
为了更好的指导客户制定广告销售策略,需要精准预测客户未来一段时间内的可用库存量。在这样的背景下,FreeWheel 机器学习团队需要构建模型以达到精准预测的目的。本文主要介绍了我们是如何构建模型解决业务问题,以及如何对算法模型进行迭代以提升预测效果。
业务需求与挑战
库存预测的业务需求是按照客户(network id)、站点(site id)等维度,按照天级别,预测未来 500 天内每天的可用库存量(也即视频观看流量,以下统称为流量)。由于流量为实数,因此所定义问题是一个回归问题。虽然需要预测未来 500 天每天的流量,但是业务对于这 500 天内不同时间段的预测精度要求是不同的。从最近的时间范围到越来越远的时间范围,预测的精度要求是逐级降低的。比如,客户对于最近 7 天内的精度要求是最高的,往后依次下降。
为了简化工程与模型调优成本,兼顾预测性能,决定采用训练一个统一模型的方式,来处理对所有客户站点流量的预测问题。这样,就需要模型能够同时学习到各个网络站点的不同流量模式。对于消费者来说,相对于传统电视的提前编排和有限选择,网络数字媒体具有海量的视频资源与灵活的选择自主性。因此,数字视频更容易发生各种突发热点流量。比如娱乐圈盛产的各种瓜,往往就会带来吃瓜群众的高峰访问,而这种访问高峰往往在不长的时间内趋于平静。也就是说数字视频的流量模式更加多样化且难以捕捉。而在我们的场景中,需要用一个模型来捕捉所有客户站点的流量模式,乃是一大挑战。
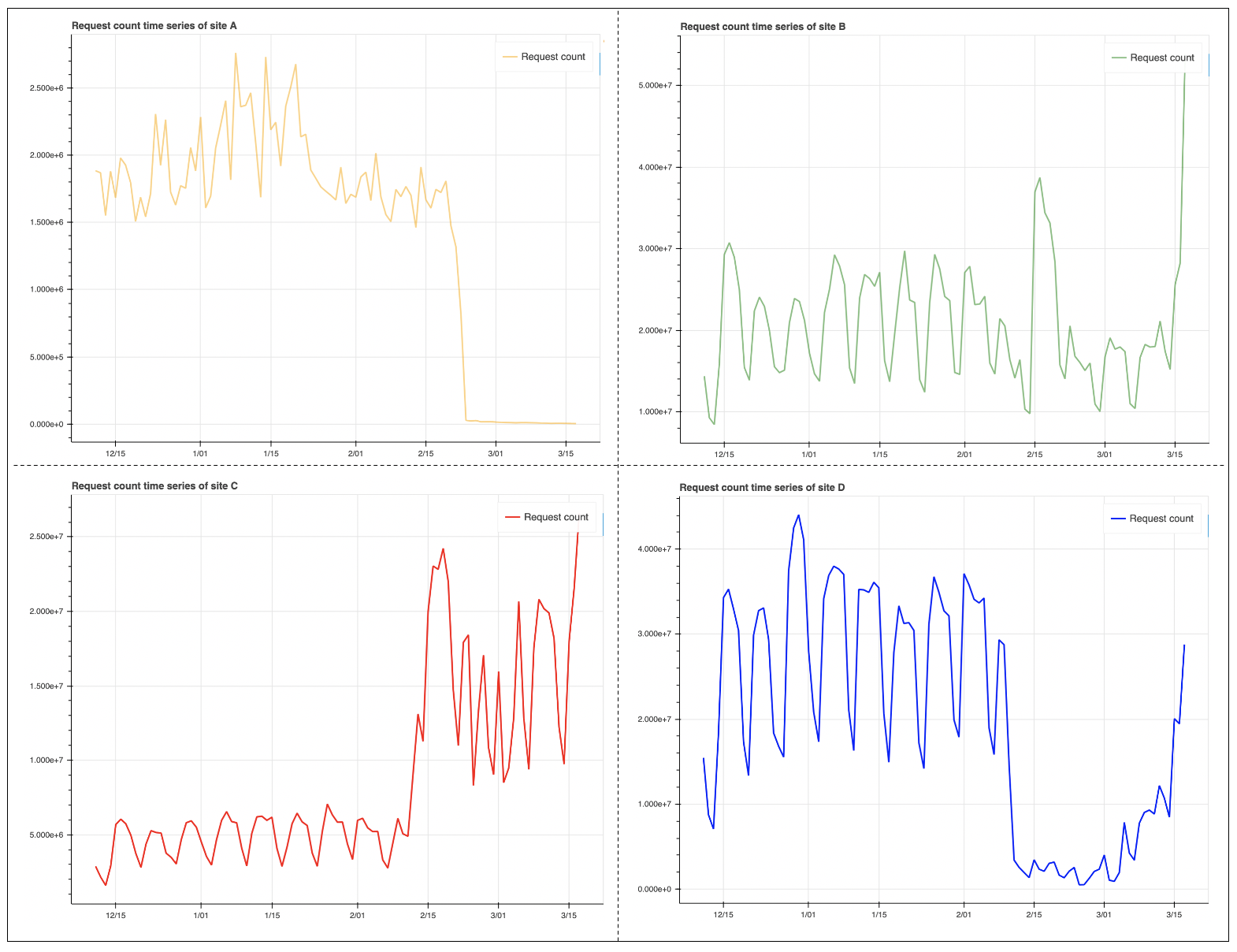
如下图所示,我随机选择了四个站点,并把它们最近几个月内的日流量通过折线图的方式展现。可以直观的看到,它们的日流量往往在某一天开始,有几倍的突增或者突降,并没有明显的趋势。
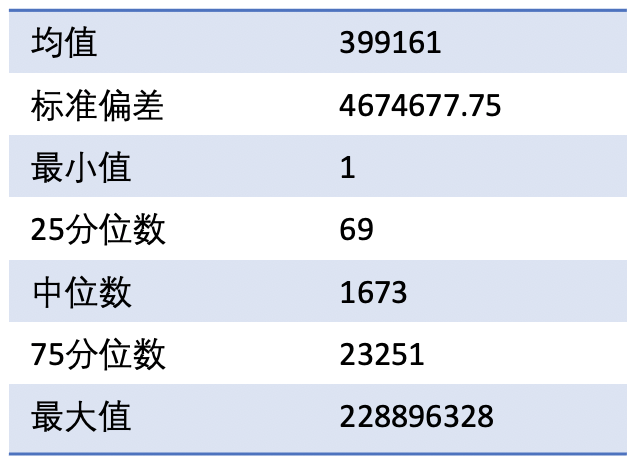
同时,由于不同的客户站点所提供的视频资源类型不同,对应的视频资源观看者数量也不尽相同,导致不同站点下所对应的流量相差非常大。比如有些站点的日均流量在千万级别,而有些站点日均只有几百个广告请求。下表是在某一天中,统计的站点流量分布。可见,在这六千多个站点中,流量的差距非常大。最小的量级是个位数,同时最大的量级达到了亿级别,标准差达到了百万级别。并且,大量的站点拥有较小的流量,仅仅 10%的站点就贡献了 96.7%的流量,也就是说剩下 90%的站点只贡献了不到 4%的流量。
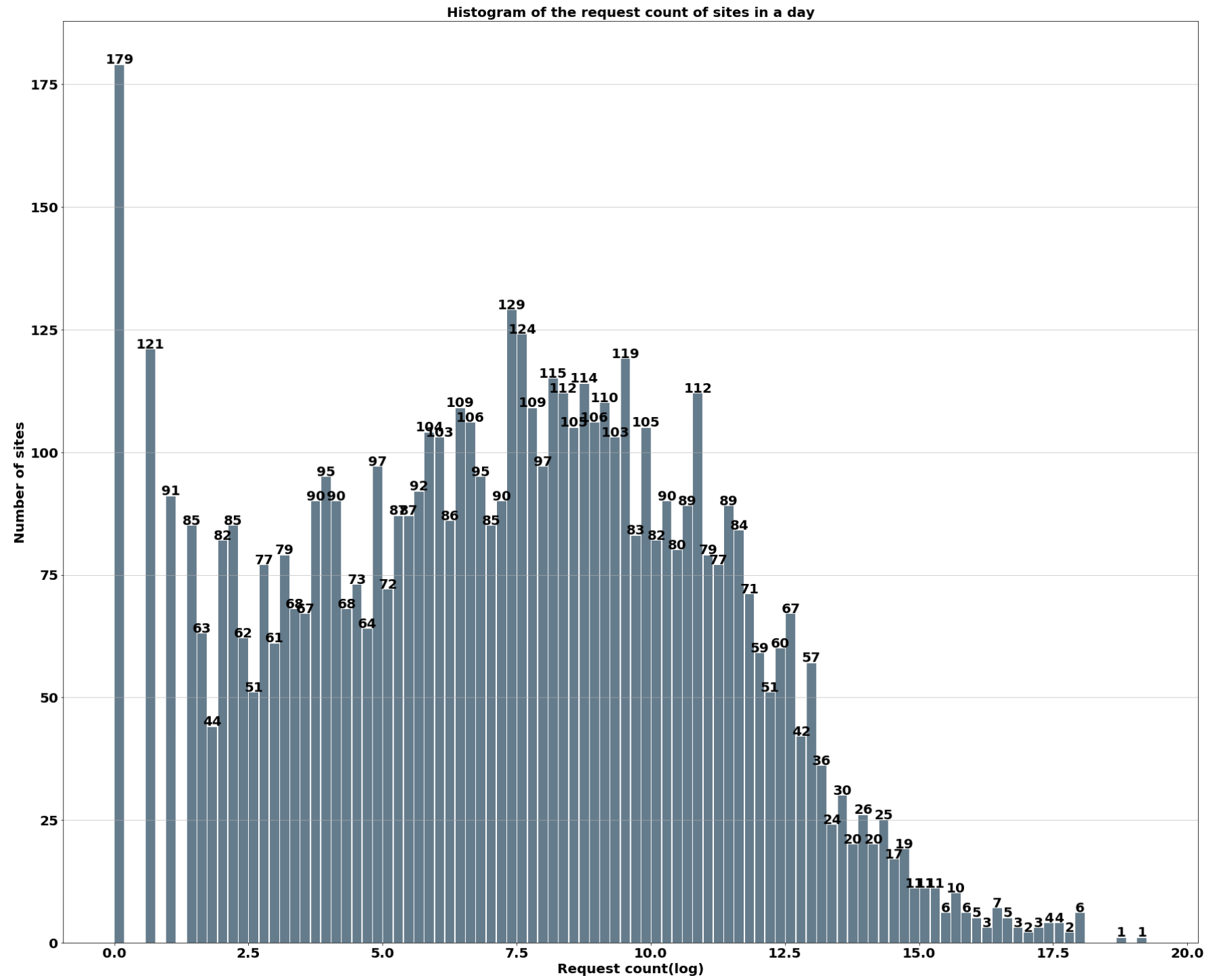
下图展现了在一天中,站点流量的直方图。横坐标代表站点在一天中的流量,由于不同站点流量相差很大,无法在一张图中进行合适的展现,因此统一对横坐标进行了 log 处理。竖坐标是各个桶含有的站点数量。在这张图中,将近六千多个站点按照流量大小分配到了一百个桶中。通过这张图可以更加直观的看到,站点之间流量的巨大差异。
在这个背景下,对于流量大的站点来说,模型预测的一点点波动就能带来非常大的偏差,而对于小流量站点的偏差则在整体偏差中没那么显著。相对于小流量站点,需要模型更加偏向于捕捉大流量站点的流量样式。
综上所述,对于本问题来说具有以下挑战:
1. 每天需要预测各个站点未来 500 天的流量,预测时间跨度较长;
2. 统一模型需要处理全部客户站点的预测任务;
3. 数字视频流量模式具有多样性与突发性;
4. 不同站点之间的流量模式不同,且流量数量级相差较大,模型需要更加偏向于大流量站点。
评价指标定义
在明确了业务需求之后,需要明确评价指标,以能够对模型性能进行量化评估。使用 MAPE(Mean Absolute Percentage Error)进行评价具有易对比性、易解释性等特点,因此决定采用 MAPE 对模型效果进行评价。MAPE 即每条样本预测值与真实值的偏差与真实值之比的平均值,公式如下:
$$MAPE = \frac{100\%}{n} \begin{matrix} \sum_{i=0}^n | \frac{y_i - f_i}{y_i + \epsilon} \end{matrix}|$$
其中,$y_i$是站点的$i$实际流量,$f_i$是站点$i$的预测流量,$\epsilon$是一个较小的正数值(0.01),以$y_i$应对为 0 时的情况,$n$是总共的站点数量。
由以上公式可以看出,对于真实流量越小的站点,对预测误差的忍受度越低,较小的预测误差就能带来较大的 MAPE 值。同时,在我们的场景中,小流量站点占据了绝大部分,导致大量的小站点对最终整体的 MAPE 值具有较大的影响。但是,这些小站点对于整体流量的贡献较低。之前说过,在我们的场景中仅仅 10%的站点贡献了 96.7%的流量,而我们更关注于这些 10%的大站点的预测精度。所以,直接用原始 MAPE 定义来评价模型效果,无法准确反映业务需求。
针对这样的场景和优化目标,我们设计了一种新的计算 MAPE 方式,来作为我们的评价指标:
§ 步骤 1:分桶。在每个客户下,按照流量从小到大将站点分到四个不同的桶里;
§ 步骤 2:桶内计算。计算每个桶内的 MAPE 值和桶内流量占对应客户总流量的占比,其中流量占比作为桶的权重;
§ 步骤 3:计算客户 MAPE。每个客户下桶的 MAPE 值的加权和,即汇总每个桶的流量占比乘以桶的 MAPE 值之和,作为客户的 MAPE;
§ 步骤 4:计算总体 MAPE。汇总每个客户 MAPE 值乘以其流量占比之和,作为总体 MAPE。

通过以上定义的评价指标,我们可以拿到每个客户的 MAPE,又可以拿到整体的评价指标。有了每个客户的 MAPE,就可以针对每个客户沟通其预测准确度。并且,在把预测结果发布给其它下游模块时,下游可以按照不同客户的预测精度有不同的决策方式。由于我们的目标是通过一个模型来实现对所有用户的流量预测。因此,整体 MAPE 用来横向对比各个不同模型的预测表现,作为选择模型的依据。
至此,模型的评价指标就定义清楚了,之后就需要调研各类模型并进行实验分析了。
前期调研
本问题是一个典型的时间序列预测问题,即根据每个站点历史上每天的流量信息预测未来一段时间内每天的流量。通常,用来解决这类问题的方法有经典的 ARIMA(Autoregressive Integrated Moving Average)、Prophet,也有深度神经网络的 RNN、DNN 等。
前期调研了 ARIMA 和 Prophet,并分别使用这两种方法进行了测试实验。ARIMA 和 Prophet 以及其它类似的方法,都需要针对每一个时间序列进行调参、训练。在利用我们的数据进行测试之后,发现对于不同站点的流量曲线,模型能够获得最佳预测效果的超参数都是不同的,需要为每个站点的流量曲线人工寻找最佳超参数。而到目前为止,我们拥有几千个站点。如果采用这种方式去为每个站点设计、训练一个模型,那么我们的工作量是极其繁重的,也是不可行的。因此,我们放弃了使用 ARIMA 和 Prophet 这类模型进行全量客户站点的流量预测。不过,可以考虑把 ARIMA 或者 Prophet 的预测能力开放给客户,让客户针对其站点特点进行调参,从而实现对自身流量的预测任务。
以下是采用 Prophet 拟合一个站点流量曲线的图例。由于篇幅有限,本文不对 ARIMA 和 Prophet 做过多介绍,如感兴趣建议访问:
ARIMA models for time series forecasting:https://people.duke.edu/~rnau/411arim.htm
Facebook prophet:https://facebook.github.io/prophet/
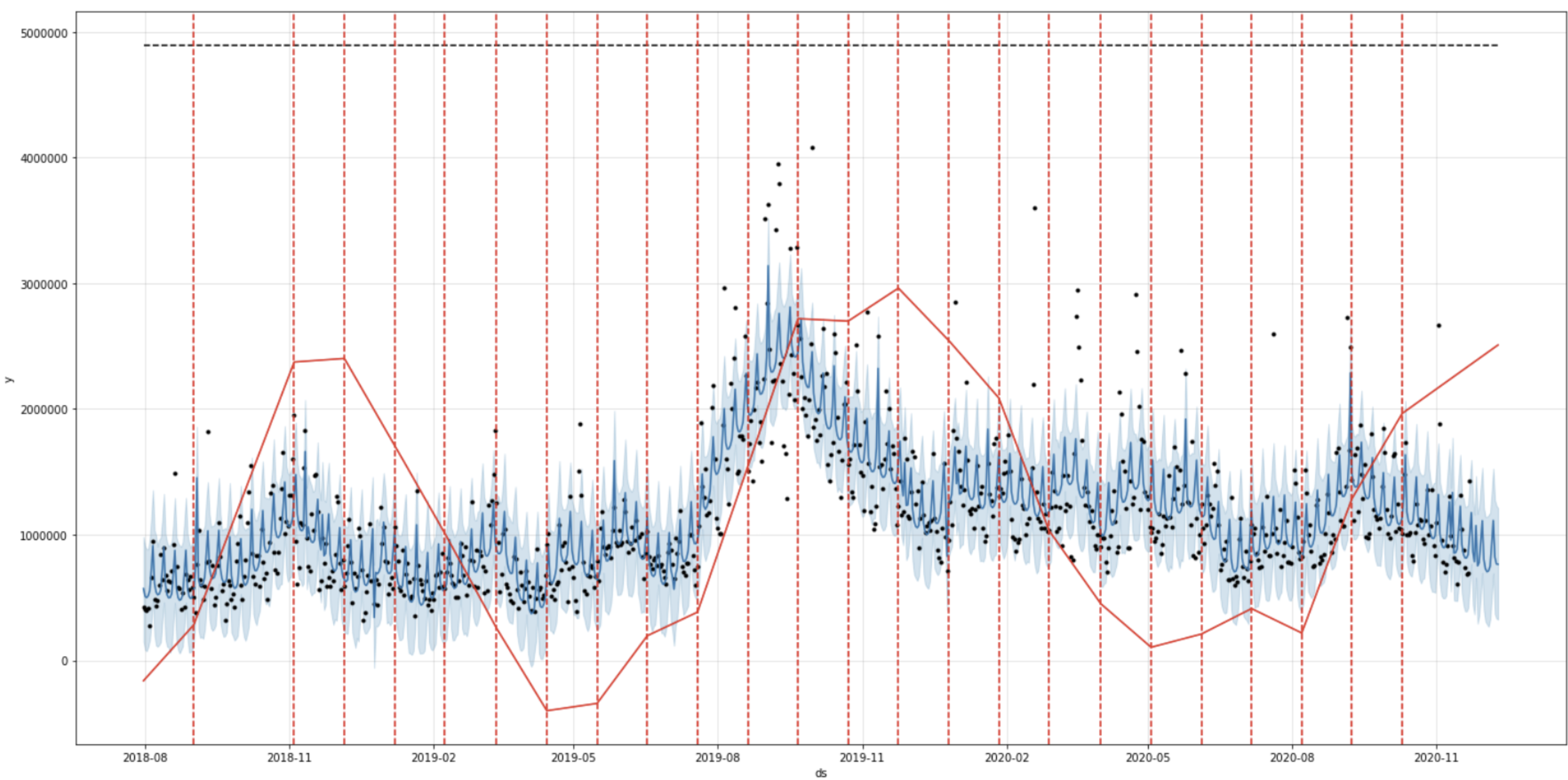
Prophet 训练数据拟合图
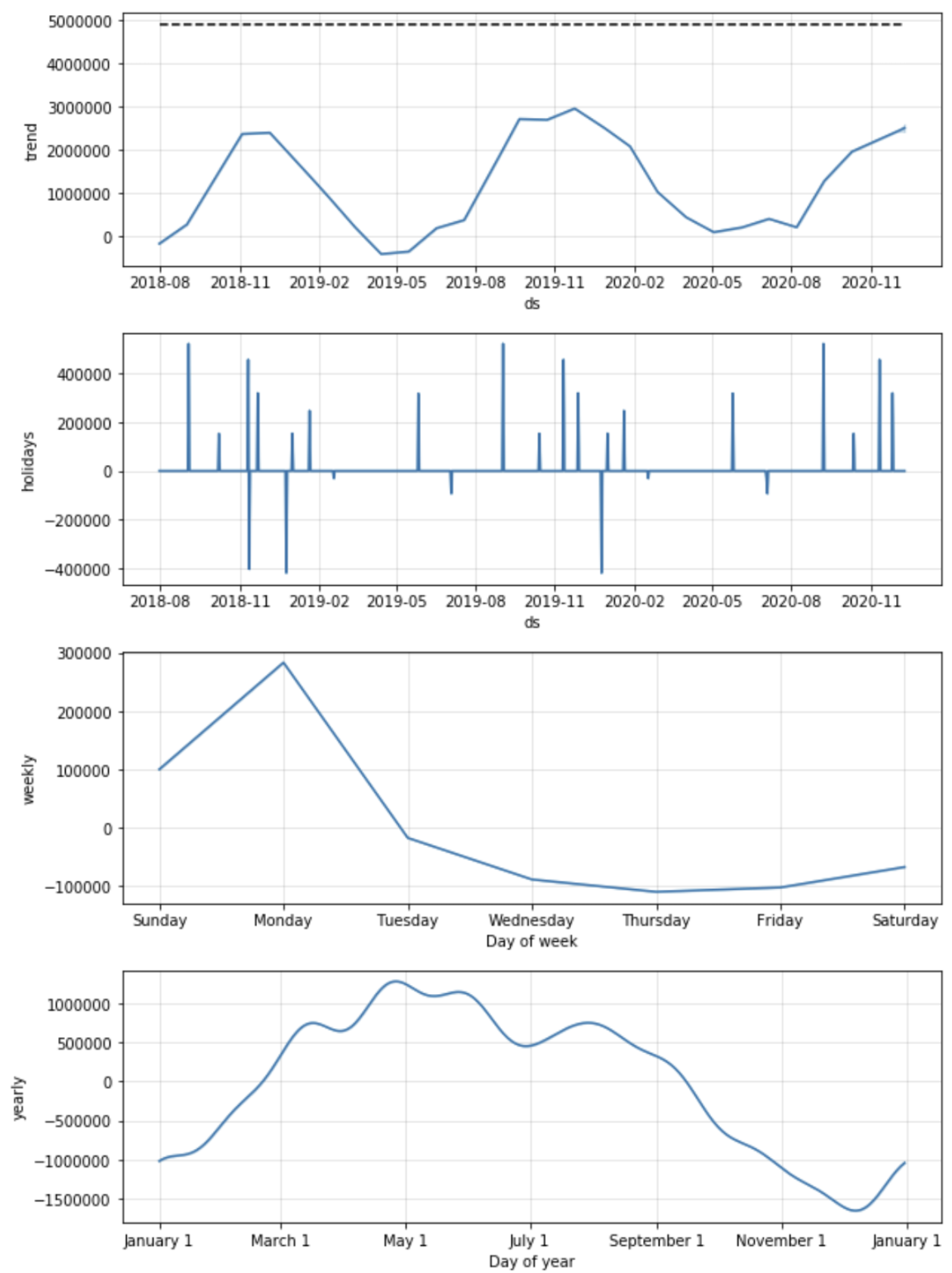
Prophet 时间序列分解图(分解为趋势、大事件、小周期、大周期)
基于以上原因,后续算法调研集中放在了深度模型,并基于深度模型进行了广泛实验,包括 DeepAR、DeepGLO 等。根据实验效果,最终选择了采用 CNN、RNN、DNN 相结合的预测模型。在介绍具体模型架构之前,先介绍训练样本是如何生成的,以及整体的预测流程。
特征工程与预测流程
下图以站点 a 为例介绍特征工程与整个预测流程。图中抽取事实数据的时间段是从 2020-06-10 到 2020-09-08。假设 2020-09-08 为最近一天的事实数据,需要预测未来七天每天的流量。
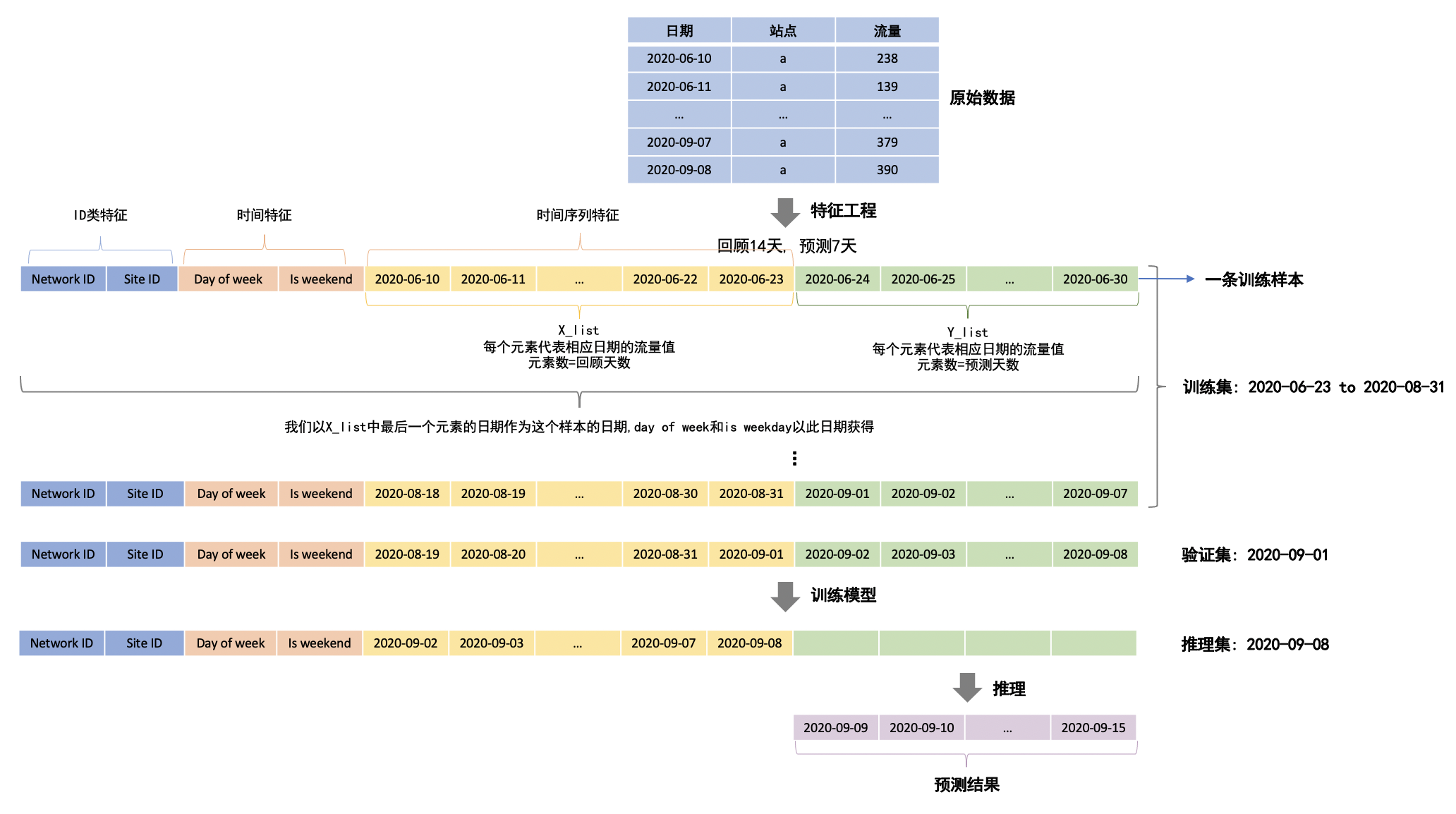
首先按照天为时间粒度,将历史上各个站点流量进行汇聚。并按照一定时间窗口大小滑动生成训练样本、验证样本、推理样本(统称样本),这些样本含有 X_list 与 Y_list 字段。|
其中 X_list 是回顾的历史流量列表,每个元素代表对应日期的流量值,X_list 的元素个数为回顾的天数。X_list 的元素按照时间降序排列。X_list 是每个样本最重要的时间序列特征。除了时间序列特征之外,还添加了另外两类特征:ID 类特征,时间类特征。其中 ID 类特征包括:Network ID(客户 ID)、Site ID(站点 ID)。时间类特征包括:Day of week(周几)、Is weekend(是否是周末)。
Y_list 为预测的流量列表,每个元素代表对应日期的预测流量值,Y_list 的元素个数为预测的天数,是每个样本的标签。在训练阶段中,模型通过拟合 Y_list 来收敛。在预测推理阶段,模型根据推理集中每个样本的特征值,预测出其 Y_list。
在原始问题中,需要预测未来 500 天的流量。如果要一次性预测这么长的时间,Y_list 的长度就要为 500,对应 X_list 中的最后一天也是 500 天之前的值。这样就会带来三个问题:
1. 最近的时间序列只能出现在 Y_list 中,无法出现在 X_list 中,因此模型无法学习到最近的时间序列特征;
2. 为了准备充足的训练样本,就需要更大时间范围的历史值。比如对于一个站点来说,采用回顾 500 天预测 500 天的策略,那么跨度一千天,才仅仅能够产生出一条样本;
3. 时间序列过长,模型无法收敛,更无法对最近时间范围内的流量进行准确预估。
由于直接预测 500 天有上述的问题,而客户对于最近 7 天内的精度要求是最高的,往后依次下降。并且,之前的预测策略是采用四周中位方法进行流量预测。所以,决定采用直接预测未来 7 天的方式进行模型的训练与预测。一是能够保证最近时间的预测精度,又能方便直接与四周中位进行横向对比。
在预测未来 7 天的流量时,即 Y_list 的长度为 7 时,经过我们对不同 X_list 长度进行实验验证发现,在 X_list 长度为 14 时能够获得相对较好的预测效果。因此,将 X_list 长度设置为 14,Y_list 长度为 7,同时增加训练集的时间跨度,以让模型学习到更多历史上的流量特点。
同时,为了达到预测 500 天的目的,我们采用将预测结果组合成特征再次输入模型,以此方式循环往复以获得 500 天的预测结果。
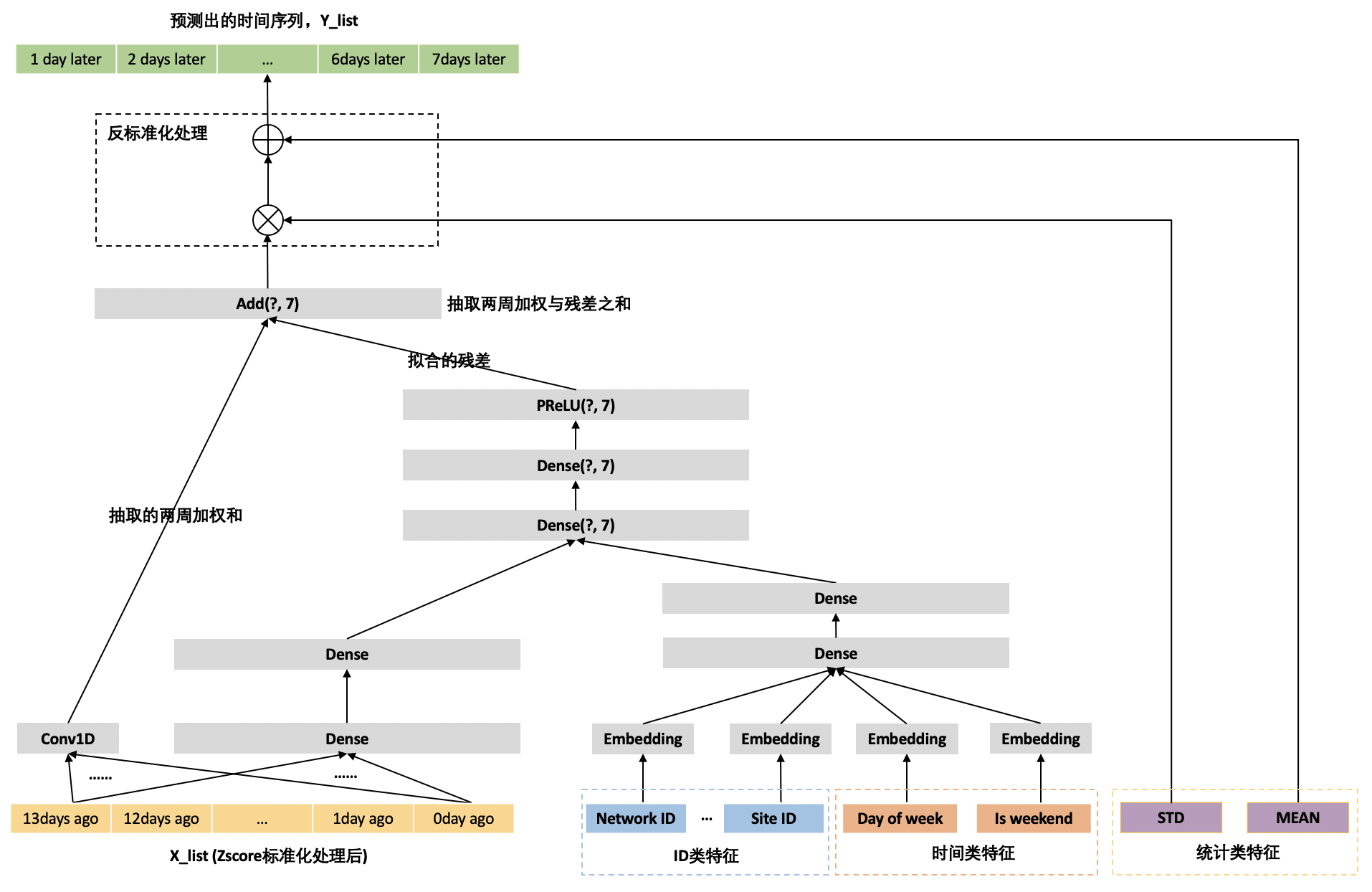
基准模型
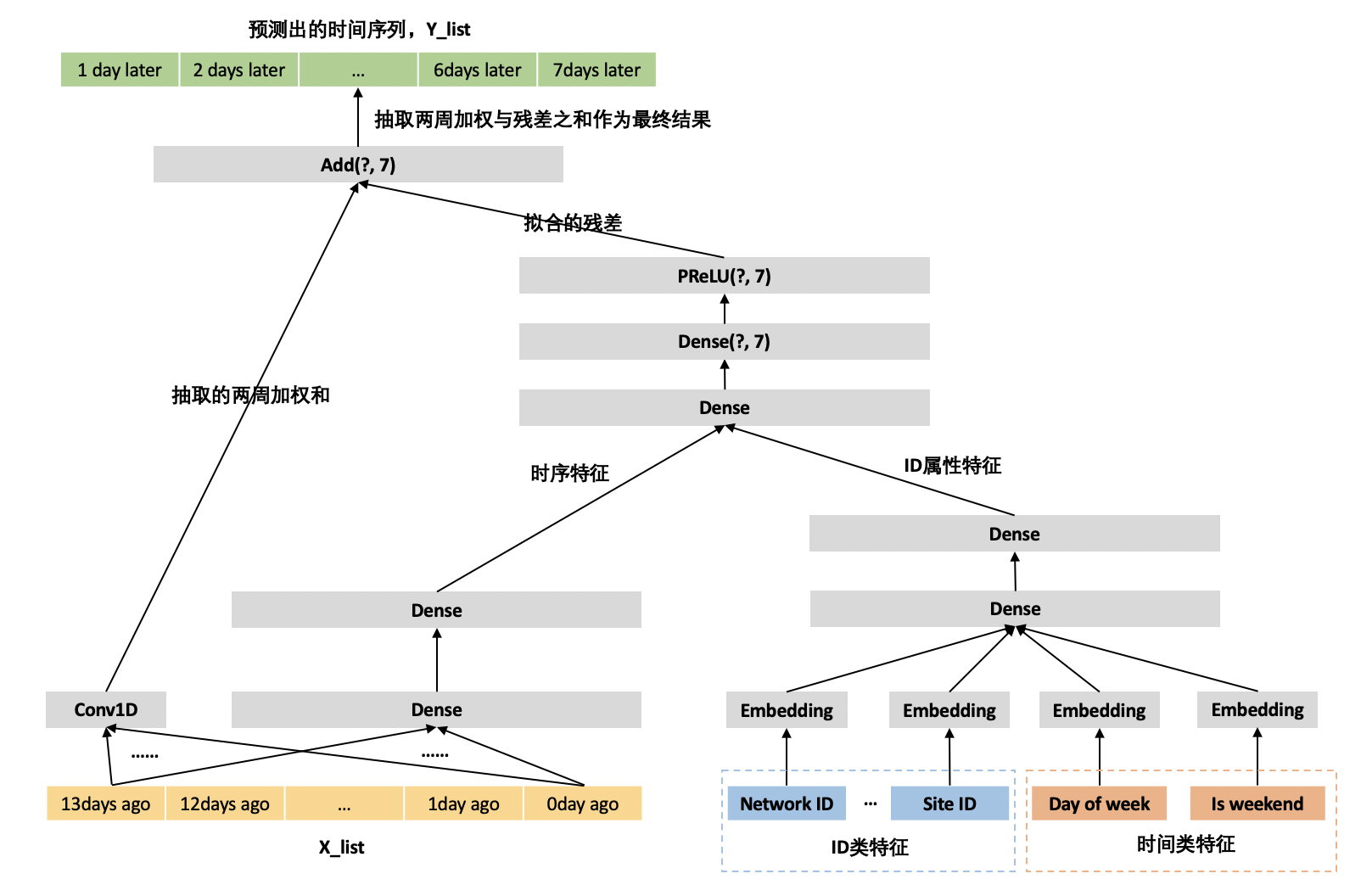
上图为基准模型的网络架构图。在基准模型中,我们从 X_list 特征中抽取两种特征:
1. 由于 X_list 中含有两周的流量数据,使用一维空洞卷积抽取出两周流量的加权和,比如第一周的周一与第二周的周一加权和生成一个元素,生成元素个数为 7 的 Dense。其每周的权重可通过模型进行拟合;
2. 通过两层全连接神经网络抽取 X_list 的时序特征。
由于 ID 类特征与时间类特征都是类别特征,分别对其做 Embedding,对类别特征进行向量化处理,让模型学习到每个客户和站点的特点。并在 Embedding 上加两层全连接神经网络,以实现这些类别特征之间的特征交叉,作为 ID 属性特征。ID 属性特征与时序特征又同时输入到两层的全连接层,以抽取出未来 7 天每天的残差。最后将残差与一维空洞卷积抽取出的两周的加权和相加,作为最终的模型输出。
在相加之前,输出残差的激活函数为 PReLU(Parameter ReLU),其中的 Parameter 就是其在负值域的斜率,在此使用 PReLU 是为了能够输出负值,这样残差才能有正有负,不仅能让模型拟合流量上升的趋势也能拟合流量下降。但是,用 PReLU 去控制整个数据空间流量的上升还是下降趋势是不合适的。在以下的优化模型二中会详细介绍这个问题。
基准模型的超参数为:
§ Loss Function:MAE;
§ Learning Rate:0.0001;
§ Optimizer:Adam;
§ Batch size:2048;
§ Epoch:3。
为了防止模型的过拟合,对一些层的参数做了正则化处理。
在本基准模型中,并未对 X_list 中的流量值做标准化处理。其原因是,我们需要模型更加偏向于拟合大流量站点的流量特点。也即想让大流量站点的样本,在训练中拥有更大的权重。当 X_list 中的流量值比较大时,模型中的参数在做梯度更新的幅度就会更加大。以达到让大流量样本具有更大权重的目的。但是,这种增大梯度更新的策略是使用更大的前向传播(Forward propagation)值带来的。但是对于 ID 类和时间类特征,其并没有较大的前向传播值,因此这部分参数无法达到照顾大流量样本的目的。如下图所示,红框部分的参数为梯度下降不足的部分。为解决这个问题,我们设计了优化模型一。
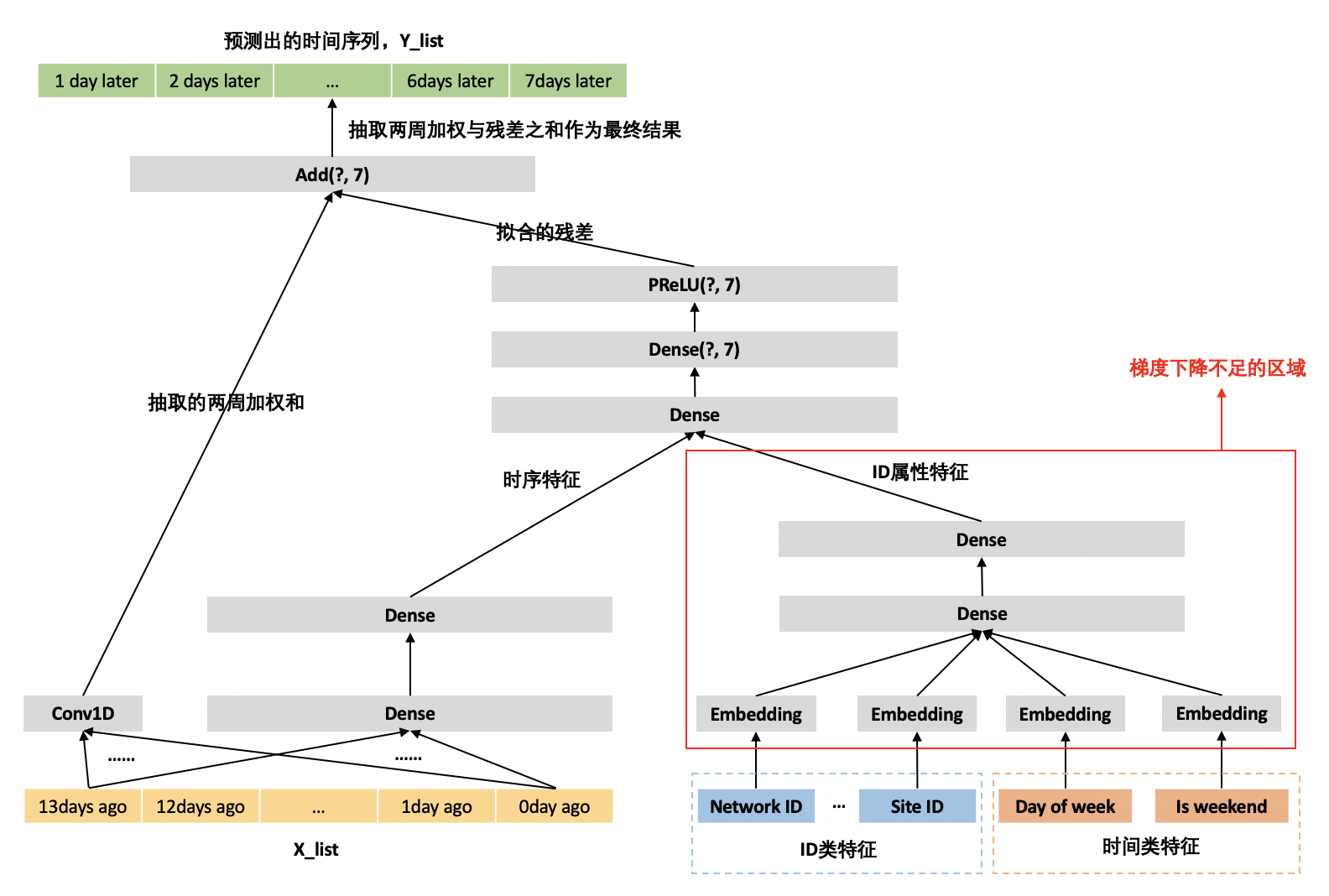
优化模型一
为了解决基准模型中 ID 类和时间类特征相关部分梯度下降不足的问题。设计出了以下的网络架构。此架构与基准模型只有两处不同。
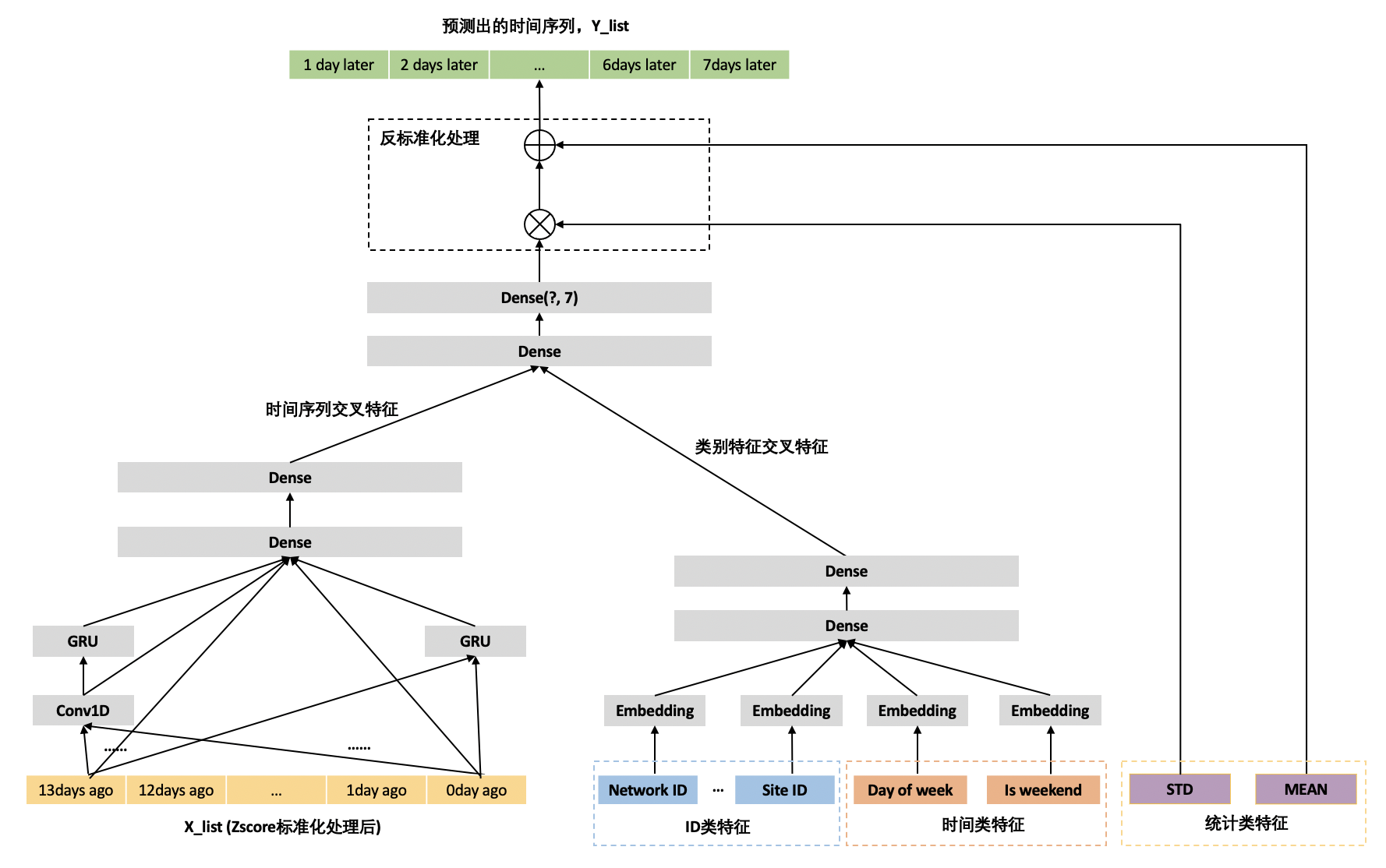
首先,输入特征 X_list 需要做 Zscore 标准化处理。注意,这里的 Zscore 标准化处理是按照站点粒度在训练集与验证集抽取的时间范围内进行的标准化处理。对应于特征工程与流程部分的那张图中,即是获取站点 a 在 2020-06-10 到 2020-09-08 这个时间范围内的均值和标准差,并让站点 a 每天的流量值减去均值除以标准差。经过 Zscore 处理后,每个站点的流量值都是均值为 0,标准差为 1。每个站点之间的流量并没有量纲的差距。
其次,把均值和标准差作为特征输入到模型。在最后模型的输出部分,通过样本的均值和标准差做反标准化处理,反标准化处理后的值作为最后的结果输出。因此,训练集和验证集中的 Y_list 不需要做 Zscore 处理。
通过以上两步,就能实现整个模型范围内的参数,能更加均匀的更新权重。同时又能“照顾“标准差比较大的样本(大流量样本的标准差往往也相对大)。而能够获得这样效果的原因是,具有更大标准差的样本在反向传播(Back propagation)中能够获取相对更大的梯度下降。与基准模型相比,都是为了让模型更加拟合大流量的样本,但实现的方式却不同。基准模型是通过 X_list 带来更大的前向传播来实现,但同时会弱化 ID 类特征和时间类特征的作用。优化模型一是通过 Y_list 带来更大的反向传播来实现,标准化处理后的 X_list 与 ID 类特征和时间类特征就不会顾此失彼,因此能够获得更好的实验效果。
优化模型二
之前介绍的基准模型和优化模型一,有一个共同的特点,就是通过拟合过去两周权重和的残差。拟合残差方法的主要问题在于输出残差的激活函数 PReLU。PReLU 是为了防止在神经网络中神经元死亡而被设计的。PReLU 在负值域的斜率虽然可以通过反向传播进行更新,但在我们的使用场景中让 PReLU 去控制残差的增减就会遇到下图描述的问题。
我们的训练样本是通过滑动窗口滑动获得的,那么 X_list 和 Y_list 每个元素代表的周几是不一定的。比如下图所示,第一个样本 Y_list 的第一个元素代表周一,第二个样本第一个元素就代表周二了,以此类推。而周一和周二的流量是上升还是下降的趋势是不同的,并且不同站点之间的流量上升还是下降趋势也是不同的。因此,在一个模型中仅仅用 PReLU 的 Parameter 去控制整个数据空间的流量上升还是下降趋势,是不足的也是不合适的。
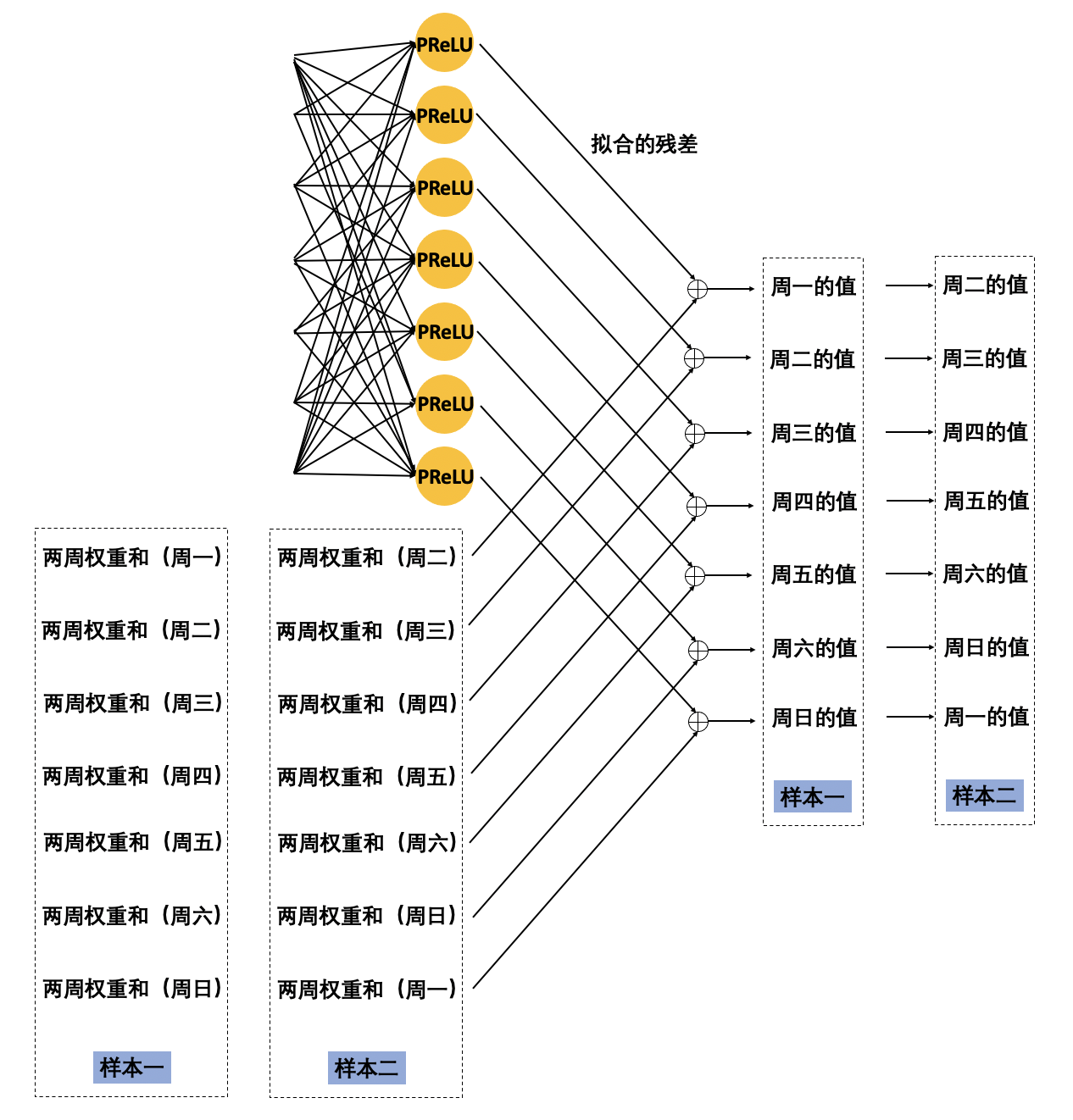
通过拟合残差方式的好处是,能够有效降低模型空间的复杂度,能让模型更易收敛。在抛弃残差方式之后,模型空间变得更大,模型能够拟合更加复杂的情形,但模型也会变得更加难以收敛。为了增强模型拟合能力,更好的抽取时序性特征,引入了 RNN 网络。并最终将抽取出的时间序列交叉特征与类别交叉特征输入到两层全连接神经网络,以直接预测出七天流量。如下图所示,为优化模型二的模型结构。
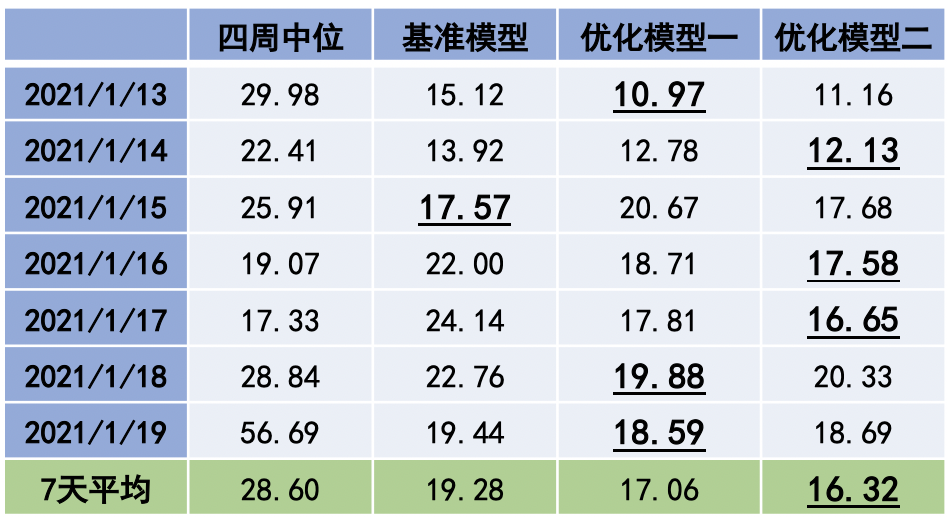
下表展示了以上三个模型和四周中位在测试集上的每天表现和总体表现,其中下划线标注的数值代表横向对比最优的值,也即最小值。可以看到优化模型二获得了总体最好的表现,比基准模型有 2.96%的提升。
总结与后续方向
本文总体介绍了我们在解决库存量预测问题上的一些思考与尝试。从基本的问题定义出发,根据业务需求特点制定合理的评价指标。基于评价指标构建预测模型,依据实验效果进行模型的迭代升级。到目前为止,模型已经部署到线上生产环境,并为下游持续提供库存量预测能力。每天依据历史流量预测未来流量,支撑公司内部其它各个模块,为客户能够及时调整其广告销售策略服务。在模型演进方面,后续可以引入更多与假期、大事件等相关特征,以便模型能够更好的应对突发流量的预测问题。同时,如何更好的获取流量的长周期特点,也是后续需要研究的课题。
作者简介:
王振亚,FreeWheel 机器学习团队高级工程师,从事计算广告业务中机器学习的算法调研与模型开发工作,并且热爱大数据处理分析技术。通过算法与工程的结合,让机器学习在计算广告领域有更多的落地。




