
屏蔽语言建模(Maksed language modelling,MLM)是一种预训练范式,它将文本分词为语义上有意义的片段。尽管 MLM 是在自然语言处理任务中转换器取得卓越性能的主要贡献者,但它在正在革命计算机视觉研究的新兴视觉转换器(visual transformers,ViT)中的潜在应用仍然相对不足。
在一篇新论文中,来自字节跳动、约翰·霍普金斯大学、上海交通大学和加州大学圣克鲁斯分校的一个研究团队试图将 MLM 应用于训练更好的视觉转换器,即 iBOT(使用在线分词器的图像 BERT 预训练),一个通过在线分词器执行屏蔽预测的自监督框架。

MLM 预训练转换器已经证明了它们在一系列语言任务中的成功性和可扩展性,这使得许多从事计算机视觉工作人员思考 ViTs 是否也能从某种形式的 MLM 中获益。
为了找到答案,研究人员探索了屏蔽图像建模(masked image modelling,MIM)以及使用一个语义上有意义的可视化分词器的优势和挑战。该团队首先确定语言分词器为最关键的 MLM 组件,该分词器旨在将语言转换为语义上有意义的标记。
他们提出,启用 MIM 需要设计一个类似语言分词器的组件——一个视觉分词器——来将屏蔽的补丁转换为目标模型的监管信号。这项任务是具有挑战性的,因为与根据词频统计分析的语言语义不同,视觉语义由于图像的连续性而不容易提取。
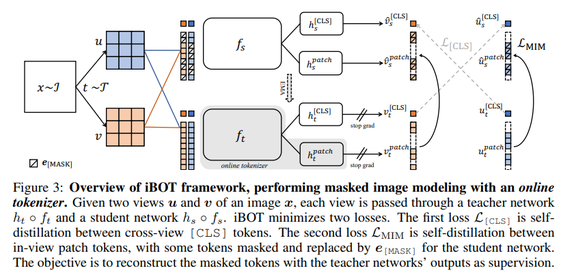
研究人员创建了 iBOT 来执行 MIM,使用了一种设计良好的视觉分词器。他们将 MIM 公式化为知识提取(knowledge distillation,KD),并建议在在线分词器的帮助下执行 MIM 的自提取。这样,目标网络可以将屏蔽图像作为输入,而在线分词器保留原始图像。目标是训练目标网络学习将每个屏蔽补丁词块恢复成相对应的分词器输出。
这个团队确定了他们的分词器的两个自然优势:
它通过在类标记上强制执行交叉视图图像的相似性来捕获高级视觉语义;
在预处理设置中不需要额外的训练阶段,因为它通过动量更新与 MIM 联合优化。
在他们的实证研究中,该团队在 ImageNet-1K 分类基准上使用 5 种协议对 iBOT 进行了评估:k-NN、线性探测(linear probing)、微调(fine-tuning)、半监督学习和无监督学习。他们还将 iBOT 传给下游任务,例如 COCO 上的对象检测和实例分割,以及 ADE20K 上的语义分割。
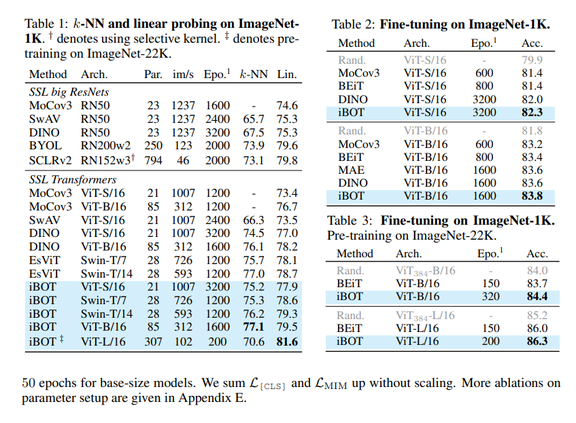
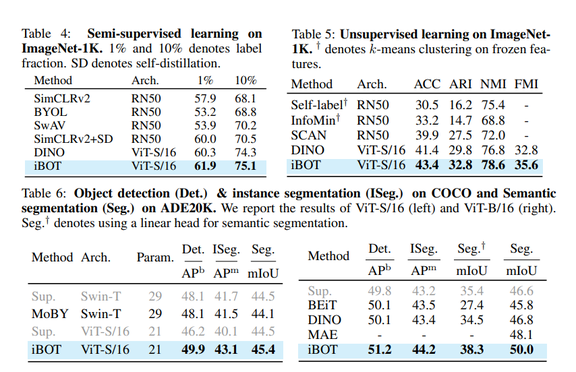
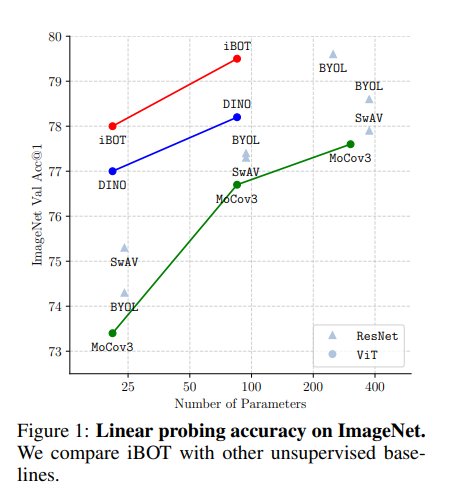
结果表明,iBOT 在 k-NN(77.1%)、线性探测(79.5%)和微调协议(83.8%)下提高了 ImageNet-1K 分类基准,比之前的最佳结果分别高出 1.0%、1.3%和 0.2%。除了最先进的图像分类性能外,iBOT 在所有下游任务上也都优于之前的结果。
总的来说,这项工作证明了 BERT 式图像转换器预训练的潜力,MIM 方法不仅可以实现高检测精度,还可以提高对常见图像损害的鲁棒性。
原文链接:




