
4 月 30 日-5 月 4 日,Google Scholar 评分计算机领域最高的人工智能顶级国际会议 ICLR 2023 (International Conference on Learning Representations)举行。同期互联网领域顶级国际会议 TheWebConf (原 WWW) 2023 也在美国奥斯丁召开。
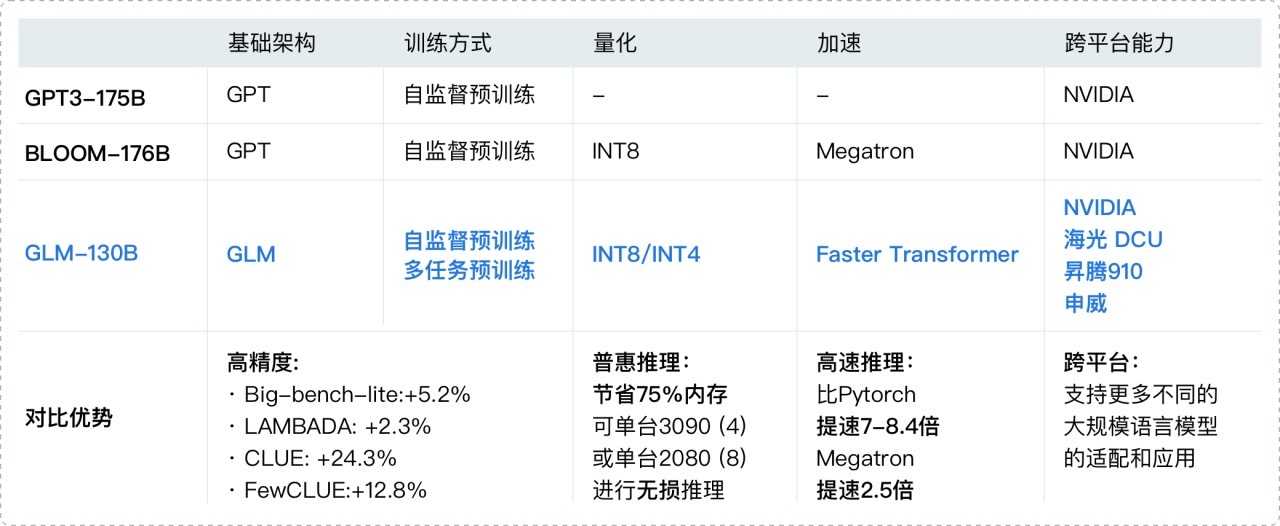
智谱 AI 和清华 KEG 联合研究预训练大模型以及图神经网络,多篇文章在大会上发表。据悉,智谱 AI 联合清华在 ICLR 2023 上发表的文章主要介绍了千亿基座模型 GLM-130B。
它是不同于 BERT、GPT-3 以及 T5 的架构,是一个包含多目标函数的自回归预训练模型。该模型有一些独特的优势:
双语: 同时支持中文和英文。
高精度(英文): 在公开的英文自然语言榜单 LAMBADA、MMLU 和 Big-bench-lite 上优于 GPT-3 175B(API: davinci,基座模型)、OPT-175B 和 BLOOM-176B。
高精度(中文): 在 7 个零样本 CLUE 数据集和 5 个零样本 FewCLUE 数据集上明显优于 ERNIE TITAN 3.0 260B 和 YUAN 1.0-245B。
快速推理: 首个实现 INT4 量化的千亿模型,支持用一台 4 卡 3090 或 8 卡 2080Ti 服务器进行快速且基本无损推理。
可复现性: 所有结果(超过 30 个任务)均可通过我们的开源代码和模型参数复现。
跨平台: 支持在国产的海光 DCU、华为昇腾 910 和申威处理器及美国的英伟达芯片上进行训练与推理。
去年 11 月,斯坦福大学大模型中心对全球 30 个主流大模型进行了全方位的评测,GLM-130B 是亚洲唯一入选的大模型。在与 OpenAI、谷歌大脑、微软、英伟达、脸书的各大模型对比中,评测报告显示 GLM-130B 在准确性和恶意性指标上与 GPT-3 175B (davinci) 接近或持平,鲁棒性和校准误差在所有千亿规模的基座大模型(作为公平对比,只对比无指令提示微调模型)中表现不错。目前,该模型收到 69 个国家 1000 多个研究机构(截至 2023 年 5 月 1 日)的下载使用需求。
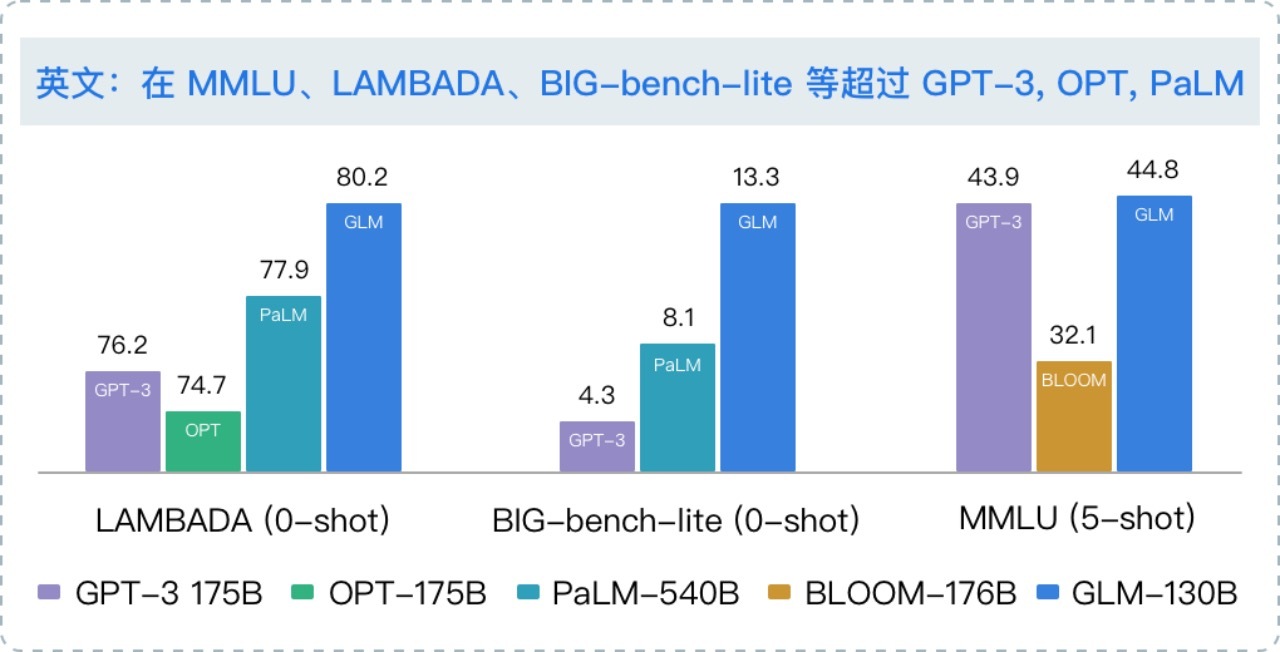
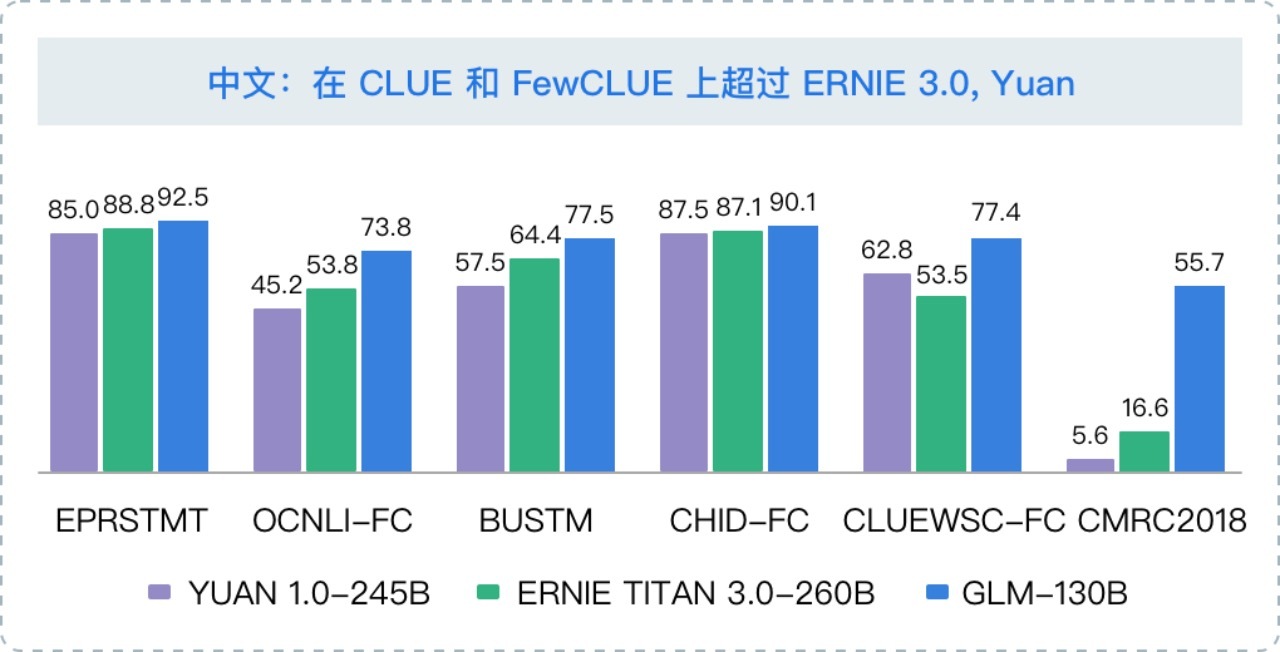
据悉,今年来,智谱 AI 在千亿基座模型 GLM-130B 中注入了代码预训练,通过有监督微调(Supervised Fine-Tuning)等技术实现人类意图对齐,发布了 ChatGLM。类似 ChatGPT,这是一个具有问答和对话功能的千亿中英语言模型, 并针对中文进行了优化。
与此同时,智谱 AI 还开源了最新的中英双语对话 GLM 模型: ChatGLM-6B,结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。经过约 1T 标识符的中英双语训练,辅以监督微调、 反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 虽然规模不及千亿模型,但大大降低了用户部署的门槛,并且已经能生成相当符合人类偏好的回答。目前, ChatGLM-6B 模型全球下载超过 100 万。
在 WWW 2023 上,智谱 AI 联合清华发表了关于图神经网络 GNN 工具平台的论文 CogDL。
CogDL 是一个广泛的图神经网络工具包,它为现实世界的问题,尤其是那些涉及大规模数据的问题提供了许多有效和高效的解决方案。该工具包通过整合多种不同的下游任务,同时搭配合适的评估方式,使得研究者和使用者可以方便、快速地运行出各种基线模型的结果,进而将更多精力投入研发新模型的工作之中。
CogDL 最特别的一点在于它以任务(task)为导向来集成所有算法,将每一个算法分配在一个或多个任务下,从而构建了 “数据处理-模型搭建-模型训练和验证” 一条龙的实现。
CogDL 的图表示学习算法可以分为两类:一类是基于图神经网络的算法,另一类是基于 Skip-gram 或矩阵分解的算法。前者包括 GCN、GAT、GraphSAGE 和 DiffPool 等,以及适用于异构图的 RGCN、GATNE 等;后者则包括 Deepwalk、Node2Vec、HOPE 和 NetMF 等,以及用于图分类的 DGK、graph2vec 等算法。大体上,CogDL 将已有图表示学习算法划分为以下 6 项任务:
有监督节点分类任务(node classification):包括 GCN、GAT、GraphSAGE、MixHop 和 GRAND 等;
无监督节点分类任务(unsupervised node classification):包括 DGI、GraphSAGE(无监督实现),以及 Deepwalk、Node2vec、ProNE 等;
有监督图分类任务(graph classification):包括 GIN、DiffPool、SortPool 等;
无监督图分类任务(unsupervised graph classification):包括 InfoGraph、DGK、Graph2Vec 等;
链接预测任务(link prediction):包括 RGCN、CompGCN、GATNE 等;
异构节点分类(multiplex node classification):包括 GTN、HAN、Metapath2vec 等。
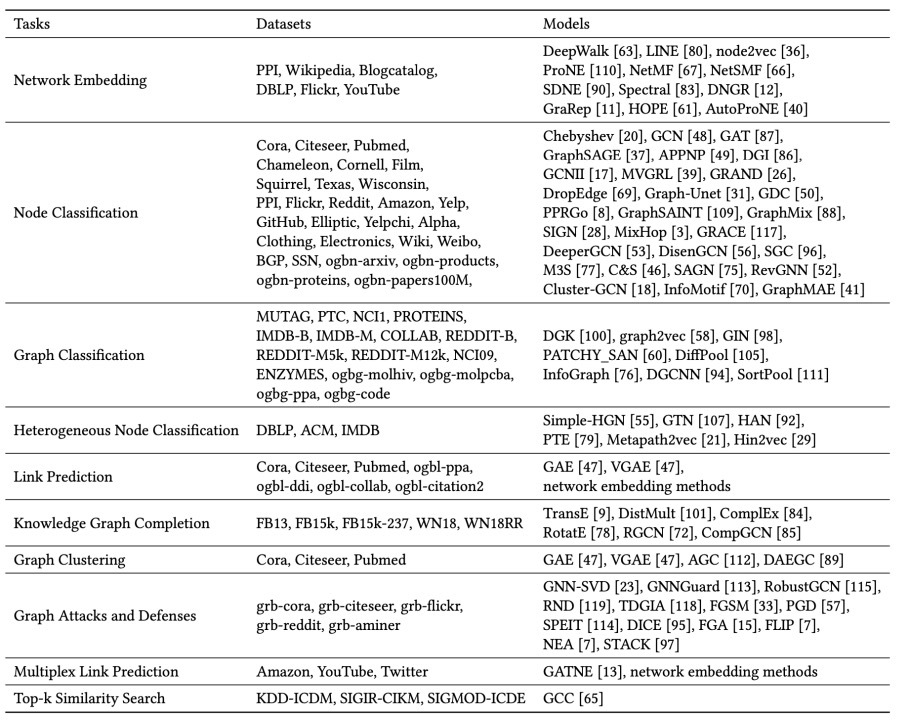
CogDL 还包括图上的预训练模型 GCC,GCC 主要利用图的结构信息来预训练图神经网络,从而使得该网络可以迁移到其他数据集上,来取得较好的节点分类和图分类的效果。
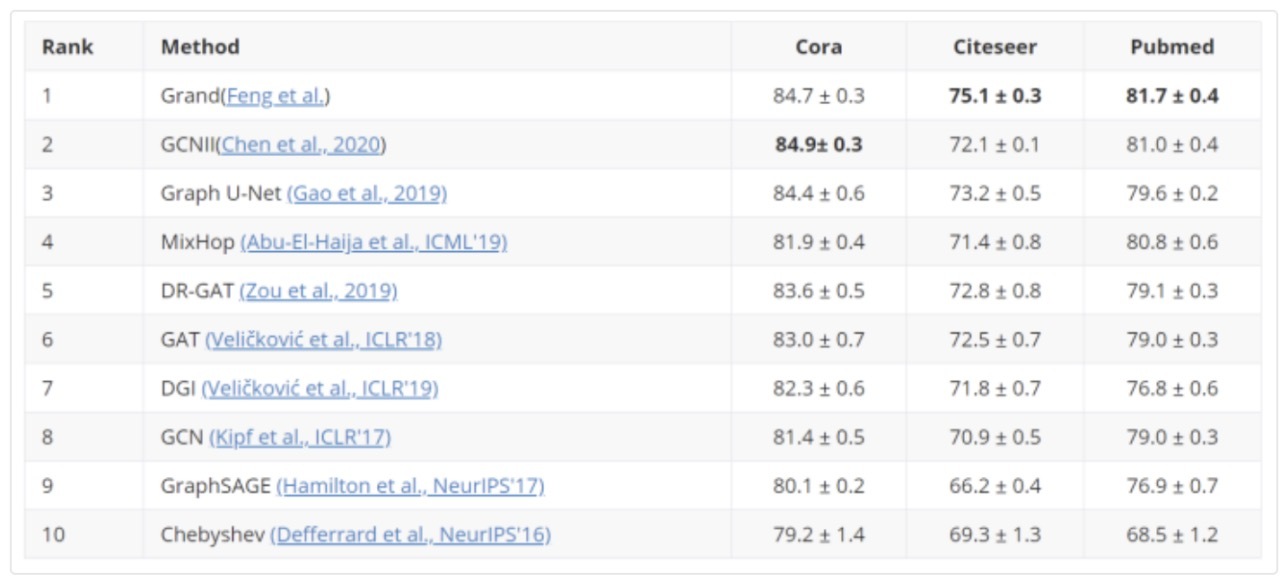
那么,研究者和使用者可以利用 CogDL 做些什么?主要有三点:跟进 SOTA、复现实验,以及自定义模型和数据。
跟进 SOTA。CogDL 跟进最新发布的算法,包含不同任务下 SOTA 的实现,同时建立了不同任务下所有模型的 leaderboard(排行榜),研究人员和开发人员可以通过 leaderboard 比较不同算法的效果。
复现实验。论文模型的可复现性是非常重要的。CogDL 通过实现不同论文的模型也是对模型可复现性的一个检验。
自定义模型和数据。“数据-模型-训练”三部分在 CogDL 中是独立的,研究者和使用者可以自定义其中任何一部分,并复用其他部分,从而提高开发效率。
CogDL 非常简单易用,下面给出了一个调用 CogDL 的例子,可以看出 CogDL 的代码比如 PyG 和 DGL 简单很多。





