
本文对论文“Druid:一个实时分析数据存储系统”进行了概括总结,对 Druid 的架构、存储格式、查询 API 等进行了简要介绍。如需深入了解更多的细节,请查看论文原文。
这篇论文研究的是什么
Druid 是一个开源数据库,可以实现低延迟的近实时和历史数据分析。Druid 最初是由广告技术公司 MetaMarkets 开发的,后来被 Snap 收购,现在已被 Netflix、Confluent 和 Lyft 等公司应用于各种不同的场景中。
Druid 的目标是支持近实时的和历史数据访问模式,这让它变得非常独特,并被应用在非常广泛的场景中——例如,近实时的数据摄取可以让应用程序(如生产警报)基于日志快速发现问题(类似于 Netflix 的应用场景),同时也可以基于大量历史数据执行警报逻辑。相比之下,许多数据仓库产品都是以“批处理”为基础,这导致记录指标时的时间与进行分析时的时间之间出现延迟。
除了介绍系统的设计和实现外,这篇论文还讨论了系统组件可用性的降低是如何影响用户的。很少有论文会用这种方式来组织有关生产系统的论文,而且这种方式令人耳目一新。
这篇论文的贡献
这篇论文有以下几个贡献。
对系统架构进行了描述;
探索设计决策和实现;
对系统查询 API 和性能结果进行了评估。
系统的工作原理
分片和数据源
片段是 Druid 的一个关键抽象。它们是一种不可变(但有版本控制)的数据结构,其中保存了一系列记录。片段的集合组合成数据源,也就是 Druid 的数据库表。每个片段中保存了某个数据源在一个时间段内写入的记录。

系统架构
Druid 通过摄取数据来构建片段,然后在对查询做出响应时访问这些片段。
Druid 通过四种类型的节点来实现数据的摄入和查询:实时节点、历史节点、Broker 节点和协调器节点。
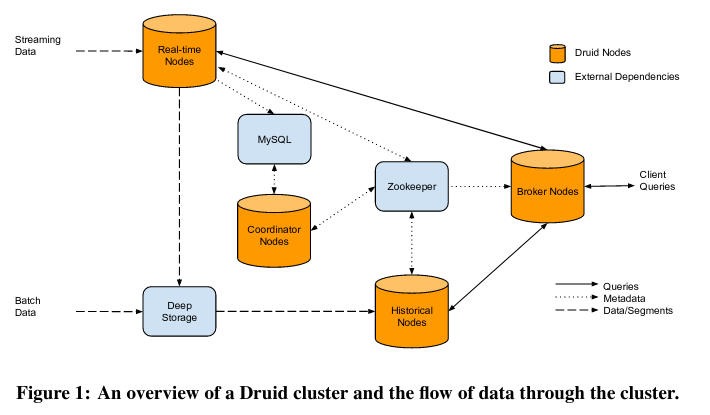
与单个无状态节点不同,Druid 将状态存储在两个数据源中。
MySQL,其中包含了配置信息和元数据,比如片段的索引。
Zookeeper,存储系统的当前状态(包括片段的副本保存在系统中的哪些分布式节点上)。
实时节点
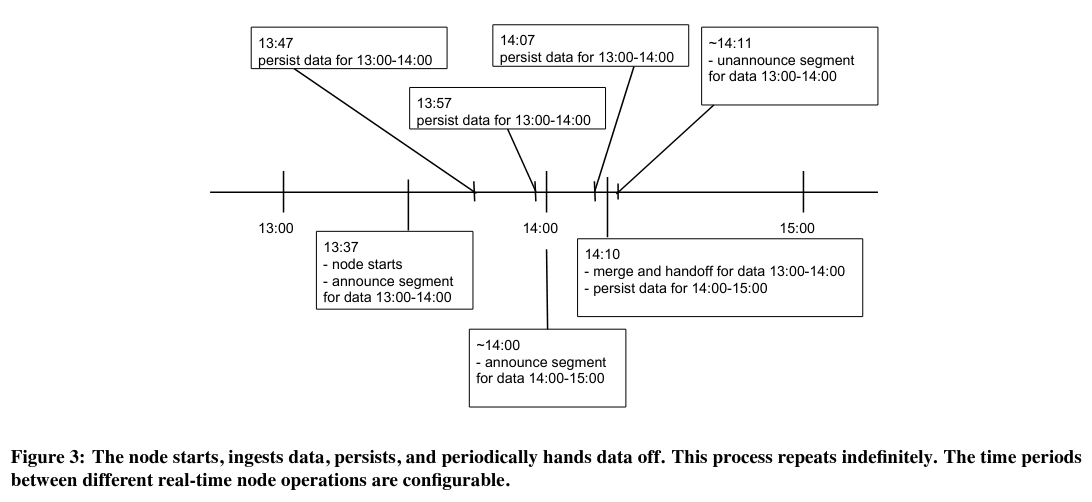
实时节点有两个职责:从生产者那里获取数据和响应用户对最新数据的请求。
生产者将原始数据(比如数据库中的记录行)或转换后的数据(比如流式处理管道的输出)发送给实时节点——常见的生产者模式依赖了 Kafka 主题。Kafka(或其他消息总线)为数据提供了更好的可用性和可伸缩性——实时节点可以保存它们已经消费的偏移量,在发生崩溃或重启时可以重置到这个偏移量。为了提高伸缩性,可以用多个实时节点分别读取相同消息总线的不同子集。
当实时节点在消费来自生产者的记录时,它会检查与记录关联的时间段和数据源,然后将记录路由到具有相同(时间段、数据源)键的内存缓冲区中。
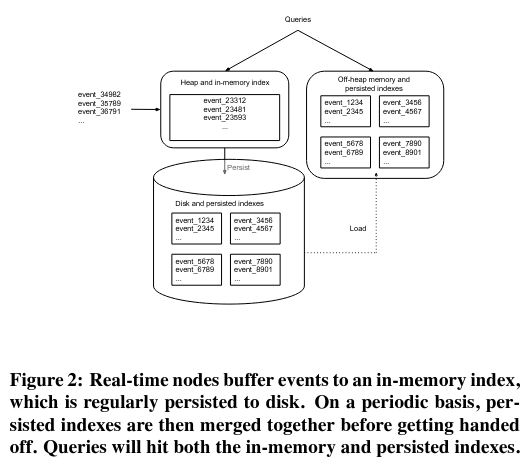
每个(时间段、数据源)缓冲区在被清除之前会暂时保留在节点上——由于资源有限,节点需要定期从内存中清除记录缓冲区。在回收时,内存缓冲区中的数据将被写入“深度”存储系统(如 S3 或谷歌云存储)。
除了数据摄取之外,实时节点还对数据查询请求做出响应。为了响应这些请求,实时节点会使用内存中的临时索引进行扫描。
历史节点
历史节点从存储中读取不可变的数据片段,并对查询做出响应——协调节点(将在下一小节介绍)控制一个历史节点可以获取哪些片段。当一个历史节点成功下载了一个片段,它会告诉系统的服务发现组件(Zookeeper),然后用户查询就可以访问这个片段。不幸的是,如果 Zookeeper 离线,系统将无法提供新的片段——历史节点将无法告知已成功获取片段,所以 Druid 负责查询数据的组件将无法转发查询。
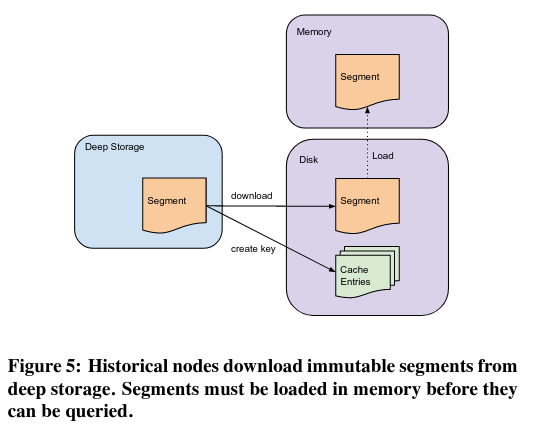
使用不可变片段简化了历史节点的实现。首先,它简化了系统的伸缩——如果有多个请求涉及同一个片段,就会有更多的历史节点存储片段的副本,导致查询在集群中扩散。其次,操作数据片段而不是较低层次的抽象意味着历史节点可以简单地等待被告知有一个新版本的数据需要获取,而不需要监听片段是否发生了变化。
协调器节点
协调器节点决定哪些片段存储在历史节点上,以及存储多长时间。
为了做出决定,协调器节点从两个位置读取数据:MySQL 和 Zookeeper。MySQL 保存了片段的信息,以及与每个段类型相关的元数据。Zookeeper 保存了系统服务的所有片段的当前状态——实时节点和历史节点用它来宣布哪些片段是可用的。协调器节点还可以在整个系统中对片段进行负载均衡,以免对同一节点进行多次读取时出现“热点”数据。
论文指出,一个集群中有多个正在运行的协调器节点,但同时只有一个“首领”——其他节点用于故障转移。如果协调器节点不可用(可能因为 MySQL 或 Zookeeper 出了问题),那么历史节点和实时节点将继续运行,但可能会出现超载(由于没有了负载均衡)。此外,论文还指出,这种情况会导致新数据不可用。
Broker 节点
最后,Broker 节点接收来自外部客户端的请求,从 Zookeeper 读取状态,并根据需要将请求转发给历史节点和实时节点。Broker 节点还可以在本地缓存数据片段,以应对未来可能出现的对相同数据的访问。
如果 Zookeeper 不可用,那么 Broker 将使用“最后已知的状态”来转发查询。
存储格式
如前所述,数据片段是 Druid 的一个关键抽象,一种用于存储数据的不可变数据结构。每一个片段都与一个数据源(Druid 中的表)相关联,并包含特定时间段的数据。
片段由两种类型的数据组成:维度和指标。维度是行聚合或过滤的值,而指标对应于数值数据(如计数)。

片段中还包含了版本号。如果一个片段发生变化,版本号会增加,并发布一个新的片段版本——如果已经确定的片段加入了延迟事件,就会发生这种情况。协调器节点会告诉历史节点获取新版本并删除旧版本,从而实现向新版本段的迁移。因为采用了这种方式,Druid 被认为实现了多版本并发控制(MVCC)。
重要的是,片段是按照列(而不是行)来存储数据的——这种方法被称为“列式存储”。这种设计被用于其他几种数据库(如 Redshift 和 Cassandra)和文件格式(如 Parquet)中,因为它提供了性能优势。
例如,如果一个查询选择了列的子集,那么数据库只需要查询这些列的数据子集。基于行的解决方案需要扫描每一行,并选择相关的列。虽然这两种扫描都会产生相同的结果,但基于行的扫描(几乎)肯定会访问不必要的列,而这些列不是查询所需要的,也不会出现在查询结果中。
查询 API
论文中对 HTTP 查询 API 进行了描述,用户可以指定数据源、时间范围、过滤和聚合。

近期版本的查询 API 与论文中描述的有所不同。当前版本的 Druid 提供了一个SQL风格的API来编写和提交查询。论文还说明了为什么 Druid 还不支持连接查询,尽管近期的工作已经实现了这个想法。
如何评估这项研究
为了评估这个系统,论文对部署在 MetaMarkets 的 Druid 的性能和规模进行了评测。
因为 Druid 最初是为低延迟查询而设计的,所以使用生产流量跟踪来评估延迟性能。
对于所有不同的数据源,平均查询延迟大约为 550 毫秒,90%的查询在 1 秒内返回,95%在 2 秒内返回,99%在 10 秒内返回。
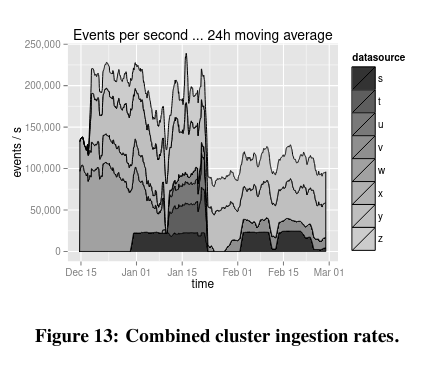
数据摄入延迟是 Druid 设计的另一个重点。MetaMarkets 的生产系统能够以最小的延迟和显著的吞吐量摄取不同形式和大小的数据集。
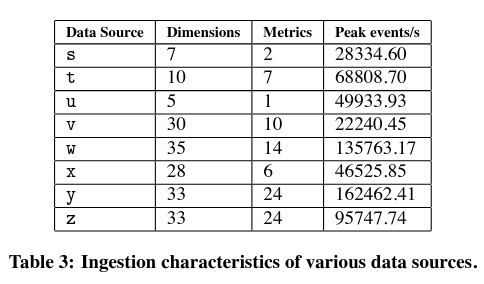
论文还指出,虽然摄入延迟存在差异,但可以通过为相关组件添加更多的资源来解决这个问题(如果特别关注这个属性,实现者可能会做出这样的决定)。
结论
我发现 Druid 论文很有趣,因为它的设计目标是同时处理实时和历史数据分析。
这个系统代表了实现上述设计目标的一个步骤——Druid 是“Lambda架构”的第一个实现。最近的Kappa和 Delta 架构似乎是对 Druid 最初建议的架构的改进。
我很喜欢这篇论文,因为它讨论了系统在退化状态下的行为。随着 Druid 后续的演进,论文的一些细节可能会过时,但它的一些系统设计想法仍然是很独特的。
原文链接:https://www.micahlerner.com/2022/05/15/druid-a-real-time-analytical-data-store.html




