
『看看论文』是一系列分析计算机和软件工程领域论文的文章,我们在这个系列的每一篇文章中都会阅读一篇来自 OSDI、SOSP 等顶会中的论文,这里不会事无巨细地介绍所有的细节,而是会筛选论文中的关键内容,如果你对相关的论文非常感兴趣,可以直接点击链接阅读原文。
本文要介绍的是 2018 年 ATC 期刊中的论文 —— NanoLog: A Nanosecond Scale Logging System1,该论文实现的 NanoLog 是高性能的日志系统,与 C++ 社区中的其他日志系统,例如:spdlog、glog 和 Boost Log 相比,它的性能可以高出 1 ~ 2 个数量级,我们在这篇文章中来简要分析 NanoLog 的设计与实现原理。
日志是系统可观测性的重要一环,相信很多工程师都有线上出问题临时加日志查问题的经历,作者刚刚又重新经历了这一过程,稍有经验的开发者都会在系统中加入很多日志方便生产环境的问题排查,更有经验的开发者会谨慎地在系统中(尤其是低延迟的实时系统)添加日志,因为打印日志这件看起来简单的事情实际上会带来很大的额外开销。
打印日志是一件简单的事情,几乎所有的工程师在踏上编程之路的第一天起就学会了如何使用 printf 等函数向标准输出打印字符串,在 99% 的程序中使用这种做法都不会带来性能问题,只是在生产环境中我们会使用结构化的、容易解析的格式替代 printf,例如:在日志中加入时间戳、文件名和行数等信息。

图 1 - 常见的日志系统
但是剩下 1% 的程序要求超低延迟的系统,它们对响应时间的要求可能是微秒甚至纳秒级别的。在这种场景下,如果仍然需要日志系统提供可观测性,我们需要深入研究向标准输出或者文件写日志的细节,例如:使用缓冲区、异步写入文件以及减少反射等动态特性的使用,除此之外,我们还要保证日志输出的顺序、避免消息丢失或者截断。
spdlog、glog 和 Boost Log 已经能够满足绝大多数应用程序的需求,但是对于这些延迟机器敏感的应用程序,打印日志需要的几微秒可能会显著地增加请求的处理时间影响程序的性能,而今天分享的 NanoLog 是一个可以在纳秒尺度打印日志的系统。
架构设计
NanoLog 能在纳秒尺度打印日志是因为它能够在编译期间提取静态日志消息并在离线阶段处理日志的格式化等问题。其核心优化都建立在以下两个条件上:
开发者可直接阅读的格式化日志不一定要在应用程序运行时直接生成,我们可以在运行期间记录日志的动态参数并在运行后按需生成;
日志消息中的绝大部分信息都是静态冗余的,只有少数参数会发生变化,我们可以在编译期间获取日志的静态内容并仅在后处理器中打印一次;
正是因为大多数日志都遵循上述特性,所以 NanoLog 可以在它们的基础上实现纳秒尺度的日志打印。NanoLog 的不同设计方式决定了它与传统日志模块会在架构上有很大的差异,它由以下三个组件构成:
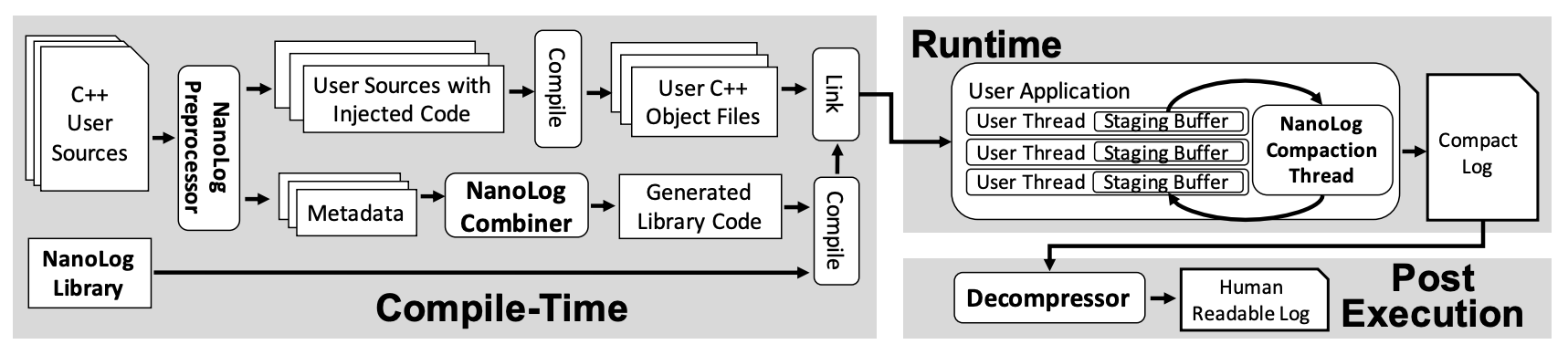
图 2 - NanoLog 系统架构
预处理器:在编译期间从源代码提取日志消息、将原始日志语句替换成优化过的代码并为每条日志消息生成压缩、字典辅助函数;
运行时库:在缓冲区中缓存多个线程打印的日志并使用预处理阶段生成的辅助函数输出压缩后的二进制日志;
解码器:利用预处理阶段生成的包含静态信息的字典解码日志,获取可以被人类阅读的日志;
传统的日志系统都仅包含运行时,我们只需要在开发时引入头文件、链接静态库或者动态库并在代码中指定的位置输出日志,日志系统会程序运行期间将日志打印到标准输出或者指定文件。
但是 NanoLog 打破了上述这种传统的设计,为了减少运行时的开销,我们将一部分操作迁移到了编译期间和运行后,这也遵循工作质量守恒定律:工作不会凭空消失,它只会从运行时转移到程序生命周期的其他阶段,NanoLog 就使用了下面的操作降低了日志系统的开销:
在编译时重写了日志语句移除静态信息并将昂贵的格式化操作推迟到代码运行后的阶段,这能够在运行时减少大量的计算和 I/O 带宽需求;
为每个日志消息编译了特定代码,能够高效地处理动态参数,避免在运行时解析日志消息并编码参数类型;
使用轻量级的压缩算法以及不保序的日志减少运行时的 I/O 和处理时间;
使用后处理组合压缩的日志数据和编译时提取的静态信息生成可读的日志;
实现原理
这一节我们将简要分析 NanoLog 系统中三大组件,即预处理、运行时和后处理的具体实现原理。
预处理
NanoLog 使用 Python 来实现预处理器,程序的入口在 processor/parser 中,它会扫描用户的源文件、生成元数据文件和修改后的源代码,接下来会将这些修改后的代码编译到 .so 或者 .a 文件中,而不是编译初始的代码。除此之外,预处理器还会读取生成的所有元数据文件、生成 C++ 源代码并编译到 NanoLog 的运行时库和最后的用户程序中:
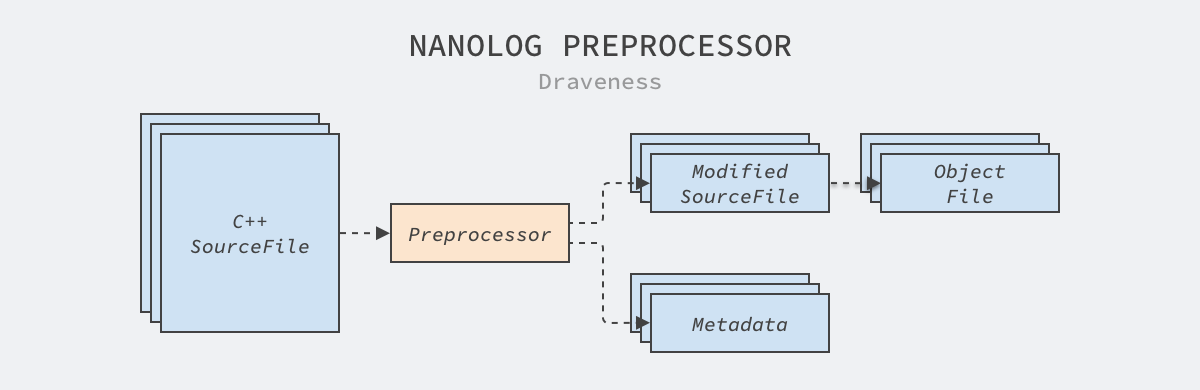
图 3 - 预处理器
它会为源代码中的每个 NANO_LOG 生成两条语句,即 record 和 compress,其中前者记录日志中的动态参数,后者压缩记录的数据减少程序的 I/O 时间。下面是预处理器生成的 record 函数:
inline void __syang0__fl__E32374s3237424642lf__s46cc__100__(NanoLog::LogLevel level, const char* fmtStr , const char* arg0, int arg1, int arg2, double arg3) { extern const uint32_t __fmtId__E32374s3237424642lf__s46cc__100__; if (level > NanoLog::getLogLevel()) return; uint64_t timestamp = PerfUtils::Cycles::rdtsc(); size_t str0Len = 1 + strlen(arg0);; size_t allocSize = sizeof(arg1) + sizeof(arg2) + sizeof(arg3) + str0Len + sizeof(NanoLogInternal::Log::UncompressedEntry); NanoLogInternal::Log::UncompressedEntry *re = reinterpret_cast<NanoLogInternal::Log::UncompressedEntry*>(NanoLogInternal::RuntimeLogger::reserveAlloc(allocSize)); re->fmtId = __fmtId__E32374s3237424642lf__s46cc__100__; re->timestamp = timestamp; re->entrySize = static_cast<uint32_t>(allocSize); char *buffer = re->argData; // Record the non-string arguments NanoLogInternal::Log::recordPrimitive(buffer, arg1); NanoLogInternal::Log::recordPrimitive(buffer, arg2); NanoLogInternal::Log::recordPrimitive(buffer, arg3); // Record the strings (if any) at the end of the entry memcpy(buffer, arg0, str0Len); buffer += str0Len;*(reinterpret_cast<std::remove_const<typename std::remove_pointer<decltype(arg0)>::type>::type*>(buffer) - 1) = L'\0'; // Make the entry visible NanoLogInternal::RuntimeLogger::finishAlloc(allocSize);}每个函数都包含特定的 fmtId,日志的压缩和解压也都会用到这里生成的标识符,上述函数还会为参数分配内存空间并按照顺序调用 recordPrimitive 将所有参数记录到缓冲区中。压缩使用的 compress 也遵循类似的逻辑:
inline ssize_tcompressArgs__E32374s3237424642lf__s46cc__100__(NanoLogInternal::Log::UncompressedEntry *re, char* out) { char *originalOutPtr = out; // Allocate nibbles BufferUtils::TwoNibbles *nib = reinterpret_cast<BufferUtils::TwoNibbles*>(out); out += 2; char *args = re->argData; // Read back all the primitives int arg1; std::memcpy(&arg1, args, sizeof(int)); args +=sizeof(int); int arg2; std::memcpy(&arg2, args, sizeof(int)); args +=sizeof(int); double arg3; std::memcpy(&arg3, args, sizeof(double)); args +=sizeof(double); // Pack all the primitives nib[0].first = 0x0f & static_cast<uint8_t>(BufferUtils::pack(&out, arg1)); nib[0].second = 0x0f & static_cast<uint8_t>(BufferUtils::pack(&out, arg2)); nib[1].first = 0x0f & static_cast<uint8_t>(BufferUtils::pack(&out, arg3)); if (true) { // memcpy all the strings without compression size_t stringBytes = re->entrySize - (sizeof(arg1) + sizeof(arg2) + sizeof(arg3) + 0) - sizeof(NanoLogInternal::Log::UncompressedEntry); if (stringBytes > 0) { memcpy(out, args, stringBytes); out += stringBytes; } } return out - originalOutPtr;}日志的记录和压缩函数都是 Python 的预处理器分析源代码生成的,工程师在开始时使用的 NANO_LOG 会被预处理器展开成新的代码,该预处理器与 C++ 的预处理器有非常相似的功能,只是这里需要展开的代码过于复杂,我们很难在 C++ 中使用预处理器实现。
运行时
应用程序静态链接的 NanoLog 运行时会通过线程上的缓冲区解耦记录动态参数的低延时 record 操作和磁盘 I/O 等高延迟操作。线程上的缓冲区会存储 record 方法调用的结果,这些数据对后台的压缩线程也是可见的:
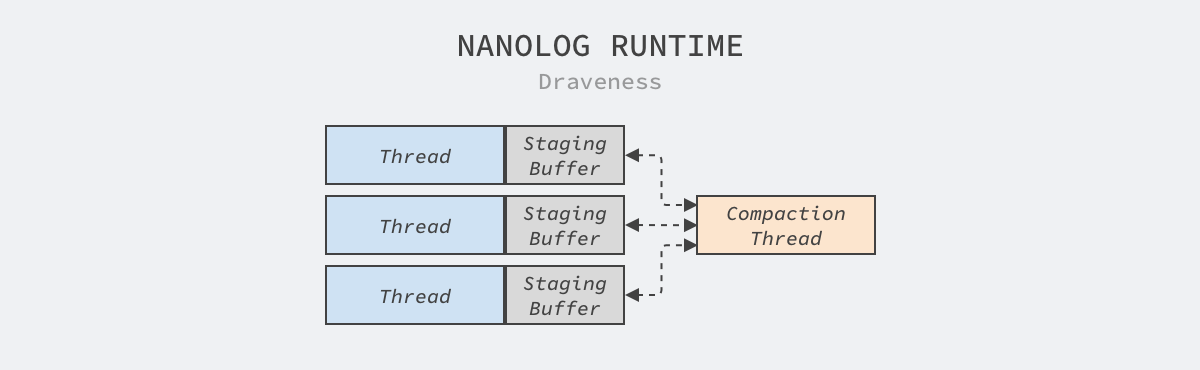
图 4 - 运行时
线程上用于暂存数据的缓冲区是程序提升性能的关键,我们要尽可能满足避免锁竞争和缓存一致性带来的额外开销,暂存缓冲区使用环形队列和单生产者的消费者模型降低数据的同步开销。
图 5 - 环形队列
环形队列是一个连续的、使用固定大小缓存的数据结构,它的头尾是相连的,非常适合缓存数据流,Linux 内核就使用这种数据结构作为 Socket 的读写缓冲区2,而音视频也会使用环形队列暂存刚刚收到还没有被解码的数据。
struct __kfifo { unsigned int in; unsigned int out; unsigned int mask; unsigned int esize; void *data;};运行时不仅通过无锁环形队列提升性能,还需要解决环形队列中的日志消费问题。为了提高后台线程的处理能力,运行时会将日志的组装推迟到后处理并压缩日志数据减少 I/O 高延迟带来的影响。
后处理
后处理器的实现相对比较简单,因为每条日志都包含特定的标识符,后处理器会根据该标识符在压缩后的日志头中找到编译时生成的相关信息,并根据这些信息展开和解压日志。
需要注意的是,因为在运行期间每个线程都有自己的暂存缓冲区存储日志,所以 NanoLog 最终打印的日志不能严格保证时间顺序,它只能保证日志输出的顺序在大体上是有序的。
总结
NanoLog 是设计非常有趣、值得学习的日志系统,但是它并不适合所有的项目,它将原本运行时需要完成的工作转移到了编译期间和后处理阶段,减轻了程序运行时的负担,但是其输出的二进制日志是无法直接阅读的,这也增加了开发者处理日志的工作量。
虽然论文中提到,日志分析引擎基本都会收集、解析并分析工程师可以直接阅读的日志,而大多数的时间都花费在了日志的读取和解析上,使用二进制的日志不仅能够减少读取和解析的时间,还能减少昂贵的 I/O 和使用的带宽,但是这点在我们的系统中是否是优点就见仁见智了。
日志使用二进制的输出格式确实能够降低多方面的成本,但是它不仅需要日志收集和解析系统的支持,还牺牲了开发者本地调试的体验,而如果没有自动收集并解压日志的模块,手动解压线上日志排查问题是非常糟糕的体验,不过在极端的性能场景下我们可能也没有太多的选择,哪怕牺牲体验可能也要上。
推荐阅读
Stephen Yang, Seo Jin Park, and John Ousterhout. 2018. NanoLog: a nanosecond scale logging system. In Proceedings of the 2018 USENIX Conference on Usenix Annual Technical Conference (USENIX ATC ‘18). USENIX Association, USA, 335–349. ↩︎
Linux Kernel, include/linux/kfifo.h https://elixir.bootlin.com/linux/v5.10.11/source/include/linux/kfifo.h#L44 ↩︎
本文转载自:Draveness




