
“我见过 10 多个数据库突然变成了向量数据库!”
“我预测每个数据库都会突然原生支持向量嵌入和向量搜索。”
“是的,兄弟,我的向量数据库初创公司刚刚结束了 A 轮融资。”
......
OpenAI 掀起的这波 AI 变革,让向量数据库越来越受关注。
AI 技术不断向前发展,一个核心驱动因素,就是背后的存储、处理和分析大量数据所需要的强大基础设施也在不断发生进步。这波“新基建”浪潮也催生出又一颗冉冉升起的新星——向量数据库,一种用于管理非结构化数据,包括数字形式的文本、音频、图像和视频的强大解决方案。
随着市场对 AI 基础设施需求的不断增加,向量数据库预计也将保持强劲的发展势头,并一步步成为未来 AI 技术愿景的重要基石。
新型数据库成就一批新富豪
数据库领域经历过一系列发展阶段。最早的是 SQL 类关系数据库,其中所有数据都被纳入结构化的矩形表中。Web 2.0 企业的需求增长引发了 NoSQL 革命,数据库变得更加灵活,能够处理体量更大的数据。如今,随着市场为 AI 技术积极筹划,向量数据库的时代也终于来临。
与传统数据库不同,向量数据库特别擅长从非结构化数据中提取见解。这些数据库使用向量嵌入来表示数值型数据,并将其排列在彼此相似的一个个聚类当中,能够帮助用户使用相似对象查询数据库,从而轻松比较并找出最适合的匹配项。向量搜索的另一个优势就是这类查询延迟更低,特别适合生成式 AI 应用。
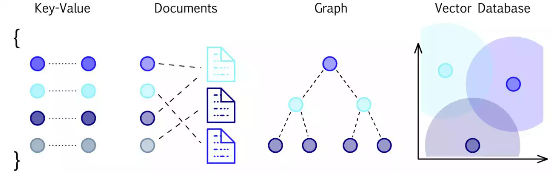
受到近期 AI 炒作的影响,更多企业开始大力投资向量数据库以提升算法准确性和效率。据相关统计,2023 年 4 月的 AI 投资领域呈增长趋势,尤其是向量数据库领域的投资活动颇为活跃,Pinecone、Chroma 和 Weviate 等向量数据库初创公司都在这个月获得了融资。

让我们具体来看看向量数据库领域非同一般的融资情况。
这个月,Pinecone 宣布以 7.5 亿美元的投后估值完成 1 亿美元的 B 轮融资。本轮融资由 Andreessen Horowitz 领投,加上去年的 2800 万美元的 A 轮融资和 2021 年的 1000 万美元的种子轮融资,该公司已累计筹集 1.38 亿美元。
Pinecone是一款云原生向量数据库,专为高性能、低延迟和可扩展的向量相似性搜索而设计。它能够处理密集和稀疏向量,因此成为各种用例的理想通用选项。Pinecone 提供易于使用的 API,用户只需编写几行代码就能实现向量的添加、搜索和检索。
而开源搜索引擎 Weviate 的开发商 SeMI Technologies 于去年 2 月宣布拿下由 New Enterprise Associates 和 Cortical Ventures 领投的 1600 万美元 A 轮融资。
今年 4 月,Weaviate 再次获得 5000 万美元 B 轮融资。
Weaviate 是一款功能丰富的向量数据库,专为复杂的数据建模和搜索用例而生。它提供 GraphQL API,支持向量相似性搜索和一系列其他高级搜索与过滤功能。Weaviate 能够存储和搜索各种数据类型,包括结构化数据、非结构化数据和图像。
同月,向量数据库初创公司 Chroma 也获得了 1800 万美元的种子资金,估值达到 7500 万美元。
Chroma 是一款简单的轻量级向量搜索数据库,可用于构建内存内的文档-向量存储。它以 Apache Cassandra 为基础,提供易于使用的 API。Chroma 的核心优势就是简单性。它能快速完成设定和配置,无需任何特殊硬件或软件。
但值得注意的是,Chroma 上个月在 GitHub 上只获得 1.2k star。
最近,另一家开发开源向量搜索引擎和非结构化数据库的德国初创公司 Qdrant 也刚刚获得 750 万美元种子资金,领投方为 Unusual Ventures、42cap 和 IBB Ventures,另有包括 Cloudera 联合创始人 Amr Awadallah 在内的一众天使投资人跟投。
就目前的情况看,跟以往的其他新技术一样,我们恐怕很难区分向量数据库领域的虚假炒作与真实优势。谷歌开发专家 Jeff Delaney 就在他的节目上(搞笑地?)谈到他在尚无任何收入、商业计划甚至是实际代码可以展示的情况下,凭借 Rektor 向量数据库初创项目让公司估值飙升至 4.2 亿美元,并呼吁大家为其投资。
社交媒体上,关于向量数据库的段子也明显多了起来。

被 ChatGPT 带火的向量数据库
向量数据库的兴起,与生成式 AI 应用对“嵌入”概念的日益推崇密切相关。嵌入是一种高维向量,可表示连续数字空间中的非结构化数据,例如文本、图像和音频等。在 NLP 场景下,嵌入以向量格式表示单词或句子的语义和句法,并可作为输入被馈送至深度学习模型当中。
例如,“我爱披萨”这句话就可以表示为一个 300 维的向量,其中每个维度代表句子的特定特征或属性,例如字数、是否存在某些关键字或情绪倾向等。为自然语言生成嵌入的过程,往往是由预训练语言模型(例如 OpenAI GPT 或 BERT)来完成。
嵌入向量的长度不受限制,可以根据具体用例和用于生成嵌入的模型而有所变化。嵌入的质量越高,语言建模、情感分析、机器翻译和问答系统等 NLP 任务的性能表现也就越好。
大语言模型(LLM)就是高度依赖嵌入的先进 AI 用例之一。这些模型往往包含数十亿个参数,嵌入则广泛作用于这些模型的训练和微调过程,使其获得执行各种 NLP 任务的能力。
SQL 数据库在处理高维嵌入方面的局限性
SQL 数据库擅长处理具有固定模式的结构化数据,各条目通常存储在行和列构成的表内。与之相反,嵌入属于高维向量,表示连续数字空间中的非结构化数据,例如文本、图像和音频。嵌入可以包含数百甚至几千个维度,因此不适合被存储在专门针对小型、固定维度数据集进行优化的传统 SQL 数据库内。
向量数据库在设计上特别适合处理高维向量,例如嵌入,因此可以为大量非结构化数据的存储、查询和分析提供更具可扩展性的效率优势的解决方案。凭借高效处理数千列相似性搜索的能力,向量数据库已经成为 AI 基础设施中的重要组成部分,为各类大语言模型和其他高级 AI 应用提供支持。
向量数据库的嵌入处理优势源自以下几个特性:
高效存储:向量数据库强调对高维向量的高效存储,能够在最小存储空间下处理大量数据。这一点对于包含数百或几千个维度的嵌入而言非常重要。
高性能相似性搜索:向量数据库使用专门的算法和数据结构对嵌入进行高性能的相似性搜索。用户可以借此快速找到与给定查询最接近的嵌入,因此非常适合对图像或文本的相似性搜索任务。
可扩展性:向量数据库具备良好的可扩展性,能够轻松处理大规模数据集。这一点对嵌入非常重要,自然也能良好支持广泛依赖嵌入的大语言模型和其他 AI 应用。
灵活性:向量数据库能够处理各种数据类型,包括文本、图像、音频和视频,因此广泛适合各类 AI 应用。
总体而言,向量数据库在设计上非常适合处理高维向量(例如嵌入),这也使其成为现代 AI 基础设施中的重要组成部分。
通过语义搜索实现 ChatGPT 定制
OpenAI 的嵌入方法是一种无监督学习方法,也被称为“表示学习”。该模型能够学会特定的数据表示方式,在无需明确了解须提取哪些特征或如何表示数据的情况下,即可完成自然语言处理等下游任务。这种方法在大语言模型训练当中效果拔群,能够准确地生成顺畅自然的文本内容。
但 OpenAI 模型也有自己的局限,那就是只能处理有限数量的输入数据。例如,ChatGPT 3.5 的 token 上限为 4096,意味着如果没有额外技术的加持,它就无法搜索更大的数据库。而嵌入的意义也正在于此。
向量数据库凭借在非结构化数据中提取见解的能力而愈发流行,其重要特征体现在语义搜索等高级 AI 应用当中。语义搜索的效果与 ChatGPT 类似,但可以在自定义知识库上运行。这里的知识可以是客户关系管理(CRM)数据,技术手册甚至是研发信息。但要实现语义搜索,数据首先需要被存储在支持低延迟查询的位置,而向量数据库就凭借种种优势而特别适合这项工作。因此,向量数据库的日益流行,也反映出越来越多的企业有意基于内部知识打造属于自己的定制化 ChatGPT。
竞争激烈程度持续提升
当然,Postgres 和 NoSQL 数据库 Redis 这类传统方案在 AI 时代也占据着一席之地。Postgres 同样具备 Pgvector 向量/相似性搜索功能。
为了不被时代抛弃,老牌数据库厂商正通过 AI 相关服务巩固自身业务。例如,甲骨文就推出一系列 AI 算法,并以“数据库内高速学习”为宣传重点。IBM 的传统 db2 如今也被更名为“AI 数据库”,利用机器学习技术改善查询性能并提供“基于置信度的查询”功能。
此外,领域中的老牌劲旅(如微软)也开始提供在自定义知识库上构建 AI 应用的解决方案。例如,Azure Cognitive Search 就能帮助企业构建并部署基于向量数据库功能的 AI 应用。Matchlt 则是谷歌开发的向量搜索解决方案。可以看到,新老势力正纷纷登场,希望能为想要在 AI 流程中引入向量数据库的客户提供有价值的技术服务。
如果说 AI 已经成为众多企业的研究前沿和中心,那么面向 AI 的基础设施自然会随之升温。
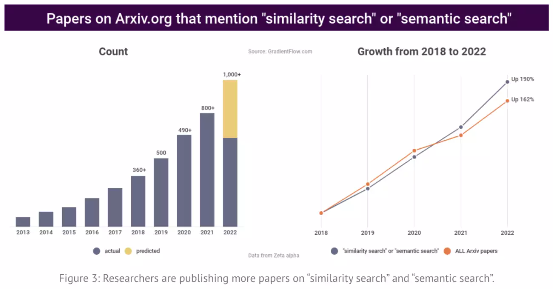
资料来源:GradientFlow.com
SeMI Technologies 公司 CEO Bob van Lujit解释了Weviate这样的厂商跟传统关系数据库供应商之间的区别。“这是我们第一次打造 AI 优先的基础设施,希望在数据科学成果跟市场业务需求之间架起桥梁。”
软件服务初创公司 Heltar 的创始人 Avyukt Aggarwal 也解释了向量数据库与生成式 AI 工具间的紧密联系。“每一场淘金热都不缺卖铲子的人。对于生成式 AI,这里的铲子是什么?就是向量数据库。几乎一切由大语言模型支持的应用程序都在用向量数据库,或者即将用上。大语言模型被集成到几乎所有主流应用当中,而提供一揽子托管向量数据库的厂商就是在挣淘金热当中卖铲子的钱。”

资料来源:Dhruv Anand 是谷歌前工程师,也是科技创新初创企业 AI Northstar tech 的创始人。
把向量数据库称为生成式 AI 的“铲子”并不为过。随着 AI 应用在企业生产部署中的快速普及,对高质量向量数据库的需求也重现了 SQL 在当年云黄金期的辉煌。
参考链接:
https://thenewstack.io/vector-databases-long-term-memory-for-artificial-intelligence/
https://twitter.com/GPTDAOCN/status/1658238286605975552
https://twitter.com/mattturck/status/1648825069177634820
https://github.com/codediodeio/rektor-db
https://www.youtube.com/watch?v=klTvEwg3oJ4
https://analyticsindiamag.com/why-are-investors-flocking-to-vector-databases/
https://www.relataly.com/vector-databases-the-rising-star-in-generative-ai-infrastructure/13599/




