
世界杯已经结束了,梅西带领阿根廷时隔三十六年之后终于如愿捧杯。抖音直播提供的 4K 超高清超低延迟看播能力给亿万观众留下了深刻的印象,决赛的 PCU 达到 3700w+,在这样大规模并发下,如何能稳定流畅地做到更低的延迟,是一个巨大的挑战。本文主要介绍世界杯期间火山引擎视频云和相关团队在低延迟上的工作和优化,作为低延迟方向上的总结。
本文主要讨论生产和传输环节的延迟。生产环节的延迟主要受视频流供应商控制,技术团队可以实现的是,尽可能准确地测量出生产的每一个环节的实际延迟,并在发现不合理的情况时推动供应商解决。传输环节的延迟技术团队更可控,也是本次优化的重点。这部分技术能力可以作为火山引擎视频云的优势能力积累并对外提供服务。在优化的过程中,一个越来越清晰的认知是:降低延迟并不困难,难的是延迟降低之后,怎么通过优化保证播放体验不下降甚至变得更好。
一、背景信息
首先简单介绍下世界杯直播的整个分发链路,还有每个环节的延迟的测量方法,让大家对整体的链路有初步的全局认识。
(一)抖音世界杯信号分发链路
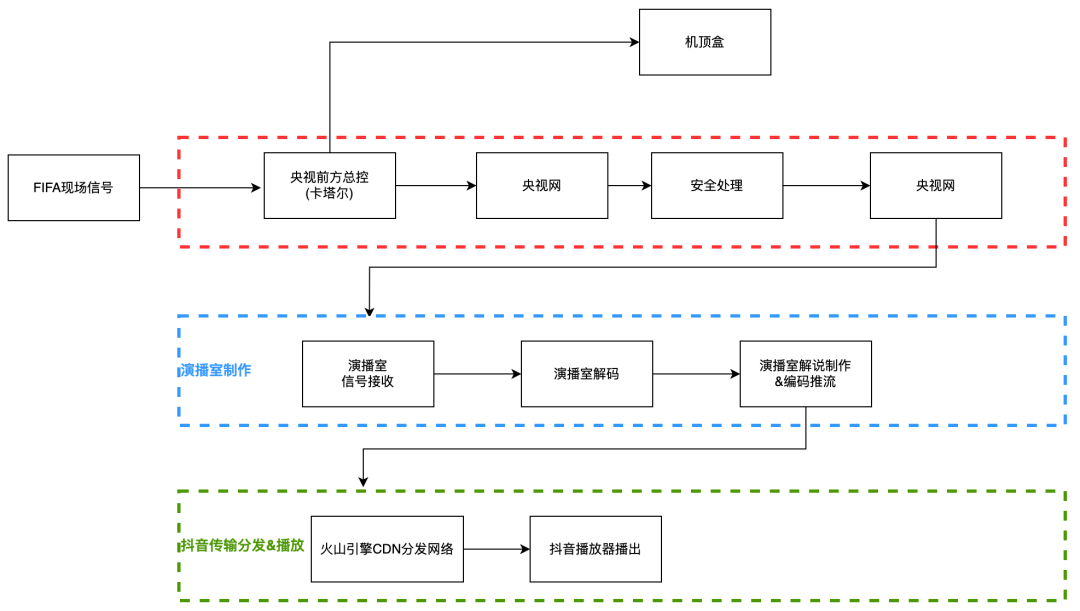
(二)全链路延迟测量以及方法
测算方法:
拍照
视频画面上有时钟展示的(比如画面左上角或者右上角的北京时间或者比赛持续时间,一般精确到秒),可以通过同时拍照两个播放画面的方式,记录同一时刻两个画面,然后通过照片中的时钟做差来计算。
手动秒表计算
如果视频画面中无时钟相关内容,那么可以从延迟低的视频画面中选取具有标志性易识别的帧启动秒表,然后观察延迟高的画面出现同样的帧画面时,停止秒表,记录秒表结果为延迟对比结果。
仅适用演播室推流到抖音播放链路

计算方法:端到端延迟 = 观众当前系统时间戳 - SEI 中的时间戳,单位 ms。
统计频度:每 2s 计算一次,每 10s 上报一次当前计算结果。
每个 I 帧前会有一个 SEI,流规格设置为 I 帧间隔为 2s,因此每 2s 演播室推流侧会生成一个 SEI 帧。
前置要求:演播室推流前进行 NTP 本地时钟校准。
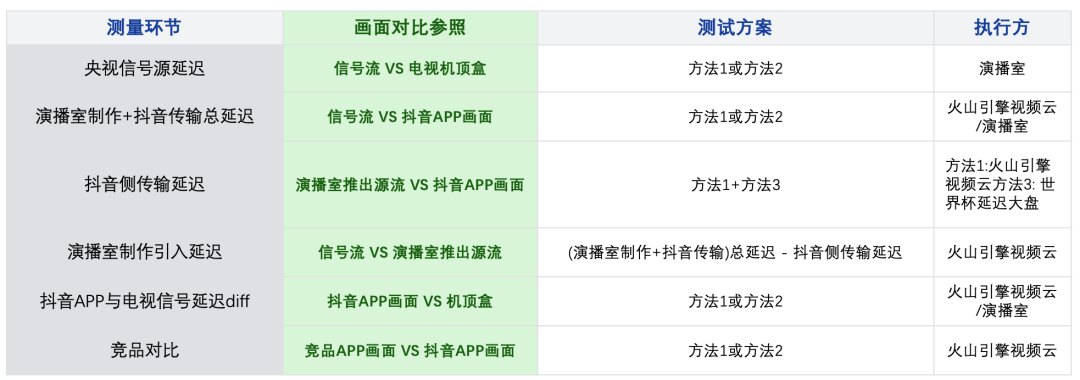
延迟测量手册:
二、生产环节的低延迟
(一)信号源
网络流信号源在给到抖音之前存在多个环节,每个环节都可能会对最终的延迟有影响,但这一部分技术团队可以影响的比较少,主要是运营同学在沟通。
(二)演播室制作环节
演播室在收到央视的源流之后,需要加上解说和包装,所以也会引入一定的延迟。这次抖音的多个演播室是由多家第三方公司负责的,第三方公司的制作规格不一,在正式比赛之前经过大量的沟通,基本确认最重要的两个演播室的技术方案和使用的编码系统是一致的。
不过这次在演播室环节引入的延迟仍然偏高,达到了 1.5s 左右,和供应商工程师沟通后,短期内为了保证稳定,没有再进一步压缩了,这部分引入的延迟和竞品也是一致的。
三、传输环节的低延迟
下图是一次直播的简化的流程:
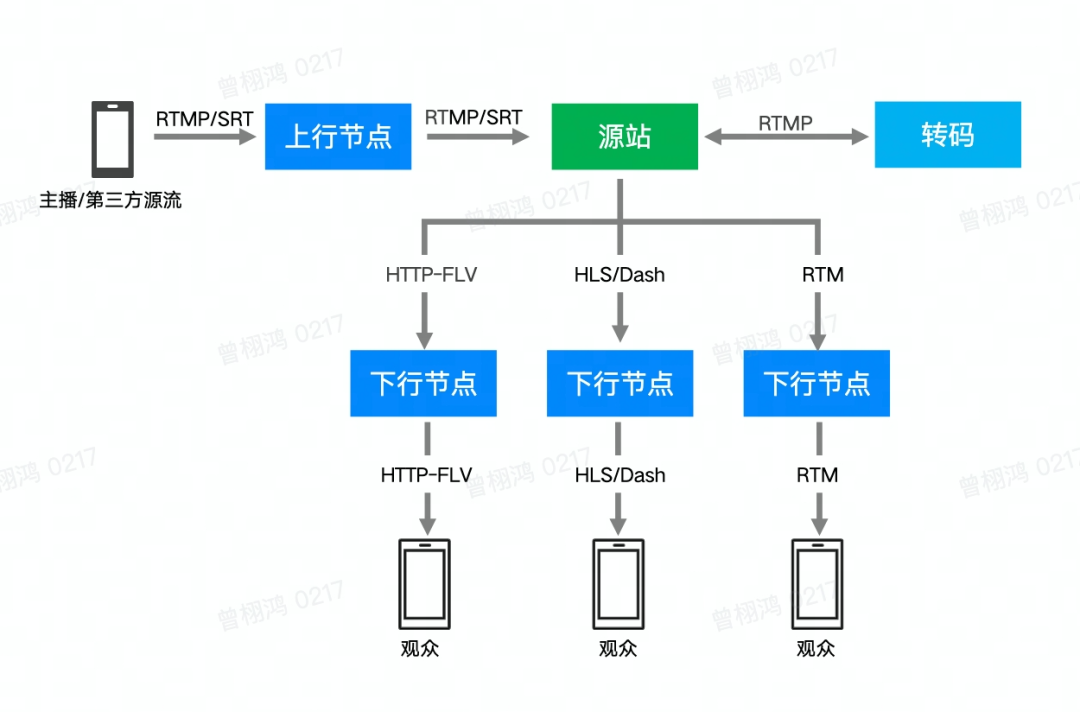
直播的传输环节里,对延迟影响大的主要是转码、分发和播放缓冲,使用实时的转码模式,转码器引入的延迟一般在 300ms 以内甚至更短。CDN 的分发环节也会带来一定的延迟,但相对也较短。为了对抗网络抖动引入的播放缓冲区引入的延迟播放缓冲引入的延迟常常会有 5s 甚至更多,所以本文主要讨论怎么在减少播放缓冲的情况下,通过不断地优化延迟降低的同时不影响整体的播放体验(不仅仅是卡顿) 。在调优过程中,大家对播放体验也有了更细致、更深的理解,逐渐弄清楚了哪些 QoS 指标可以对关键的 QoE 指标产生直接的影响,对以后要优化的方向也更明确了。
(一)FLV 方案
FLV 是现在国内主流直播播放使用的协议,火山引擎对低延迟直播的探索也是从 FLV 开始的。在百万英雄、内购会等活动中,FLV 低延迟方案也多次得到了验证。
之前详细介绍过 FLV-3s 方案在抖音落地的详细实践过程(细节内容可跳转到 基于 http-FLV 的抖音直播端到端延迟优化实践),同时提出过基于 FLV 方案做更低延迟下探,所面临的挑战也会更大:更低延迟的场景对直播全链路的传输稳定性要求苛刻程度会几何倍数增加,由于端到端链路的整体 buffer 更低,生产环节或者观众网络抖动,就更容易发生卡顿。只要发生一次卡顿,延迟就会秒级增加,最终累积延迟会越来越大。而世界杯赛事延迟要求达到 2s,继续延续 FLV-3s 方案显然达不到要求,需要配合精细的追帧或者丢帧策略。
1、基于 buffer & 卡顿信息的双阈值延迟追赶策略
音视频数据流转时序
在展开描述延迟追赶策略方案细节前,先简单介绍播放器音视频数据流转时序:网络 IO 下载音视频数据到播放器缓存 buffer->解码器从 buffer 中取数据解码并降解码后的数据存入待播放缓存->音画同步等播控策略->渲染播放音视频帧。
数据驱动 QoE & QoS 优化
由于进一步下探延迟,卡顿也会随之恶化,反而延迟逐渐累积增加达不到低延迟的效果,因此延迟下探必须配合延迟追赶播控策略来确保延迟增大后可及时追赶恢复到低延迟。是否只要在延迟增加后立即倍速追赶就能满足业务的需求呢?对于延迟 QoS 指标来说的确是,但对于用户主观体验的 QoE 指标,这样的策略反而可能是负向的。
结合历史 AB 实验以及 DA 详细数据分析,有以下几点倍速追赶与 QoE 指标之间的关联现象:
倍速追赶带来的播放速度变化本身就是负面的体验
倍速时长超过 2 秒,用户即可有感知且负向反馈
倍速速度越大,播放速度前后变化 diff 越大,负向越严重
倍速与正常速度的切换过于频繁,会带来负向反馈
综上,需要一套精细的播控策略兼顾延迟与 QoE 指标的平衡。详细方案设计如下:
输入:播放器当前 Buffer 时长、历史 Ns 内 buffer 抖动方差、历史 Ns 内卡顿信息以及追帧参数配置。
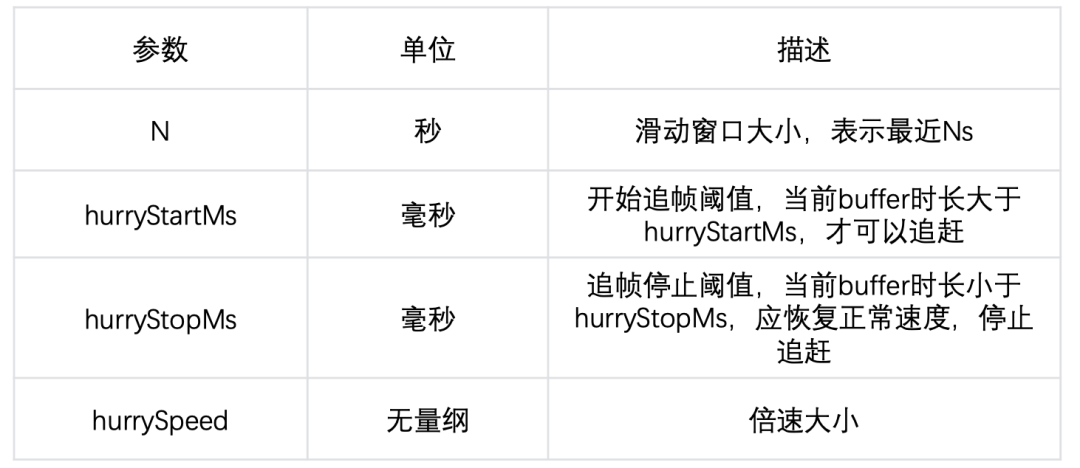
策略可配置参数以及含义映射:
输出:目标播放速度。
原理:
基于 buffer 抖动方差 & 历史卡顿信息,来定性衡量网络质量,判断是否可以追赶,只有在网络质量良好是才能触发追赶逻辑避免卡顿。
追帧采用双阈值,并且支持可配置,可以控制追帧持续时长不超过 2s,同时也可以保证不频繁变速。
追帧速度可配置,保证倍速变化不超过一定辐度。
2、FLV 2s 低延迟方案在抖音上调优总结
(1)收益总结
FLV 2s 低延迟已在抖音验证收益:核心 QoE 波动,电商指标显著正向,成本也有一定比例的节省,目前已全量。
世界杯:双端 FLV-2s 方案作为世界杯低延迟方案之一,支持了开幕赛到决赛的全部赛事。
(2)调优经验总结
无论播放过程中丢帧方式追赶延迟,还是卡顿后立即丢帧追赶延迟,只要是丢帧,QoE 都是负向。
iOS 端对倍速负向没有 Android 敏感,对倍速容忍度高。
精细化倍速追帧策略可以满足 FLV-2s 的延迟需求,但再进一步下探延迟,就需要同时配合卡顿优化方案从源头避免延迟增加。
(二) RTM 方案
RTM 的方案参考了 WebRTC,可以让端到端延迟直接进入 1s 以内,已经持续在抖音上打磨了一年多,整体来说遇到的困难很大,在推进的过程也不断地发现了新的问题,也逐渐认识到,直接把 RTC 在视频会议上的方案应用到直播播放场景的效果并不好,需要做大量的改造才能让直播的体验得到抖音用户的认可。同时评测的同学也持续对行业内已经上线的类似方案进行了跟踪和测试,经过线上测试后,也发现现有多方案也存在很多问题, 所以一直也没有停止自研。RTM 优化的目标是在延迟降低的情况下,用户核心体验指标对齐或者优于大盘的 FLV 方案。但是由于 FLV 低延迟方案的持续优化并拿到结果,一定程度上 RTM 的优化目标的 bar 是在不断提高的。
每次迭代都要经过分析数据->找到问题点->提出优化方案->完成开发和测试->AB 实验->分析数据的反复循环,每一次循环的都需要至少一个版本甚至多个版本的周期,所以项目整体耗时较长。关于如何提升实验的效率,也做了很多思考和探索。最后通过多次的实验和反复的问题解决,在核心用户体验指标基本对齐了 FLV,所以在世界杯的多场比赛中,RTM 方案也承担了一定量级的 CDN 容量,核心键指标上都对齐了大盘,稳定性和质量得到了充分的验证。
1、RTM 方案优化概述
项目启动后,将 RTC 实时通信 SDK 直接集成进入播放器后首先进行线上 AB 测试,初期的实验效果显得大跌眼镜:除了端到端延迟指标符合预期以外无论是拉流成功率,首屏秒开时间,卡顿等指标均与 FLV 差距很大;所以 RTC 技术方案要顺利部署到直播场景,还需要配合直播播控策略进一步优化。
为了让 RTM 的综合指标对齐 FLV,从若干角度来进行 RTM 的播控逻辑定制化,所有的优化围绕着核心用户体验指标进行展开:
DNS 节点优选、SDK 信令预加载、UDP 连通性预探测主要解决的拉流成功率相关问题。
SDP 信令相关优化主要解决信令时间消耗的问题(首帧时间)与成功率问题。
RTC 内核播控定制化主要解决播放的卡顿问题。
播放器播控逻辑结合解决的音画同步与渲染策略的问题。
2、首帧时间的优化
传统的 RTC 技术采用 SDP 信令方式进行媒体能力协商,SDP 信令通过如下图方式进行交互参见下图:
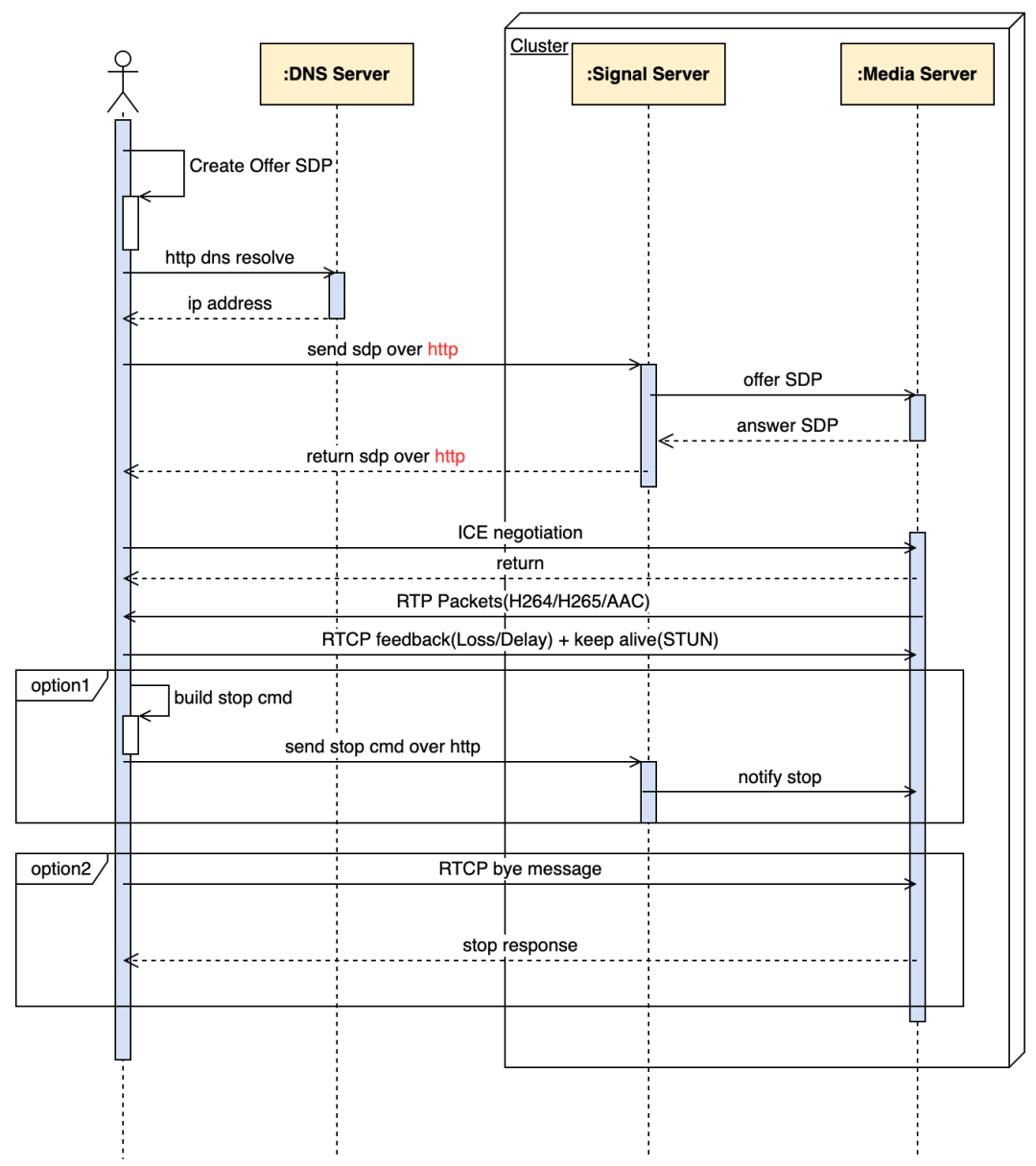
但是 HTTP SDP 信令交互存在如下方案的弊端:弱网环境下(如 RTT 较大/网络信号不稳定),HTTP 信令建联成功率不理想;导致播放请求响应缓慢或超时(基于信令数据包庞大且发生 TCP 重传导致信令响应速度不理想);另一方面 SDP 交互传输 SDP 文本的内容很大(通常 3KB~10KB)建联的成本较高导致初始化的成本无法忍受;对比 FLV 的 HTTP 请求完成后直接完成建联和媒体数据直接传输,可以采用新的信令模式:MiniSDP 信令。这是一种基于二进制编码的压缩协议,提供对标准 SDP 协议进行压缩处理;这种方案可以降低信令交互时间,提高网络传输效能,降低直播拉流首帧渲染时间,提高拉流秒开率/成功率等 QoS 统计指标。其作用原理是将原生 SDP 转换成更小的二进制格式(300bytes)通过一个 UDP 包(MTU 限制之内)完成整个 C/S 交互。
采用 MiniSDP 信令进行媒体协商通信的信令交互流程如下图所示:采用 MiniSDP 压缩信令方式利用 UDP 网络传输;预期单个 UDP 数据包请求即可完成 SDP 完整压缩信息的传输。
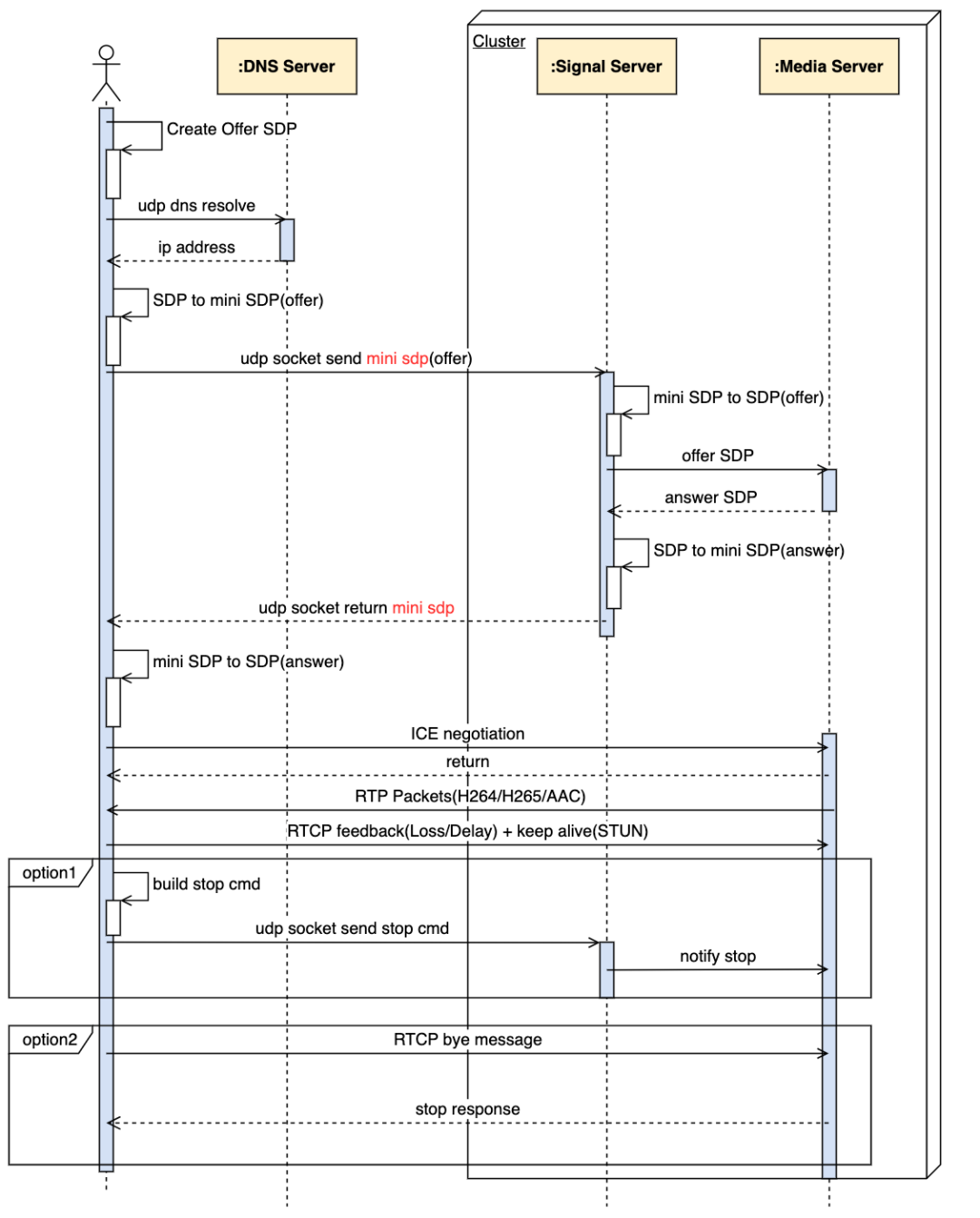
当前 MiniSDP 信令(UDP)信令上线后观察后续的 QoS 指标发现,信令建联的成功率和首帧时间得到了大幅度的优化。
3、拉流成功率的优化
经过线上的 AB 实验发现:RTM 拉流成功率相比 FLV 持续存在着一定的差距,而且这种差距经过观察得知:用户的网络等级质量和用户的拉流成功率存在一定的正相关性(UDP 协议本身特性),即用户网络质量越高成功率越高。
拉流网络等级筛选
根据网络质量预估信息综合评估用户的 TCP/UDP RTT 和数据下行吞吐率,得出用户网络等级;选择网络质量优异的用户采用 RTM 拉流降低失败率。
当线上 AB 实验采用网络等级漏斗进行网络筛选以后,选择用户网络情况相对较好的这一部分的用户开启实验(这部分用户占全网用户的绝大部分,剩余的用户采用默认 FLV 低延时),原理就是用户在拉流前综合权衡当前网络状态,当网络不适合 RTM 时候通过策略前置回落到 FLV,使得这部分用户的体验不受到影响。
UDP 节点探测
拉流前根据用户请求的 URL 所归属的对应 CDN 边缘节点,发起 UDP 探测;一段时间内发送数据包观察对应 CDN 节点的数据 RTT 和丢包率,只有满足一定条件(如 RTT<80ms 且丢包率<10%)的场景才会认为 UDP 传输可以保证质量和组帧成功率。
信令预加载
在当前点播/直播房间中,预先加载后一个直播间的信令信息,提前做好 SDP 加载,降低下一个房间的首帧上屏时间。
4、卡顿的优化
内核 JitterBuffer 禁用丢帧优化
未调优时候经过 AB 实验发现,RTM 的视频卡顿大幅度上涨,跟预期不匹配,对此团队分析了线上的大量日志数据观察。当前的硬解具有核心用户体验指标的收益,但卡顿是 FLV 的将近 3 倍,分析了大量线上 badcase,发现部分机型网络条件较好,但帧率却极低,类似下表这种:
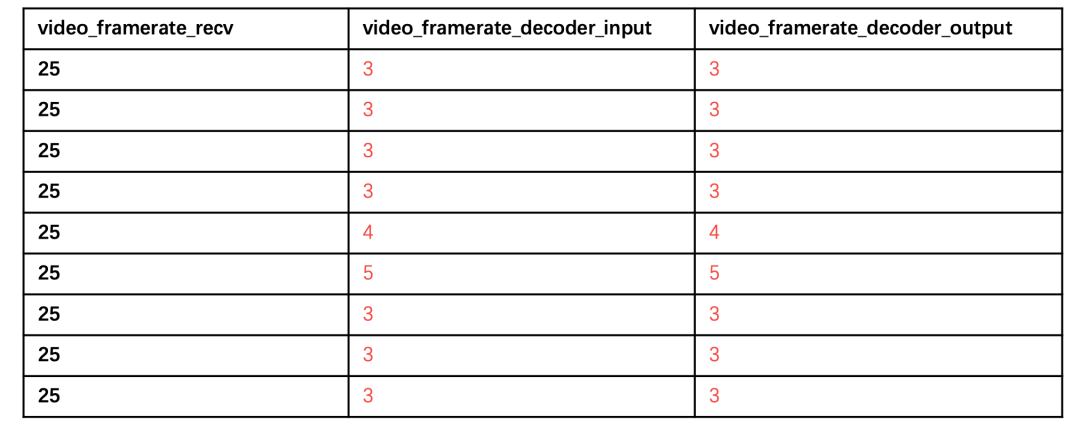
这种问题在部分高热机型上的比例也是很高的,但同样的机型,FLV 播放并无这样的问题,通过对比 FLV 和 RTM 的播控策略,发现了一个关键不同点——传统的 RTC 场景优先保时延,全链路会触发各种丢帧(包括但不限于解码模块,网络模块),FLV 直播场景会优先保证观播体验(不丢帧,良好的音画同步效果)。RTM 要想减少卡顿,取得 QoE 的收益,播控策略需进行定制化,不影响连麦场景下的逻辑,内部采用新的播控策略,最后上线后卡顿显著减少。
RTC 内核 JitterBuffer 平滑出帧优化
5、播控逻辑的优化
RTM 网络传输 SDK 的抽象:将内核进行改造,复用引擎中的网络传输-组包-JitterBuffer/NetEQ 模块;去掉解码/渲染等模块;将音视频的裸数据抛出供播放器 demuxer 集成。
解码器复用:降低解码器重新初始化的时间,降低解码首帧延时;复用解码器-渲染器的播放缓冲区控速逻辑。
音画同步的优化:RTC 音视频出帧之后在播放器侧按照 FLV 的播控逻辑进行二次音画同步处理;按照 audio master clock 主时钟进行渲染校准,视频帧渲染同步到音频时间轴上。
6、RTM 针对世界杯的优化
本次世界杯超高清档位的分辨率达到了 4K,对 RTM 方案的性能带来了很大的挑战,在前期测试时也发现了一些低分辨率没有的问题。当时时间非常紧,不过在正式比赛之前,还是完成了这些问题的修复,赶上了最后一班车。主要的问题和解决方案如下:
4K 高清档位卡顿严重卡顿: 优化 NACK 策略,保证更大的帧的组帧成功率。
CPU/GPU 内存: 优化 video 传输 pipeline,减少不必要的 raw 数据格式转换。
最终在性能和效果都通过了测试,RTM 在世界杯期间也顺利上线,承担了一定的流量,上线后稳定性和质量都符合预期。
(三)世界杯中抖音和其它产品平均的延迟对比
在实际的世界杯比赛中,抖音的延迟一直领先于相同信号源的其它产品 30s 左右。即使最后两场其它产品在个别直播间上了快速追赶策略比抖音快 0~1s,但追的速度过快且持续时间超过 15s+,有明显感知,体验相对较差,这种策略在抖音上也曾经做过 AB 实验 ,播放时长是显著负向的,所以最后并没有跟进。
四、未来的优化方向
未来在高清、沉浸、互动的直播场景中,针对高码率、低延迟的需求,火山引擎视频云会继续打磨现有的适合不同场景的各种低延迟的方案,同时也会不断地探索新的方案,在延迟、成本、卡顿和其它播放体验上找到适合不同场景的最佳或者最平衡的方案。
在我看来,火山引擎视频云的最大的优势,在于可以把先进的技术放到真实的海量用户的场景去做线上训练,通过不断地总结失败的教训和成功的经验,对用户体验有更深更细微的理解。下面简单介绍一下火山引擎视频云在各个方案上继续努力的方向。
(一)FLV
追帧策略实现更细粒度的追帧,做到“按需追帧”,避免不必要的追帧,引起 QoE 的负向。
挖掘合适的传输框架,建立与边缘云节点(发送端)交互的通道,实现云端联动的拥塞控制算法,优化卡顿,避免延迟增加。
目前大盘的平均延迟已经有了相当程度的降低,但有一小部分长尾用户的延迟是很大的,后期的优化方向也会适当地侧重到这部分长尾用户,让更多的长尾用户能享受到真正的低延迟,降低观看同一直播流的观众间延迟差,满足基于流内容的一些强互动玩法,比如倒计时跨年。
FLV 低延迟协议标准化:沉淀适用不同直播场景(电商、赛事、游戏、演唱会等)、不同网络环境、可一键部署的套餐方案。
(二)RTM
在 RTM 方案上,火山引擎视频云还在不断地发掘优化点。以下几点是未来会继续探索的几个方向:
拉流成功率的持续改进
从 SDK 技术层面共性差异看,RTM 协议中的 RTP 包组首帧存在成功率短板,后续的成功率优化需要从引擎的调优持续探索。
RTP 扩展特性的持续迭代
降低首帧时间缩小和 FLV 的差距:RTM 异步回源的深入探索,目前只有一家 CDN 支持,需要推广至其它 CDN。
进一步探索提升 RTM 的拉流成功率(针对用户网络不佳的场景):探测 ICE 多模式启播能力对成功率的提升,明确各家 CDN 支持 RTM 启播 TCP/UDP 及混合模式的能力。
RTM 是降低延迟的一种全新方案,为了把在海量用户的业务上积累的经验和教训反馈给整个业界,火山引擎视频云也联合腾讯和阿里发起了 RTM 行业标准的制订,具体可以参考https://www.volcengine.com/docs/6469/103014,未来也会把标准推广到更多的 CDN,不断完善的同时,和业界一起向更低延迟演进。
(三)切片类协议的延迟优化
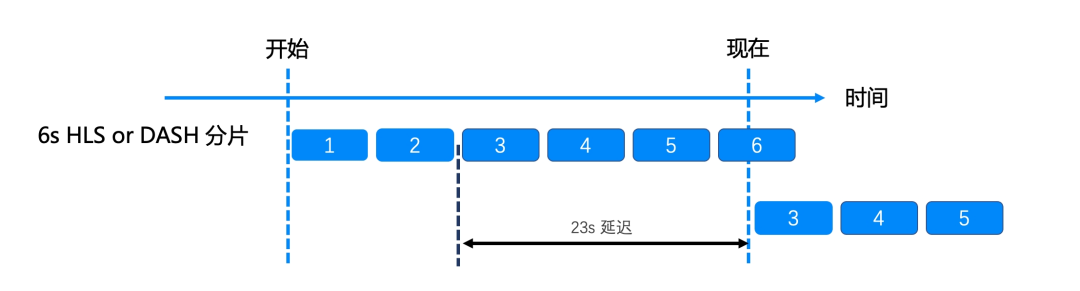
海外的 CDN 基本都只支持切片式的协议如 HLS/Dash 等,不支持 FLV 这类“过时”的传输协议。但 HLS/Dash 因为切片的存在,而且为了保证视频的压缩率,切片一般都是秒级的,且需要切片完全生成才能分发该分片,并且需要至少两三个分片都生成完才能分发,所以和流式的协议相比,延迟上天然有一些劣势。其实这也是竞品使用的方式,如下图,每个分片 6s,在三个分片生成完后才可以分发,带来了 23s 的延迟。世界杯期间,在视频同源的情况下,其它产品的延迟显著高于 抖音 ,就是因为使用了类似的 HLS 的切片传输方案。
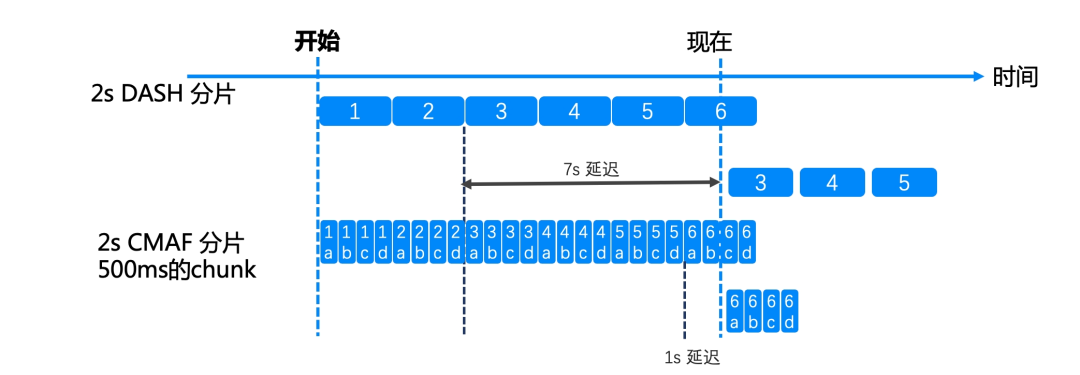
但随着 Akamai 和 Apple 分别提出了 CMAF 和 LL-HLS,引入了 fmp4 和 chunk 的概念,可以实现分片没有完全生成的时候就开始分发分片的部分 chunk,延迟下限有了很大程度的下降。如下图,延迟可以降到 1s。
火山引擎视频云在 Apple 提出 LL-HLS 之前就跟进了 CMAF,在 CMAF 的延迟和卡顿、拉流成功率上的优化上也持续有不小的投入。现在回顾 CMAF 的优化的过程,可以发现其实要解决的问题和 RTM 有很大的相似性,比如 CMAF 也存在拉流成功率、音画同步、性能问题,优化前在核心 体验指标 上同样显著差于 FLV。
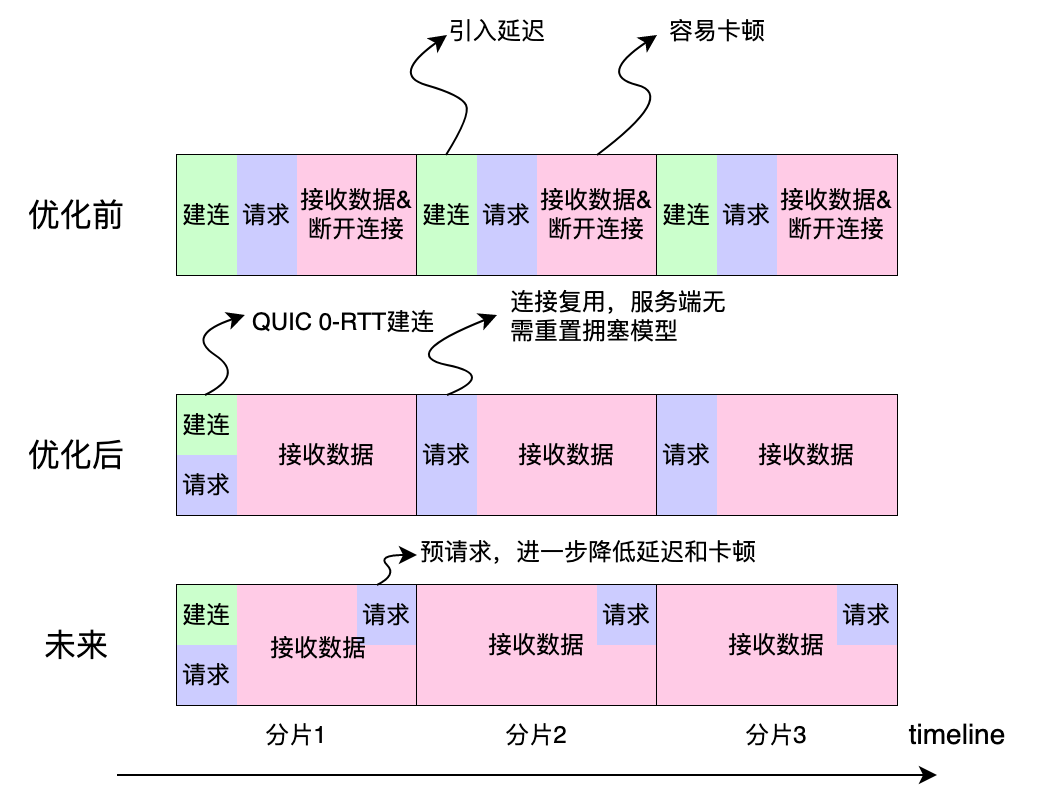
与 FLV 的流式传输不同,CMAF 需要依赖用户不断发起各个分片的请求来获取音视频数据,如果继续采用 FLV 的请求模式,即建连->请求->响应->断开连接,会引入大量的建连耗时,造成卡顿,同时导致延迟的增大。做一个简单的计算,假设每个切片是 2s,那么平均 1s 就会有一次音频或视频请求的建连,这对于网络较差,尤其是高 RTT 的用户来说是不可接受的,如果此时为了低延迟强行降低 buffer 水位,建连时的缓存消耗将导致频繁的卡顿。
为此,可以在 CMAF 上采用 QUIC 协议与连接复用结合的方式,首先 QUIC 协议的 0-RTT 建连允许客户端在服务端确认握手成功之前就发出 HTTP 请求,而连接复用直接省去了后续请求的建连操作,大幅优化了建连耗时,维持延迟的稳定。但即使如此,每个分片的请求也会引入 1-RTT 的延迟,未来将与服务端一起探索预请求模式,进一步压缩延迟、降低卡顿。
CMAF 优化的整体难度较大,团队同学也经常需要在半夜和海外的 CDN 的工程师对齐和解决问题。不过经过不断的努力,最近在部分地区的也已经有了阶段性的进展,在部分场景下核心指标已经对齐 FLV,团队也有信心在最近一段时间就能去掉机型和网络类型的限制,让 CMAF 可以承载更多常规比例的流量。
(四)XR 直播的延迟优化
XR 直播的沉浸感以及高交互性是普通直播无法比拟的,但是这也导致了传输层需要承担更大的压力:分辨率为 8K x 4K 或 8K x 8K, 源流码率达到 50M 甚至 120M、非常容易因为拥塞导致卡顿、延迟增大,甚至无法正常解码播放。火山引擎视频云的做法是将 8K 的视频切分成多个块(tile),只传输用户视角(viewport)内的部分超高清块,其它区域只传输 2K 或 4K 分辨率的缩小后的背景流,在用户切换视角的时候再去重新请求新的超高清块。当然这里需要把切换延迟尽可能降到更低,经过长时间的优化,切换延迟已经降低到非常低,一般情况下已经感受不到切换的过程,未来会持续优化,让切换延迟更低。
这两种做法都引入了优先级的概念,即用户视角内的数据优先级高于其他部分,低清数据优先级高于高清数据。基于这种特性,火山引擎视频云将探索基于 UDP 的内容优先级感知的传输方案,优先保障高优数据的传输,对于低优数据可选择非可靠传输,即使丢失也无需重传,保证 XR 直播低延迟的同时不引入过大的视觉失真。经过优化后,在传输 8K x 8K/8K x 4K 的超高清视频时对播放端的码率要求从 120M/50M 降低到 20M/10M 左右甚至更低,在用户侧极大地减少了卡顿发生的概率,从而也减少了延迟增大的概率。
未来火山引擎视频云也会持续优化 XR 直播下在更高码率更高分辨率下的卡顿和延迟,为用户提供更沉浸的观看体验。




