随着多核处理器成为主流,应用开发人员对于如何编写高伸缩性的应用以利用底层硬件的优势这个问题面临巨大的压力。此外,遗留系统不得不移植到新的架构上。 保证应用伸缩性的一种有效方式是使用高伸缩性组件构建应用。举例来说,在各种应用 中,java.util.concurrent.ConcurrentHashMap 可以替代同步的 HashTable,使应用伸缩性更好。因此,向应用 直接提供一套高伸缩性构造块以引入并行是非常有用的。
我们创建了一套高伸缩性并发 Java 组件作为 Amin 库项目的一部分。在本文中,我们将介绍一些创建该开源库的想法。
概述
作为软件工程师,我们不得不并行我们的应用使它们在多核机器上很好的伸缩。一种并行方式是把它们分成若干子任务,其中每一个子任务与应用的其他子任务通信和同步。这通常被称为基于任务的并发。我们可以基于子任务的通信模式将应用分类。
- 尴尬式并行——应用的子任务从不或者很少与其他子任务通信。通常情况下,每一个任务只处理自己的私有数据。一些例子包括:
- 蒙特卡洛模拟程序
- 快速排序程序,使用 fork/join 模式很容易实现并发。当我们处理尴尬式并行应用时容易得到很好的伸缩性。
- 粗粒度和细粒度式并行——这些应用的子任务需要互相通信。根据子任务之间的通信频率可以把程序分为粗粒度和细粒度并行。一个例子是生产者 / 消费者问题。生 产者产生驱动消费者的数据。从生产者到消费者的数据发送需要通信。相比尴尬式并行应用,处理子任务频繁交互的应用较难得到良好的伸缩性。
经过为伸缩性而优化的组件非常有益于解决这些困难问题。举例来说,如果存在一个高伸缩性队列组件,那么实现生产者 / 消费者伸缩性相对容易些。本文中,我们提供了若干通用技术提高软件组件的伸缩性。
针对伸缩性的分析
应用分析是开发过程的重要方面。分析是为了了解应用的运行特征。分析数据经常被用于提高应用的性能和伸缩性。大多数分析器遵从一个简单的执行模式,其中有 一个配置阶段。在该阶段,根据信息获取的类型,会配置不同层次的计算堆栈。硬件计数器可以被用来监控硬件事件。操作系统可以通过配置各种操作系统事件来监 控。如果在计算层次中还有虚拟机,那么需要配置以访问虚拟机的事件。最后,应用需要配置以得到真实应用的事件。优秀的分析器能够在不要求应用重新编译的情 况下完成这些配置。大多数分析器通常都配置虚拟机和应用层。应用在配置之后运行时,会生成跟踪信息,例如函数运行时间、资源使用情况、硬件性能参数、锁使 用、系统时间、用户时间等等。不同的分析器会在把跟踪信息输出到文件系统前做一些计算。最后,分析器会通过显示界面可视化这些数据。
用于并发应用的分析器需要提供有关线程、锁竞争和同步点的详细信息。我们使用了下面一些分析器作为 Amino 性能分析:
- Java 锁监控器(Java Lock Monitor)——Java 开发人员使用该工具分析应用中锁的使用情况。在运行时,监控组件收集各种锁数据用于发现锁竞争。该工具能够通过表格展示详细 的锁和竞争信息。IBM Java Lock Analyzer (JLA) 是另一个提供锁信息的工具。它与 JLA 类似,只不是通过图形界面显示缩合竞争数据。两个工具都支持 x86 和 Power 平台。
- THOR——该工具用于详细分析 Java 应用的性能。它能够深入分析完整的执行栈,从硬件到应用层。信息来自于栈的四个层面——硬件、操作系统、JVM 和 应用。用户可以看到锁竞争的信息以及对应的代码、瓶颈、多核之间的线程迁移和竞争导致的性能下降。该工具支持 x86 和 Power 平台。
- AIX 性能工具——IBM 的 AIX 操作系统自带一套底层的性能分析和调试工具。其中包括:
- Simple Performance Lock Analysis Tool (SPLAT) ——该工具是 AIX 系统上的一个锁分析工具,可以通过命令行运行,用于分析各种内核级的锁。同时,它也可以分析和显示用户级锁(读 / 写和 mutex)的竞 争。应用必须启用跟踪选项,SPLAT 需要用到这些跟踪数据。
- XProfiler——该分析工具基于 X—Windows,用于 C 语言应用的函数级分析,能够显示在用户代码中计算敏感的函数。如果要使用 XProfiler,代码需要使用特殊的标志(-pg 选项)编译。
- prof、tprof 和 gprofncbr——各种 prof 命令都可以用于分析用户应用。prof 命令能够得到所有应用中的外部符号和函数。gprof 是 prof 的超集,可以获得应用的调用关系图。最后,tprof 用于得到应用的宏观和微观的分析信息。tprof 能够得到各个指令、子程序、线程、进程的计 时数据,还有用户模式函数、库函数、Java 类、Java 方法、内核函数、内核扩展等的处理器使用情况。
减少热点
传统的性能调优方法,比如适用于顺序应用的方法也适用于并行应用。在完成传统调优之后,我们需要检查共享数据是如何被多线程访问的。通过使用 JLM 或者 JLA,我们能够发现线程在访问共享资源时是如何竞争的。
举例来说,如果应用有 100 个线程,并且所有的线程都需要从一个 java.util.HashTable 提取 / 存储元素,该应用的性能由于线程竞争会下降。每一个线程需要在访问该 HashTable 之前等待很长时间。
如果我们使用类似 JLM 的工具就会发现,该 Hash 表关联的 monitor 使用非常频繁。解决这一问题的办法是使用能够替代 HashTable 的高扩展性 组件。在本例中,我们可以通过 java.util.concurrent.ConcurrentHashMap 替换该 hash 表。 ConcurrentHashMap 把它的内部数据结构分成若干段。在应用中使用 ConcurrentHashMap 替换 HashMap 替换使线程针对多 个子组件竞争而不是单个大组件。使用 ConcurrentHashMap 的应用产生竞争的几率比之前要小得多。
还有一种办法降低访问共享组件的竞争几率。如果一个组件具有相反语义的操作,如栈的压入和弹出,这两种操作可以无需接触核心数据结构即可完成。这种技术最 早由 Danny Hendler、Nir Shavit 和 Lena Yerushalmi 引入,已经在 Amino 库中实现。这种方法的性能改善见图 1。
图 1. 性能比较:EBStack 和 TreiberStack
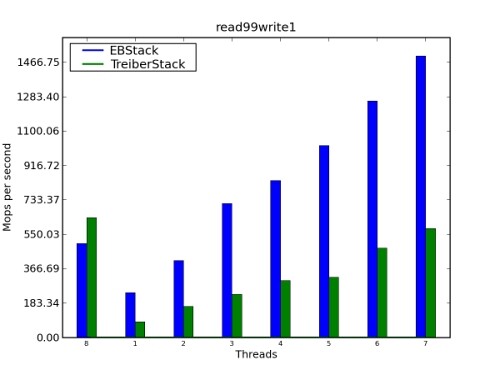
使用无锁 / 无等待算法
传统上,大家都采用基于锁的方法来确保共享数据的一致性和对关键区域的互斥访问。锁的概念易懂,但基于锁的算法引起了很多挑战。其中一些著名的问题包括死锁、活锁、优先级倒置和锁竞争等。锁竞争会减少组件和算法的可扩展性。
无锁和无等待算法到现在已经存在二十多年了。它们被认为可以能够解决大部分与锁有关的问题。这些算法支持在不使用任何锁算法的情况下更新共享数据结构,不 仅如此,还有助于创建扩展性良好的算法。最初,这些无锁和无等待的算法纯粹是理论兴趣。但是,随着算法社区的发展和新硬件的支持,无锁技术在现实产品中得 到了越来越多的应用,比如操作系统内核、虚拟机、线程库等。
从 JDK 1.5 以后,JDK 包含了这些无锁算法,比如 ConcurrentLinkedQueue、AtomicInteger 等。它们的伸缩性通常比对应的基于 锁的组件要好。当我们在 Amino 库实现新组件时,我们会使用目前研究的最新无锁算法。这使得 Amino 数据结构扩展性和效率非常好。但是有时候,特别是 在低核硬件上,无锁数据结构比基于锁数据结构的吞吐量差,但是一般来说,它们的吞吐量比较好。
尽可能减少比较—交换(CAS)操作
从 JDK 1.5 以后,JDK 包含了由 Doug Lea 开发的位于 java.util.concurrent 包的无锁的 FIFO(先进先出)队列。该队列采用的算法基于单链表的并发操作,最初由 Michael 和 Scott 开发。它的出列操作需要一次比较—交换,而入列操作需要两次比较—交换。这对入列和出列操作来说太容易了。但是分析数据(图 2)显示比较—交换操作占用了大部分执行时间,同时入列操作需要两次交换—比较,这增加了失败的概率。在现代多处理器上,一次成功的比较—交换操作要比一 次加载或者存储的时间长一个数量级,因为它们需要独立占用和冲刷处理器写缓存。
图 2. CAS 操作的执行时间
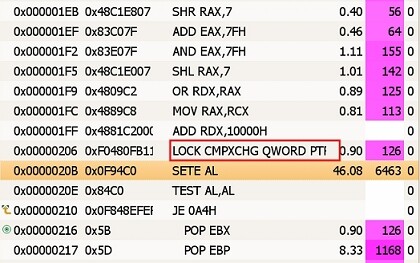
从图 2 可以看出,CAS 操作执行时间的百分比为 46.08%,几乎占了全部执行时间的一半。分析数据有一个操作的延迟。真正的时间是在"SETE AL"指令之后发生的。
Mozes 和 Shavit(MoS-queue)在它们的无锁队列算法中,提供了一种新颖的办法来降低入列操作时 CAS 的数量。其关键点在于替换单链表, 因为其中的指针在插入时需要浪费一次 CAS 操作,取而代之的是采用一个双链表,其中的指针在更新时只需要一次存储操作,如果事件乱序导致双链表不一致则可 以修复。
我们做了一次基准测试来比较 ConcurrentLinkedQueue(JSR166y)和 Mos-Queue 的性能。结果在图 3 中显示。对于大量线程来说,Mos-Queue 的性能优于 JDK ConcurrentLinkedQueue。
图 3. 性能比较:ConcurrentLinkedQueue 和 Mos-Queue
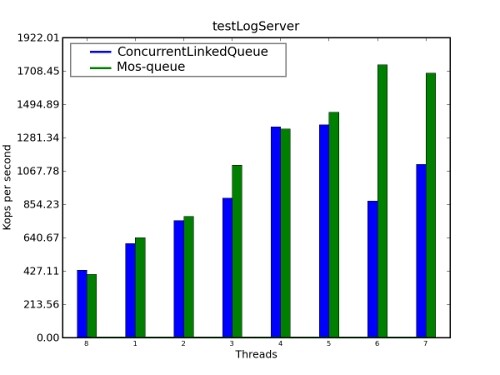
更多有关 Mos-Queue 的信息参见 Mozes 和 Shavit 的论文《An Optimistic Approach to Lock-Free FIFO Queues》。
减少内存分配
Java 虚拟机拥有一套强大、有效的内存管理体系。垃圾回收器能够压缩现有对象,以确保在垃圾回收之后 Java 堆里没有空隙。因为空闲空间在垃圾回收之后都是连续的,所以内存分配不多是增加了一个指针而已。
这对多线程应用同样有效,如果内存使用不敏感的话。JVM 为每一个线程分配了一个线程范围的缓存。在内存分配时,线程范围的缓存首先被使用。只有在线程范围的缓存被耗尽之后才会使用全局堆。
在线程范围内分配内存对应用性能非常有益,但是如果分配过于频繁,则会不起作用。根据我们的经验,线程范围的缓存在分配频率高的情况下会很快耗尽。
如果在循环中需要暂时性的对象,则线程范围的类会比较有益。如果我们在线程本地对象中存储临时对象,我们可以在每一次循环迭代中重用它。虽然,线程本地类会增加额外的负担,但是大多数时候都比在内存中频繁分配内存要好。
图 4. 性能比较:线程本地和分配
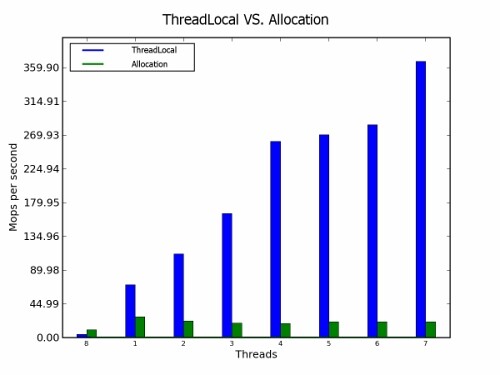
结论
在本文中,我们介绍了使用 Java 创建高扩展性组件的几个重要原则。一般来说,这些原则通常很有帮助,但是它们无法替代谨慎的测试和性能调优。
资源
- JLA , IBM Lock Analyzer for Java
- “ CAS-Based Lock-Free Algorithm for Shared Deques ” by Maged. It is a highly efficient algorithm of lock-free deque.
- “ Simple, fast, and practical non-blocking and blocking concurrent queue algorithms ” by Michael and Scott. It is a highly efficient algorithm of lock-free queue.
- “ An Optimistic Approach to Lock-Free FIFO Queues ” by Mozes and Shavit. It is another highly efficient algorithm of lock-free queue.
- In the Website for Amino project , get the sources of Amino project website.
- Browse the technology bookstore for books on these and other technical topics.
- A Scalable Lock-Free Stack Algorithm, Danny Hendler, Nir Shavit and Lena Yerushalmi, SPAA 2004, pages 206-215.
关于作者
Zhi Gan是 IBM 中国开发中心的软件工程师,在上海交通大学获得计算机安全方向的博士学位。Gan 博士在 SOA(面向服务的架构)、AOP(面向切面编程)和 Eclipse 领域拥有丰富的经验。他目前主要关注于使用 Java/C++ 进行并行软件开发。
Raja Das是 IBM 软件集团的软件架构师。目前,他正在开发支持多核 / 众核系统的库和框架。他之前是 WebSphere® Partner Gateway 的产品架构师。Das 博士感兴趣的领域包括编程语言、并行软件和系统。
Xiao Jun Dai是 IBM 中国开发中心的软件工程师,在中国科学院软件所获得计算机科学硕士学位。他在敏捷方法和编程语言方面拥有丰富的经验。他目前关注于并发编程和多核系统。
阅读英文原文: Creating Highly-Scalable Components in Java 。
感谢曹云飞对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家加入到 InfoQ 中文站用户讨论组中与我们的编辑和其他读者朋友交流。




