
一、概述
在第一篇文章《苏宁基于知识图谱的大规模告警收敛和根因定位实践》中,我们详细阐述了如何构建基础设施层的知识图谱,得到了很多同行的反馈,在实际的线上环境取得了很好的告警收敛效果。但是,线上的异常事件还有另一个非常重要来源:基于 AI 的异常检测。(注:我们的 AI 异常检测复现了亚马逊诸多模型并且进行改进,通过集成算法做母模型取得了与亚马逊模型相当的水准) 异常检测虽然是通向 AIOps 的重要一环,但是由于其预测/检测的不确定性,会存在一定的误告警,当大规模使用在生产环境中时,误告警的数量开始不断叠加,很可能形成告警风暴,这是一个突出及困难的问题。本文的宗旨就是要通过可解释的知识图谱关联出现异常事件的上下文并进行真假告警的判定。此文的另一个贡献就是通过分析服务与服务间的调用关系来构建服务级的知识图谱,同时,在构建过程中,我们借鉴复现并优化了复旦与 eBay 的很有价值 Paper[3]:Graph-Based Trace Analysis for Microservice Architecture Understanding and Problem Diagnosis , 在此特别感谢他们此前做的杰出的工作。
二、痛点及对策
痛点
(1)大规模上线后异常检测形成的误告警很多
例如:某一系统的 3 天指标进行分析,3 日中告警次数为 141 次告警,而用户标记的真实告警仅发生了 7 次。
(2)告警事件中真假样本不均衡
例如:本文分析的某系统 3 天的样本标记数据来看,假告警样本为 134 个,真告警样本为 7 个,进一步分析发现真告警样本的告警类型也是 7 个,也就是每个真实告警类型 3 天内只发生了一次真实告警,进一步地,真实告警的发生频次必然不会太高这也意味着不可能获取到很多的真实告警样本数据。
(3)误告警事件种类多样
抢购活动导致异常指标飙升引发异常检测系统报警
检测指标经常性的在 0 点附近波动,导致异常检测系统发现指标异常触发下限而报警
被检测指标本身波动性较大且无周期性规律,触发异常检测系统报警
(4)标记工作量大
从用户标记的工作量来看,目前每天系统发出近百的告警信息,如果都需要用户去对每一个告警进行人工标记真假也会对用户带来巨大的工作量,影响其本来的正常工作。
由于存在着真实样本较少且样本不平衡的问题,即使通过数据增强等产生真告警样本,也需要大量的工作量去验证样本质量。我们尝试了使用对抗神经网络产生真样本,但是样本质量并不理想。
对策
针对上述痛点,我们经过大量资料翻阅和讨论,决定结合业务上下文指标和历史标记过数据进行推理。技术上构建可解释的服务层知识图谱:使用切分窗口的实时调用链数据构造基于知识图谱的调用关系,并获取调用上下文的关联指标,进而与历史标记过的数据做相似性推理,从而判明真假。
三、架构
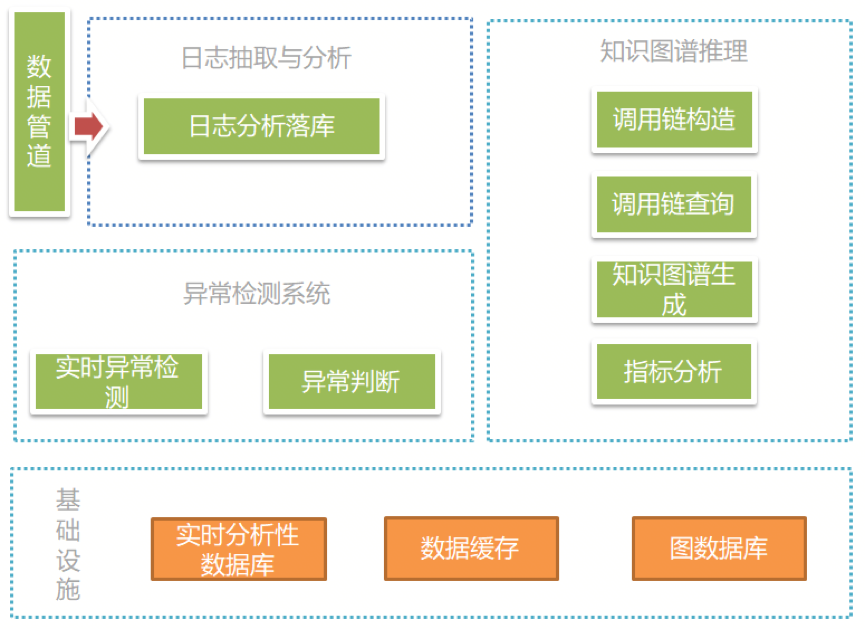
图 1 系统架构图
(1) 数据管道:利用消息中间件将调用链日志抽取到“日志抽取与分析”模块中。
(2) 日志抽取与分析:主要功能为将抽取的日志进行实时分析,并将分析结果写入到分析型数据库中。
(3) 异常检测系统:利用历史数据和深度学习概率性地计算未来指标波动边界,并以此边界判断指标是否异常。
(4) 知识图谱推理:主要功能是将分析好的调用关系同步至图数据库中,并提供查询分析功能,依据调用上下文的指标数据和历史数据进行告警的真伪判断。
四、流程
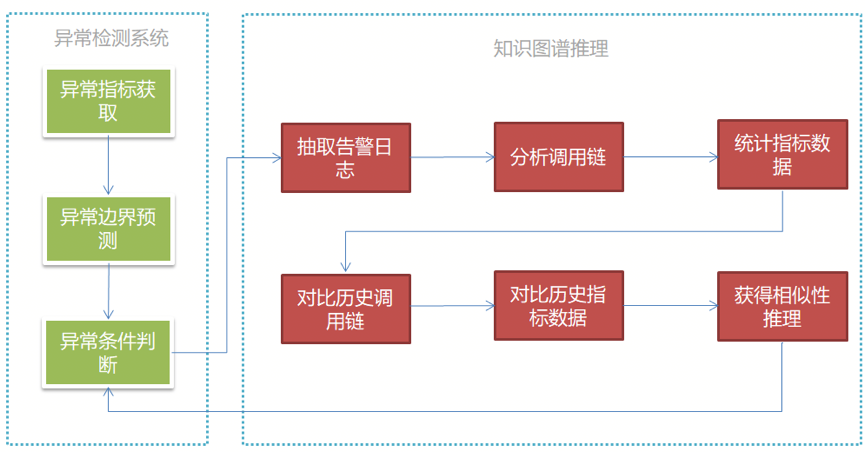
图 2 真假告警推理流程图
(1)抽取实时指标数据;
(2)历史实时指标数据集作为输入,通过深度学习模型对异常边界进行预测;
(3)对超出异常边界阈值进行判断,如超出阈值则先判定为“疑似”异常,请求知识图谱推理系统对当前异常的真伪性进行判定;
(4)设定分析窗口(3 分钟,可配置的超参),从分析型数据库中抽取对应的告警日志进行分析;
(5)根据告警日志中的 TraceID 分析出本次告警所在时间窗口内的调用链 PathID 的列表;
(6)依据本次告警所在时间窗口内的调用链 PathID 列表来统计在此列表中同时发生的上下文异常指标,以及指标的发生频次;
(7)对比历史上同告警事件的 PathID,以获得调用链相似度;
(8)利用本次告警与历史告警知识图谱上指标及其指标发生频次来推理出本次告警与历史告警上误告的上下文相似性;
(9)综合调用链相似性与指标上下文的相似性来判断本次告警是否为真实告警。
五、详细的知识图谱构建与分析
5.1 调用链日志数据的解析与入库
设定分析窗口(3 分钟),从消息管道中抽取数据。
按照日志中的 TraceID 进行聚合分析,其中调用链中服务名与操作名有缺失的部分进行丢弃处理,对没有 root 头的 Trace,多余一个 root 的 Trace 进行丢弃处理。在生成 TraceID 后按下列算法计算 PathID 并和已有的 PathID 进行对比,如果不存在则将当前调用链发给知识图谱推理系统进行保存,如果已存在则只更新当前 PathID 的相关信息。

将分析后的 Trace 信息,指标信息写入到实时分析数据库中。
5.2 Trace 明细表构建
以 TraceID 为粒度分析每条 Trace 明细的调用链关系,并生成 PathID。
将日志抽取数据和 PathID 合并,插入到 Trace 明细表中,如下图:
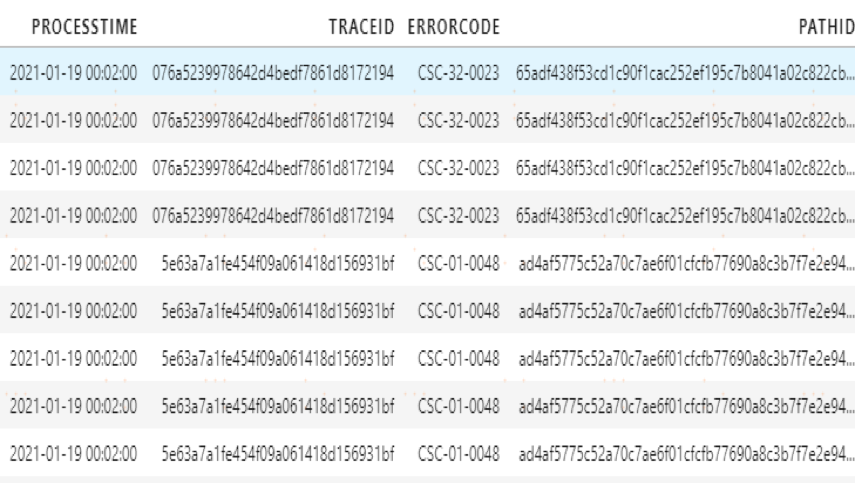
图 3 Trace 表明细
5.3 图谱构建
依据调用链中的引用关系,构建完整的实体树状结构,并计算该调用链的 PathID。
如果 PathID 相同则认为该调用链已存在不用处理,如果不同则认为是条新的调用链关系并将之存入到图数据库中。
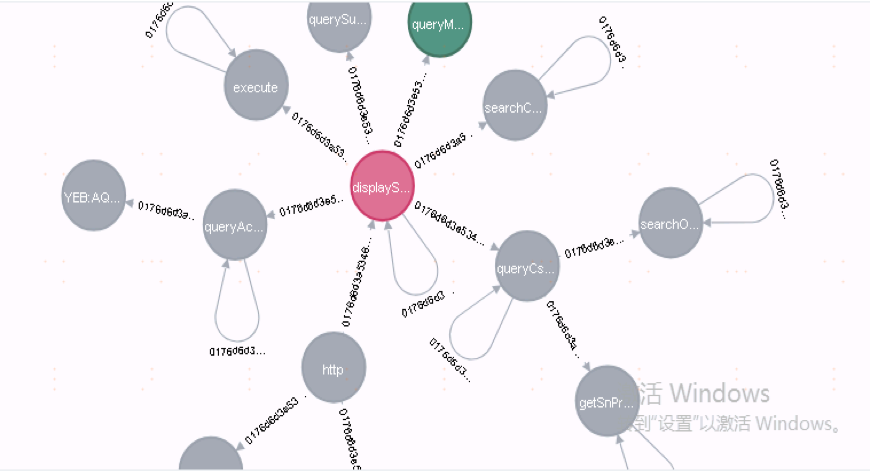
图 4 图谱构建
5.4 指标表构建
分析调用链的结构,找到发生在窗口时间内的调用链上的相关指标。
在分析窗口时间内分析相关指标的发生次数。
将相关指标的统计信息记录至指标表中。
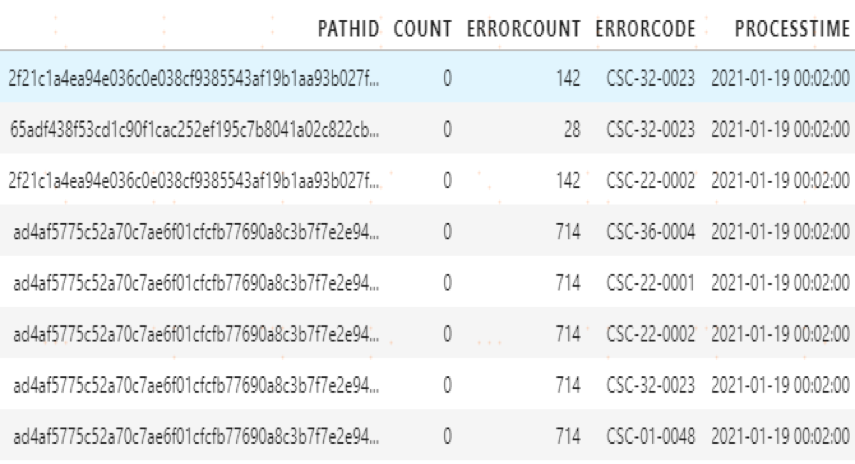
图 5 指标表明细
5.2 基于知识图谱的告警真伪分析
首先依据当前告警的调用链 PathID 寻找历史上相同指标发生误报的调用链 PathID。
依据调用链 PathID 搜寻发生在本次调用链上的相关指标以及该指标的发生次数。
通过调用链以及调用链上的相关指标来计算本地告警与历史告警的相似度。
如果相似度高于阈值则认为本次告警是误报,否则为真实告警。
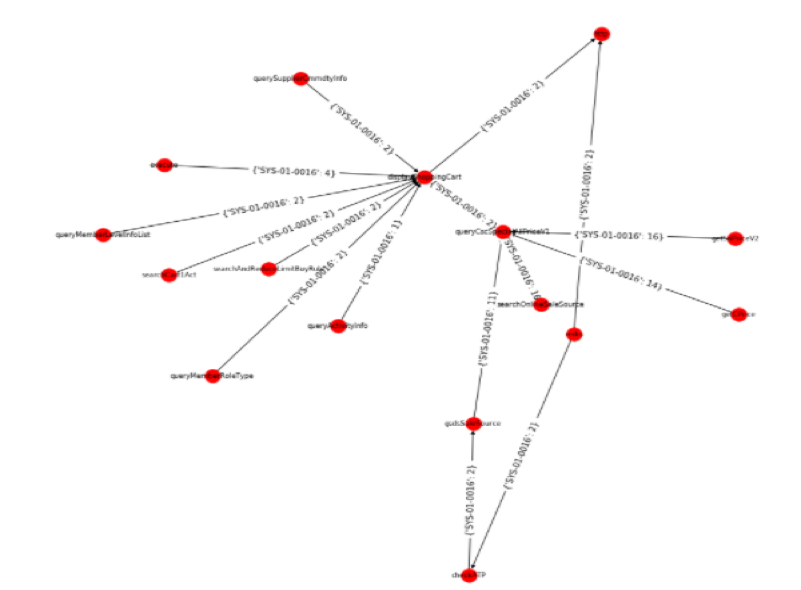
图 6 指标图谱
六、效果及后续
效果
(1)现状分析
分析样本抽取某平台 2021 年 1 月 18 日至 2021 年 1 月 20 日 3 天的告警数据,分析结果如下:
总计发生告警 141 次,其中 18 日告警发生 52 次,19 日发生告警 34 次,20 日发生告警 57 次;
进一步分析发现,在这 3 日的告警中误告发生了 134 次,真实告警只发生了 7 次,误告占比非常高;
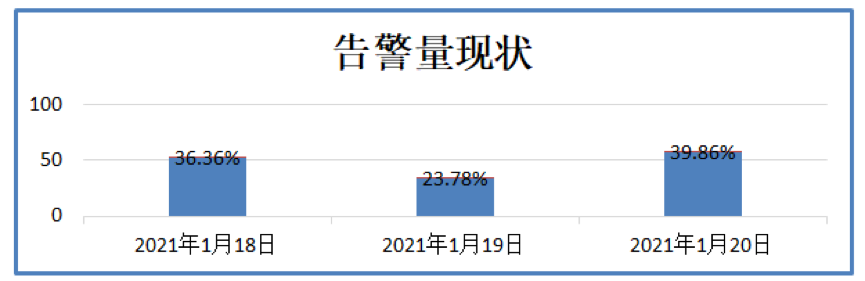
图 7 告警量现状
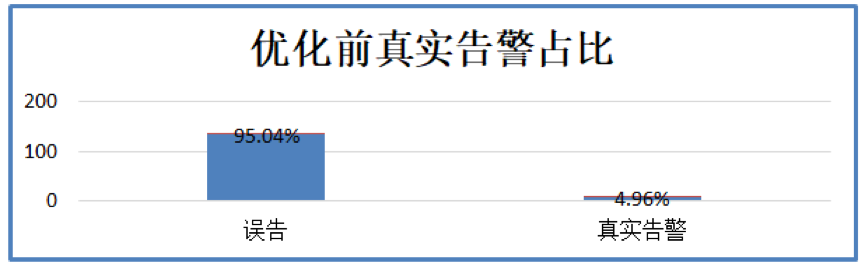
图 8 真实告警占比占比
(2)误报类型分析
从该平台告警分析的结果来看,2021 年 1 月 18 日至 2021 年 1 月 20 日 3 天的告警情况分析,共有 59 个类型的指标发生告警;
在这 59 个类型的告警中大致可分为“抢购误报类型”与“波动性误报类型”。
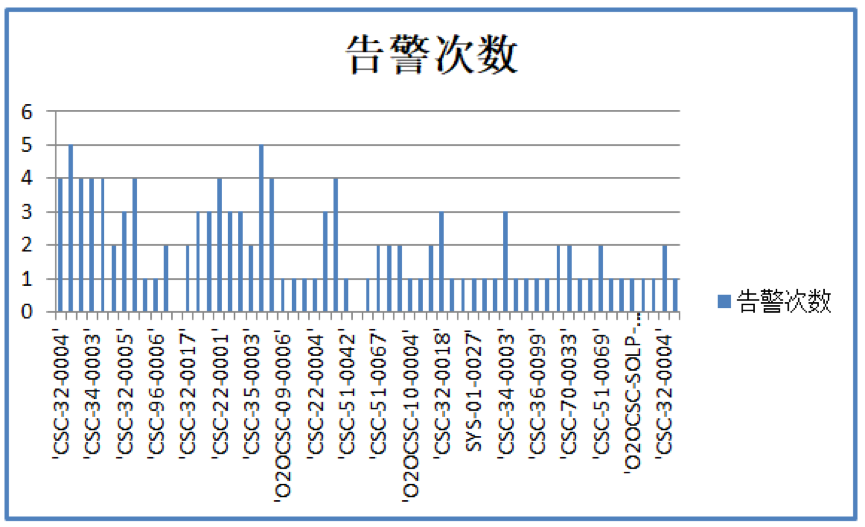
图 9 告警次数分析
(3)结果分析
“抢购误报类型”我们选择 CSC-32-0023 作为分析目标,从表中可以看出该指标 3 日都在同一时间发生告警,且该时段是有抢购现象。
“波动性误报类型”我们选择 SYS-01-0016 作为分析目标,从表中可以看出该指标每天发生在不同的时间段,且从告警现状分析该指标存在明显的波动过大而造成误报的特征。
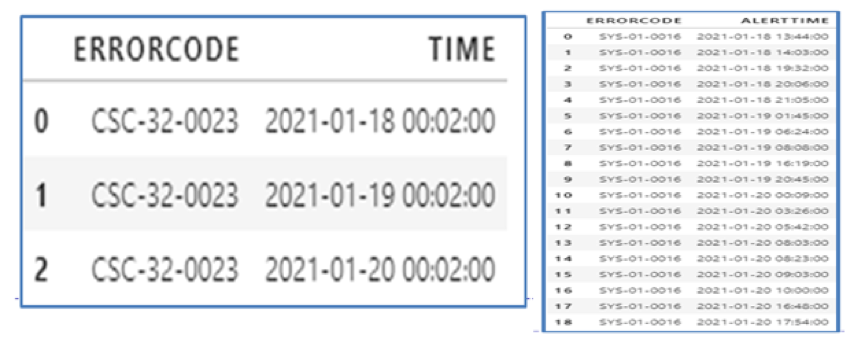
图 10
对于告警码 CSC-32-0023,18-20 号发出的告警都在每天的同一时刻,其调用链上的指标相似度较高,这三次告警得关联程度达到了 99%以上,通过初始阈值就可过滤掉该指标的误报问题。
对于告警码 SYS-01-0016,18-20 发出得告警分散在每天的不同时刻,其调用链上的指标关联性较低,所以这些告警的关联程度相较前一个告警码有所降低,不同时段调用链的相似度大约在 70%,但通过历史标记数据学习合理的关联程度阈值,可以有效的避免该指标的误报问题。
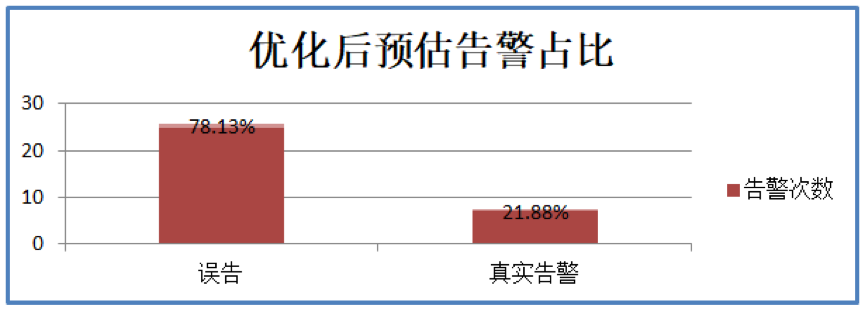
图 11 结果分析
(4)最终效果
通过分析上述误告数据,在加入知识图谱推理流程后大致能够降低 80%以上的误报,误告从 134 次减少到了 25 次,而真实告警正确率达到了 100%。
后续
服务架构理解与异常传播分析:微服务架构的全面应用虽然在开发、部署、维护方面带来极大的易用性,但也带来了微服务间接口调用的复杂性以及对系统全局的清晰理解,基于调用链构建的服务级知识图谱能能够清晰地洞察服务调用的全局,以及更重要的是,当发生故障时,能够洞察故障传播的路径和影响的系统,以便更好地响应排查故障,最大程度地减轻企业的损失。
结合《苏宁基于知识图谱的大规模告警收敛和根因定位实践》,我们已经构建了多级知识图谱,基于业务领域特点做了实体的解析和关系抽取,但是并没有针对 RDF 语义规范[4]来构建语义知识图谱,并不是说一定要按照 RDF 的标准来构建,相反,如果能够遵循这套标准来构建并使用 SPARQL 以及分布式数据处理[5]等来进行分析推理,那么语义分析的能力将进一步增强,这也是下一步我们将开展的重要工作。
参考:
Graph-Based Trace Analysis for Microservice Architecture Understanding and Problem Diagnosis
RDF 1.1 Concepts and Abstract Syntax
Distributed Semantic Analytics using the SANSA Stack
作者介绍(排名不分先后):
苏宁科技智能监控 AILab)汤泳、苏宁科技智能监控 AILab)陈延彬、苏宁科技智能监控 AILab)胡创奇、苏宁科技智能监控 AILab)张波、苏宁科技智能监控 AILab)陈松




