
导读:本文主要介绍京东实时数据仓库技术的过去和未来,使用 Delta Lake 完成离线数据的增量更新,建设批流一体开发分析体系简化传统数据仓库架构,以及京东的业务场景在数据湖上的落地经验和技术挑战。
传统数据仓库面临的挑战
1. 传统数据仓库的架构
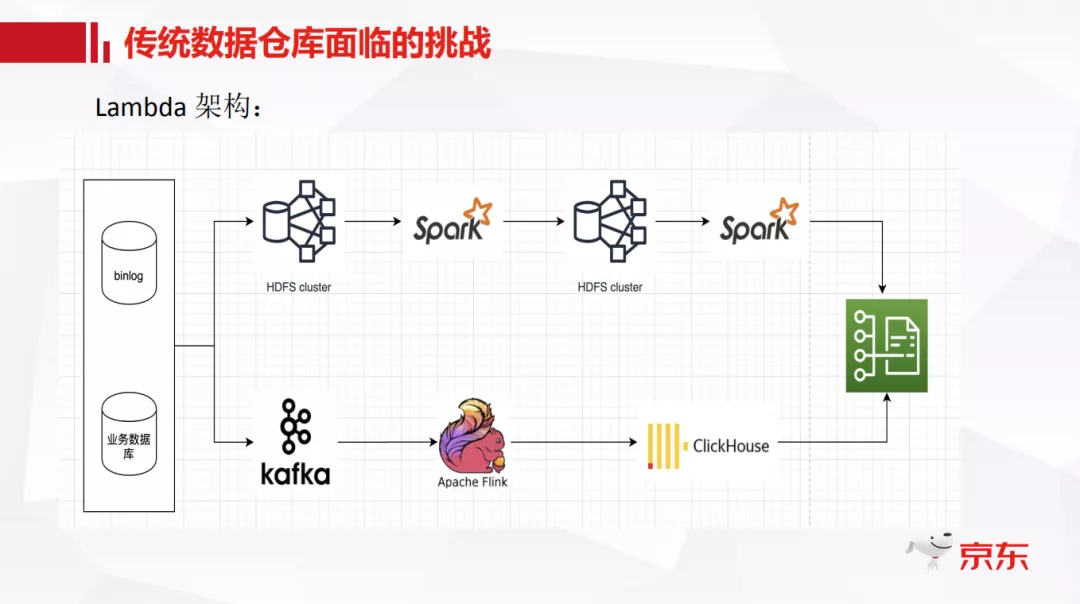
首先介绍一下我们传统数据仓库的架构,目前主流的离线数据仓库是基于分布式存储分层的 Lambda 架构。如上图所示,由上下两条链路构成,上面链路代表离线层的处理,下面链路代表实时层的处理。这个链路既是现在设计架构上的链路,也是业务数据流转的链路,同样也是我们日常开发维护的链路。这套体系架构奠定了我们大数据分析的基础,也取得了很多收益。但随着技术的发展和业务上对实时性的要求越来越强,尤其近几年实时计算发展的特别快,现有的这套架构逐渐暴露出一些弊端。
基于 Lambda 架构建设的实时数仓,第一条是针对于实时性要求高的业务系统 ( 通常是秒级 ) 的数据流转链路,另一条就是传统意义上的离线计算 ( 通常是天级 ) 的数据流转链路,甚至有些业务系统还会有准实时计算的数据链路 ( 例如小时级延迟 )。不同业务系统,根据不同的时效性去选择和设计数据处理加工方式。
2. 在传统数据仓库实践中遇到的问题
① ACID 语义性无法保证
简单来说就是无法做到一边写入一边读取,我们目前更多依赖读写任务在调度时间上的错配来解决读写冲突,保证数据一致性。
② 离线入库潜在的不可靠性
离线数据加工任务一般是 T+1 的,今天的生产数据,需要第二天凌晨抽取到大数据机房,然后进行后面的业务计算。有些业务系统的数据可能分布在全国各地数千个 MySQL 数据库中,假如其中某几个数据库出现问题,那么离线数据就会造成缺失,从而影响后面的数据分析计算的准确性。
③ 细粒度的数据更新功能缺失
Hive 中不支持 update、delete 这种细粒度操作,即使只更新 Hive 表中的某几条数据,都需要重写整个表,或至少重写整个分区,而一个分区就是一天的数据,整个操作就需要先读取一天的数据,然后计算后再写回去。这样的话,他所需的执行时间,读写数据量,资源消耗都是比较大的。
④ 数据流转路径复杂
很多情况下,处理离线数据和实时处理的数据逻辑都是一样的,只不过需要面向不同的场景。比如说离线要使用数据做更复杂的分析,实时需要做一些秒级或毫秒级的查询。这样的话,当业务逻辑有变化时,实时需要更新一次,离线还需要更新第二次,两条链路对应两份数据,很多时候,实时链路的处理结果和离线链路的处理结果甚至对不上。
上面就是针对目前数仓所涉及到的四个挑战的大致介绍,因此我们也是通过对数据湖的调研和实践,希望能在这四个方面对数仓建设有所帮助。接下来重点讲解下对数据湖的一些思考。
实时数据湖的探索和经验
1. 数据湖开源产品调研
数据湖大致是从 19 年慢慢火起来的,目前社区主流的开源产品主要有三种:Delta、Hudi 和 Iceberg。它们在功能实现上各有优劣,接下来简单对比一下。
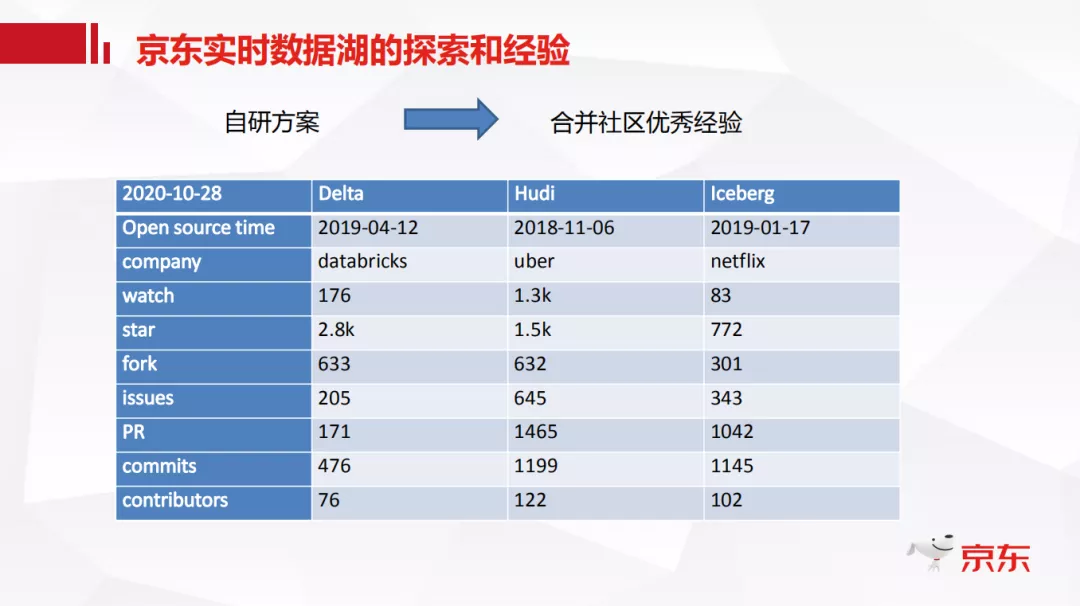
上表是一个简单的社区热度统计:
Delta Lake:在 17 年的时候 DataBricks 就做了 Delta Lake 的商业版,主要想解决的也是 Lambda 架构带来的数据存储和控制问题。
Hudi:支持快速的更新以及增量的拉取操作,包含 copy on write 和 merge on read 两种表格式。
Iceberg:的初衷是想做一个标准的 Table Format,代码抽象程度比较高,社区也正在进行 Flink 的读写支持。
2. 选择 Delta lake 的原因
下面这个表格例举了部分功能点的对比,这些都是我们在做技术选型时比较关心的几个点。比如说 ACID 特性,历史回溯,多版本并发控制等。
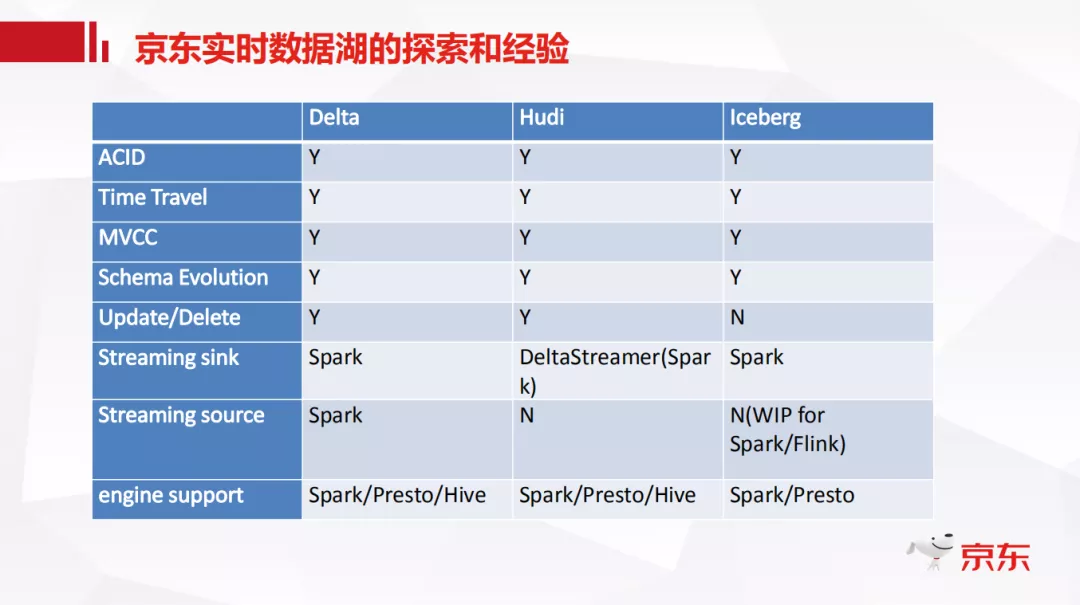
当时我们团队也在技术方案选型上讨论了很久,使用不同的应用场景做了不同方面的测试,最终选择了 Delta。首先是因为功能完整性上比较符合我们的要求;其次我们本身将数据湖定位成基于离线计算的数据存储更新服务,再加上我们团队本身就承担着 spark 的基础研发工作,比如常见的 sql 查询优化,shuffle 优化等等,对 spark 的了解会比较深入一些,所以我们最终选择 Delta 作为数据湖的基础,同时开发过程中吸取 Hudi 和 Iceberg 的各自特点。
Delta Lake 核心原理
1. Delta Lake 简介
引用来自官网对于 Delta lake 的一段介绍"Delta 是一个开源的带有 ACID 语义的存储控制层,其中 Delta 的数据表主要是由数据文件和事务日志两部分组成。"
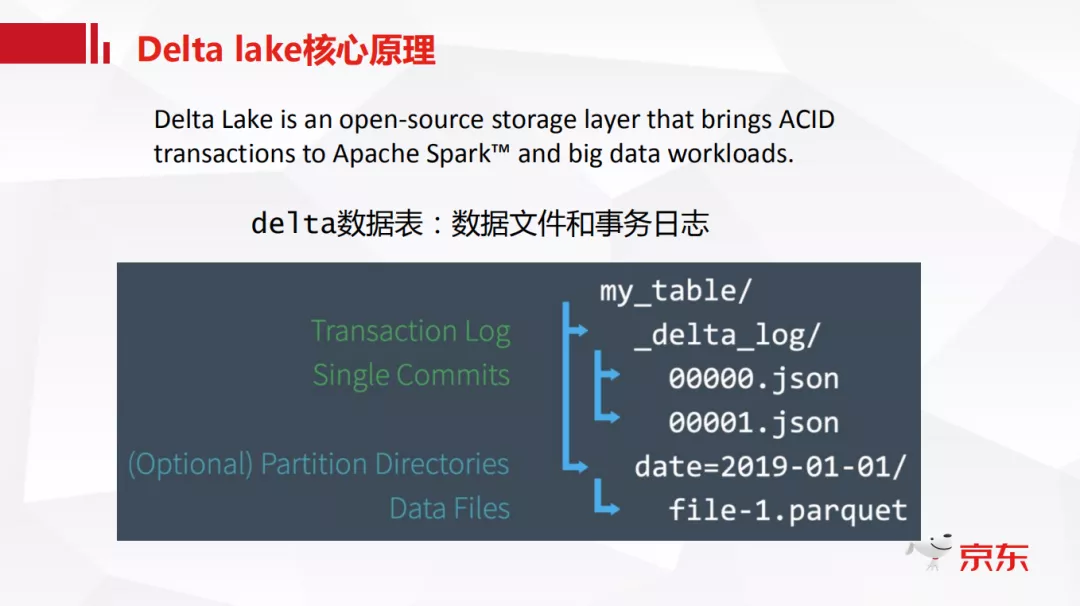
如图所示,可以看到这是 Delta 表物理上的文件结构的组成,比如说我们有一个 my_table 表,与常规的离线 Hive 表不同的是,它下面会有一个_delta_log 目录,这个_delta_log 我们叫做 Transaction log,也就是事务日志,然后就是常规的数据文件,数据文件的格式是 parquet,日志文件的格式是普通的 json 格式。
Transaction log 是整个 Delta 核心,也是所有 Delta 功能实现的基础,所有对 Delta 的操作,无论是增删改还是修改表结构,都会被记录到 Transaction log 中。所以我们接下来重点介绍一下 Transaction log 是什么。
2. 事务日志解析
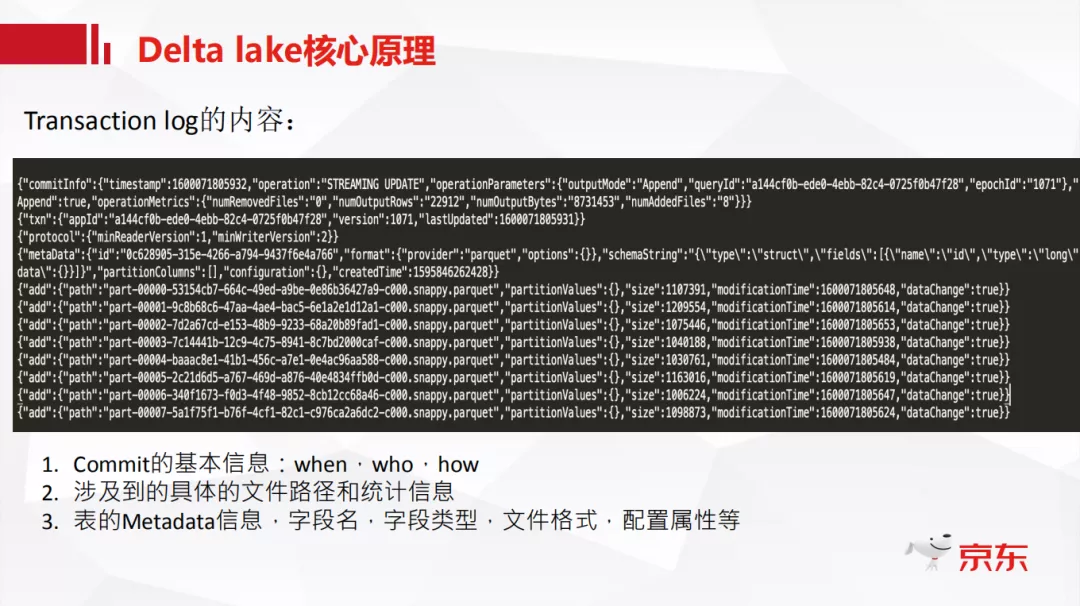
Transaction log 主要涉及到三方面的信息:when,who,how
一次事务就是一次 commit,日志中会记录 commit 的基本信息,简单来说就是是谁在什么时候怎么做的 commit,以截图中的日志为例,会有一个时间戳 1600071805932 来记录什么时候的 commit,是 STREAMING UPDATE 做的 commit 的,commit 内容是新增了 8 个数据文件。
把涉及到的具体文件路径和统计信息写到 log 中,比如说他的文件名是什么,每个文件的大小是多少,是什么时间修改的,它都会记录。
表的 Metadata 信息,字段名、字段类型、文件格式、配置属性等。这些与普通 Hive 表存在 metastore 里的内容是完全一样的。
3. Delta 数据表读取流程
以一次添加数据的操作为例,简单介绍一下 log 的具体内容,以及 Delta 数据表的读取流程。

Delta 每次更新都会形成一个 log,一系列的更新操作也就形成了多个 log。log 的命名是严格按照版本号递增的顺序命名的。Delta 内部为了提高读取性能,每 10 个 log 会生成一个 checkpoint 文件,每次 checkpoint 都会把最新的 checkpoint 文件路径记录到_last_checkpoint 文件中,这样随着时间的迁移整个表的变更操作都会被记录下来。
Checkpoint 简单来说是前面所有 json log 的总和,但并不是简单的堆在一起,他包括消除一些冗余信息的合并操作。比如说在 3 版本中新增了两个文件 A 和 B,在 10 版本中删除了文件 A,那么这个表就只剩下文件 B 了,此时 checkpoint 只会记录文件 B,再加上本身 checkpoint 使用 parquet 列式格式保存,spark 读取性能会提高很多。
以图中左边的例子为例,总结一下 Delta 数据表具体读取流程:
① 先使用_last_checkpoint 找到最近的 checkpoint 文件,也就是图中的 000010.checkpoint.parquet。
② 再找到 checkpoint 文件之后的 json log 文件,就是图中的 11 版本和 12 版本的 json。
③ 最后合并所有 json log 和 checkpoint log 的记录,得到数据表在该版本状态下包含哪些具体的数据文件。
4. Delta Lake 特点
有了 Transaction log 后,很容易实现下面一些特点:
支持批流读写
提供 ACID 语义
Update/delete 的支持
历史版本回溯和审计
抽象存储接口
查询性能提升
批流一体开发流程
使用 Delta 实时数据湖后我们的开发流程可以简化如下:
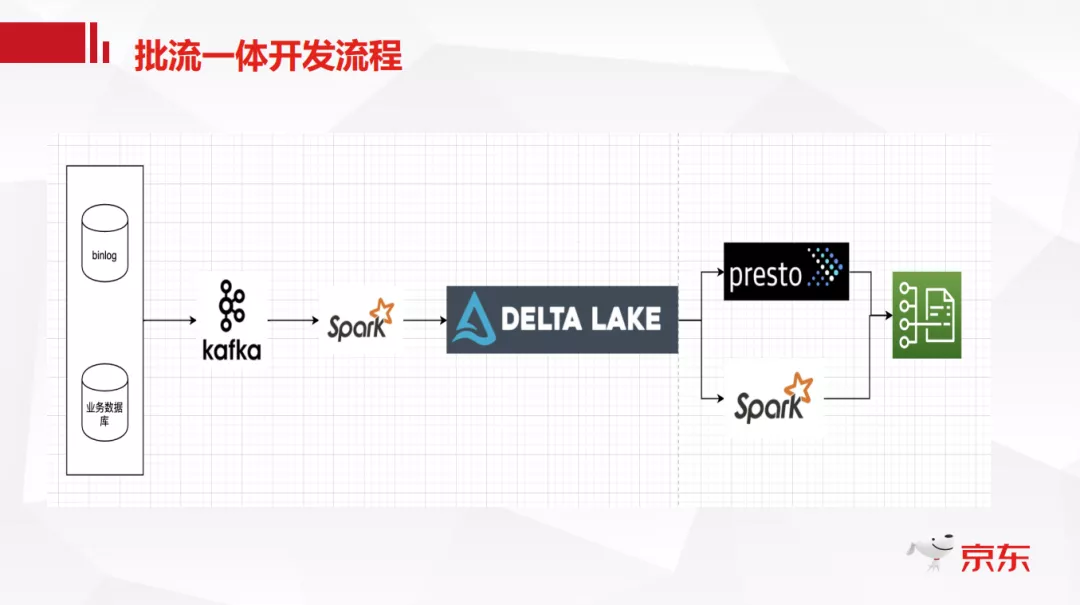
如图所示,与上面的 Lambda 架构相比,只有一条数据流转链路。首先将业务数据库的 binlog 日志实时的写入 kafka,然后通过 SparkStreaming 实时消费 kafka 中的数据,解析 binglog 日志后落入 Delta 数据湖中,因为整体的落数过程是实时的,所以下游既可以实时流处理也可以离线批处理。这样可以降低开发成本和存储成本,而且如果遇到脏数据的写入,整个回滚和 Debug 过程也会很方便。
总结
最后做一下简单的总结:
Delta 本身刚开源不久,内部有很多优秀特性没有开源出来,如直接使用 SQL 进行版本回溯,DFP 动态文件裁剪,还有 Z-Ordering,使用一些策略来优化数据存储分布,提高下游数据的查询效率等。
小文件和历史文件的清理问题。Delta 每次写入数据时都要写一批小文件,HDFS 对小文件是非常敏感的,如果小文件过多,namenode 的压力会特别大。
Hive Connector 的支持。社区的 Hive Connector 绑定的 Spark Delta 版本都是紧耦合的,有一些 API 的接口都不一样,需要自定义改造 Hive Connector,支持生产环境上的版本。
计算引擎和使用方式的支持。这一点主要是突出在 Hive 和 Presto 的使用上,无论是 Hive 还是 Presto,如果想读一个 Delta 表的话,必须新建一个名字不一样的外部表,location 指向 Delta 表的位置,这样对用户侧来说,读同样的数据,存在多个不同的表名,用起来会不太方便。
文章转载自:DataFunTalk(ID:datafuntalk)
原文链接:京东实时数据仓库开发实践




