
广受欢迎的内存数据结构存储系统 Redis 最近发布了其增强版的查询引擎,恰逢向量数据库因在 GenAI 应用程序中的检索增强生成(RAG)功能而日益受到重视。
Redis 宣布对其查询引擎进行了重大改进,使用多线程来增强查询吞吐量,并确保低延迟。Redis 方面表示:
通过允许查询并发访问索引,有效地实现了垂直扩展,不仅增强了 Redis 的操作性能,也显著提升了查询的吞吐量。
下图描述了 Redis 的垂直扩展设计。
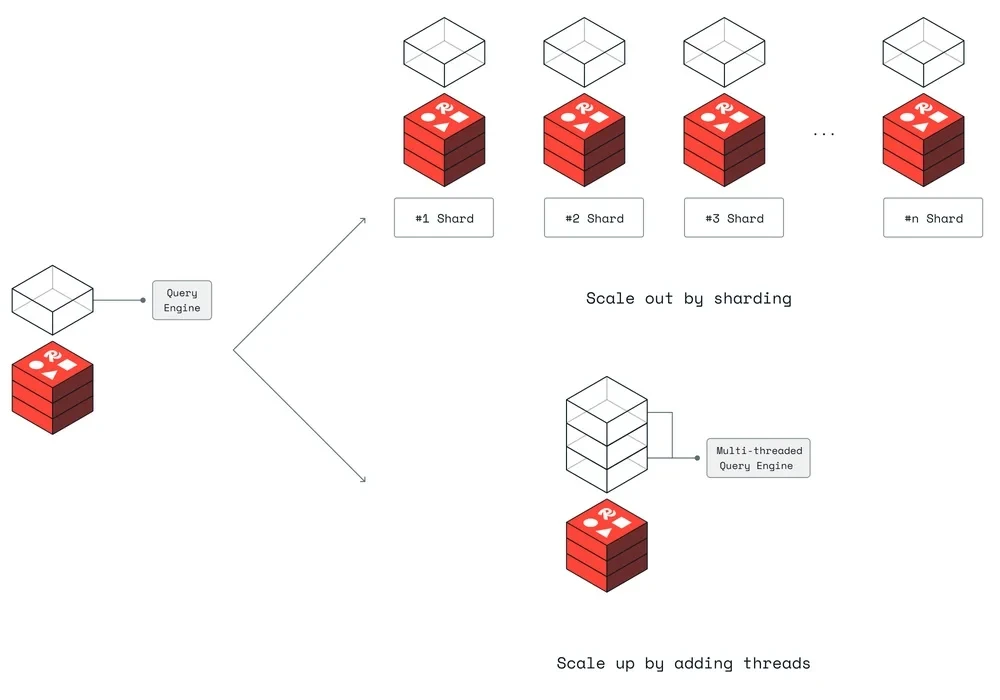
来源:Redis伸缩性设计
Redis 方面强调,随着文档数据量增长到数亿份,复杂查询可能会限制吞吐量,因此这一改进至关重要。Redis 声称其响应时间可以保持在亚毫秒级别,且查询的平均延迟低于 10 毫秒。
Redis 承认传统的单线程架构在处理某些操作时存在一定限制。他们解释说,长时间运行的查询在单线程环境中可能会导致系统拥堵,并降低整体的处理能力,特别是在使用倒排索引搜索数据等操作的情况下。
他们进一步阐述了搜索操作的复杂性:
搜索并不是 O(1)时间复杂度的指令,通常需要结合多个索引扫描来满足多个查询条件。这些扫描通常以对数时间复杂度 O(log(n))执行,这里的 n 代表索引映射的数据点数量。
Redis 方面表示,新的多线程方案有效地解决了这些问题,使 Redis 在保持高性能简单操作的同时,显著提高了如向量相似性搜索等计算密集型任务的吞吐量。
Redis 强调,“为了有效扩展搜索功能,需要将数据负载水平分布(即横向扩展)和垂直多线程化,以实现索引的并发访问(即纵向扩展)。”
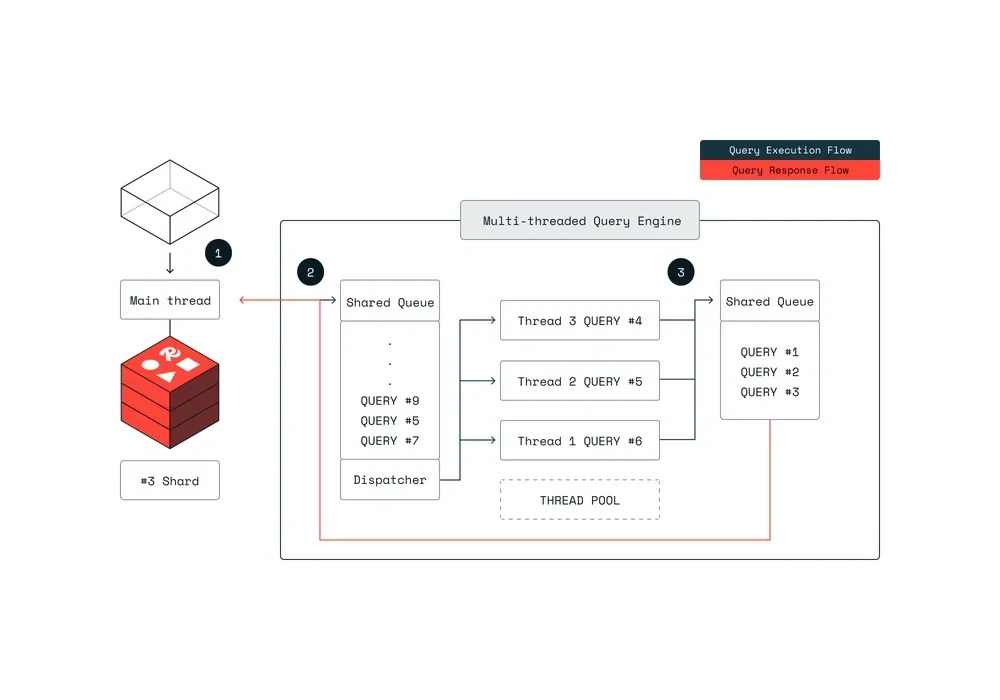
上图描述了新的架构,多个查询同时进行,每个查询都在自己的独立线程中运行。Redis 概述了一个包含三个步骤的流程:
查询上下文(计划)在主线程中准备好并加入到一个共享队列中。随后,各个线程从队列中取出任务并执行查询流程,与其他线程并行工作。这使得我们能够在保持主线程处理更多传入请求的同时执行多个并发查询,例如其他 Redis 命令,或准备并让新的查询入列。查询完成后,结果会被传回至主线程。
Redis 宣称,这种新架构不仅可以保持主线程对标准 Redis 操作的响应性,还能同时处理多个复杂查询,从而显著提升了整个系统的吞吐量和可扩展性。
为了验证查询引擎的性能,Redis 进行了广泛的基准测试,将其与三类向量数据库供应商进行了对比:纯向量数据库、具有向量能力的通用数据库和完全托管的内存 Redis 云服务供应商(CSP)。Redis 宣称,升级后的查询引擎在速度和可扩展性方面超越了纯向量数据库,同时在整体性能上显著超越了通用数据库和完全托管的 Redis 云服务供应商。
向量数据库市场近年来出现了显著增长,众多产品纷纷涌入这一领域。这种快速增长为新进入者和用户创造了一个充满挑战的环境。行业专家指出,市场上已经有太多可选择的向量数据库,这使得新入局的产品难以突出自身特点并确立独特的价值主张。
Reddit 首席工程师Doug Turnbull指出:
然而,在向量搜索领域,我们面临着数十种不同的选择。作为这些众多选项的“用户”,这个市场变得令人不知所措……向量检索本身不再是难题。解决现实世界中的检索挑战不仅仅关乎如何检索向量,更关乎向量检索之外的诸多因素。
这种观点强调了在 AI 驱动的数据检索中,需要一个全面的解决方案来应对更广泛的挑战。
新的 Redis 查询引擎声称与前一代相比查询吞吐量提升了 16 倍。特别值得一提的是,查询引擎对 GenAI 应用的需求进行了优化,例如依赖实时RAG的聊天机器人,它们需要快速地处理多个步骤,同时从向量数据库中检索数据。
Gmail 作者Paul Buchheit提出了“100 毫秒法则”,即每个交互都应该在 100 毫秒内发生,以便让用户感觉是即时的。
在 RAG(检索增强生成)架构中,延迟涉及网络往返、LLM(大型语言模型)处理、GenAI(生成式人工智能)应用程序操作和向量数据库查询等环节,这些因素共同导致了平均端到端响应时间为 1513 毫秒(1.5 秒)。为了应对这一挑战,开发者需要重新审视他们的数据架构,以构建符合 100 毫秒法则的实时 GenAI 应用程序。实时RAG让应用程序在利用 AI 能力的同时保持快速响应,确保用户能够体验到近乎即时的交互并保持对应用程序的满意度和参与度。
Vectera 的Ofer Mendelevitch提醒我们,虽然向量数据库的性能至关重要,但它只是 AI 应用程序开发中整体大蓝图的一部分。
确实,目前已成为构建基于大型语言模型应用程序的主流方法,需要强大的语义搜索能力作为整体检索能力的一部分(RAG 中的 R),但向量数据库只是整体技术栈的一部分,甚至可能不是最重要的部分。
RisingWave Labs创始人Yingjun Wu对向量数据库的发展提供了补充观点:
与其投入资源于开发新的向量数据库项目,不如将注意力集中在优化和提升现有数据库的性能上,探索通过集成向量引擎来增强这些数据库的可能性,让它们变得更加强大和高效。
Redis 通过强化其现有基础设施,与这一理念不谋而合,可能为开发者提供了一个更加集成化和高效率的解决方案。
全面的基准测试涉及了数据摄取和搜索工作负载评估。在数据摄取方面,Redis 测量了使用(HNSW)算法、近似最近邻(ANN)搜索进行数据摄取和索引的时间。在查询方面,重点放在纯 K 最近邻(k-NN)搜索上,测量了每秒请求数(RPS)和包括往返时间(RTT)在内的平均客户端延迟。
Redis 对gist-960-euclidean、glove-100-angular、deep-image-96-angular、dbpedia-openai-1M-angular数据集进行了基准测试。这些数据集覆盖了不同的向量维度和距离度量方法,确保了测试的全面性。为了模拟真实环境,Redis 采用了行业标准的基准测试工具,如Qdrant的vector-db-benchmark,以确保测试结果的可靠性和可重复性。
尽管 Redis 在其基准测试中展示了卓越的性能,但综合其他行业参与者的见解同样重要。Redis 的一个竞争对手通过比较研究提供了对 Redis 性能的不同看法。此外,数据库即服务(DBaaS)管理平台提供商ScaleGrid也分享了他们对 Redis 的见解。
新的查询引擎已加入到 Redis 中,并计划在秋季推出 Redis Cloud。要了解如何在 LangChain 框架中使用 Redis 向量数据库,请观看这个演示,它展示了这些技术如何被用来解决现实世界中的问题。有关向量数据库的更多信息,请观看这个PostgresML演示,并收听InfoQ播客,其中 Pinecone 向量数据库创始人兼首席执行官Edo Liberty分享了他对这些技术在 RAG 应用程序中应用的看法。
原文链接:
https://www.infoq.com/news/2024/07/redis-vector-database-genai-rag/





{kind=link}