙的并行模型切分的策略:流水线并行。
第二种切分方法是张量并行,它解决的是单层参数过大的问题。
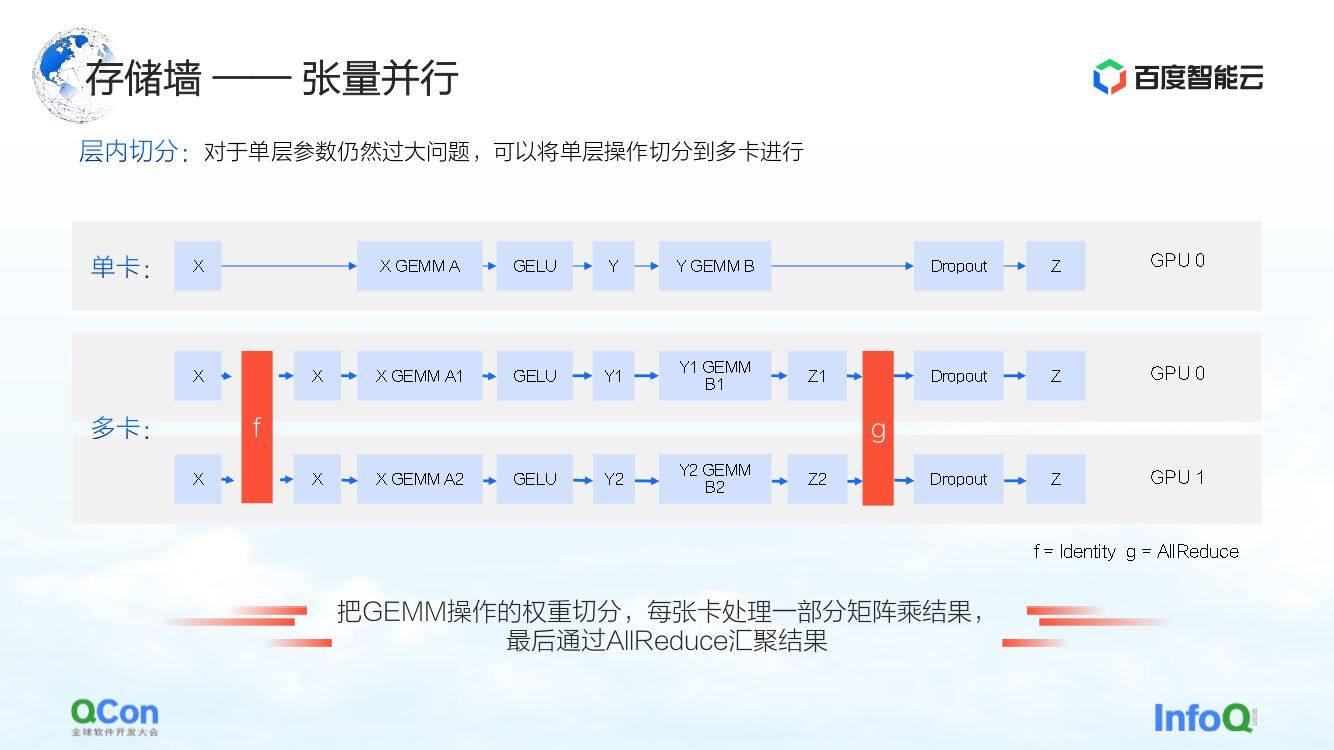
模型虽然有很多层,但其中某一层的计算量很大。此时我们期望将这一层的计算量在机器之间或者在卡间进行共同计算。从算法工程师的视角来看,解决的方法就是将不同的输入切分成几块,然后分别用不同的块分别做部分计算,最后再做聚合。
但从基础设施工程师的视角来看,我们还是关注这个过程中引入了哪些额外的操作。刚刚提到的场景中,额外操作就是图中的 f 和 g。f 和 g 分别代表的什么意思?在做前向的时候, f 是一个不变的操作,通过 f 把 x 透传过去,后面做部分的计算即可。但在最后做结果聚合的时候,还需要把整个数值继续往下传递。对于这种情况,就要引入 g 的操作。 g 就是 AllReduce 的操作,它在语义上就是将两个不同的数值做一次聚合,以保证输出 z 在两张卡上都能拿到相同数据。
所以从基础设施工程师的视角来看,就会看到它引入额外的 AllReduce 的通信操作。该操作的通信量还是比较大的,因为里面的参数规模比较大。我们在后文中也会提到应对的方法。
这是第二种可以打破存储墙的优化方法。
第三种切分方法是分组参数切片。该方法在一定程度上减少了数据并行中的显存冗余。传统的数据运行中,每张卡都会有自己的模型参数和优化器状态。由于它们在各自的训练过程中还需要做同步和更新,这些状态在不同卡上都有完整备份。
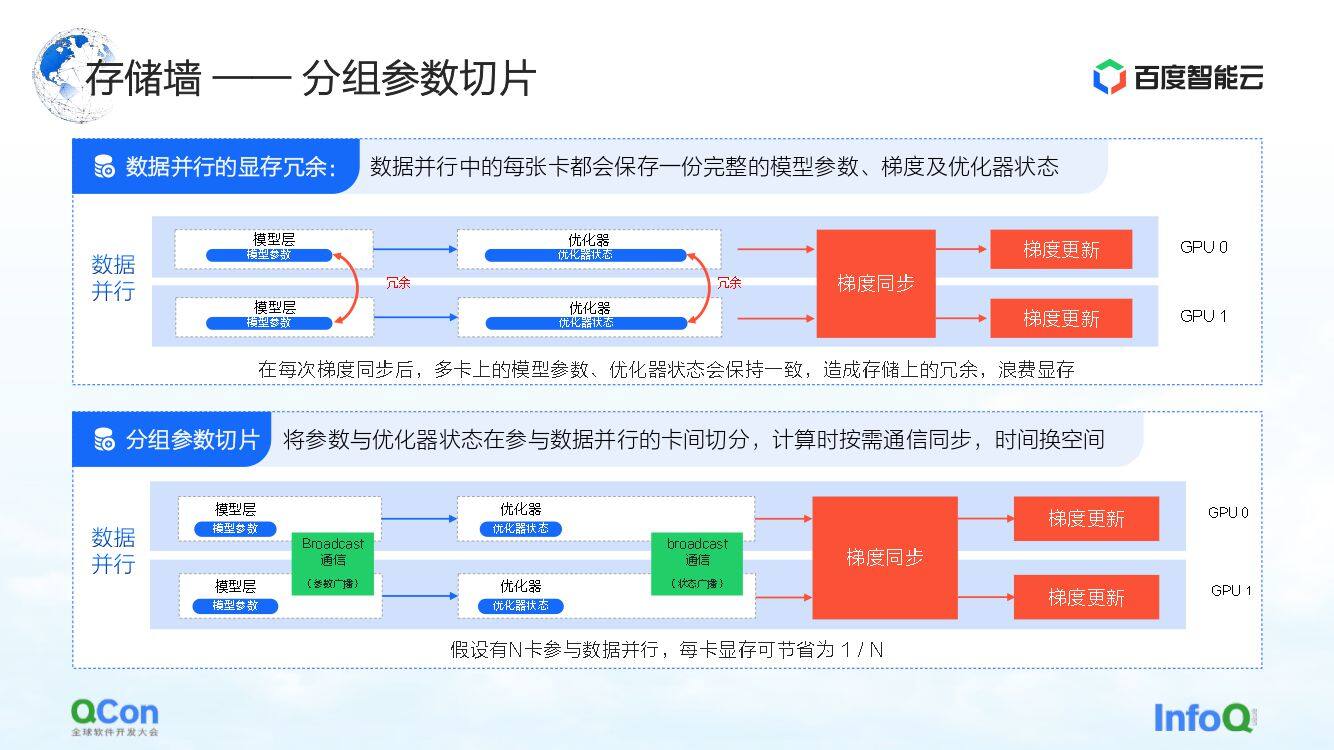
对于上述过程,其实就是同样的数据和参数,在不同的卡上做了冗余的存储。因为大模型对存储空间要求特别高,所以这样的冗余存储是不可接受的。为了解决这个问题,我们将模型参数做了切分,每张卡上只保留一部分参数。
在真正需要计算的时候,我们用时间换空间:将其中的参数先做同步,等计算完成之后,再丢弃这些冗余数据。通过这种方式可以进一步压缩对显存的需求,可以更好地在现有的机器上做训练。
同样,站在基础设施工程师的视角来看,我们就需要引入 Broadcast 这样的通信操作,通信的内容就是这些优化器的状态与模型的参数。
以上就是第三种打破存储墙的优化方法。
除了上面提到的显存优化的方法和策略之外,还有一种方法是减少模型的计算量。
当数据量足够大的时候,模型的参数越多,模型的精度越好。但是随着参数的增加,计算量也随之增加,就需要更多的资源,与此同时计算的时间也会更长。
那如何保证在参数规模不变的情况下减少计算量呢?其中一个解决方案就是条件计算:根据一定的条件(即右图中的 Gating 层,或者称为路由层),去选择激活其中部分参数。
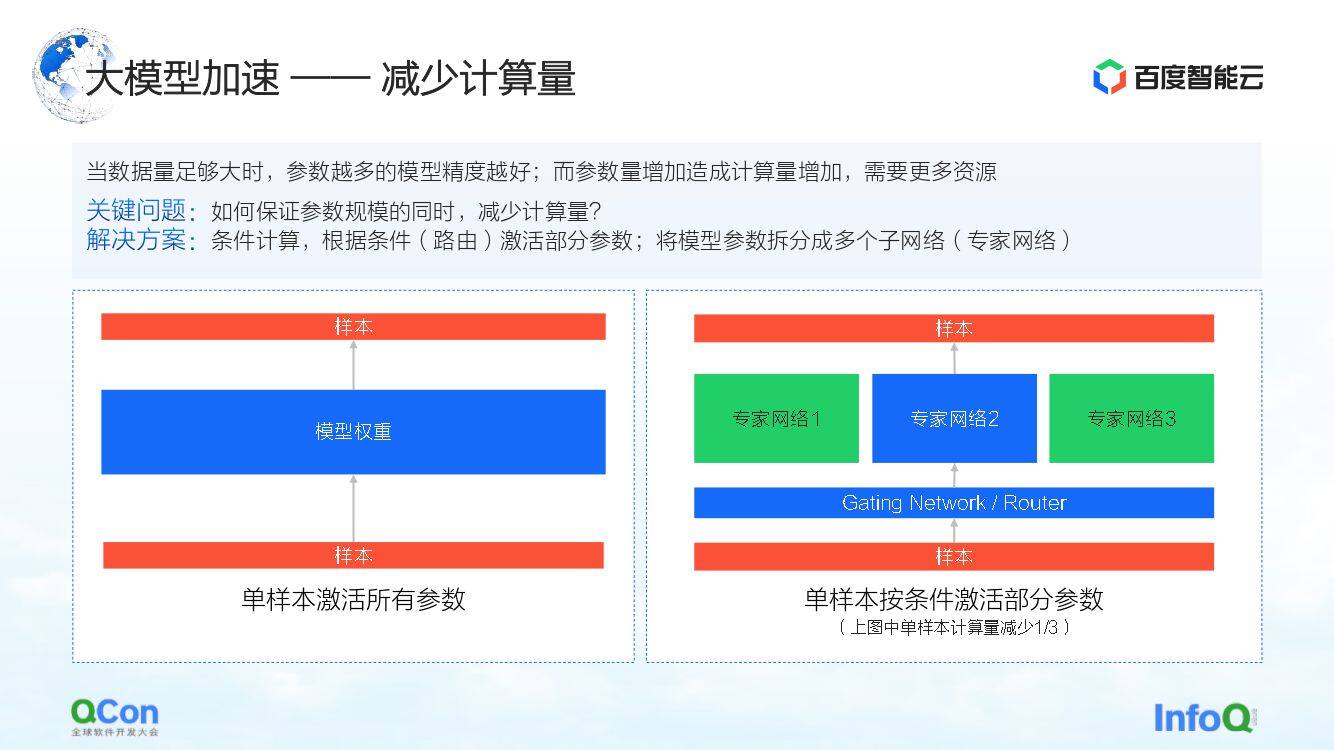
举个例子,在右侧图中,我们将参数切分为三份,样本根据模型的条件,只激活部分的参数来在专家网络 2 中进行计算。而专家 1 和专家 3 中的部分参数则不做计算。这样就可以在保证参数规模的同时,减少其中的计算量。
以上就是基于条件计算的方式来减少计算量的方法。
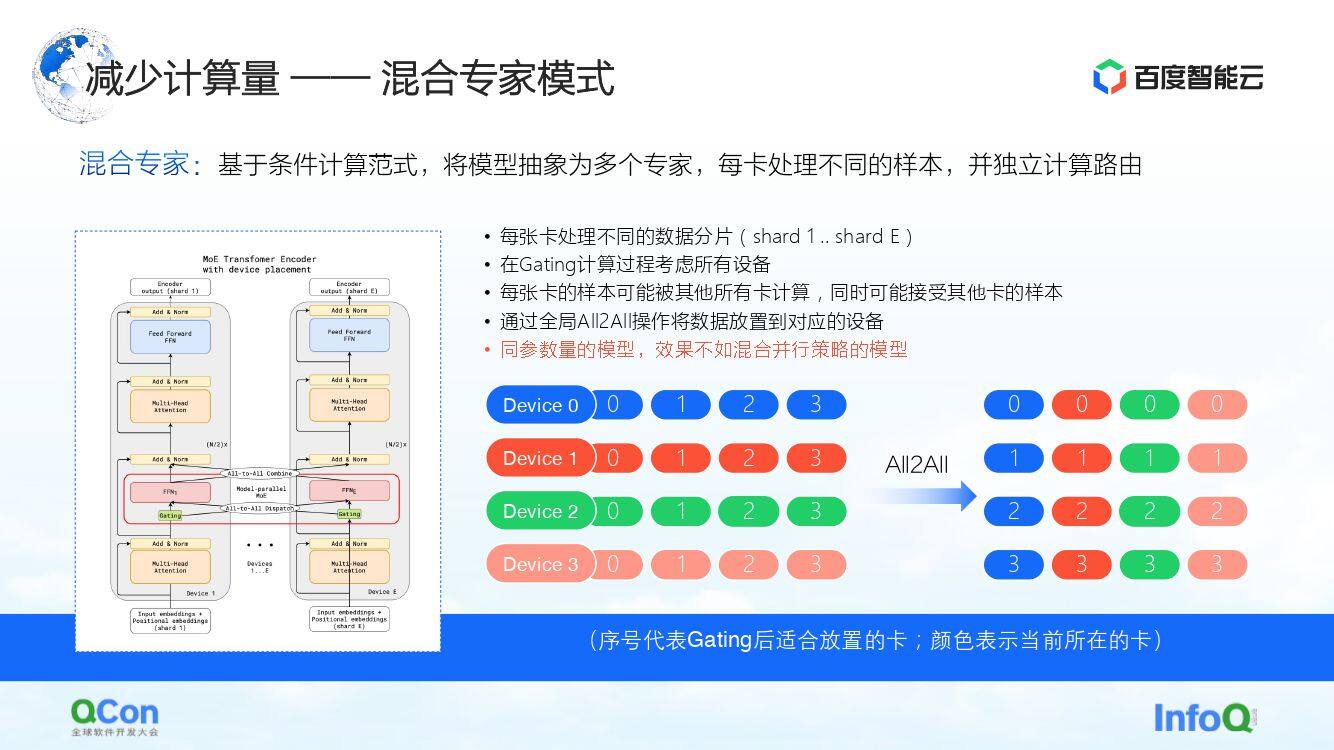
业界基于上述方法,我们提出了混合专家的模式,就是将模型抽象为多个专家,每张卡处理其中不同的样本。具体来说就是在模型层插入了一些路由的选择,然后根据这种选择只激活其中的一部分参数。同时,不同的卡上会保留不同专家的参数。这样,在样本分发的过程中就会分到不同的卡上去做计算。
但是站在基础设施工程师的视角来看,我们发现这个过程中引入了 All2All 的操作。如下方右图所示,在多个 Device 上,存储了 0、1、2、3 这样的样本。Device 里面的数值则表示适合被哪张卡来计算,或者说它适合被哪个专家来计算。比如 0 表示适合被 0 号专家 ,也就是 0 号卡来计算,以此类推。每张卡均会去判断存储的数据分别适合被谁来计算,比如 1 号卡,它判断出部分参数适合被 0 号卡计算,另一部分参数适合被 1 号卡计算。然后下一个动作就是把样本分发到不同的卡上去。
经过如上操作之后, 0 号卡上全为 0 的样本,1 号卡上全为 1 的样本。以上过程在通信里就叫 All2All。这个操作从基础设施工程师的视角来看是一个比较重的操作,我们需要在此基础上做一些相关的优化。我们在后文中也会有进一步介绍。
在这个模式里,我们观察到的一个现象是,如果采用混合专家的模式,它在同样参数的模型下,训练的精度不如刚才提到的各种并行策略、混合叠加策略好,大家需要根据自己的实际情况来酌情选择。
刚刚介绍了几种并行策略,接下来分享下百度智能云的一个内部实战。
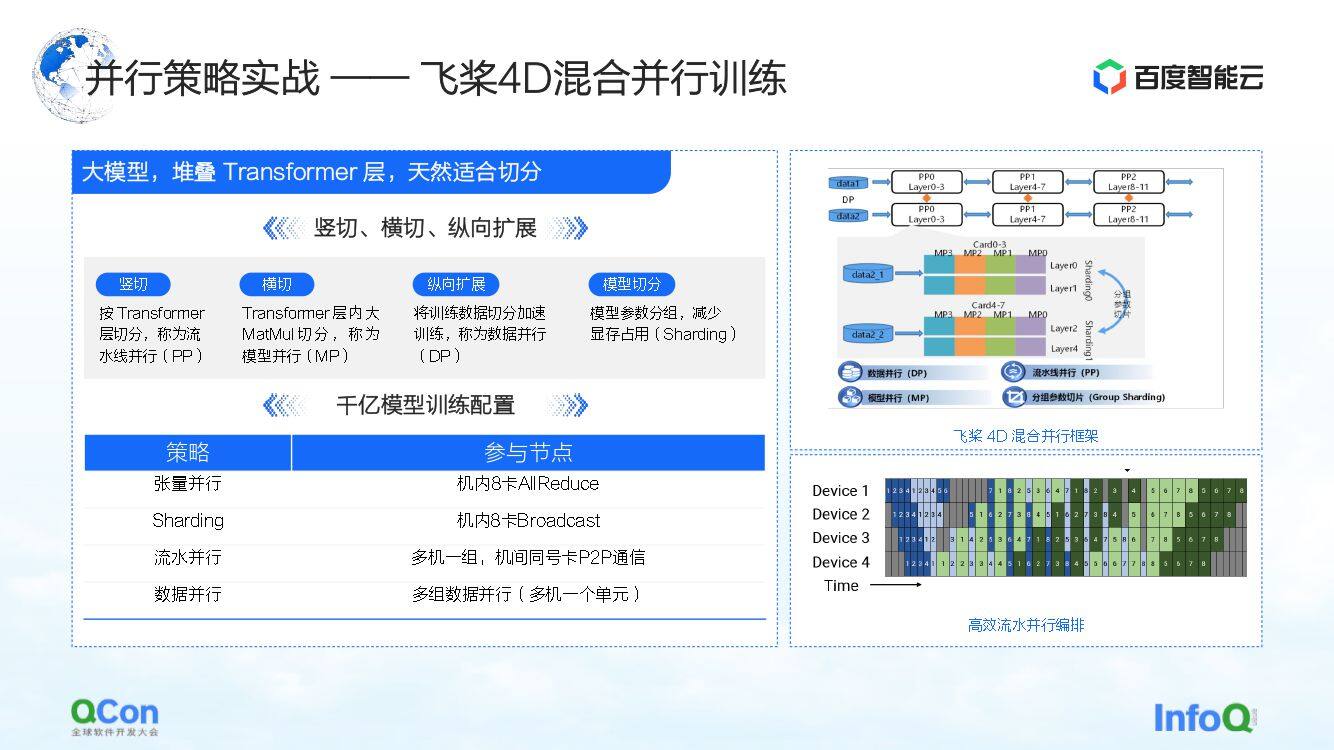
我们用飞桨训练了一个有 2600 亿参数的大模型,堆叠了一些优化过的 Transformer 类的层。我们可以按照横切竖切的方式给它做一个切分,比如竖切就是采用流水线并行策略将模型按 Transformer 层进行切分。横切则是采用模型并行策略/张量并行策略对 Transformer 内部的 MetaMul 这种大的矩阵乘的计算做切分。同时我们再辅以数据并行的纵向优化,以及配合在数据并行上做的分组模型参数切分的显存优化。通过如上四种方式,我们推出了飞桨的 4D 混合并行训练的框架。
在千亿参数模型的训练配置上,我们采用机内八卡做张量并行,同时配合数据并行进行一些分组参数切分操作。同时还使用多组机器组成流水线并行,以此来承载 2600 亿的模型参数。最后,再利用数据并行的方式进行分布式计算,从而完成模型的月级别训练。
以上就是我们整个的模型并行参数模型并行策略的一个实战。
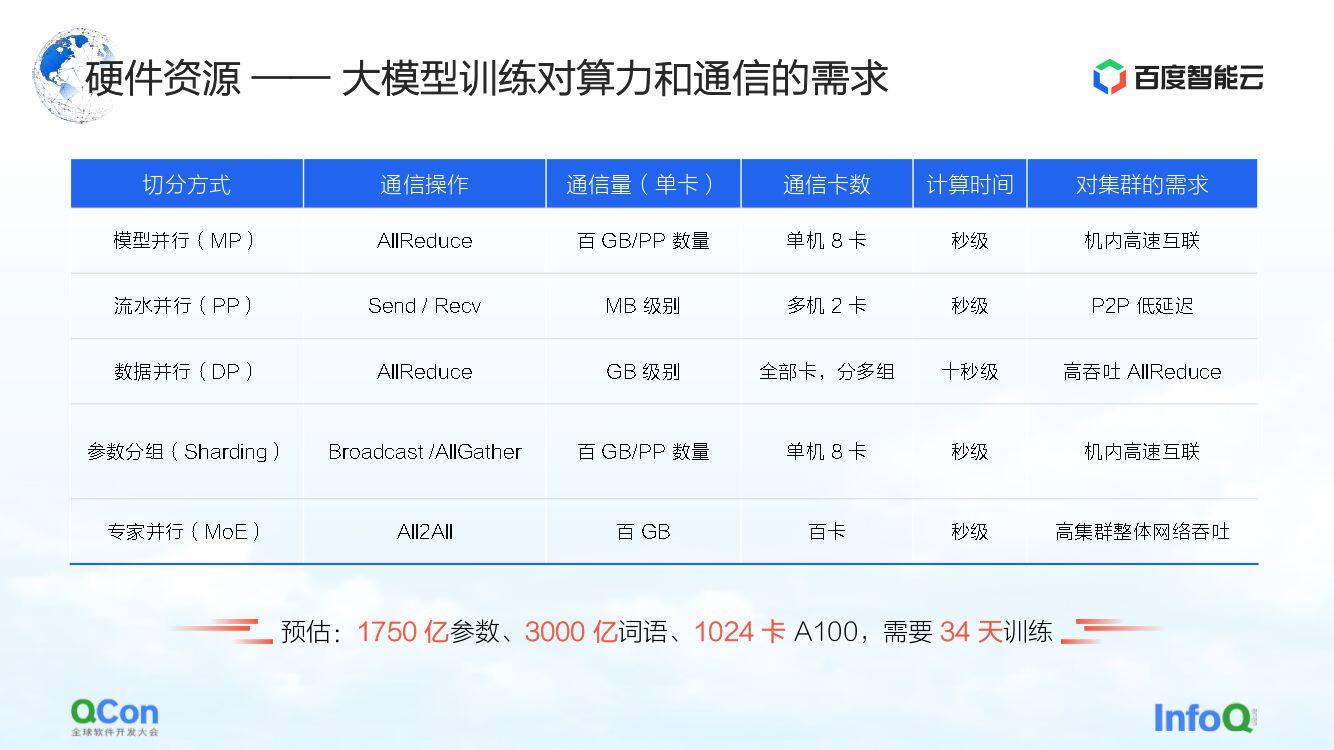
接下来,让我们再回到基础设施的视角,评估模型训练中不同的切分策略对通信和算力的需求。
如表格所示,我们按照千亿参数的规模,列出了不同切分方式所需的通信量和计算时间。从整个训练过程来说,最好的效果是计算过程和通信过程可以完全覆盖,或者互相重叠。
从这张表格中,我们可以推算出千亿参数模型对集群、硬件、网络,包括整体通信模式上的需求。根据估算 1750 亿参数的模型在 1024 张 A100 卡上使用 3000 亿词语进行训练,需要 34 天就可以完成完整的端到端训练。
以上就是我们对硬件侧的评估。
有了硬件的需求,接下来就是单机和网络层面的选型。
在单机层面,由于需要在机内做大量的 AllReduce 和 Broadcast 操作,我们希望机内可以支持高性能,高带宽的连接方式。所以我们在选型中采用了当时最先进的 A100 80G 的套餐,采用 8 张 A100 组成单机。
此外,在外部的网络连接方式中,最重要的就是拓扑的连接方式。我们希望网卡和 GPU 卡之间能尽可能在同一个 PCIe Switch 下,通过对称的方式可以更好地减少整个训练过程中卡之间交互的吞吐瓶颈。同时也要尽量避免它们经过 CPU 的 PCIe Root Port。

说完单机,我们再来看看集群网络的设计。
首先我们先评估下需求,如果我们对业务的预期是在一个月之内完成模型的端到端训练,就需要单作业训练中达到千卡级别,大模型训练集群达到万卡级别。因此,在网络设计的过程中,我们应该兼顾两个点:第一,为了满足流水线中的 Send/Receive 这种点到点的操作,需要减少 P2P 的延迟。第二,由于 AI 训练中网络侧流量集中于同号卡 AllReduce 操作,我们还希望它有很高的通信吞吐。

针对这种通信需求。我们设计了右边所示的三层 CLOS 架构的拓扑。这种拓扑跟传统方式相比,最重要的是做了八导轨的优化,让任一同号卡在不同机器中的通信中的跳步数尽可能少。
在 CLOS 架构中,最底下的一层是 Unit。每个 Unit 中有 20 台机器,我们将每台机器中的同号 GPU 卡连接到与对应编号的同一组 TOR 上。这样单个 Unit 内的所有同号卡,只需要一跳就可以完成通信,可以很好地提升同号卡之间的通信。
但是,一个 Unit 中只有 20 台机器共 160 张卡,这个规模是达不到大模型训练要求的。所以我们又设计了第二层 Leaf 层。 Leaf 层将不同的 Unit 中的同号卡连到同一组 Leaf 的交换设备上,解决的依然是同号卡互联的问题。通过这一层,我们可以将 20 个 Unit 再做一次互联。到这里,我们已经可以连出 400 台机器共 3200 卡的规模。对于这样一个 3200 卡规模的集群来说,任意两张同号卡之间最多就跳到 3 跳即可实现通信。
如果我们想支持异号卡的通信怎么办?我们在上面又加了 Spine 层,进而解决了异号卡之间通信的问题。
通过这三层的架构,我们便实现了一个支持 3200 卡间专门针对 AllReduce 操作优化的整体架构。如果是在 IB 的网络设备上,该架构可以支持 16000 卡的规模,这也是目前 IB 盒式组网的最大规模。
我们将 CLOS 架构跟其他的一些网络架构做了比较,比如 Dragonfly,Torus 等。跟它们相比,这套架构的网络带宽更加充足、节点间的跳步数更加稳定,对于做可预期的训练性能的估计很有帮助。
以上就是从单机到集群网络的一整套建设思路。
软硬件结合的联合优化
大模型训练并不是把硬件买好了,放在那里就可以完成训练。我们还需要对硬件和软件进行联合优化。
首先我们先来说说计算优化。大模型的训练整体来看还是一个计算密集型的过程。在计算优化上,目前很多思路和想法都是基于静态图的多后端加速。用户构建的图,无论是飞桨、PyTorch 还是 TensorFlow,都会先通过图捕获把动态图转换成静态图,然后再让静态图进入到后端进行加速。

上图是我们整个基于静态图的多后端架构,它分为如下几部分。
第一个是图接入,把动态图转换成静态图。
第二个是多后端接入的方法,通过不同的后端提供基于计时的选优能力。
第三个是图优化,我们针对静态图做了一些计算上的优化和图转换,从而进一步提升计算效率。
最后我们会通过一些自定义的算子,整体加速大模型的训练过程。
下面我们分别展开介绍一下。
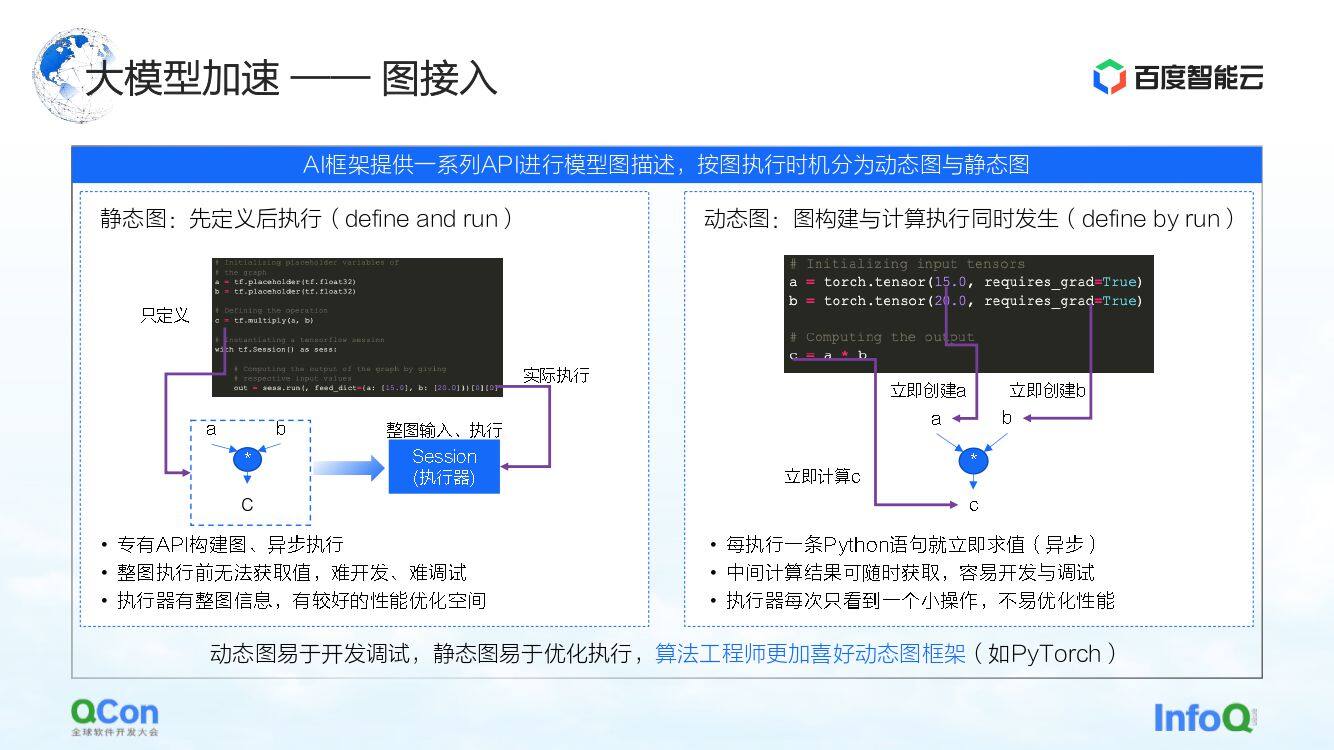
大模型的训练架构中,第一部分是图接入。在 AI 框架里描述图的时候,通常分为静态图和动态图。
静态图是用户在执行之前先把图构造出来,再结合自己的实际输入做执行。结合这样的特点,在计算过程中可以提前做些编译上的优化或者调度的优化,可以更好地提升训练性能。
但与之对应的是动态图的构造过程。用户随便写了一些代码,在写的过程中就动态执行了。比如 PyTorch,在用户写完一条语句之后,它就会做相关的执行和求值。对用户来说,这种方式的好处就是很容易开发和调试。但是对于执行器或者对于加速过程来说,由于每次看到都是一部分很小的操作,反而不是很好优化。
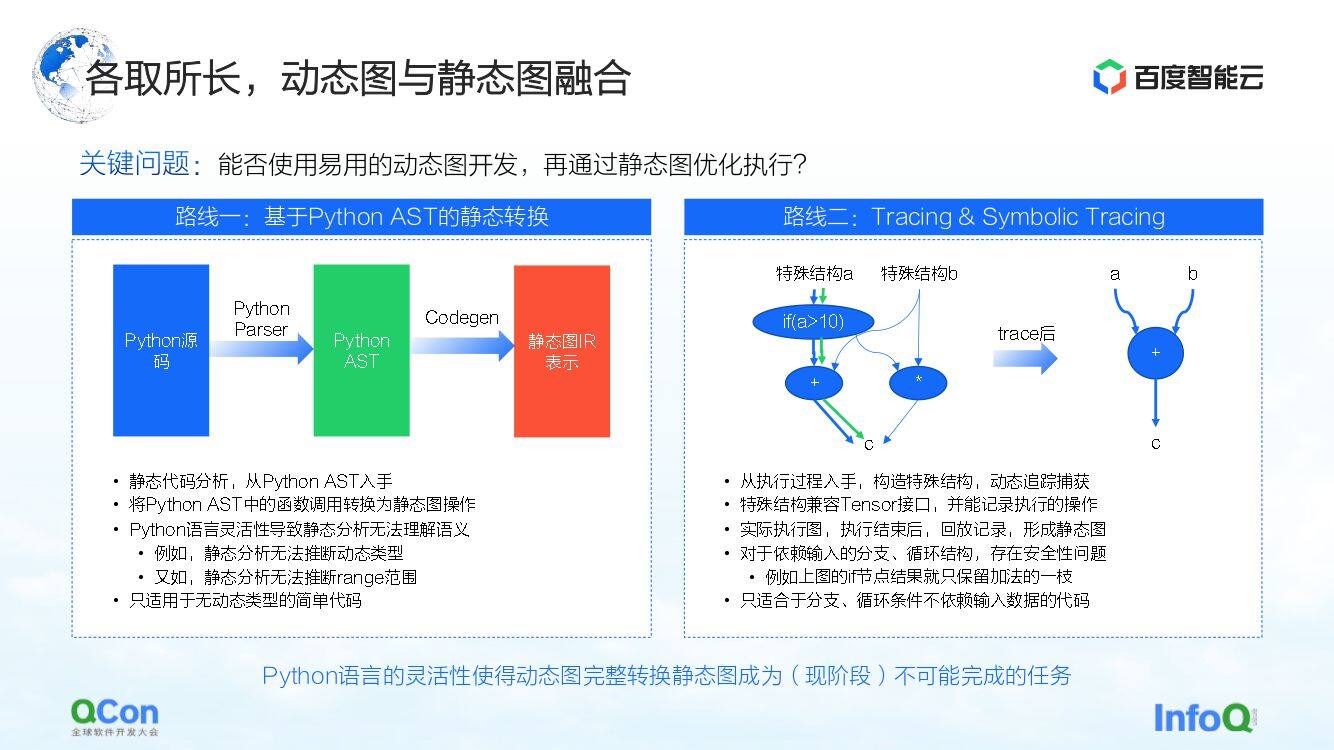
为了解决这个问题,一般的想法就是把动态图和静态图做融合,使用动态图做开发,再通过静态图做执行。我们现在看到的主要有两种实现的路径。
第一种就是基于 Python AST 去做静态的转换。比如我们拿到用户写的 Python 源码,将其转换成 Python AST 树后,再根据 AST 树去做 CodeGen。在这个过程中使用静态组图的方法和 API 就可以将 Python 的动态源码转换成静态图。
但这个过程中,最大的问题是 Python 语言的灵活性,导致静态的分析没办法很好地理解语义,进而出现动态图转静态图转换失败的情况。比如在静态分析过程中,它没办法推断动态类型,又比如静态分析没办法推断 range 的范围,导致实际转换过程中经常失败。所以静态转换只能适用一些简单的模型场景。
第二条路线就是通过 Tracing 或者 Symbolic Tracing 的方法,去做简单的执行和模拟。Tracer 记录过程中遇到的一些计算节点,将这些计算节点记录下来之后,再通过回放或者重组的方式去后验构造一整个静态图。这种方式的好处是可以通过模拟一些输入的方法,或者通过一些构造特殊结构的方法来做整体动态图的捕获和计算,进而可以较为成功地捕获到一条路径。
但是这个过程其实也存在一些问题。对于依赖输入的分支或者循环结构来说,由于 Tracer 是通过构造模拟输入的方式来构造静态图,因此 Tracer 只会走到其中一些分支,从而导致安全性上存在问题。
这几种方法比较下来之后,我们发现在 Python 现有的语言灵活性下,如果想让动态图完整地转换成静态图,在现阶段基本上是一个不太可能完成的任务。因此我们的重心就转移到了在云上如何给用户提供更安全易用的图转化能力。现阶段有如下几种方案。
第一个方案是自研基于 AST 代码替换的方法。该方法由百度智能云来提供相应的模型转换和优化的能力,对用户而言是无感的。比如,用户输入一段源码,但是其中部分代码(图中 XXXX、YYYY 所示)在做静态图捕获、图优化、算子优化的过程中,我们发现这部分代码无法将动态图转换为静态图、或者代码有性能优化的空间。那么我们就会写一段替换代码,如中间图所示。左边是我们认为是可以被替换的一段 Python 代码,右边是我们替换后的另一段 Python 代码。然后,我们就会通过 AST 匹配的方法,把用户的输入和我们的原始的目标模式做 AST 的转换,在这上面执行我们子树的树匹配算法。
通过这种方式,就可以把我们原始输入的 XXXX、YYYY 变成 WWWW、HHHH,变成一个可以更好执行的方案,一定程度上提升了动态图转静态图的成功率,同时提升了算子的性能,并可以做到用户基本无感的效果。

第二种是社区上的一些方案,尤其是 PyTorch 2.0 提出的 TorchDynamo 方案,这也是我们目前看到的比较适合计算优化的方案。它可以实现部分的图捕获,不支持的结构可以 fallback 回 Python。 通过这样的方式,它可以一定程度上把其中的部分子图吐给后端,然后后端再针对这些子图做进一步的计算加速。
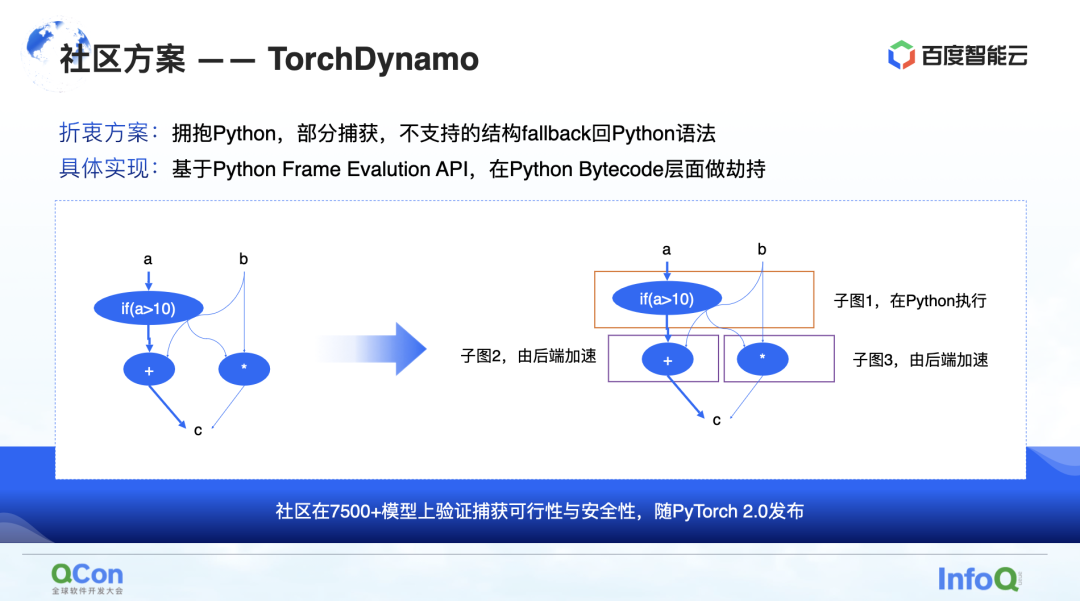
当我们将图整个捕获完之后,接下来就要真正开始做计算加速了,即后端加速。
我们认为,在 GPU 计算的时序图中比较关键的其实是访存时间和计算时间。我们从如下几个角度去加速这个时间。
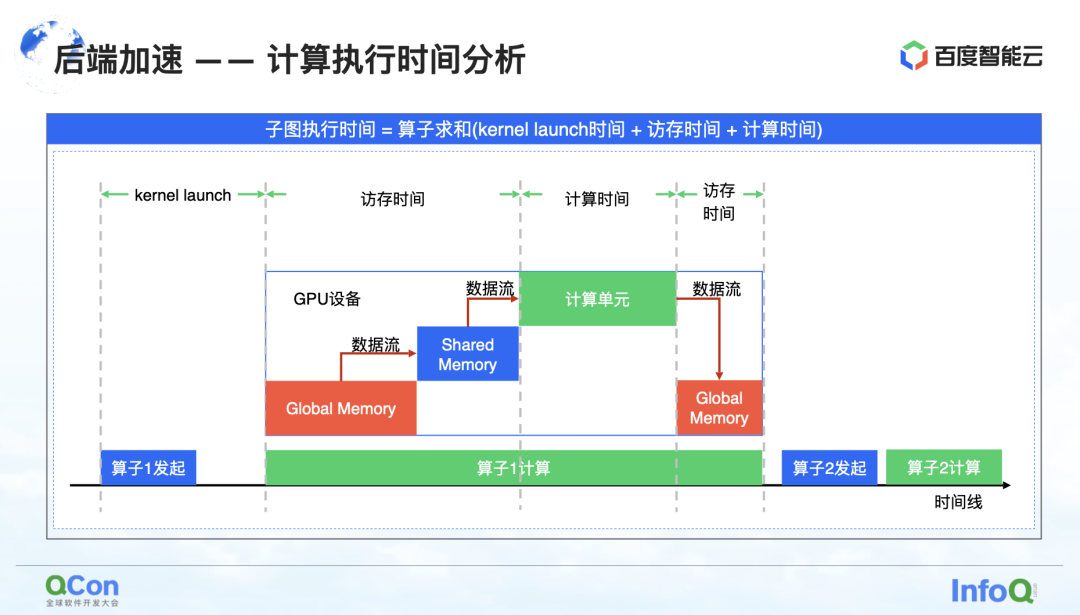
第一个是算子融合。算子融合主要的收益就是去掉 kernel launch 的时间、提升计算密度、减少额外的访存。我们将算子单位访存上的计算次数,定义为计算密度。
根据计算密度的不同,我们把算子分为计算密集型和访存密集型两类。举个例子,像 GEMM 就是典型的计算密集型算子,像 Elementwise 就是典型的访存密集型的算子。我们发现,“计算密集型算子 + 访存密集型的算子”和“访存密集型算子 + 访存密集型算子”之间,是可以做比较好的融合的。
我们的目标是将所有在 GPU 上执行的算子转化为偏计算密集性的算子,这样可以充分利用我们的算力。
左边是我们的一个例子,比如在 Transformer 的结构中,最重要的 Multihead Attention,是可以做一个很好的融合的。同时右边还有我们发现一些其他模式,限于篇幅就不一一列举了。

另一类计算优化是对算子实现上的优化。
算子实现的本质问题是如何将计算逻辑和芯片架构相结合,从而更好地去实现整个计算过程。我们目前看到三类方案:
第一类是手写算子。相关厂商会提供比如 cuBLAS 、cuDNN 等算子库。它提供的的算子性能是最好的,但是它支持的操作有限,同时对定制开发的支持也比较差。
第二类是半自动化模板,比如 CUTLASS。这种方法做了开源的抽象,让开发人员可以在上面做二次开发。这也是我们目前实现计算密集型与访存密集型算子融合中实际使用的方法。
第三个是基于搜索的优化。我们关注了社区上一些像 Halide, TVM 的编译方法。目前发现该方法在一些算子上是有效果的,但在另外一些算子上则还需要进一步打磨。
在实践中这三种方法各有优势,因此我们会通过计时选择的方式来为大家提供最好的实现。

说完计算的优化,我们再分享下通信优化的几种方法。
第一个是交换机哈希冲突问题的解决。下图是我们做的一个实验,我们起了一个 32 卡的任务,每次执行 30 次 AllReduce 操作。下图是我们测出来通信带宽,可以看到它有很大的概率是会出现降速。这是在大模型训练中比较严重的问题。
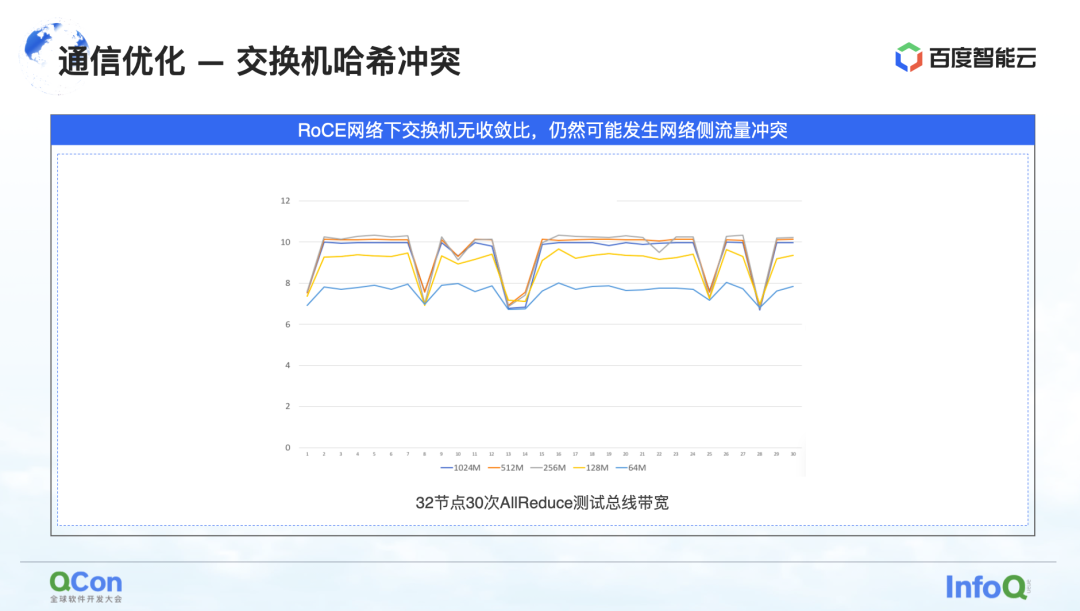
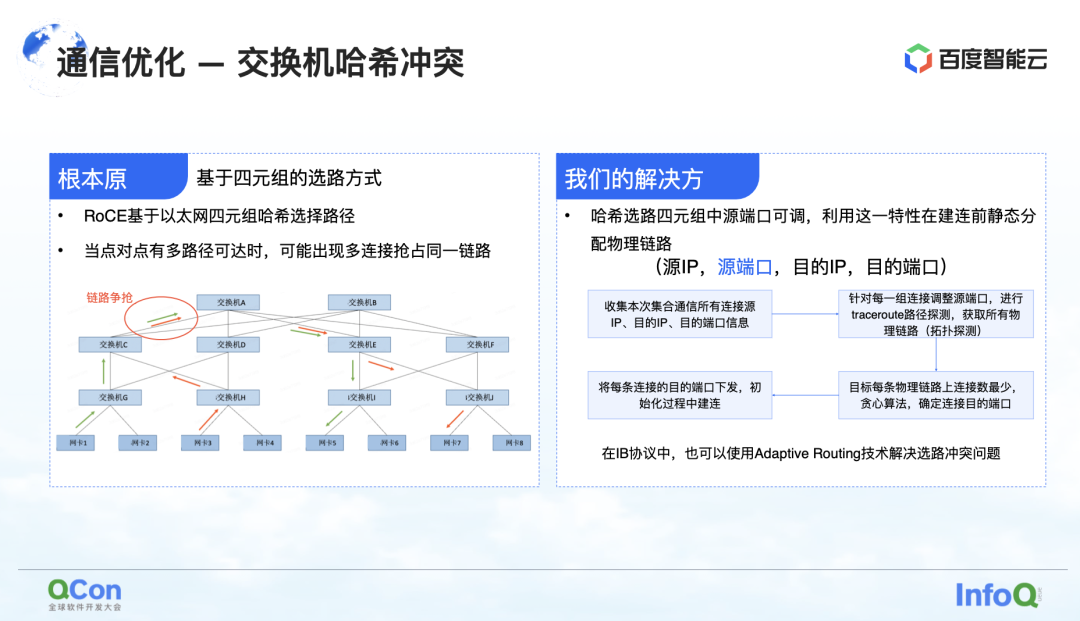
降速的原因是因为存在哈希冲突。虽然在网络设计上,交换机没有收敛比,即我们网络设计上的带宽资源都是充足的,但是由于使用了 RoCE 这种基于以太网四元组选路的方法,仍然可能发生网络侧的流量冲突。
比如下图中的例子,绿色的机器之间要通信,红色的机器之间也要通信,那么在选路的过程中,就会因为哈希冲突导致大家的通信争抢到了同一带宽上,导致虽然整体的网络带宽是充足的,但是依然会形成局部网络热点,导致通信性能降速。
我们的解决方法其实也很简单。在整个通信过程中有源 IP、 源端口、目的 IP、 目的端口这个四元组。其中源 IP、目的 IP、目的端口固定不变,而源端口是可以调整的。利用这个特点,我们通过不断地调整源端口来选择不同的路径,再通过整体的贪心算法,尽量减少哈希冲突的发生。
通信优化中,除了刚才说到在 AllReduce 上的一些优化,在 All2All 上也有一定优化空间,尤其是我们这种面向八导轨的专门定制过的网络。
该网络在整个 All2All 的操作上会给上层的 Spine 交换机较大的压力。优化方法是使用了 NCCL 里面的 Rail-Local All2All,或者 PXN 的优化。原理就是将异号卡之间的通信通过机内高性能的 NVLink 转换为同号卡之间的通信。
通过这种方式,我们将机间的原本要上到 Spine 层的所有的网络通信转换为机内通信,这样只需要做 TOR 层或者 Leaf 层通信就可以实现异号卡通信,在性能上也会有较大的提升。

此外,除了在 RoCE 上做的这些优化,还有一个直接就能拿到效果的就是使能 Infiniband。比如刚才提到的交换机哈希冲突,它自己的自适应路由就可以搞定。而对于 AllReduce 来说,它还有一些高级的特性如 Sharp,可以很好地把 AllReduce 计算操作的一部分卸载到我们的网络设备中,以释放计算单元,同时提升计算性能。通过这样的方法,我们可以很好地将 AllReduce 的训练效果再次提升。
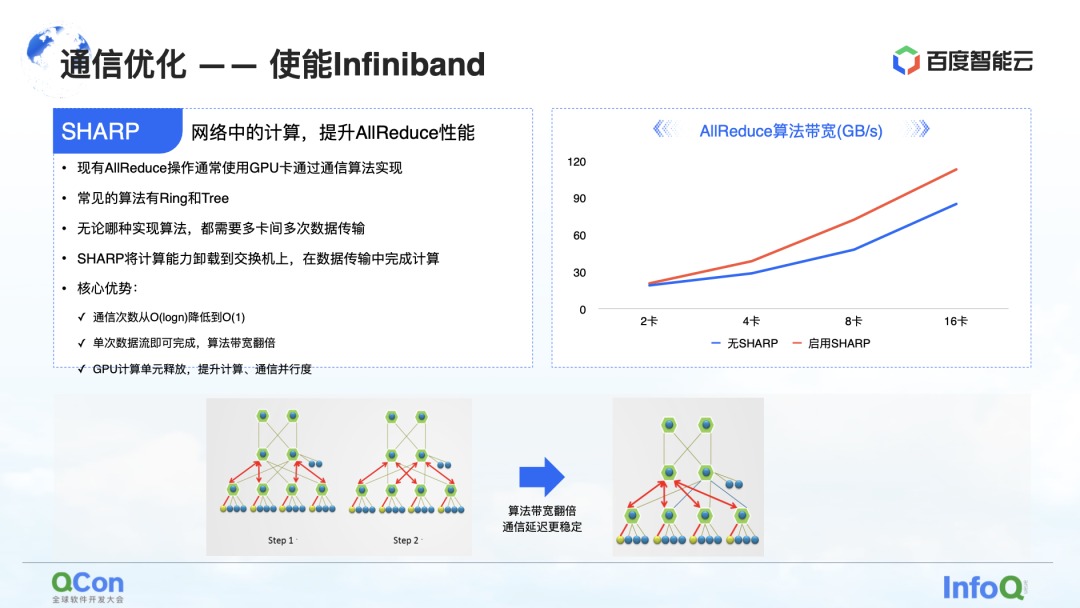
刚才讲完了计算和通信的优化,我们接下来再从端到端去看这个问题。
从整个大模型训练来说,它其实分为两大部分,第一部分是模型代码,第二部分是高性能的网络。在这两个不同的层级上,有一个问题亟待解决:经过多种切分策略切分后的模型放置到哪张卡上是最合适的?
我们举个例子,在做张量并行的时候,我们需要将一个张量的计算切分为两块。由于分块计算结果之间需要做大量的 AllReduce 操作,因此需要很高的带宽。
如果我们将一个张量并行切完的两块分别放到不同机器的两张卡上,就会引入网络通信,造成性能问题。反之,如果我们把这两块放到同一机器内,就可以高效完成计算任务,提升训练效率。因此,放置问题的核心诉求,就是要找到切分的模型和异构硬件间最合适或者说性能最好的映射关系。
在我们早期的模型训练中,是基于专家经验知识手工完成映射。比如下图就是我们跟业务团队合作时,当我们认为机内的带宽好,就建议放到机内。如果我们认为机间可能有改进时,就建议放到机间。
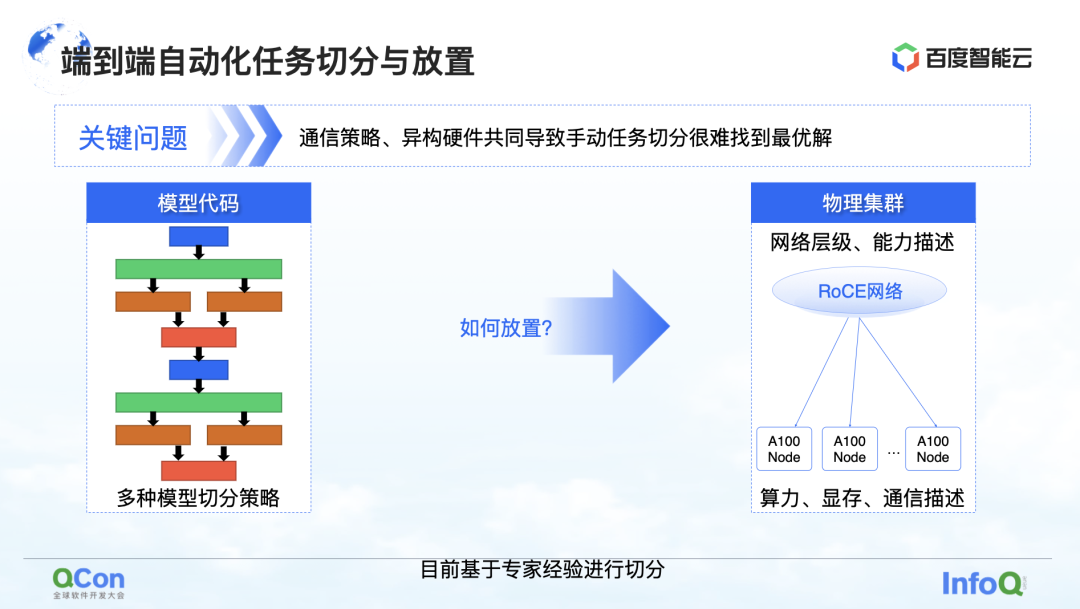
那有没有工程化或者系统化的方案呢?
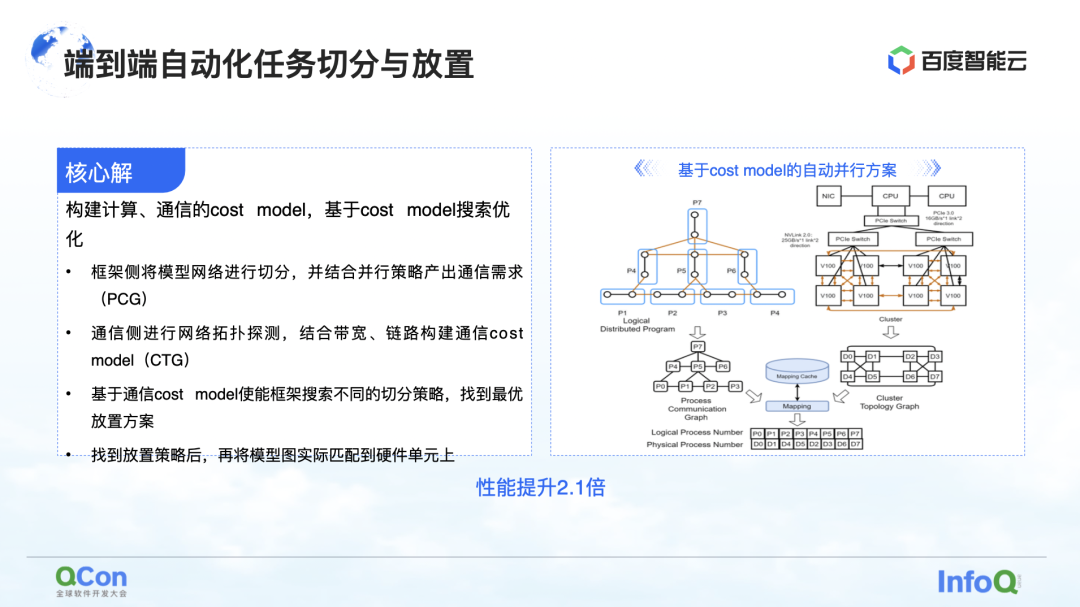
我们核心的解法就是构建计算、通信的 Cost Model,然后基于 Cost Model 做搜索优化。通过这种方式产出最优的映射。
在整个过程中会先将框架侧的模型网络做抽象和切分,映射成一个计算框架图。同时会将单机和集群上的计算能力、通信能力做相关建模,建立集群的拓扑图。
当我们有了右图左边的模型上的计算和通信需求,以及右图右边硬件上的计算和通信能力,我们就可以通过图算法或者其他一些搜索方法进行模型的拆分和映射,最终拿到右图下边的一个最优解。
在实际的大模型训练过程中,通过这种方式可以让最后的性能提升 2.1 倍。
大模型发展推动基础设施演进
最后和大家探讨下在未来,大模型会对基础设施提出哪些新的要求。
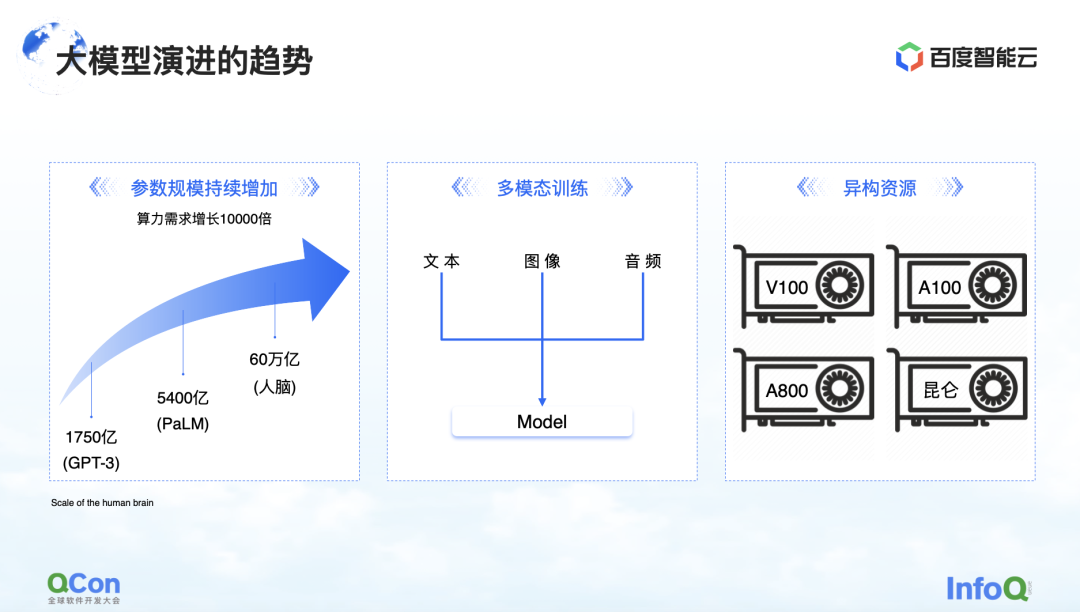
目前我们看到的变化有三个。第一个是模型的参数,模型参数还会持续地增长,从 GPT-3 的 1750 亿到 PaLM 的 5400 亿。关于未来参数增长的最终值,我们可以参考下大概有 60 万亿参数规模的人脑。
第二个是多模态训练。在未来我们会处理更多的模态数据。不同的模态数据对存储、计算量、显存都会带来更多的挑战。
第三个是异构资源。在未来我们会有越来越多的异构资源。在训练过程中,各种类型的算力,如何更好地使用它们也是一个亟待解决的挑战。
同时从业务角度看,在一个完整的训练过程中可能还会有不同的类型的作业,可能同时会存在传统的 GPT-3 训练、强化学习训练、和数据标注任务。如何把这些异构的任务更好地放置在我们异构的集群上将会是一个更大的问题。

我们现在看到的几个方法,其中一种方法是基于统一视图的端到端的优化:将整个模型和异构资源做视图上的统一,基于统一视图扩展 Cost Model ,可以支持单任务多作业在异构资源集群下的放置。结合弹性调度的能力,可以更好地感知集群资源的变化。
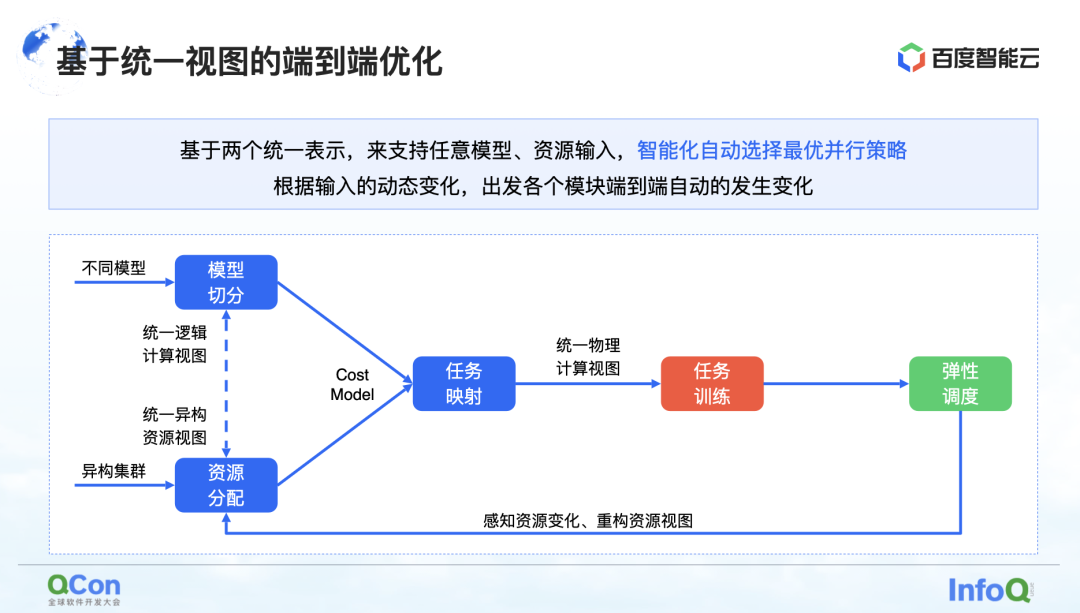
上文讲到的所有能力,都已经全部融合到了百度百舸· AI 异构计算平台中。

作者简介
孙鹏,百度资深研发工程师。毕业于哈尔滨工业大学,百度智能云异构计算团队加速方向技术负责人,专注于面向 AI 的云上基础设施建设工作,有近 10 年分布式及 AI 优化经验。推动了万卡规模异构大集群建设和落地,支撑百度文心等超大模型的训练和发布。
今年 5 月,QCon全球软件开发大会即将落地广州,从下一代软件架构、金融分布式核心系统、现代编程语言、AIGC、现代数据架构、新型数据库、业务出海的思考、大前端变革等角度与你探讨,点击了解详情。




