
Uber 最近详细介绍了它构建 Genie 的经历,这是一款由 AI 驱动的随时待命的 Copilot,旨在提高随时待命的支持工程师的效率。Genie 利用检索增强生成(RAG)技术提供准确的实时响应,并显著提高事件响应的速度和效率。
自 2023 年 9 月推出以来,Genie 对 Uber 的支持团队产生了重大影响。它已在 154 个 Slack 频道中回答了超过 70,000 个问题,节省了大约 13,000 个工程小时,根据用户的评估,其回答有效率为 48.9%。
Uber 的待命工程师通常花费大量时间答复重复的查询或浏览零散的文档,使用户难以独立找到答案。这些情况导致了响应时间过长和生产力下降,这也是构建 Genie 的驱动力。
Uber 使用检索增强生成(RAG)来驱动 Genie。RAG 是一种创新方法,它将信息检索系统的优势与生成式 AI 模型相结合,以产生准确且相关的响应。它让 Uber 可以利用现有知识来源快速部署解决方案,这样就用不着 AI 模型微调所需的大量示例数据了。
Genie 从各种内部来源提取数据,例如 Uber 的 wiki、Stack Overflow 和工程文档。信息被抓取后,使用 OpenAI 模型转换为向量嵌入,并存储在 Uber 的内部向量数据库 Search In Action(SIA)中。Genie 仅从预先批准的数据源提取数据,且不包含敏感数据,以避免泄露敏感信息。
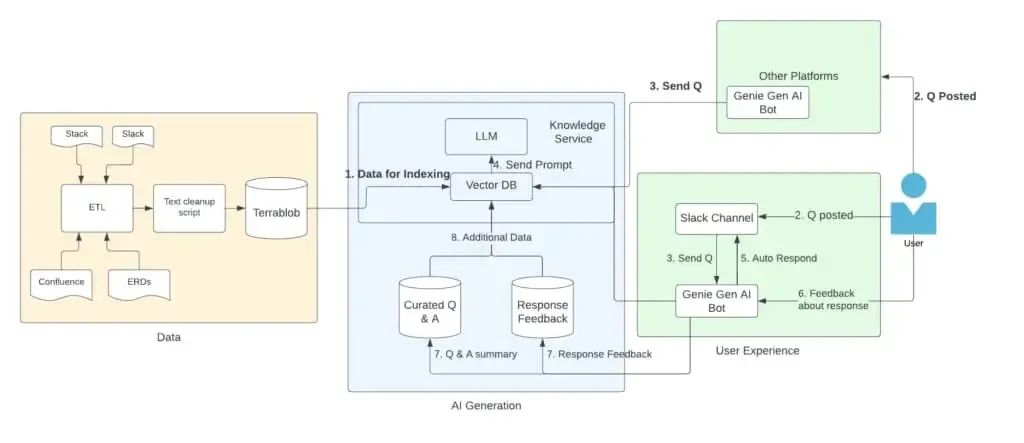
Genie 的整体架构(来源)
当用户在 Slack 中提出问题时,查询会被转换为嵌入,Genie 会使用该嵌入在向量数据库中获取上下文相似的数据。然后它将这些数据输入到大型语言模型中,以根据检索到的信息生成准确的响应。
Uber 实施了一个指标框架,通过持续的实时用户反馈来提高 Genie 的性能。在 Genie 回答问题后,用户可以通过选择“已解决”、“有帮助”或“不相关”等选项来提供反馈。

Genie 的用户反馈流程(来源)
这些反馈通过 Slack 插件收集,并使用 Uber 的内部数据流系统处理,将指标发送到 Hive 表中分析。反馈循环允许 Uber 的团队跟踪 Genie 的帮助有效率,并根据真实的用户体验改进其响应。
对于性能评估,Uber 设计了一个自定义评估管道,用于评估各种指标,例如幻觉率和响应的相关性。该管道处理的是历史数据,包括 Slack 元数据、用户反馈和 Genie 以前的响应。它通过由 LLM 提供支持的评分系统来处理这些数据,用这个系统充当评判者。
Uber 还采用了一套文档评估流程,以保障 Genie 在其响应中检索和使用的信息的质量。系统将抓取的知识库转换为结构化格式,其中一行代表一个文档。
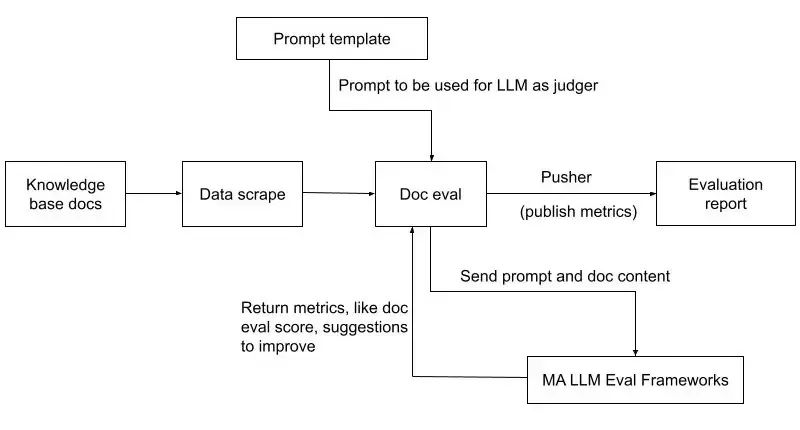
文档评估应用程序的工作流程(来源)
Genie 将这些文档输入带有自定义评估提示的 LLM 来评估每个文档的清晰度、准确性和实用性。然后,LLM 返回分数并提供改进每个文档的可行建议。此过程有助于保持底层文档的高标准,确保 Genie 的响应保持可靠和有效。
查看原文链接:




