背景介绍
HDFS
HDFS 全称是 Hadoop Distributed System。HDFS 是为以流的方式存取大文件而设计的。适用于几百 MB,GB 以及 TB,并写一次读多次的场合。
构成 HDFS 主要是 Namenode(master)和一系列的 Datanode(workers)。Namenode 负责管理 HDFS 的目录树和相关的文件元数据,Datanode 则是存取文件实际内容的节点,Datanodes 会定时地将 block 的列表汇报给 Namenode。
如果 Namenode 出现了故障,整个 HDFS 集群将不可用,除非 Namenode 机器重启,并且需要等待一定时间的回复初始化之后,才能正常提供服务。除此之外,Namenode 还存在内存的瓶颈,当整个 HDFS 集群当中文件的数据达到一定的上限之后,Namenode 将出现一系列与内存相关的问题。
Map Reduce
MapReduce 是 Hadoop 中处理海量计算的编程模型。在这种编程模型下,用户通过定义一个 map 函数和一个 reduce 函数来解决问题。构成 Map Reduce 只要是 JobTracker(master)和一系列的 TaskTraker(workers)。
JobTracker 负责管理,分配和监控所有的计算任务,TaskTraker 则是实际执行任务的节点,TaskTraker 会将任务的执行情况都汇报给 JobTracker。
如果 JobTracker 出现了故障,集群中所有正在执行的计算任务都会失败,并且在重启 JobTracker 之前,无法在提交任何计算任务。
Hive
Hive 是基于 Hadoop 的一种数据查询工具,它可以将结构化的数据文件映射为一张数据库表,并提供完整的 SQL 查询功能,能够将 SQL 语句转换为 MapReduce 任务进行运行。
Cassandra
Cassandra 是一款面向列的 NoSQL 数据库,和 Google 的 BitTable 数据库属于同一类。此数据库比一个类似 Dynamo 的 Key Value 数据库功能更多,但相比面向文档的数据库(例如 MongoDB),它所支持的查询类型要少。
Cassandra 结合了 Dynamo 的 Key Value 与 Bigtable 的面向列的特点:
- 模式灵活:不需要象数据库一样数据使用预先设计的模式,增加或者删除字段非常方便(on the fly)。
- 支持范围查询:可以对任意 Key 进行范围查询。
- 支持二级索引查询:可以对任意列(Column)的值进行查询。
- 支持 Map Reduce 计算:可以对 Cassandra 中的数据批量进行复杂的分析计算。
- 数据具备最终一致性,集群整体的可用性非常高。
- 高可用,可扩展:单点故障不影响集群服务,集群的性能可线性扩展。
- 数据可靠性高:一旦数据写入成功,数据就已经在机器的磁盘中完成了存储,不容易丢失。
Brisk
Brisk 是由 DataStax 开发的一款基于 Apache Cassandra 的开源产品,它提供了 HadoopMapReduce,HDFS 和 Hive 所包含的相关功能。Brisk 中包含了一个与 HDFS 接口兼容的 CassandraFS 。 与 HDFS 相比,CassandraFS 没有单点故障,整个文件系统所能承载的文件上限也不会受机器内存上限的影响。
用户如果希望使用 Brisk 来替代整个 Hadoop 系统,整个系统的部署图如下:
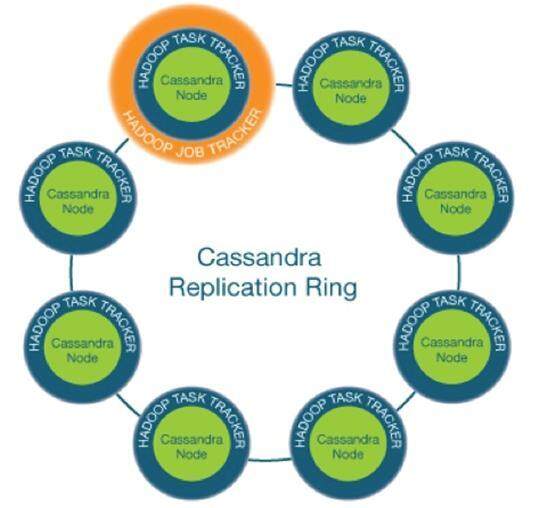
整个系统只需要三类角色即可:
- Cassandra
- TaskTracker
- JobTracker
其中 Cassandra Node 负责实时数据读写和海量文件的存储(HDFS),TaskTracker 和 JobTracker 负责海量计算(MapReduce)。
每个模块的功能图示如下:
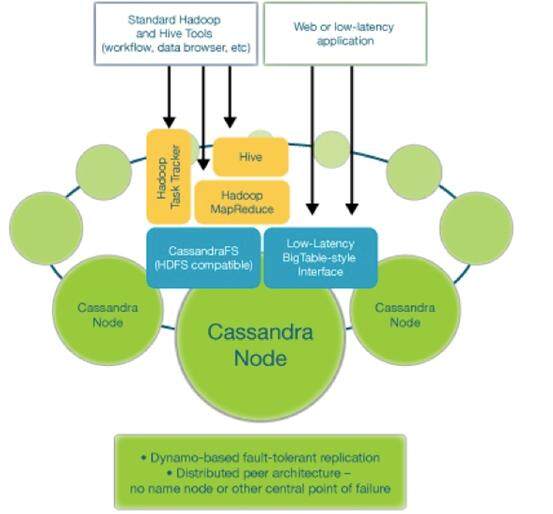
Brisk 单机部署
环境配置
下载 brisk-1.0~beta2-bin.tar.gz,jdk6 并解压。
配置环境变量
export JAVA_HOME=/home/aaron/jdk1.6.0_25
export BRISK_HOME=/home/aaron/brisk-1.0~beta2
export PATH=$JAVA_HOME/bin::$BRISK_HOME/bin:$PATH
修改 Cassandra 中数据存放的目录配置参数文件:$BRISK_HOME /resources/cassandra/conf/cassandra.yaml
# directories where Cassandra should store data on disk.
data_file_directories:
- /var/lib/cassandra/data
# commit log
commitlog_directory: /var/lib/cassandra/commitlog
# saved caches
saved_caches_directory: /var/lib/cassandra/saved_caches
将上面的路径修改为合适的路径,如:
# directories where Cassandra should store data on disk.
data_file_directories:
- /home/aaron/brisk-1.0~beta2/resources/cassandra/data
# commit log
commitlog_directory: /home/aaron/brisk-1.0~beta2/resources/cassandra/commitlog
# saved caches
saved_caches_directory: /home/aaron/brisk-1.0~beta2/resources/cassandra/saved_caches
修改 Cassandra 中日志存放的目录配置参数文件:$BRISK_HOME/resources/cassandra/conf/log4j-server.properties
# Edit the next line to point to your logs directory
log4j.appender.R.File=/var/log/cassandra/system.log
将上面的路径修改为合适的路径,如:
# Edit the next line to point to your logs directory
log4j.appender.R.File=/home/aaron/brisk-1.0~beta2/resources/cassandra/system.log
安装 JNA(可选)
下载 jna.jar,并放到 $BRISK_HOME/resources/cassandra/lib 目录中。
修改 /etc/security/limits.conf,加入如下内容:
$USER soft memlockunlimited
$USER hard memlock unlimited
其中 $USER 为实际运行 Brisk 的用户名称。
启动 Brisk
在命令行中执行如下命令即可:
briskcassandra -t
使用 CassandraFS
CassandraFS 的使用与 HDFS 一致,唯一的区别在于命令行多了一个 brisk 的前缀。
如创建一个文件夹 /test。
在 HDFS 中的命令为:
hadoopfs –mkdir /test
<p> 在 CassandraFS 中执行的命令为:</p><p>briskhadoopfs –mkdir /test</p>
Brisk 集群部署
本文将配置 3 台服务器进行说明示例:
- 192.168.104.139
- 192.168.104.142
- 192.168.104.143
环境配置
每台服务器在单机部署的基础之上,还需要修改 Cassandra 的配置文件 resources/cassandra/conf/cassandra.yaml
cluster_name: 'BriskTest'
initial_token:
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
- seeds: "192.168.104.139,192.168.104.142,192.168.104.143"
#每台服务器需要填写实际的 ip 地址
listen_address: 192.168.104.139
启动 Brisk
在每台服务器的命令行中执行如下命令即可:
briskcassandra–t
在启动之后,可以通过下面的命令查看到集群的状态,如果所有的服务器节点都加入到环中,并且状态为 Up,说明所有的服务器都正常启动了:
aaron@t01:~/brisk-1.0~beta2/resources/cassandra$ sh bin/nodetool -h 192.168.104.139 -p 7199 ring
Address DC Rack Status State Load Owns Token
98783511047116141127937631965326696126
192.168.104.142 Brisk rack1 Up Normal 76.4 KB 80.25% 65174827350587778232091121501149362614
192.168.104.139 Brisk rack1 Up Normal 66.2 KB 13.78% 88615937102692658579489875256308528421
192.168.104.143 Brisk rack1 Up Normal 66.2 KB 5.98% 98783511047116141127937631965326696126
CassandraFS 工作原理
CassandraFS 的实现非常精简巧妙,是基于 Cassandra0.8.1 和 Hadoop 0.20.203 的实现,并在此之上做了简单的扩展实现的。。
Cassandra 改动
为了让 Cassandra 能够支持文件存储的功能,Brisk 在 thrift 接口文件($BRISK_HOME/interface/brisk.thrift)中定义了支持类似 HDFS 中分块存储文件的基本功能接口:
LocalOrRemoteBlockget_cfs_sblock(
1:required string caller_host_name,
2:required binary block_id,
3:required binary sblock_id,
4:i32 offset=0,
5:required StorageTypestorageType)
throws (
1:InvalidRequestException ire,
2:UnavailableException ue,
3:TimedOutException te,
4:NotFoundException nfe)
为了能够实现这个接口,Brisk 又修改 Cassandra 的启动脚本($BRISK_HOME/resources/cassandra/bin/Cassandra)逻辑:
将默认的启动主类:
classname="org.apache.cassandra.thrift.CassandraDaemon"
修改为:
classname="com.datastax.brisk.BriskDaemon"
新的启动主类 com.datastax.brisk.BriskDaemon 在实现原有接口(cassandra.thrift)的基础之上,而外实现了 brisk.thrift 中定义的 get_cfs_sblock 接口。
Cassadnra 中定义了新的 keyspace 存储文件的元数据信息和数据块信息:
Keyspace: cfs:
Replication Strategy: org.apache.cassandra.locator.NetworkTopologyStrategy
Durable Writes: true
Options: [Brisk:1, Cassandra:0]
其中存储文件的元数据信息 ColumnFamily 的定义如下:
ColumnFamily: inode
"Stores file meta data"
Key Validation Class: org.apache.cassandra.db.marshal.BytesType
Default column value validator: org.apache.cassandra.db.marshal.BytesType
Columns sorted by: org.apache.cassandra.db.marshal.BytesType
Row cache size / save period in seconds: 0.0/0
Key cache size / save period in seconds: 1000000.0/14400
Memtable thresholds: 0.103125/128/1 (millions of ops/MB/minutes)
GC grace seconds: 60
Compaction min/max thresholds: 4/32
Read repair chance: 1.0
Replicate on write: false
Built indexes: [inode.parent_path, inode.path, inode.sentinel]
Column Metadata:
Column Name: parent_path (706172656e745f70617468)
Validation Class: org.apache.cassandra.db.marshal.BytesType
Index Name: parent_path
Index Type: KEYS
Column Name: path (70617468)
Validation Class: org.apache.cassandra.db.marshal.BytesType
Index Name: path
Index Type: KEYS
Column Name: sentinel (73656e74696e656c)
Validation Class: org.apache.cassandra.db.marshal.BytesType
Index Name: sentinel
Index Type: KEYS
其中存储文件的数据块信息 ColumnFamily 的定义如下:
ColumnFamily: sblocks
"Stores blocks of information associated with a inode"
Key Validation Class: org.apache.cassandra.db.marshal.BytesType
Default column value validator: org.apache.cassandra.db.marshal.BytesType
Columns sorted by: org.apache.cassandra.db.marshal.BytesType
Row cache size / save period in seconds: 0.0/0
Key cache size / save period in seconds: 1000000.0/14400
Memtable thresholds: 0.103125/128/1 (millions of ops/MB/minutes)
GC grace seconds: 60
Compaction min/max thresholds: 16/64
Read repair chance: 1.0
Replicate on write: false
Built indexes: []
Hadoop 改动
在 Hadoop 的默认配置(core-default.xml)中,定义了 hdfs 文件类型的实现:
<property>
<name>fs.hdfs.impl</name>
<value>org.apache.hadoop.hdfs.DistributedFileSystem</value>
<description>The FileSystem for hdfs: uris.</description>
</property>
为了能够提供 Cassandra 特有的文件系统实现,Brisk 将 hadoop 默认的 hdfs 文件类型修改为了 cfs 文件类型,其在 core-site.xml 文件中的配置重置了默认配置:
<property>
<name>fs.cfs.impl</name>
<value>org.apache.cassandra.hadoop.fs.CassandraFileSystem</value>
</property>
<property>
<name>fs.cfs-archive.impl</name>
<value>org.apache.cassandra.hadoop.fs.CassandraFileSystem</value>
</property>
其中 org.apache.cassandra.hadoop.fs.CassandraFileSystem 与 HDFS 中默认的实现 org.apache.hadoop.hdfs.DistributedFileSystem 一样,都继承于 Hadoop 通用的文件接口基类 org.apache.hadoop.fs.FileSystem,所有能够保证接口的兼容性。
此外,Brisk 还修改了 HDFS 中默认使用的文件类型:
<property>
<name>fs.default.name</name>
<value>cfs:///</value>
</property>
所以在当我们在 Brisk 环境中调用 HDFS 的操作时,都将定向到 cfs 的实现,如:
briskhadoopfs -ls /test
将相应地转化为:
briskhadoopfs -ls cfs:///test
org.apache.cassandra.hadoop.fs.CassandraFileSystem 中所有文件的操作都是通过调用 Brisk 中提供的 get_cfs_sblock 接口服务来实现读写操作的,通过整合这些模块,从而完成了利用 Cassandra 替换 HDFS 的需求。
不过目前 CassandraFS 实现和 HDFS 的实现还是有一些区别的,比如不支持权限,不支持追加写入等等。
关于作者
郭鹏,《Cassandra 实战》作者,爱好 NoSQL 以及 Hadoop 相关的开源产品。
感谢张凯峰对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家加入到 InfoQ 中文站用户讨论组中与我们的编辑和其他读者朋友交流。




